
- 13D-DIC数字图像相关法测量流程介绍-数字图像采集_视觉软件中触发周期是什么意思
- 2【windows】亲测-win11系统跳过联网和微软账户登录,实现本地账户登录_win11跳过联网激活
- 3【数据结构和算法初阶(C语言)】时间复杂度(衡量算法快慢的高端玩家,搭配例题详细剖析)_衡量一个算法好坏一般以最坏的时间复杂度为标准
- 4如何在群晖NAS搭建bitwarden密码管理软件并实现无公网IP远程访问_群晖怎么安装bitwarden
- 5基于Hadoop的区块链海量数据存储的设计与实现_区块链 hdfs
- 6iOS(一):Swift纯代码模式iOS开发入门教程_swift 开发ios入门教程
- 7学懂C语言系列(三):C语言基本语法
- 8kafka架构深入
- 9Langchain-chatchat: Langchain核心组件及应用_langchain chatchat
- 10【爬虫】1.4 POST 方法向网站发送数据_网页爬虫 post数据
Amazon SageMaker 上的 Baichuan2 模型微调及部署(一)微调部分
赞
踩

自 2022 年底以来,生成式 AI 技术已经成为我们这个时代最具创新力的技术之一,也是引领未来发展的关键力量。大语言模型作为潮流最前线的推动者,有着不可置否的影响力。以 Meta 的 LLaMA 为首,生成式 AI 模型社区在短时间内涌现出大批开源模型,成为构建开源模型生态的重要里程碑。同时,国内的中文开源模型也不遑多让,包括 Baichuan 在内的模型在各大模型评测榜单上都有着出色的表现。模型的微调和部署是玩转开源模型的关键技术,本文将以 Baichuan2 为例,主要介绍如何利用 Amazon SageMaker 微调及部署 Baichuan2 模型。
Baichuan2 模型介绍
Baichuan2 系列模型是百川智能推出的新一代开源大语言模型,其在总量为 2.6 万亿 Tokens 的高质量中英文及代码语料上做预训练,在多个权威评测榜单上取得同尺寸下较好的效果。开源版本中包含有 7B、13B 的 Base 和 Chat 版本,其中 Base 版本指的是直接经过预训练得到的模型,而 Chat 是基于 Base 版本的基础上做指令微调(instruction-tuning)和 RLHF 得到。
Baichuan2 模型微调
本章将介绍如何使用 SageMaker 进行 Baichuan2 模型的微调,内容将分为三部分:
进行训练的准备工作;
构建 SageMaker Training Job 需要的相关代码;
用不同方法对 Baichuan2 模型进行微调,包括了 LoRA 微调和全量微调两种方法。
准备工作
使用 SageMaker Training Job 进行模型训练时,训练环境每次都将会被重新构建,因此我们推荐预先准备好微调需要的预训练模型和数据,上传至 Amazon S3,这可以有效节省启动训练花费的时间。
准备预训练模型
首先我们在 SageMaker Notebook 中(或任意可以访问互联网和 S3 的环境中)下载 Baichuan2 提供的预训练模型,这里以 Baichuan2-13B-Chat 为例:
Python
- from huggingface_hub import snapshot_download
- from pathlib import Path
-
-
- local_cache_path = Path("./baichuan2-13b-chat")
- local_cache_path.mkdir(exist_ok=True)
-
-
- model_name = "baichuan-inc/Baichuan2-13B-Chat"
-
-
- # Only download pytorch checkpoint files
- allow_patterns = ["*.json", "*.pt", "*.bin", "*.model", "*.py"]
-
-
- model_download_path = snapshot_download(
- repo_id=model_name,
- cache_dir=local_cache_path,
- allow_patterns=allow_patterns,
- )

再上传至 S3,供后续训练模型时使用:
Bash
- # Change to your own local path and S3 bucket
- aws s3 cp ./baichuan2-13b-chat s3://{your-s3-pretrain-model-path} --recursive
准备训练数据
以官方提供的数据样例为例,将它上传至 S3,供后续训练模型时使用:
Bash
- # Change to your own local path and S3 bucket
- aws s3 cp ./belle_chat_random_10k.json s3://{your-s3-data-path}
SageMaker Training Job 相关代码
使用 SageMaker Training Job 时,除了微调 Baichuan2 模型本身需要的训练代码外,还依赖其他一些代码来构建训练环境。这里我们推荐按以下结构来组织文件:
- src/
- ├── fine-tune.py
- ├── ds_config.json
- ├── requirements.txt
- ├── s5cmd
- ├── entry.py
- └── train.sh
下面将解释每个文件的内容和用途。
fine-tune.py 和 ds_config.json
这两个文件均由 Baichuan2 官方提供,地址位于:https://github.com/baichuan-inc/Baichuan2/tree/main/fine-tune。
为了适配 SageMaker Training Job 的训练环境,需要对 fine-tune.py 文件做以下修改:
Python
- if __name__ == "__main__":
- ############################
- LOCAL_RANK = int(os.environ['LOCAL_RANK'])
- WORLD_SIZE = int(os.environ['WORLD_SIZE'])
- WORLD_RANK = int(os.environ['RANK'])
- deepspeed.init_distributed(dist_backend='nccl', rank=WORLD_RANK, world_size=WORLD_SIZE)
- ############################
- train()
为了在训练时使用我们提前上传至 S3 的预训练模型,我们推荐在 fine-tune.py 的 train()函数中进行以下修改,将上传的预训练模型拷贝到运行环境中:
Python
- ...
-
-
- def train():
- parser = transformers.HfArgumentParser(
- (ModelArguments, DataArguments, TrainingArguments)
- )
- model_args, data_args, training_args = parser.parse_args_into_dataclasses()
-
- ############################
- if 0 == LOCAL_RANK:
- print("*****************start cp pretrain model*****************************")
- os.system("chmod +x ./s5cmd")
- os.system("./s5cmd sync {0} {1}".format(os.environ['MODEL_S3_PATH'], os.environ['MODEL_LOCAL_PATH']))
- print(f'------rank {LOCAL_RANK} finished cp-------')
-
- torch.distributed.barrier()
- ############################
- model = transformers.AutoModelForCausalLM.from_pretrained(
- model_args.model_name_or_path,
- trust_remote_code=True,
- cache_dir=os.environ['MODEL_LOCAL_PATH'],
- )
-
- ...
此外,为了将微调后的模型保存至 S3 方便我们后续使用,我们对 train()函数进行以下修改,在保存模型后上传至 S3:
Python
- ...
- def train():
-
- ...
-
- trainer.save_state()
- trainer.save_model(output_dir=training_args.output_dir)
-
- ############################
- if WORLD_RANK == 0:
- persistant_path = os.environ['OUTPUT_MODEL_S3_PATH'] + str(datetime.now().strftime("%m-%d-%Y-%H-%M-%S")) + '/'
- os.system("./s5cmd sync {0} {1}".format(training_args.output_dir, persistant_path))
-
-
- torch.distributed.barrier()
- ############################
当训练的 GPU 显存不是很大时,例如在 A10G 卡(24G 显存)上训练,为了避免出现 Out Of Memory 的错误,可以通过在 ds_config.json 文件里修改 zero_optimization 的配置来开启 offloading,修改的方式如下:
- "zero_optimization": {
- "stage": 3,
- "offload_optimizer": {
- "device": "cpu",
- "pin_memory": true
- },
- "offload_param": {
- "device": "cpu",
- "pin_memory": true
- },
- "overlap_comm": true,
- "stage3_gather_16bit_weights_on_model_save": true
- },
requirements.txt
这个文件定义了训练所需的 python 环境,可参考:
- numpy
- transformers==4.33.1
- sentencepiece
- tokenizers
- accelerate
- deepspeed==0.12.2
- bitsandbytes
特别注意其中 transformers 的版本,在本文写作时推荐使用 4.33.1,但这个信息可能失效。
s5cmd
上面的代码用到了 s5cmd 这个工具在本地和 S3 间传输文件,可以使用下面的代码下载这个工具:
Bash
curl -L https://github.com/peak/s5cmd/releases/download/v2.0.0/s5cmd_2.0.0_Linux-64bit.tar.gz | tar -xz如果不希望使用这个工具,也可以将相关命令替换为 s3 cp 实现同样功能。
entry.py
这个文件定义了 SageMaker Training Job 训练环境的一些参数,通常不需要修改:
Python
- import os
- import json
- import socket
-
-
- if __name__ == "__main__":
-
- hosts = json.loads(os.environ['SM_HOSTS'])
- current_host = os.environ['SM_CURRENT_HOST']
- host_rank = int(hosts.index(current_host))
-
- #Parse the IP address of the master node in the multiple nodes cluster of SageMaker training.
- master = json.loads(os.environ['SM_TRAINING_ENV'])['master_hostname']
- master_addr = socket.gethostbyname(master)
-
- os.environ['DS_BUILD_FUSED_ADAM'] = '1'
- os.environ['NODE_INDEX'] = str(host_rank)
- os.environ['SM_MASTER'] = str(master)
- os.environ['SM_MASTER_ADDR'] = str(master_addr)
- os.environ['NCCL_SOCKET_IFNAME'] = 'eth0'
-
- # backend env config
- # os.environ['CUDA_LAUNCH_BLOCKING'] = '1'
- os.environ['FI_PROVIDER'] = 'efa'
- os.environ['NCCL_PROTO'] = 'simple'
- # os.environ['FI_EFA_USE_DEVICE_RDMA'] = '1'
- os.environ['NCCL_DEBUG'] = 'INFO'
- os.environ['HCCL_OVER_OFI'] = '1'
-
- # os.system("wandb disabled")
-
- #invoke the torch launcher shell script.
- #Note: we will use the pytorch launcher to launch deepspeed for multi-nodes training.
- #Note: we will use the s5cmd to speed up the uploading model assets to S3.
- os.system("chmod +x ./train.sh")
- os.system("chmod +x ./s5cmd")
- os.system("/bin/bash -c ./train.sh")
train.sh
这个文件主要定义了微调 Baichuan2 模型的超参数,其中一些比较重要的超参数我们将在下一节进行讲解:
Bash
- #!/bin/bash
-
-
- pip uninstall -y torch torchvision torchaudio
- pip install torch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 --index-url https://download.pytorch.org/whl/cu118
-
-
- chmod +x ./s5cmd
-
-
- DISTRIBUTED_ARGS="--nproc_per_node $SM_NUM_GPUS --nnodes $NODE_NUMBER --node_rank $NODE_INDEX --master_addr $SM_MASTER_ADDR --master_port 12345"
-
- torchrun ${DISTRIBUTED_ARGS} fine-tune.py \
- --data_path "/opt/ml/input/data/train1/belle_chat_random_10k.json" \
- --model_name_or_path "baichuan-inc/baichuan2-13B-Chat" \
- --output_dir "/tmp/baichuan2_out" \
- --model_max_length 1024 \
- --num_train_epochs 2 \
- --per_device_train_batch_size 2 \
- --gradient_accumulation_steps 16 \
- --evaluation_strategy "no" \
- --save_strategy epoch \
- --learning_rate 1e-5 \
- --lr_scheduler_type constant \
- --adam_beta1 0.9 \
- --adam_beta2 0.98 \
- --adam_epsilon 1e-8 \
- --max_grad_norm 1.0 \
- --weight_decay 1e-4 \
- --warmup_ratio 0.2 \
- --logging_steps 1 \
- --gradient_checkpointing True \
- --deepspeed ds_config.json \
- --fp16 False \
- --bf16 True \
- --cache_dir "/tmp"
-
-
-
-
- if [ $? -eq 1 ]; then
- echo "Training script error, please check CloudWatch logs"
- exit 1
- fi
注意上面的代码升级了 pytorch 的版本以满足 Baichuan2 模型微调的需要,如果您后续使用的训练镜像中 pytorch 版本已经满足要求,则不需要执行这部分命令。
正式进行微调
这一节将介绍微调 Baichuan2 模型的一些重要配置,最后会介绍如何启动 SageMaker Training Job。
微调方法选择
Baichuan2 模型提供了便捷的方式在全量微调和 LoRA 微调两种方法间切换,在 train.sh 脚本的 torchrun 命令中增加以下参数就可以切换为 LoRA 微调:
Bash
--use_lora True训练数据路径
在 train.sh 脚本中,我们通过以下参数定义训练文件的路径:
Bash
--data_path "/opt/ml/input/data/train1/belle_chat_random_10k.json"请注意在实际训练中,您需要将这个路径中的文件名(belle_chat_random_10k.json)部分修改为您自己的文件名,但目录名(/opt/ml/input/data/train1/)不需要修改,这是因为在启动训练时会指定训练文件所在的 S3 路径,随后 SageMaker Training Job 会自动将训练文件从 S3 同步至训练环境的/opt/ml/input/data/train1/目录下,因此这里的参数只需要修改文件名即可。
其他重要超参数
其他比较重要的超参数包括了 per_device_train_batch_size(即 micro batch,每个 GPU 上同时训练的样本数量),gradient_accumulation_steps,model_max_length 等:
Bash
- --model_max_length 1024 \
- --per_device_train_batch_size 2 \
- --gradient_accumulation_steps 16 \
这些参数不仅影响微调效果,也决定了模型在微调时的显存使用量是否适配您选择的实例类型,需要根据实际情况进行相应修改。
启动训练
在 SageMaker Notebook 中使用以下代码正式启动 Training Job:
Python
- import sagemaker
- import boto3
- import time
- from sagemaker import get_execution_role
- from sagemaker.estimator import Estimator
-
-
- sess = sagemaker.Session()
- role = get_execution_role()
- sagemaker_default_bucket = sess.default_bucket()
- region = sess.boto_session.region_name
-
-
- ## pre-built docker in https://github.com/aws/deep-learning-containers/blob/master/available_images.mdr'
- image_uri = '763104351884.dkr.ecr.us-west-2.amazonaws.com/pytorch-training:2.0.1-gpu-py310-cu118-ubuntu20.04-sagemaker'
-
-
- instance_count = 1
- instance_type = 'ml.p4de.24xlarge' ## p4d - 8*40G / p4de - 8*80G
-
-
- environment = {
- 'NODE_NUMBER':str(instance_count),
- 'MODEL_S3_PATH': '{your-s3-pretrain-model-path}/*', # pretrain model files in s3, note must have /*
- 'MODEL_LOCAL_PATH': '/tmp/hf_models',
- 'OUTPUT_MODEL_S3_PATH': '{your-s3-finetune-model-path}', # finetune model destination
- }
- estimator = Estimator(role=role,
- entry_point='entry.py',
- source_dir='./src',
- base_job_name='multi-node-baichuan-train',
- instance_count=instance_count,
- instance_type=instance_type,
- image_uri=image_uri,
- environment=environment,
- max_run=2*24*3600, #任务最大存续时间
- disable_profiler=True,
- debugger_hook_config=False)
- # # data in channel will be automatically copied to each node - /opt/ml/input/data/train1
- # # should change data_path param to above path in torchrun
- input_channel = {'train1': '{your-s3-data-path-prefix}'}
- estimator.fit(input_channel)
其中 instance_type 和 instance_count 定义了训练任务使用的实例类型和数量。根据训练数据文本长度的不同,在进行全量微调时我们推荐使用 1 个 g5.48xlarge、p4d.24xlarge 或 p4de.24xlarge 实例,在进行 LoRA 微调时,推荐使用 1 个 g5.48xlarge 实例。最优的实例配置需要根据实际情况进行探索。environment 中定义了预训练模型的 S3 路径(MODEL_S3_PATH),以及微调后模型的保存路径的 S3 路径(OUTPUT_MODEL_S3_PATH),在 input_channel 部分则定义了训练数据所在的 S3 路径前缀(即不包括文件名的部分),这些参数均需要根据实际情况做相应修改。
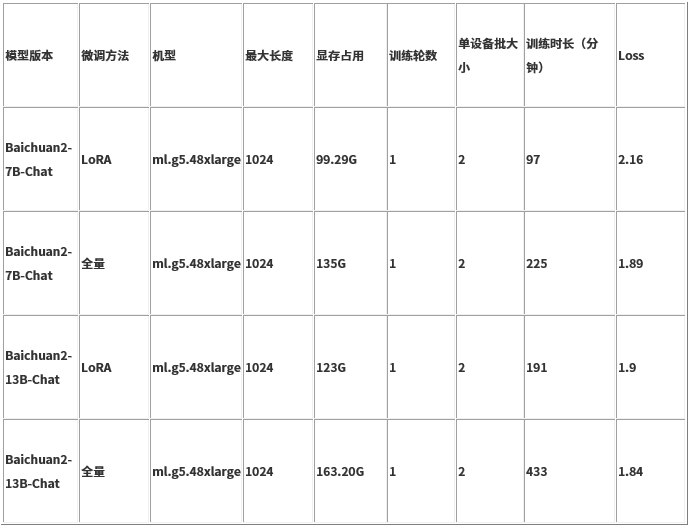
微调性能对比
我们以 belle 数据集为例,对比不同微调方法在不同模型大小下的训练时长和 Loss。
系列博客
Amazon SageMaker 上的 Baichuan2 模型微调及部署(二)部署部分:https://aws.amazon.com/cn/blogs/china/baichuan2-model-fine-tuning-and-deployment-on-amazon-sagemaker-part-two/
本篇作者

冉晨伟
亚马逊云科技应用科学家,长期从事生成式 AI、自然语言处理、信息检索等领域的研究和开发工作。支持 GenAI 实验室项目,在大语言模型、搜索排序、预训练、多模态模型等方向有丰富的算法开发以及落地实践经验。

魏亦豪
亚马逊云科技应用科学家,长期从事生成式 AI、自然语言处理、多模态预训练等领域的研究和开发工作。支持 GenAI 实验室项目,在对话系统、智能客服、虚拟陪伴、预训练、多模态模型等方向有丰富的算法开发以及落地实践经验。

张闯
亚马逊云科技应用科学家,长期从事生成式 AI、自然语言处理、计算机视觉等领域的研究和开发工作。支持 GenAI 实验室项目,在大语言模型、多模态模型、强化学习、智能客服、内容安全等方向有丰富的算法开发以及落地实践经验。

蔡天勤
亚马逊云科技应用科学家,长期从事生成式 AI、自然语言处理、多模态预训练等领域的研究和开发工作。支持 GenAI 实验室项目,在广告推荐、搜索排序、预训练、多模态模型等方向有丰富的算法开发以及落地实践经验。

王鹤男
亚马逊云科技资深应用科学家,负责数据实验室项目,熟悉计算机视觉、自然语言处理、传统机器学习模型等领域,领导了首汽约车语音降噪、LiveMe 直播场景反欺诈等项目,为企业客户提供云上的人工智能和机器学习赋能。曾任汉迪推荐算法工程师,神州优车集团人工智能实验室负责人等职位。

星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」

听说,点完下面4个按钮
就不会碰到bug了!


