- 1【C++】类与对象(三)—运算符重载|const成员函数|取地址及const取地址操作符重载_c++运算符重载的const
- 2《云原生安全攻防》-- 容器攻击案例:Docker容器逃逸
- 3【Ai应用】Springboot集成通义千问api开发一个对话应用_springboot 对接通义千问
- 4ES(ElasticSearch)搜索_es获取每个索引当天搜索词
- 5Linux 入门教程 by 程序员鱼皮
- 6放弃 RNN/LSTM 吧,因为真的不好用!望周知~_lstm文本分类准确率不高的原因
- 7PyQt5 事件处理机制_pyqt5 按钮事件
- 8网络工程专业的毕业生现在都在干什么,后悔当时的选择吗?_选网络工程后悔
- 9Bert解析,state of the art的语言模型
- 10详解QPropertyAnimation的使用--实现Qt动画效果_qpropertyanimation 起到
Transformer——encoder_transformer encoder
赞
踩
本文参考了b站的Eve的科学频道中的深入浅出解释Transformer原理和DASOU讲AI中的Transformer从零详解。
入浅出解释Transformer原理
Transformer从零详解
前言:
在自然语言识别中,之前讲过lstm,但是lstm有明显的缺陷,就是当文本过于长的时候,考前的文本信息和后的文本信息,关联性就会越来越弱,并且因为链式求导的原因,会导致梯度消失,所以这里就学习了一种新型神经网络Transformer,他和前面的网络很不一样,他是一种基于注意力的编码-解码架构。
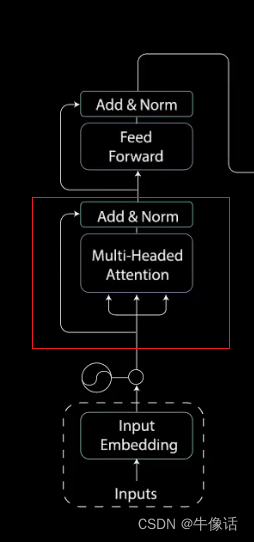
单个网络结构:
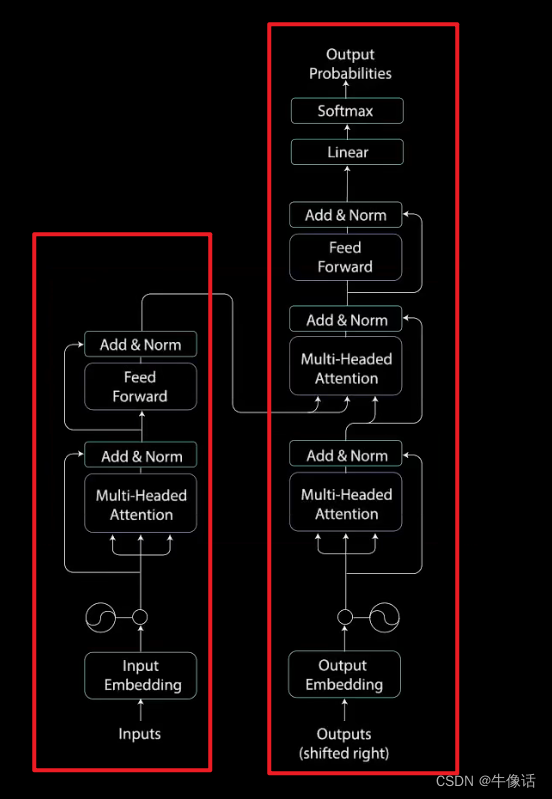
如上图所示,左边为编码部分,右边为解码部分,接下里,我们将会从编码部分开始讲解。
1.输入部分
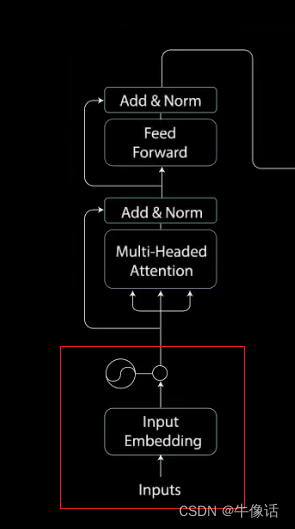
如上图所示,红框部分就是输入部分,inputs就是我们的文本信息,比如how are you ,而input Embedding,就是把我们输入的这一段话,做嵌入,使他形成词向量(比如word2vec),比如我们把how are you,可以做成如下所示的词向量
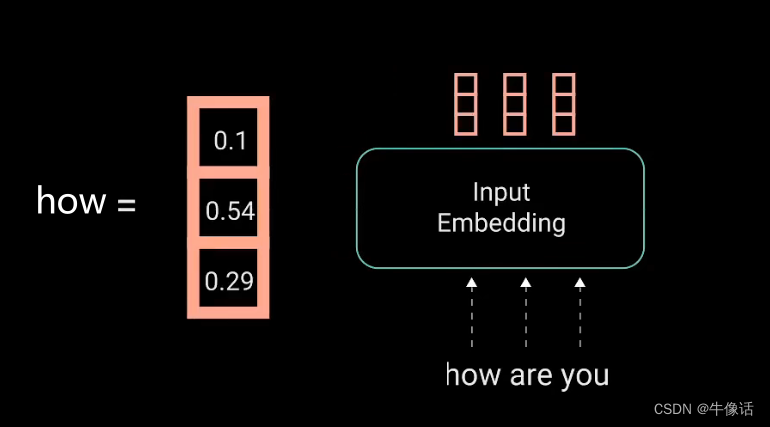
词向量嵌入完成后,还要加上位置信息,因为在lstm中,每个隐含层的节点,都是要接收上一个隐含层的输出,所以他是有天然的时序顺序在里面的。但是transformer中,我们没有使用rnn,所以就需要我们给他的词向量中加入位置信息。
位置编码公式如下:
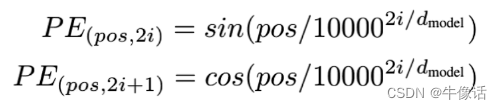
我们可以看出有两个参数2i和2i+1,他的意思就是在词向量的偶数位置做sin运算,在奇数位置做cos运算,如下图
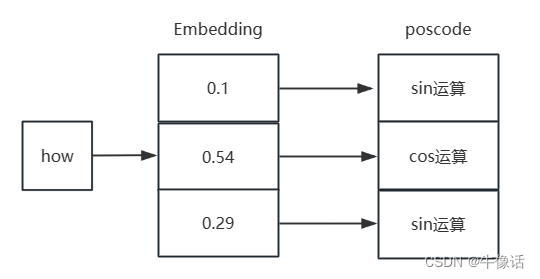
然后接下来,把原来的Embedding和posCode进行相加,如下图所示
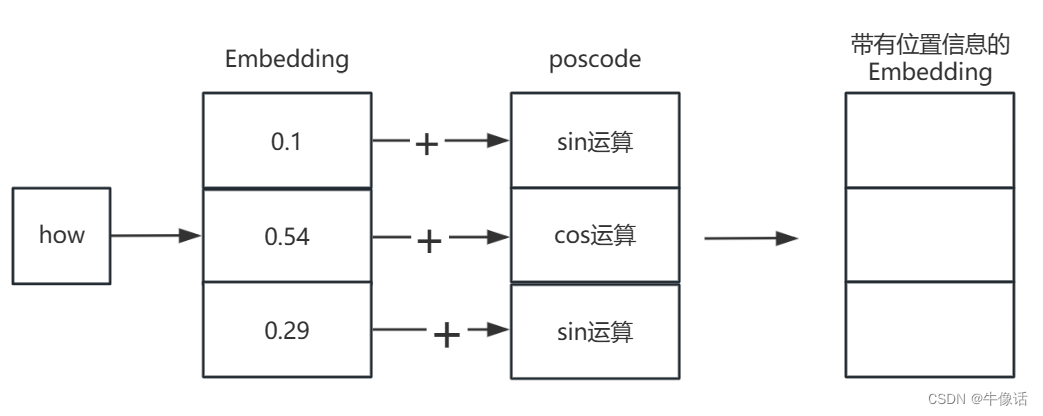
2.多头注意力模块:
自注意力机制,简单来说就是模型先要把输入的文本中,每个单词和其他单词关联起来,然后在矩阵中表示出,哪些单词是重要的单词,下图就是自注意力机制的内部构造。
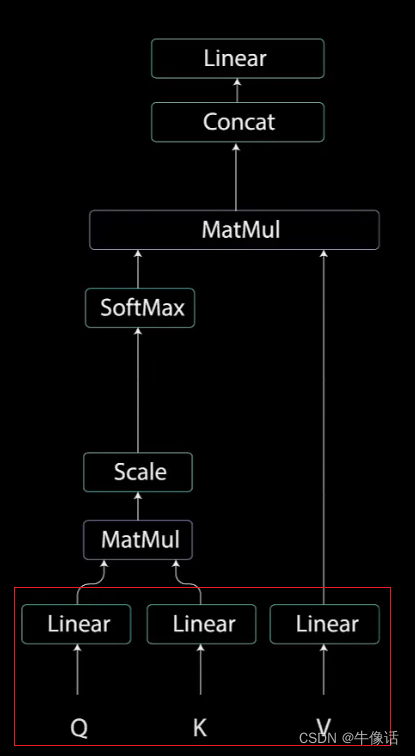
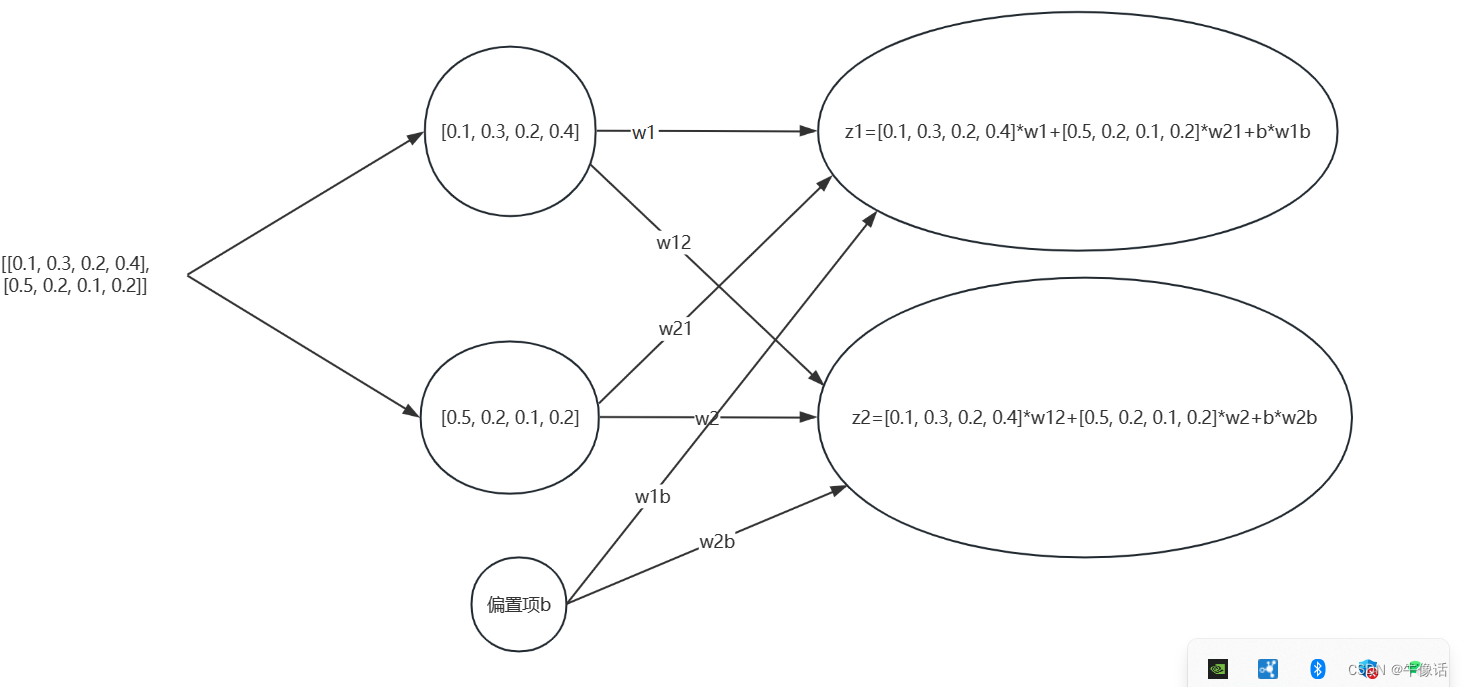
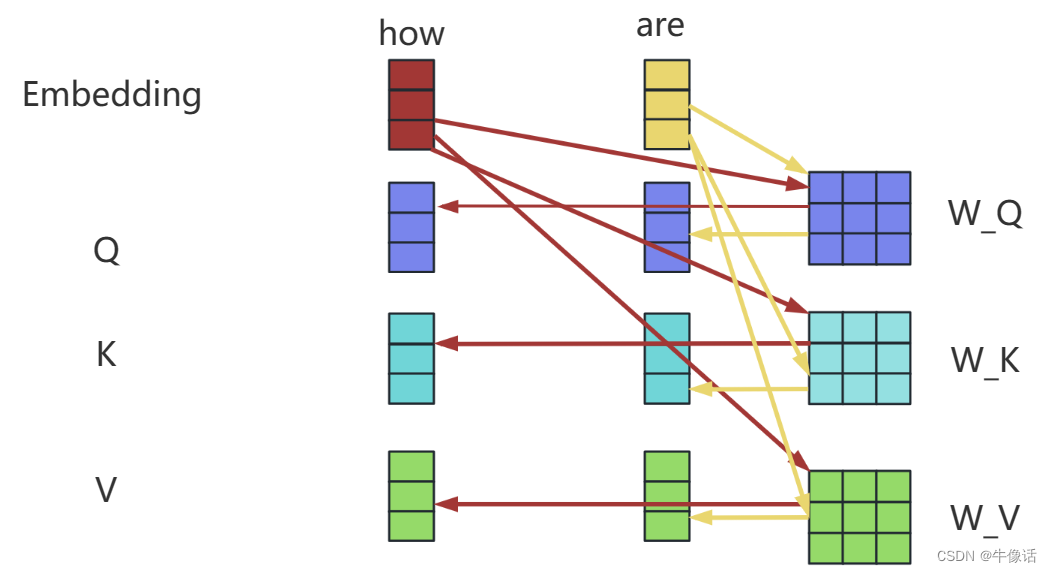
QKV: 上图红框中的意思是,我们把前面输入部分的输出,分别送入三个不同的全链接层,得出三个向量。那这句话换个说法就是,我们把之前的每个词向量,乘上三个不同的矩阵,如下图所示,就可以得到每个词向量自己的QKV矩阵。例如Q矩阵,他实际上是由how are you 三个词的Q矩阵,所构成的一个三行三列的Q矩阵。所谓的多头,其实就是可以有多个注意力部分,其中每个注意力部分的结构其实都是一样的,不同的是下图中的WQ WK WV矩阵的内容,因为这三个矩阵的不同,所以相当于在不同的空间中注意到不同的信息。
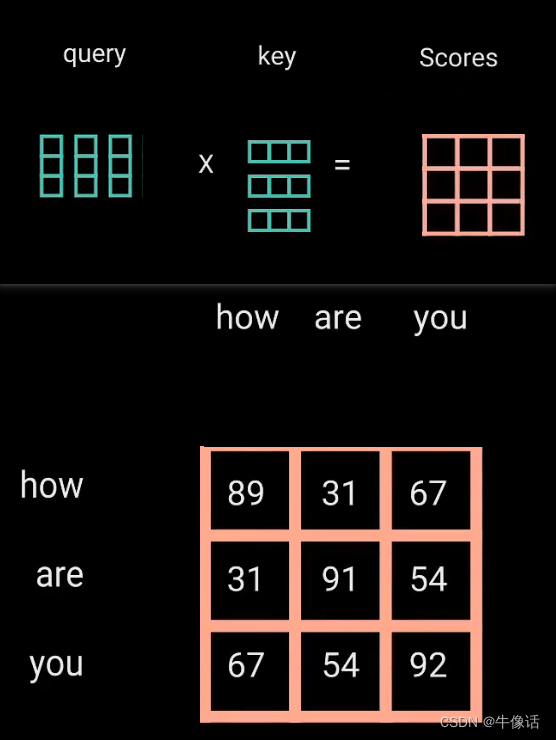
matmul: 接下来就把Q矩阵和KT矩阵进行相乘,所得到的这个矩阵,确定了一个单词应该如何关注其他单词,如下图所示,可以明显的看出,矩阵中的数字,代表了这个单词和其他单词的关注度,分数越高代表关注度越高。
然后把相乘后的矩阵进行缩放,如下图所示,目的是让梯度稳定,因为乘法后的数据会很爆炸,换句人话说就是,因为后面要拿这个矩阵做softmax,如果这个矩阵过大的话,就会导致softMax很小,从而导致梯度的消失。
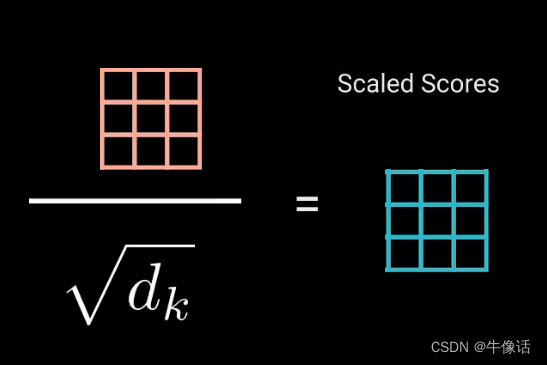
softMax: 接下来对缩放后的矩阵进行softMax变化,入下图所示,把矩阵变成注意力的权重矩阵,其实还有个好处是可以让注意力强的单词更强,弱的更弱。

第二次MatMul: 把softMax变换后的注意力权重矩阵,乘上V矩阵,所得到输出向量,就可以把原本不重要的词给变小,给重要的词变大。
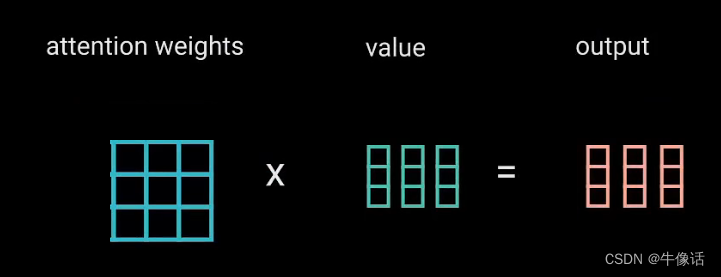
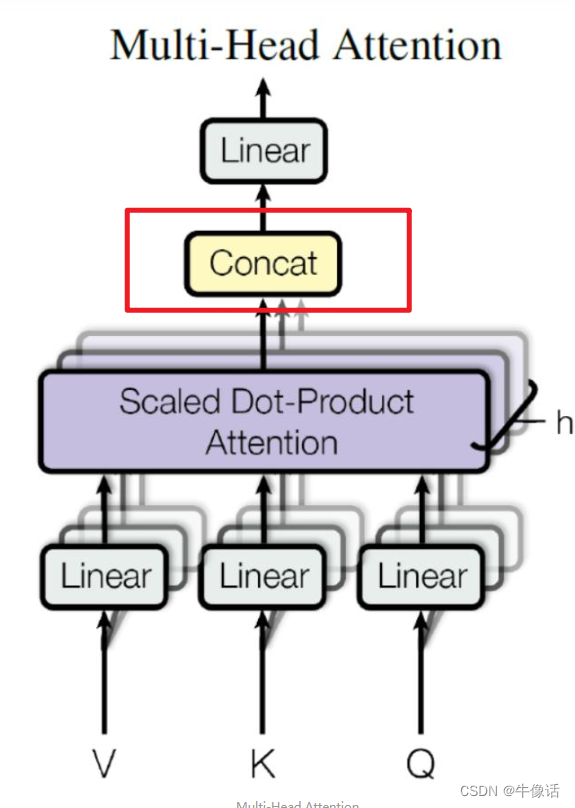
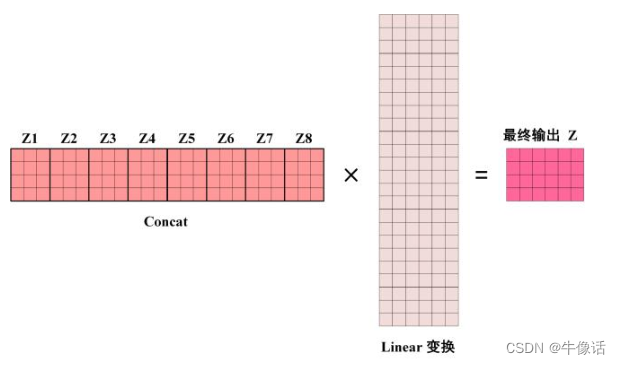
concat和Linear:
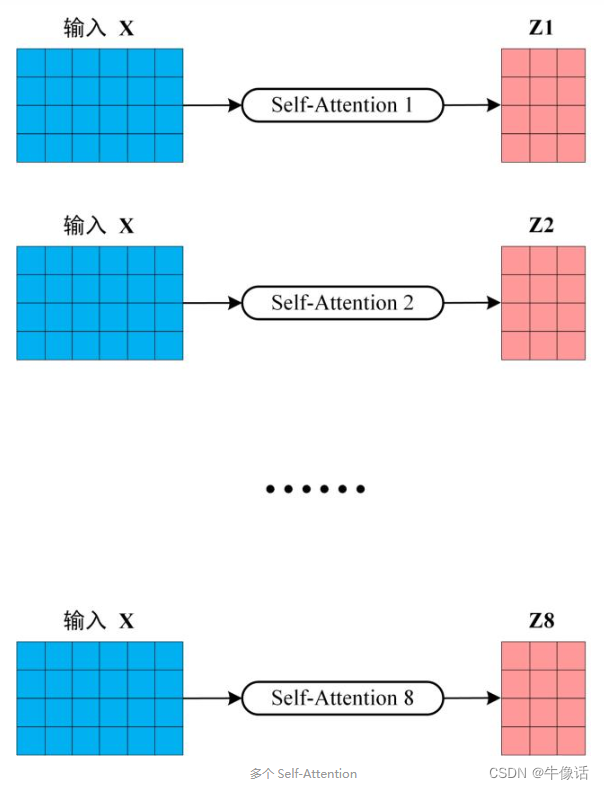
上面所说的,只是一头,就相当于下图中的“一片”,但是实际中,是多头。是由很多片构成的,所以concat的目的就是把每片输出的注意力权重矩阵给拼接起来。
假如我们由8个头,那么将会输出8个注意力权重矩阵
问题来了,feed forward是一个前馈神经网络,只输入一个矩阵,但我们多头注意力机制输出了8个。所以,我们要把这8个矩阵压缩成一个矩阵
conact拼接效果如下:
显然这么长的矩阵,不是我们的目标矩阵,因为我们要的是让输出矩阵和输入矩阵,所以要进行Linear变换(Linear是一个权重矩阵),如下图所示,最后所得到的结果,就是多头自注意力机制的输出
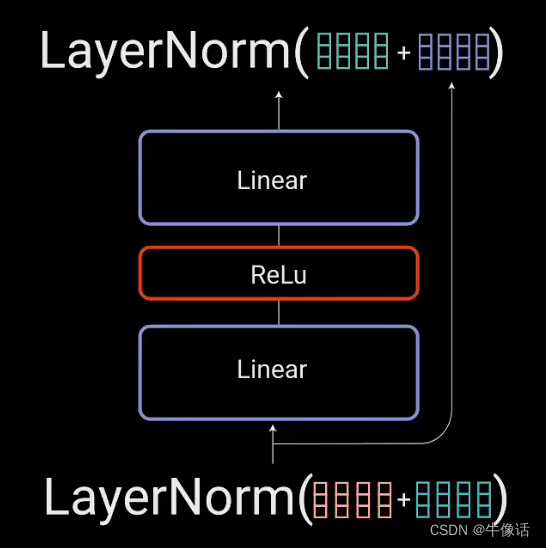
add&norm: add和norm是两个操作,其中把多头注意力矩阵加上pos-embedding矩阵,这是add,也就是残差链接,连接后经过归一化(norm),如下图所示 。

残差链接有什么用?
如下图所示,通过链式求导法则可以看出,当使用残差时,括号内存在一个1,梯度消失一般情况下是因为连乘从而导致梯度变小,而下面因为这个1的存在,导致梯度不会那么容易消失
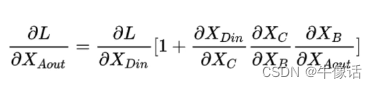
LayerNorm有什么用?
是一种用于神经网络的归一化技术,它可以对网络中的每个神经元的输出进行归一化,使得网络中每一层的输出都具有相似的分布。用人话来说就是,我们一次的输入,包含的可能不止一句子句,并且每句话的长度都可能不一样。
3.全链接模块:
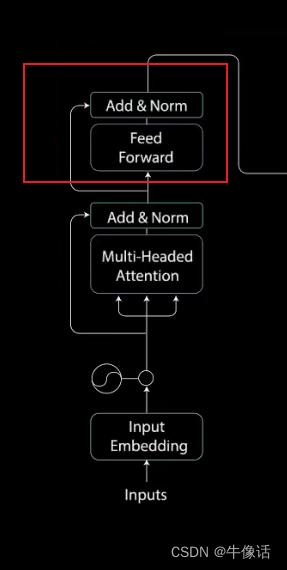
这层很简单,两层全连接,用ReLu作为激活函数,这层会被反向传播更新参数,feed forward参数的传入方式如下,后面一篇decoder会讲解如何更新。