
- 1Hadoop详解_大数据的特点谁提出的
- 2mfc用oledb链接mysql_MFC用ADO连接数据库(ACCESS)
- 3手动下载并安装nltk_data_nltk data lives in the gh-pages branch of this rep
- 46行代码入门RAG开发_rag代码
- 5matlab的边缘检测方法,Matlab多种图像边缘检测方法
- 6Axure RP 9 for Mac/win:打造极致交互体验的原型设计神器_axure mac
- 7【在FastAPI应用中嵌入Gradio界面的实现方法】如何在有一个Fastapi应用的基础上,新加一个gradio程序_gradio fastapi
- 8打造安全高效的身份管理:七大顶级CIAM工具推荐
- 9基于C++Qt实现考试系统[2024-05-05]_qt考试系统
- 10【ubuntu连接xshell最新2024史上最全小白教程】_ubuntu xshell
【机器学习】在【PyCharm中的学习】:从【基础到进阶的全面指南】_pycahrm机器学习
赞
踩
目录


专栏:机器学习笔记
pycharm专业版免费激活教程见资源,私信我给你发
第一步:基础准备
1.1 Python基础
1.1.1 学习Python的基本语法
变量和数据类型:
- 学习如何声明变量,理解Python的弱类型特性。
- 掌握基本数据类型:整数、浮点数、字符串、布尔值和None。
示例代码:
- a = 10 # 整数
- b = 3.14 # 浮点数
- c = "Hello, Python!" # 字符串
- d = True # 布尔值
- e = None # 空值
1.1.2 控制流
条件语句:
掌握if、elif和else语句的使用。
示例代码:
- age = 18
- if age >= 18:
- print("You are an adult.")
- elif age > 12:
- print("You are a teenager.")
- else:
- print("You are a child.")
循环语句:
- 学习for循环和while循环,理解其应用场景。
示例代码:
- # for循环
- for i in range(5):
- print(i)
-
- # while循环
- count = 0
- while count < 5:
- print(count)
- count += 1
1.1.3 函数和模块
函数:
- 学习如何定义和调用函数,理解参数和返回值的概念。
示例代码:
- def greet(name):
- return f"Hello, {name}!"
-
- print(greet("Alice"))
模块:
- 学习如何导入和使用模块,理解标准库的概念。
示例代码:
- import math
-
- print(math.sqrt(16))
1.2 安装PyCharm
1.2.1 下载并安装
- 下载:
- 访问JetBrains官网,下载PyCharm社区版或专业版安装包。
- 链接:PyCharm下载页面
- 安装:
- 运行安装包,按照提示完成安装。
- 安装过程中,可以选择安装路径和附加组件(如Git、Anaconda等)。
- 创建新项目:
- 打开PyCharm,点击“New Project”。
- 选择项目位置和Python解释器,点击“Create”创建项目。
- 管理项目:
- 理解PyCharm的项目结构,包括项目视图、文件导航、工具窗口等。
- 学习如何创建Python文件、包和虚拟环境。
- 基本功能:
- 学习如何运行和调试Python代码,使用断点和调试工具。
- 学习如何使用代码补全、代码检查和重构工具提高编码效率。
- 快捷键:
- 熟悉常用快捷键,如:
- 运行代码:
Shift + F10 - 调试代码:
Shift + F9 - 查找文件:
Ctrl + Shift + N - 查找类:
Ctrl + N - 重命名:
Shift + F6
- 运行代码:
- 熟悉常用快捷键,如:
第二步:数据科学基础
2.1 安装必备库
2.1.1 使用pip安装
安装NumPy:
- 在PyCharm的终端窗口中,输入以下命令安装NumPy:
pip install numpy -
- NumPy是一个支持大量高维数组与矩阵运算的库,提供了大量的数学函数库。
安装Pandas:
- 在PyCharm的终端窗口中,输入以下命令安装Pandas:
pip install pandas -
- Pandas是一个数据分析和数据操作的库,提供了数据结构和数据分析工具。
安装Matplotlib:
- 在PyCharm的终端窗口中,输入以下命令安装Matplotlib:
pip install matplotlib -
- Matplotlib是一个绘图库,可以生成各种静态、动态和交互式的图表。
安装Scikit-Learn:
- 在PyCharm的终端窗口中,输入以下命令安装Scikit-Learn:
pip install scikit-learn -
- Scikit-Learn是一个机器学习库,提供了各种分类、回归和聚类算法的实现。
2.2 数据操作
2.2.1 Pandas基础操作
读取数据:
- 学习如何使用Pandas读取CSV、Excel和SQL等格式的数据。
- 示例代码:
-
- import pandas as pd
- # 读取CSV文件
- df = pd.read_csv('data.csv')
- print(df.head())
- # 读取Excel文件
- df = pd.read_excel('data.xlsx')
- print(df.head())
- # 读取SQL数据库
- import sqlite3
- conn = sqlite3.connect('database.db')
- df = pd.read_sql_query('SELECT * FROM table_name', conn)
- print(df.head())
数据清洗:
- 学习如何处理缺失值、重复值和异常值。
- 示例代码:
- # 处理缺失值
- df.dropna(inplace=True) # 删除缺失值所在行
- df.fillna(0, inplace=True) # 填充缺失值为0
- # 处理重复值
- df.drop_duplicates(inplace=True)
- # 处理异常值
- df = df[df['column_name'] > 0] # 过滤异常值
数据操作:
- 学习如何进行数据选择、过滤、排序和分组操作。
- 示例代码:
- # 选择数据
- df_selected = df[['column1', 'column2']]
- # 过滤数据
- df_filtered = df[df['column1'] > 10]
- # 排序数据
- df_sorted = df.sort_values(by='column1')
- # 分组操作
- df_grouped = df.groupby('column1').mean()
2.2.2 NumPy基础操作
数组创建:
- 学习如何使用NumPy创建数组和矩阵。
- 示例代码:
- import numpy as np
- # 创建一维数组
- arr1 = np.array([1, 2, 3, 4, 5])
- # 创建二维数组
- arr2 = np.array([[1, 2, 3], [4, 5, 6]])
- # 创建全零数组
- zeros = np.zeros((3, 3))
- # 创建全一数组
- ones = np.ones((2, 2))
- # 创建等差数组
- arange = np.arange(0, 10, 2)
- # 创建等间隔数组
- linspace = np.linspace(0, 1, 5)

数组运算:
- 学习如何进行数组运算,包括加减乘除、矩阵运算和广播机制。
- 示例代码:
- # 数组加减乘除
- arr1 = np.array([1, 2, 3])
- arr2 = np.array([4, 5, 6])
- arr_sum = arr1 + arr2
- arr_diff = arr1 - arr2
- arr_prod = arr1 * arr2
- arr_quot = arr1 / arr2
- # 矩阵运算
- mat1 = np.array([[1, 2], [3, 4]])
- mat2 = np.array([[5, 6], [7, 8]])
- mat_dot = np.dot(mat1, mat2) # 矩阵乘法
- # 广播机制
- arr_broadcast = arr1 + 5 # 每个元素加5
第三步:机器学习基础

3.1 了解机器学习基本概念
3.1.1 监督学习
-
定义:
- 监督学习是一种利用已标注数据进行模型训练的方法,包括分类和回归任务。
- 分类任务示例:垃圾邮件检测(识别邮件是否为垃圾邮件)。
- 回归任务示例:房价预测(根据特征预测房价)。
-
特征工程:
- 特征选择:选择对模型性能有显著影响的特征。方法包括过滤法(如方差选择法)、包裹法(如递归特征消除)和嵌入法(如Lasso回归)。
- 特征提取:将原始特征转换为新的、更具代表性的特征。常用方法有PCA(主成分分析)和LDA(线性判别分析)。
示例代码:
- from sklearn.datasets import load_iris
- from sklearn.model_selection import train_test_split
- from sklearn.preprocessing import StandardScaler
- from sklearn.linear_model import LogisticRegression
- from sklearn.metrics import accuracy_score
-
- # 加载数据集
- data = load_iris()
- X = data.data
- y = data.target
-
- # 数据分割
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
-
- # 数据标准化
- scaler = StandardScaler()
- X_train = scaler.fit_transform(X_train)
- X_test = scaler.transform(X_test)
-
- # 训练逻辑回归模型
- model = LogisticRegression()
- model.fit(X_train, y_train)
-
- # 预测
- y_pred = model.predict(X_test)
-
- # 评估模型
- accuracy = accuracy_score(y_test, y_pred)
- print(f"Accuracy: {accuracy}")
机器学习中的监督学习方法种类繁多,适用于不同类型的任务和数据集。下面详细介绍几种常见的监督学习方法,包括它们的基本原理、适用场景以及优缺点。
1. 线性回归(Linear Regression)
基本原理
线性回归是最简单的监督学习算法之一,主要用于解决回归问题。其基本思想是通过拟合一条直线来预测因变量(目标变量)与自变量(特征变量)之间的关系。
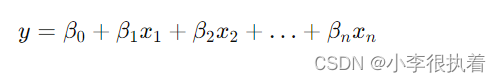
适用场景
- 预测房价
- 销售预测
- 经济指标预测
优缺点
优点:
- 简单易懂,容易实现
- 计算效率高
缺点:
- 对线性关系有强假设,实际问题中不一定成立
- 对异常值敏感
2. 逻辑回归(Logistic Regression)
基本原理
逻辑回归用于解决二分类问题,其输出是一个概率值,表示样本属于某一类的概率。模型使用sigmoid函数将线性回归的结果映射到(0,1)区间。

适用场景
- 信用卡欺诈检测
- 疾病预测(如癌症检测)
- 客户流失预测
优缺点
优点:
- 实现简单,计算效率高
- 输出结果具有概率意义
缺点:
- 只能处理线性可分问题
- 对异常值敏感
3. 决策树(Decision Tree)
基本原理
决策树通过递归地将数据分成多个子集来进行分类或回归。每个节点表示对一个特征的测试,分支表示测试结果,叶子节点表示最终的预测结果。
适用场景
- 客户细分
- 病例分类
- 股票市场分析
优缺点
优点:
- 易于理解和解释
- 可以处理非线性数据
缺点:
- 容易过拟合
- 对数据中的小变化敏感
4. 支持向量机(Support Vector Machine, SVM)
基本原理
SVM通过找到最优超平面来将数据分类。对于线性不可分数据,可以通过核函数将数据映射到高维空间,使其线性可分。
适用场景
- 文本分类
- 图像识别
- 基因数据分析
优缺点
优点:
- 能处理高维数据
- 有效避免过拟合
缺点:
- 训练时间较长
- 对于大规模数据集表现不佳
5. k-近邻算法(k-Nearest Neighbors, k-NN)
基本原理
k-NN是一种基于实例的学习方法,通过计算样本点与训练集中所有样本点的距离,选择距离最近的k个点,最终通过多数投票(分类)或平均值(回归)来预测。
适用场景
- 图像识别
- 手写数字识别
- 推荐系统
优缺点
优点:
- 实现简单
- 无需训练过程
缺点:
- 计算复杂度高,预测阶段速度慢
- 对噪声和无关特征敏感
6. 朴素贝叶斯(Naive Bayes)
基本原理
朴素贝叶斯基于贝叶斯定理,并假设特征之间相互独立。通过计算每个类别的后验概率,选择概率最大的类别作为预测结果。

适用场景
- 垃圾邮件分类
- 文本分类
- 医学诊断
优缺点
优点:
- 计算效率高
- 对小规模数据集表现良好
缺点:
- 特征独立假设在实际中很难成立
- 对连续特征处理较差
7. 随机森林(Random Forest)
基本原理
随机森林是一种集成学习方法,通过构建多个决策树并结合其预测结果来提高模型性能。每棵树在训练时使用不同的随机样本和特征。
适用场景
- 银行贷款风险评估
- 生物信息学
- 市场预测
优缺点
优点:
- 减少过拟合
- 能处理高维数据
缺点:
- 模型复杂度高,计算开销大
- 对实时预测不友好
8. 梯度提升树(Gradient Boosting Tree, GBT)
基本原理
梯度提升树是一种通过逐步构建模型的集成方法,每个新模型都试图纠正前一个模型的错误。常见实现包括XGBoost、LightGBM等。
适用场景
- 排序问题(如搜索引擎)
- 销售预测
- 信用评分
优缺点
优点:
- 高预测精度
- 能处理各种类型的数据
缺点:
- 训练时间较长
- 参数调优复杂
9. 神经网络(Neural Networks)
基本原理
神经网络模仿人脑神经元结构,通过多层感知器和反向传播算法来进行训练和预测。近年来,深度学习中的卷积神经网络(CNN)、循环神经网络(RNN)等变体在图像和自然语言处理等领域取得了巨大成功。
适用场景
- 图像识别
- 自然语言处理
- 游戏 AI
优缺点
优点:
- 高表达能力,能处理复杂非线性问题
- 在大数据和高计算资源支持下表现优秀
缺点:
- 训练时间长,计算资源需求高
- 解释性差,不易理解模型内部机制
总结
监督学习方法种类繁多,各有优缺点,适用于不同类型的任务和数据。选择合适的方法需要考虑数据的特性、任务的需求以及计算资源等因素。以下是对几种常见方法的总结:
- 线性回归:适合简单的回归任务,但假设较强。
- 逻辑回归:适用于二分类任务,解释性强。
- 决策树:易于理解和解释,但容易过拟合。
- 支持向量机:适合高维数据,但计算复杂度高。
- k-近邻算法:实现简单,但计算开销大。
- 朴素贝叶斯:计算效率高,但假设较强。
- 随机森林:性能强大,减少过拟合,但复杂度高。
- 梯度提升树:高预测精度,但训练时间长。
- 神经网络:适合复杂任务,但计算资源需求高。
通过对这些方法的理解和应用,可以在不同的实际问题中找到最合适的解决方案,从而实现更好的预测和分类效果。
3.1.2 非监督学习
-
定义:
- 非监督学习是一种无需已标注数据进行模型训练的方法,包括聚类和降维任务。
- 聚类任务示例:客户细分(将客户分成不同群体)。
- 降维任务示例:数据可视化(将高维数据转换为低维以便于可视化)。
-
异常检测:
- 异常检测用于识别数据中的异常模式,常用方法有孤立森林(Isolation Forest)和本地离群因子(Local Outlier Factor)。
示例代码:
- from sklearn.ensemble import IsolationForest
- import numpy as np
-
- # 生成示例数据
- X = np.array([[1, 2], [2, 3], [3, 4], [8, 8], [9, 9], [10, 10]])
-
- # 训练孤立森林模型
- model = IsolationForest(contamination=0.2)
- model.fit(X)
-
- # 预测
- outliers = model.predict(X)
- print(f"Outliers: {outliers}")
机器学习中的非监督学习方法主要用于从无标签的数据中发现隐藏的模式和结构。非监督学习算法的种类繁多,适用于不同类型的任务,如聚类、降维和异常检测。下面详细介绍几种常见的非监督学习方法,包括它们的基本原理、适用场景以及优缺点。
1. 聚类(Clustering)
聚类是一种将数据集分成多个组(簇)的技术,使得同一组内的数据点尽可能相似,而不同组的数据点尽可能不同。常见的聚类算法包括 K-means、层次聚类和 DBSCAN。
1.1 K-means 聚类
基本原理
K-means 聚类是一种迭代优化算法,通过最小化簇内距离的总和,将数据点分配到 K 个簇中。算法的步骤包括:
- 随机选择 K 个初始质心。
- 分配每个数据点到最近的质心。
- 重新计算每个簇的质心。
- 重复步骤 2 和 3,直到质心不再变化或达到最大迭代次数。
适用场景
- 客户细分
- 图像压缩
- 文本聚类
优缺点
优点:
- 简单易懂,计算效率高
- 易于实现
缺点:
- 需要预先指定 K 值
- 对初始值敏感,可能陷入局部最优
- 只能发现凸形簇
1.2 层次聚类(Hierarchical Clustering)
基本原理
层次聚类通过构建一个树状结构(树状图)来表示数据的聚类过程,分为自下而上(凝聚)和自上而下(分裂)两种方法。
适用场景
- 基因序列分析
- 社交网络分析
- 市场研究
优缺点
优点:
- 不需要预先指定簇的数量
- 可以生成层次结构,便于理解数据关系
缺点:
- 计算复杂度高,适用于小规模数据集
- 对噪声和异常值敏感
1.3 DBSCAN(Density-Based Spatial Clustering of Applications with Noise)
基本原理
DBSCAN 基于密度的聚类算法,通过寻找高密度区域中的数据点形成簇,能够识别任意形状的簇,并且对噪声数据有很好的鲁棒性。
适用场景
- 空间数据分析
- 图像处理
- 社交网络分析
优缺点
优点:
- 不需要指定簇的数量
- 能发现任意形状的簇
- 对噪声数据具有鲁棒性
缺点:
- 对参数选择敏感(如 $\epsilon$ 和最小点数)
- 对高维数据表现较差
2. 降维(Dimensionality Reduction)
降维是一种将高维数据映射到低维空间的方法,旨在减少特征数量,保持数据的主要信息。常见的降维算法包括 PCA、t-SNE 和 LDA。
2.1 主成分分析(Principal Component Analysis, PCA)
基本原理
PCA 通过线性变换将数据映射到新的坐标系中,新坐标系的轴(主成分)是数据中方差最大的方向。前几个主成分通常能够保留大部分数据的信息。
适用场景
- 数据可视化
- 特征提取
- 数据压缩
优缺点
优点:
- 降低数据维度,减少计算复杂度
- 消除特征间的线性相关性
缺点:
- 仅适用于线性关系的数据
- 主成分难以解释
2.2 t-SNE(t-Distributed Stochastic Neighbor Embedding)
基本原理
t-SNE 是一种非线性降维方法,主要用于高维数据的可视化。它通过最小化高维数据和低维数据之间的概率分布差异,将相似的数据点映射到低维空间中尽可能接近的位置。
适用场景
- 高维数据可视化
- 图像数据降维
- 基因数据分析
优缺点
优点:
- 能有效处理非线性数据
- 适合数据可视化
缺点:
- 计算复杂度高,适用于小规模数据集
- 结果不稳定,难以解释
2.3 线性判别分析(Linear Discriminant Analysis, LDA)
基本原理
LDA 是一种监督学习的降维方法,旨在通过最大化类间距离和最小化类内距离来找到最优投影方向,使得不同类别的数据在低维空间中更容易区分。
适用场景
- 模式识别
- 文本分类
- 面部识别
优缺点
优点:
- 适合分类任务的降维
- 能有效提高分类性能
缺点:
- 仅适用于线性可分的数据
- 需要标签信息
3. 异常检测(Anomaly Detection)
异常检测是识别数据集中异常或异常行为的过程。常见的异常检测算法包括孤立森林(Isolation Forest)、局部异常因子(Local Outlier Factor, LOF)和高斯混合模型(Gaussian Mixture Model, GMM)。
3.1 孤立森林(Isolation Forest)
基本原理
孤立森林通过随机选择特征和切分点来构建树,异常点更容易被孤立(在较浅的树层级上分开),因此这些点的平均路径长度较短。
适用场景
- 网络入侵检测
- 信用卡欺诈检测
- 工业设备故障检测
优缺点
优点:
- 对大规模数据集表现良好
- 处理高维数据效果好
缺点:
- 对参数选择敏感
3.2 局部异常因子(Local Outlier Factor, LOF)
基本原理
LOF 通过比较数据点的局部密度与其邻居的局部密度来识别异常点。如果一个点的局部密度显著低于其邻居的局部密度,则该点被认为是异常的。
适用场景
- 健康监测
- 金融欺诈检测
- 制造业质量控制
优缺点
优点:
- 能有效识别局部异常
- 适用于多种数据分布
缺点:
- 计算复杂度高
- 对参数选择敏感
3.3 高斯混合模型(Gaussian Mixture Model, GMM)
基本原理
GMM 假设数据由多个高斯分布组成,通过最大似然估计或期望最大化算法来估计模型参数。异常点是那些概率密度较低的数据点。
适用场景
- 图像分割
- 市场细分
- 数据生成
优缺点
优点:
- 能处理复杂数据分布
- 适用于多种应用场景
缺点:
- 对初始参数敏感
- 可能陷入局部最优
总结
非监督学习方法主要包括聚类、降维和异常检测,每种方法都有其特定的应用场景和优缺点。以下是对几种常见方法的总结:
-
聚类:将数据分成多个组,使同一组内的数据点尽可能相似。
- K-means:简单高效,但需要预先指定簇数。
- 层次聚类:生成层次结构,但计算复杂度高。
- DBSCAN:发现任意形状簇,对噪声有鲁棒性,但对参数敏感。
-
降维:将高维数据映射到低维空间,保留主要信息。
- PCA:线性降维,减少计算复杂度,但只适用于线性关系。
- t-SNE:非线性降维,适合可视化,但计算复杂度高。
- LDA:监督降维,提高分类性能,但需要标签信息。
-
异常检测:识别数据中的异常点。
- 孤立森林:适合大规模高维数据,但对参数敏感。
- 局部异常因子:识别局部异常,但计算复杂度高。
- 高斯混合模型:处理复杂分布,但对初始参数敏感。
通过对这些非监督学习方法的理解和应用,可以在无标签数据中发现有价值的模式和结构,从而解决实际问题。
3.1.3 模型训练和评估
模型训练:
- 使用训练数据训练模型,理解模型参数(模型的可学习参数)和超参数(控制学习过程的参数)。
示例代码:
- from sklearn.linear_model import LinearRegression
-
- # 创建线性回归模型
- model = LinearRegression()
-
- # 训练模型
- model.fit(X_train, y_train)
模型评估:
- 评估模型的性能,常用指标有准确率、精确率、召回率和F1分数。
示例代码:
- from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
-
- # 预测
- y_pred = model.predict(X_test)
-
- # 评估模型
- accuracy = accuracy_score(y_test, y_pred)
- precision = precision_score(y_test, y_pred, average='macro')
- recall = recall_score(y_test, y_pred, average='macro')
- f1 = f1_score(y_test, y_pred, average='macro')
-
- print(f"Accuracy: {accuracy}")
- print(f"Precision: {precision}")
- print(f"Recall: {recall}")
- print(f"F1 Score: {f1}")
在机器学习中,模型训练和评估是两个关键步骤。以下是对这两个步骤的详细总结,包括其各个阶段的具体内容和方法。
1. 训练过程
数据准备
数据准备是训练模型的第一步,涉及以下几个方面:
- 数据清洗:处理缺失值、异常值和重复数据,确保数据质量。
- 特征选择:从数据集中选择对预测目标最有影响的特征。
- 数据分割:将数据分成训练集和测试集,通常按照80-20或70-30的比例分割,以便模型训练和评估。
模型选择和训练
根据问题的类型(如分类、回归等),选择合适的机器学习模型进行训练。常见的模型包括:
- 线性回归:用于解决回归问题,预测连续型变量。
- 逻辑回归:用于二分类问题,预测类别。
- 决策树:通过树状结构进行分类或回归,易于解释。
- 随机森林:由多棵决策树组成的集成模型,具有较高的准确性和鲁棒性。
- 支持向量机(SVM):用于分类问题,通过寻找最优超平面分离数据。
模型训练的过程是使用训练集的数据来调整模型的参数,使其能够较好地拟合数据。
2. 模型评估
模型评估用于衡量模型在新数据上的表现,常用的方法有:
分类模型评估
- 准确率(Accuracy):预测正确的样本占总样本的比例。
- 精确率(Precision):预测为正类的样本中实际为正类的比例。
- 召回率(Recall):实际为正类的样本中被正确预测为正类的比例。
- F1-score:精确率和召回率的调和平均数,综合评估模型的性能。
- 混淆矩阵(Confusion Matrix):用于具体评估分类模型的表现,显示预测结果与实际结果的对比。
回归模型评估
- 均方误差(MSE):预测值与实际值之差的平方的平均值。
- 均方根误差(RMSE):均方误差的平方根,更直观地反映误差大小。
- 平均绝对误差(MAE):预测值与实际值之差的绝对值的平均值。
- 决定系数(R²):表示模型的预测值与实际值之间的拟合程度,值越接近1表示模型越好。
3. 模型优化
模型优化是提高模型性能的关键步骤,常用的方法包括:
交叉验证
通过将数据集分成多个子集,交替使用一个子集作为验证集,其余子集作为训练集,来评估模型性能。这种方法有助于避免过拟合和欠拟合,常用的是K折交叉验证。
超参数调优
超参数调优通过调整模型的超参数来找到最佳的参数组合。常见的方法有:
- 网格搜索(Grid Search):通过穷举搜索所有可能的参数组合,找到最佳参数。
- 随机搜索(Random Search):通过随机选择参数组合进行搜索,比网格搜索更高效。
4. 模型保存与加载
为了在后续使用中避免重复训练,可以将训练好的模型保存下来。常用的保存方法包括使用 joblib 或 pickle 库。保存的模型可以在需要时加载并使用,从而提高工作效率。
总结
机器学习中的模型训练和评估包括以下几个主要步骤:
- 数据准备:数据清洗、特征选择和数据分割。
- 模型选择与训练:根据任务类型选择合适的模型并进行训练。
- 模型评估:使用各种评估指标衡量模型在测试集上的性能。
- 模型优化:通过交叉验证和超参数调优提高模型性能。
- 模型保存与加载:保存训练好的模型以便后续使用。
通过这些步骤,可以系统地训练和评估机器学习模型,确保其在实际应用中的表现达到预期效果。
3.2 实践机器学习模型
3.2.1 数据预处理
-
数据标准化和归一化:
- 标准化(Standardization):将特征缩放到均值为0、标准差为1的范围。
- 归一化(Normalization):将特征缩放到0到1的范围。
示例代码:
- from sklearn.preprocessing import StandardScaler, MinMaxScaler
-
- # 标准化
- scaler = StandardScaler()
- X_standardized = scaler.fit_transform(X)
-
- # 归一化
- scaler = MinMaxScaler()
- X_normalized = scaler.fit_transform(X)
数据分割:
- 将数据分为训练集和测试集,以评估模型的泛化能力。
- 示例代码:
- from sklearn.model_selection import train_test_split
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
3.2.2 简单模型实现
线性回归:
- 线性回归用于预测连续值,模型假设特征和目标之间是线性关系。
示例代码:
- from sklearn.linear_model import LinearRegression
-
- # 创建线性回归模型
- model = LinearRegression()
-
- # 训练模型
- model.fit(X_train, y_train)
-
- # 预测
- y_pred = model.predict(X_test)
-
- # 评估模型
- from sklearn.metrics import mean_squared_error
- mse = mean_squared_error(y_test, y_pred)
- print(f"Mean Squared Error: {mse}")
逻辑回归:
- 逻辑回归用于分类任务,模型输出类别的概率。
示例代码:
- from sklearn.linear_model import LogisticRegression
-
- # 创建逻辑回归模型
- model = LogisticRegression()
-
- # 训练模型
- model.fit(X_train, y_train)
-
- # 预测
- y_pred = model.predict(X_test)
-
- # 评估模型
- from sklearn.metrics import accuracy_score
- accuracy = accuracy_score(y_test, y_pred)
- print(f"Accuracy: {accuracy}")
决策树:
- 决策树是一种树状结构的模型,通过分裂特征来进行决策。
示例代码:
- from sklearn.tree import DecisionTreeClassifier
-
- # 创建决策树模型
- model = DecisionTreeClassifier()
-
- # 训练模型
- model.fit(X_train, y_train)
-
- # 预测
- y_pred = model.predict(X_test)
-
- # 评估模型
- from sklearn.metrics import accuracy_score
- accuracy = accuracy_score(y_test, y_pred)
- print(f"Accuracy: {accuracy}")
KNN(K-最近邻):
- KNN是一种基于实例的学习算法,通过计算样本间的距离进行分类或回归。
示例代码:
- from sklearn.neighbors import KNeighborsClassifier
-
- # 创建KNN模型
- model = KNeighborsClassifier(n_neighbors=3)
-
- # 训练模型
- model.fit(X_train, y_train)
-
- # 预测
- y_pred = model.predict(X_test)
-
- # 评估模型
- from sklearn.metrics import accuracy_score
- accuracy = accuracy_score(y_test, y_pred)
- print(f"Accuracy: {accuracy}")
第四步:进阶学习
4.1 深入学习模型
4.1.1 复杂模型和算法
随机森林:
- 随机森林是一种集成学习方法,通过构建多棵决策树来提高模型的泛化能力。
示例代码:
- from sklearn.ensemble import RandomForestClassifier
-
- # 创建随机森林模型
- model = RandomForestClassifier(n_estimators=100)
-
- # 训练模型
- model.fit(X_train, y_train)
-
- # 预测
- y_pred = model.predict(X_test)
-
- # 评估模型
- from sklearn.metrics import accuracy_score
- accuracy = accuracy_score(y_test, y_pred)
- print(f"Accuracy: {accuracy}")
支持向量机:
- 支持向量机是一种用于分类的模型,通过寻找最佳超平面来分割数据。
示例代码:
- from sklearn.svm import SVC
-
- # 创建支持向量机模型
- model = SVC(kernel='linear')
-
- # 训练模型
- model.fit(X_train, y_train)
-
- # 预测
- y_pred = model.predict(X_test)
-
- # 评估模型
- from sklearn.metrics import accuracy_score
- accuracy = accuracy_score(y_test, y_pred)
- print(f"Accuracy: {accuracy}")
聚类算法:
- K均值聚类是一种常用的聚类算法,通过迭代优化将样本分配到k个聚类中心。
示例代码:
- from sklearn.cluster import KMeans
-
- # 创建K均值聚类模型
- model = KMeans(n_clusters=3)
-
- # 训练模型
- model.fit(X)
-
- # 获取聚类结果
- labels = model.predict(X)
神经网络:
- 神经网络用于复杂任务,具有强大的学习能力。常用的框架有Keras和TensorFlow。
示例代码(使用Keras):
- from keras.models import Sequential
- from keras.layers import Dense
-
- # 创建神经网络模型
- model = Sequential()
- model.add(Dense(units=64, activation='relu', input_dim=100))
- model.add(Dense(units=10, activation='softmax'))
-
- # 编译模型
- model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
-
- # 训练模型
- model.fit(X_train, y_train, epochs=5, batch_size=32)
-
- # 评估模型
- loss, accuracy = model.evaluate(X_test, y_test)
- print(f"Loss: {loss}, Accuracy: {accuracy}")
4.1.2 调参、交叉验证和模型优化
调参:
- 调整模型的超参数以优化模型性能。可以使用Grid Search和Random Search。
示例代码(使用Grid Search):
- from sklearn.model_selection import GridSearchCV
-
- # 定义参数网格
- param_grid = {'n_estimators': [50, 100, 200], 'max_depth': [None, 10, 20]}
-
- # 创建随机森林模型
- model = RandomForestClassifier()
-
- # 网格搜索
- grid_search = GridSearchCV(model, param_grid, cv=5)
- grid_search.fit(X_train, y_train)
-
- # 最优参数
- print(f"Best parameters: {grid_search.best_params_}")
交叉验证:
- 使用交叉验证评估模型,减少过拟合的风险。
示例代码:
- from sklearn.model_selection import cross_val_score
-
- # 创建随机森林模型
- model = RandomForestClassifier(n_estimators=100)
-
- # 交叉验证
- scores = cross_val_score(model, X, y, cv=5)
- print(f"Cross-validation scores: {scores}")
- print(f"Mean score: {scores.mean()}")
模型优化:
- 使用正则化、特征选择和集成方法优化模型。
示例代码(Lasso正则化):
- from sklearn.linear_model import Lasso
-
- # 创建Lasso回归模型
- model = Lasso(alpha=0.1)
-
- # 训练模型
- model.fit(X_train, y_train)
-
- # 预测
- y_pred = model.predict(X_test)
-
- # 评估模型
- from sklearn.metrics import mean_squared_error
- mse = mean_squared_error(y_test, y_pred)
- print(f"Mean Squared Error: {mse}")
4.2 项目实践
4.2.1 选择项目
- 项目选择:
- 根据自己的兴趣和实际应用场景,选择一个机器学习项目进行实践。
- 示例项目:
- 房价预测:使用回归模型预测房价。
- 图像分类:使用卷积神经网络分类图像。
- 文本分类:使用自然语言处理技术分类文本。
4.2.2 数据收集和清洗
-
数据收集:
- 从公开数据集、企业数据库或自定义数据源中收集数据。
- 示例:
- 使用Kaggle上的公开数据集。
- 使用API抓取数据。
-
数据清洗:
- 对收集到的数据进行清洗,确保数据质量。
- 示例:
- 处理缺失值、异常值和重复值。
- 数据转换和标准化。
-
特征工程:
- 进行特征选择和特征提取,确保模型能有效利用数据。
- 示例:
- 使用PCA进行降维。
- 使用互信息进行特征选择。
-
模型训练:
- 选择合适的模型,进行模型训练和优化。
- 示例:
- 使用随机森林进行分类。
- 使用支持向量机进行回归。
-
模型评估:
- 使用各种评估指标评估模型性能,确保模型的泛化能力。
- 示例:
- 使用混淆矩阵评估分类模型。
- 使用均方误差评估回归模型。
-
模型部署:
- 将训练好的模型部署到生产环境,提供实际服务。
- 示例:
- 使用Flask或Django构建API服务。
- 使用Docker容器化部署。
-
模型维护:
- 定期监控和更新模型,确保其性能和稳定性。
- 示例:
- 使用监控工具跟踪模型的预测结果。
- 根据新数据定期重新训练模型。
第五步:学习资源
5.1 在线课程和文档
5.1.1 在线课程
-
Coursera:
- Andrew Ng的《机器学习》课程是入门机器学习的经典课程,涵盖了机器学习的基本概念和算法。
- 链接:Coursera机器学习课程
-
Kaggle:
- Kaggle提供了大量的数据科学和机器学习教程,从入门到进阶,适合各种水平的学习者。
- 链接:Kaggle教程
5.1.2 官方文档
-
Scikit-Learn:
- 阅读Scikit-Learn的官方文档,了解各个模型和方法的具体用法和参数。
- 链接:Scikit-Learn文档
-
Pandas:
- 阅读Pandas的官方文档,掌握数据操作和分析的技巧。
- 链接:Pandas文档
5.2 书籍推荐
5.2.1 《Python机器学习》
- 作者:Sebastian Raschka
- 内容概述:这本书详细介绍了机器学习的基本概念和Scikit-Learn库的使用,适合初学者和中级学习者。
- 购买链接:Python机器学习
5.2.2 《机器学习实战》
- 作者:Peter Harrington
- 内容概述:这本书通过实际案例讲解了多种机器学习算法的实现和应用,适合实践导向的学习者。
- 购买链接:机器学习实战

总结
学习机器学习的路线可以分为几个主要步骤。首先,准备基础知识,学习Python的基本语法,包括变量、数据类型、控制流、函数和模块等。安装PyCharm并熟悉其基本功能和快捷键。接着,掌握数据科学基础,安装NumPy、Pandas、Matplotlib和Scikit-Learn等库,学习数据读取、清洗、处理及可视化技巧。然后,理解机器学习的基本概念,包括监督学习和非监督学习,掌握特征工程、模型训练和评估的方法。
在此基础上,进行数据预处理,标准化和归一化数据,分割训练集和测试集。实践简单模型,如线性回归、逻辑回归、决策树和KNN。进阶学习复杂模型和算法,包括随机森林、支持向量机和神经网络,理解调参、交叉验证和模型优化的技术。
最后,通过实际项目巩固所学知识,从数据收集、清洗、建模到部署,完成整个项目流程。选择一个感兴趣的项目,如房价预测、图像分类或文本分类,进行全面实践,并通过持续的模型维护和优化提升模型性能。通过这一系统的学习路线,你将逐步掌握机器学习的知识和技能。

