
- 1JavaTCP和UDP套接字编程_在了解网络编程之前,我们先了解一下什么叫套接字
- 2Baidu Comate中文名——文心快码——送礼物来了(活动最后3天)_文心快码怎么用
- 3计算机学院北航算法作业,北航《算法与数据结构》在线作业一(BUAA algorithms and data structures online homework).doc...
- 4【AI 大模型】大模型应用架构 ( 业务架构 - AI Embedded、AI Copilot、AI Agent | 技术架构 - 提示词、代理 + 函数调用、RAG、Fine-tuning )_大模型应用模式 embedded
- 5SCI投稿经验(三) 回复审稿人_sci感谢审稿人的语句
- 6Oracle数据库表空间使用情况查询_oracle查看表空间使用情况
- 7【多机器人】基于A星实现多机器人避障路径规划附Matlab代码_多机器人避障研究
- 8ES入门系列 — 4 索引及分析器_es索引analyzer 分析器
- 9详解Hook框架frida,让你在逆向工作中效率成倍提升!_nexus 6p frida
- 10英特尔CPU研发团队繁忙的一天
[Spark]一、Spark基础入门
赞
踩
1. Spark概述
1.1 什么是Spark
回顾:Hadoop主要解决,海量数据的存储和海量数据的分析计算。
Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
1.2 Hadoop与Spark历史
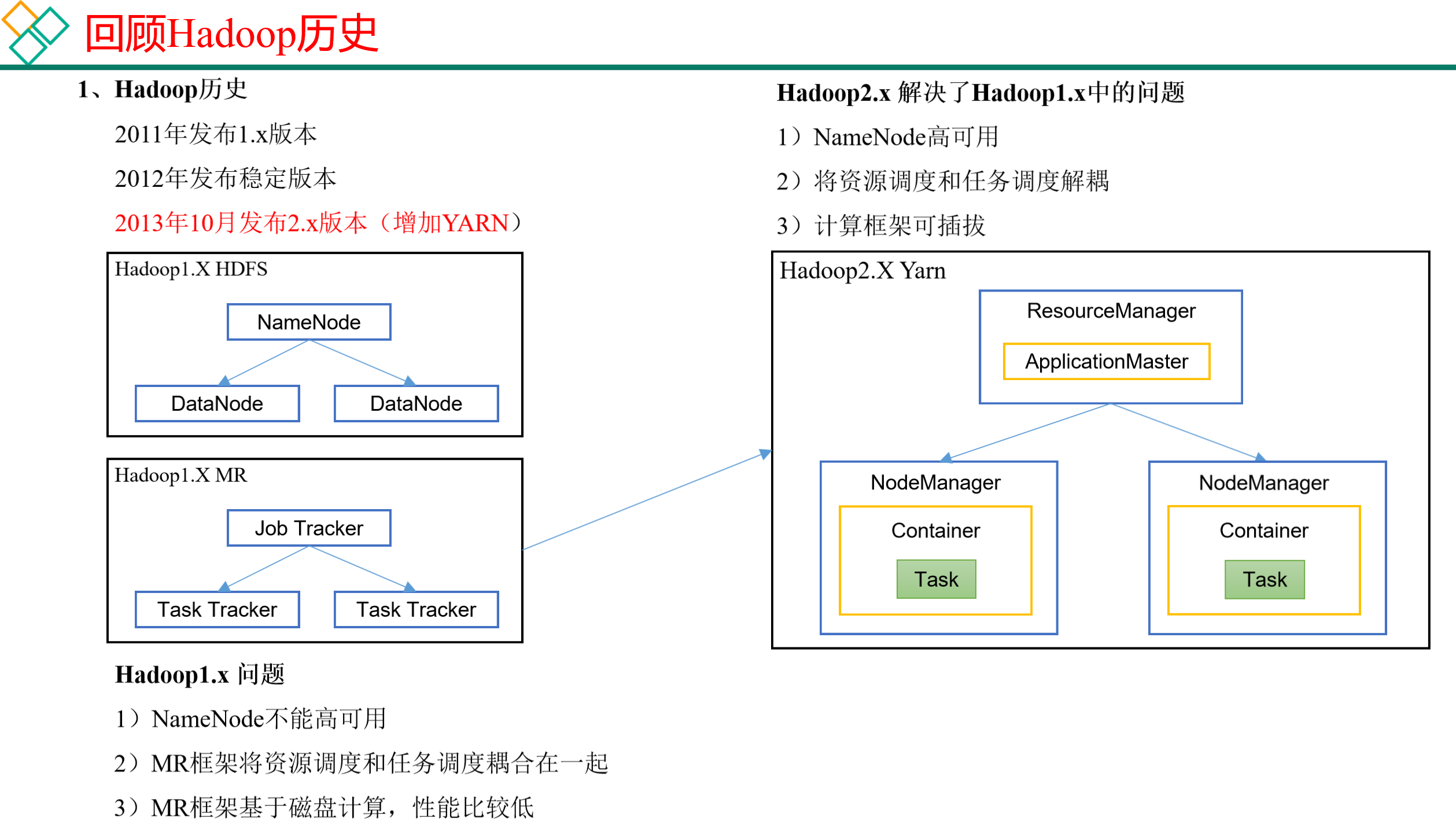
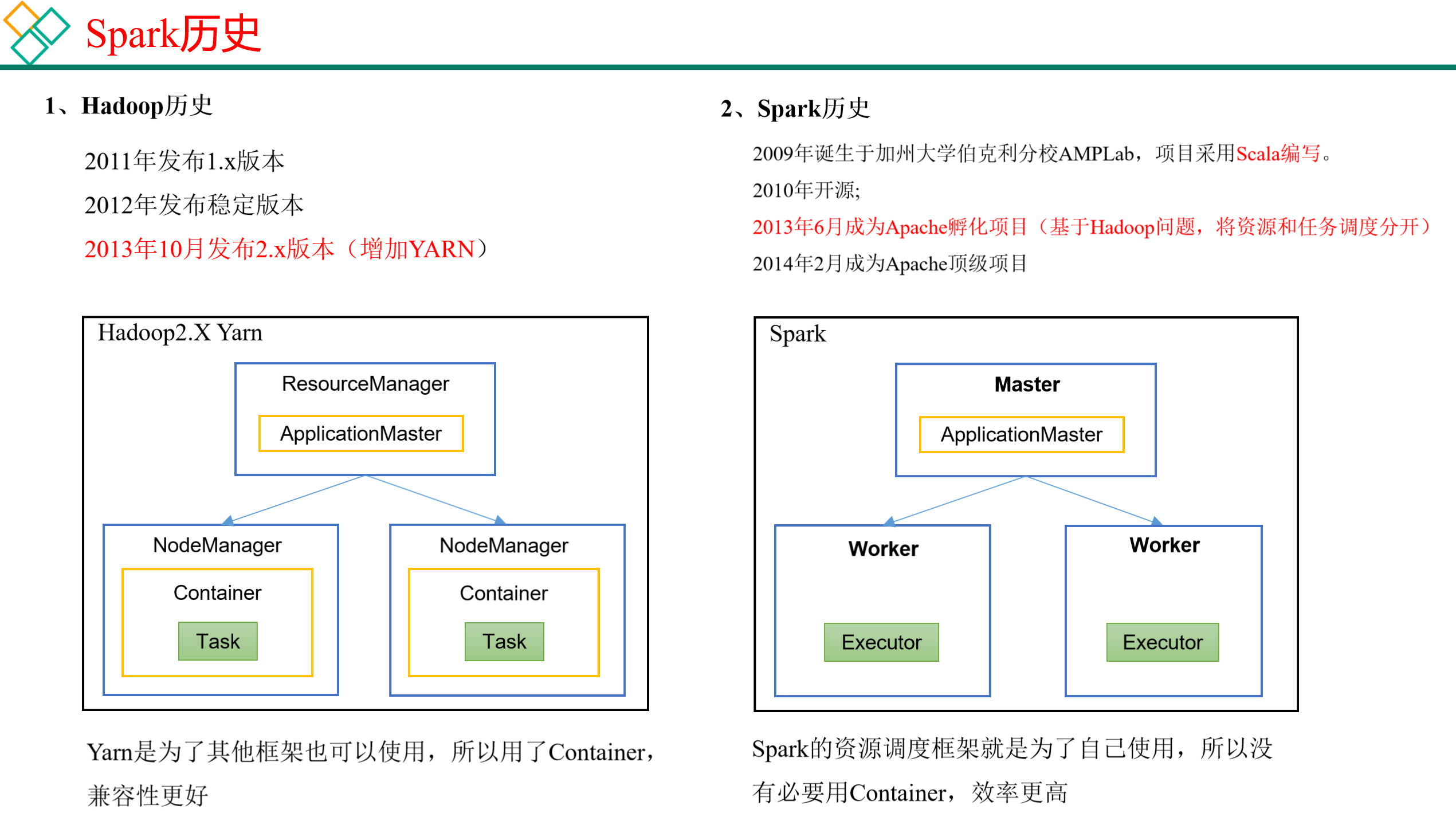
Hadoop的Yarn框架比Spark框架诞生的晚,所以Spark自己也设计了一套资源调度框架。
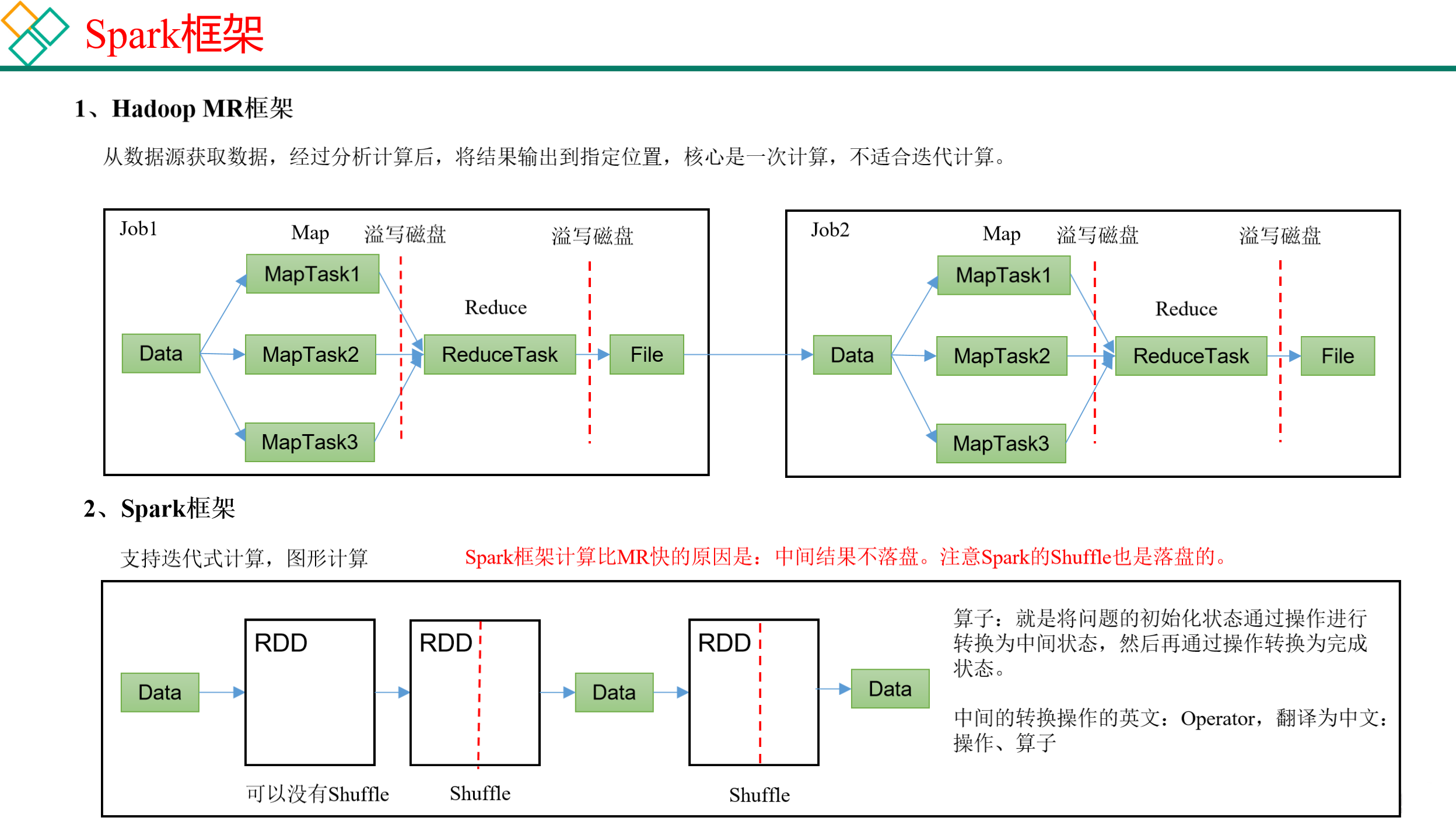
1.3 Hadoop与Spark框架对比
1.4 Spark内置模块
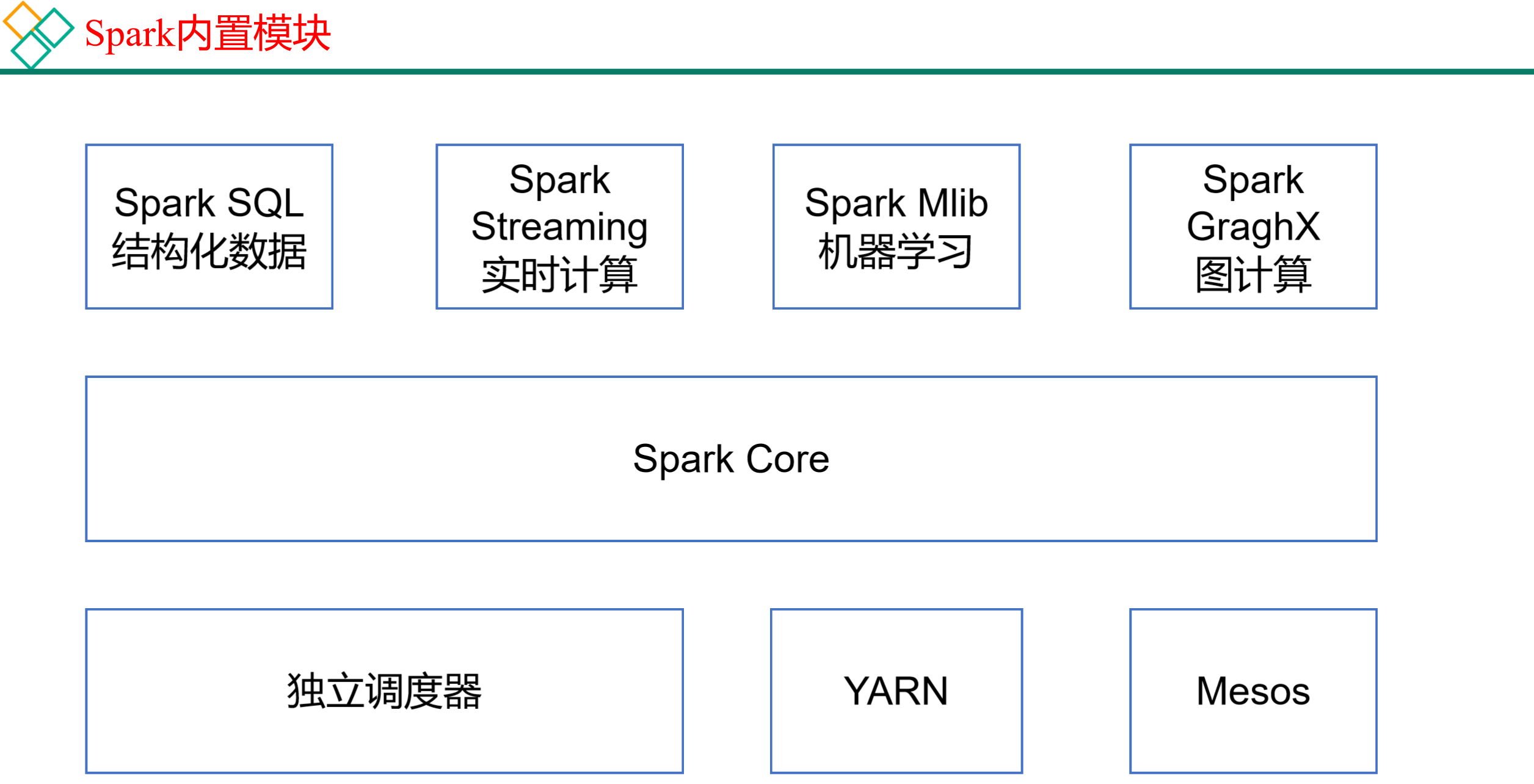
Spark Core:实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core中还包含了对弹性分布式数据集(Resilient Distributed DataSet,简称RDD)的API定义。
Spark SQL:是Spark用来操作结构化数据的程序包。通过Spark SQL,我们可以使用 SQL或者Apache Hive版本的HQL来查询数据。Spark SQL支持多种数据源,比如Hive表、Parquet以及JSON等。
Spark Streaming:是Spark提供的对实时数据进行流式计算的组件。提供了用来操作数据流的API,并且与Spark Core中的 RDD API高度对应。
Spark MLlib:提供常见的机器学习功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据 导入等额外的支持功能。
Spark GraphX:主要用于图形并行计算和图挖掘系统的组件。
集群管理器:Spark设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。为了实现这样的要求,同时获得最大灵活性,Spark支持在各种集群管理器(Cluster Manager)上运行,包括Hadoop YARN、Apache Mesos,以及Spark自带的一个简易调度器,叫作独立调度器。
Spark得到了众多大数据公司的支持,这些公司包括Hortonworks、IBM、Intel、Cloudera、MapR、Pivotal、百度、阿里、腾讯、京东、携程、优酷土豆。当前百度的Spark已应用于大搜索、直达号、百度大数据等业务;阿里利用GraphX构建了大规模的图计算和图挖掘系统,实现了很多生产系统的推荐算法;腾讯Spark集群达到8000台的规模,是当前已知的世界上最大的Spark集群。
1.5 Spark特点 
2. Spark运行模式
部署Spark集群大体上分为两种模式:单机模式与集群模式
大多数分布式框架都支持单机模式,方便开发者调试框架的运行环境。但是在生产环境中,并不会使用单机模式。因此,后续直接按照集群模式部署Spark集群。
下面详细列举了Spark目前支持的部署模式。
(1)Local模式:在本地部署单个Spark服务
(2)Standalone模式:Spark自带的任务调度模式。(不常用)
(3)YARN模式:Spark使用Hadoop的YARN组件进行资源与任务调度。(国内最常用)
(4)Mesos模式:Spark使用Mesos平台进行资源与任务的调度。
2.1 Spark安装地址
1)官网地址: Apache Spark™ - Unified Engine for large-scale data analytics
2)文档查看地址: Overview - Spark 3.3.1 Documentation
3)下载地址:
2.2 Local模式
Local模式就是运行在一台计算机上的模式,通常就是用于在本机上练手和测试。
2.2.1 安装使用
1)上传并解压Spark安装包
[hadoop102 sorfware]$ tar -zxvf spark-3.3.1-bin-hadoop3.tgz -C /opt/module/
[hadoop102 module]$ mv spark-3.3.1-bin-hadoop3 spark-local
2)官方求PI案例
- [hadoop102 spark-local]$ bin/spark-submit \
- --class org.apache.spark.examples.SparkPi \
- --master local[2] \
- ./examples/jars/spark-examples_2.12-3.3.1.jar \
- 10
可以查看spark-submit所有参数:
[hadoop102 spark-local]$ bin/spark-submit
--class:表示要执行程序的主类;
--master local[2]
(1)local: 没有指定线程数,则所有计算都运行在一个线程当中,没有任何并行计算
(2)local[K]:指定使用K个Core来运行计算,比如local[2]就是运行2个Core来执行
- 20/09/20 09:30:53 INFO TaskSetManager:
- 20/09/15 10:15:00 INFO Executor: Running task 1.0 in stage 0.0 (TID 1)
- 20/09/15 10:15:00 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
(3)local[*]:默认模式。自动帮你按照CPU最多核来设置线程数。比如CPU有8核,Spark帮你自动设置8个线程计算。
- 20/09/20 09:30:53 INFO TaskSetManager:
- 20/09/15 10:15:58 INFO Executor: Running task 1.0 in stage 0.0 (TID 1)
- 20/09/15 10:15:58 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
- 20/09/15 10:15:58 INFO Executor: Running task 2.0 in stage 0.0 (TID 2)
- 20/09/15 10:15:58 INFO Executor: Running task 4.0 in stage 0.0 (TID 4)
- 20/09/15 10:15:58 INFO Executor: Running task 3.0 in stage 0.0 (TID 3)
- 20/09/15 10:15:58 INFO Executor: Running task 5.0 in stage 0.0 (TID 5)
- 20/09/15 10:15:59 INFO Executor: Running task 7.0 in stage 0.0 (TID 7)
- 20/09/15 10:15:59 INFO Executor: Running task 6.0 in stage 0.0 (TID 6)
(4)spark-examples_2.12-3.3.1.jar:要运行的程序;
(5)10:要运行程序的输入参数(计算圆周率π的次数,计算次数越多,准确率越高);
3)结果展示
该算法是利用蒙特·卡罗算法求PI。
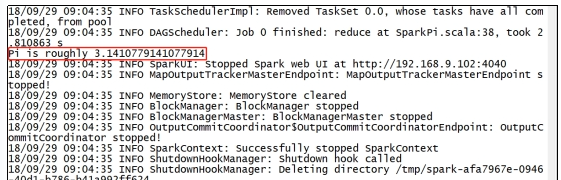
2.2.2 查看任务运行详情
1)再次运行求PI任务,增加任务次数
- [hadoop102 spark-local]$ bin/spark-submit \
- --class org.apache.spark.examples.SparkPi \
- --master local[2] \
- ./examples/jars/spark-examples_2.12-3.3.1.jar \
- 1000
2)在任务运行还没有完成时,可登录hadoop102:4040查看程序运行结果
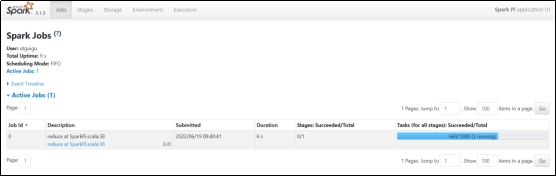
2.3 Yarn模式(重点)
Spark客户端直接连接Yarn
2.3.1 安装使用
1)解压spark
[hadoop102 software]$ tar -zxvf spark-3.3.1-bin-hadoop3.tgz -C /opt/module/
2)进入到/opt/module目录,修改spark-3.3.1-bin-hadoop3名称为spark-yarn
[hadoop102 module]$ mv spark-3.3.1-bin-hadoop3/ spark-yarn
3)修改hadoop配置文件/opt/module/hadoop/etc/hadoop/yarn-site.xml,添加如下内容
因为测试环境虚拟机内存较少,防止执行过程进行被意外杀死,做如下配置
[hadoop102 hadoop]$ vim yarn-site.xml
- <!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
- <property>
- <name>yarn.nodemanager.pmem-check-enabled</name>
- <value>false</value>
- </property>
-
- <!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
- <property>
- <name>yarn.nodemanager.vmem-check-enabled</name>
- <value>false</value>
- </property>
4)分发配置文件
[hadoop102 conf]$ xsync /opt/module/hadoop/etc/hadoop/yarn-site.xml
5)修改/opt/module/spark-yarn/conf/spark-env.sh,添加YARN_CONF_DIR配置,保证后续运行任务的路径都变成集群路径
[hadoop102 conf]$ mv spark-env.sh.template spark-env.sh
[hadoop102 conf]$ vim spark-env.sh
YARN_CONF_DIR=/opt/module/hadoop/etc/hadoop6)启动HDFS以及YARN集群
[@hadoop102 hadoop-3.3.1]$ sbin/start-dfs.sh
[@hadoop103 hadoop-3.3.1]$ sbin/start-yarn.sh
7)执行一个程序
- [@hadoop102 spark-yarn]$ bin/spark-submit \
- --class org.apache.spark.examples.SparkPi \
- --master yarn \
- ./examples/jars/spark-examples_2.12-3.3.1.jar \
- 10
参数:--master yarn,表示Yarn方式运行;--deploy-mode表示客户端方式运行程序
8)查看hadoop103:8088页面,点击History,查看历史页面
思考:目前是Hadoop的作业运行日志展示,如果想获取Spark的作业运行日志,怎么办?

2.3.2 配置历史服务
由于是重新解压的Spark压缩文件,所以需要针对Yarn模式,再次配置一下历史服务器。
1)修改spark-default.conf.template名称
[hadoop102 conf]$ mv spark-defaults.conf.template spark-defaults.conf
2)修改spark-default.conf文件,配置日志存储路径(写)
[hadoop102 conf]$ vim spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop102:8020/directory
3)修改spark-env.sh文件,添加如下配置:
[hadoop102 conf]$ vim spark-env.sh
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://hadoop102:8020/directory
-Dspark.history.retainedApplications=30"
# 参数1含义:WEBUI访问的端口号为18080
# 参数2含义:指定历史服务器日志存储路径(读)
# 参数3含义:指定保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
2.3.3 配置查看历史日志
为了能从Yarn上关联到Spark历史服务器,需要配置spark历史服务器关联路径。
目的:点击yarn(8088)上spark任务的history按钮,进入的是spark历史服务器(18080),而不再是yarn历史服务器(19888)。
1)修改配置文件/opt/module/spark-yarn/conf/spark-defaults.conf
添加如下内容:
spark.yarn.historyServer.address=hadoop102:18080
spark.history.ui.port=18080
2)重启Spark历史服务
[hadoop102 spark-yarn]$ sbin/stop-history-server.sh
[hadoop102 spark-yarn]$ sbin/start-history-server.sh
3)提交任务到Yarn执行
[hadoop102 spark-yarn]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
./examples/jars/spark-examples_2.12-3.3.1.jar \
10
4)Web页面查看日志:http://hadoop103:8088/cluster

点击“history”跳转到http://hadoop102:18080/

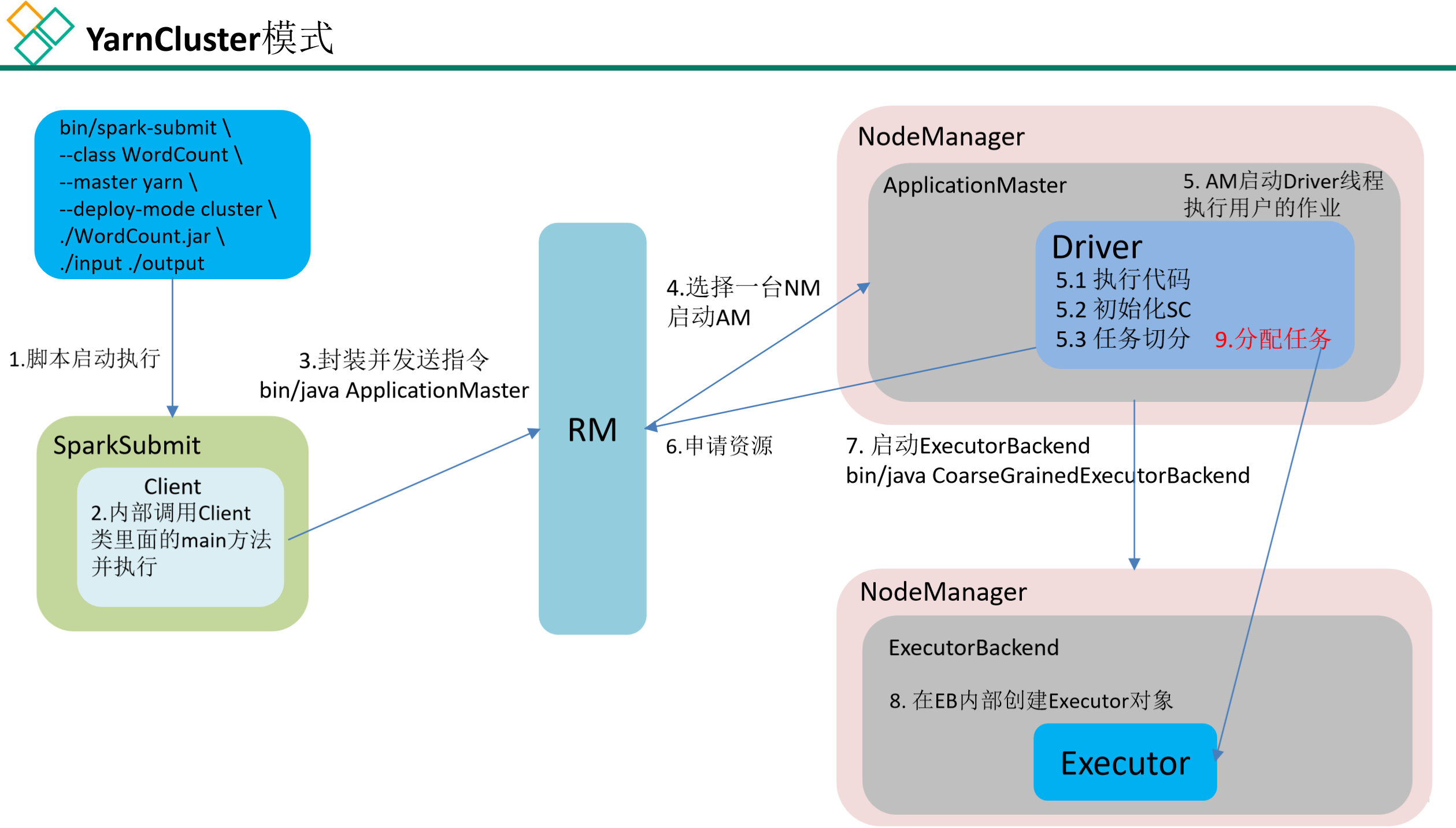
2.3.4 运行流程
Spark有yarn-client和yarn-cluster两种模式,主要区别在于:Driver程序的运行节点。
yarn-client:Driver程序运行在客户端,适用于交互、调试,希望立即看到app的输出。
yarn-cluster:Driver程序运行在由ResourceManager启动的APPMaster,适用于生产环境。
1)客户端模式(默认)
[hadoop102 spark-yarn]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.12-3.3.1.jar \
10

2)集群模式
[hadoop102 spark-yarn]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.12-3.3.1.jar \
10
(1)查看 http://hadoop103:8088/cluster页面,点击History按钮,跳转到历史详情页面
![]()
(2)http://hadoop102:18080点击Executors->点击driver中的stdout

![]()

注意:如果在yarn日志端无法查看到具体的日志,则在yarn-site.xml中添加如下配置并启动Yarn历史服务器
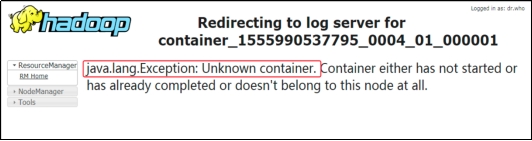
- <property>
- <name>yarn.log.server.url</name>
- <value>http://hadoop102:19888/jobhistory/logs</value>
- </property>
注意:hadoop历史服务器也要启动 mr-jobhistory-daemon.sh start historyserver
2.4 Standalone模式(了解)
Standalone模式是Spark自带的资源调度引擎,构建一个由Master + Worker构成的Spark集群,Spark运行在集群中。
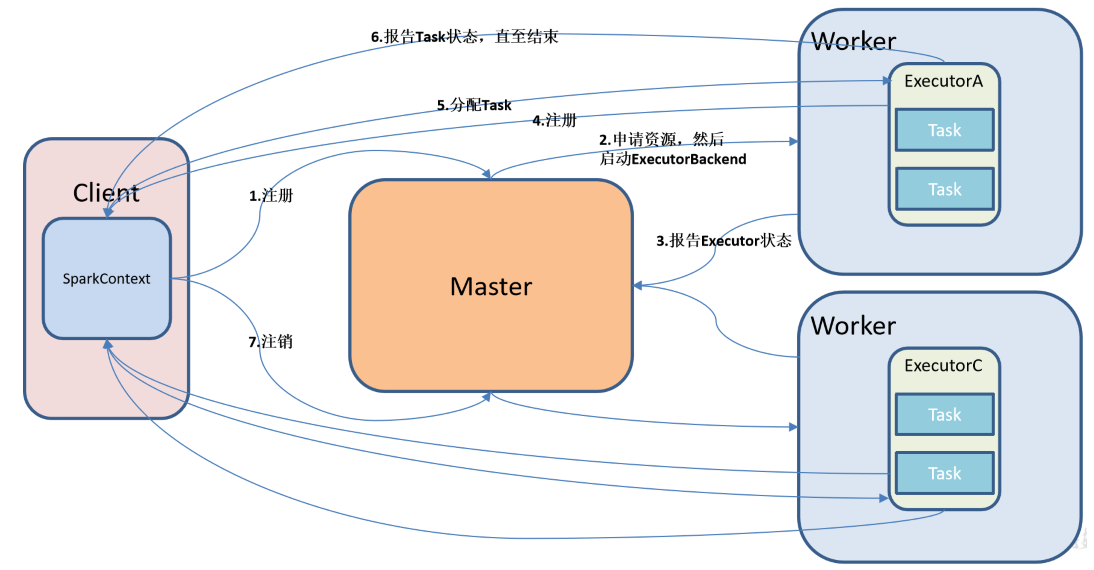
这个要和Hadoop中的Standalone区别开来。这里的Standalone是指只用Spark来搭建一个集群,不需要借助Hadoop的Yarn和Mesos等其他框架。
Spark 的 Standalone 模式体现了经典的master-slave 模式。集群规划:
| 主机 | Linux1 | Linux2 | Linux3 |
| Spark | Worker Master | Worker | Worker |
1. 解压缩文件:
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module cd /opt/module
mv spark-3.0.0-bin-hadoop3.2 spark-standalone
2. 修改配置文件
1)进入解压缩后路径的 conf 目录,修改 workers.template 文件名为 workers
mv workers.template workers
2)修改 slaves 文件,添加work 节点
- hadoop102
- hadoop103
- hadoop104
3)修改 spark-env.sh.template 文件名为 spark-env.sh
mv spark-env.sh.template spark-env.sh
4)修改 spark-env.sh 文件,添加 JAVA_HOME 环境变量和集群对应的 master 节点
- export JAVA_HOME=/opt/module/jdk1.8.0_144
- SPARK_MASTER_HOST=hadoop102
- SPARK_MASTER_PORT=7077
注意:7077 端口,相当于hadoop3内部通信的 8020 端口,此处的端口需要确认自己的Hadoop配置
5)分发 spark-standalone 目录
xsync spark-standalone
3. 启动集群
(1)执行脚本命令:sbin/start-all.sh
(2)查看三台服务器进程
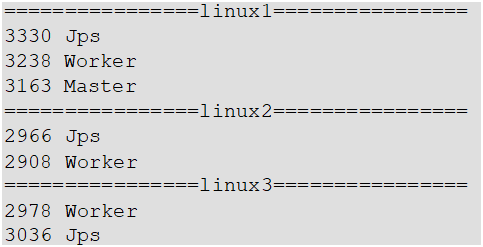
(3)查看WebUI界面:Master资源监控Web UI界面 http://hadoop102:8080
4. 提交应用
| bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark://hadoop101:7077 \ ./examples/jars/spark-examples_2.12-3.0.0.jar 10 |
| 1)--class 表示要执行程序的主类 2)--master spark://linux1:7077 独立部署模式,连接到Spark集群 3)spark-examples_2.12-3.0.0.jar 运行类所在的jar包 4)数字 10 表示程序的入口参数,用于设定当前应用的任务数量 |
5. 提交参数说明
- bin/spark-submit \
- --class <main-class>
- --master <master-url> \
- ... # other options
- <application-jar> \ [application-arguments]
| --class | Spark 程序中包含主函数的类 |
|
| --master | Spark 程序运行的模式(环境) | 模式:local[*]、spark://linux1:7077、 Yarn |
| --executor-memory 1G | 指定每个 executor 可用内存为 1G | 符合集群内存配置即可,具体情况具体分析。 |
| --total-executor-cores 2 | 指定所有executor 使用的cpu 核数为 2 个 |
|
| --executor-cores | 指定每个executor 使用的cpu 核数 |
|
| application-jar | 打包好的应用 jar,包含依赖。 这个 URL 在集群中全局可见。 比如 hdfs:// 共享存储系统, 如果是file:// path, 那么所有的节点的 path 都包含同样的jar |
|
| application-arguments | 传给 main()方法的参数 |
|
6. 配置历史服务器
由于 spark-shell 停止掉后,集群监控 linux1:4040 页面就看不到历史任务的运行情况,
所以开发时都配置历史服务器记录任务运行情况。
- (1) 修改spark-defaults.conf.template 文件名为:spark-defaults.conf
- mv spark-defaults.conf.template spark-defaults.conf
-
- (2) 修改修改spark-default.conf文件,开启Log:
- $ vi spark-defaults.conf
- spark.eventLog.enabled true
- spark.eventLog.dir hdfs://hadoop101:9000/sparklog
-
- 注意:HDFS上的目录需要提前存在。
- $ hadoop fs -mkdir /sparklog
- (3) 修改spark-env.sh文件,添加如下配置:
- $ vi spark-env.sh
- export SPARK_HISTORY_OPTS="
- -Dspark.history.ui.port=18080
- -Dspark.history.retainedApplications=30
- -Dspark.history.fs.logDirectory=hdfs://hadoop101:9000/sparklog"
-
- 参数描述:
- spark.eventLog.dir:Application在运行过程中所有的信息均记录在该属性指定的路径下;
- spark.history.ui.port=18080 WEBUI访问的端口号为18080
- spark.history.fs.logDirectory=hdfs://hadoop102:9000/directory 配置了该属性后,在start-history-server.sh 时就无需再显式的指定路径,Spark History Server页面只展示该指定路径下的信息
- spark.history.retainedApplications=30 指定保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
-
- (4) 分发配置文件:xsync conf
- (5) 重新启动集群和历史服务
- sbin/start-all.sh
- sbin/start-history-server.sh
- (6) 重新提交任务
- bin/spark-submit \
- --class org.apache.spark.examples.SparkPi \
- --master spark://hadoop101:7077 \
- ./examples/jars/spark-examples_2.12-3.0.0.jar \
- 10
- (7) 查看历史任务:http://hadoop102:18080
7. 配置高可用HA
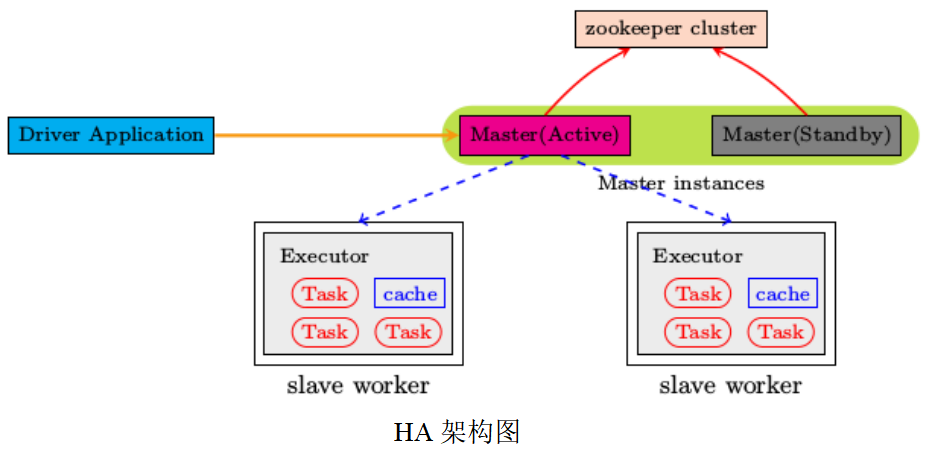
所谓的高可用是因为当前集群中的 Master 节点只有一个,所以会存在单点故障问题。所以为了解决单点故障问题,需要在集群中配置多个 Master 节点,一旦处于活动状态的 Master 发生故障时,由备用 Master 提供服务,保证作业可以继续执行。这里的高可用一般采用Zookeeper 设置.
集群规划:
| 主机 | hadoop102 | hadoop103 | hadoop104 |
| spark | Master zookeeper worker | Master Zookeeper Worker | Zookeeper Worker |
(1)启动Zookeeper
(2)修改spark-env.sh
- 注 释 如 下 内 容 :
- #SPARK_MASTER_HOST=hadoop101
- #SPARK_MASTER_PORT=7077
-
- 添加如下内容:
- #Master 监控页面默认访问端口为 8080,但是可能会和Zookeeper 冲突,所以改成8989,也可以自定义,访问UI监控页面时请注意
- SPARK_MASTER_WEBUI_PORT=8989
- export SPARK_DAEMON_JAVA_OPTS="
- -Dspark.deploy.recoveryMode=ZOOKEEPER
- -Dspark.deploy.zookeeper.url=hadoop102,hadoop103,hadoop104
- -Dspark.deploy.zookeeper.dir=/spark"
(3)分发配置:xsync spark-env.sh
(4)在hadoop102启动全部节点:sbin/start-all.sh
(5)在hadoop103上单独启动master:sbin/start-master.sh 此时hadoop103上的master处于Standby状态
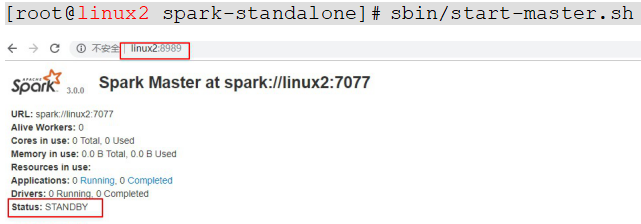
(6)Spark-HA集群访问
(7)停止hadoop102上的Master进程
(8)观察hadoop103上的Master进程是否进入Active状态
2.5 Mesos模式(了解)
Spark客户端直接连接Mesos;不需要额外构建Spark集群。国内应用比较少,更多的是运用Yarn调度。
2.6 几种模式对比
| 模式 | Spark安装机器数 | 需启动的进程 | 所属者 |
| Local | 1 | 无 | Spark |
| Standalone | 3 | Master及Worker | Spark |
| Yarn | 1 | Yarn及HDFS | Hadoop |
2.7 端口号总结
1)Spark查看当前Spark-shell运行任务情况端口号:4040
2)Spark历史服务器端口号:18080 (类比于Hadoop历史服务器端口号:19888)

