
- 1【MediaPipe】(3) AI视觉,人脸识别,附python完整代码_mediapipe bbox获取
- 2linux内核源码git操作简单总结_linux kernel git
- 3ChatGPT:ChatOpenAI 是什么?_langchain-openai的chatopenai参数
- 4WBOLT 搜索推送管理插件(原百度推送管理插件) 3.4.11 Pro
- 5Apache Kylin性能优化全景:释放大数据加速潜力_apachkylin 配置参数优化
- 6桥接模式、NAT模式和仅主机模式_桥接 nat
- 7【以Qwen2大模型为例】vLLM部署流式推理,openai接口调用,requests调用_vllm流式输出
- 8【软件测试】软件测试学习笔记(一)_验收测试笔记
- 9华为仓颉开发语言“可能”明天正式面世(2024年6月20日写下)_仓颉编程 2024
- 10spark学习之SparkStreaming_spark任务执行进展日志隔几秒更新一次?
【大模型】基于ChatGLM的大模型微调(P-Tuning v2、LoRA、Full Parameter) [更新中......]_chatglm模型文档
赞
踩
一、前言
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
二、说明
2.1 代码结构
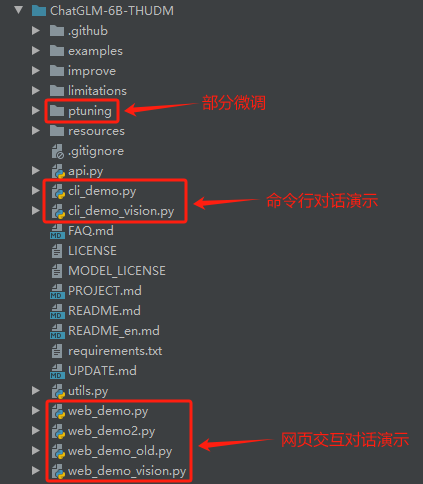
2.2 依赖包版本
由于大模型相关的各种依赖包版本更新较快,会导致各种报错,如:
'ChatGLMTokenizer' object has no attribute 'sp_tokenizer'
- 1
这里主要是由transformers 版本问题导致的,解决方案可以参考博客:https://blog.csdn.net/Tink_bell/article/details/137942170
三、启动对话演示
ChatGLM-6B下提供了cli_demo.py和web_demo.py两个文件来启动模型:
- cli_demo.py:使用命令行进行交互。
- web_demo.py:使用gradio库使用本机服务器进行网页交互。
这里,依赖包的版本会影响到代码的运行。经过多次报错与尝试,我这里使用的依赖包版本为:
transformers==4.33.0
gradio==3.39.0
- 1
- 2
3.1 命令行交互 cli_demo.py
[待补充]
3.2 网页交互 web_demo.py
web_demo.py中基于gradio库使用本机服务器进行网页交互,具体运行步骤如下:
(1)模型路径测试。
首先需要将模型地址配置为本地模型路径
原代码:
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
- 1
- 2
修改为本地模型路径后的代码:
model_path = './model/chatglm-6b'
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModel.from_pretrained(model_path, trust_remote_code=True).half().cuda()
model = model.eval()
- 1
- 2
- 3
- 4
(2)模型量化。
这里,由于我的GPU内存不够,所以对模型做量化操作:
model_path = './model/chatglm-6b'
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModel.from_pretrained(model_path, quantization_config=bnb_config, device_map={"":0}, trust_remote_code=True)
model = model.eval()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
(3)运行 web_demo.py
可以看到控制台输出

说明网页交互服务已在本地 http://127.0.0.1:7860 运行起来。
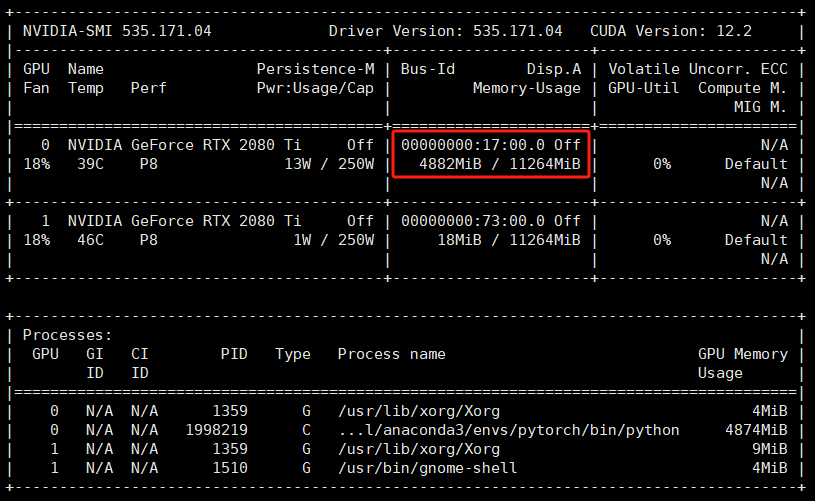
查看GPU显存占用情况,可以看到使用模型量化,最后只占用了不到5GB的显存:
(4)端口映射。
这里,由于我们是在远程服务器上运行的服务,如果想在本地浏览器访问,需要做一个端口映射,具体命令如下:
ssh -L 1234:localhost:7860 root@172.xxx.yyy.zzz
- 1
基于上述命令,将远程服务器的 7860 端口映射至本地 1234 端口。
(5)本地访问服务。
然后我们在本地浏览器打开 http://localhost:1234/ 即可访问该页面,如下所示:

在输入窗口输入文本信息并提交即可实现调用ChatGLM的对话功能。
四、微调模型
ChatGLM模型的fine-tune有多种模式:
- P-Tuning v2
- LoRA
- Full parameter
其中ChatGLM官方代码仓库中给出了基于 P-Tuning v2 及 Full parameter 的方法,具体微调模型的方式可以参考B站视频:【官方教程】ChatGLM-6B 微调:P-Tuning,LoRA,Full parameter
LoRA的微调方法可以参考:https://github.com/yuanzhoulvpi2017/zero_nlp/tree/main/chatglm_v2_6b_lora
4.1 基于 P-Tuning v2 微调模型
官方给出的微调教程:https://github.com/THUDM/ChatGLM-6B/blob/main/ptuning/README.md
本仓库实现了对于 ChatGLM-6B 模型基于 P-Tuning v2 的微调。P-Tuning v2 将需要微调的参数量减少到原来的 0.1%,再通过模型量化、Gradient Checkpoint 等方法,最低只需要 7GB 显存即可运行。
下面以 ADGEN (广告生成) 数据集为例介绍代码的使用方法。
4.1.1 软件依赖
这里,基于P-Tuning v2 微调模型对于transformers的版本有限制,需要4.27.1版本的transformers:
pip install transformers==4.27.1
- 1
此外,还需要安装以下依赖
pip install rouge_chinese nltk jieba datasets
- 1
4.1.2 下载数据集
ADGEN 数据集任务为根据输入(content)生成一段广告词(summary)。
{
"content": "类型#上衣*版型#宽松*版型#显瘦*图案#线条*衣样式#衬衫*衣袖型#泡泡袖*衣款式#抽绳",
"summary": "这件衬衫的款式非常的宽松,利落的线条可以很好的隐藏身材上的小缺点,穿在身上有着很好的显瘦效果。领口装饰了一个可爱的抽绳,漂亮的绳结展现出了十足的个性,配合时尚的泡泡袖型,尽显女性甜美可爱的气息。"
}
- 1
- 2
- 3
- 4
ADGEN 数据集可以从 Google Drive 或者 Tsinghua Cloud 来下载。
4.1.3 下载模型文件
模型文件:https://huggingface.co/THUDM/chatglm-6b/tree/main
可以选择 git clone 或者 手动 的方式来下载模型文件。
4.1.4 训练步骤
(1)文件及数据准备
使用 ptuning 文件夹下的代码进行微调,这里我们在当前目录下创建:
model目录存放下载的模型文件data目录存放ADGEN 数据文件
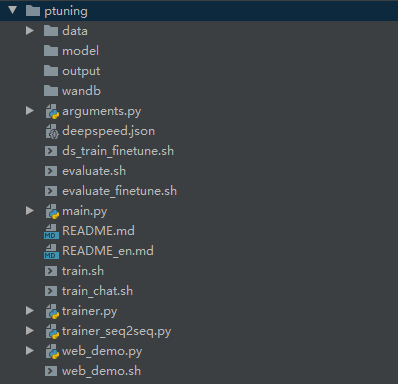
(2)修改 train.sh 代码
根据本地模型及数据文件目录,修改train.sh 中的相应参数:
PRE_SEQ_LEN=128 LR=2e-2 CUDA_VISIBLE_DEVICES=0 python3 main.py \ --do_train \ --train_file './data/AdvertiseGen/train.json' \ --validation_file './data/AdvertiseGen/dev.json' \ --prompt_column content \ --response_column summary \ --overwrite_cache \ --model_name_or_path './model/chatglm-6b/' \ --output_dir output/adgen-chatglm-6b-pt-$PRE_SEQ_LEN-$LR \ --overwrite_output_dir \ --max_source_length 64 \ --max_target_length 64 \ --per_device_train_batch_size 1 \ --per_device_eval_batch_size 1 \ --gradient_accumulation_steps 16 \ --predict_with_generate \ --max_steps 3000 \ --logging_steps 10 \ --save_steps 1000 \ --learning_rate $LR \ --pre_seq_len $PRE_SEQ_LEN \ --quantization_bit 4

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
【参数说明】:
train.sh 中的 PRE_SEQ_LEN 和 LR 分别是 soft prompt 长度和训练的学习率,可以进行调节以取得最佳的效果。P-Tuning-v2 方法会冻结全部的模型参数,可通过调整 quantization_bit 来被原始模型的量化等级,不加此选项则为 FP16 精度加载。
在默认配置 quantization_bit=4、per_device_train_batch_size=1、gradient_accumulation_steps=16 下,INT4 的模型参数被冻结,一次训练迭代会以 1 的批处理大小进行 16 次累加的前后向传播,等效为 16 的总批处理大小,此时最低只需 6.7G 显存。若想在同等批处理大小下提升训练效率,可在二者乘积不变的情况下,加大 per_device_train_batch_size 的值,但也会带来更多的显存消耗,请根据实际情况酌情调整。
(3)运行脚本
bash train.sh
- 1
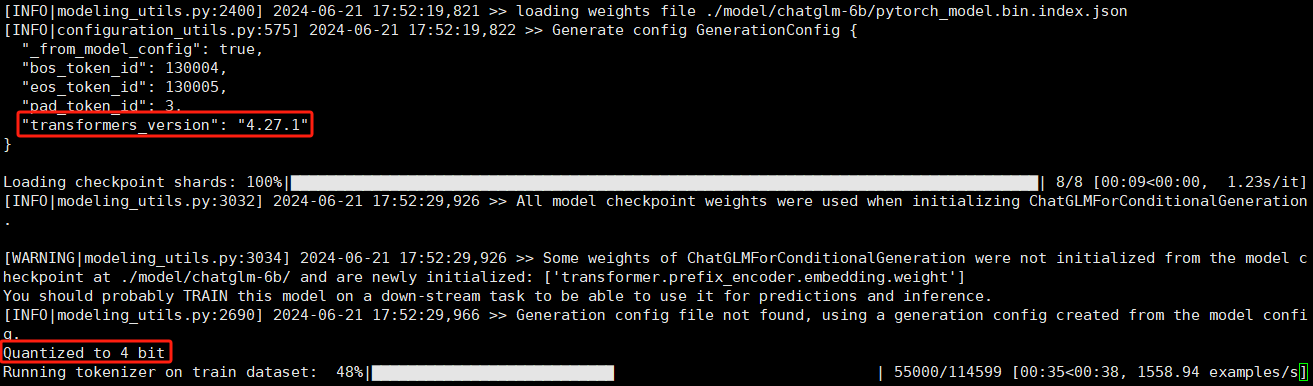
这里,我们对模型做了量化处理,可以看到占用的显存占用情况:
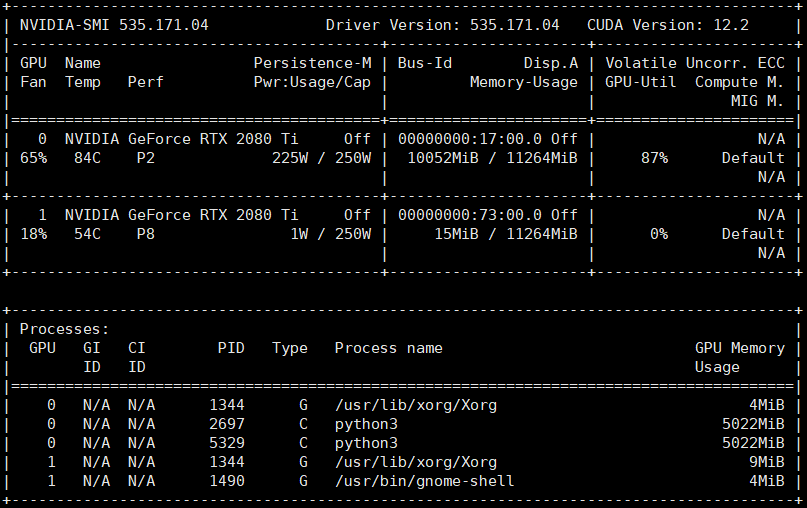
迭代3000次:

可以通过wandb 查看运行中的参数变化情况:

wandb中可以看到 train_loss 的变化情况:

【问题记录】:
- 训练/推理过程中,出现报错
name‘round_up’ is not define
解决方案:可以注释掉train.sh中的这一行代码--quantization_bit 4解决
4.1.5 推理步骤
(1)将 evaluate.sh 中的参数修改为自己环境的。
- 在 P-tuning v2 训练时模型只保存 PrefixEncoder 部分的参数,所以在推理时需要同时加载原 ChatGLM-6B 模型以及 PrefixEncoder 的权重。
因此需要指定 evaluate.sh 中的参数:
--model_name_or_path './model/chatglm-6b'
--ptuning_checkpoint $CHECKPOINT_PATH
- 1
- 2
第一行是给出我们原始的 chatglm-6b 模型所在路径,第二行给出ptuning生成的checkpoint路径。
- 评测指标为中文 Rouge score 和 BLEU-4。
(2)运行如下命令:
bash evaluate.sh
- 1
推理过程如下:

(3)生成的结果保存在 ./output/adgen-chatglm-6b-pt-8-1e-2/generated_predictions.txt

我们来看看其中的前3条推理数据的内容:
{"content": "类型#上衣*材质#牛仔布*颜色#白色*风格#简约*图案#刺绣*衣样式#外套*衣款式#破洞",}
{"content": "类型#裙*材质#针织*颜色#纯色*风格#复古*风格#文艺*风格#简约*图案#格子*图案#纯色*图案#复古*裙型#背带裙*裙长#连衣裙*裙领型#半高领"}
{"content": "类型#上衣*风格#嘻哈*图案#卡通*图案#印花*图案#撞色*衣样式#卫衣*衣款式#连帽"}
- 1
- 2
- 3
- 4
- 5
对应的label与推理结果:
{"labels": "简约而不简单的牛仔外套,白色的衣身十分百搭。衣身多处有做旧破洞设计,打破单调乏味,增加一丝造型看点。衣身后背处有趣味刺绣装饰,丰富层次感,彰显别样时尚。",
"predict": "牛仔外套作为季节必备单品,总是能够彰显男性的魅力。这款牛仔外套采用了经典的破洞元素,让整体更显随性与洒脱。而白色刺绣点缀在衣身上,更是增添了一丝浪漫气息。"}
{"labels": "这款BRAND针织两件套连衣裙,简约的纯色半高领针织上衣,修饰着颈部线,尽显优雅气质。同时搭配叠穿起一条背带式的复古格纹裙,整体散发着一股怀旧的时髦魅力,很是文艺范。",
"predict": "纯色的针织连衣裙,简约的半高领,修饰颈部曲线,展现女性的优雅气质。复古的格纹,尽显文艺范儿。背带裙的裙型,展现少女的俏皮。"}
{"labels": "嘻哈玩转童年,随时<UNK>,没错,出街还是要靠卫衣来装酷哦!时尚个性的连帽设计,率性有范还防风保暖。还有胸前撞色的卡通印花设计,靓丽抢眼更富有趣味性,加上前幅大容量又时尚美观的袋鼠兜,简直就是",
"predict": "BRAND的这款卫衣采用连帽的版型设计,穿着舒适,彰显嘻哈风范。衣身的撞色印花图案,彰显时尚个性,彰显时尚风格。衣身的卡通图案设计,充满了俏皮感,彰显少女气息。"}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
可以看到整体上推理效果还是不错的。
4.2 基于 Full Parameter 微调模型
如果需要进行全参数的 Finetune,需要安装 Deepspeed,然后运行以下指令:
bash ds_train_finetune.sh
- 1
4.3 基于LoRA微调模型
ChatGLM官方仓库中的部分微调使用的是基于 P Tuning v2的微调方式,并未给出基于LoRA的微调。
LoRA的微调方法可以参考:https://github.com/yuanzhoulvpi2017/zero_nlp/tree/main/chatglm_v2_6b_lora
这里LoRA微调是基于
ChatGLM-v2-6B的微调,所以需要在Hugging Face上下载ChatGLM-v2-6B的模型文件。如果直接使用ChatGLM-v3-6B会出现报错。
这里给出微调前后模型的输出效果:
- 微调前(ChatGLM-v2-6B)
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0, 1'
from transformers import AutoTokenizer, AutoModel
import torch
model_name_or_path = "./model/chatglm2-6b/"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True)
model = AutoModel.from_pretrained(model_name_or_path, trust_remote_code=True, device_map='auto', torch_dtype=torch.bfloat16) #.half().cuda()
model = model.eval()
response, history = model.chat(tokenizer, "类型#上衣*材质#牛仔布*颜色#白色*风格#简约*图案#刺绣*衣样式#外套*衣款式#破洞", history=[])
print(response)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
输出结果为:
根据您提供的信息,我们可以为您提供一件简约刺绣牛仔布外套,衣样式为外套,衣款式为破洞,材质为牛仔布,颜色为白色,风格为简约。
- 1
- 微调后(ChatGLM-v2-6B + lora model)
from peft import PeftModel, PeftConfig
# 注意这里需要传递lora训练的路径
peft_model_id = "output/adgen-chatglm2-6b-lora_version/checkpoint-3000"
model = PeftModel.from_pretrained(model, peft_model_id) # 基础模型与Lora模型合并
model = model.eval()
response, history = model.chat(tokenizer, "类型#上衣*材质#牛仔布*颜色#白色*风格#简约*图案#刺绣*衣样式#外套*衣款式#破洞", history=[])
print(response)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
输出结果为:
这款外套是简约白色设计,采用牛仔布材质制作,有着非常出色的舒适感,破洞的元素设计更是增添个性魅力,时尚有型。衣身两侧的刺绣图案,充满了艺术气息,衬托出女性独特的魅力,彰显出女性的优雅气质。
- 1
可以看出经过Lora微调后,模型能够比较好的生成广告语。

