
- 1Java基础:浅析List、Set、Map的特点和区别_java map set 区别
- 2LSTM+CRF
- 3Transformers架构系列---transformers库的使用_使用transformers库 rnn
- 4ES中文分词器-ik分词器安装_es 集成中文分词器 maven
- 5【Linux】进程间通信——管道_管道文件的本质
- 6python使用matplotlib可视化线图(line plot)、自定义设置不同线条的色彩(setting the color of multiple plots)_python plt 线段颜色改编
- 7实验5Hive查询_(1)创建emp表,包含empno(int)、ename(string)、gender(string
- 8资源整理
- 9spring boot项目中ackson-databind 升级至2.9.9.2引起错误NoClassDefFoundError:Could not initialize class_jackson databind版本升级项目启动报错
- 10教你正确整治流氓APP,做好安卓手机权限管理来保护隐私_com.web1n.permissiondog
大模型面试题目
赞
踩
1.为什么需要做位置编码
位置编码(Positional Encoding)在变换器(Transformer)模型中非常重要,因为变换器架构本身没有内置的顺序信息。变换器使用的是自注意力机制,它能够捕捉输入序列中所有词之间的相关性,但它并不关心这些词的顺序。因此,我们需要一种方法来向模型提供词的顺序信息,这就是位置编码的作用。
为什么需要位置编码?
transformer模型的输入是一个序列的词向量,这些词向量是通过嵌入层(Embedding Layer)得到的。这些词向量本质上是无序的,因为嵌入层只负责将词转换为向量表示,并不包含任何顺序信息。
为了使模型理解序列中词的顺序,我们需要将位置信息引入到词向量中。这有助于模型捕捉序列的结构和上下文关系,从而更好地理解和生成自然语言文本。
位置编码的实现
位置编码有多种实现方法,其中最常见的是正弦和余弦位置编码。这种方法的主要思想是使用不同频率的正弦和余弦函数为每个位置生成唯一的编码。具体公式如下:

位置编码的特点
- 周期性:正弦和余弦函数的周期性使得位置编码能够捕捉到词与词之间的相对位置。
- 唯一性:不同位置的编码是唯一的,确保每个位置的信息不会混淆。
- 易于计算:这种方法无需学习参数,只需计算正弦和余弦函数。
如何使用位置编码
在变换器模型中,位置编码通常与词向量相加,形成包含顺序信息的输入向量。具体步骤如下:
- 计算位置编码:根据前面的公式,为每个位置计算位置编码。
- 加位置编码到词向量:将位置编码与词向量相加,形成新的输入向量。
2.LLMs中,量化权重和量化激活的区别是什么?
在大型语言模型(LLMs)中,量化(Quantization)是一种将浮点数表示的权重和激活值转换为较低位数的整数(例如,从32位浮点数转换为8位整数)的技术。量化的目的是减少模型的计算和存储需求,同时尽量保持模型性能。量化可以应用于模型的权重和激活值,它们之间有一些关键的区别。
量化权重(Weight Quantization)
量化权重是指将模型中的权重参数转换为较低位数的表示。具体来说:
- 作用对象:模型的权重矩阵。
- 目的:减少模型的内存占用和计算复杂度。
- 方法:常见的方法包括对权重进行线性量化,将浮点数范围映射到整数范围。
- 影响:对推理过程中计算效率的提高非常显著,因为权重在推理过程中是固定的。
示例
假设有一个浮点数权重矩阵:
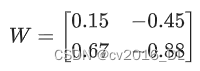
经过量化后,可能变成一个8位整数矩阵:
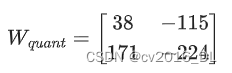
量化激活(Activation Quantization)
量化激活是指将模型在推理过程中生成的激活值转换为较低位数的表示。具体来说:
- 作用对象:模型在前向传播过程中生成的中间激活值。
- 目的:进一步减少内存占用和加快计算速度,尤其是在推理阶段。
- 方法:通常对激活值进行动态量化,因为激活值是随输入变化的。
- 影响:对模型性能的影响较大,因为激活值是动态变化的,需要更精确的量化方法来保持模型的准确性。
示例
假设有一个浮点数激活矩阵: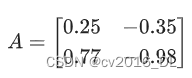
经过量化后,可能变成一个8位整数矩阵:
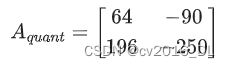
主要区别
-
作用时间:
- 权重量化通常在模型训练完成后进行,主要用于推理阶段。
- 激活量化在推理过程中实时进行,因为激活值是动态变化的。
-
存储需求:
- 权重量化主要减少模型文件的存储需求。
- 激活量化主要减少推理过程中内存的使用量。
-
计算复杂度:
- 权重量化减少了每次前向传播中的计算复杂度,因为权重是预先量化好的。
- 激活量化需要在每层激活值生成时进行量化,增加了一些计算开销。
-
精度影响:
- 权重量化对模型精度的影响较小,因为可以在量化过程中进行精细调整。
- 激活量化对模型精度的影响较大,需要更加谨慎的量化策略。
总结
量化权重和量化激活都是为了提高模型的计算效率和减少内存占用,但它们在应用时有不同的侧重点和技术难点。权重量化主要针对模型的固定参数,激活量化则针对模型的动态输出。理解这两者的区别和应用场景,有助于更好地优化大型语言模型的性能。
3.什么是检索增强生成(RAG)?
检索增强生成(Retrieval-Augmented Generation,简称RAG)是一种将检索模型和生成模型结合起来的混合方法,用于提高文本生成任务的性能。这种方法利用信息检索技术从大型数据库中检索相关文档,然后利用生成模型基于这些检索到的文档生成高质量的文本。这种方法在处理需要丰富背景知识或长尾信息的问题时特别有效。
RAG 的基本流程
以下是 RAG 的基本工作流程:
- 检索阶段(Retrieval Stage):
- 给定一个输入查询(query),使用信息检索模型从大型数据库(如文档库、知识库)中检索出若干相关文档。常用的检索模型包括BM25、TF-IDF以及基于深度学习的双编码器(bi-encoder)模型。
- 生成阶段(Generation Stage):
- 将检索到的文档作为上下文输入到生成模型(如GPT-3、T5等),生成响应文本。生成模型基于输入查询和检索到的相关文档,生成更为准确和丰富的答案。
优势
- 丰富的背景知识:通过检索相关文档,生成模型可以参考更广泛的信息源,从而生成更为详细和准确的回答。
- 处理长尾问题:对于一些长尾问题或罕见问题,RAG 可以通过检索相关文档提供必要的背景信息,从而生成高质量的回答。
- 灵活性:RAG 方法可以应用于多种任务,包括问答系统、对话生成、文本摘要等。
RAG 示例
以下是一个简单的例子,展示了 RAG 的基本思路:
-
输入查询:
- 用户输入:
“什么是量子计算?”
- 用户输入:
-
检索阶段:
- 检索模型从数据库中检索出相关的文档,例如:
- 文档1:
“量子计算是一种基于量子力学原理的新型计算方法...” - 文档2:
“量子计算机利用量子比特(qubits)进行计算...”
- 文档1:
- 检索模型从数据库中检索出相关的文档,例如:
-
生成阶段:
- 生成模型基于输入查询和检索到的文档,生成一个综合的回答:
- 回答:
“量子计算是一种利用量子比特进行计算的新型计算方法,它基于量子力学的原理,可以比传统计算机更高效地解决某些复杂问题。”
- 回答:
- 生成模型基于输入查询和检索到的文档,生成一个综合的回答:
RAG 的架构
RAG 的架构通常由以下几个部分组成:
-
查询编码器(Query Encoder):
编码输入查询,将其转换为向量表示。 -
检索器(Retriever):
利用查询向量从大型文档库中检索相关文档。 -
文档编码器(Document Encoder):
对检索到的文档进行编码,生成文档向量表示。 -
生成器(Generator):
基于输入查询和检索到的文档向量,生成最终的回答。
实际应用
RAG 在许多实际应用中表现出色,包括:
- 开放域问答系统:回答用户提出的各种问题。
- 对话系统:生成具有上下文意识的对话。
- 文本摘要:生成文档的简明摘要。
- 信息检索:从大型数据库中检索相关信息并生成综合报告。
总结
检索增强生成(RAG)是一种强大的方法,通过结合信息检索和文本生成技术,能够生成高质量的文本回答。它在处理需要丰富背景知识和长尾信息的问题时特别有效。RAG 的应用广泛,涵盖了问答系统、对话生成、文本摘要等领域。
4.温度系数和top-p、top-k参数有什么区别?
在自然语言生成模型(如GPT-3、T5等)的生成过程中,温度系数(Temperature)、top-p和top-k参数都是用于控制生成文本的多样性和质量的重要超参数。它们各自有不同的机制和效果,下面我们详细介绍它们的区别和作用。
温度系数(Temperature)
温度系数是一个控制生成模型输出概率分布“平滑度”的参数。
- 定义:温度系数通常用符号T 表示。
- 范围:通常为正数,常见范围是
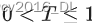 。
。 - 影响:
- 当 T=1时,模型输出的概率分布不变。
- 当 T<1 时,模型输出的概率分布变得“尖锐”,高概率的词更有可能被选择,生成文本更加确定和保守。
- 当 T>1 时,模型输出的概率分布变得更平滑,低概率的词也有更大机会被选择,生成文本更加多样化和随机。
- 公式:通过调整生成时的概率分布 :
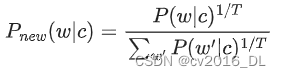
top-k 采样
top-k 采样是一种截断采样方法,通过只考虑概率最高的 个词来生成下一个词。
- 定义:top-k 采样是指在生成下一个词时,只从模型预测的概率最高的 个词中进行选择。
- 范围: k是一个正整数,通常 的取值范围从几到几千不等。
- 影响:
- 当 k 较小时,生成的文本更加保守和确定,因为只考虑了少量高概率词。
- 当 k较大时,生成的文本更加多样化,因为考虑了更多的词。
- 机制:从预测的概率分布中选择前 个最高概率的词,然后在这些词中进行随机采样。
top-p 采样(又称核采样,Nucleus Sampling)
top-p 采样是一种动态截断采样方法,通过选择累积概率超过阈值 的最小词集合来生成下一个词。
- 定义:top-p 采样是指在生成下一个词时,从模型预测的词中选择累积概率超过 的最小词集合进行采样。
- 范围: p 是一个在 0 到 0之间的实数。
- 影响:
- 当 p 较小时,生成的文本更加保守和确定,因为只考虑了少量的高概率词。
- 当 p 较大时,生成的文本更加多样化,因为考虑了更多的词。
- 机制:从预测的概率分布中选择使得累积概率超过 p的最小词集合,然后在这些词中进行随机采样。
这三种参数各有优劣,可以根据具体应用场景和需求进行选择和调节。例如,在需要生成更加多样化和创造性的文本时,可以适当增加温度系数和top-p值;在需要生成更加确定和准确的文本时,可以减小温度系数和top-p值,或者使用较小的top-k值。
5.为什么transformer块使用LayerNorm而不是BatchNorm?
在Transformer架构中,Layer Normalization(LayerNorm)被广泛使用,而不是Batch Normalization(BatchNorm)。主要原因有几个方面,包括计算效率、适用性以及训练过程中的稳定性。下面详细介绍这些原因。
1. 适用性和计算效率
序列建模的特点
-
Batch Normalization:BatchNorm是针对一个批次(batch)内的数据进行归一化。因此,它需要在整个batch上计算均值和方差。对于序列建模任务,批次内的序列长度和位置可能变化多端,导致计算复杂度增加。
-
Layer Normalization:LayerNorm是针对每一个样本的特征维度进行归一化。它不依赖于批次内其他样本的分布。因此,LayerNorm在处理变长序列或在线推理时更加灵活和高效。
2. 训练过程的稳定性
动态变化
-
Batch Normalization:在训练过程中,BatchNorm对每个批次的数据进行归一化,可能导致归一化参数在不同批次之间发生剧烈变化。这在处理序列数据(如自然语言处理任务)时,尤其是在Transformer中,可能导致训练过程不稳定。
-
Layer Normalization:LayerNorm对每个样本的特征进行归一化,不依赖于批次内的其他样本。因此,LayerNorm的归一化参数在训练过程中更加稳定,适合处理动态变化的输入数据。
3. 并行计算和依赖性
批次依赖性
-
Batch Normalization:由于BatchNorm依赖于整个批次的数据分布,它在计算时需要等待整个批次的数据可用。这在分布式计算或GPU加速时可能成为瓶颈,因为需要同步批次数据。
-
Layer Normalization:LayerNorm对每个样本独立进行归一化,可以在样本级别并行处理,减少了批次依赖性,提高了计算效率。
4. 序列依赖性和自注意力机制
自注意力机制
-
Batch Normalization:在自注意力机制中,每个位置的输出依赖于整个序列的其他位置。BatchNorm在这种情况下可能会引入额外的复杂性,因为它需要在整个批次内的不同位置进行归一化。
-
Layer Normalization:LayerNorm直接在每个位置的特征维度上进行归一化,不受序列长度和批次分布的影响,更加适合自注意力机制。
6.介绍一下post layer norm和pre layer norm的区别?
在Transformer模型中,Layer Normalization(LayerNorm)可以应用在不同的位置,主要有两种常见的方式:Post-LayerNorm 和 Pre-LayerNorm。它们在模型中的位置不同,对模型的训练稳定性和性能有不同的影响。下面详细介绍这两种方法及其区别。
Post-LayerNorm
Post-LayerNorm是最早在原始Transformer论文中使用的方法。它将LayerNorm应用在残差连接(Residual Connection)之后。
结构
- 残差连接前的子层输出(例如,自注意力层或前馈网络层)
- 加上残差连接(输入直接加上子层输出)
- 应用LayerNorm
公式表示:
![]()
优点
- 直观性:残差连接后的LayerNorm使得每一层的输出更为平滑和归一化,直观上容易理解。
缺点
- 训练不稳定:在深层Transformer中,由于LayerNorm放在残差连接之后,可能会导致梯度消失或爆炸问题,影响训练稳定性。
Pre-LayerNorm
Pre-LayerNorm是将LayerNorm应用在残差连接之前的方法。近年来,这种方法被证明在许多情况下可以提高训练稳定性和模型性能。
结构
- 应用LayerNorm(在残差连接之前)
- 残差连接前的子层输出(例如,自注意力层或前馈网络层)
- 加上残差连接(输入直接加上子层输出)
公式表示:
![]()
优点
- 训练稳定性更好:由于LayerNorm在残差连接之前应用,可以在梯度传播时保持更稳定的梯度,减少梯度消失或爆炸现象。
- 更深层次的模型:Pre-LayerNorm使得训练更深层次的Transformer模型成为可能,进一步提高模型性能。
缺点
- 输出分布变化:残差连接后的输出没有经过归一化,可能导致输出分布变化较大。
7.RAG和微调的区别是什么?
检索增强生成(Retrieval-Augmented Generation, RAG)和微调(Fine-Tuning)都是提高大型语言模型性能的有效方法,但它们有着不同的机制和应用场景。下面详细介绍它们的区别。
RAG(Retrieval-Augmented Generation)
概念
RAG 是一种将检索模型和生成模型结合起来的方法。它通过从外部知识库或文档库中检索相关信息,然后利用生成模型基于这些信息生成回答或文本。
工作流程
- 检索阶段:给定一个输入查询,使用检索模型(如BM25、双编码器等)从大型文档库中检索出相关文档。
- 生成阶段:将检索到的文档作为上下文输入到生成模型(如GPT-3、T5等),生成最终的文本或回答。
优点
- 丰富的背景知识:通过检索外部文档,生成模型可以参考更多的信息源,从而生成更为详实和准确的文本。
- 动态信息更新:可以实时检索最新的信息,适应动态变化的知识需求。
- 处理长尾问题:对于罕见或长尾问题,RAG 可以通过检索提供必要的背景信息,提高生成质量。
缺点
- 复杂性增加:需要维护一个高效的检索系统,并处理检索和生成的结合。
- 时延:检索过程增加了生成时间,可能导致延迟。
微调(Fine-Tuning)
概念
微调是一种通过在特定任务或特定数据集上进一步训练预训练模型的方法。通过在目标任务的数据上进行额外训练,模型可以更好地适应特定任务的需求。
工作流程
- 预训练:首先,模型在大规模通用数据集上进行预训练,以学习通用的语言表示。
- 微调:然后,在特定任务的数据集上进一步训练模型,使其在该任务上表现更好。
优点
- 任务适应性强:通过微调,模型可以很好地适应特定任务,提高在该任务上的性能。
- 简单直接:只需要在目标任务的数据集上进一步训练模型,无需复杂的检索系统。
缺点
- 数据依赖性强:微调需要大量与目标任务相关的数据,数据不足时效果有限。
- 更新不灵活:微调后的模型固定了知识,无法动态获取最新信息。如果需要更新知识,可能需要重新微调模型。
对比与总结
| 特性 | RAG | 微调 |
|---|---|---|
| 机制 | 检索相关文档并基于文档生成回答 | 在特定任务数据集上进一步训练模型 |
| 优点 | 丰富背景知识,动态信息更新 | 任务适应性强,简单直接 |
| 缺点 | 复杂性增加,时延 | 数据依赖性强,更新不灵活 |
| 适用场景 | 需要丰富背景知识和动态信息 | 任务明确且有足够数据支持的场景 |
| 训练需求 | 需要维护检索系统和生成模型 | 需要大量相关数据进行训练 |
选择依据
- 需要动态信息更新:如果你的应用场景需要频繁获取最新信息或背景知识,RAG 是一个更好的选择。
- 任务数据充足:如果你有大量与目标任务相关的数据,并且任务相对固定,微调模型能够提供更高的性能。
- 复杂度和资源:RAG 需要更多的资源来维护检索系统,而微调相对简单,但需要更多特定数据。
8. 讲一下GPT系列模型的是如何演进的?
GPT(Generative Pre-trained Transformer)系列模型是由OpenAI开发的一系列大规模自然语言处理模型。这些模型基于Transformer架构,通过在大规模文本数据集上进行无监督预训练,然后在特定任务上进行微调,取得了显著的效果。以下是GPT系列模型的演进过程及其主要特点。
GPT-1(2018年)
- 发布:2018年6月
- 论文:Improving Language Understanding by Generative Pre-Training
- 架构:基于Transformer的解码器部分,包含12层Transformer块。
- 参数:1.1亿个参数。
- 训练数据:BooksCorpus数据集,包含约7,000本书。
- 特点:
- 预训练:在大规模文本数据上进行无监督预训练,学习语言模型。
- 微调:在特定任务的数据集上进行监督微调,适应具体任务需求。
- 创新点:展示了通过预训练生成模型,然后进行微调,可以在多种自然语言处理任务上取得良好效果。
GPT-2(2019年)
- 发布:2019年2月
- 论文:Language Models are Unsupervised Multitask Learners
- 架构:延续GPT-1的架构,扩大了模型规模,包括48层Transformer块(最大版本)。
- 参数:有四个版本,分别为117M、345M、762M和1.5B(15亿)参数。
- 训练数据:WebText数据集,包含约800万个网页。
- 特点:
- 更大模型:显著增加了模型参数量,提高了生成文本的能力。
- 开放域生成:展示了在开放域文本生成任务中的强大能力,能够生成连贯且有意义的长文本。
- 多任务学习:模型在预训练过程中学习了多任务能力,无需微调即可在多种任务上表现出色。
- 伦理考量:由于模型生成高质量文本的能力,OpenAI最初选择逐步发布模型,以评估其潜在风险。
GPT-3(2020年)
- 发布:2020年6月
- 论文:Language Models are Few-Shot Learners
- 架构:进一步扩大了模型规模,包括96层Transformer块(最大版本)。
- 参数:有多个版本,最大版本包含1750亿参数。
- 训练数据:多种数据集,包括Common Crawl、WebText、BooksCorpus和Wikipedia等。
- 特点:
- 超大规模:1750亿参数使得GPT-3成为当时最大的语言模型,极大地提升了生成能力和理解能力。
- 少样本学习:展示了强大的Few-Shot、One-Shot和Zero-Shot学习能力,在无需大规模微调的情况下,能够通过提供少量示例进行任务。
- 广泛应用:在文本生成、翻译、问答、总结等任务上表现优异,被广泛应用于各种自然语言处理任务。
GPT-4(预期中的演进)
虽然截至目前(2024年),GPT-4尚未正式发布,但可以预期其在以下方面可能的改进:
- 更大规模:进一步增加模型参数量,可能达到数千亿甚至上万亿参数。
- 多模态:结合文本、图像等多种模态数据,增强模型的多模态理解和生成能力。
- 更强的推理能力:在逻辑推理、常识理解等方面进一步提升。
- 更好的控制和安全性:增强模型的可控性,减少偏见和有害内容生成,提升使用安全性。
主要进展和影响
- 规模提升:随着每一代模型的推出,参数量显著增加,模型能力不断提升。
- 应用广泛:GPT系列模型被应用于各种自然语言处理任务,包括文本生成、翻译、问答、对话系统等。
- 技术创新:展示了预训练-微调范式的巨大潜力,推动了自然语言处理领域的发展。
- 伦理和安全:由于模型生成高质量文本的能力,引发了对其潜在滥用和伦理问题的关注,推动了对AI伦理和安全的研究。

