
- 1NLTK报错_import nltk nltk.download('stopwords') nltk.downlo
- 2《RabbitMQ》如何保证消息不被重复消费_rabbitmq集群保证消息消费一次
- 3Android应用接入支付宝,Android接入支付宝支付指南_安卓接入支付宝支付
- 439岁阿里P9Java架构师失业了,总资产1.5亿..._架构师会失业吗
- 5【uni-app】uni-app 两种提示框示例_uni-ui 警告提示
- 6Vue3.0环境搭建之npm的安装_npm 安装vue3
- 7Java之集合(最全集合相关知识)_java集合知识点总结
- 8数字音频接口之I2S总线协议详解_i2s接口
- 9Vue3 - Element Plus 表格组件 table 隐藏鼠标移入时 hover 高亮背景色,el-table 组件去除鼠标悬停在表格行的 hover 高亮效果(完美解决表格合并后导致行错位)_element plus取消鼠标悬停高亮
- 10stm32f407与陶晶驰串口屏的简易通信 / 串口收发(hal库)_串口屏通信
搭建PySpark大数据分析环境_pyspark环境搭建
赞
踩
担心自己遗忘,便做此纪录。
普通的数据分析其实仅仅在PyCharm环境即可做相应的分析。但是如果数据较大,还是要在集群环境里跑会快一些,一下又两种方案:
针对数据量不大(不是几十上百个G或者百万条级数据)的情况,为了方便可采用方案一:
下图为需要使用到的文件:

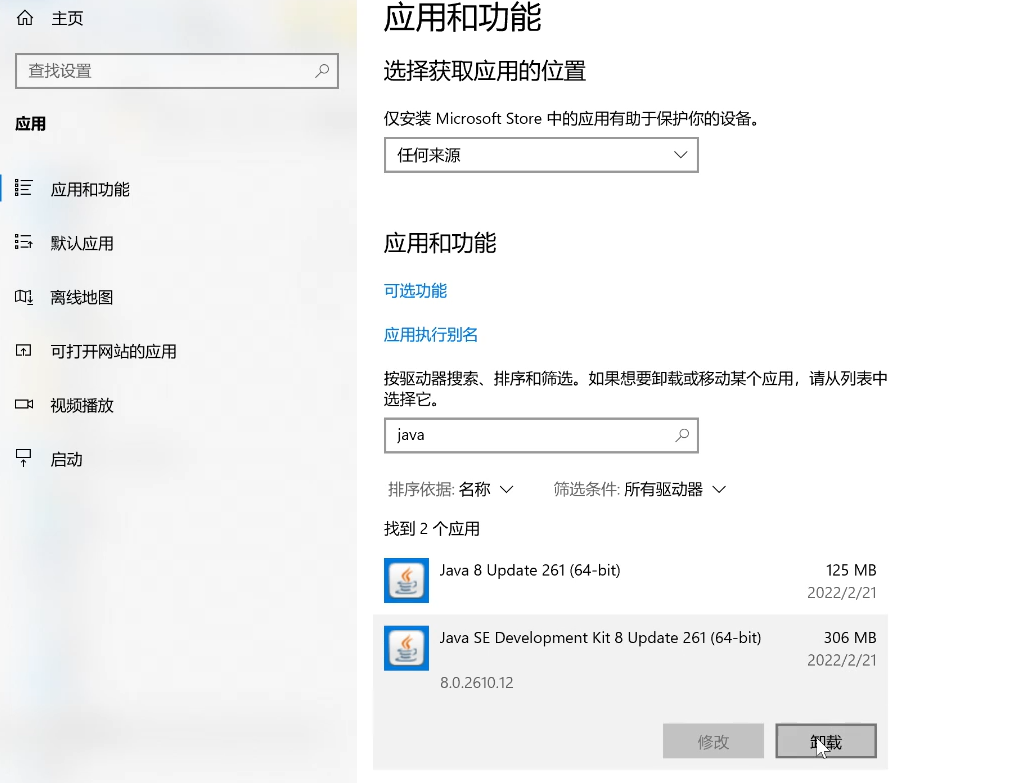
第一步,安装JDK(如果不确定自己的电脑之前是否装过jdk,可以前往设置——应用——应用和功能——搜索java即可查看是否有jdk,后面的查看自己的python也是一样,搜索python即可),再次我安装的是jdk8,当然也可以使用其他版本,但是如果比较佛系想小小偷个懒,那么也可以直接和我的环境的文件版本完全一样即可。双击jdk文件以安装jdk,一直点击下一步即可完成安装。
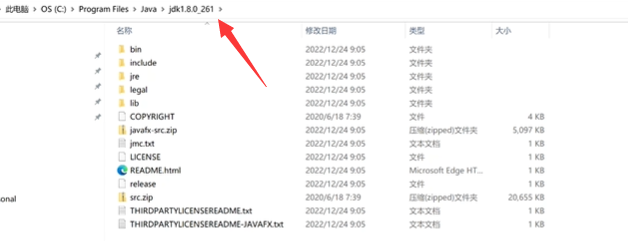
进入jdk的安装位置可以看到以下文件夹:(也有可能只有上面那一个):

进入jdk 1.8.0_261文件夹,复制路径
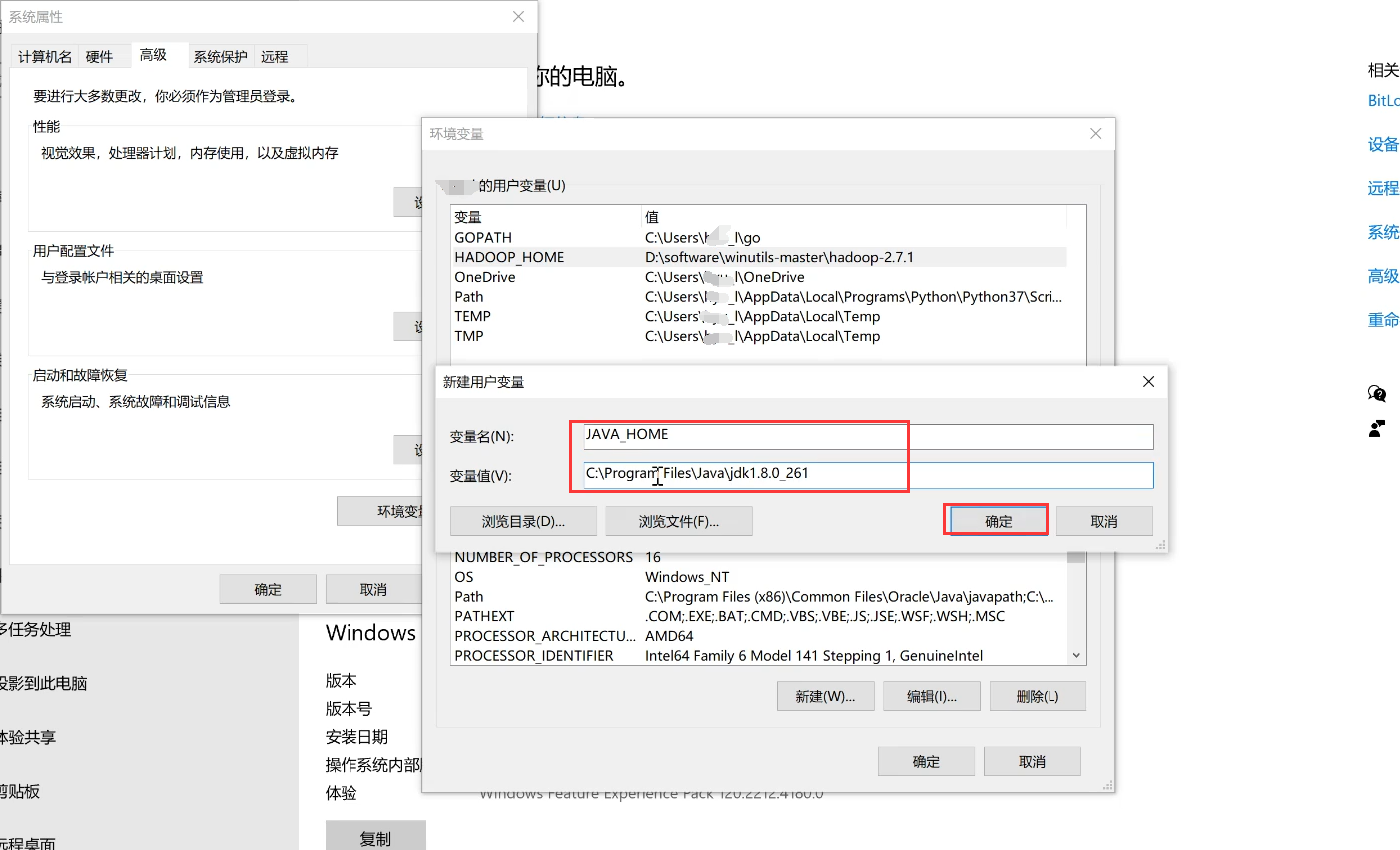
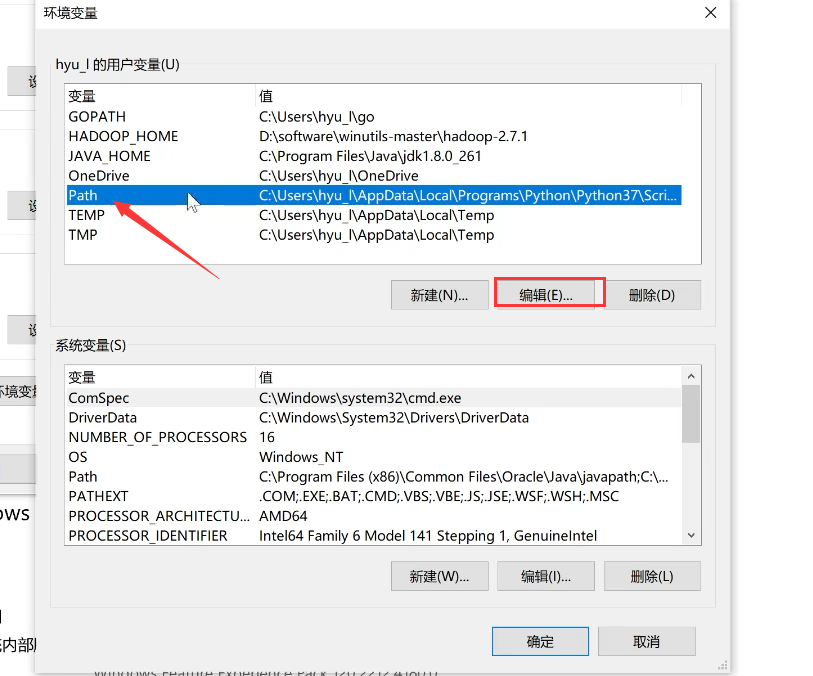
进入系统环境变量的设置,新增用户变量,变量名为JAVA_HOME,变量值为刚刚你复制的JDK的文件的路径,点击确定。
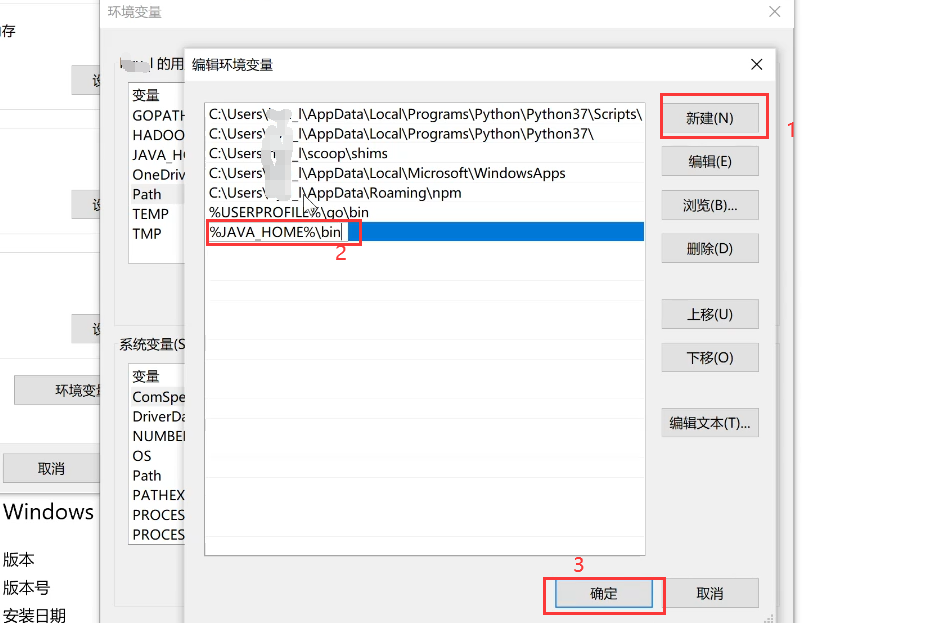
然后找到自己的变量名为Path的变量,选中并点击编辑——新建,输入%JAVA_HOME%\bin,确定即可。
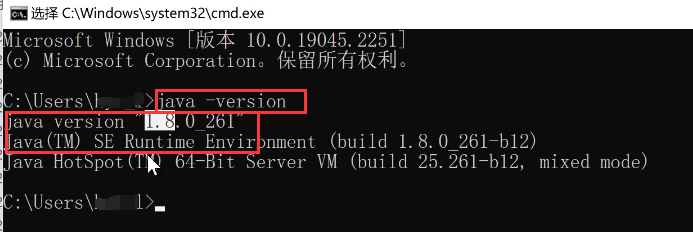
打开命令行,输入‘java -version’,回车,如果出现版本号即说明安装成功。
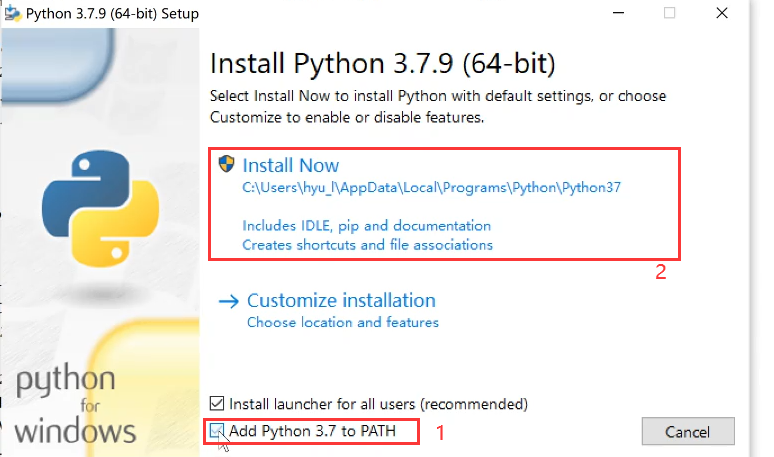
第二步,安装Python,双击python文件以安装,然后如下无脑安装(也可以自定义安装):
根据提示安装完成后进入命令行输入‘python’,如果显示版本号就说明安装成功。
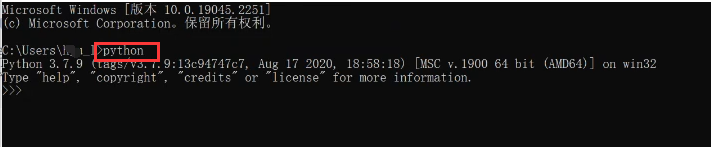
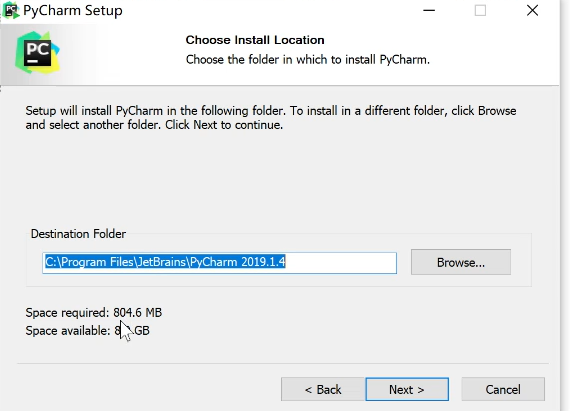
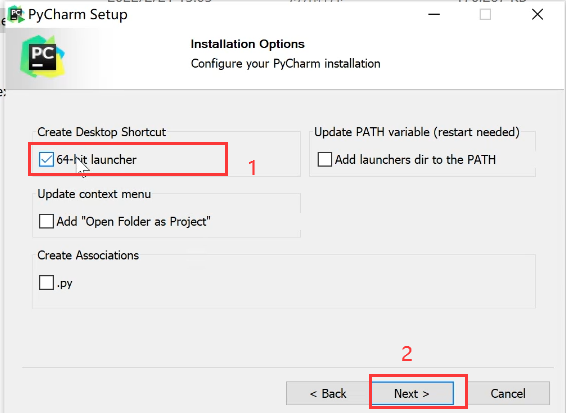
第三步,安装PyCharm.双击Pycharm文件以安装,详情看图,最后一直next即可完成安装()
安装完成后,打开Pycharm,

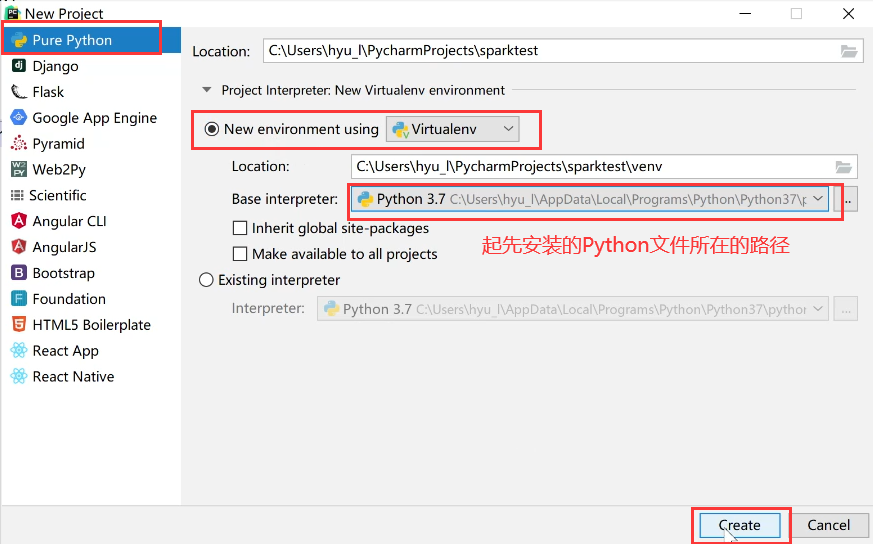
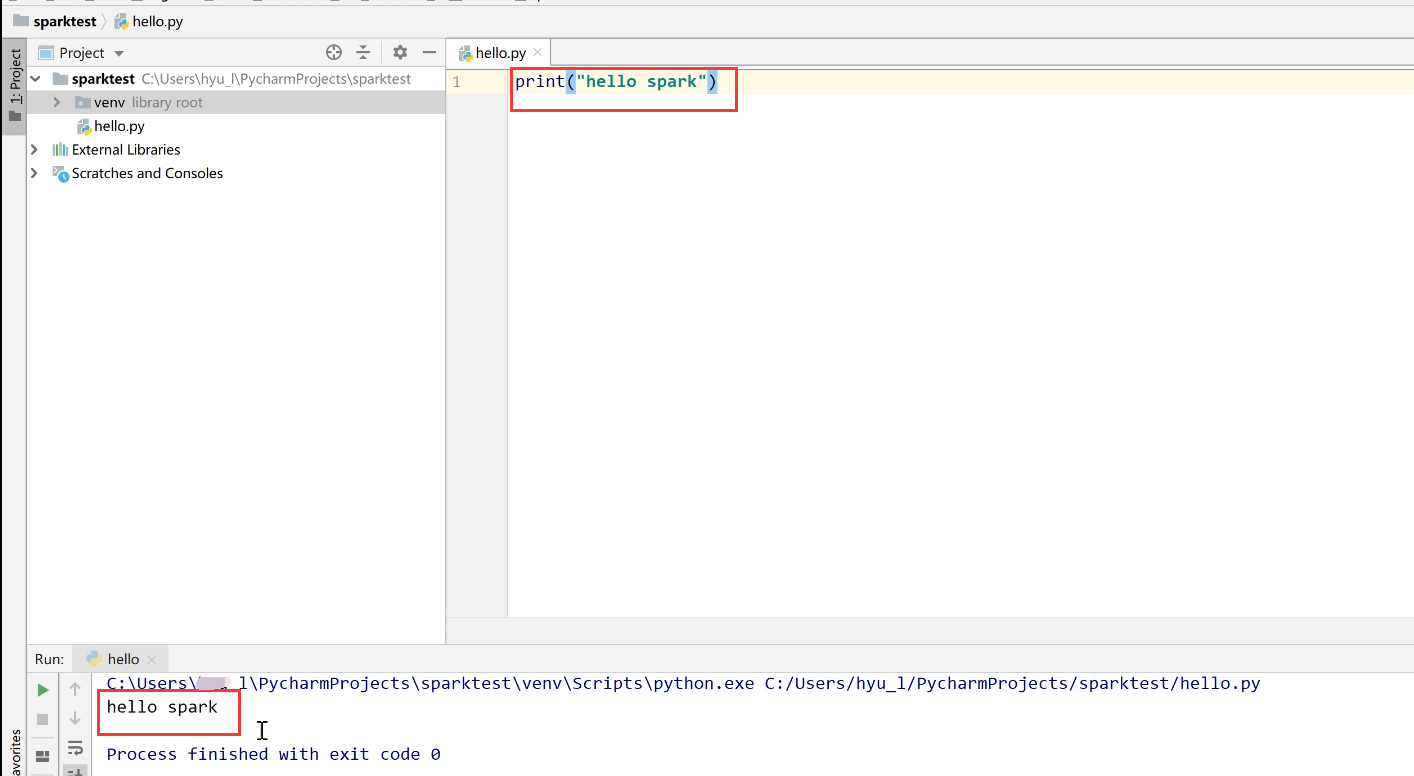
输入样例观察能否成功运行:
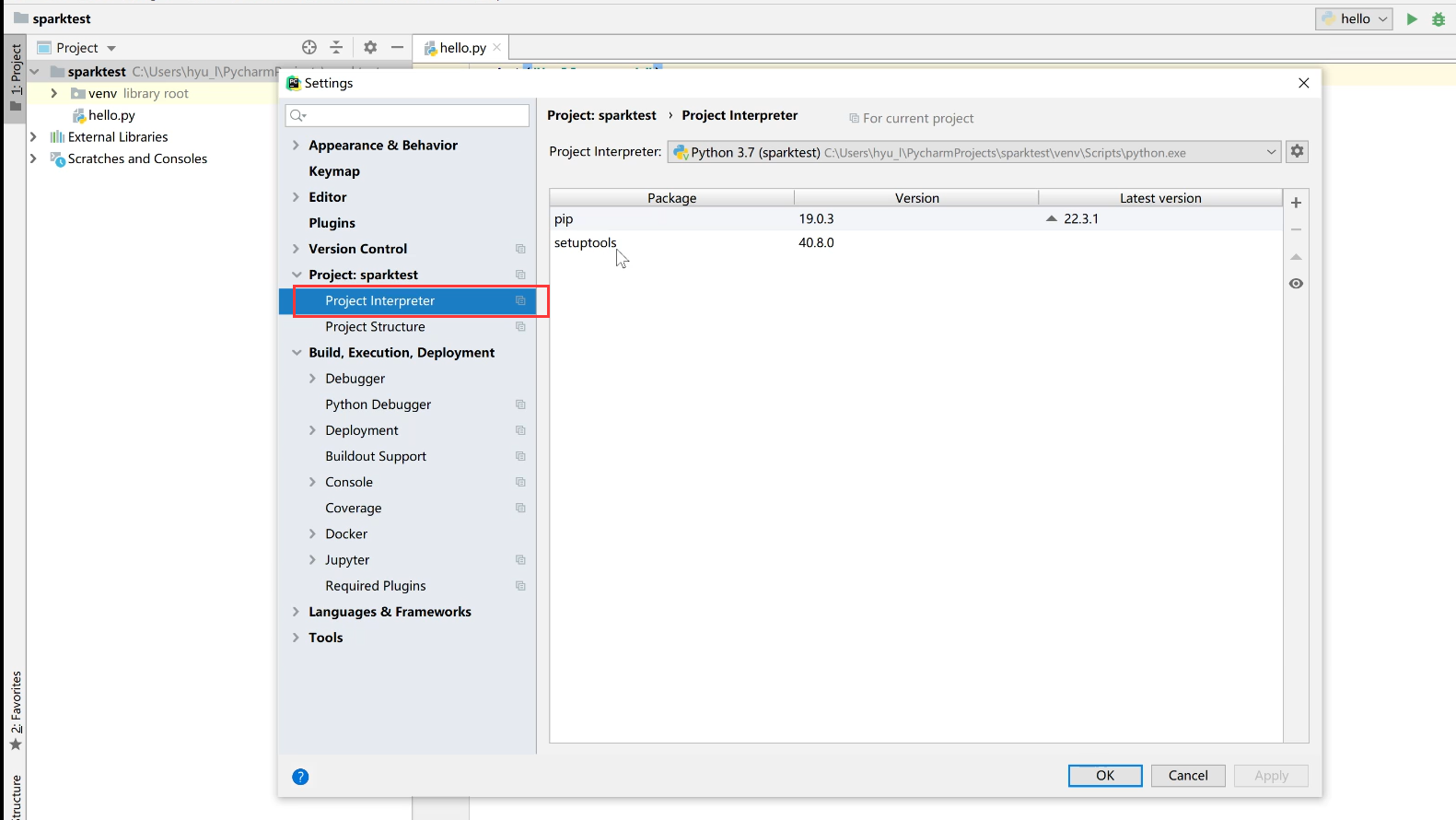
点击File—settings然后到如下位置:
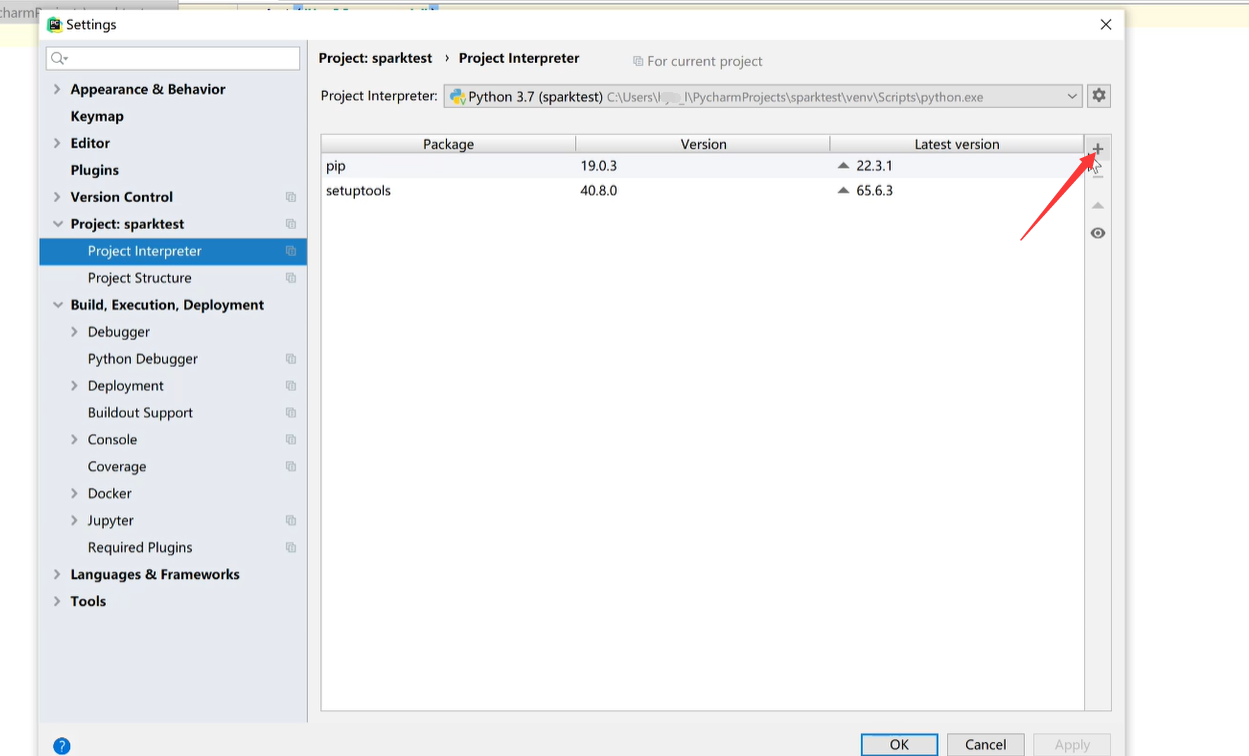
点击加号:
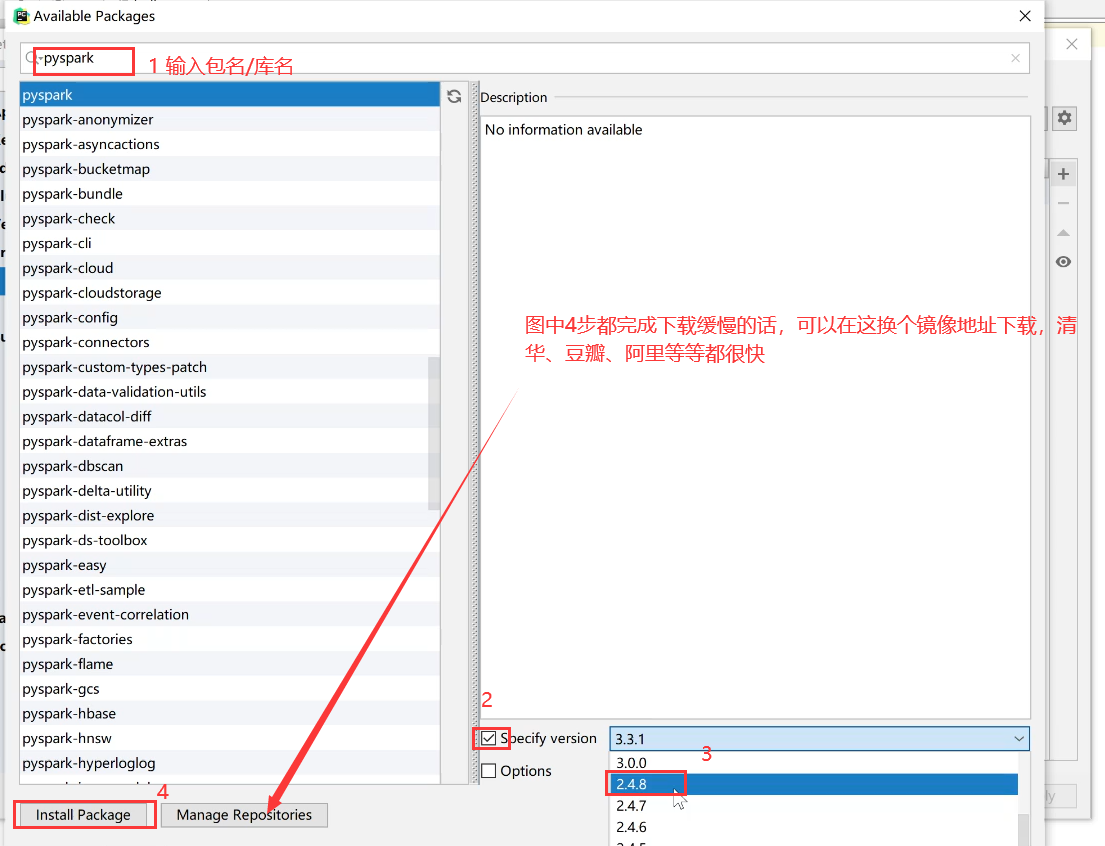
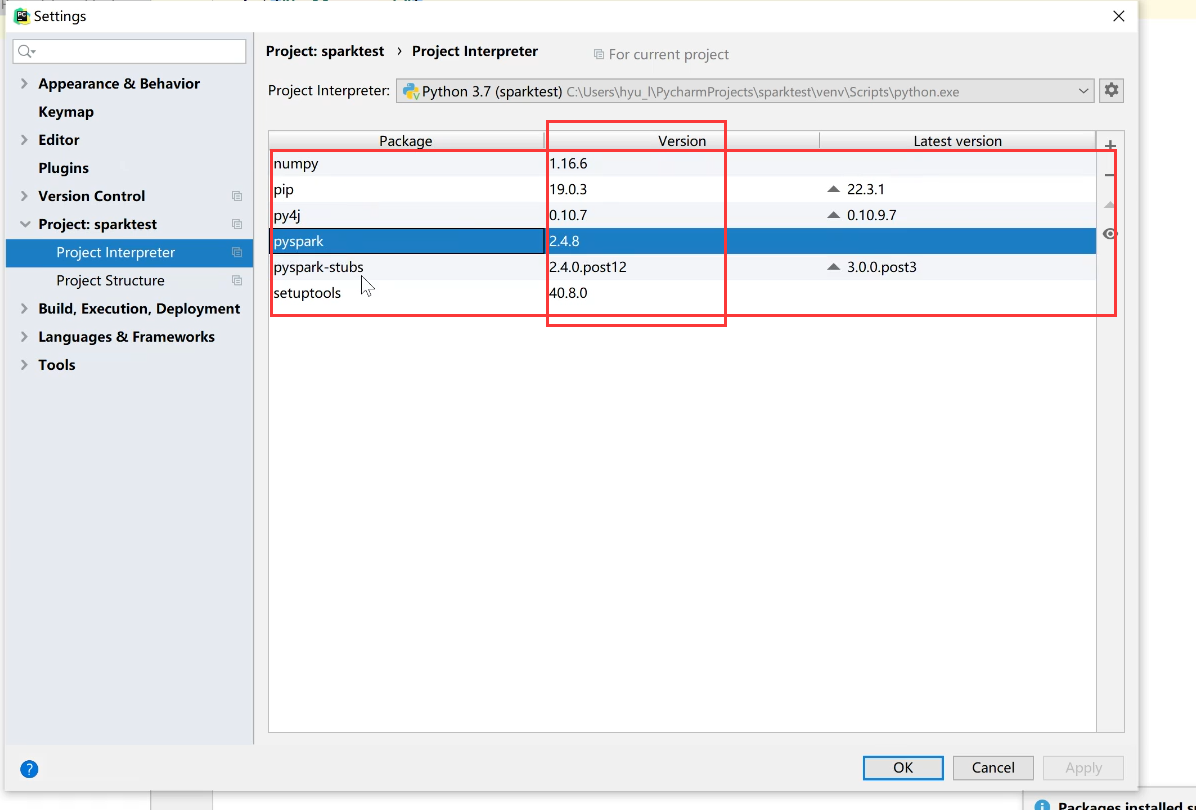
搜索Pyspark,按下图操作:
同理对应讲下图的所有文件下载好(尽量保持和我的版本一致,避免出错自己难以处理):
创建python文件测试:
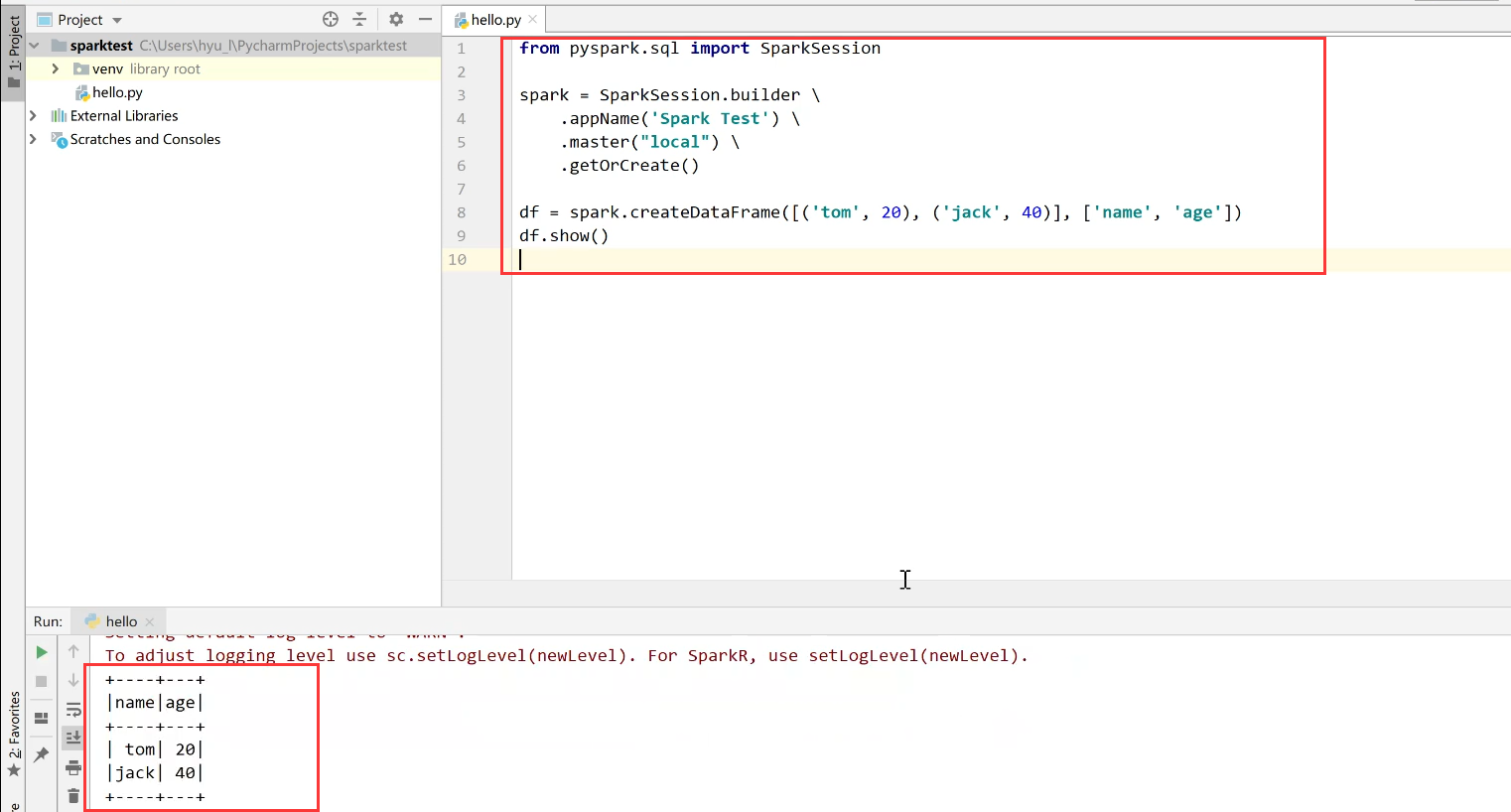
如果可以正常运行,就完成第一个方法的环境的搭建啦!接下来自己导入数据即可进行分析处理。
方案二:
第一步,安装Virtualbox(国产、开源,关键是免费)
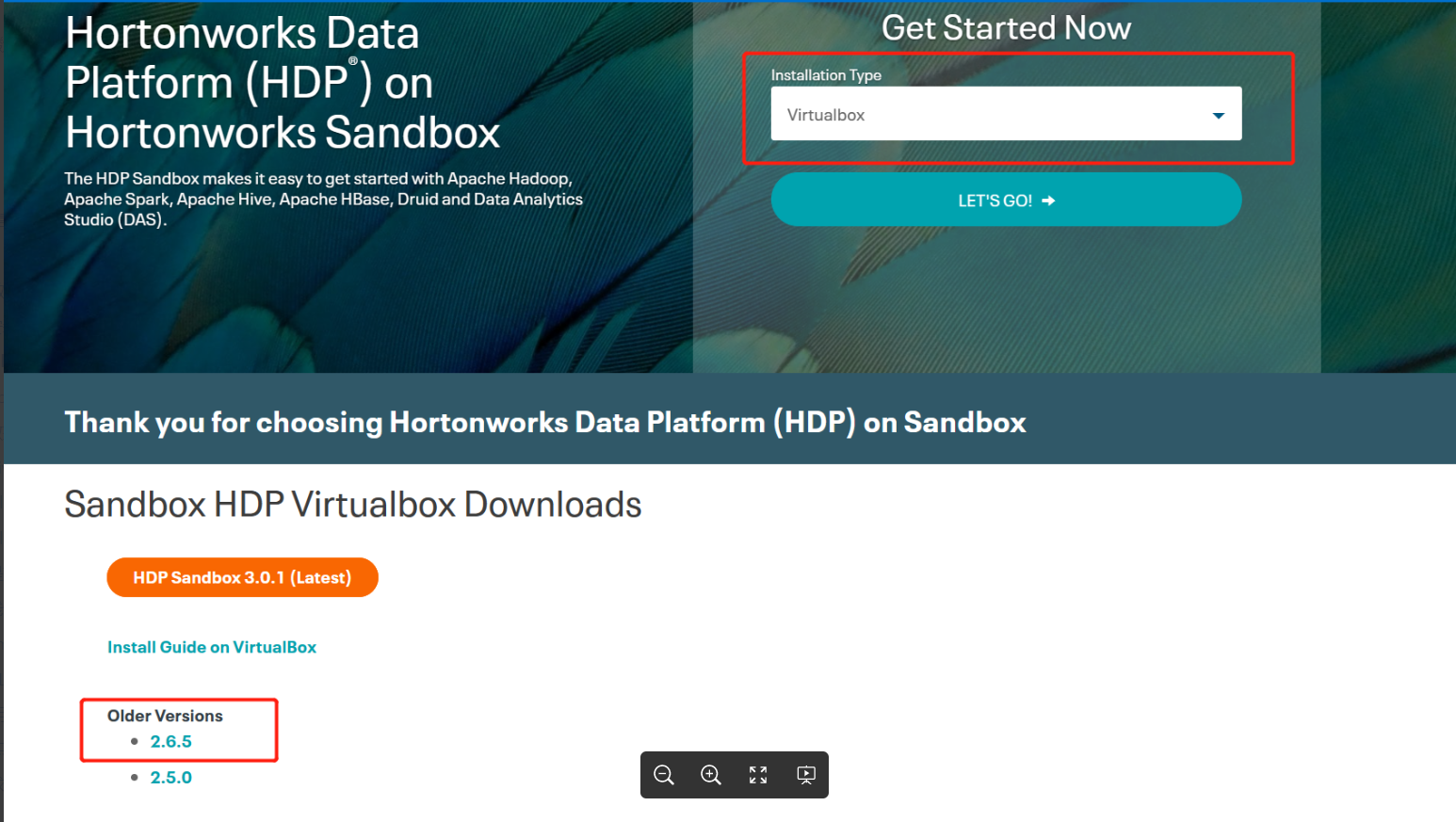
第二步,下载虚拟机镜像:
https://archive.cloudera.com/hwx-sandbox/hdp/hdp-2.6.5/HDP_2.6.5_virtualbox_180626.ova
打开VirtualBox,导入虚拟机镜像:
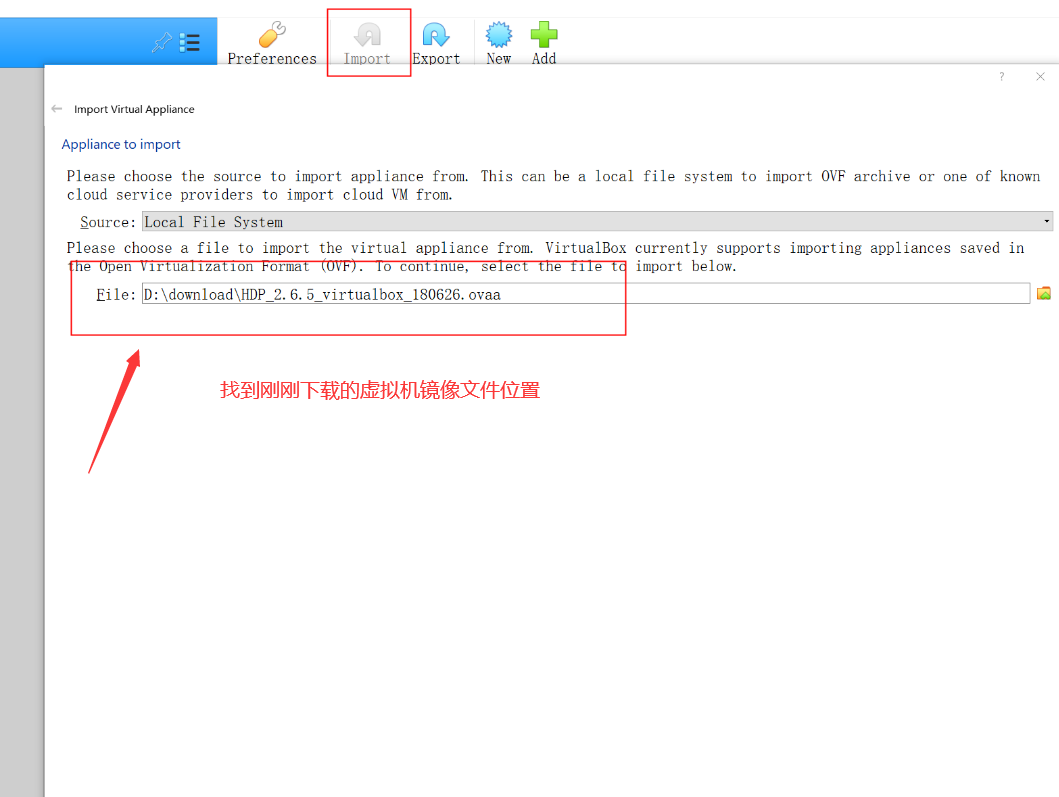
注意内存大小及导入路径,必须保证磁盘有充足的剩余空间
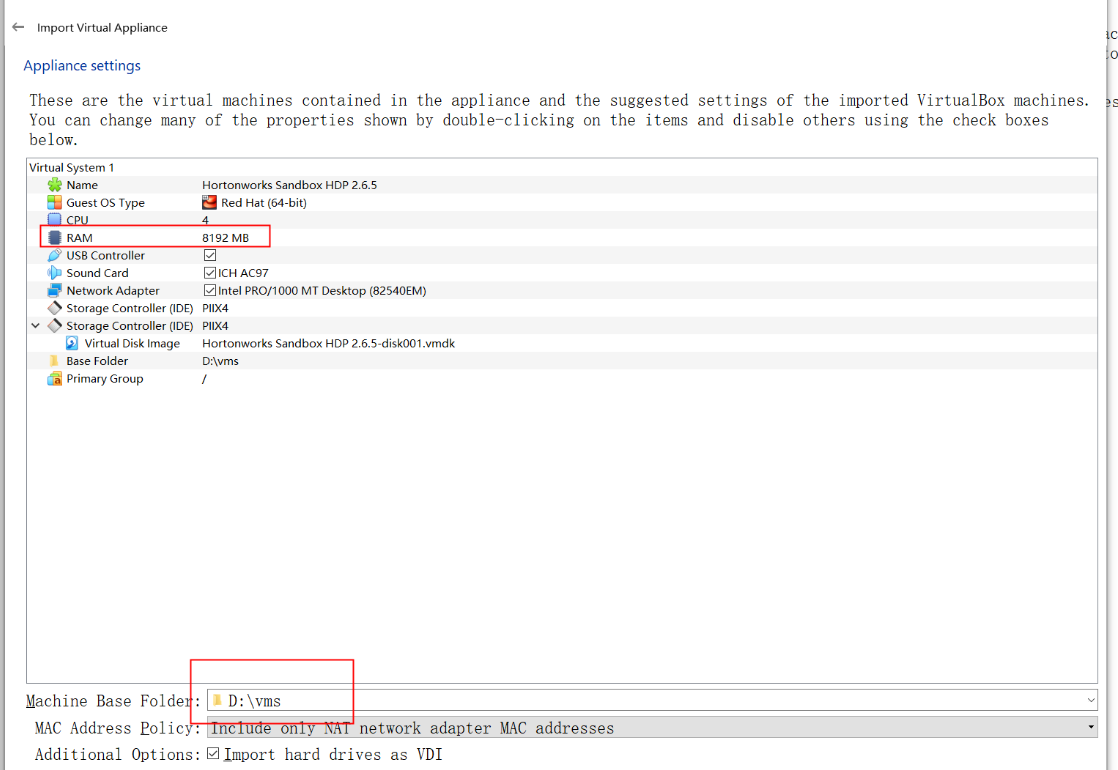
等待导入完成:
启动虚拟机:
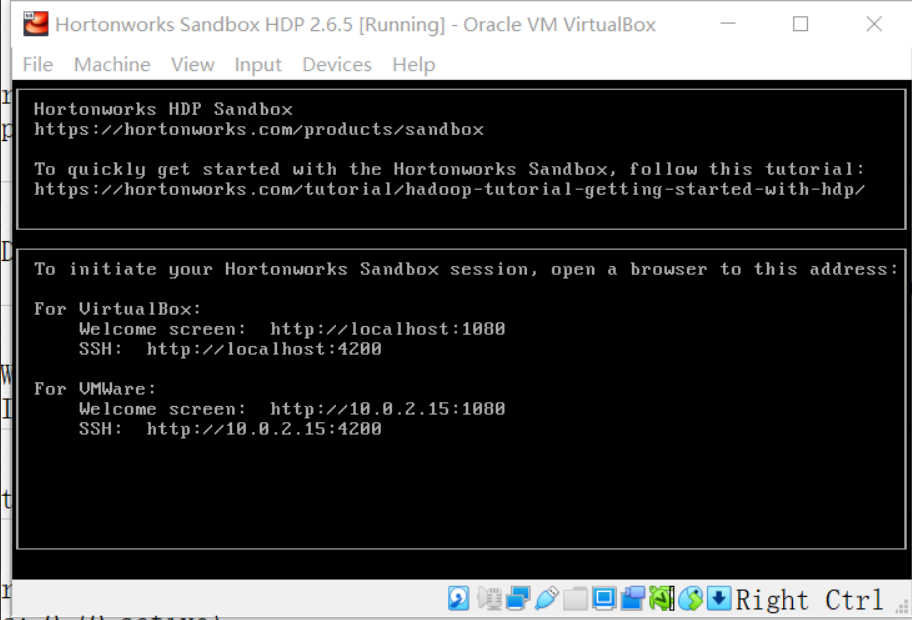
启动完成

安装Xshell和Xftp。
打开Xshell,点击新建:
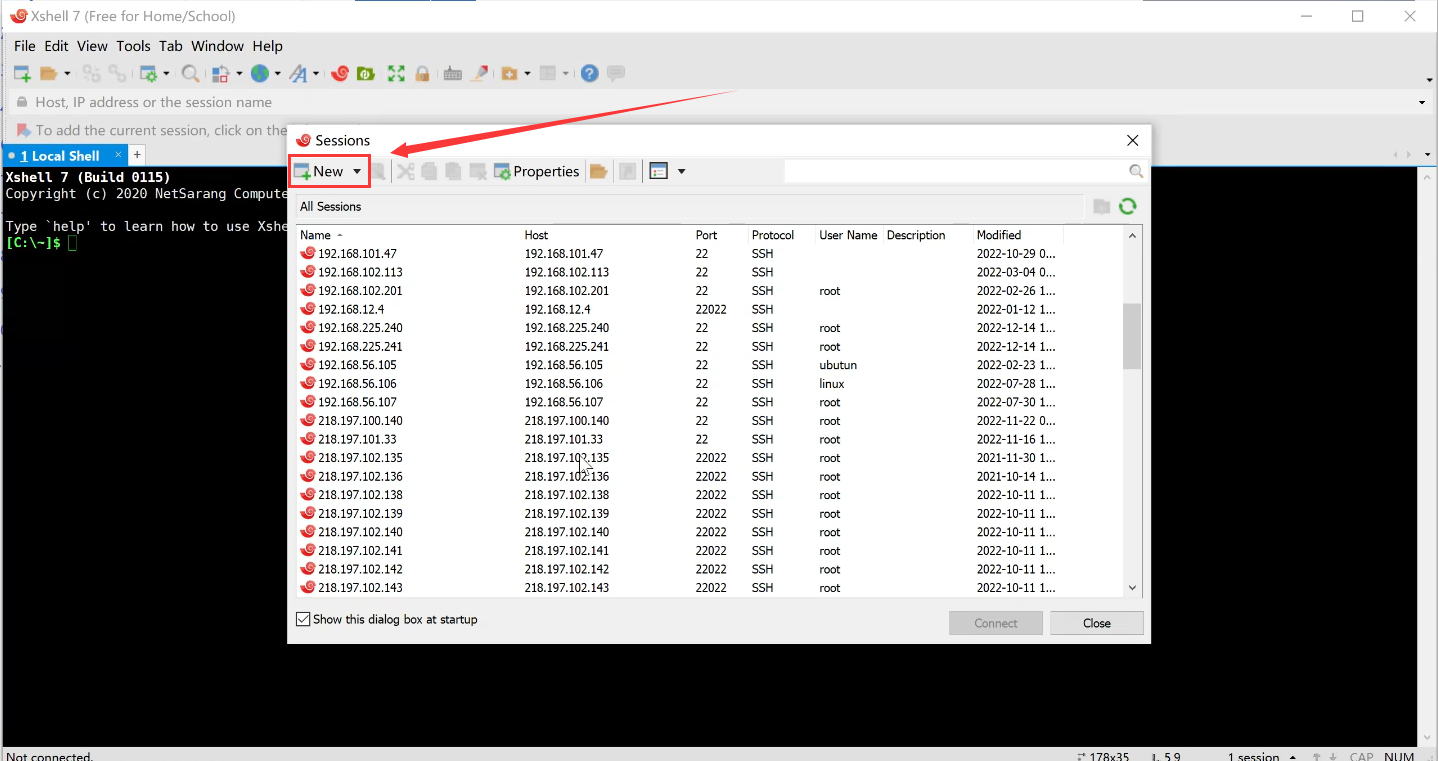
输入下列参数,准备上传文件:
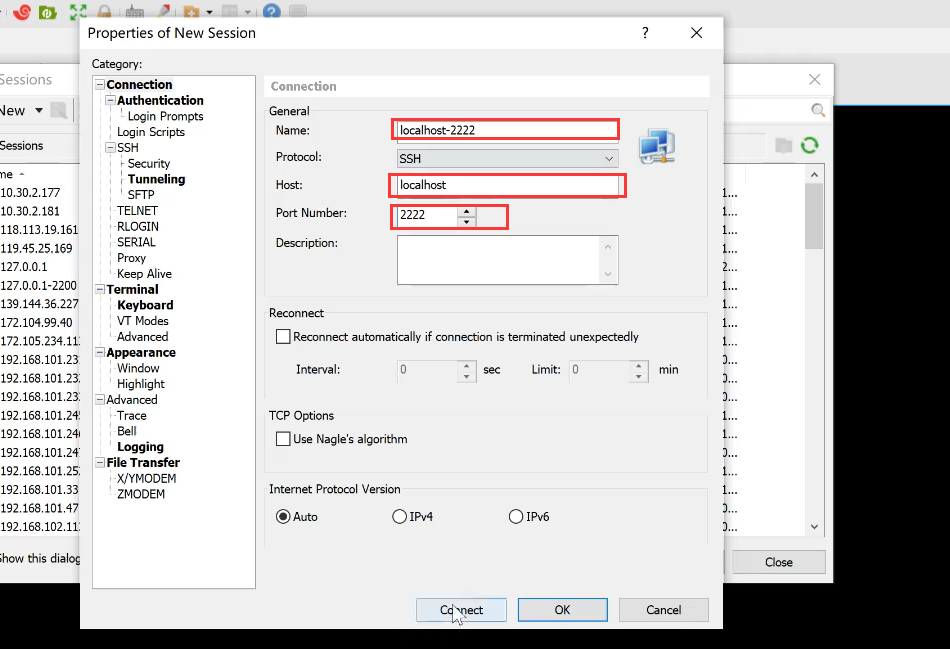
输入用户名:root
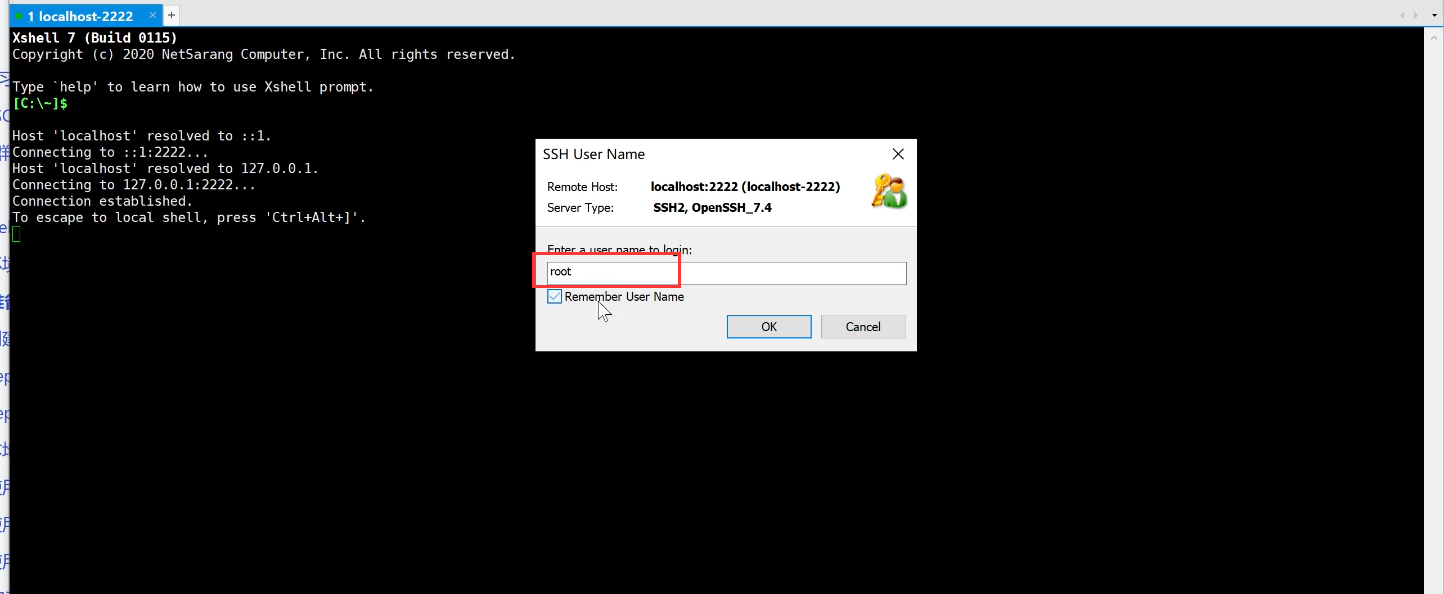
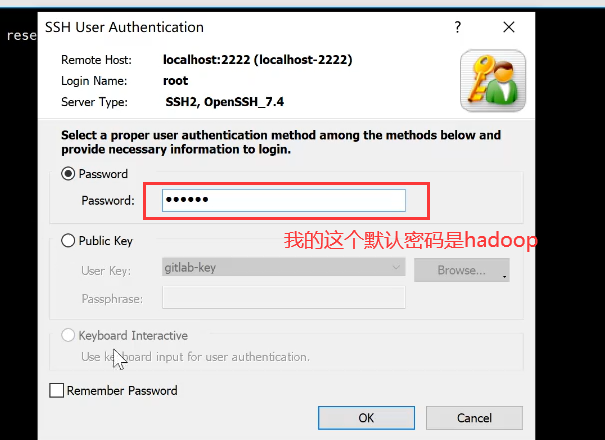
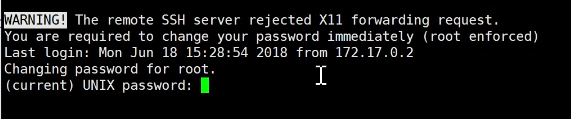
第一次登录需要更改密码,但是需要先输入当前密码,然后输入新密码,确认密码,最后即可使用:
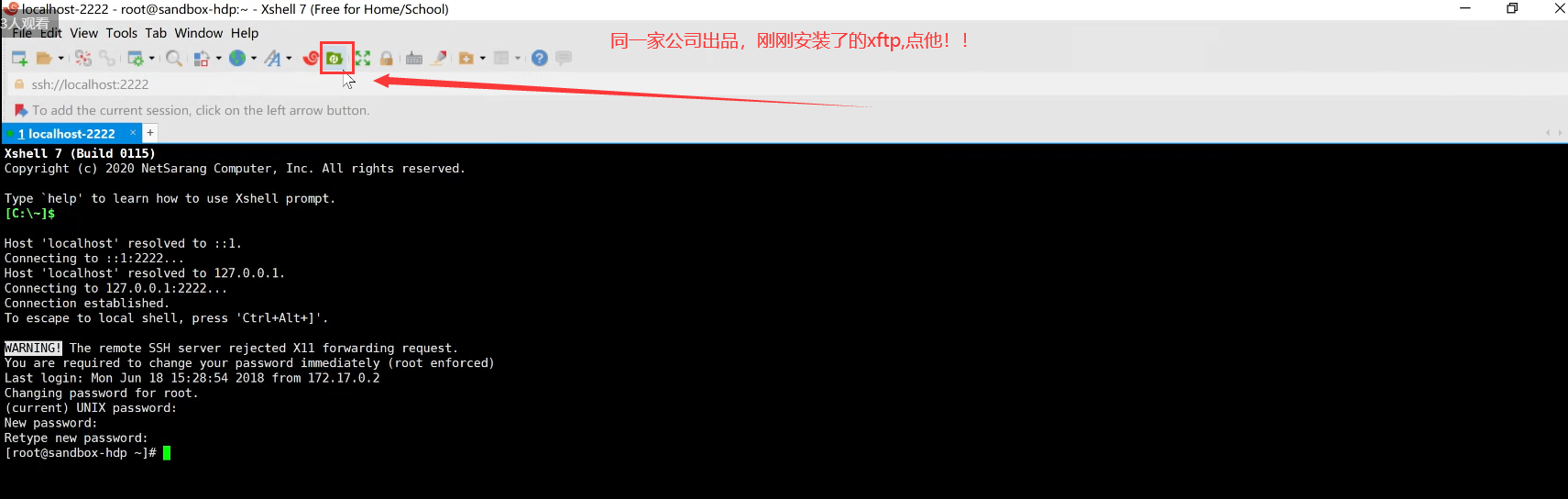
点击图中的Xftp按钮:
打开Xftp后,输入起先新设置的密码,进入到远程Linux服务器:
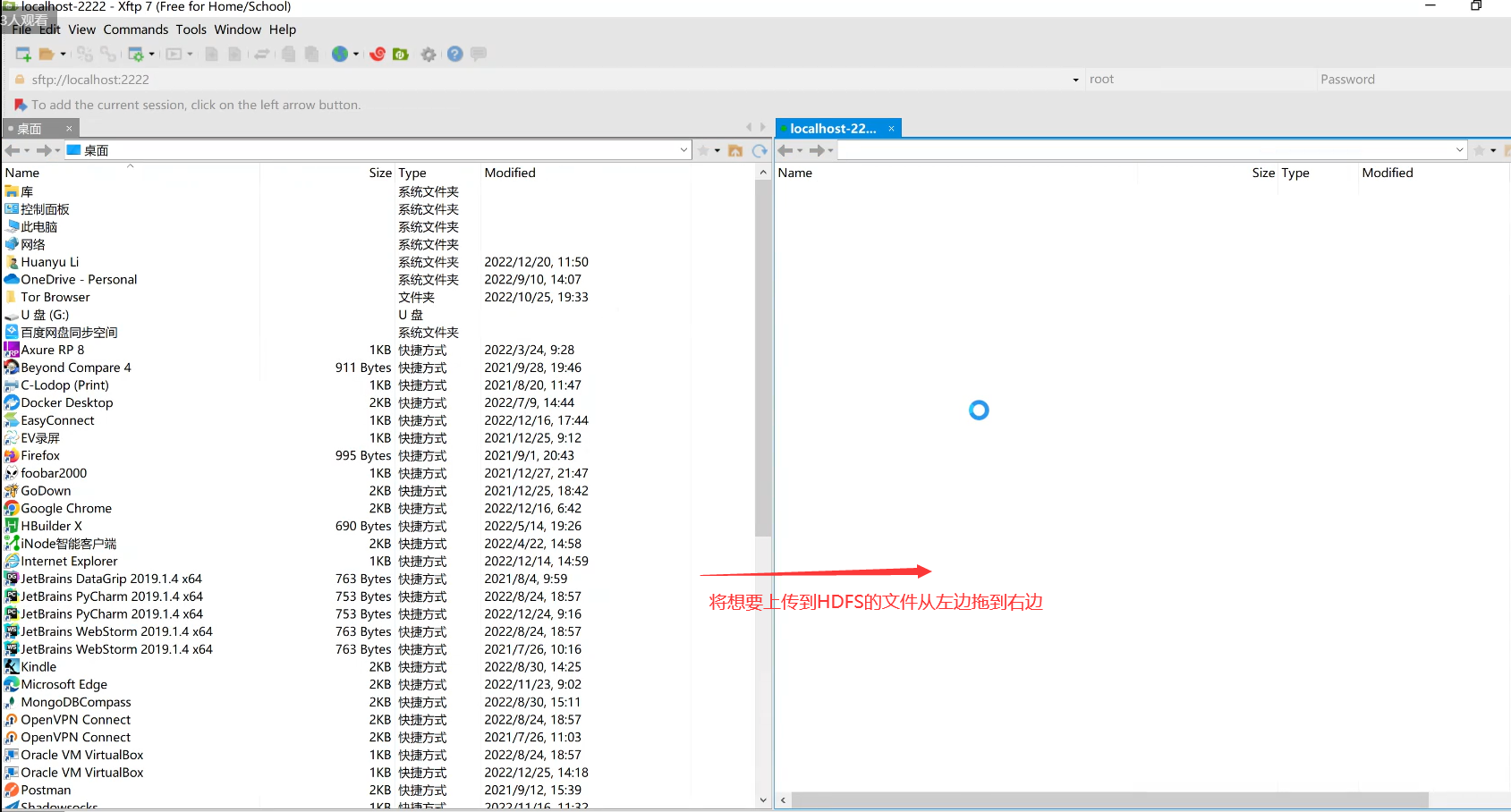
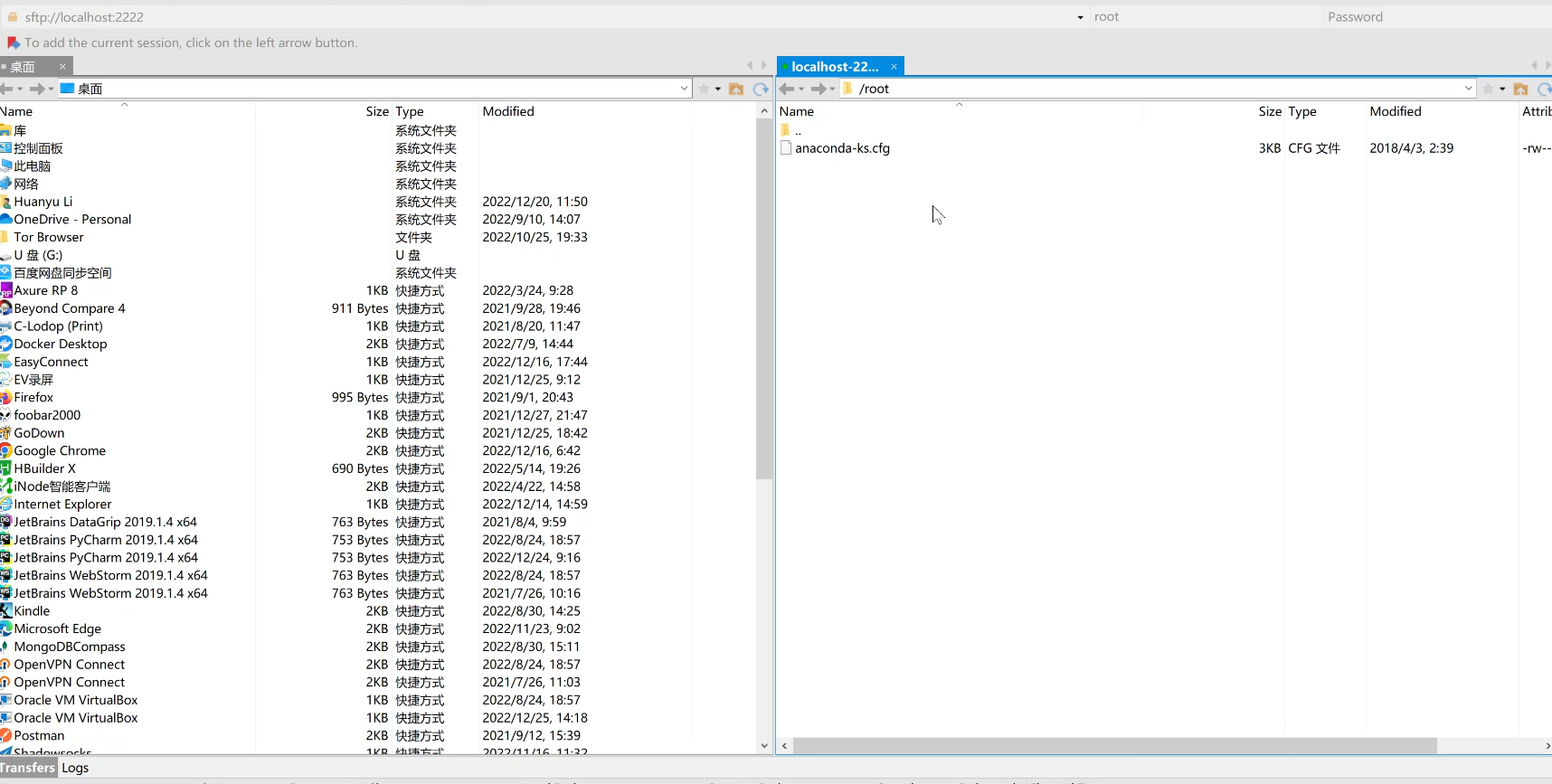
将文件拖放进去后,就会看到上传进度:

等待上传完成后回到Xshell:
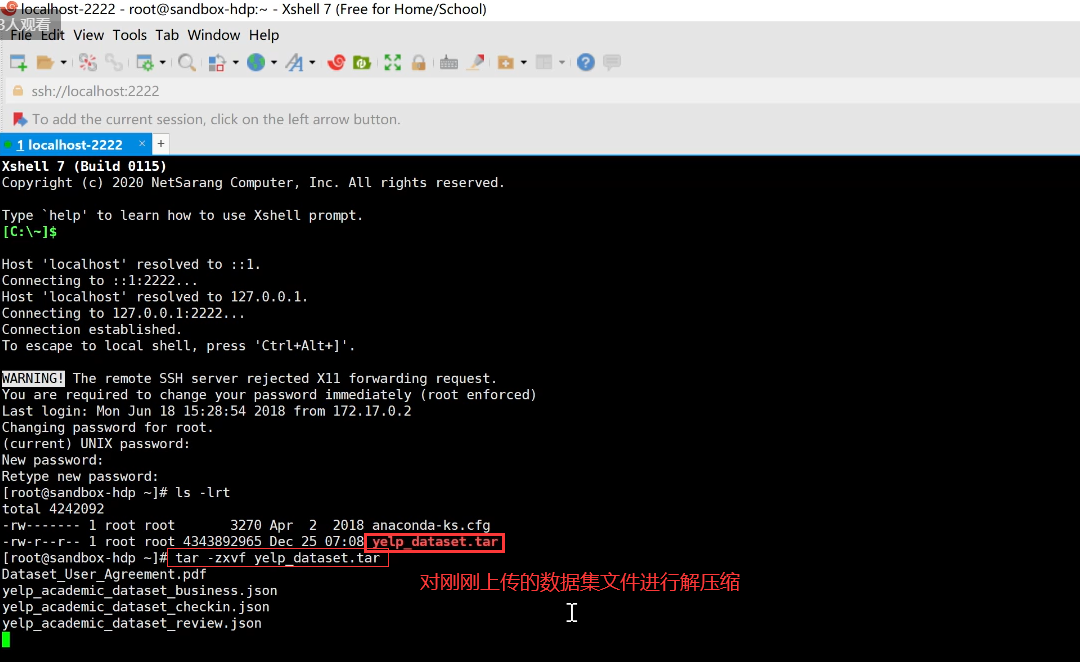
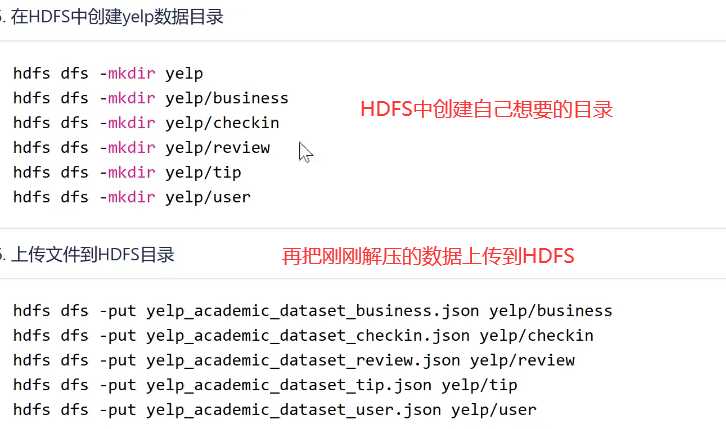
创建文件夹,上传自己的文件到HDFS中:
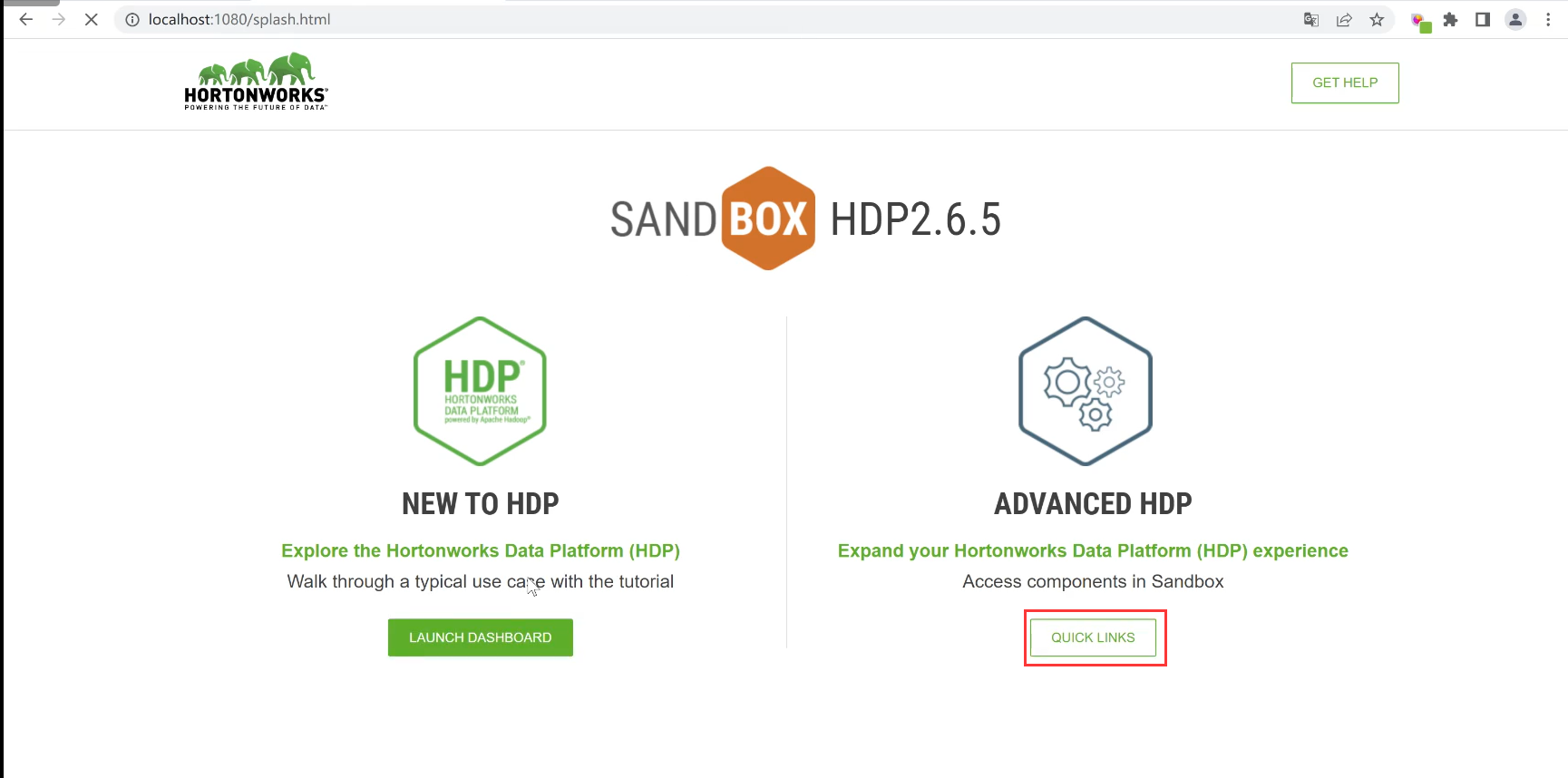
这样就可以在http://localhost:1080/里面进入并找到HDFS相应的文件夹并查询自己刚刚上传的文件是否成功。
这样,后续就可以开始对数据进行处理了:

至此方案二环境搭建完成。

