- 1k8s 攻击面
- 2【Linux】在Ubuntu下安装Zotero_ubuntu安装zotero
- 3开源驰骋BPM低代码-积极拥抱AI时代
- 4【数学建模】【优化算法】:【MATLAB】从【一维搜索】到】非线性方程】求解的综合解析_非线性方程的一维搜索
- 5Flink - Java篇_java flink
- 6Leecode刷题笔记——378. 有序矩阵中第K小的元素_leeetcode378 python
- 7SQL:DATE_FORMAT()函数_dateformat sql函数
- 8FastDFS配置之常见错误_fastdfs部署,配置能用127.0.0.1么
- 9Mac环境安装jmeter - 终端启动(输入jmeter即可启动)_jmeter怎么显示终端
- 10解决RequestContextHolder获取请求的javax与Jakarta不匹配的问题_jakarta 获取request
Python数据分析
赞
踩
数据分析的概念:数据分析是利用数学,统计学理论与实践相结合的科学统计分析方法,对excel数据,数据库中的数据,收集的大量数据,网页抓取的数据进行分析,从中提取有价值的信息并形成结论进行展示的过程。
广义的数据分析包括狭义数据分析和数据挖。
①狭义的数据分析是指根据分析目的,采用对比分析、分组分析、交叉分析和回归分析等分析方法,对收集的数据进行处理与分析,提取有价值的信息,发挥数据的作用,得到一个特征统计量结果的过程。
②数据挖掘则是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,通过应用聚类模型、分类模型、回归和关联规则等技术,挖掘潜在价值的过程。
二、数据分析流程:
1.需求分析
需求分析一词来源于产品设计,主要是指从用户提出的需求出发,挖掘用户内心的真实意图,并转化为产品需求的过程。
2.数据获取
数据获取是数据分析工作的基础,是指根据需求分析的结果提取、收集数据。数据获取主要有两种方式:网络数据和本地数据(在线数据和离线数据)。网络数据是指存储在互联网中的各类视频、图片、语音和文字等信息;本地数据则是指存储在本地数据库中的生产、营销和财务等系统数据。本地数据按照时间又可以分为两部分:历史数据和实时数据。历史数据是指系统在运行过程中遗存下来的数据,其数据量随系统运行时间的增加而增长;实时数据是指最近一个单位时间周期内产生的数据。
3.数据预处理
数据预处理是指对数据进行数据合并、数据清洗、数据标准化和数据变换,并直接用于分析建模的这一过程的总称。其中,数据合并可以将多张相互关联的表格合并为一张;数据清洗可以去掉重复、缺失、异常、不一致的数据;数据标准化可以去除特征间的量纲差异;数据变换则可以通过离散化、哑变量处理等技术满足后期分析与建模的数据要求。在数据分析的过程中,数据预处理的各个过程相互交叉,并没有明确的前后顺序。
4.分析与建模
分析与建模是指通过对比分析、分组分析、交叉分析、回归分析等分析方法,以及聚类模型、分类模型、关联规则、智能推荐等模型和算法,发现数据中的有价值信息,并得出结论的过程。
分析与建模的方法按照目标不同可以分为几类。如果分析目标是描述客户行为模式的,可以采用描述型数据分析方法,同时还可以考虑关联规则、序列规则和聚类模型等。如果分析目标是量化未来一段时间内某个事件发生的概率,则可以使用两大预测分析模型,即分类预测模型和回归预测模型。在常见的分类预测模型中,目标特征通常都是二元数据,例如欺诈与否、流失与否、信用好坏等。在回归预测模型中,目标特征通常都是连续型数据,常见的有股票价格预测和违约损失率预测等。
5.模型评价与优化
模型评价是指对于已经建立的一个或多个模型,根据其模型的类别,使用不同的指标评价其性能优劣的过程。常用的聚类模型评价指标有ARI评价法(兰德系数)、AMI评价法(互信息)、V-measure评分、FMI评价法和轮廓系数等。常用的分类模型评价指标有准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1值(F1 Value)、ROC和AUC等。常用的回归模型评价指标有平均绝对误差、均方根误差、中值绝对误差和可解释方差值等。
模型优化则是指模型性能在经过模型评价后已经达到了要求,但在实际生产环境应用过程中,发现模型的性能并不理想,继而对模型进行重构与优化的过程。在多数情况下,模型优化和分析与建模的过程基本一致。
6.部署
部署指将数据分析结果与结论应用至实际生产系统的过程中。根据需求的不同,部署阶段可以是一份包含了现状具体整改措施的数据分析报告,也可以是将模型部署在整个生产系统的解决方案。在多数项目中,数据分析师提供的是一份数据分析报告或者一套解决方案,实际执行与部署的是需求方。
三、数据分析的应用场景
1.客户分析(Customer Analysis)
客户分析主要是根据客户的基本数据信息进行商业行为分析,首先界定目标客户,根据客户的需求、目标客户的性质、所处行业的特征以及客户的经济状况等基本信息,使用统计分析方法和预测验证法分析目标客户,提高销售效率。其次了解客户的采购过程,根据客户采购类型、采购性质进行分类分析,制定不同的营销策略。最后还可以根据已有的客户特征进行客户特征分析、客户忠诚度分析、客户注意力分析、客户营销分析和客户收益分析。通过有效的客户分析能够掌握客户的具体行为特征,将客户细分,使得运营策略达到最优,提升企业整体效益等。
2.营销分析(Sales and Marketing Analytics)
营销分析囊括了产品分析、价格分析、渠道分析、广告与促销分析这4类分析。产品分析主要是竞争产品分析,通过对竞争产品的分析制定自身产品策略。价格分析又可以分为成本分析和售价分析。成本分析的目的是降低不必要的成本开销;销售分析的目的是制定符合市场的价格。渠道分析是指对产品的销售渠道进行分析,确定最优的渠道配比。广告与促销分析则能够结合客户分析,实现销量的提升、利润的增加。
3.社交媒体分析(Social Media Analytics)
社交媒体分析是以不同的社交媒体渠道生成的内容为基础,实现不同社交媒体的用户分析、访问分析和互动分析等。用户分析主要根据用户注册信息、登录平台的时间点和平时发表的内容等用户数据,分析用户个人画像和行为特征;访问分析则是通过用户平时访问的内容分析用户的兴趣爱好,进而分析潜在的商业价值;互动分析根据互相关注对象的行为预测该对象未来的某些行为特征。同时,社交媒体分析还能为情感和舆情监督提供丰富的资料。
4.网络安全(Cyber Security)
大规模网络安全事件的发生,让企业意识到网络攻击发生时预先快速识别的重要性。传统的网络安全主要依靠静态防御,处理病毒的主要流程是发现威胁、分析威胁和处理威胁。这种情况下,往往在威胁发生以后才能做出反应。新型的病毒防御系统可使用数据分析技术,建立潜在攻击识别分析模型,监测大量网络活动数据和相应的访问行为,识别可能进行入侵的可疑模式,做到未雨绸缪。
5.设备管理(Plan and Facility Management)
设备管理同样是企业关注的重点,设备维修一般采用标准修理法、定期修理法和检查后修理法等。其中,标准修理法可能会造成设备过剩修理,修理费用高;检查后修理法解决了修理费用的成本问题,但是修理前的准备工作繁多,设备的停歇时间过长。目前企业能够通过物联网技术收集和分析设备上的数据流,包括连续用电、零部件温度、环境湿度和污染物颗粒等多种潜在特征,建立设备管理模型,从而预测设备故障,合理安排预防性的维护,以确保设备正常工作,降低因设备故障带来的安全风险。
6.交通物流分析(Transport and Logistics Analytics)
物流是物品从供应地向接受地的实体流动,是将运输、储存、装卸搬运、包装、流通加工、配送和信息处理等功能有机结合来实现用户要求的过程。用户可以通过业务系统和GPS定位系统获得数据,使用数据构建交通状况预测分析模型,有效预测实时路况、物流状况、车流量、客流量和货物吞吐量,进而提前补货,制定库存管理策略。
7.欺诈行为检测(Fraud Detection)
身份信息泄露及盗用事件逐年增长,随之而来的是欺诈行为和交易的增多。公安机关、各大金融机构、电信部门可利用用户基本信息、用户交易信息和用户通话短信信息等数据,识别可能发生的潜在欺诈行为,做到提前预防。以大型金融机构为例,通过分类模型分析对非法集资和洗钱的逻辑路径进行分析,找到其行为特征。聚类模型分析可以分析相似价格的运动模式。例如对股票进行聚类,可能发现关联交易及内幕交易的可疑信息。关联规则分析可以监控多个用户的关联交易行为,为发现跨账号协同的金融诈骗行为提供依据。
四、Python数据分析的工具
目前主流的数据分析语言有Python、R、MATLAB这3种。其中,Python具有丰富和强大的库。常被称为胶水语言,能够把其他语言制作的各种模块(尤其是C/C++)很轻松地连接在一起。三种语言的之间的比较如下表
Python
R
MATLAB
语言学习难度
接口统一,学习曲线平缓
接口众多,学习曲线陡峭
自由度大,学习曲线较为平缓
使用场景
数据分析、机器学习、矩阵运算、科学数据可视化、数字图像处理、Web应用、网络爬虫、系统维护等
统计分析、机器学习、科学数据可视化等
矩阵运算、数值分析、科学数据可视化、机器学习、符号运算、数字图像处理、数字信号处理、仿真模拟等
第三方支持
拥有大量的第三方库,能够简便地调用C、C++、Java等其他程序语言
拥有大量的包,能够调用C/C++、Java等其他程序语言
拥有大量专业的工具箱,在新版本中加入了对C、C++、Java的支持
流行领域
工业界>学术界
工业界≈学术界
工业界≤学术界
软件成本
开源免费
开源免费
商业收费
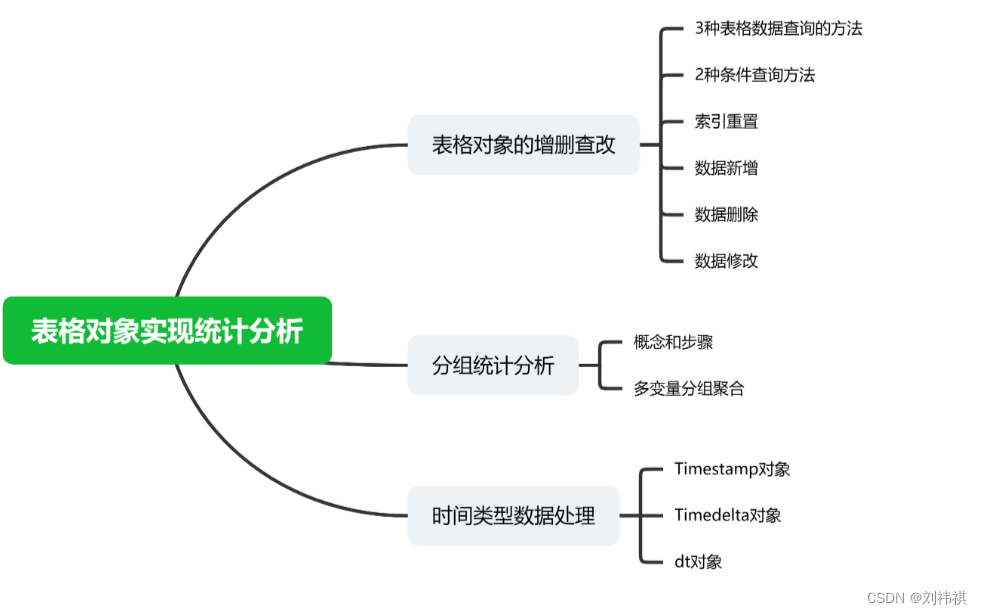
表格对象的增删查改
1.三种表格对象的查询方法
·三种表格对象的查询方法
使用Pandas库:Pandas是一个强大的数据处理库,主要用于数据分析和处理。它提供了DataFrame数据结构,可以方便地处理表格数据。
import pandas as pd
# 读取表格数据
df = pd.read_csv('data.csv')
# 查询数据
result = df[df['column_name'] == value] # 查询列等于特定值的行
result = df[df['column_name'].isin([value1, value2])] # 查询列在特定值列表中的行
result = df[df['column_name'] > threshold] # 查询列大于特定阈值的行
使用SQLAlchemy库:SQLAlchemy是一个用于Python的SQL工具包和对象关系映射(ORM)系统,可以用于查询数据库中的表格数据。通过创建数据库连接、会话和查询语句,可以灵活地获取表格数据。
from sqlalchemy import create_engine, asc, and_
from sqlalchemy.orm import sessionmaker
from your_model import YourTable # 替换为你的模型类名
# 创建数据库连接
engine = create_engine('sqlite:///data.db') # 替换为你的数据库连接字符串
Session = sessionmaker(bind=engine)
session = Session()
# 查询数据
result = session.query(YourTable).filter(and_(YourTable.column1 == value1, YourTable.column2 == value2)).order_by(asc(YourTable.column_name)).all() # 查询满足多个条件的行
使用Python内建的字典数据结构:如果表格数据存储在一个字典中,可以通过字典的键来查询数据。可以使用字典的get()方法或[]运算符来获取指定键的值。如果需要查询多个键的值,可以使用字典的values()方法或items()方法。
data = {
'column1': ['value1', 'value2', 'value3'],
'column2': ['value4', 'value5', 'value6'],
'column3': ['value7', 'value8', 'value9']
} # 替换为你的表格数据
# 查询数据
result = data.get('column_name', []) # 获取指定键的值,如果不存在则返回空列表
result = [value for key, value in data.items() if key == 'column_name'] # 获取所有键等于指定值的值列表
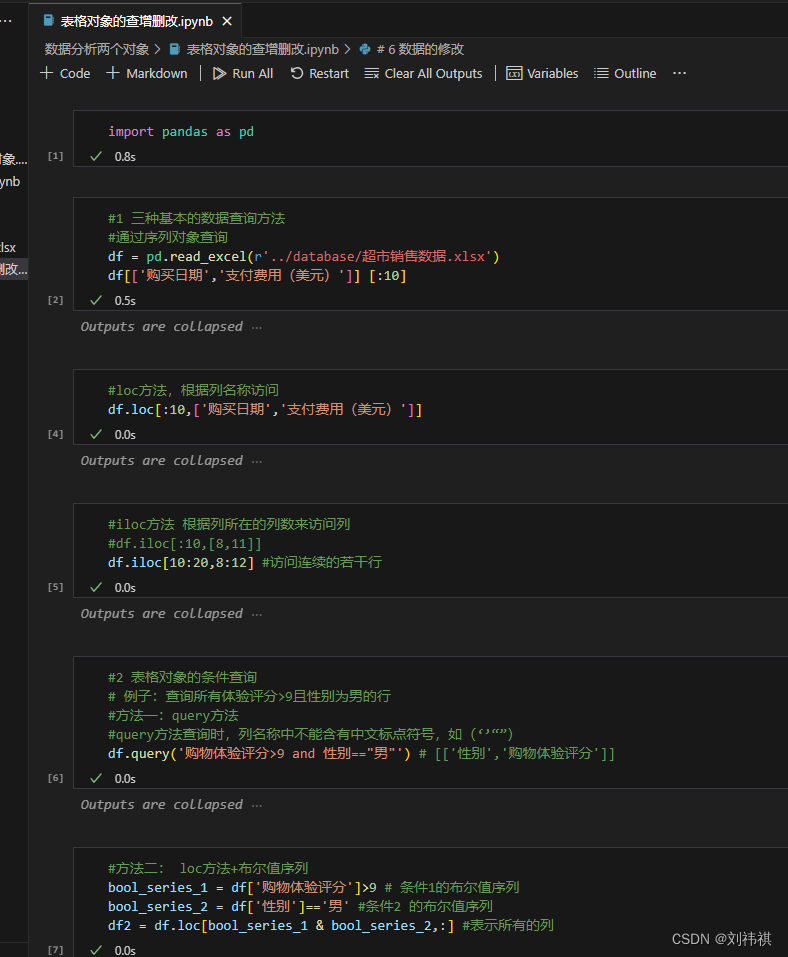

2、两种查询方法
· query方法
语法:**表格对象.query(查询条件字符串)**
查询条件字符串:例如:'a>1','性别=="男"','a>1 and b==2'
·loc方法
语法:**表格对象.loc[ 布尔值序列 , 列索引 ]**
布尔值序列由一个序列对象做条件判断运算得到,如:df['年龄']==18
布尔值序列中True所在的行即满足条件的行
当列索引为":"时(查询所有的列),条件查询语句也可以简写为:**表格对象[布尔值序列]**
3、表格对象索引重置
对于Pandas的DataFrame对象,可以使用reset_index()方法来重置索引。这将创建一个新的列,其中包含原始索引的值,并将原始索引替换为默认的整数索引。例如:
import pandas as pd
# 创建一个示例DataFrame
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
# 重置索引
df_reset = df.reset_index()
print(df_reset)
输出:
css `A B index
0 1 4 0
1 2 5 1
2 3 6 2
4、数据新增
导入必要的库:根据所使用的数据库或数据存储系统,需要导入相应的Python库。例如,对于关系型数据库(如MySQL、PostgreSQL等),可以使用pymysql、psycopg2等库;对于NoSQL数据库(如MongoDB),可以使用pymongo库。
import pymysql
# 建立连接
conn = pymysql.connect(host='localhost', user='username', password='password', db='database_name')
# 创建游标
cursor = conn.cursor()
# 定义要插入的数据
data = {'name': 'John Doe', 'age': 30, 'email': 'johndoe@example.com'}
# 执行插入操作
sql = "INSERT INTO users (name, age, email) VALUES (%s, %s, %s)"
cursor.execute(sql, (data['name'], data['age'], data['email']))
# 提交事务
conn.commit()
# 关闭连接
cursor.close()
conn.close()


四、分组统计分析
在Python中,可以使用Pandas库进行分组统计分析。Pandas提供了一个强大的DataFrame对象,可以方便地对数据进行分组、聚合和统计。
五、时间类型数据处理
Python中的时间类型数据处理主要涉及到datetime模块。以下是关于datetime模块的一些基本操作:
1.导入datetime模块:
from datetime import datetime
2.获取当前时间:
now = datetime.now()
print("当前时间:", now)
3.格式化日期:
formatted_date = now.strftime("%Y-%m-%d %H:%M:%S")
print("格式化后的时间:", formatted_date)
4.解析日期字符串:
date_string = "2023-07-18 15:30:00"
parsed_date = datetime.strptime(date_string, "%Y-%m-%d %H:%M:%S")
print("解析后的时间:", parsed_date)
5.时间差计算:
start_time = datetime(2023, 7, 18, 10, 0, 0)
end_time = datetime(2023, 7, 18, 15, 30, 0)
time_difference = end_time - start_time
print("时间差:", time_difference)
6.时间加减:
# 加时间
new_time = now + datetime.timedelta(days=5)
print("加5天后的时间:", new_time)
# 减时间
new_time = now - datetime.timedelta(hours=3)
Python在可视化表格对象实现统计分析方面的优势:
易用性:Python拥有众多用于数据分析和可视化的库,如Pandas、Matplotlib和Seaborn等。这些库为用户提供了直观的API,使得数据的处理、清洗、分析和可视化变得简单快速。
灵活性:Python的可视化库允许用户根据需求定制图表,从简单的线图到复杂的散点图、热力图等,都可以轻松实现。
高效性:Python在数据科学和机器学习领域有很高的性能。通过利用NumPy等科学计算库,Python可以进行大规模数据的快速处理和分析。
交互性:Python的可视化图表可以与用户进行交互,允许用户通过鼠标操作进行图表的缩放、平移等操作,增强了用户体验。
python数据分析之数据清洗
1.简介
数据清洗是指发现并纠正数据文件中可识别的错误的最后一道程序,包括检查数据一致性,处理无效值和缺失值等。数据清洗的主要任务是过滤那些不符合要求的数据,将数据转化为“干净”的、可信赖的、一致的数据,从而满足数据质量、准确性、完整性和其他要求。
数据清洗通常包括以下步骤:
识别和定位问题数据:通过数据探索和可视化,识别出异常值、缺失值、重复数据等问题数据。
处理缺失值:根据实际情况选择填充方法,如使用均值、中位数、众数等。
处理异常值:根据数据的分布和特征,选择合适的异常值处理方法,如删除、替换、或用插值等方法处理。
去除重复数据:基于业务规则和需求判断重复数据的取舍。
转换数据:根据业务规则和需求对数据进行转换和编码。
验证数据:通过数据质量检查来验证清洗后的数据是否满足要求。
数据清洗是数据分析的重要前置步骤,清洗后的“干净”数据能够提高数据分析的准确性和可靠性,为后续的数据分析提供更好的基础。
2.学习内容:
数据类型转换:
了解如何将字符串转换为数值类型,例如使用pd.to_numeric()函数。
学习日期时间数据的处理,如何将字符串转换为日期时间类型,以及如何提取日期和时间的不同部分。
重复值和重复行处理:
掌握如何检测重复的行或列,例如使用duplicated()和drop_duplicates()函数。
学习如何基于特定的列或多个列进行去重处理。
数据整合与重塑:
了解如何将多个数据源合并为一个数据集,例如使用pd.concat()或pd.merge()函数。
学习如何重塑数据,例如使用melt()和pivot()函数。
数据探索与可视化:
利用数据可视化来探索数据分布、异常值和模式。
学习如何使用Matplotlib、Seaborn等库进行数据可视化。
学习资源推荐:
《Python数据分析从入门到实践》:一本系统介绍Python数据分析基础知识的书籍,涵盖数据清洗的各个方面。
Datacamp平台上的Python数据分析课程:提供了大量的实际案例和实践操作,有助于深入理解数据清洗的技巧和方法。
GitHub上的开源项目:可以找到许多关于数据清洗的Python代码示例和项目,从中学习不同的数据处理策略和技巧。
通过不断地学习和实践,你将逐渐掌握数据清洗的技巧和方法,提升你的数据分析能力。记住,数据清洗是一个持续的过程,随着数据的不断变化和新的数据处理技术的出现,需要不断地更新和改进你的清洗策略
3.示例代码
假设我们有一个简单的Pandas DataFrame,其中包含了一些缺失值和异常值
#导入需要用到的模块
import pandas as pd
import numpy as np
# 创建一个包含缺失值和异常值的简单DataFrame
data = {
'Name': ['Alice', np.nan, 'Charlie'],
'Age': [25, 100, 35], # 假设35岁是异常值
'Salary': [50000, 100000, 200000] # 假设100000是不寻常的高薪
}
df = pd.DataFrame(data)
print("原始DataFrame:")
print(df)
接下来,我们将展示如何进行数据清洗:
# 1. 缺失值处理 - 使用fillna方法填充缺失值,例如用平均值填充
df['Name'].fillna('Unknown', inplace=True) # 用'Unknown'填充Name列的缺失值
df['Age'].fillna(df['Age'].mean(), inplace=True) # 用Age列的平均值填充缺失值
print("处理后的DataFrame:")
print(df)
接下来,我们将展示如何进行异常值处理:
# 2. 异常值处理 - 使用IQR方法检测异常值
Q1 = df['Age'].quantile(0.25)
Q3 = df['Age'].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = df[(df['Age'] < lower_bound) | (df['Age'] > upper_bound)]
print("异常值:")
print(outliers)
最后,我们将展示如何进行数据规范化:
# 3. 数据规范化 - 使用最小-最大规范化方法
min_age = df['Age'].min()
max_age = df['Age'].max()
df['Age'] = (df['Age'] - min_age) / (max_age - min_age) # 0-1规范化
print("规范化后的DataFrame:")
print(df)