
- 1【postgresql初级使用】数据库安全防护,核心数据是黑客的终极大boss,多层次建立安全体系_postgresql安全基线
- 2C++匿名函数lamba简介
- 3python爬虫基础测试_python爬虫系统测试怎么写
- 4为什么使用负采样技术(附详细求导过程)_word2vec负采样的作用
- 5KotLin ORM数据库_kotlin orm 生成table
- 6WordPress网站迁移教程_wordpress怎么迁移网站到本地
- 7[DiMP跟踪算法]代码学习笔记
- 8基于Python的网络爬虫开发与实现_基于python网络爬虫设计与实现
- 9Ubuntu22.04配置ROS2 Humble_ros-humble-desktop-full
- 10自开发自用浏览器chromeium内核最新版
《Cloud Native Data Center Networking》(云原生数据中心网络设计)读书笔记 -- 06容器网络
赞
踩
本章将回答以下问题
- Linux上可用的容器网络组件有哪此?
- 各种选择的限制和性能特征是什么?
命令空间
命名空间是一个 Linux 内核虚拟化组件。该组件类似 Linux 内核提供的网络和服务器虚拟化的组件。命名空间对内核管理的特定的资源进行虚拟化,允许一个虚拟资源有多个隔离实例。一个进程与该资源的一个虚拟实例相关联。多个进程可以属于该资源的一个共有的虚拟实例。从进程的角度看,进程似乎完全拥有资源。
自内核版本 3.8 起,命名空间是完全可用的虚拟化组件。 内核支持以下六种资源的虚拟化
- Cgroup
对进程的 cgroups 视图进行虚拟化,可以通过/proc/pid/egroup和/proc/pidmountinfo查看,其中 pid是进程的进程ID。这样做的原因是容器化应用无法识别自己运行在容器中。 - 进程间通信(IPC)
对IPC 的各种组件进行虚拟化,例如: POSIX 消息队列、共享内存、信号灯等。这样进程无法跨越其隔离单元,访问其他进程状态。 - Network
对所有网络资源进行虚拟化,例如: 接口、套接字、路由表、MAC 表等。我们将在下一节中讨论网络命名空间。 - Mount
对文件系统挂载点进行虚拟化。每组隔离的进程都认为它们拥有自己的根文件系统。实际上,它们的根文件系统通常仅是一个较大文件系统的容器视图。chroot 是一个非常古老的 UNIX 组件,仅限制单个进程看到的根文件系统视图 - PID
对进程ID 空间进行虚拟化。该技术也使进程无法发现它们运行在容器中。每个容器像运行在裸金属服务器上,具有一个 PID 为1的进程(系统初始化进程)。 - User
对用户、用户和用户组进行虚拟化。每组隔离的进程都有一个 root 用户,仅作为该虚拟实例内的 root 用户。 - uTS
对主机名和域名进行虚拟化。这样,每个隔离的单元都可以设置自己的主机名和域名,而不会影响其他隔离单元或宿主机系统。
可以使用命名空间构造逻辑路由器。许多传统路由器比服务器需要少一些的 CPU,命名空间比使用虚拟机能够更持久的支持逻辑路由器。这样的组件允许网络管理员向不同租户提供自己的物理基础设施视图和管理。当然,使用虚拟机提供逻辑路由器意味着你可以为每个租户提供路由器 OS 的不同版本,但是在大多数情况下不需要这样。
网络命名空间
网络命名空间 (network namespace,又称 netns) 的概念类似网络虚拟化,但是网络命名空间是一个重量级的虚拟化组件,因为它包括网络栈的传输层至整个网络栈。
举例来说,可以创建两个独立的容器,每个容器运行一个端口为 80 的服务器。一般网络虚拟化组件仅对单层进行虚拟化,例如: 二层或三层。如果要提供多层拟化,需要同时部署多个这样的组件。
创建一个新的 netns 时,Linux 内核会在 netns 上创建一个回环接口。下面是查看新创建的netns的ip link 信息。为了使输出符合本书格式,我们使用省略号 (…)对输出的列和文本进行了剪裁,保留了与本次讨论有关的信息
$ sudo ip netns add myown
$ sudo nsenter --net=/var/run/netns/myown ip -d link show
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT ...
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 ...
eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
- 1
- 2
- 3
- 4
- 5
代码解释
$ sudo ip netns add myown
- 1
这行代码使用ip命令的netns子命令来创建一个新的网络命名空间,名为myown。网络命名空间是Linux内核提供的一种功能,允许你创建多个隔离的网络环境。
$ sudo nsenter --net=/var/run/netns/myown ip -d link show
- 1
这行代码使用nsenter工具来进入先前创建的myown网络命名空间。--net=/var/run/netns/myown指定了要进入的网络命名空间的路径。然后,它执行ip -d link show命令来显示该命名空间中的网络接口及其详细信息。
- 输出解释
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT ...
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 ...
eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
- 1
- 2
- 3
这段输出描述了myown网络命名空间中的一个网络接口。具体来说:
1: lo::这是网络接口的名称和编号。lo代表回环接口(loopback interface),它是一个特殊的网络接口,用于允许主机上的程序与其自身进行通信。<LOOPBACK>:这表示该接口是一个回环接口。mtu 65536:这表示该接口的最大传输单元(MTU)为65536字节。对于回环接口,这通常是一个非常大的值,因为它仅用于本地通信。qdisc noop:这表示该接口的排队规则(qdisc,queueing discipline)是noop,即不进行任何队列处理。state DOWN:这表示该接口当前处于关闭状态。在创建新的网络命名空间时,回环接口通常默认是关闭的。link/loopback 00:00:00:00:00:00:这提供了该接口的MAC地址信息,但由于是回环接口,其MAC地址固定为00:00:00:00:00:00。brd 00:00:00:00:00:00:这是广播地址,对于回环接口,它也是固定的。- 剩下的部分是其他关于该接口的详细属性,如
numtxqueues、numrxqueues、gso_max_size和gso_max_segs,它们分别表示发送队列数量、接收队列数量、GSO(Generic Segmentation Offload)的最大大小和GSO的最大段数。
虚拟以太网接口
netns 中的接口需要使用外部连接,向相同物理系统的不同 netns 中的接口发送或接收数据包。Linux 提供了一个虚拟以太网组件,称为 veth,允许与 netns 外部进通信。veth 总是成对被创建。数据包进入 veth 一端会自动从另一端出来、以下示了 veth pair 的创建:
$ sudo ip link add veth1 type veth
$ ip -br link show type veth
veth0@veth1 DOWN c2:9c:96:5c:fa:bf <BROADCAST,MULTICAST,M-DOWN>
veth1@veth0 DOWN 8a:69:f2:c9:76:e7 <BROADCAST,MULTICAST,M-DOWN>
- 1
- 2
- 3
- 4
因此,为了允许 netns 内部与外部进行通信,可以将 veth 的一端放入 netns,然后将另一端放入希望进行外部通信的位置。例如,当你通过 docker 命令创建容器时,会创建一个 veth pair,其中一端在创建的容器的 netns中,另一端在默认的 netns 或主机netns中。这样,你可以建立容器和外界之间的通信。 图7-1 演示了在 Linux中使用veth。NS1和 NS2 是两个独立的网络命名空间,用 veth 接口使它们之间通信。
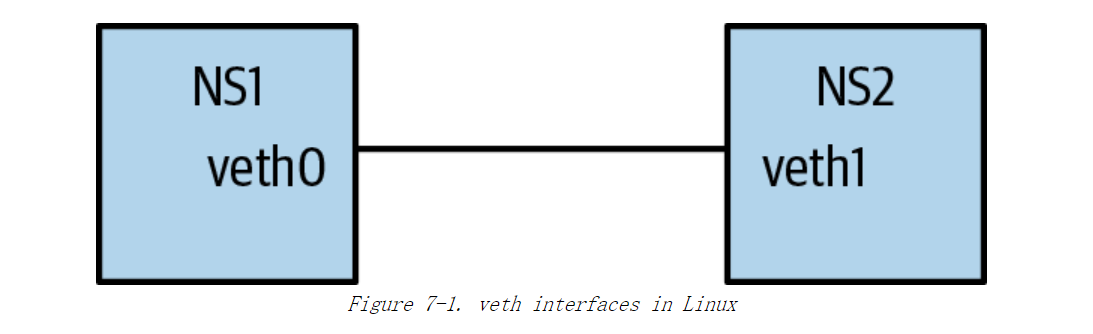
Docker中,容器内部会创建一个最常见的网络接口,特别是使用默认的 Docker桥接网络时,这个网络接口就是一个 veth 接口。检查容器中接口类型的一种简单方法是执行 ip -d link show 命令。但是在一些最小的容器 (例如 alpine)不支持 ip link show的-d选项。在这种情况下,你可以使用 nsenter 命令,假设要检查的容
器名为“container1”,需要执行以下操作:
$ sudo nsenter -t `docker inspect --format '{{.State.Pid}}'
container1` -n ip -d link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN ...
default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 promiscuity ...
17: eth0@if18: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue ...
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0 ...
veth addrgenmode eui64
$
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
You can see that
eth0is of type veth.This veth interface has an ifindex of17and the other veth interface of this pair is at ifindex18, as shown by@if18in the interface information.docker 将接口名称重命名为 eth0,给应用运行在一个裸金属环境的感觉。
ifindex是interface index (接口索引) 的缩写,是分配给设备上个接口的唯一ID
可以看到 eth0的类型为veth。这个 veth 接口的ifindex为17,该接口信息中显示@if18,表明该 veth对的另一个 veth 接口的ifindex为18。
在主机上执行link show ,如下所示:
$ ip -d link show
...
4: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 ... state UP ...
link/ether 02:42:f5:4c:09:f4 brd ff:ff:ff:ff:ff:ff promiscuity 0
bridge forward_delay 1500 hello_time 200 max_age 2000 ...
32768 vlan_filtering 0 vlan_protocol 802.1Q addrgenmode eui64
18: vethcd16cb7@if17: <BROADCAST,MULTICAST,UP,LOWER_UP> ... master docker0 ...
link/ether ba:66:d1:d2:70:df brd ff:ff:ff:ff:ff:ff link-netnsid 0 ...
veth
bridge_slave state forwarding priority 32 cost 2 hairpin off ...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Vethcd16cb7 是 veth 接口,它的 ifindex 为 18,该口是 docker0 网桥的一个端口。
深入容器网络
从根本上讲,任何容器网络都必须解决以下问题:
- 容器接口如何获取IP 地址?
- 容器如何与外部世界之间通信?
- 容器如何与其他容器之间通信? 在多宿主机情景下,容器可以运行在相同的宿主机上,容器也可以运行在其他节点上。容器与其他容器之间通信需要考虑这两种情况。
Container networking has four operating modes:
-
No network
容器不与外界通信,没有任何类型的网络连接
-
Host network
容器与主机 OS 共享网络命名空间。换句话说,第二种模式是没有隔离性的,容器可以查看宿主机的所有内容。这样做的好处是容器网络性能几乎与主机OS 网络性能相同,因为容器和外界之间通信没有额外的开销。当容器以特权模式运行时,可以修改主机操作系统的网络状态,例如: 路由表,MAC表,接口状态等。
FRR 是开源路由包,允许路由作为服务器上的容器化服务被提供,当 FRR 在服务器上以容器方式运行时,需要使用特权模式。这个可以帮助那些希望所有应用以容器部署的用户,他们不希望仅需要路由服务是一个例外。Mesos 是基于容器的计算节点的集群管理软件,也使用主机网络作为默认的网络类型。这种模式的主要缺点是容器共享网络状态,因此两个容器不能使用相同 TCP/UDP 端口与外界通信。
-
Single-host network
单主机网络模式是 Docker 提供的默认网络模式。在这种模式下,运行在同一主机上的容器可以相互通信,并且可以与外界通信。
-
Multihost network
多主机容器网络模式允许容器运行在不同服务器上,并且可以相互通信。
单主机容器网络
单主机容器网络允许在同一主机上运行的容器相互通信以及与外界通信。
bridge
**首次启动 Docker 服务时,将创建一个 Docker0 设备,Docker0 是 Linux 网桥。**当通过docker run 命令创建新容器,不指定网络选项时,Docker 会创建一个 veth pair接口,veth pair 的一端分配给容器的 netns 中,然后另一端附加到 docker0 网桥上。其他容器以类似方式被创建,具有相同的行为。这样,因为每个容器中的 veth 接口
的另一端连接到 docker 网桥上,所以在主机上创建的多个容器可以相互通信,如图7-2 所示。
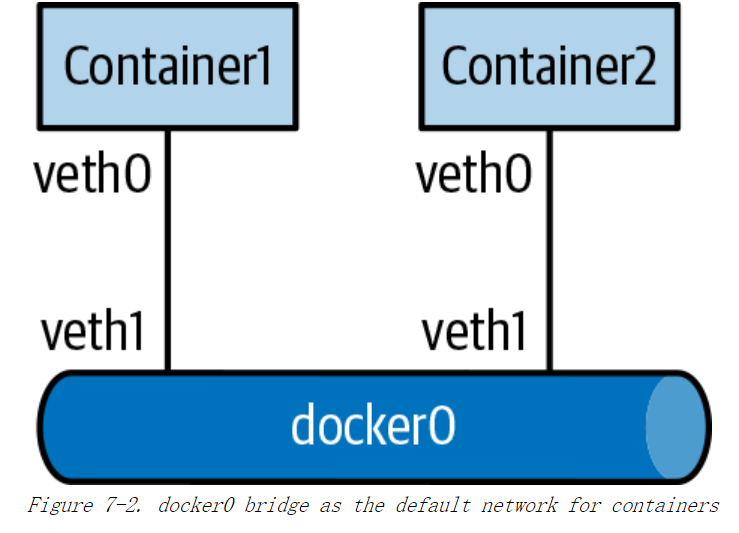
Docker给 docker0 网桥分配的默认子网是172.17.0.0/16。它给网桥本身分配的地址为172.17.0.1。 当启动一个容器时,该容器将创建一个与 dockero 网桥关联的网络接口,Docker 会自动从 docker0 子网 172.17.0.0/16 中,给该容器分配一个未使用的IP地址。Docker 还在容器的命名空间中添加一条默认路由,该路由指定下一跳为docker0 的 IP 地址172.17.0.1。默认情况下,Docker 还会对网桥流向外部的任何数据包执行 NAT,以便多个容器可以共享一个主机IP 地址,与其他主机上的实体进行通信。
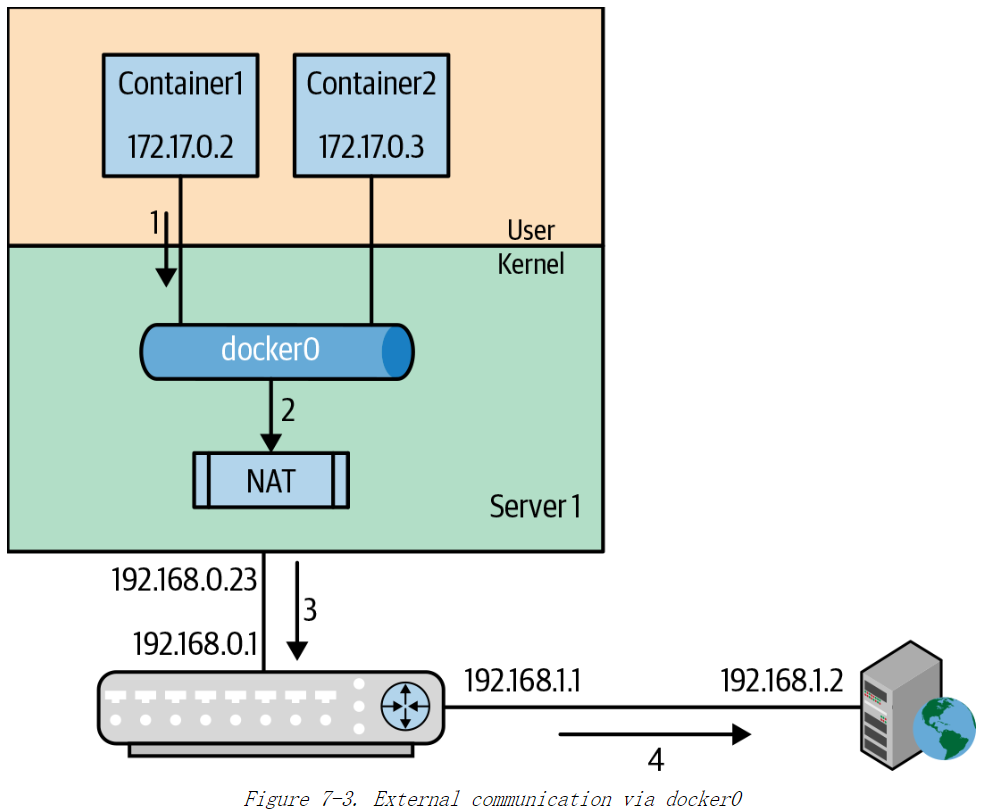
图 7-3 展示了 container1 要与外部 Web 服务器进行通信的一系列操作。运行 Docker容器的主机和 Web 服务器均位于 192.168.0.0/24 网段上,Docker 位于192.168.0.23的主机上,Web 服务器的 IP 地址是192.168.1.2。
- 由于地址
192.168.1.2在 Containerl 的子网172.17.0.5/16之外,因此它将数据包发送到其配置的默认网关172.17.0.1,这是常规路由的一部分。
- Linux 内核栈接收这个数据包,进行路由查找,并确定该数据包发往其默认网关
192.168.0.1,它是外部路由器。 - docker 设置了 iptables 规则,从 docker0 到外界的任何通信都执行 NAT。因此数据包发送给外部路由器之前,先对数据包的源端口和源 IP 地址进行了修改。
- 外部路由器将数据包路由到 Web 服务器。
$ sudo iptables -L -t nat Chain PREROUTING (policy ACCEPT) target prot opt source destination DOCKER all -- anywhere anywhere ADDRTYPE match dst-type LOCAL Chain INPUT (policy ACCEPT) target prot opt source destination Chain OUTPUT (policy ACCEPT) target prot opt source destination DOCKER all -- anywhere !localhost/8 ADDRTYPE match dst-type LOCAL # 这一行显示 post-routing 链上的 NAT 操作。数据包的源地址与 172.17.0.0/16 子网匹配,目的是任何其他地址 (本地地址或其他地址),这样的数据包将执行NAT 操作。Masquerade 是 iptables 模块,用来执行 NAT 等操作 Chain POSTROUTING (policy ACCEPT) target prot opt source destination MASQUERADE all -- 172.17.0.0/16 anywhere Chain DOCKER (2 references) target prot opt source destination RETURN all -- anywhere anywhere $

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
如果容器想要与同一网桥上另一个容器进行通信,docker0 网桥负责将流量转发到适当的容器上。
默认情况下,连接到同一网络的容器可以相互通信,例如: 连接 docker0 的容器间可以相互通信。但是,默认情况下,容器无法与连接到同一主机上其他网络的容器相互通信。 例如:如果我们通过 docker network create docker1,创建另一个名为docker1网桥,并且创建一个与 docker1连接的 Container3,则默认情况下,连接
docker0 网桥的 Container1 无法与 Container3 进行通信。
Macvlan
单主机容器通信使用桥接模式的替代方式是 Macvlan。Macvlan 是与一个物理接口关联的 L2 虚拟网络接口。内核驱动程序为每个 Macvlan 接口分配一个唯一的MAC地址。如果 macvlan 接口的 MAC 地址与数据包的目的 MAC 地址匹配,内核将发送数据包到此 Macvlan 接口上,从而到达正确的容器。
docker 生成的MAC地址的高三字节设置为 02:42:ac,这是一个未分配的OUI(Organizationally Unique Identifier,组织唯一标识符)。
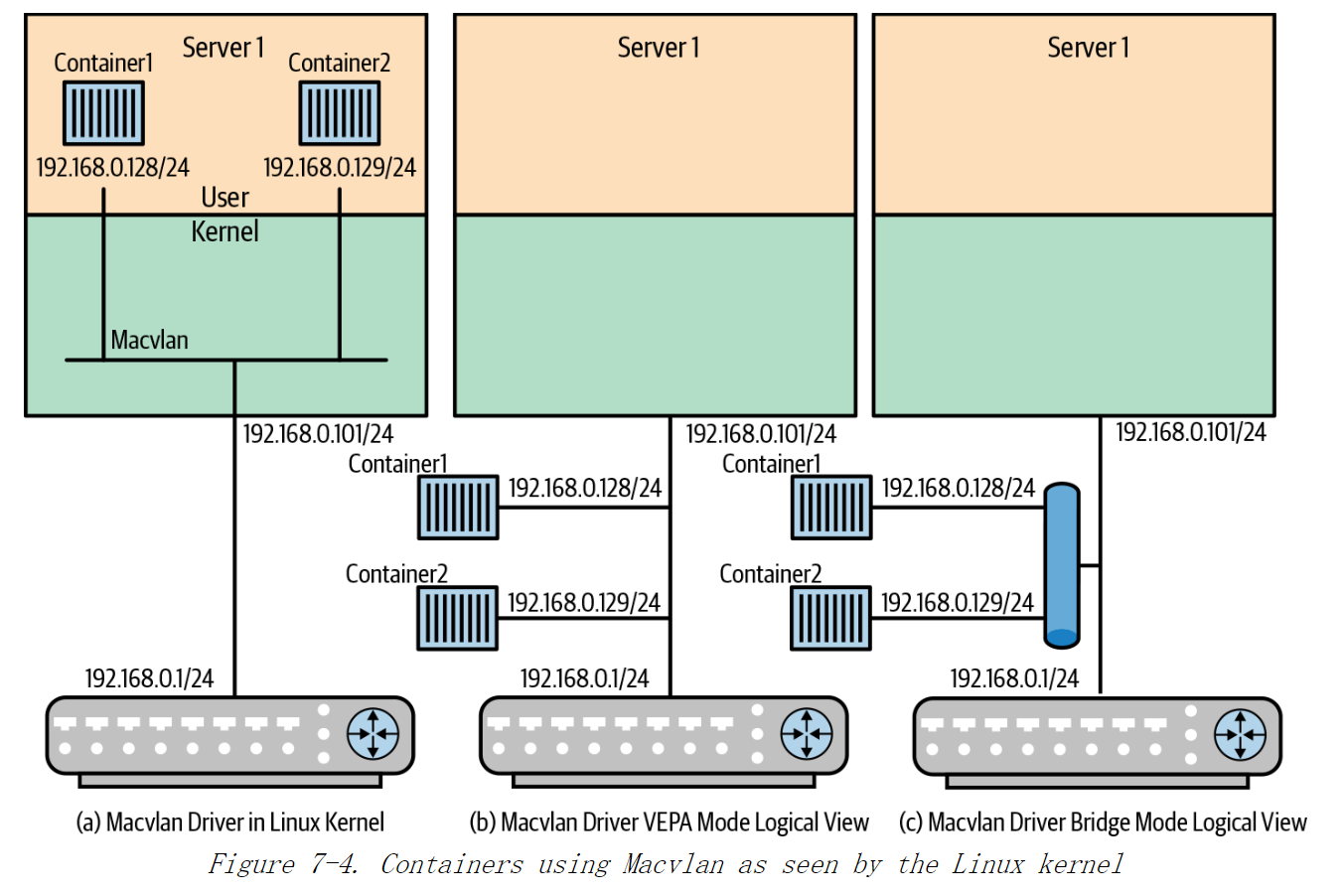
图7-4(a) 展示了 Macvlan 网络,容器可以连接到 Macvlan 网络,Macvlan 网络本身直接连接到一个物理接口上。Macvlan 网络会为与其相连的容器分配IP地址,该IP 地址与相连的路由器接口 (上游接口) 属于同一子网。
如图 7-4(a)所示,上游路由器指定上游接口位于子网192.168.0.0/24中,其上游接口地址为192.168.0.1。主机分配的地址段为192.168.0.101/24,容器分配的地址分别为192.168.0.128和192.168.0.129。
使用 Macvlan 接口首先要考虑的是 IP 地址约定。默认情况下,当一个容器启动时,Docker 会为其分配IP地址。为了避免容器 IP 与上游这些非容器的 IP 地址发生冲突,你需要为 Docker 提供上游设备不会使用的 IP 地址范围,通常使用 DHCP (DynamiHost Configuration Protocol,动态主机配置协议) 服务器作为IP 地址的分配器,或者在每个容器启动时,手工分配IP地址。不幸的是,我们无法通过简单的预先构建的方法,使用 DHCP 服务向上游路由器请求容器接口的IP 地址,你需要使用第三方插件驱动程序或使用自己的 IPAM ( IP Address Management,IP 地址管理)模块来处理这种情况。
幸运的是,docker network create 命令解决了部分的问题。 我们可以使用 ip-range 选项,使 Docker 使用子网中较小范围内的 IP 地址作为容器的IP 地址。 以下
是命令示例
$ docker network create -d macvlan \
--subnet=192.168.0.0/24 \
--ip-range=192.168.0.128/25 \
--gateway=192.168.0.1 \
--aux-address="my-router=192.168.0.129" \
-o parent=eth1 macv
- 1
- 2
- 3
- 4
- 5
- 6
尽管主机和容器位于相同的子网中,并且在相同的 Linux 内核上运行,但是它们不能直接相互 ping 通。图 7-4(b)和图 7-4©展示了实际的 Macvlan 行为。如果容器想要 ping其主机,数据包必须先到达上游设备(即路由器),然后再返回。这称为“发夹”(hairpinning)。如图 7-4(b) 所示,即使容器连接到同一Macvlan 设备,也无法直接彼此 ping 通,这种模式称为 Macvlan 驱动程序的 VEPA 模式。
VEPA 是虚拟以太网端口聚合器,IEEE标准定义了 VEPA 行为
默认情况下,Docker 以另一种模式创建 Macvlan 网络,该模式称为桥接模式,如图7-4©所示。在桥接模式下,连接到同一 Macvlan 的容器可以彼此直接通信,而不会发生“发夹”。但是与主机本身通信仍然需要发生“发夹”。
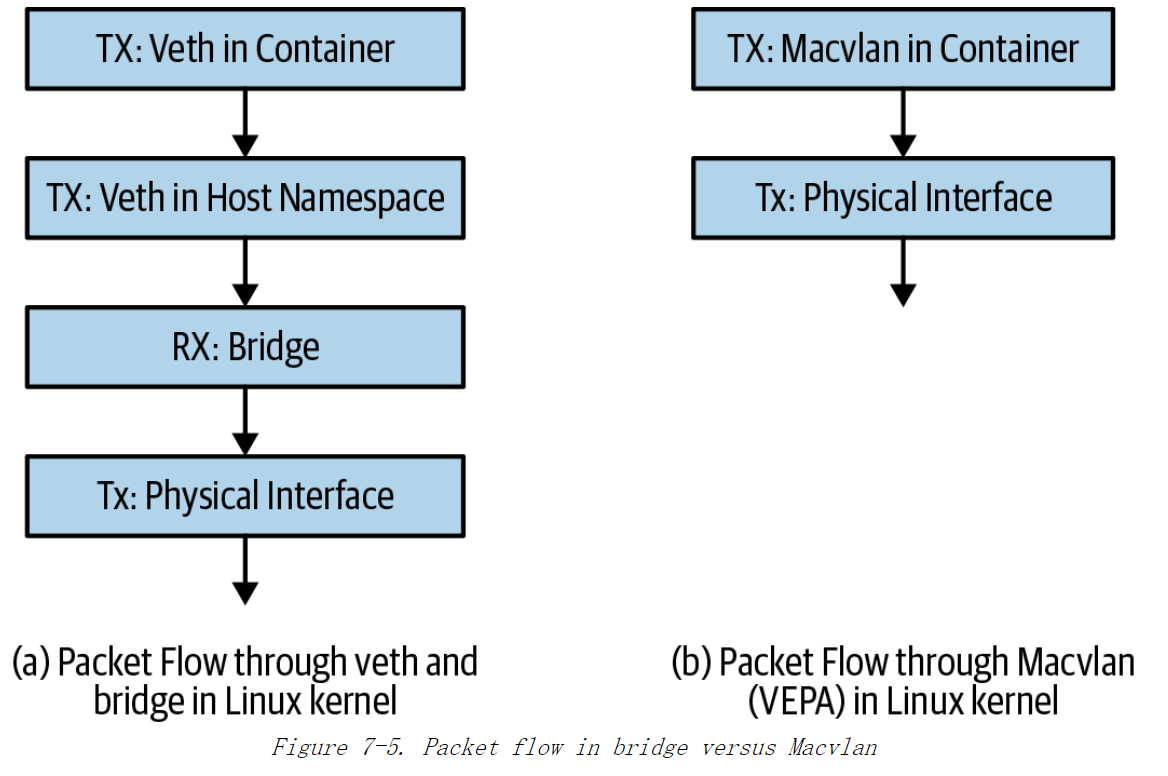
图 7-5 比较了常规网桥网络与 Macvlan 网络的 VEPA 模式的数据包转发。与网桥网络相比,Macvlan 网络的 VEPA 式的主要好处是性能更高。Macvlan 的接口直接位于与其相连的物理接口上。与网桥模式不同,Macvlan 不需要任何额外的处理。在网桥网络下,需要将数据包从 veth 接口的一端传递到另一端到网桥,然后传递到物理接口发出去。此外,在 Macvlan 模式下,不需要执行 NAT,每个容器都有一个外部可达的IP 地址。如果同一主机上的容器需要相互通信,将 Macvlan 接口设置为桥接模式会更有效,因为这可以阻止相互通信的流量被“发夹。
veth/bridge 网络中包括了一些额外的过程,而在 Macvlan 网络中不存在这些过程。此外,在网桥模式下,除非你明确禁用,否则这些数据包都会执行NAT。当网桥与路由守护程序结合用于多主机网络时,则不会使用 NAT。
在 Macvlan 网络中,Macvlan 设备不存在路由表查找。如果是 Macvlan 的 VEPA模式,Macvlan 设备也不存在 MAC 表查找,学习,也不会像 Linux 网桥那样造成网络性能开销。然而 Macvlan 增加了 DHCP 地址分配的复杂性,由于需要多个IPAM masters,例如:主机使用 DHCP 服务器,容器使用 DHCP IPAM。如果你可以在部署中克服这些问题,Macvlan 的 VEPA 模式性能是最佳的单主机容器网络。对于多主机容器网络,Linux 网桥结合路由守护程序是性能最佳的、最普遍的解决方案。Kubernetes 也倾向使用 Linux 网桥。
使用 Macvlan 设备时有一个限制,大多数网卡仅可配置 512 个左右的 MAC 地址。 并且,在 Macvlan 模式下网卡必须配置为性能较差的混杂模式。 因此,使用Macvlan 网络,需要保证过多的容器 MAC 地址不会溢出网卡 MAC 地址过滤器设置的限制。
多主机容器网络
Macvlan网络也可以提供2层的多主机容器网络
以下是另外两种方式
Overlay网络
Docker为多主机连接定义了一种称为 Overlay 的网络类型,Overlay 网络使用的是 VXLAN。Overlay 网络是一个 2 层网络。换句话说,分布在多主机上的容器位于同一子网中。在这种情况下,在多主机上分配同一子网的IP 地址,比本地 Docker 守护程序在容器启动时分配IP 地址要复杂。当创建 Overlay 网络时,Docker需要 Swarm 功能。Swarm 是Docker的控制面板,用于处理多个主机之间的IPAM (IP Address Management,IP地址管理),以及提供服务抽象等。
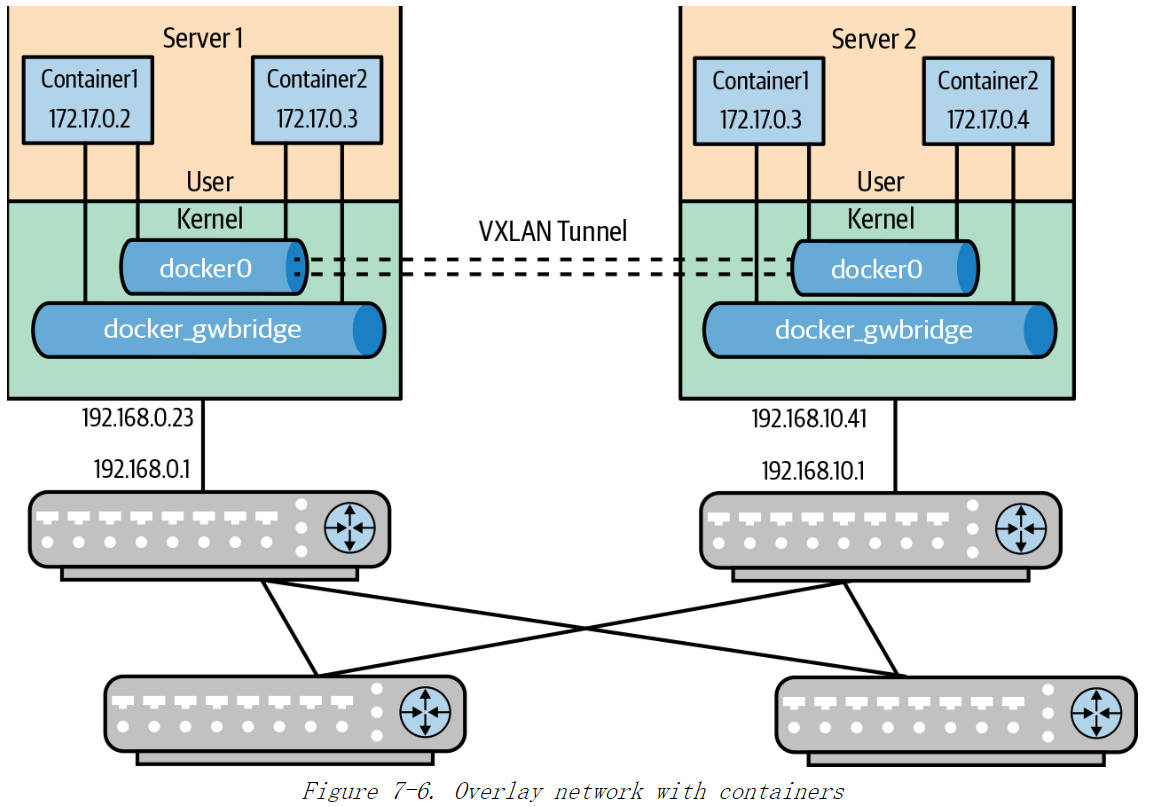
图 7-6 展示了数据平面处理数据包转发。不同服务器中的两个容器都属于同一子网 172.17.0.0/24。服务器1的 VTEPIP 地址为192.168.0.23,而服务器2的VTBP IP 为192.168.10.41。上游路由器都已交换路由信息,所有路由器都知道如何访问192.168.0.0/24 和192.168.10.0/24子网。因此,从服务器1到服务器2的 VXLAN数据包可以在所示的网络中进行路由。
从容器的角度来看,在单主机网桥网络中,veth 接口会连接到 Linux 网桥。
在Overlay 网络中,在网络节点上也会创建 VXLAN隧道。VXLAN 隧道会连接到 veths 连接的 Linux 网桥,通常是docker0。每个连接到 Swarm(或Flannel或
Weave) 的节点都会创建一个 VXLAN 隧道,并连接到网桥上,以此在底层承载网络上建立数据包隧道。使用 Overlay 网络时,Docker 在容器内创建两个接口。
- 一个接口用于 Overlay 同一子网中容器之间进行通信。
- 另一个接口用于与外界交流。这个新接口也是veth,但是它会连接到另一个网桥
docker-gwbridge,该网桥有自己的IP子网。
容器内的路由表为每种通信形式设置使用适当的接口。
下面输出显示了一系列命令的执行及结果输出

1)创建一个“Overlay”类型的新网络
2)创建一个新容器,使用新创建的 Overlay 网络
3)查看容器内部的IP 路由表内容。路由表的默认路由指向172.19.0.1 和接口 eth1。
4)因为alpine的基本命令集只包括 iproute2 命令集的限制版本,所以退出容器,从主机上执行命令。输出显示eth1是 veth,其 veth pair 的另一端接口索引为
ifindex 114 (eth1@if114)。
5)主机上执行 ip link show veth71a0f27 命令,输出显示该 veth 的索引为ifindex114。输出还显示了该 veth 的主接口为docker_gwbridge。换句话说,该接口是docker_gwbridge 网桥的一部分。
默认情况下,像 docker0 网桥一样,通过 docker_gwbridge 的数据包会执行 NAT。
直连路由
overlay 解决方案的替代方法是使用路由,即 3 层解决方案。该解决方案使用单主机容器网络驱动程序(通常是网桥驱动序)构建多主机容器,然后通过路由进行连接。要使用这个解决方案,必须关闭网桥子网的 NAT功能。由各个服务器上运行的路由守护程序(例如,FRR 中的 ospf或 bgp) 来宣布各个容器地址或网桥子网。
To turn off NAT, create a daemon.json file in the /etc/docker directory containing the following fragment:
{ "ip-masq": false }
- 1
- 2
- 3
Restart docker via
systemctl restart dockerand the masquerade line from the iptables output (described in Example 7-1) will be gone. If this does not happen, you might need to reboot the server.
对于仅网桥子网的路由通告,当第一个容器连接到网桥时,子网路由将被通告,而当连接到网桥的最后一个容器终止时,子网路由将被撤消。这是由现存的路由通告逻辑所决定,当第一个容器启动并连接到网桥时,网桥将其接口状态设置为 up,而当连接到网桥的最后一个容器终止时,网桥将其接口状态设置为 down。
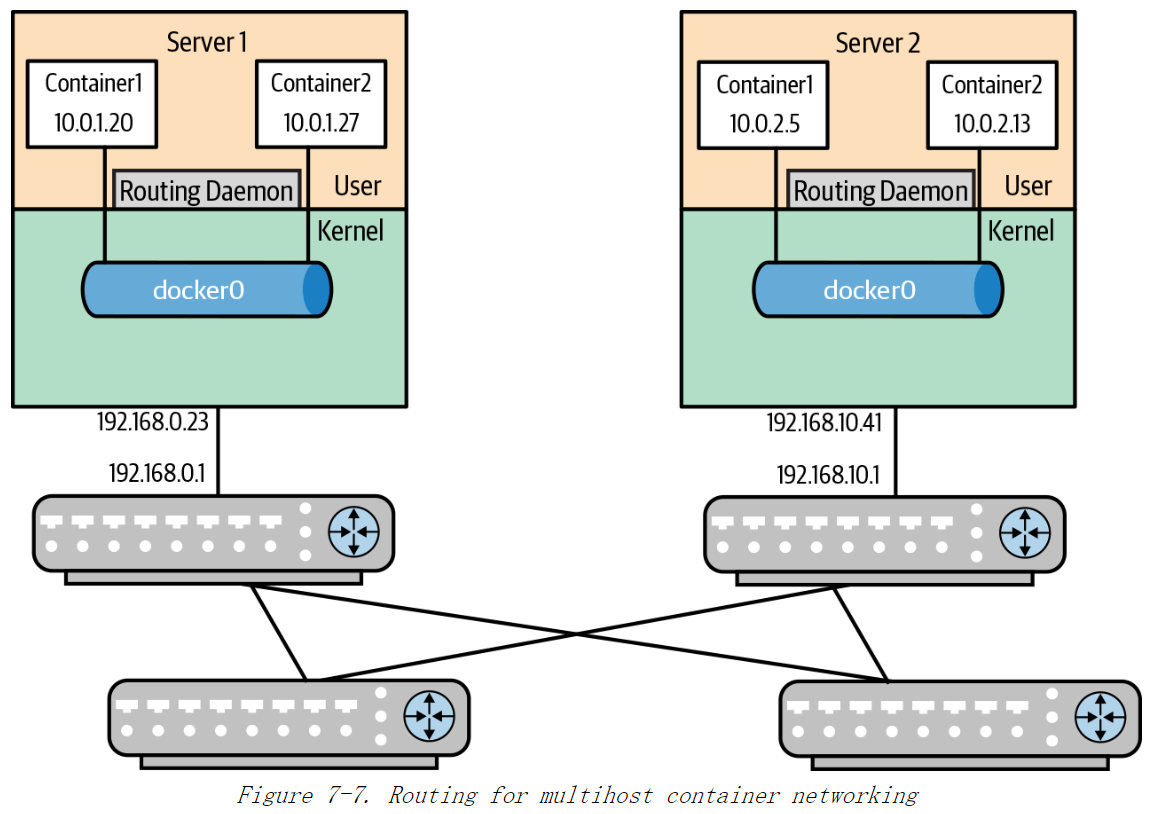
Kube-router 是另一个解决方案,我们可以将 kube-router 与 Kubernetes 一起部署为多主机容器连接提供直连路由的解决方案。如图7-7所示:
这种解决方案中没有 NAT,并且每个节点有一个路由守护程序用来通告容器路由。
- 如果路由守护程序是独立的守护程序如FRR,唯一无需任何配置就可以通告出去的路由就是网桥的子网路由(the bridge subnet route)。
- 当路由守护程序是驱动程序方案的一部分时,例如; kube-router 或 Calico,那么各个容器地址将被其通告。
路由作为多主机容器网络
这种解决方案的一个缺点是无法跨多个节点从同一子网分配 IP 地址
仅基于性能的原因,作者建议避免使用任何 Overlay 解决方案
Kubernetes网络
pod是一组容器,总是一起执行启动和调度。pod 中的容器还共享相同的Linux 命名空间和 cgroup。pod 是短暂的,因此在 Kubernetes 中不建议直接与 pod通信。取而代之的是,一组 pod 提供一个服务,可能是对应的微服务,服务有名称和IP 地址。服务外部的实体通过服务名称和IP地址来访问该服务。例如:你可以使用DNS提供的负载均衡机制访问 pod,或者使用 Linux的iptables 或IPVS (IPVirtual Server,虚拟服务器 )机制提供的负载均衡,通过服务访问提供服务的 pod.Kubernetes 还可以监视 pod 的状态以及流入的访问负载,使用这种机制,在负载高的情况下可以启动更多 pod,在负载减少的情况下停止一些 pod,或者更新发生故障的 pod。
对于 pod和pod 之间通信或 pod 和主机之间通信,Kubernetes 有如下限制
- 所有容器都应该能够与 pod 中的所有其他容器进行通信,不需要使用 NAT
- pod 中的所有容器都应该能够与主机通信,反之亦然,不需使用NAT
- 无论是在容器内还是容器外,查看容器的IP 地址都相同。换句话说,pod 外部没有 NAT。
Linux 网桥与路由守护程序结合能够很好地满足这些要求
Kubernetes 还包含一个路由守护程序 Kube-router,Kube-router 是 Kubernetes 软件包的一部分。引述 kubernetes 网站的话:“ Kube-router 的关键设计原则之一是使用标准 Linux 网络堆栈和工具集,没有 Overlay 或者 SDN,只有简单的老式Linux 网络因此它要精简得多。” Kube-router 使用 BGP 通告可达的容器地址,并使用 IPVS提供负载平衡。
当访间服务虚拟IP 地址时,采用IPVS 或 iptables 形式的负载均衡器,会将目的 IP地址从服务IP 地址重写为特定的 pod 的 IP 地址,从而将请求负载均衡到特定的pod上。当然,负载均衡器可确保从节点上访问该服务的所有后续流量都路由到同pod上。对于 pod 与 pod之间或 pod 与主机之间的那些 Kubernetes 基本通信限制,同样适用于外部实体访问服务。
在 Kubernetes 中使用Overlay网络不是一种性能好的解决方案,将默认网桥和路由模型一起使用是更简单,更高性能的方式。
小结
微服务和容器是云原生生态系统的组成部分,本章介绍了容器网络的各个方面。作为网络管理员或工程师,希望看到使用默认 Linux 网桥和不使用 NAT,允许同一主机上的容器相互通信所带来的好处。路由守护程序的使用可以轻松地将最佳单主机解决方案扩展到多主机容器网络。它们为 kubernetes 提供了快速且简单的网络。此外,基本 Linux 组件和路由的使用,允许容器、裸金属服务器和虚拟机之间无缝地进行通信,再次展示了路由技术是云原生数据中心和应用程序的关键基础技术

