- 1AI论文精读之CSPNet—— 一种加强CNN模型学习能力的主干网络
- 2spark—三层架构_控制层,服务层,持久层
- 3[转载]SAR影像斑点噪声及去噪方法
- 4Python+tkinter限制文本框中只能使用英文输入法
- 5基于STM32的电子时钟设计!!!_基于stm32的电子钟设计
- 6obsidian和bookmaster_obsidian bookmaster
- 7spring boot3整合spring AI组件_springboot集成spring ai
- 8Unity 有关属性的反射获取及赋值问题_unity getproperty
- 9虚拟机vmare16使用u盘装安装ghost系统_vm虚拟机16支持ghost吗
- 104 款好用到爆的 JSON 处理工具,极大提高效率!
【机器学习】9、最小二乘法和岭回归_最小二乘回归
赞
踩
一、最小二乘法(线性回归)
1.1 公式
1.2 矩阵
假设我们有n个样本数据,每个数据有p个特征值,然后p个特征值是线性关系。
即对应的线性模型

写成矩阵的形式即是Y=XA
由于样本与模型不一定百分百符合,存在一些噪声,即误差,用B表示,B也是一个向量
即B=Y-XA
Y为样本值,XA为模型的计算值,即期望值
误差平方的计算公式为:
e
=
∑
i
=
1
n
(
y
i
−
X
i
A
)
2
e=\sum_{i=1} ^n(y_i-X_iA)^2
e=i=1∑n(yi−XiA)2
其中,
X
i
X_i
Xi为行向量,
A
A
A为列向量。
最小二乘法的目标是取得最小的e对应的A,由于方差的计算是一个二次函数,即抛物线,所以对应存在一个最小值,即导数为0对应的A,所以对e求A的偏导数,再使其等于0,求解方程即可获得A。
将误差写为矩阵形式:
E = ( Y − X A ) ( Y − X A ) T E=(Y-XA)(Y-XA)^T E=(Y−XA)(Y−XA)T
矩阵求解:
关于最小二乘问题的求解,之前已有梯度下降法,还有比较快速的牛顿迭代,此处的最小二乘通过矩阵求导来计算,计算方式更加简洁高效,不需要大量的迭代,只需要解一个正规方程组。
矩阵的迹:矩阵主对角线上各个元素之和,也等于特征值的总和



有了上述7个定理,就可以求解最小二乘的解了,设:
那么进一步得到:
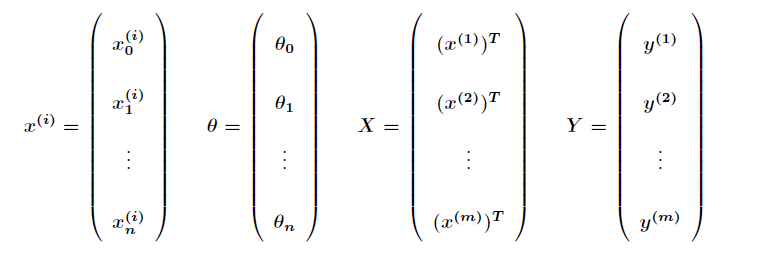

接下来会涉及到矩阵求导,因为
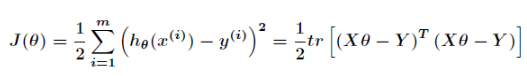
那么进一步利用矩阵求导并利用上述定理,得到
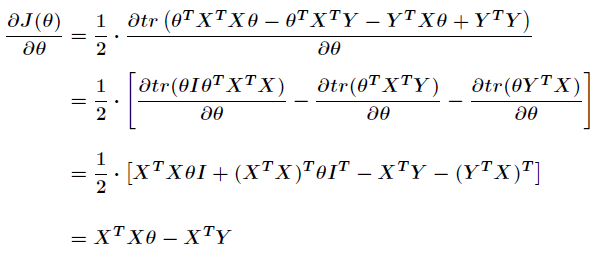
我们知道在极值点处梯度值为零,即
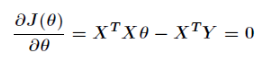
上述得到的方程组叫做正规方程组,那么最终得到:

这样最小二乘问题只需解一个线性方程组即可,不再需要像梯度下降那样迭代了。
奇异矩阵: ∣ A ∣ = 0 |A|=0 ∣A∣=0
非奇异矩阵: ∣ A ∣ ≠ 0 |A| \not= 0 ∣A∣=0
矩阵可逆的条件是矩阵非奇异,所以如果矩阵中有线性相关的列,也就是存在共线性,则无法求逆,只能求广义逆矩阵。
广义逆矩阵:
若A为非奇异矩阵,则线性方程组 A x = b Ax=b Ax=b的解为 x = A − 1 b x=A^{-1}b x=A−1b ,其中 A A A的逆矩阵 A − 1 A^{-1} A−1满足 A − 1 A = A A − 1 = I A^{-1}A=AA{-1}=I A−1A=AA−1=I( I I I为单位矩阵)。
若 A A A是奇异阵或长方阵, A x = b Ax=b Ax=b可能无解或有很多解。
若有解,则解为 x = X b + ( I − X A ) y x=Xb+(I-XA)y x=Xb+(I−XA)y ,其中у是维数与A的列数相同的任意向量,X是满足 A X A = A AXA=A AXA=A的任何一个矩阵,通常称X为A的广义逆矩阵,用 A g A^g Ag、 A − A^- A− 或 A 1 A^1 A1 等符号表示,有时简称广义逆。
当A非奇异时, A − 1 A^{-1} A−1 也满足 A A − 1 A = A AA^{-1}A=A AA−1A=A ,且 x = A − 1 b + ( I − A − 1 A ) y = A − 1 b x=A^{-1}b+(I-A^{-1}A)y=A^{-1}b x=A−1b+(I−A−1A)y=A−1b 。
故非奇异阵的广义逆矩阵就是它的逆矩阵,说明广义逆矩阵确是通常逆矩阵概念的推广。
当A的维数比Y的维数多,即样本数量n少于特征值p的时候,下式存在多个解,可能导致结果 θ = ( X T X ) − 1 X T Y \theta=(X^TX)^{-1}X^TY θ=(XTX)−1XTY很不稳定,所以要确保 n > p n>p n>p。
矩阵X不存在广义逆的情况有两种:
- X本身存在线性相关关系(即多重共线性),即矩阵非满秩(矩阵的值为0,存在多个解),
当采样值误差造成本身线性相关的样本矩阵仍然可以求出逆阵时,此时的逆阵非常不稳定,所求的解也没有什么意义。
- 当变量比样本多时,即p>n
这时,回归系数会变得很大,无法求解。在统计学上,可证明A的最小二乘解为无偏估计,即多次得到的采样值X而计算出来的多个系数估计值向量 的平均值将无限接近于真实值向量β。
为什么进行回归分析要消除共线性的影响:
-
X本身存在线性相关关系(多重共线性),即矩阵非满秩,表明在数据矩阵X中,至少有一个列向量可以用其余的列向量线性表示,则说明存在完全的多重共线性。也就是 ( X T X ) − 1 (X^TX)^{-1} (XTX)−1不存在。导致 θ = ( X T X ) − 1 X T Y \theta=(X^TX)^{-1}X^TY θ=(XTX)−1XTY无法估计。
-
进行回归分析需要了解每个自变量对因变量的单纯效应,多重共线性就是说自变量间存在某种函数关系,如果你的两个自变量间(X1和X2)存在函数关系,那么X1改变一个单位时,X2也会相应地改变,此时你无法做到固定其他条件,单独考查X1对因变量Y的作用,你所观察到的X1的效应总是混杂了X2的作用,这就造成了分析误差,使得对自变量效应的分析不准确,所以做回归分析时需要排除多重共线性的影响。
如何消除共线性:1.逐步回归,2.主成分回归,3.岭回归
1. 删除不重要的共线性变量
2. 增加样本容量
3. 对变量进行一定的变换(构造一个多重共线性变量的组合;把方程的函数形式转换为一阶差分形式)
4. 岭回归:
线性回归模型的基本假设满足时,用最小二乘法得到的回归系数估计量是无偏的且具有最小方差,即使在高度多重相关的情况下,最小二乘法的回归系数估计量依然是线性无偏的,且具有最小的方差,也就是说多重共线性并不影响最小二乘估计量的无偏性和最小方差性。因此在所有的线性无偏估计中,最小二乘估计仍然具有较小的方差,但这并不意味着最小二乘的估计量的方差一定是最小的,因为虽然它在所有线性无偏估计量中方差较小,但是该值确不一定是最好的。
于是就启发我们,是否可以找到一个有偏估计,使得虽然有微小的偏差,但其精度却能够大大高于无偏的估计量。岭回归就是一种放弃无偏估计性要求的方法。

此时估计量比普通最小二乘估计要稳定的多。
5. 主成分回归

1.3 代码实现
公式为:
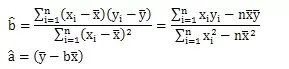
实际代码实现时,给 b 的分子分母同时乘以 n,如下:

代码实现如下:
//功能 : 最小二乘法直线拟合 y = a + b*x, 计算系数a 和 b
//参数 : x -- 辐照度的数组
// y -- 功率的数组
// num 是数组包含的元素个数,x[]和y[]的元素个数必须相等
// a,b 都是返回值
//返回 : 拟合计算成功返回true, 拟合计算失败返回false
//-------------------------------------------------------------
voud LeastSquareLinearFit(float x[], float y[], const int num, double &a, double &b)
{
uint64_t sum_x = 0;
uint64_t sum_y = 0;
uint64_t sum_x2 = 0;
uint64_t sum_xy = 0;
for(uint32_t i = 0; i < num; i++)
{
sum_x += x[i];
sum_y += y[i];
sum_x2 += x[i]*x[i];
sum_xy += x[i]*y[i];
}
a = (double)(sum_x2*sum_y - sum_x*sum_xy)/(double)(num*sum_x2-sum_x*sum_x); // 偏移
b = (double)(num*sum_xy - sum_x*sum_y)/(double)(num*sum_x2 - sum_x*sum_x); // 斜率
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
二、岭回归
当训练集足够大的时候,经验风险最小化能够保证得到很好的学习效果,当训练集较小时,会产生过拟合现象,虽然对训练数据的拟合程度高,但对未知数据的预测精度低,这样的模型不适用。
结构风险最小化是为了防止过拟合现象而提出的策略,结构风险最小化等价于正则化,在风险函数上加上表示模型复杂度的正则化项:
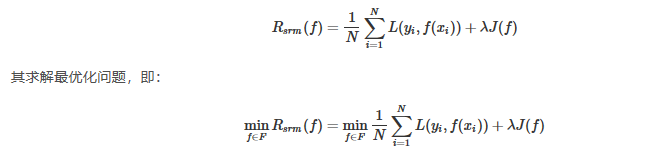
通过调节 λ \lambda λ值权衡经验风险和模型复杂度。
岭回归和Lasso,使用的是结构风险最小化的思想,在线性回归的基础上,加上对模型复杂度的约束。
岭回归:
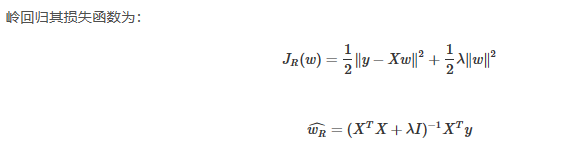
LASSO回归:
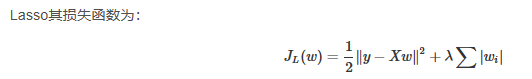
在原先的A的最小二乘估计中加一个小的扰动 λ I \lambda I λI,是原先无法求广义逆的情况变成可以求出广义逆,使得问题稳定并得以求解。
A ( λ ) = ( X T X + λ I ) − 1 X T Y A(\lambda)=(X^TX+\lambda I)^{-1}X^TY A(λ)=(XTX+λI)−1XTY
可以得到 ( X T X + λ I ) (X^TX+\lambda I) (XTX+λI)变为满秩矩阵,可以求得稳定的逆。
对应的推导过程如下:
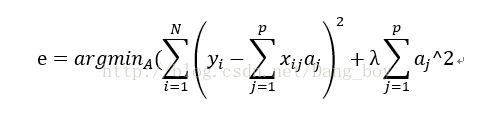
上式写为矩阵的形式为:
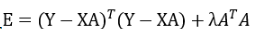
对上式子采用一样的方式(求A的偏导数=0)可得
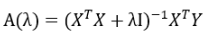
岭回归和最小二乘的区别在于:
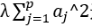
该项称为正则项,这一项可以看成是对A的各个元素,即各个特征的权的总体的平衡程度,也就是权之间的方差。
偏差:预测数据和真实数据的差距
方差:预测出来数据的分散程度
<img src=“https://img-blog.csdn.net/20180619171840747?”,width=60%,alt=“”/>
二维的情况下可以这样理解(RSS为误差):
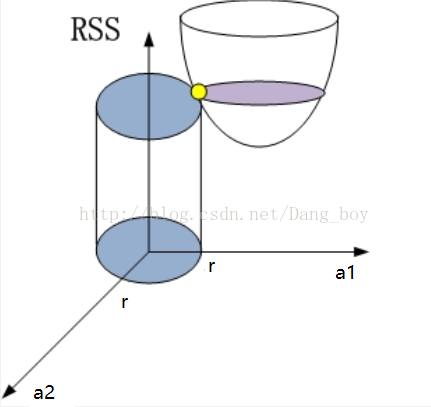
椭圆形抛物面为 ( y i − ∑ j = i p x i j a j ) 2 (y_i-\sum_{j=i}^p x_{ij}a_j)^2 (yi−∑j=ipxijaj)2,圆柱形为 λ ∑ j = 1 p a j 2 \lambda \sum_{j=1}^p a_j^2 λ∑j=1paj2,由最小二乘法求得的解释抛物面的最低点,由岭回归得到的是黄色的点,一般来说,拟合的误差值(偏差)越小,A的各个元素(权值)的方差越高,所以岭回归是找到一个方差不会太大,误差也不会太大的权衡的点,随着r增大,方差变大
岭回归的性质:
1)当岭参数为0,得到最小二乘解。
2)当岭参数λ趋向更大时,岭回归系数A估计趋向于0。
3)岭回归是回归参数A的有偏估计。它的结果是使得残差平和变大,但是会使系数检验变好。
4)在认为岭参数λ是与y无关的常数时,是最小二乘估计的一个线性变换,也是y的线性函数。
但在实际应用中,由于λ总是要通过数据确定,因此λ也依赖于y、因此从本质上说,并非的线性变换,也非y的线性函数。
5)对于回归系数向量来说,有偏估计回归系数向量长度<无偏估计回归系数向量长度。即
∣
∣
A
(
λ
)
∣
∣
<
∣
∣
A
∣
∣
||A(\lambda)||<||A||
∣∣A(λ)∣∣<∣∣A∣∣
6)存在某一个λ,使得它所对应的的MSE(估计向量的均方误差)<最小二乘法对应估计向量的的MSE。即 存在λ>0,使得
M
S
E
(
A
(
λ
)
)
<
M
S
E
(
A
)
MSE(A(\lambda))<MSE(A)
MSE(A(λ))<MSE(A)
岭迹图:
是λ的函数,岭迹图的横坐标为λ,纵坐标为A(λ)。而A(λ)是一个向量,由a1(λ)、a2(λ)、…等很多分量组成,每一个分量都是λ的函数,将每一个分量分别用一条线。
当不存在奇异性时,岭迹应是稳定地逐渐趋向于0
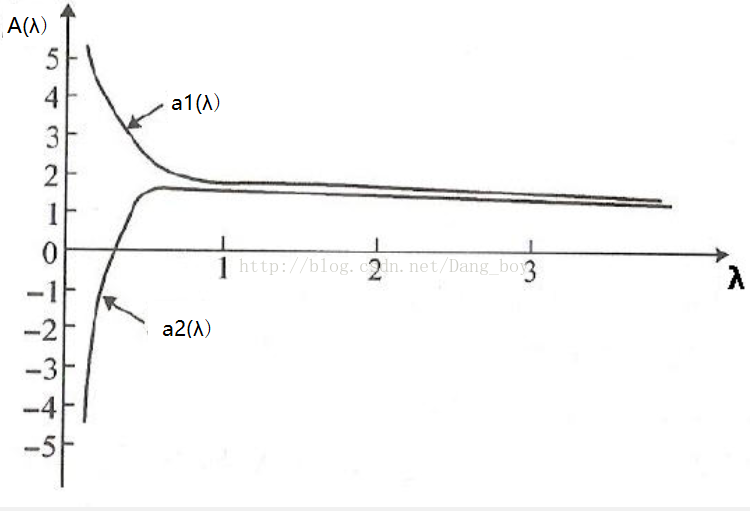
岭迹图作用:
1)观察λ较佳取值;
2)观察变量是否有多重共线性;
在λ很小时,A很大,且不稳定,当λ增大到一定程度时,A系数迅速缩小,趋于稳定。
λ的选择:一般通过观察,选取喇叭口附近的值,此时各β值已趋于稳定,但总的RSS又不是很大。
选择变量:删除那些β取值一直趋于0的变量。
三、LASSO回归:
LASSO回归和岭回归的区别只在于正则项不同
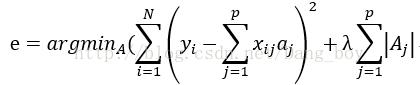
两者的区别对应到图形上则是
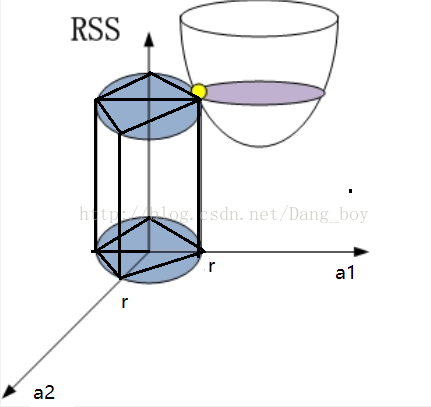
图片中的黑色粗线,即为一个底面为正方形的柱体与抛物面的交点
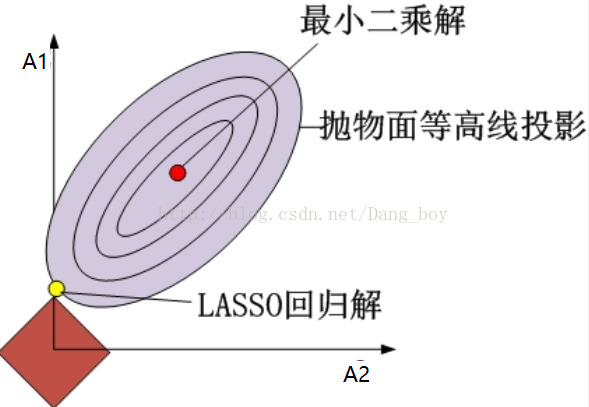
从投影图看则更加的直观,lasso更容易产生解为0的情况,可以起到筛选变量的目的。
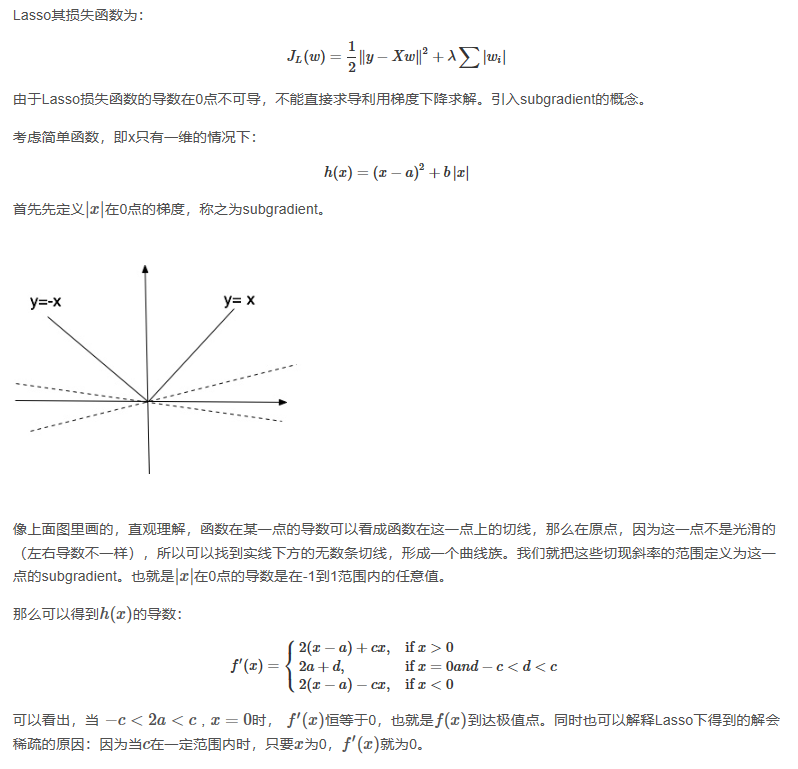
(次梯度方法(subgradient method)是传统的梯度下降方法的拓展,用来处理不可导的凸函数)