
热门标签
热门文章
- 1JNI中的log日志_jnilog1699437787981.txta
- 2人工智能和机器学习相关的比较活跃的论坛网址列表_人工智能论坛网站
- 3sklearn包中K近邻分类器 KNeighborsClassifier的使用_from sklearn.neighbors import kneighborsclassifier
- 4【demo】用opencv+qt识别人脸与眼睛_qt opencv获取瞳孔
- 5局域网安全17 dot1x
- 6androidStudio配置安装git以及下载项目_android studio从git上下载项目
- 7【Kafka】Kafka的重复消费和消息丢失问题_kafka重复消费
- 8使用STM32芯片ID作为MAC地址_0x1fff7a10
- 9韩国Meetup | Trias,区块链公链底层的一条“高速公路”
- 10如何在自定义数据集上训练YOLOv8的各个模型_yolov8训练示例
当前位置: article > 正文
毕业设计:python哔哩哔哩弹幕数据分析可视化系统 B站 bilibili 弹幕 Django框架(源码)✅_哔哩哔哩 弹幕 数据结构
作者:正经夜光杯 | 2024-06-26 07:05:28
赞
踩
哔哩哔哩 弹幕 数据结构
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业毕业设计项目实战6年之久,选择我们就是选择放心、选择安心毕业✌感兴趣的可以先收藏起来,点赞、关注不迷路✌
毕业设计:2023-2024年计算机毕业设计1000套(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕业设计选题汇总
1、项目介绍
技术栈:
Python语言、Django框架、Echarts可视化、requests爬虫、HTML
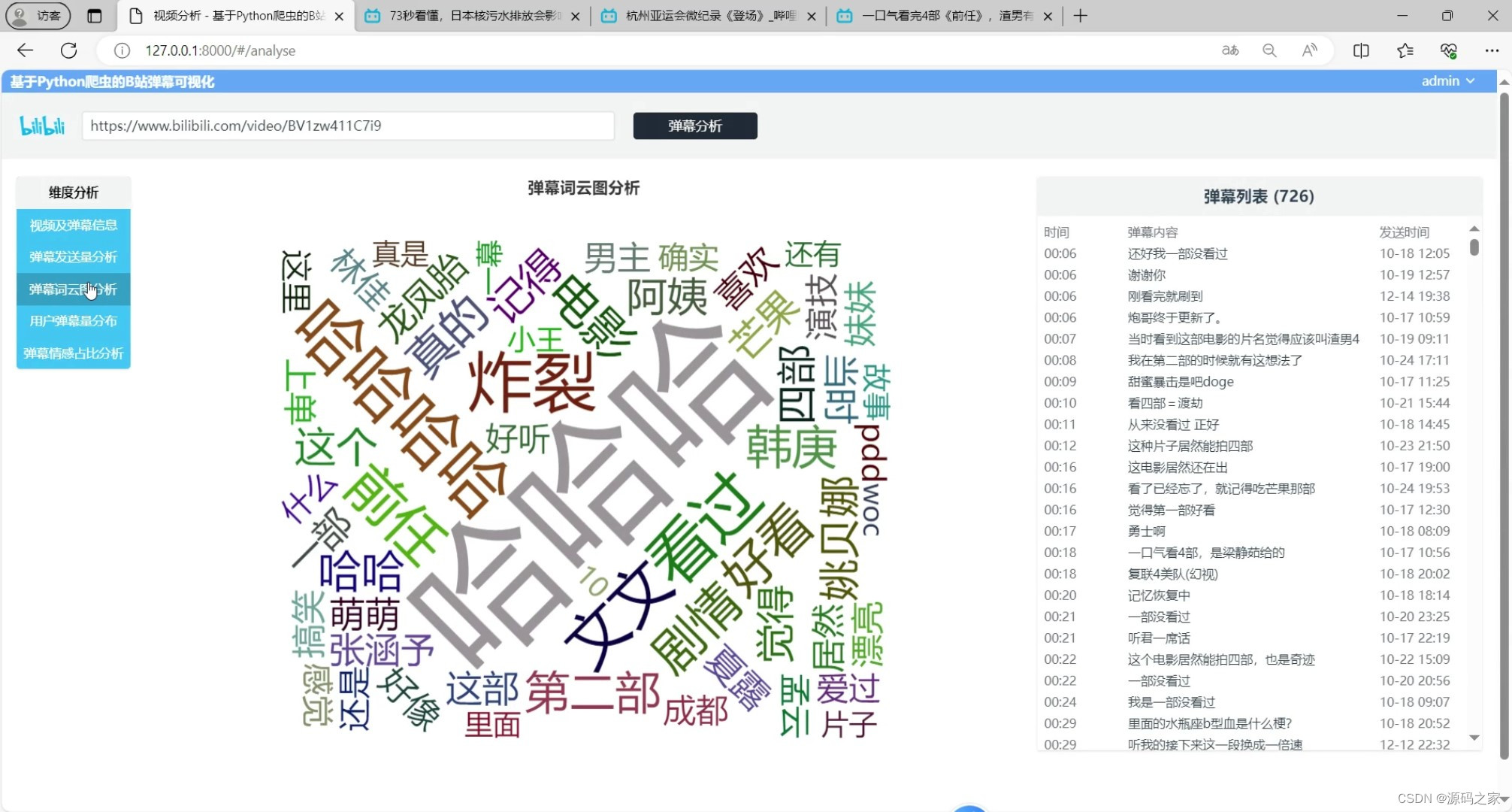
(1)B站弹幕词云图分析
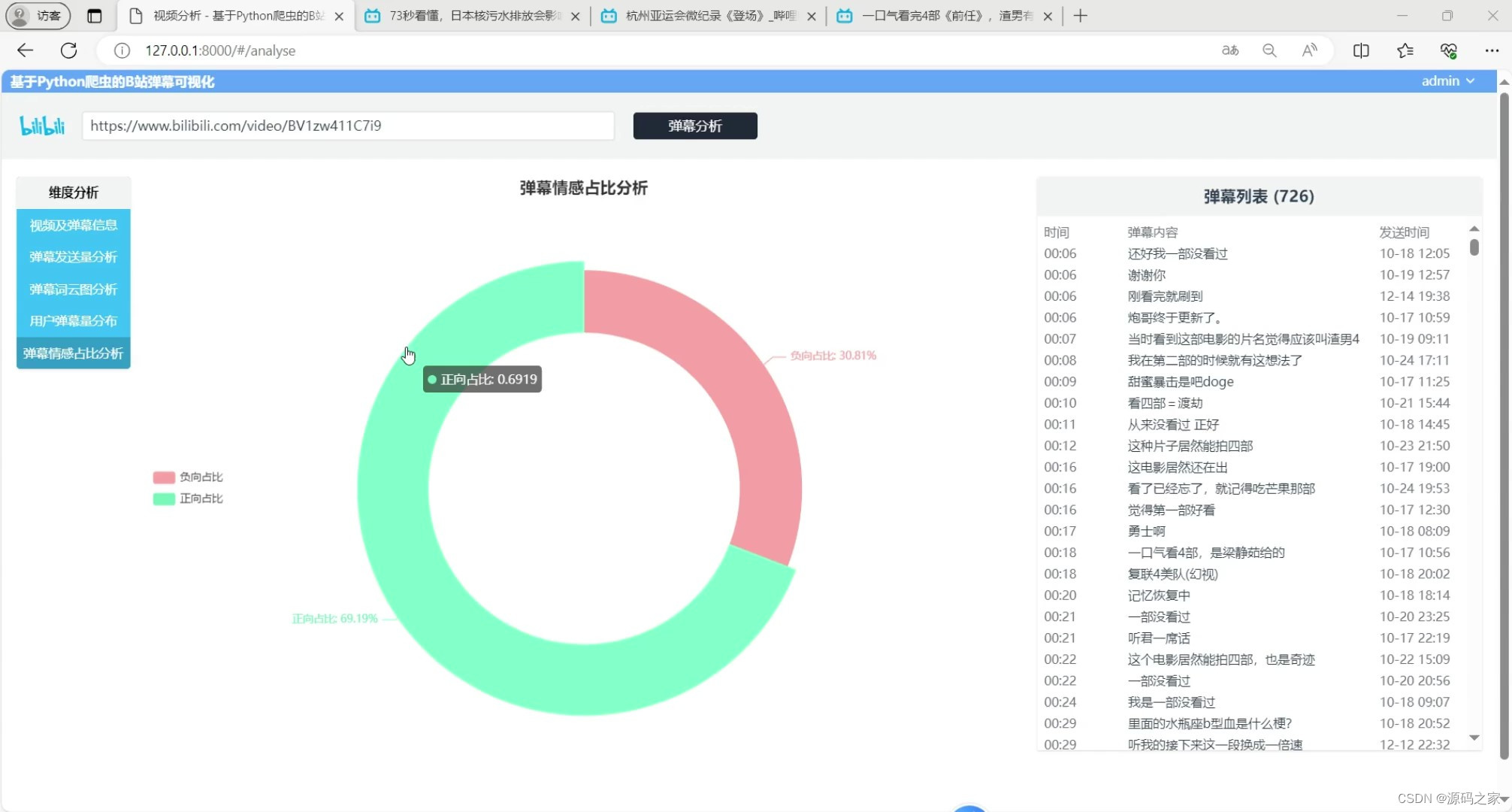
(2)B站弹幕情感占比分析
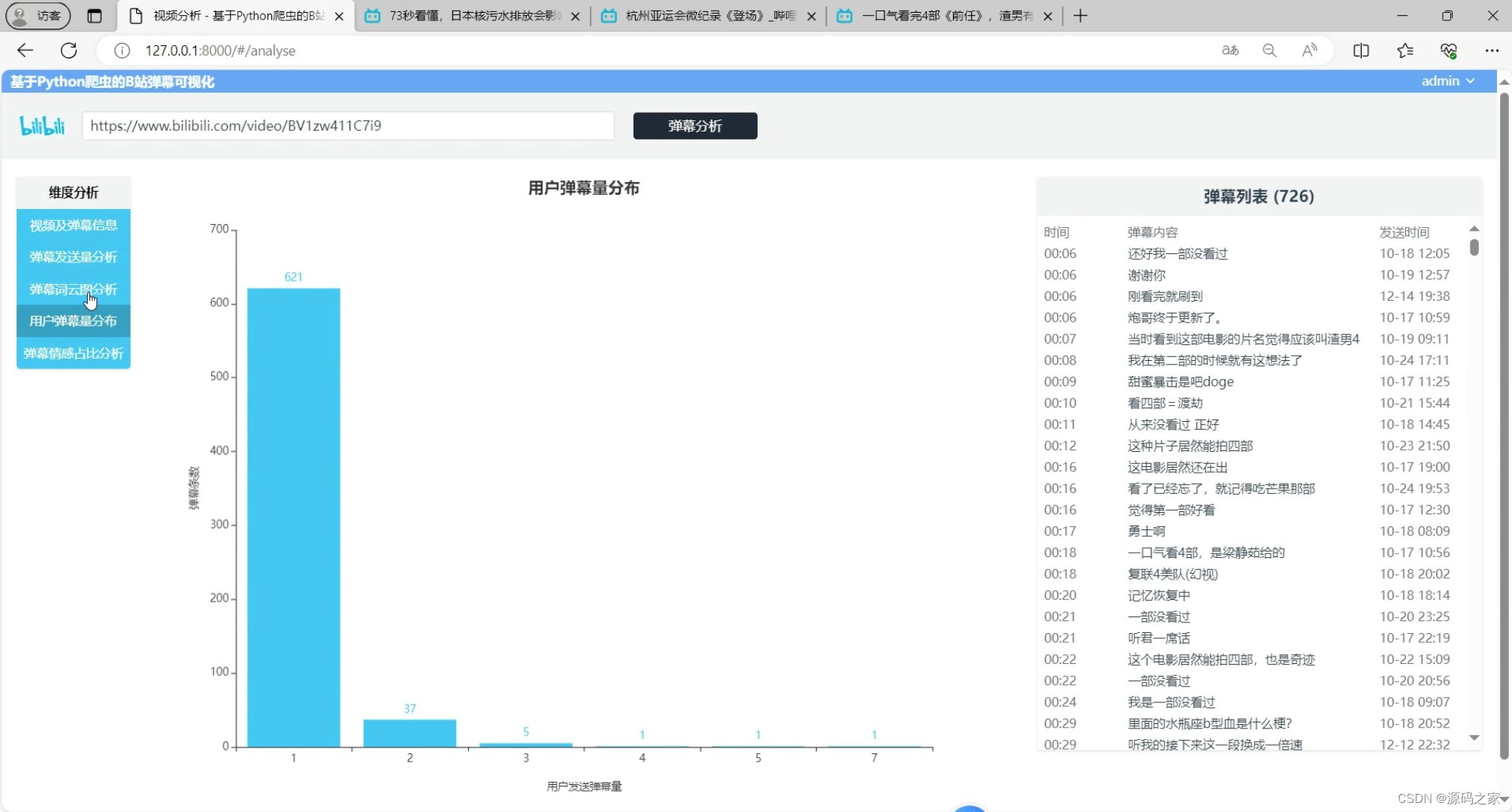
(3)用户弹幕数量分布
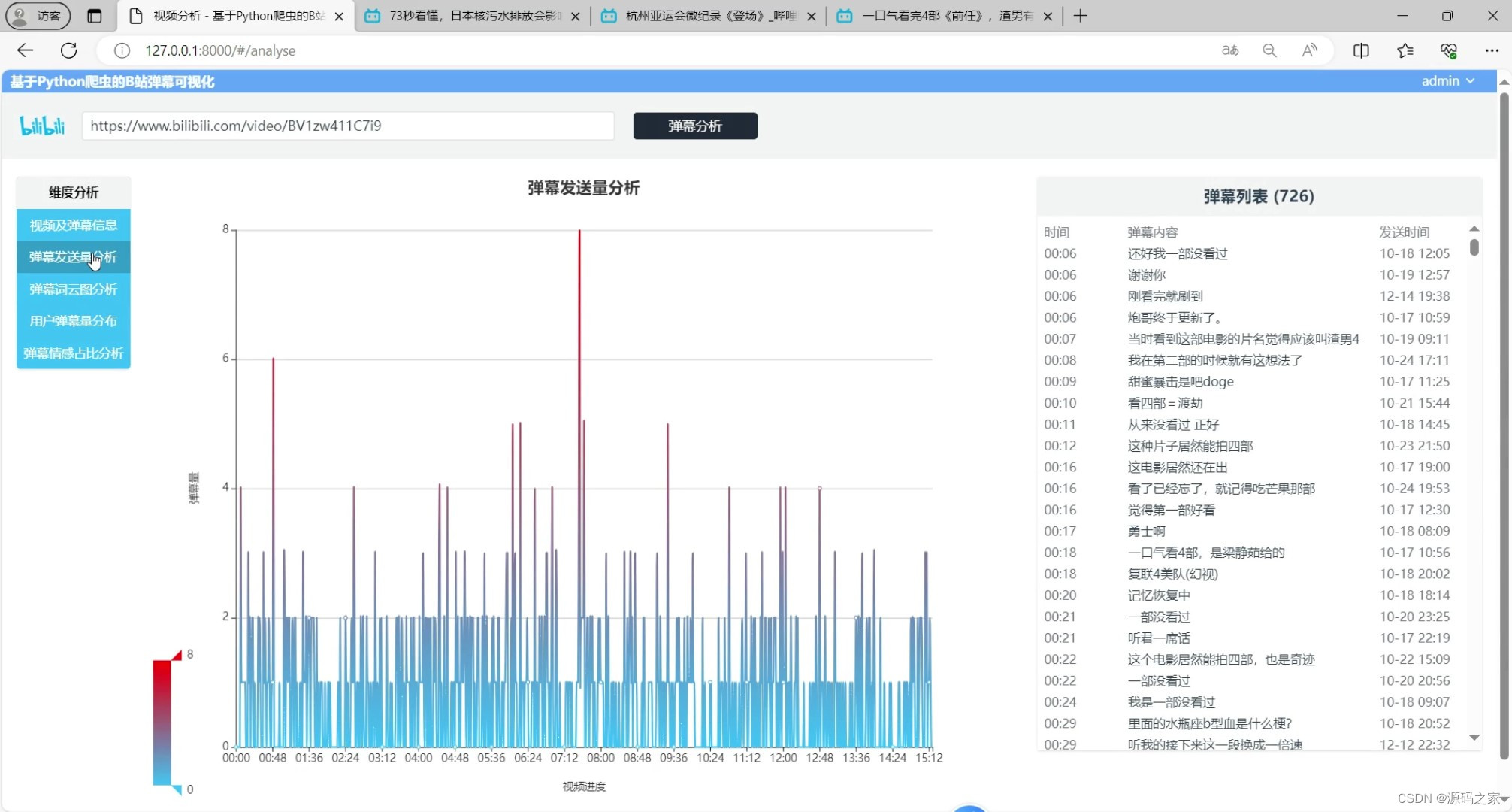
(4)弹幕不同时间发送量分析
(5)B站弹幕列表
(6)输入需要分析弹幕的B站视频链接
(7)后台管理
2、项目界面
(1)B站弹幕词云图分析
(2)B站弹幕情感占比分析
(3)用户弹幕数量分布
(4)弹幕不同时间发送量分析
(5)B站弹幕列表
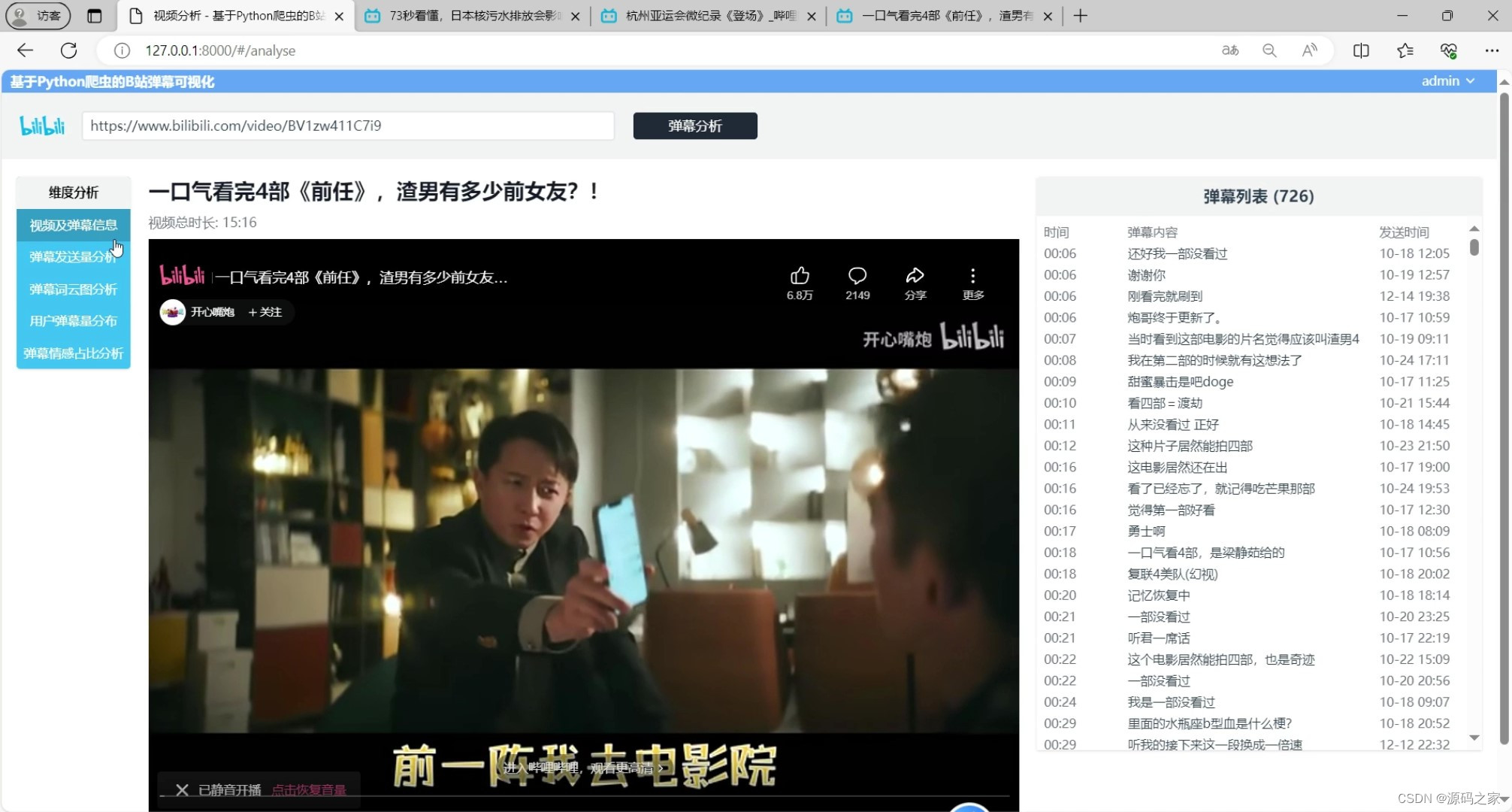
(6)输入需要分析弹幕的B站视频链接

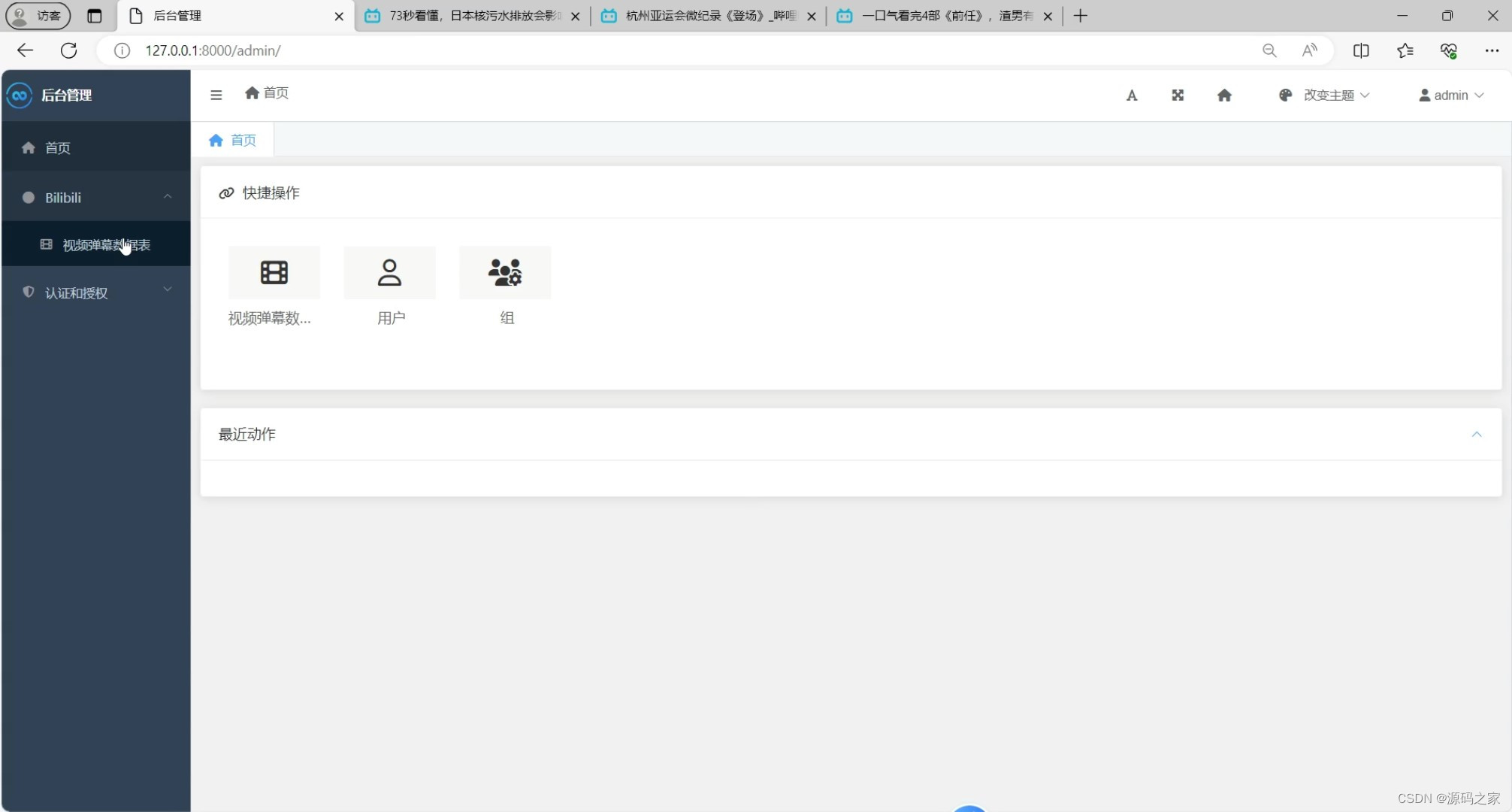
(7)后台管理
3、项目说明
随着互联网技术的快速发展,弹幕文化在视频分享平台如Bilibili(简称B站)上得到了广泛的应用。为了深入了解B站用户的弹幕行为,我们设计并开发了一款基于Python的B站弹幕分析可视化系统。该系统利用Django框架作为后端基础,结合requests爬虫获取B站弹幕数据,并使用Echarts进行数据可视化。同时,系统提供了HTML前端界面,让用户能够直观地查看和分析弹幕数据。
一、系统主要功能
B站弹幕词云图分析:系统通过爬虫从B站获取弹幕数据后,对弹幕文本进行分词和关键词提取,然后利用Echarts生成词云图。词云图以关键词出现频率为权重,直观地展示了弹幕中的热门话题和关注点。
B站弹幕情感占比分析:系统利用自然语言处理技术对弹幕进行情感分析,将弹幕分为积极、消极和中性三类。通过统计各类情感弹幕的数量,系统生成情感占比图,帮助用户了解用户对视频内容的情感态度。
用户弹幕数量分布:系统根据用户的弹幕发送量进行统计,生成用户弹幕数量分布图。这有助于了解不同用户在弹幕互动中的活跃度和参与度。
弹幕不同时间发送量分析:系统对弹幕的发送时间进行统计,生成弹幕发送量随时间变化的折线图。这有助于分析弹幕发送的高峰期和低谷期,以及用户在不同时间段的活跃度。
B站弹幕列表:系统提供弹幕列表功能,用户可以查看视频的弹幕内容、发送时间和发送者等信息。这有助于用户深入了解弹幕的具体内容和互动情况。
输入需要分析弹幕的B站视频链接:用户可以通过系统界面输入B站视频链接,系统将根据链接自动爬取该视频的弹幕数据并进行分析和可视化展示。
后台管理:系统提供后台管理功能,管理员可以对弹幕数据进行增删改查等操作,确保数据的准确性和安全性。
二、技术实现
本系统采用Python语言进行开发,利用Django框架构建后端系统。requests库用于实现B站弹幕数据的爬取,Echarts库则负责数据可视化。前端采用HTML进行界面展示,用户可以通过浏览器访问系统并查看分析结果。在数据处理方面,系统使用自然语言处理技术对弹幕进行分词、关键词提取和情感分析等操作,确保分析结果的准确性和可靠性。
总的来说,B站弹幕分析可视化系统通过结合Python语言、Django框架、requests爬虫、Echarts可视化和HTML等技术手段,实现了对B站弹幕数据的全面分析和可视化展示。该系统不仅有助于用户深入了解B站用户的弹幕行为和情感态度,也为B站运营和管理提供了有力的数据支持。
4、核心代码
from django.shortcuts import render from biliapi import get_danmaku from .models import Danmaku import json from django.http.response import JsonResponse, HttpResponse from pyecharts import options as opts from pyecharts.charts import Pie, Funnel, Bar, Scatter, Line, WordCloud, Map from jieba.analyse import extract_tags from bilibili import bd_sentiment, sentiment from collections import Counter from itertools import groupby def get_video_danmaku(request): data = request.json bvid = data.get("bvid") danmaku = Danmaku.objects.filter(bvid=bvid).first() if not danmaku: result = get_danmaku(bvid) danmaku, created = Danmaku.objects.get_or_create( bvid=bvid, defaults=dict(bvid=bvid, result=json.dumps(result, ensure_ascii=False)), ) result = json.loads(danmaku.result) result["bvid"] = danmaku.bvid return JsonResponse(result) def duration_format(d, fullduration=None): """ 视频时长格式化 :param d: 时长(秒数) :return: """ d = int(float(d)) result = [] hour = int(d / (60 * 60)) result.append("{:0>2}".format(hour)) dd = int(d % (60 * 60)) min = int(dd / 60) result.append("{:0>2}".format(min)) sec = int(dd % 60) result.append("{:0>2}".format(sec)) if fullduration and fullduration < 3600: return ":".join(result[1:]) elif d < 3600: return ":".join(result[1:]) return ":".join(result) def get_danmaku_line(request): bvid = request.json.get("bvid") danmaku = Danmaku.objects.filter(bvid=bvid).first() result = json.loads(danmaku.result) durations = dict([[duration_format(i), 0] for i in range(result["duration"] + 1)]) for i in result["danmaku"]: if "progress" in i: durations[duration_format(i["progress"] / 1000, result["duration"])] += 1 durations = list(durations.items()) durations.sort(key=lambda x: x[0]) max_ = max(durations, key=lambda x: x[1])[1] c = ( Line() .add_xaxis([i[0] for i in durations]) .add_yaxis( "每秒视频弹幕量", [i[1] for i in durations], is_smooth=True, label_opts=opts.LabelOpts(is_show=False), color="rgb(56, 189, 248)", linestyle_opts=opts.LineStyleOpts(width=2), ) .set_global_opts( title_opts=opts.TitleOpts(title="弹幕发送量分析", pos_left="center"), legend_opts=opts.LegendOpts(is_show=False), xaxis_opts=opts.AxisOpts( name="视频进度", name_location="center", name_gap=40, axispointer_opts=opts.AxisPointerOpts(is_show=True, type_="line"), ), yaxis_opts=opts.AxisOpts( name="弹幕量", name_location="center", name_gap=40, splitline_opts=opts.SplitLineOpts(is_show=True), ), visualmap_opts=opts.VisualMapOpts( range_color=["rgb(56, 189, 248)", "red"], max_=max_ ), ) ) return HttpResponse(c.dump_options(), content_type="application/json") def get_danmaku_wordcloud(request): bvid = request.json.get("bvid") danmaku = Danmaku.objects.filter(bvid=bvid).first() result = json.loads(danmaku.result) contentset = list(set([i["content"] for i in result["danmaku"]])) counter = extract_tags(" ".join(contentset), topK=200, withWeight=True) c = ( WordCloud() .add("", counter, word_size_range=[30, 160]) .set_global_opts( title_opts=opts.TitleOpts(title="弹幕词云图分析", pos_left="center"), legend_opts=opts.LegendOpts(is_show=False), ) ) return HttpResponse(c.dump_options(), content_type="aplication/json") def get_danmaku_pie(request): bvid = request.json.get("bvid") danmaku = Danmaku.objects.filter(bvid=bvid).first() result = json.loads(danmaku.result) contentset = list(set([i["content"] for i in result["danmaku"]])) content = " ".join(contentset) pos, neg = bd_sentiment(content[:2000]) # pos, neg = sentiment(content) result = [ ["负向占比", neg], ["正向占比", pos], ] c = ( Pie() .add( "", result, radius=["50%", "70%"], label_opts=opts.LabelOpts(formatter="{b}: {d}%"), ) .set_colors( [ "rgb(252, 165, 165)", "rgb(110, 231, 183)", ] ) .set_global_opts( title_opts=opts.TitleOpts("弹幕情感占比分析", pos_left="center"), legend_opts=opts.LegendOpts( is_show=True, pos_left="left", pos_top="center", orient="vertical" ), ) ) return HttpResponse(c.dump_options(), content_type="aplication/json") def get_danmaku_user_bar(request): bvid = request.json.get("bvid") danmaku = Danmaku.objects.filter(bvid=bvid).first() result = json.loads(danmaku.result) data = [ [num, len(list(arr))] for num, arr in groupby( sorted(list(Counter([i["midHash"] for i in result["danmaku"]]).values())) ) ] c = ( Bar() .add_xaxis([i[0] for i in data]) .add_yaxis( "", [i[1] for i in data], # bar_max_width=40, label_opts=opts.LabelOpts(position="top"), color="rgb(56, 189, 248)", ) .set_global_opts( title_opts=opts.TitleOpts(title="用户弹幕量分布", pos_left="center"), legend_opts=opts.LegendOpts(is_show=False), xaxis_opts=opts.AxisOpts( name="用户发送弹幕量", name_location="center", name_gap=40, axislabel_opts=opts.LabelOpts(), axispointer_opts=opts.AxisPointerOpts(is_show=True, type_="shadow"), ), yaxis_opts=opts.AxisOpts( name="弹幕条数", name_location="center", name_gap=40, ), ) ) return HttpResponse(c.dump_options(), content_type="aplication/json")

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/正经夜光杯/article/detail/758568
推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

