- 1网易终面:4款主流分布式MQ消息队列如何技术选型,2024年最新java电商购物车面试题_rabbitmq和rocketmq对比面试
- 2MySQL介绍_mysql是一个关系型数据库管理系统,用于存储、管理和检索数据。它能够处理大量的数
- 3解密Teradata与中国市场“分手”背后的原因!国产数据库能填补空白吗?_teradata 竞对
- 4访问网站显示不安全怎么办?教您不花一分钱解决!_此站点的连接不安全
- 5十、Git
- 6Python基础库-JSON库_python json库
- 7Unity中UGUI 图片实现鼠标拖拽功能以及松开复位_unity ui 拖拽
- 8基于SSM的图书借阅系统的开发与实现_基于ssm 技术路线
- 92024年最全该死!GitHub上这些C++项目真香_tbox c++,2024年最新卑微打工人_github上c++11开源项目
- 10智能合约与身份验证:区块链技术的创新应用_怎么通过区块链来管理报名某个项目过程中的信息和身份验证
Flink1.12-2021黑马 8 Flink高级特性和新特性_黑马flink
赞
踩
8.Flink高级特性和新特性
课程目标
掌握使用Flink-BroadcastState实现配置动态更新
了解端对端一次性语义
了解异步IO
了解Streaming file sink的使用
掌握FileSink的使用
掌握FlinkSQL整合Hive
https://developer.aliyun.com/article/780123?spm=a2c6h.12873581.0.0.1e3e46ccbYFFrC
1. BroadcastState(状态广播)
1.1 BroadcastState介绍
在开发过程中,如果遇到需要下发/广播配置、规则等低吞吐事件流到下游所有 task 时,就可以使用 Broadcast State。Broadcast State 是 Flink 1.5 引入的新特性。
下游的 task 接收这些配置、规则并保存为 BroadcastState, 将这些配置应用到另一个数据流的计算中 。
场景举例
1)动态更新计算规则: 如事件流需要根据最新的规则进行计算,则可将规则作为广播状态广播到下游Task中。
** ** 如事件流需要实时增加用户的基础信息,则可将用户的基础信息作为广播状态广播到下游Task中。
API介绍
首先创建一个Keyed 或Non-Keyed 的DataStream,
然后再创建一个BroadcastedStream,
最后通过DataStream来连接(调用connect 方法)到Broadcasted Stream 上,
这样实现将BroadcastState广播到Data Stream 下游的每个Task中。
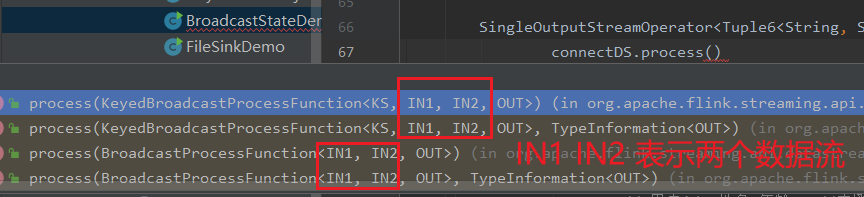
1.如果DataStream是Keyed Stream ,则连接到Broadcasted Stream 后, 添加处理ProcessFunction 时需要使用KeyedBroadcastProcessFunction 来实现, 下面是KeyedBroadcastProcessFunction 的API,代码如下所示:
public abstract class KeyedBroadcastProcessFunction<KS, IN1, IN2, OUT> extends BaseBroadcastProcessFunction {
public abstract void processElement(final IN1 value, final ReadOnlyContext ctx, final Collector<OUT> out) throws Exception;
public abstract void processBroadcastElement(final IN2 value, final Context ctx, final Collector<OUT> out) throws Exception;
}
- 1
- 2
- 3
- 4
上面泛型中的各个参数的含义,说明如下:
KS:表示Flink 程序从最上游的Source Operator 开始构建Stream,当调用keyBy 时所依赖的Key 的类型;
IN1:表示非Broadcast 的Data Stream 中的数据记录的类型;
IN2:表示Broadcast Stream 中的数据记录的类型;
OUT:表示经过KeyedBroadcastProcessFunction 的processElement()和processBroadcastElement()方法处理后输出结果数据记录的类型。
2.如果Data Stream 是Non-Keyed Stream,则连接到Broadcasted Stream 后,添加处理ProcessFunction 时需要使用BroadcastProcessFunction 来实现, 下面是BroadcastProcessFunction 的API,代码如下所示:
public abstract class BroadcastProcessFunction<IN1, IN2, OUT> extends BaseBroadcastProcessFunction {
public abstract void processElement(final IN1 value, final ReadOnlyContext ctx, final Collector<OUT> out) throws Exception;
public abstract void processBroadcastElement(final IN2 value, final Context ctx, final Collector<OUT> out) throws Exception;
}
- 1
- 2
- 3
- 4
上面泛型中的各个参数的含义,与前面KeyedBroadcastProcessFunction 的泛型类型中的后3 个含义相同,只是没有调用keyBy 操作对原始Stream 进行分区操作,就不需要KS 泛型参数。
具体如何使用上面的BroadcastProcessFunction,接下来我们会在通过实际编程,来以使用KeyedBroadcastProcessFunction 为例进行详细说明。
注意事项
- Broadcast State 是Map 类型,即K-V 类型。
- Broadcast State 只有在广播的一侧, 即在BroadcastProcessFunction 或KeyedBroadcastProcessFunction 的processBroadcastElement 方法中可以修改。在非广播的一侧, 即在BroadcastProcessFunction 或KeyedBroadcastProcessFunction 的processElement 方法中只读。
- Broadcast State 中元素的顺序,在各Task 中可能不同。基于顺序的处理,需要注意。
- Broadcast State 在Checkpoint 时,每个Task 都会Checkpoint 广播状态。
- Broadcast State 在运行时保存在内存中,目前还不能保存在RocksDB State Backend 中。
1.2 需求-实现配置动态更新
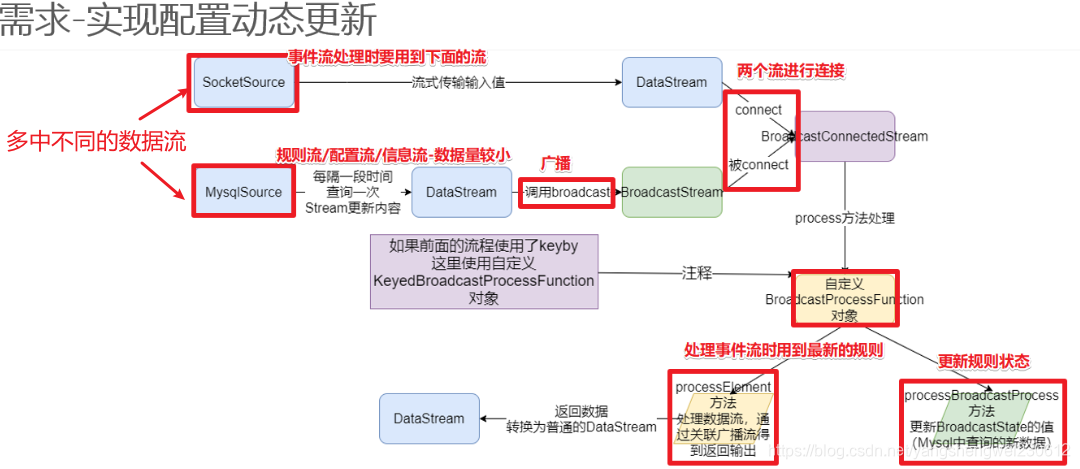
实时过滤出配置中的用户,并在事件流中补全这批用户的基础信息。
事件流:表示用户在某个时刻浏览或点击了某个商品,格式如下。
{"userID": "user_3", "eventTime": "2019-08-17 12:19:47", "eventType": "browse", "productID": 1}
{"userID": "user_2", "eventTime": "2019-08-17 12:19:48", "eventType": "click", "productID": 1}
- 1
- 2
配置数据: 表示用户的详细信息,在Mysql中,如下:
DROP TABLE IF EXISTS `user_info`;
CREATE TABLE `user_info` (
`userID` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`userName` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`userAge` int(11) NULL DEFAULT NULL,
PRIMARY KEY (`userID`) USING BTREE
) ENGINE = MyISAM CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of user_info
-- ----------------------------
INSERT INTO `user_info` VALUES ('user_1', '张三', 10);
INSERT INTO `user_info` VALUES ('user_2', '李四', 20);
INSERT INTO `user_info` VALUES ('user_3', '王五', 30);
INSERT INTO `user_info` VALUES ('user_4', '赵六', 40);
SET FOREIGN_KEY_CHECKS = 1;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
输出结果:
(user_3,2019-08-17 12:19:47,browse,1,王五,33)
(user_2,2019-08-17 12:19:48,click,1,李四,20)
- 1
- 2
1.3 编码步骤
1.env
2.source
-1.构建实时数据事件流-自定义随机
<userID, eventTime, eventType, productID>
-2.构建配置流-从MySQL
<用户id,<姓名,年龄>>
3.transformation
-1.定义状态描述器
MapStateDescriptor<Void, Map<String, Tuple2<String, Integer>>> descriptor =
new MapStateDescriptor<>(“config”,Types.VOID, Types.MAP(Types.STRING, Types.TUPLE(Types.STRING, Types.INT)));
-2.广播配置流
BroadcastStream<Map<String, Tuple2<String, Integer>>> broadcastDS = configDS.broadcast(descriptor);
-3.将事件流和广播流进行连接
BroadcastConnectedStream<Tuple4<String, String, String, Integer>, Map<String, Tuple2<String, Integer>>> connectDS =eventDS.connect(broadcastDS);
-4.处理连接后的流-根据配置流补全事件流中的用户的信息
4.sink
5.execute


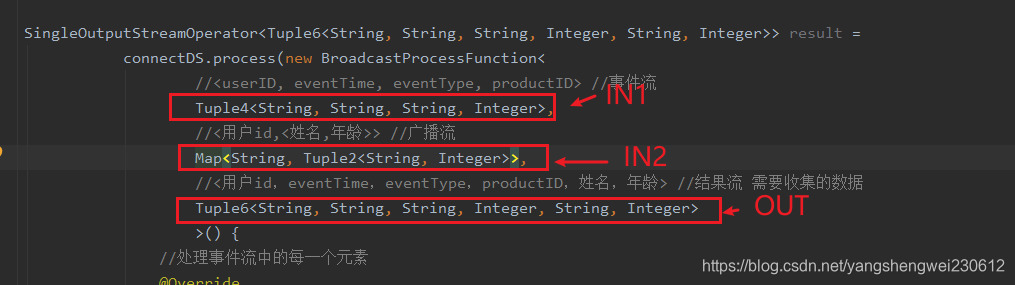
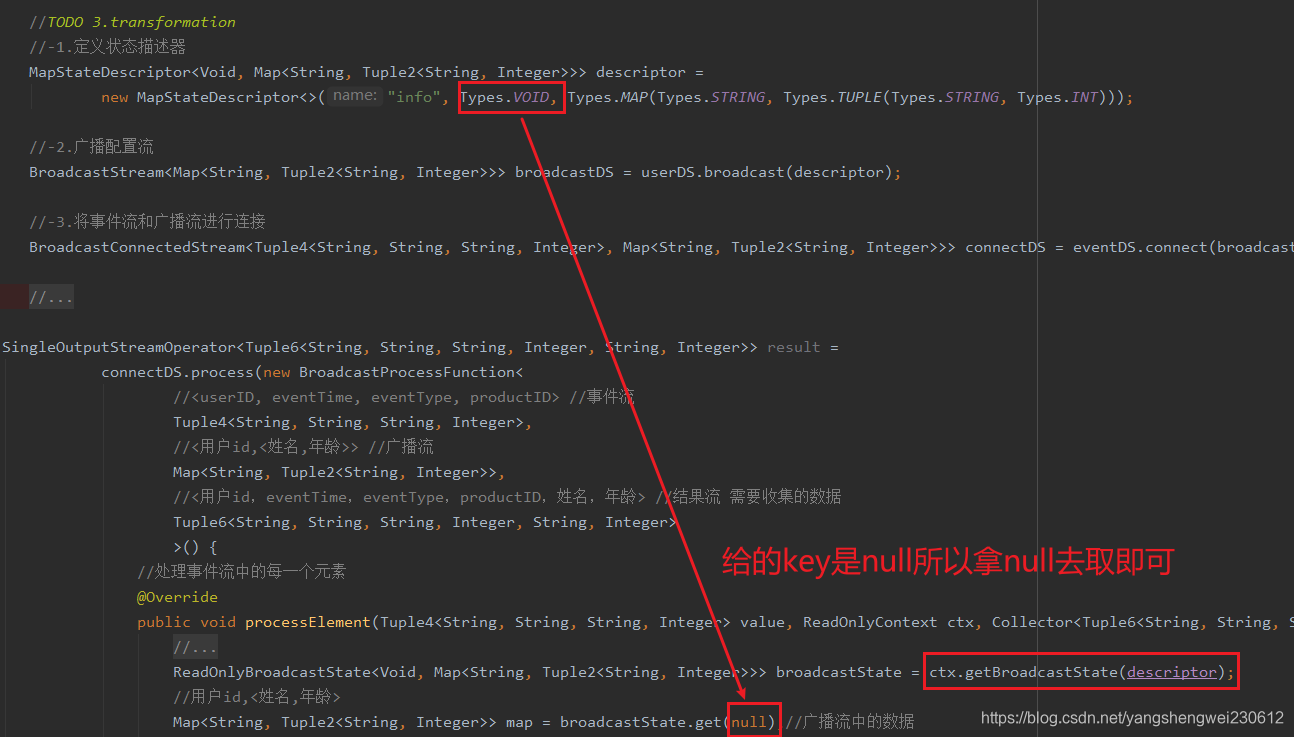
package cn.itcast.feature; import org.apache.flink.api.common.RuntimeExecutionMode; import org.apache.flink.api.common.state.BroadcastState; import org.apache.flink.api.common.state.MapStateDescriptor; import org.apache.flink.api.common.state.ReadOnlyBroadcastState; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.api.java.tuple.Tuple4; import org.apache.flink.api.java.tuple.Tuple6; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.datastream.BroadcastConnectedStream; import org.apache.flink.streaming.api.datastream.BroadcastStream; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.co.BroadcastProcessFunction; import org.apache.flink.streaming.api.functions.source.RichSourceFunction; import org.apache.flink.streaming.api.functions.source.SourceFunction; import org.apache.flink.util.Collector; import java.sql.Connection; import java.sql.DriverManager; import java.sql.PreparedStatement; import java.sql.ResultSet; import java.text.SimpleDateFormat; import java.util.Date; import java.util.HashMap; import java.util.Map; import java.util.Random; /** * Author itcast * Desc */ public class BroadcastStateDemo { public static void main(String[] args) throws Exception { //TODO 1.env StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC); env.setParallelism(1); //TODO 2.source //-1.构建实时数据事件流--数据量较大 //<userID, eventTime, eventType, productID> DataStreamSource<Tuple4<String, String, String, Integer>> eventDS = env.addSource(new MySource()); //-2.配置流/规则流/用户信息流--数据量较小-从MySQL //<用户id,<姓名,年龄>> DataStreamSource<Map<String, Tuple2<String, Integer>>> userDS = env.addSource(new MySQLSource()); //TODO 3.transformation //-1.定义状态描述器 MapStateDescriptor<Void, Map<String, Tuple2<String, Integer>>> descriptor = new MapStateDescriptor<>("info", Types.VOID, Types.MAP(Types.STRING, Types.TUPLE(Types.STRING, Types.INT))); //-2.广播配置流 BroadcastStream<Map<String, Tuple2<String, Integer>>> broadcastDS = userDS.broadcast(descriptor); //-3.将事件流和广播流进行连接 BroadcastConnectedStream<Tuple4<String, String, String, Integer>, Map<String, Tuple2<String, Integer>>> connectDS = eventDS.connect(broadcastDS); //-4.处理连接后的流-根据配置流补全事件流中的用户的信息 //BroadcastProcessFunction<IN1, IN2, OUT> SingleOutputStreamOperator<Tuple6<String, String, String, Integer, String, Integer>> result = connectDS.process(new BroadcastProcessFunction< //<userID, eventTime, eventType, productID> //事件流 Tuple4<String, String, String, Integer>, //<用户id,<姓名,年龄>> //广播流 Map<String, Tuple2<String, Integer>>, //<用户id,eventTime,eventType,productID,姓名,年龄> //结果流 需要收集的数据 Tuple6<String, String, String, Integer, String, Integer> >() { //处理事件流中的每一个元素 @Override public void processElement(Tuple4<String, String, String, Integer> value, ReadOnlyContext ctx, Collector<Tuple6<String, String, String, Integer, String, Integer>> out) throws Exception { //value就是事件流中的数据 //<userID, eventTime, eventType, productID> //事件流--已经有了 //Tuple4<String, String, String, Integer>, //目标是将value和广播流中的数据进行关联,返回结果流 //<用户id,<姓名,年龄>> //广播流--需要获取 //Map<String, Tuple2<String, Integer>> //<用户id,eventTime,eventType,productID,姓名,年龄> //结果流 需要收集的数据 // Tuple6<String, String, String, Integer, String, Integer> //获取广播流 ReadOnlyBroadcastState<Void, Map<String, Tuple2<String, Integer>>> broadcastState = ctx.getBroadcastState(descriptor); //用户id,<姓名,年龄> Map<String, Tuple2<String, Integer>> map = broadcastState.get(null);//广播流中的数据 if (map != null) { //根据value中的用户id去map中获取用户信息 String userId = value.f0; Tuple2<String, Integer> tuple2 = map.get(userId); String username = tuple2.f0; Integer age = tuple2.f1; //收集数据 out.collect(Tuple6.of(userId, value.f1, value.f2, value.f3, username, age)); } } //更新处理广播流中的数据 @Override public void processBroadcastElement(Map<String, Tuple2<String, Integer>> value, Context ctx, Collector<Tuple6<String, String, String, Integer, String, Integer>> out) throws Exception { //value就是从MySQL中每隔5是查询出来并广播到状态中的最新数据! //要把最新的数据放到state中 BroadcastState<Void, Map<String, Tuple2<String, Integer>>> broadcastState = ctx.getBroadcastState(descriptor); broadcastState.clear();//清空旧数据 broadcastState.put(null, value);//放入新数据 } }); //TODO 4.sink // result.print(); //TODO 5.execute env.execute(); } /** * 随机事件流--数据量较大 * 用户id,时间,类型,产品id * <userID, eventTime, eventType, productID> */ public static class MySource implements SourceFunction<Tuple4<String, String, String, Integer>> { private boolean isRunning = true; @Override public void run(SourceContext<Tuple4<String, String, String, Integer>> ctx) throws Exception { Random random = new Random(); SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); while (isRunning) { int id = random.nextInt(4) + 1; String user_id = "user_" + id; String eventTime = df.format(new Date()); String eventType = "type_" + random.nextInt(3); int productId = random.nextInt(4); ctx.collect(Tuple4.of(user_id, eventTime, eventType, productId)); Thread.sleep(500); } } @Override public void cancel() { isRunning = false; } } /** * 配置流/规则流/用户信息流--数据量较小 * <用户id,<姓名,年龄>> */ /* CREATE TABLE `user_info` ( `userID` varchar(20) NOT NULL, `userName` varchar(10) DEFAULT NULL, `userAge` int(11) DEFAULT NULL, PRIMARY KEY (`userID`) USING BTREE ) ENGINE=MyISAM DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC; INSERT INTO `user_info` VALUES ('user_1', '张三', 10); INSERT INTO `user_info` VALUES ('user_2', '李四', 20); INSERT INTO `user_info` VALUES ('user_3', '王五', 30); INSERT INTO `user_info` VALUES ('user_4', '赵六', 40); */ public static class MySQLSource extends RichSourceFunction<Map<String, Tuple2<String, Integer>>> { private boolean flag = true; private Connection conn = null; private PreparedStatement ps = null; private ResultSet rs = null; @Override public void open(Configuration parameters) throws Exception { conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata", "root", "root"); String sql = "select `userID`, `userName`, `userAge` from `user_info`"; ps = conn.prepareStatement(sql); } @Override public void run(SourceContext<Map<String, Tuple2<String, Integer>>> ctx) throws Exception { while (flag) { Map<String, Tuple2<String, Integer>> map = new HashMap<>(); ResultSet rs = ps.executeQuery(); while (rs.next()) { String userID = rs.getString("userID"); String userName = rs.getString("userName"); int userAge = rs.getInt("userAge"); //Map<String, Tuple2<String, Integer>> map.put(userID, Tuple2.of(userName, userAge)); } ctx.collect(map); Thread.sleep(5000);//每隔5s更新一下用户的配置信息! } } @Override public void cancel() { flag = false; } @Override public void close() throws Exception { if (conn != null) conn.close(); if (ps != null) ps.close(); if (rs != null) rs.close(); } } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
2. 双流Join(将两个数据源关联到一起)
2.1 介绍
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/stream/operators/joining.html
https://zhuanlan.zhihu.com/p/340560908
https://blog.csdn.net/andyonlines/article/details/108173259

双流Join是Flink面试的高频问题。一般情况下说明以下几点就可以hold了:
Join大体分类只有两种:Window Join和Interval Join。
Window Join又可以根据Window的类型细分出3种:
Tumbling Window Join、Sliding Window Join、Session Widnow Join。
Windows类型的join都是利用window的机制,先将数据缓存在Window State中,当窗口触发计算时,执行join操作;
interval join也是利用state存储数据再处理,区别在于state中的数据有失效机制,依靠数据触发数据清理;
目前Stream join的结果是数据的笛卡尔积;
2.2 Window Join
Tumbling Window Join (滚动窗口(没有重复数据)的的join)
执行翻滚窗口联接时,具有公共键和公共翻滚窗口的所有元素将作为成对组合联接,并传递给JoinFunction或FlatJoinFunction。因为它的行为类似于内部连接,所以一个流中的元素在其滚动窗口中没有来自另一个流的元素,因此不会被发射!
如图所示,我们定义了一个大小为2毫秒的翻滚窗口,结果窗口的形式为[0,1]、[2,3]、。。。。该图显示了每个窗口中所有元素的成对组合,这些元素将传递给JoinFunction。注意,在翻滚窗口[6,7]中没有发射任何东西,因为绿色流中不存在与橙色元素⑥和⑦结合的元素。


import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
...
DataStream<Integer> orangeStream = ...DataStream<Integer> greenStream = ...
orangeStream.join(greenStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(TumblingEventTimeWindows.of(Time.milliseconds(2)))
.apply (new JoinFunction<Integer, Integer, String> (){
@Override
public String join(Integer first, Integer second) {
return first + "," + second;
}
});
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
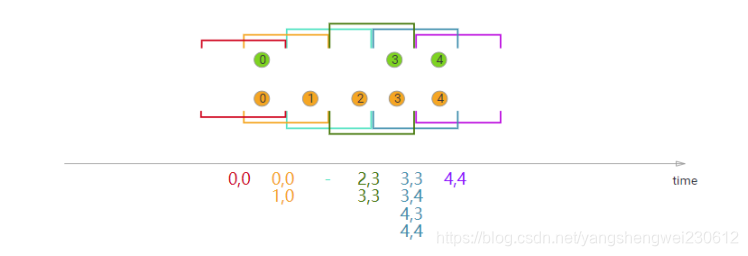
Sliding Window Join (滑动窗口(有重复数据)的的join)
在执行滑动窗口联接时,具有公共键和公共滑动窗口的所有元素将作为成对组合联接,并传递给JoinFunction或FlatJoinFunction。在当前滑动窗口中,一个流的元素没有来自另一个流的元素,则不会发射!请注意,某些元素可能会连接到一个滑动窗口中,但不会连接到另一个滑动窗口中!
在本例中,我们使用大小为2毫秒的滑动窗口,并将其滑动1毫秒,从而产生滑动窗口[-1,0],[0,1],[1,2],[2,3]…。x轴下方的连接元素是传递给每个滑动窗口的JoinFunction的元素。在这里,您还可以看到,例如,在窗口[2,3]中,橙色②与绿色③连接,但在窗口[1,2]中没有与任何对象连接。
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
...
DataStream<Integer> orangeStream = ...DataStream<Integer> greenStream = ...
orangeStream.join(greenStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(SlidingEventTimeWindows.of(Time.milliseconds(2) /* size */, Time.milliseconds(1) /* slide */))
.apply (new JoinFunction<Integer, Integer, String> (){
@Override
public String join(Integer first, Integer second) {
return first + "," + second;
}
});
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
session Window Join
在执行会话窗口联接时,具有相同键(当“组合”时满足会话条件)的所有元素以成对组合方式联接,并传递给JoinFunction或FlatJoinFunction。同样,这执行一个内部连接,所以如果有一个会话窗口只包含来自一个流的元素,则不会发出任何输出!
在这里,我们定义了一个会话窗口连接,其中每个会话被至少1ms的间隔分割。有三个会话,在前两个会话中,来自两个流的连接元素被传递给JoinFunction。在第三个会话中,绿色流中没有元素,所以⑧和⑨没有连接!
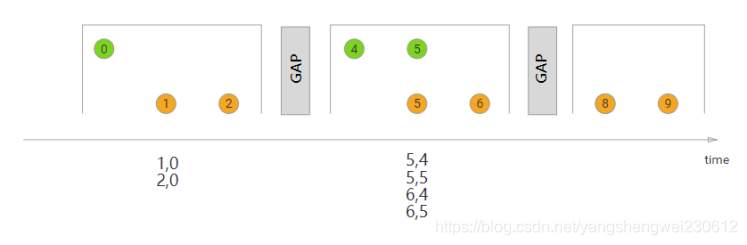
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.windowing.assigners.EventTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
...
DataStream<Integer> orangeStream = ...DataStream<Integer> greenStream = ...
orangeStream.join(greenStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(EventTimeSessionWindows.withGap(Time.milliseconds(1)))
.apply (new JoinFunction<Integer, Integer, String> (){
@Override
public String join(Integer first, Integer second) {
return first + "," + second;
}
});
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
2.3 Interval Join

前面学习的Window Join必须要在一个Window中进行JOIN,那如果没有Window如何处理呢?
interval join也是使用相同的key来join两个流(流A、流B),
并且流B中的元素中的时间戳,和流A元素的时间戳,有一个时间间隔。
b.timestamp ∈ [a.timestamp + lowerBound; a.timestamp + upperBound]
or
a.timestamp + lowerBound <= b.timestamp <= a.timestamp + upperBound
也就是:
流B的元素的时间戳 ≥ 流A的元素时间戳 + 下界,且,流B的元素的时间戳 ≤ 流A的元素时间戳 + 上界。
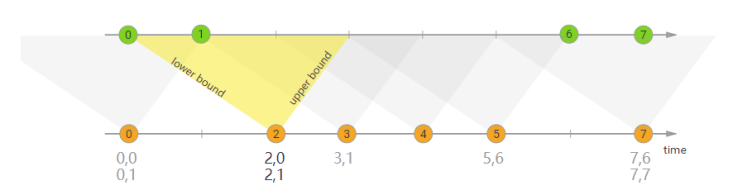
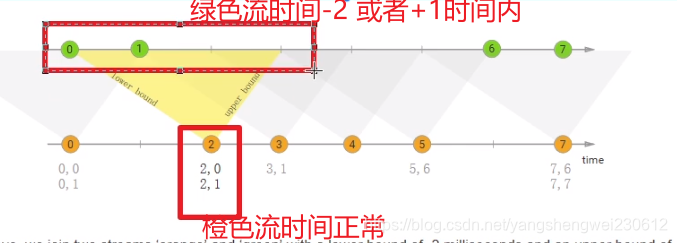
在上面的示例中,我们将两个流“orange”和“green”连接起来,其下限为-2毫秒,上限为+1毫秒。默认情况下,这些边界是包含的,但是可以应用.lowerBoundExclusive()和.upperBoundExclusive来更改行为
orangeElem.ts + lowerBound <= greenElem.ts <= orangeElem.ts + upperBound

橙色流等绿色流
import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.streaming.api.functions.co.ProcessJoinFunction; import org.apache.flink.streaming.api.windowing.time.Time; ... DataStream<Integer> orangeStream = ...DataStream<Integer> greenStream = ... orangeStream .keyBy(<KeySelector>) .intervalJoin(greenStream.keyBy(<KeySelector>)) .between(Time.milliseconds(-2), Time.milliseconds(1)) .process (new ProcessJoinFunction<Integer, Integer, String(){ @Override public void processElement(Integer left, Integer right, Context ctx, Collector<String> out) { out.collect(first + "," + second); } });
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
2.4 代码演示 Window Join
需求
来做个案例:
使用两个指定Source模拟数据,一个Source是订单明细,一个Source是商品数据。我们通过window join,将数据关联到一起。
思路
1、Window Join首先需要使用where和equalTo指定使用哪个key来进行关联,此处我们通过应用方法,基于GoodsId来关联两个流中的元素。
2、设置5秒的滚动窗口,流的元素关联都会在这个5秒的窗口中进行关联。
3、apply方法中实现将两个不同类型的元素关联并生成一个新类型的元素。
package cn.itcast.extend; import com.alibaba.fastjson.JSON; import lombok.Data; import org.apache.flink.api.common.eventtime.*; import org.apache.flink.api.common.typeinfo.TypeInformation; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.source.RichSourceFunction; import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; import java.math.BigDecimal; import java.util.ArrayList; import java.util.List; import java.util.Random; import java.util.UUID; import java.util.concurrent.TimeUnit; /** * Author itcast * Desc */ public class JoinDemo01 { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 构建商品数据流 DataStream<Goods> goodsDS = env.addSource(new GoodsSource11(), TypeInformation.of(Goods.class)).assignTimestampsAndWatermarks(new GoodsWatermark()); // 构建订单明细数据流 DataStream<OrderItem> orderItemDS = env.addSource(new OrderItemSource(), TypeInformation.of(OrderItem.class)).assignTimestampsAndWatermarks(new OrderItemWatermark()); // 进行关联查询 DataStream<FactOrderItem> factOrderItemDS = orderItemDS.join(goodsDS) // 第一个流orderItemDS .where(OrderItem::getGoodsId) // 第二流goodsDS .equalTo(Goods::getGoodsId) .window(TumblingEventTimeWindows.of(Time.seconds(5))) .apply((OrderItem item, Goods goods) -> { FactOrderItem factOrderItem = new FactOrderItem(); factOrderItem.setGoodsId(goods.getGoodsId()); factOrderItem.setGoodsName(goods.getGoodsName()); factOrderItem.setCount(new BigDecimal(item.getCount())); factOrderItem.setTotalMoney(goods.getGoodsPrice().multiply(new BigDecimal(item.getCount()))); return factOrderItem; }); factOrderItemDS.print(); env.execute("滚动窗口JOIN"); } //商品类 @Data public static class Goods { private String goodsId; private String goodsName; private BigDecimal goodsPrice; public static List<Goods> GOODS_LIST; public static Random r; static { r = new Random(); GOODS_LIST = new ArrayList<>(); GOODS_LIST.add(new Goods("1", "小米12", new BigDecimal(4890))); GOODS_LIST.add(new Goods("2", "iphone12", new BigDecimal(12000))); GOODS_LIST.add(new Goods("3", "MacBookPro", new BigDecimal(15000))); GOODS_LIST.add(new Goods("4", "Thinkpad X1", new BigDecimal(9800))); GOODS_LIST.add(new Goods("5", "MeiZu One", new BigDecimal(3200))); GOODS_LIST.add(new Goods("6", "Mate 40", new BigDecimal(6500))); } public static Goods randomGoods() { int rIndex = r.nextInt(GOODS_LIST.size()); return GOODS_LIST.get(rIndex); } public Goods() { } public Goods(String goodsId, String goodsName, BigDecimal goodsPrice) { this.goodsId = goodsId; this.goodsName = goodsName; this.goodsPrice = goodsPrice; } @Override public String toString() { return JSON.toJSONString(this); } } //订单明细类 @Data public static class OrderItem { private String itemId; private String goodsId; private Integer count; @Override public String toString() { return JSON.toJSONString(this); } } //关联结果 @Data public static class FactOrderItem { private String goodsId; private String goodsName; private BigDecimal count; private BigDecimal totalMoney; @Override public String toString() { return JSON.toJSONString(this); } } //构建一个商品Stream源(这个好比就是维表) public static class GoodsSource11 extends RichSourceFunction { private Boolean isCancel; @Override public void open(Configuration parameters) throws Exception { isCancel = false; } @Override public void run(SourceContext sourceContext) throws Exception { while(!isCancel) { Goods.GOODS_LIST.stream().forEach(goods -> sourceContext.collect(goods)); TimeUnit.SECONDS.sleep(1); } } @Override public void cancel() { isCancel = true; } } //构建订单明细Stream源 public static class OrderItemSource extends RichSourceFunction { private Boolean isCancel; private Random r; @Override public void open(Configuration parameters) throws Exception { isCancel = false; r = new Random(); } @Override public void run(SourceContext sourceContext) throws Exception { while(!isCancel) { Goods goods = Goods.randomGoods(); OrderItem orderItem = new OrderItem(); orderItem.setGoodsId(goods.getGoodsId()); orderItem.setCount(r.nextInt(10) + 1); orderItem.setItemId(UUID.randomUUID().toString()); sourceContext.collect(orderItem); orderItem.setGoodsId("111"); sourceContext.collect(orderItem); TimeUnit.SECONDS.sleep(1); } } @Override public void cancel() { isCancel = true; } } //构建水印分配器(此处为了简单),直接使用系统时间了 public static class GoodsWatermark implements WatermarkStrategy<Goods> { @Override public TimestampAssigner<Goods> createTimestampAssigner(TimestampAssignerSupplier.Context context) { return (element, recordTimestamp) -> System.currentTimeMillis(); } @Override public WatermarkGenerator<Goods> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context) { return new WatermarkGenerator<Goods>() { @Override public void onEvent(Goods event, long eventTimestamp, WatermarkOutput output) { output.emitWatermark(new Watermark(System.currentTimeMillis())); } @Override public void onPeriodicEmit(WatermarkOutput output) { output.emitWatermark(new Watermark(System.currentTimeMillis())); } }; } } public static class OrderItemWatermark implements WatermarkStrategy<OrderItem> { @Override public TimestampAssigner<OrderItem> createTimestampAssigner(TimestampAssignerSupplier.Context context) { return (element, recordTimestamp) -> System.currentTimeMillis(); } @Override public WatermarkGenerator<OrderItem> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context) { return new WatermarkGenerator<OrderItem>() { @Override public void onEvent(OrderItem event, long eventTimestamp, WatermarkOutput output) { output.emitWatermark(new Watermark(System.currentTimeMillis())); } @Override public void onPeriodicEmit(WatermarkOutput output) { output.emitWatermark(new Watermark(System.currentTimeMillis())); } }; } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
2.5 代码演示 interval join
1、通过keyBy将两个流join到一起
2、interval join需要设置流A去关联哪个时间范围的流B中的元素。此处,我设置的下界为-1、上界为0,且上界是一个开区间。表达的意思就是流A中某个元素的时间,对应上一秒的流B中的元素。
3、process中将两个key一样的元素,关联在一起,并加载到一个新的FactOrderItem对象中
package cn.itcast.feature; import com.alibaba.fastjson.JSON; import lombok.Data; import org.apache.flink.api.common.RuntimeExecutionMode; import org.apache.flink.api.common.eventtime.*; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.co.ProcessJoinFunction; import org.apache.flink.streaming.api.functions.source.RichSourceFunction; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.util.Collector; import java.math.BigDecimal; import java.util.ArrayList; import java.util.List; import java.util.Random; import java.util.UUID; import java.util.concurrent.TimeUnit; /** * Author itcast * Desc 演示Flink双流Join-IntervalJoin */ public class JoinDemo02_IntervalJoin { public static void main(String[] args) throws Exception { //TODO 0.env StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC); //TODO 1.source //商品数据流 DataStreamSource<Goods> goodsDS = env.addSource(new GoodsSource()); //订单数据流 DataStreamSource<OrderItem> OrderItemDS = env.addSource(new OrderItemSource()); //给数据添加水印(这里简单一点直接使用系统时间作为事件时间) /* SingleOutputStreamOperator<Order> orderDSWithWatermark = orderDS.assignTimestampsAndWatermarks( WatermarkStrategy.<Order>forBoundedOutOfOrderness(Duration.ofSeconds(3))//指定maxOutOfOrderness最大无序度/最大允许的延迟时间/乱序时间 .withTimestampAssigner((order, timestamp) -> order.getEventTime())//指定事件时间列 ); */ SingleOutputStreamOperator<Goods> goodsDSWithWatermark = goodsDS.assignTimestampsAndWatermarks(new GoodsWatermark()); SingleOutputStreamOperator<OrderItem> OrderItemDSWithWatermark = OrderItemDS.assignTimestampsAndWatermarks(new OrderItemWatermark()); //TODO 2.transformation---这里是重点 //商品类(商品id,商品名称,商品价格) //订单明细类(订单id,商品id,商品数量) //关联结果(商品id,商品名称,商品数量,商品价格*商品数量) SingleOutputStreamOperator<FactOrderItem> resultDS = goodsDSWithWatermark.keyBy(Goods::getGoodsId) .intervalJoin(OrderItemDSWithWatermark.keyBy(OrderItem::getGoodsId)) //join的条件: // 条件1.id要相等 // 条件2. OrderItem的时间戳 - 2 <=Goods的时间戳 <= OrderItem的时间戳 + 1 .between(Time.seconds(-2), Time.seconds(1)) //ProcessJoinFunction<IN1, IN2, OUT> .process(new ProcessJoinFunction<Goods, OrderItem, FactOrderItem>() { @Override public void processElement(Goods left, OrderItem right, Context ctx, Collector<FactOrderItem> out) throws Exception { FactOrderItem result = new FactOrderItem(); result.setGoodsId(left.getGoodsId()); result.setGoodsName(left.getGoodsName()); result.setCount(new BigDecimal(right.getCount())); result.setTotalMoney(new BigDecimal(right.getCount()).multiply(left.getGoodsPrice())); out.collect(result); } }); //TODO 3.sink resultDS.print(); //TODO 4.execute env.execute(); } //商品类(商品id,商品名称,商品价格) @Data public static class Goods { private String goodsId; private String goodsName; private BigDecimal goodsPrice; public static List<Goods> GOODS_LIST; public static Random r; static { r = new Random(); GOODS_LIST = new ArrayList<>(); GOODS_LIST.add(new Goods("1", "小米12", new BigDecimal(4890))); GOODS_LIST.add(new Goods("2", "iphone12", new BigDecimal(12000))); GOODS_LIST.add(new Goods("3", "MacBookPro", new BigDecimal(15000))); GOODS_LIST.add(new Goods("4", "Thinkpad X1", new BigDecimal(9800))); GOODS_LIST.add(new Goods("5", "MeiZu One", new BigDecimal(3200))); GOODS_LIST.add(new Goods("6", "Mate 40", new BigDecimal(6500))); } public static Goods randomGoods() { int rIndex = r.nextInt(GOODS_LIST.size()); return GOODS_LIST.get(rIndex); } public Goods() { } public Goods(String goodsId, String goodsName, BigDecimal goodsPrice) { this.goodsId = goodsId; this.goodsName = goodsName; this.goodsPrice = goodsPrice; } @Override public String toString() { return JSON.toJSONString(this); } } //订单明细类(订单id,商品id,商品数量) @Data public static class OrderItem { private String itemId; private String goodsId; private Integer count; @Override public String toString() { return JSON.toJSONString(this); } } //商品类(商品id,商品名称,商品价格) //订单明细类(订单id,商品id,商品数量) //关联结果(商品id,商品名称,商品数量,商品价格*商品数量) @Data public static class FactOrderItem { private String goodsId; private String goodsName; private BigDecimal count; private BigDecimal totalMoney; @Override public String toString() { return JSON.toJSONString(this); } } //实时生成商品数据流 //构建一个商品Stream源(这个好比就是维表) public static class GoodsSource extends RichSourceFunction<Goods> { private Boolean isCancel; @Override public void open(Configuration parameters) throws Exception { isCancel = false; } @Override public void run(SourceContext sourceContext) throws Exception { while(!isCancel) { Goods.GOODS_LIST.stream().forEach(goods -> sourceContext.collect(goods)); TimeUnit.SECONDS.sleep(1); } } @Override public void cancel() { isCancel = true; } } //实时生成订单数据流 //构建订单明细Stream源 public static class OrderItemSource extends RichSourceFunction<OrderItem> { private Boolean isCancel; private Random r; @Override public void open(Configuration parameters) throws Exception { isCancel = false; r = new Random(); } @Override public void run(SourceContext sourceContext) throws Exception { while(!isCancel) { Goods goods = Goods.randomGoods(); OrderItem orderItem = new OrderItem(); orderItem.setGoodsId(goods.getGoodsId()); orderItem.setCount(r.nextInt(10) + 1); orderItem.setItemId(UUID.randomUUID().toString()); sourceContext.collect(orderItem); orderItem.setGoodsId("111"); sourceContext.collect(orderItem); TimeUnit.SECONDS.sleep(1); } } @Override public void cancel() { isCancel = true; } } //构建水印分配器,学习测试直接使用系统时间了 public static class GoodsWatermark implements WatermarkStrategy<Goods> { @Override public TimestampAssigner<Goods> createTimestampAssigner(TimestampAssignerSupplier.Context context) { return (element, recordTimestamp) -> System.currentTimeMillis(); } @Override public WatermarkGenerator<Goods> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context) { return new WatermarkGenerator<Goods>() { @Override public void onEvent(Goods event, long eventTimestamp, WatermarkOutput output) { output.emitWatermark(new Watermark(System.currentTimeMillis())); } @Override public void onPeriodicEmit(WatermarkOutput output) { output.emitWatermark(new Watermark(System.currentTimeMillis())); } }; } } //构建水印分配器,学习测试直接使用系统时间了 public static class OrderItemWatermark implements WatermarkStrategy<OrderItem> { @Override public TimestampAssigner<OrderItem> createTimestampAssigner(TimestampAssignerSupplier.Context context) { return (element, recordTimestamp) -> System.currentTimeMillis(); } @Override public WatermarkGenerator<OrderItem> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context) { return new WatermarkGenerator<OrderItem>() { @Override public void onEvent(OrderItem event, long eventTimestamp, WatermarkOutput output) { output.emitWatermark(new Watermark(System.currentTimeMillis())); } @Override public void onPeriodicEmit(WatermarkOutput output) { output.emitWatermark(new Watermark(System.currentTimeMillis())); } }; } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
3. Flink-高级特性-新特性-End-to-End Exactly-Once
Exactly-Once只是集群内部, Flink 通过checkpoint实现Exactly-Once
End-to-End Exactly-Once是结群内部+外部,Flink 通过checkpoint+两阶段提交实现End-to-End Exactly-Once,两阶段提交是在sink阶段
Flink 在1.4.0 版本引入『exactly-once』并号称支持『End-to-End Exactly-Once』“端到端的精确一次”语义。
数据一致性语义分类:

3.1 流处理的数据处理语义
对于批处理,fault-tolerant(容错性)很容易做,失败只需要replay,就可以完美做到容错。
对于流处理,数据流本身是动态,没有所谓的开始或结束,虽然可以replay buffer的部分数据,但fault-tolerant做起来会复杂的多
流处理(有时称为事件处理)可以简单地描述为是对无界数据或事件的连续处理。流或事件处理应用程序可以或多或少地被描述为有向图,并且通常被描述为有向无环图(DAG)。在这样的图中,每个边表示数据或事件流,每个顶点表示运算符,会使用程序中定义的逻辑处理来自相邻边的数据或事件。有两种特殊类型的顶点,通常称为 sources 和 sinks。sources读取外部数据/事件到应用程序中,而 sinks 通常会收集应用程序生成的结果。下图是流式应用程序的示例。有如下特点:
分布式情况下是由多个Source(读取数据)节点、多个Operator(数据处理)节点、多个Sink(输出)节点构成
每个节点的并行数可以有差异,且每个节点都有可能发生故障
对于数据正确性最重要的一点,就是当发生故障时,是怎样容错与恢复的。

流处理引擎通常为应用程序提供了三种数据处理语义:最多一次、至少一次和精确一次。
如下是对这些不同处理语义的宽松定义(一致性由弱到强):
At most noce < At least once < Exactly once < End to End Exactly once
3.1.1 At-most-once-最多一次
有可能会有数据丢失
**这本质上是简单的恢复方式,也就是直接从失败处的下个数据开始恢复程序(处理数据A时挂了,重启后,从失败的下一个数据开始处理,及不管A有没有处理成功,都不再处理A而是从B开始处理,如果A没有处理成功A就丢失了)**之前的失败数据处理就不管了。可以保证数据或事件最多由应用程序中的所有算子处理一次。 这意味着如果数据在被流应用程序完全处理之前发生丢失,则不会进行其他重试或者重新发送。

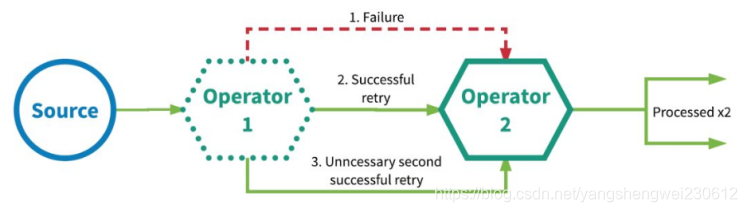
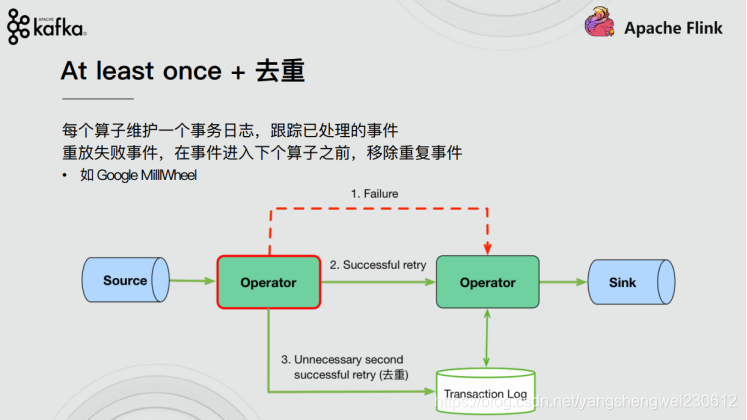
3.1.2 At-least-once-至少一次
有可能重复处理数据
**应用程序中的所有算子都保证数据或事件至少被处理一次。这通常意味着如果事件在流应用程序完全处理之前丢失,则将从源头重放或重新传输事件(处理数据A时挂了,重启后,不管A重启之前有没有处理成功,都再把A处理一次,如果A上次处理成功了就会出现数据重复处理了)。**然而,由于事件是可以被重传的,因此一个事件有时会被处理多次(至少一次),至于有没有重复数据,不会关心,所以这种场景需要人工干预自己处理重复数据
3.1.3 Exactly-once-精确一次
注意:
Exactly-Once 更准确的理解 应该是:
数据只会被正确的处理一次!
而不是说数据只被处理一次,有可能多次,但只有最后一次是正确的,成功的!
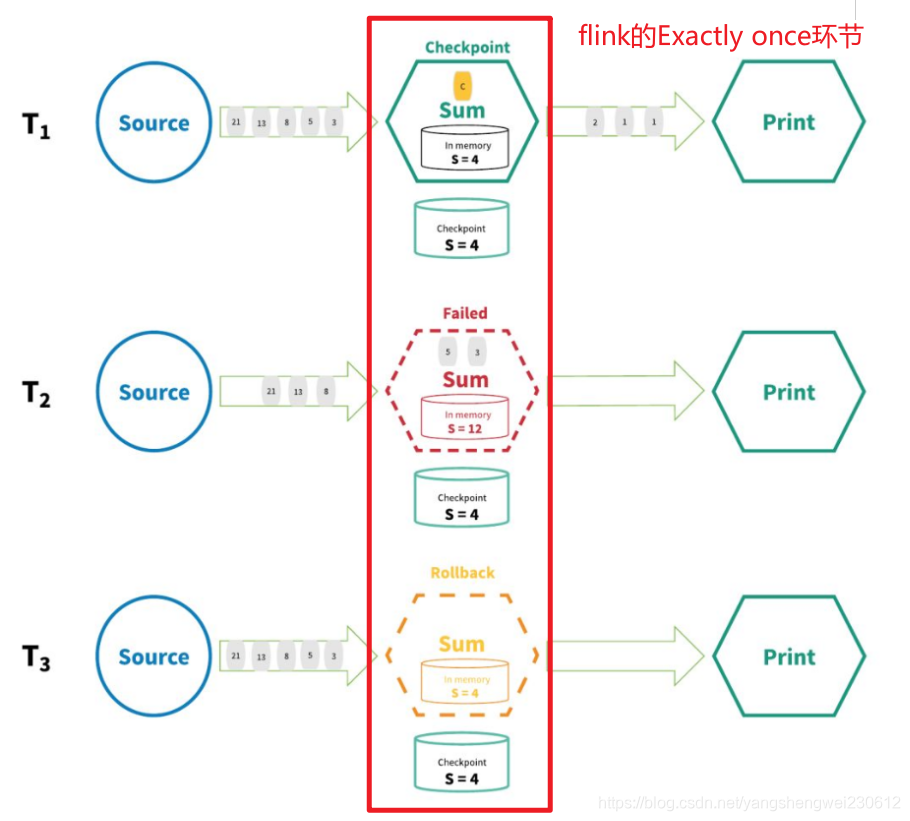
Exactly-Once 是 Flink、Spark 等流处理系统的核心特性之一,这种语义会保证每一条消息只被流处理系成功的处理一次。即使是在各种故障的情况下,流应用程序中的所有算子都保证事件只会被『精确一次』的处理。(也有文章将 Exactly-once 翻译为:完全一次,恰好一次)
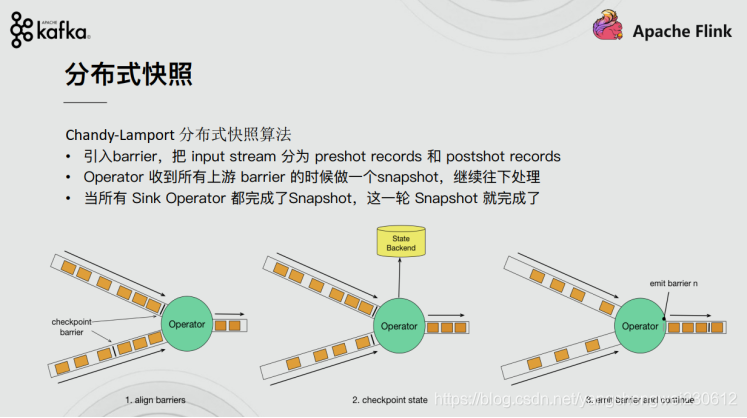
Flink实现『精确一次』的分布式快照/状态检查点方法受到 Chandy-Lamport 分布式快照算法的启发。通过这种机制,流应用程序中每个算子的所有状态都会定期做 checkpoint。如果是在系统中的任何地方发生失败,每个算子的所有状态都回滚到最新的全局一致 checkpoint 点。在回滚期间,将暂停所有处理。源也会重置为与最近 checkpoint 相对应的正确偏移量。整个流应用程序基本上是回到最近一次的一致状态,然后程序可以从该状态重新启动。
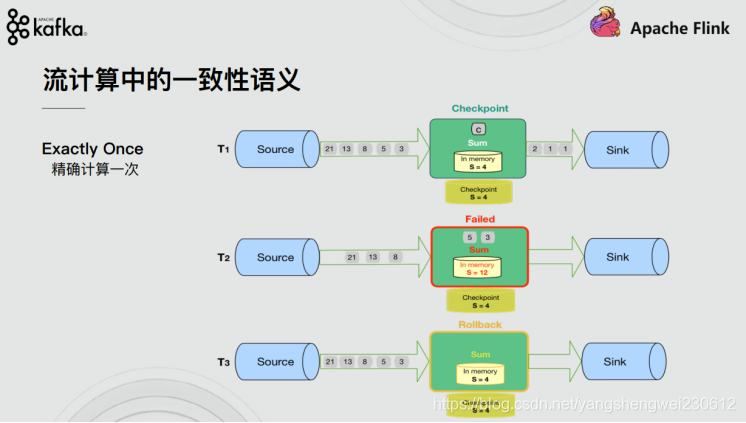
3.1.4 End-to-End Exactly-Once-端到端的精确一次
Flink 在1.4.0 版本引入『exactly-once』并号称支持『End-to-End Exactly-Once』“端到端的精确一次”语义。
它指的是 Flink 应用从 Source 端开始到 Sink 端结束,数据必须经过的起始点和结束点。
注意:
『exactly-once』和『End-to-End Exactly-Once』的区别:

3.1.5 注意:精确一次? 有效一次!
有些人可能认为『精确一次』描述了事件处理的保证,其中流中的每个事件只被处理一次。实际上,没有引擎能够保证正好只处理一次。在面对任意故障时,不可能保证每个算子中的用户定义逻辑在每个事件中只执行一次,因为用户代码被部分执行的可能性是永远存在的。
那么,当引擎声明『精确一次』处理语义时,它们能保证什么呢?如果不能保证用户逻辑只执行一次,那么什么逻辑只执行一次?当引擎声明『精确一次』处理语义时,它们实际上是在说,它们可以保证引擎管理的状态更新只提交一次到持久的后端存储。
事件的处理可以发生多次,但是该处理的效果只在持久后端状态存储中反映一次。因此,我们认为有效地描述这些处理语义最好的术语是『有效一次』(effectively once)
3.1.6 补充:流计算系统如何支持一致性语义
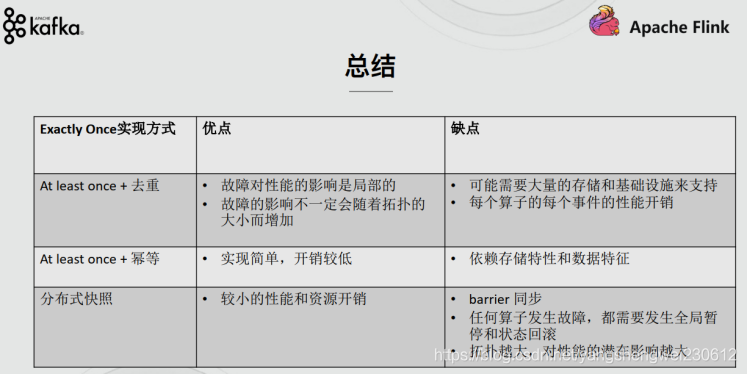
**一致性语义语义及Exactly once,实现的方式主要有以下几种:
1.去重
2.幂等
3.分布式快照/Checkpoint—Flink使用的是这个
Flink使用的是分布式快照及checkpoint
kafka发送消息Exactly once是用的是at least+幂等**

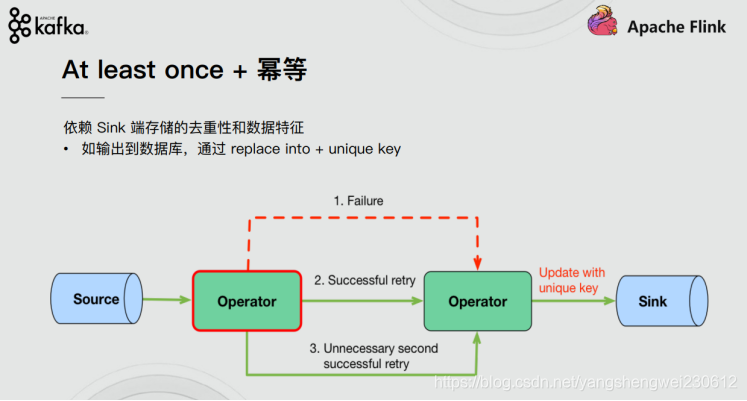
3.2Flink End-to-End Exactly-Once的实现
通过前面的学习,我们了解到,Flink内部借助分布式快照Checkpoint已经实现了内部的Exactly-Once,但是Flink 自身是无法保证外部其他系统“精确一次”语义的,所以 Flink 若要实现所谓“端到端(End to End)的精确一次”的要求,那么外部系统必须支持“精确一次”语义;然后借助一些其他手段才能实现。如下:
3.2.1 Source
发生故障时需要支持重设数据的读取位置,如Kafka可以通过offset来实现(其他的没有offset系统,我们可以自己实现累加器计数)
3.2.2 Transformation
也就是Flink内部,已经通过Checkpoint保证了,如果发生故障或出错时,Flink应用重启后会从最新成功完成的checkpoint中恢复——重置应用状态并回滚状态到checkpoint中输入流的正确位置,之后再开始执行数据处理,就好像该故障或崩溃从未发生过一般。
分布式快照机制
我们在之前的课程中讲解过 Flink 的容错机制,Flink 提供了失败恢复的容错机制,而这个容错机制的核心就是持续创建分布式数据流的快照来实现。
同 Spark 相比,Spark 仅仅是针对 Driver 的故障恢复 Checkpoint。而 Flink 的快照可以到算子级别,并且对全局数据也可以做快照。Flink 的分布式快照受到 Chandy-Lamport 分布式快照算法启发,同时进行了量身定做。
异步和增量
按照上面我们介绍的机制,每次在把快照存储到我们的状态后端时,如果是同步进行就会阻塞正常任务,从而引入延迟。因此 Flink 在做快照存储时,可采用异步方式。
此外,由于 checkpoint 是一个全局状态,用户保存的状态可能非常大,多数达 G 或者 T 级别。在这种情况下,checkpoint 的创建会非常慢,而且执行时占用的资源也比较多,因此 Flink 提出了增量快照的概念。也就是说,每次都是进行的全量 checkpoint,是基于上次进行更新的。
3.2.3 Sink
需要支持幂等写入或事务写入(Flink的两阶段提交需要事务支持)
3.3 Flink+Kafka的End-to-End Exactly-Once
Source: 如Kafka的offset 支持数据的replay/重放/重新传输
Transformation: 借助于Checkpoint
Sink: Checkpoint + 两阶段事务提交
在上一小节我们了解到Flink的 End-to-End Exactly-Once需要Checkpoint+事务的提交/回滚操作,在分布式系统中协调提交和回滚的一个常见方法就是使用两阶段提交协议。接下来我们了解下Flink的TwoPhaseCommitSinkFunction是如何支持End-to-End Exactly-Once的
3.3.1 版本说明
Flink 1.4版本之前,支持Exactly Once语义,仅限于应用内部。
Flink 1.4版本之后,通过两阶段提交(TwoPhaseCommitSinkFunction)支持End-To-End Exactly Once,而且要求Kafka 0.11+。
利用TwoPhaseCommitSinkFunction是通用的管理方案,只要实现对应的接口,而且Sink的存储支持变乱提交,即可实现端到端的划一性语义。

3.3.2 两阶段提交-API
在 Flink 中的Two-Phase-Commit-2PC两阶段提交的实现方法被封装到了 TwoPhaseCommitSinkFunction 这个抽象类中,只需要实现其中的beginTransaction、preCommit、commit、abort 四个方法就可以实现“精确一次”的处理语义,如FlinkKafkaProducer就实现了该类并实现了这些方法

对于文件系统(hdfs)举例:(hsfs本身不支持事务)
1.beginTransaction,在开启事务之前,我们在目标文件系统的临时目录中创建一个临时文件,后面在处理数据时将数据写入此文件;
2.preCommit,在预提交阶段,刷写(flush)文件,然后关闭文件,之后就不能写入到文件了,我们还将为属于下一个检查点的任何后续写入启动新事务;
3.commit,在提交阶段,我们将预提交的文件原子性移动到真正的目标目录中,请注意,这会增加输出数据可见性的延迟;
4.abort,在中止阶段,我们删除临时文件。
总结:先将与提交的写入临时文件,真正提交之后在写入目标文件,如果失败则删除临时文件。
3.3.3 两阶段提交-简单流程
kafka和mysql支持事务可以直接利用sink目标组件的事务
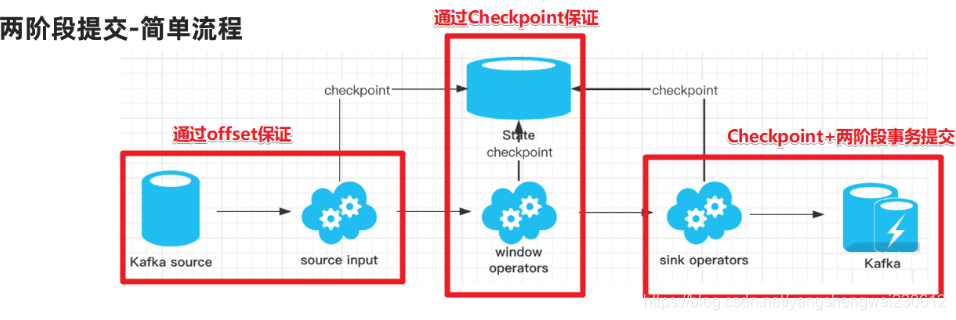
整个过程可以总结为下面四个阶段:
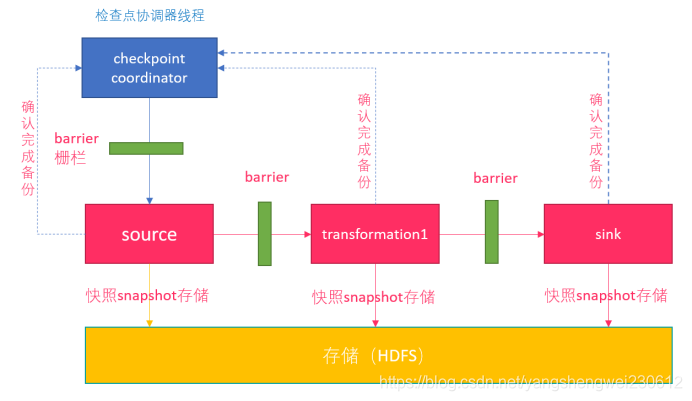
1.一旦 Flink 开始做 checkpoint 操作,那么就会进入 pre-commit “预提交”阶段,同时JobManager的Coordinator 会将 Barrier 注入数据流中 ;
2.当所有的 barrier 在算子中成功进行一遍传递(就是Checkpoint完成),并完成快照后,则“预提交”阶段完成;
3.等所有的算子完成“预提交”,就会发起一个commit“提交”动作,但是任何一个“预提交”失败都会导致 Flink 回滚到最近的 checkpoint;
总结:
- SourceOperater从Kafka消费消息/数据并记录offset
- TransformationOperater对数据进行处理转换并做Checkpoint
- SinkOperator将结果写入到Kafka
注意:在sink的时候会执行两阶段提交:
1.开启事务
2.各个Operator执行barrier的Checkpoint, 成功则进行预提交
3.所有Operator执行完预提交则执行真正的提交
4.如果有任何一个预提交失败则回滚到最近的Checkpoint
3.3.4 两阶段提交-详细流程
需求
接下来将介绍两阶段提交协议,以及它如何在一个读写Kafka的Flink程序中实现端到端的Exactly-Once语义。Kafka经常与Flink一起使用,且Kafka在最近的0.11版本中添加了对事务的支持。这意味着现在通过Flink读写Kafaka,并提供端到端的Exactly-Once语义有了必要的支持。
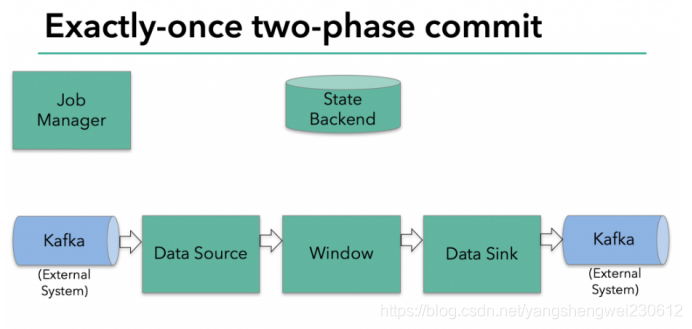
在上图中,我们有:
– 从Kafka读取的数据源(Flink内置的KafkaConsumer)
– 窗口聚合
– 将数据写回Kafka的数据输出端(Flink内置的KafkaProducer)
要使数据输出端提供Exactly-Once保证,它必须将所有数据通过一个事务提交给Kafka。提交捆绑了两个checkpoint之间的所有要写入的数据。这可确保在发生故障时能回滚写入的数据。
但是在分布式系统中,通常会有多个并发运行的写入任务的,简单的提交或回滚是不够的,因为所有组件必须在提交或回滚时“一致”才能确保一致的结果。
Flink使用两阶段提交协议及预提交阶段来解决这个问题。
预提交-内部状态
在checkpoint开始的时候,即两阶段提交协议的“预提交”阶段。当checkpoint开始时,Flink的JobManager会将checkpoint barrier(将数据流中的记录分为进入当前checkpoint与进入下一个checkpoint)注入数据流。
brarrier在operator之间传递。对于每一个operator,它触发operator的状态快照写入到state backend。
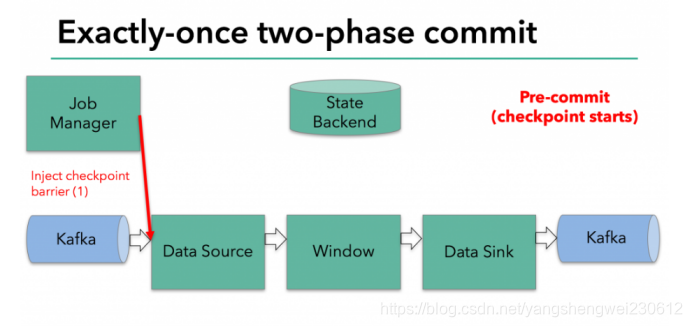
数据源保存了消费Kafka的偏移量(offset),之后将checkpoint barrier传递给下一个operator。
这种方式仅适用于operator具有『内部』状态。所谓内部状态,是指Flink state backend保存和管理的 -例如,第二个operator中window聚合算出来的sum值。当一个进程有它的内部状态的时候,除了在checkpoint之前需要将数据变更写入到state backend,不需要在预提交阶段执行任何其他操作。Flink负责在checkpoint成功的情况下正确提交这些写入,或者在出现故障时中止这些写入。
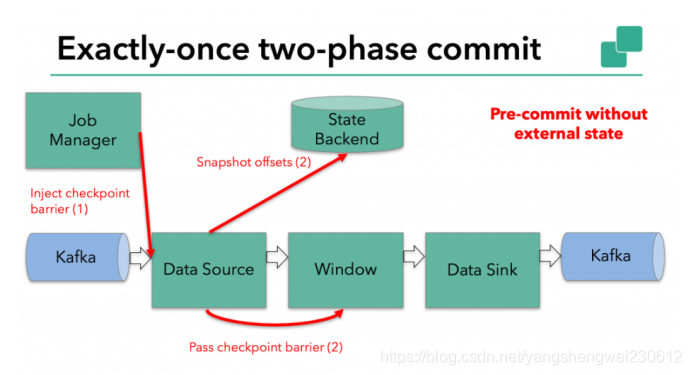
预提交-外部状态
但是,当进程具有『外部』状态时,需要作些额外的处理。外部状态通常以写入外部系统(如Kafka)的形式出现。在这种情况下,为了提供Exactly-Once保证,外部系统必须支持事务,这样才能和两阶段提交协议集成。
在该示例中的数据需要写入Kafka,因此数据输出端(Data Sink)有外部状态。在这种情况下,在预提交阶段,除了将其状态写入state backend之外,数据输出端还必须预先提交其外部事务。
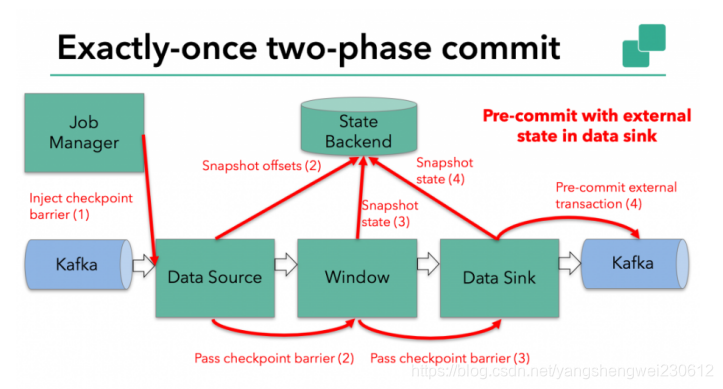
当checkpoint barrier在所有operator都传递了一遍,并且触发的checkpoint回调成功完成时,预提交阶段就结束了。所有触发的状态快照都被视为该checkpoint的一部分。checkpoint是整个应用程序状态的快照,包括预先提交的外部状态。如果发生故障,我们可以回滚到上次成功完成快照的时间点。
提交阶段
下一步是通知所有operator,checkpoint已经成功了。这是两阶段提交协议的提交阶段,JobManager为应用程序中的每个operator发出checkpoint已完成的回调。
数据源和widnow operator没有外部状态,因此在提交阶段,这些operator不必执行任何操作。但是,数据输出端(Data Sink)拥有外部状态,此时应该提交外部事务。

总结
我们对上述知识点总结下:
1.一旦所有operator完成预提交,就提交一个commit。
2.如果只要有一个预提交失败,则所有其他提交都将中止,我们将回滚到上一个成功完成的checkpoint。
3.在预提交成功之后,提交的commit需要保证最终成功 – operator和外部系统都需要保障这点。如果commit失败(例如,由于间歇性网络问题),整个Flink应用程序将失败,应用程序将根据用户的重启策略重新启动,还会尝试再提交。这个过程至关重要,因为如果commit最终没有成功,将会导致数据丢失。
4.完整的实现两阶段提交协议可能有点复杂,这就是为什么Flink将它的通用逻辑提取到抽象类TwoPhaseCommitSinkFunction中的原因。
3.4 代码示例
3.4.1 Flink+Kafka实现End-to-End Exactly-Once
package cn.itcast.feature; import org.apache.commons.lang3.SystemUtils; import org.apache.flink.api.common.RuntimeExecutionMode; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.common.restartstrategy.RestartStrategies; import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.api.common.time.Time; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.runtime.state.filesystem.FsStateBackend; import org.apache.flink.streaming.api.CheckpointingMode; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.CheckpointConfig; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer; import org.apache.flink.streaming.connectors.kafka.internals.KeyedSerializationSchemaWrapper; import org.apache.flink.util.Collector; import java.util.Properties; import java.util.Random; import java.util.concurrent.TimeUnit; /** * Author itcast * Desc 演示Flink的EndToEnd_Exactly_Once * 需求: * kafka主题flink-kafka1 --->Flink Source -->Flink-Transformation做WordCount-->结果存储到kafka主题-flink-kafka2 */ public class Flink_Kafka_EndToEnd_Exactly_Once { public static void main(String[] args) throws Exception { //TODO 0.env StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC); //开启Checkpoint //===========类型1:必须参数============= //设置Checkpoint的时间间隔为1000ms做一次Checkpoint/其实就是每隔1000ms发一次Barrier! env.enableCheckpointing(1000); if (SystemUtils.IS_OS_WINDOWS) { env.setStateBackend(new FsStateBackend("file:///D:/ckp")); } else { env.setStateBackend(new FsStateBackend("hdfs://node1:8020/flink-checkpoint/checkpoint")); } //===========类型2:建议参数=========== //设置两个Checkpoint 之间最少等待时间,如设置Checkpoint之间最少是要等 500ms(为了避免每隔1000ms做一次Checkpoint的时候,前一次太慢和后一次重叠到一起去了) //如:高速公路上,每隔1s关口放行一辆车,但是规定了两车之前的最小车距为500m env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);//默认是0 //设置如果在做Checkpoint过程中出现错误,是否让整体任务失败:true是 false不是 //env.getCheckpointConfig().setFailOnCheckpointingErrors(false);//默认是true env.getCheckpointConfig().setTolerableCheckpointFailureNumber(10);//默认值为0,表示不容忍任何检查点失败 //设置是否清理检查点,表示 Cancel 时是否需要保留当前的 Checkpoint,默认 Checkpoint会在作业被Cancel时被删除 //ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION:true,当作业被取消时,删除外部的checkpoint(默认值) //ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION:false,当作业被取消时,保留外部的checkpoint env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); //===========类型3:直接使用默认的即可=============== //设置checkpoint的执行模式为EXACTLY_ONCE(默认) env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); //设置checkpoint的超时时间,如果 Checkpoint在 60s内尚未完成说明该次Checkpoint失败,则丢弃。 env.getCheckpointConfig().setCheckpointTimeout(60000);//默认10分钟 //设置同一时间有多少个checkpoint可以同时执行 env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);//默认为1 //TODO ===配置重启策略: //1.配置了Checkpoint的情况下不做任务配置:默认是无限重启并自动恢复,可以解决小问题,但是可能会隐藏真正的bug //2.单独配置无重启策略 //env.setRestartStrategy(RestartStrategies.noRestart()); //3.固定延迟重启--开发中常用 env.setRestartStrategy(RestartStrategies.fixedDelayRestart( 3, // 最多重启3次数 Time.of(5, TimeUnit.SECONDS) // 重启时间间隔 )); //上面的设置表示:如果job失败,重启3次, 每次间隔5s //4.失败率重启--开发中偶尔使用 /*env.setRestartStrategy(RestartStrategies.failureRateRestart( 3, // 每个测量阶段内最大失败次数 Time.of(1, TimeUnit.MINUTES), //失败率测量的时间间隔 Time.of(3, TimeUnit.SECONDS) // 两次连续重启的时间间隔 ));*/ //上面的设置表示:如果1分钟内job失败不超过三次,自动重启,每次重启间隔3s (如果1分钟内程序失败达到3次,则程序退出) //TODO 1.source-主题:flink-kafka1 //准备kafka连接参数 Properties props1 = new Properties(); props1.setProperty("bootstrap.servers", "node1:9092");//集群地址 props1.setProperty("group.id", "flink");//消费者组id props1.setProperty("auto.offset.reset", "latest");//latest有offset记录从记录位置开始消费,没有记录从最新的/最后的消息开始消费 /earliest有offset记录从记录位置开始消费,没有记录从最早的/最开始的消息开始消费 props1.setProperty("flink.partition-discovery.interval-millis", "5000");//会开启一个后台线程每隔5s检测一下Kafka的分区情况,实现动态分区检测 //props1.setProperty("enable.auto.commit", "true");//自动提交(提交到默认主题,后续学习了Checkpoint后随着Checkpoint存储在Checkpoint和默认主题中) //props1.setProperty("auto.commit.interval.ms", "2000");//自动提交的时间间隔 //使用连接参数创建FlinkKafkaConsumer/kafkaSource //FlinkKafkaConsumer里面已经实现了offset的Checkpoint维护! FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<String>("flink_kafka1", new SimpleStringSchema(), props1); kafkaSource.setCommitOffsetsOnCheckpoints(true);//默认就是true//在做Checkpoint的时候提交offset到Checkpoint(为容错)和默认主题(为了外部工具获取)中 //使用kafkaSource DataStream<String> kafkaDS = env.addSource(kafkaSource); //TODO 2.transformation-做WordCount SingleOutputStreamOperator<String> result = kafkaDS.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() { private Random ran = new Random(); @Override public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception { String[] arr = value.split(" "); for (String word : arr) { int num = ran.nextInt(5); if(num > 3){ System.out.println("随机异常产生了"); throw new Exception("随机异常产生了"); } out.collect(Tuple2.of(word, 1)); } } }).keyBy(t -> t.f0) .sum(1) .map(new MapFunction<Tuple2<String, Integer>, String>() { @Override public String map(Tuple2<String, Integer> value) throws Exception { return value.f0 + ":" + value.f1; } }); //TODO 3.sink-主题:flink-kafka2 Properties props2 = new Properties(); props2.setProperty("bootstrap.servers", "node1:9092"); props2.setProperty("transaction.timeout.ms", "5000"); FlinkKafkaProducer<String> kafkaSink = new FlinkKafkaProducer<>( "flink_kafka2", // target topic new KeyedSerializationSchemaWrapper(new SimpleStringSchema()), // serialization schema props2, // producer config FlinkKafkaProducer.Semantic.EXACTLY_ONCE); // fault-tolerance result.addSink(kafkaSink); //TODO 4.execute env.execute(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
3.4.2 Flink+MySQL实现End-to-End Exactly-Once
https://www.jianshu.com/p/5bdd9a0d7d02
需求
1.checkpoint每10s进行一次,此时用FlinkKafkaConsumer实时消费kafka中的消息
2.消费并处理完消息后,进行一次预提交数据库的操作
3.如果预提交没有问题,10s后进行真正的插入数据库操作,如果插入成功,进行一次checkpoint,flink会自动记录消费的offset,可以将checkpoint保存的数据放到hdfs中
4.如果预提交出错,比如在5s的时候出错了,此时Flink程序就会进入不断的重启中,重启的策略可以在配置中设置,checkpoint记录的还是上一次成功消费的offset,因为本次消费的数据在checkpoint期间,消费成功,但是预提交过程中失败了
5.注意此时数据并没有真正的执行插入操作,因为预提交(preCommit)失败,提交(commit)过程也不会发生。等将异常数据处理完成之后,再重新启动这个Flink程序,它会自动从上一次成功的checkpoint中继续消费数据,以此来达到Kafka到Mysql的Exactly-Once。
代码1
package cn.itcast.extend; import org.apache.flink.api.common.ExecutionConfig; import org.apache.flink.api.common.typeutils.base.VoidSerializer; import org.apache.flink.api.java.typeutils.runtime.kryo.KryoSerializer; import org.apache.flink.runtime.state.filesystem.FsStateBackend; import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.node.ObjectNode; import org.apache.flink.streaming.api.CheckpointingMode; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.sink.TwoPhaseCommitSinkFunction; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer; import org.apache.flink.streaming.util.serialization.JSONKeyValueDeserializationSchema; import org.apache.kafka.clients.CommonClientConfigs; import java.sql.*; import java.text.SimpleDateFormat; import java.util.Date; import java.util.Properties; public class Kafka_Flink_MySQL_EndToEnd_ExactlyOnce { public static void main(String[] args) throws Exception { //1.env StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1);//方便测试 env.enableCheckpointing(10000); env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); env.getCheckpointConfig().setMinPauseBetweenCheckpoints(1000); //env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); env.setStateBackend(new FsStateBackend("file:///D:/ckp")); //2.Source String topic = "flink_kafka"; Properties props = new Properties(); props.setProperty(CommonClientConfigs.BOOTSTRAP_SERVERS_CONFIG,"node1:9092"); props.setProperty("group.id","flink"); props.setProperty("auto.offset.reset","latest");//如果有记录偏移量从记录的位置开始消费,如果没有从最新的数据开始消费 props.setProperty("flink.partition-discovery.interval-millis","5000");//开一个后台线程每隔5s检查Kafka的分区状态 FlinkKafkaConsumer<ObjectNode> kafkaSource = new FlinkKafkaConsumer<>("topic_in", new JSONKeyValueDeserializationSchema(true), props); kafkaSource.setStartFromGroupOffsets();//从group offset记录的位置位置开始消费,如果kafka broker 端没有该group信息,会根据"auto.offset.reset"的设置来决定从哪开始消费 kafkaSource.setCommitOffsetsOnCheckpoints(true);//Flink执行Checkpoint的时候提交偏移量(一份在Checkpoint中,一份在Kafka的默认主题中__comsumer_offsets(方便外部监控工具去看)) DataStreamSource<ObjectNode> kafkaDS = env.addSource(kafkaSource); //3.transformation //4.Sink kafkaDS.addSink(new MySqlTwoPhaseCommitSink()).name("MySqlTwoPhaseCommitSink"); //5.execute env.execute(); } } /** 自定义kafka to mysql,继承TwoPhaseCommitSinkFunction,实现两阶段提交。 功能:保证kafak to mysql 的Exactly-Once CREATE TABLE `t_test` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `value` varchar(255) DEFAULT NULL, `insert_time` datetime DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 */ class MySqlTwoPhaseCommitSink extends TwoPhaseCommitSinkFunction<ObjectNode, Connection, Void> { public MySqlTwoPhaseCommitSink() { super(new KryoSerializer<>(Connection.class, new ExecutionConfig()), VoidSerializer.INSTANCE); } /** * 执行数据入库操作 */ @Override protected void invoke(Connection connection, ObjectNode objectNode, Context context) throws Exception { System.err.println("start invoke......."); String date = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date()); System.err.println("===>date:" + date + " " + objectNode); String value = objectNode.get("value").toString(); String sql = "insert into `t_test` (`value`,`insert_time`) values (?,?)"; PreparedStatement ps = connection.prepareStatement(sql); ps.setString(1, value); ps.setTimestamp(2, new Timestamp(System.currentTimeMillis())); //执行insert语句 ps.execute(); //手动制造异常 if(Integer.parseInt(value) == 15) System.out.println(1/0); } /** * 获取连接,开启手动提交事务(getConnection方法中) */ @Override protected Connection beginTransaction() throws Exception { String url = "jdbc:mysql://localhost:3306/bigdata?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&useSSL=false&autoReconnect=true"; Connection connection = DBConnectUtil.getConnection(url, "root", "root"); System.err.println("start beginTransaction......."+connection); return connection; } /** * 预提交,这里预提交的逻辑在invoke方法中 */ @Override protected void preCommit(Connection connection) throws Exception { System.err.println("start preCommit......."+connection); } /** * 如果invoke执行正常则提交事务 */ @Override protected void commit(Connection connection) { System.err.println("start commit......."+connection); DBConnectUtil.commit(connection); } @Override protected void recoverAndCommit(Connection connection) { System.err.println("start recoverAndCommit......."+connection); } @Override protected void recoverAndAbort(Connection connection) { System.err.println("start abort recoverAndAbort......."+connection); } /** * 如果invoke执行异常则回滚事务,下一次的checkpoint操作也不会执行 */ @Override protected void abort(Connection connection) { System.err.println("start abort rollback......."+connection); DBConnectUtil.rollback(connection); } } class DBConnectUtil { /** * 获取连接 */ public static Connection getConnection(String url, String user, String password) throws SQLException { Connection conn = null; conn = DriverManager.getConnection(url, user, password); //设置手动提交 conn.setAutoCommit(false); return conn; } /** * 提交事务 */ public static void commit(Connection conn) { if (conn != null) { try { conn.commit(); } catch (SQLException e) { e.printStackTrace(); } finally { close(conn); } } } /** * 事务回滚 */ public static void rollback(Connection conn) { if (conn != null) { try { conn.rollback(); } catch (SQLException e) { e.printStackTrace(); } finally { close(conn); } } } /** * 关闭连接 */ public static void close(Connection conn) { if (conn != null) { try { conn.close(); } catch (SQLException e) { e.printStackTrace(); } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
代码2
package cn.itcast.extend; import com.alibaba.fastjson.JSON; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; import org.apache.kafka.clients.producer.Producer; import org.apache.kafka.clients.producer.ProducerRecord; import java.util.Properties; public class DataProducer { public static void main(String[] args) throws InterruptedException { Properties props = new Properties(); props.put("bootstrap.servers", "node1:9092"); props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); Producer<String, String> producer = new org.apache.kafka.clients.producer.KafkaProducer<>(props); try { for (int i = 1; i <= 20; i++) { DataBean data = new DataBean(String.valueOf(i)); ProducerRecord record = new ProducerRecord<String, String>("flink_kafka", null, null, JSON.toJSONString(data)); producer.send(record); System.out.println("发送数据: " + JSON.toJSONString(data)); Thread.sleep(1000); } }catch (Exception e){ System.out.println(e); } producer.flush(); } } @Data @NoArgsConstructor @AllArgsConstructor class DataBean { private String value; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
4. 异步IO
4.1 介绍
4.1.1 异步IO操作的需求
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/stream/operators/asyncio.html
Async I/O 是阿里巴巴贡献给社区的一个呼声非常高的特性,于1.2版本引入。主要目的是为了解决与外部系统交互时网络延迟成为了系统瓶颈的问题。
流计算系统中经常需要与外部系统进行交互,我们通常的做法如向数据库发送用户a的查询请求,然后等待结果返回,在这之前,我们的程序无法发送用户b的查询请求。这是一种同步访问方式,如下图所示
5. Streaming File Sink
5.1 介绍
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/connectors/streamfile_sink.html
https://blog.csdn.net/u013220482/article/details/100901471
5.1.1 场景描述
StreamingFileSink是Flink1.7中推出的新特性,是为了解决如下的问题:
大数据业务场景中,经常有一种场景:外部数据发送到kafka中,flink作为中间件消费kafka数据并进行业务处理;处理完成之后的数据可能还需要写入到数据库或者文件系统中,比如写入hdfs中。
StreamingFileSink就可以用来将分区文件写入到支持 Flink FileSystem 接口的文件系统中,支持Exactly-Once语义。
这种sink实现的Exactly-Once都是基于Flink checkpoint来实现的两阶段提交模式来保证的,主要应用在实时数仓、topic拆分、基于小时分析处理等场景下。
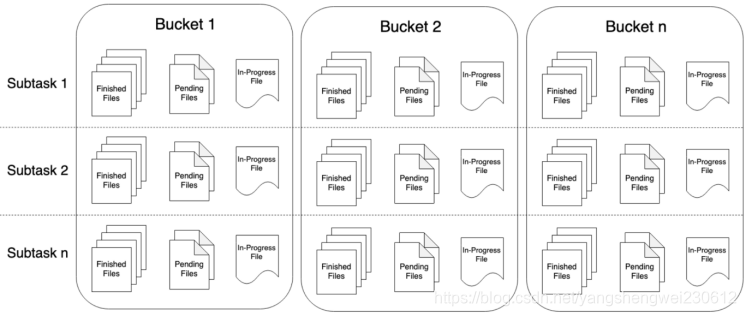
5.1.2 Bucket和SubTask、PartFile
Bucket
StreamingFileSink可向由Flink FileSystem抽象支持的文件系统写入分区文件(因为是流式写入,数据被视为无界)。该分区行为可配,默认按时间,具体来说每小时写入一个Bucket,该Bucket包括若干文件,内容是这一小时间隔内流中收到的所有record。
PartFile
每个Bukcket内部分为多个PartFile来存储输出数据,该Bucket生命周期内接收到数据的sink的每个子任务至少有一个PartFile。
而额外文件滚动由可配的滚动策略决定,默认策略是根据文件大小和打开超时(文件可以被打开的最大持续时间)以及文件最大不活动超时等决定是否滚动。
Bucket和SubTask、PartFile关系如图所示
5.2 案例演示
需求
编写Flink程序,接收socket的字符串数据,然后将接收到的数据流式方式存储到hdfs
开发步骤
1.初始化流计算运行环境
2.设置Checkpoint(10s)周期性启动
3.指定并行度为1
4.接入socket数据源,获取数据
5.指定文件编码格式为行编码格式
6.设置桶分配策略
7.设置文件滚动策略
8.指定文件输出配置
9.将streamingfilesink对象添加到环境
10.执行任务
实现代码
package cn.itcast.extend; import org.apache.flink.api.common.serialization.SimpleStringEncoder; import org.apache.flink.core.fs.Path; import org.apache.flink.runtime.state.filesystem.FsStateBackend; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.sink.filesystem.OutputFileConfig; import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink; import org.apache.flink.streaming.api.functions.sink.filesystem.bucketassigners.DateTimeBucketAssigner; import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy; import java.util.concurrent.TimeUnit; public class StreamFileSinkDemo { public static void main(String[] args) throws Exception { //1.env StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.enableCheckpointing(TimeUnit.SECONDS.toMillis(10)); env.setStateBackend(new FsStateBackend("file:///D:/ckp")); //2.source DataStreamSource<String> lines = env.socketTextStream("node1", 9999); //3.sink //设置sink的前缀和后缀 //文件的头和文件扩展名 //prefix-xxx-.txt OutputFileConfig config = OutputFileConfig .builder() .withPartPrefix("prefix") .withPartSuffix(".txt") .build(); //设置sink的路径 String outputPath = "hdfs://node1:8020/FlinkStreamFileSink/parquet"; //创建StreamingFileSink final StreamingFileSink<String> sink = StreamingFileSink .forRowFormat( new Path(outputPath), new SimpleStringEncoder<String>("UTF-8")) /** * 设置桶分配政策 * DateTimeBucketAssigner --默认的桶分配政策,默认基于时间的分配器,每小时产生一个桶,格式如下yyyy-MM-dd--HH * BasePathBucketAssigner :将所有部分文件(part file)存储在基本路径中的分配器(单个全局桶) */ .withBucketAssigner(new DateTimeBucketAssigner<>()) /** * 有三种滚动政策 * CheckpointRollingPolicy * DefaultRollingPolicy * OnCheckpointRollingPolicy */ .withRollingPolicy( /** * 滚动策略决定了写出文件的状态变化过程 * 1. In-progress :当前文件正在写入中 * 2. Pending :当处于 In-progress 状态的文件关闭(closed)了,就变为 Pending 状态 * 3. Finished :在成功的 Checkpoint 后,Pending 状态将变为 Finished 状态 * * 观察到的现象 * 1.会根据本地时间和时区,先创建桶目录 * 2.文件名称规则:part-<subtaskIndex>-<partFileIndex> * 3.在macos中默认不显示隐藏文件,需要显示隐藏文件才能看到处于In-progress和Pending状态的文件,因为文件是按照.开头命名的 * */ DefaultRollingPolicy.builder() .withRolloverInterval(TimeUnit.SECONDS.toMillis(2)) //设置滚动间隔 .withInactivityInterval(TimeUnit.SECONDS.toMillis(1)) //设置不活动时间间隔 .withMaxPartSize(1024 * 1024 * 1024) // 最大尺寸 .build()) .withOutputFileConfig(config) .build(); lines.addSink(sink).setParallelism(1); env.execute(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
6. File Sink
6.1 介绍
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/connectors/file_sink.html
新的 Data Sink API (Beta)
之前发布的 Flink 版本中[1],已经支持了 source connector 工作在流批两种模式下,因此在 Flink 1.12 中,社区着重实现了统一的 Data Sink API(FLIP-143)。新的抽象引入了 write/commit 协议和一个更加模块化的接口。Sink 的实现者只需要定义 what 和 how:SinkWriter,用于写数据,并输出需要 commit 的内容(例如,committables);Committer 和 GlobalCommitter,封装了如何处理 committables。框架会负责 when 和 where:即在什么时间,以及在哪些机器或进程中 commit。
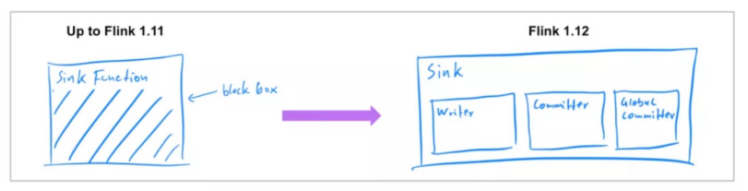
这种模块化的抽象允许为 BATCH 和 STREAMING 两种执行模式,实现不同的运行时策略,以达到仅使用一种 sink 实现,也可以使两种模式都可以高效执行。Flink 1.12 中,提供了统一的 FileSink connector,以替换现有的 StreamingFileSink connector (FLINK-19758)。其它的 connector 也将逐步迁移到新的接口。
Flink 1.12的 FileSink 为批处理和流式处理提供了一个统一的接收器,它将分区文件写入Flink文件系统抽象所支持的文件系统。这个文件系统连接器为批处理和流式处理提供了相同的保证,它是现有流式文件接收器的一种改进。
6.2 案例演示
package cn.itcast.extend; import org.apache.flink.api.common.serialization.SimpleStringEncoder; import org.apache.flink.connector.file.sink.FileSink; import org.apache.flink.core.fs.Path; import org.apache.flink.runtime.state.filesystem.FsStateBackend; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.sink.filesystem.OutputFileConfig; import org.apache.flink.streaming.api.functions.sink.filesystem.bucketassigners.DateTimeBucketAssigner; import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy; import java.util.concurrent.TimeUnit; /** * Author itcast * Desc */ public class FileSinkDemo { public static void main(String[] args) throws Exception { //1.env StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.enableCheckpointing(TimeUnit.SECONDS.toMillis(10)); env.setStateBackend(new FsStateBackend("file:///D:/ckp")); //2.source DataStreamSource<String> lines = env.socketTextStream("node1", 9999); //3.sink //设置sink的前缀和后缀 //文件的头和文件扩展名 //prefix-xxx-.txt OutputFileConfig config = OutputFileConfig .builder() .withPartPrefix("prefix") .withPartSuffix(".txt") .build(); //设置sink的路径 String outputPath = "hdfs://node1:8020/FlinkFileSink/parquet"; final FileSink<String> sink = FileSink .forRowFormat(new Path(outputPath), new SimpleStringEncoder<String>("UTF-8")) .withBucketAssigner(new DateTimeBucketAssigner<>()) .withRollingPolicy( DefaultRollingPolicy.builder() .withRolloverInterval(TimeUnit.MINUTES.toMillis(15)) .withInactivityInterval(TimeUnit.MINUTES.toMillis(5)) .withMaxPartSize(1024 * 1024 * 1024) .build()) .withOutputFileConfig(config) .build(); lines.sinkTo(sink).setParallelism(1); env.execute(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
7. FlinkSQL整合Hive
7.1 介绍
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/connectors/hive/
https://zhuanlan.zhihu.com/p/338506408
使用Hive构建数据仓库已经成为了比较普遍的一种解决方案。目前,一些比较常见的大数据处理引擎,都无一例外兼容Hive。Flink从1.9开始支持集成Hive,不过1.9版本为beta版,不推荐在生产环境中使用。在Flink1.10版本中,标志着对 Blink的整合宣告完成,对 Hive 的集成也达到了生产级别的要求。值得注意的是,不同版本的Flink对于Hive的集成有所差异,接下来将以最新的Flink1.12版本为例,实现Flink集成Hive
7.2 集成Hive的基本方式
Flink 与 Hive 的集成主要体现在以下两个方面:
持久化元数据
Flink利用 Hive 的 MetaStore 作为持久化的 Catalog,我们可通过HiveCatalog将不同会话中的 Flink 元数据存储到 Hive Metastore 中。例如,我们可以使用HiveCatalog将其 Kafka的数据源表存储在 Hive Metastore 中,这样该表的元数据信息会被持久化到Hive的MetaStore对应的元数据库中,在后续的 SQL 查询中,我们可以重复使用它们。
利用 Flink 来读写 Hive 的表
Flink打通了与Hive的集成,如同使用SparkSQL或者Impala操作Hive中的数据一样,我们可以使用Flink直接读写Hive中的表。
HiveCatalog的设计提供了与 Hive 良好的兼容性,用户可以”开箱即用”的访问其已有的 Hive表。不需要修改现有的 Hive Metastore,也不需要更改表的数据位置或分区。
7.3 准备工作
1.添加hadoop_classpath
vim /etc/profile
增加如下配置
export HADOOP_CLASSPATH=hadoop classpath
刷新配置
source /etc/profile
2.下载jar并上传至flink/lib目录
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/connectors/hive/

3.修改hive配置
vim /export/server/hive/conf/hive-site.xml
<property>
<name>hive.metastore.uris</name>
<value>thrift://node3:9083</value>
</property>
- 1
- 2
- 3
- 4
4.启动hive元数据服务
nohup /export/server/hive/bin/hive --service metastore &
7.4 SQL CLI
1.修改flinksql配置
vim /export/server/flink/conf/sql-client-defaults.yaml
增加如下配置
catalogs:
- name: myhive
type: hive
hive-conf-dir: /export/server/hive/conf
default-database: default
2.启动flink集群
/export/server/flink/bin/start-cluster.sh
3.启动flink-sql客户端
/export/server/flink/bin/sql-client.sh embedded
4.执行sql:
show catalogs;
use catalog myhive;
show tables;
select * from person;
7.5 代码演示
package cn.itcast.extend; import org.apache.flink.table.api.EnvironmentSettings; import org.apache.flink.table.api.Table; import org.apache.flink.table.api.TableEnvironment; import org.apache.flink.table.api.TableResult; import org.apache.flink.table.catalog.hive.HiveCatalog; /** * Author itcast * Desc */ public class HiveDemo { public static void main(String[] args){ EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().build(); TableEnvironment tableEnv = TableEnvironment.create(settings); String name = "myhive"; String defaultDatabase = "default"; String hiveConfDir = "./conf"; HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir); //注册catalog tableEnv.registerCatalog("myhive", hive); //使用注册的catalog tableEnv.useCatalog("myhive"); //向Hive表中写入数据 String insertSQL = "insert into person select * from person"; TableResult result = tableEnv.executeSql(insertSQL); System.out.println(result.getJobClient().get().getJobStatus()); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
8.Flink多语言开发
课程目标
了解PyFlink并掌握官方示例
掌握Scala语音编写Flink程序
实现电商点击流日志分析
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/scala_api_extensions.html
9.Flink监控与优化
课程目标
了解FlinkMetrics指标监控
了解Flink性能优化
了解Flink内存管理
了解Flink和Spark的异同
了解Flink网络流控和反压
1. Flink-Metrics监控
1.1 什么是 Metrics?
https://ci.apache.org/projects/flink/flink-docs-release-1.12/ops/metrics.html
1.1.1 Metrics介绍
由于集群运行后很难发现内部的实际状况,跑得慢或快,是否异常等,开发人员无法实时查看所有的 Task 日志,比如作业很大或者有很多作业的情况下,该如何处理?此时 Metrics 可以很好的帮助开发人员了解作业的当前状况。
Flink 提供的 Metrics 可以在 Flink 内部收集一些指标,通过这些指标让开发人员更好地理解作业或集群的状态。
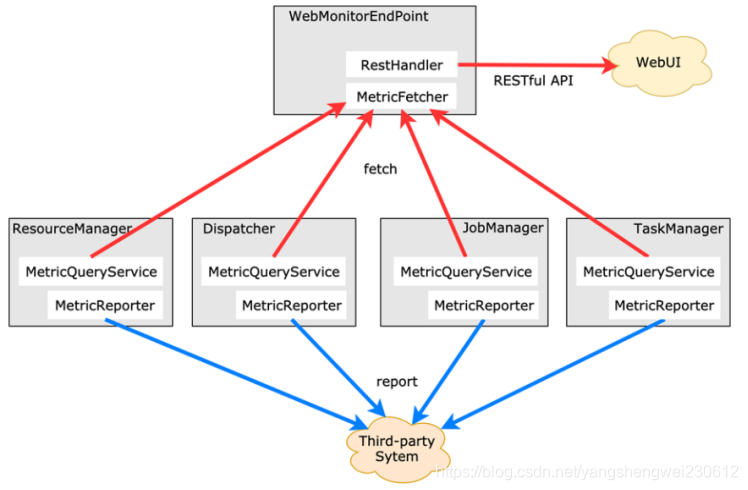
1.1.2 Metric Types
Metrics 的类型如下:
1,常用的如 Counter,写过 mapreduce 作业的开发人员就应该很熟悉 Counter,其实含义都是一样的,就是对一个计数器进行累加,即对于多条数据和多兆数据一直往上加的过程。
2,Gauge,Gauge 是最简单的 Metrics,它反映一个值。比如要看现在 Java heap 内存用了多少,就可以每次实时的暴露一个 Gauge,Gauge 当前的值就是heap使用的量。
3,Meter,Meter 是指统计吞吐量和单位时间内发生“事件”的次数。它相当于求一种速率,即事件次数除以使用的时间。
4,Histogram,Histogram 比较复杂,也并不常用,Histogram 用于统计一些数据的分布,比如说 Quantile、Mean、StdDev、Max、Min 等。
Metric 在 Flink 内部有多层结构,以 Group 的方式组织,它并不是一个扁平化的结构,Metric Group + Metric Name 是 Metrics 的唯一标识。
1.2 WebUI监控
在flink的UI的界面上点击任务详情,然后点击Task Metrics会弹出如下的界面,在 add metic按钮上可以添加我需要的监控指标。
自定义监控指标
○案例:在map算子内计算输入的总数据
○设置MetricGroup为:flink_test_metric
○指标变量为:mapDataNub
○参考代码
package cn.itcast.hello; import org.apache.flink.api.common.RuntimeExecutionMode; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.common.functions.RichMapFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.configuration.Configuration; import org.apache.flink.metrics.Counter; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; /** * Author itcast * Desc */ public class WordCount5_Metrics { public static void main(String[] args) throws Exception { //1.准备环境-env StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC); //2.准备数据-source //2.source DataStream<String> linesDS = env.socketTextStream("node1", 9999); //3.处理数据-transformation DataStream<String> wordsDS = linesDS.flatMap(new FlatMapFunction<String, String>() { @Override public void flatMap(String value, Collector<String> out) throws Exception { //value就是一行行的数据 String[] words = value.split(" "); for (String word : words) { out.collect(word);//将切割处理的一个个的单词收集起来并返回 } } }); //3.2对集合中的每个单词记为1 DataStream<Tuple2<String, Integer>> wordAndOnesDS = wordsDS.map(new RichMapFunction<String, Tuple2<String, Integer>>() { Counter myCounter; @Override public void open(Configuration parameters) throws Exception { myCounter= getRuntimeContext().getMetricGroup().addGroup("myGroup").counter("myCounter"); } @Override public Tuple2<String, Integer> map(String value) throws Exception { myCounter.inc(); //value就是进来一个个的单词 return Tuple2.of(value, 1); } }); //3.3对数据按照单词(key)进行分组 KeyedStream<Tuple2<String, Integer>, String> groupedDS = wordAndOnesDS.keyBy(t -> t.f0); //3.4对各个组内的数据按照数量(value)进行聚合就是求sum DataStream<Tuple2<String, Integer>> result = groupedDS.sum(1); //4.输出结果-sink result.print().name("mySink"); //5.触发执行-execute env.execute(); } } // /export/server/flink/bin/yarn-session.sh -n 2 -tm 800 -s 1 -d // /export/server/flink/bin/flink run --class cn.itcast.hello.WordCount5_Metrics /root/metrics.jar // 查看WebUI
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
○程序启动之后就可以在任务的ui界面上查看
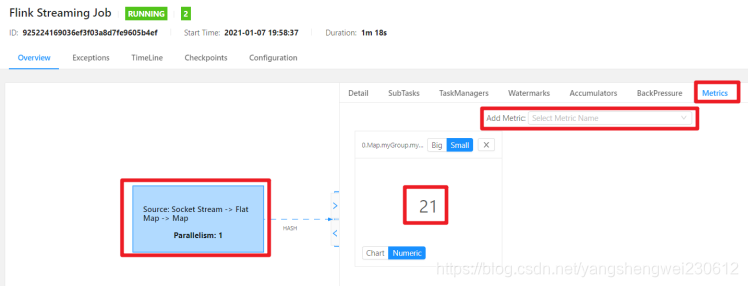
1.3 REST API监控
前面介绍了flink公共的监控指标以及如何自定义监控指标,那么实际开发flink任务我们需要及时知道这些监控指标的数据,去获取程序的健康值以及状态。这时候就需要我们通过 flink REST API ,自己编写监控程序去获取这些指标。很简单,当我们知道每个指标请求的URL,我们便可以编写程序通过http请求获取指标的监控数据。
对于 flink on yarn 模式来说,则需要知道 RM 代理的 JobManager UI 地址
格式:
http://Yarn-WebUI-host:port/proxy/application_id
如:
http://node1:8088/proxy/application_1609508087977_0004/jobs
1.3.1 http请求获取监控数据
操作步骤:
获取flink任务运行状态(我们可以在浏览器进行测试,输入如下的连接)
http://node1:8088/proxy/application_1609508087977_0004/jobs
返回的结果
{
jobs: [{
id: "ce793f18efab10127f0626a37ff4b4d4",
status: "RUNNING"
}
]
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
获取 job 详情
http://node1:8088/proxy/application_1609508087977_0004/jobs/925224169036ef3f03a8d7fe9605b4ef 返回的结果 { jid: "ce793f18efab10127f0626a37ff4b4d4", name: "Test", isStoppable: false, state: "RUNNING", start - time: 1551577191874, end - time: -1, duration: 295120489, now: 1551872312363, 。。。。。。 此处省略n行 。。。。。。 }, { id: "cbc357ccb763df2852fee8c4fc7d55f2", parallelism: 12, operator: "", operator_strategy: "", description: "Source: Custom Source -> Flat Map", optimizer_properties: {} } ] } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
1.3.2 开发者模式获取指标url
指标非常多,不需要记住每个指标的请求的URL格式?可以进入flink任务的UI界面,按住F12进入开发者模式,然后我们点击任意一个metric指标,便能立即看到每个指标的请求的URL。比如获取flink任务的背压情况:
如下图我们点击某一个task的status,按一下f12,便看到了backpressue,点开backpressue就是获取任务背压情况的连接如下:
http://node1:8088/proxy/application_1609508087977_0004/jobs/925224169036ef3f03a8d7fe9605b4ef/vertices/cbc357ccb763df2852fee8c4fc7d55f2/backpressure

请求连接返回的json字符串如下:我们可以获取每一个分区的背压情况,如果不是OK状态便可以进行任务报警,其他的指标获取监控值都可以这样获取 简单而又便捷。
1.3.3 代码中Flink任务运行状态
使用 flink REST API的方式,通过http请求实时获取flink任务状态,不是RUNNING状态则进行短信、电话或邮件报警,达到实时监控的效果。
package cn.itcast.hello; import java.io.BufferedReader; import java.io.InputStreamReader; import java.net.URL; import java.net.URLConnection; public class MetricsTest { public static void main(String[] args) { String result = sendGet("http://node1:8088/proxy/application_1609508087977_0004/jobs"); System.out.println(result); } public static String sendGet(String url) { String result = ""; BufferedReader in = null; try { String urlNameString = url; URL realUrl = new URL(urlNameString); URLConnection connection = realUrl.openConnection(); // 设置通用的请求属性 connection.setRequestProperty("accept", "*/*"); connection.setRequestProperty("connection", "Keep-Alive"); connection.setRequestProperty("user-agent", "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;SV1)"); // 建立实际的连接 connection.connect(); in = new BufferedReader(new InputStreamReader(connection.getInputStream())); String line; while ((line = in.readLine()) != null) { result += line; } } catch (Exception e) { System.out.println("发送GET请求出现异常!" + e); e.printStackTrace(); } // 使用finally块来关闭输入流 finally { try { if (in != null) { in.close(); } } catch (Exception e2) { e2.printStackTrace(); } } return result; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
2. Flink-性能优化
主要从以下几点:
1.复用对象
2.数据倾斜
3.异步IO
4.合理调整并行度:
- 数据过滤之后可以减少并行度 ,
- 数据合并之后再处理之前可以增加并行度
- 大量小文件写入到HDFS可以减少并行度
设置并行度方法:
1.ds.writeAsText("data/output/result1").setParallelism(1);//单个算子的设置会覆盖环境的
2.env.setParallelism(1); //环境
3.提交任务时webUI或命令行参数 flink run -p 10 //优先级低于代码设置的
4.配置文件flink-conf.yaml parallelism.default: 1 //真个集群的
- 1
- 2
- 3
- 4
2.1 History Server
flink的HistoryServer主要是用来存储和查看任务的历史记录,具体信息可以看官网
https://ci.apache.org/projects/flink/flink-docs-release-1.12/deployment/advanced/historyserver.html
# Directory to upload completed jobs to. Add this directory to the list of # monitored directories of the HistoryServer as well (see below). # 将已完成的作业上传到的目录 jobmanager.archive.fs.dir: hdfs://node01:8020/completed-jobs/ # The address under which the web-based HistoryServer listens. # 基于 Web 的 HistoryServer 的地址 historyserver.web.address: 0.0.0.0 # The port under which the web-based HistoryServer listens. # 基于 Web 的 HistoryServer 的端口号 historyserver.web.port: 8082 # Comma separated list of directories to monitor for completed jobs. # 以逗号分隔的目录列表,用于监视已完成的作业 historyserver.archive.fs.dir: hdfs://node01:8020/completed-jobs/ # Interval in milliseconds for refreshing the monitored directories. # 刷新受监控目录的时间间隔(以毫秒为单位) historyserver.archive.fs.refresh-interval: 10000
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
参数释义
○jobmanager.archive.fs.dir:flink job运行完成后的日志存放目录
○historyserver.archive.fs.dir:flink history进程的hdfs监控目录
○historyserver.web.address:flink history进程所在的主机
○historyserver.web.port:flink history进程的占用端口
○historyserver.archive.fs.refresh-interval:刷新受监视目录的时间间隔(以毫秒为单位)。
默认启动端口8082:
○bin/historyserver.sh (start|start-foreground|stop)
2.2 序列化
首先说一下 Java 原生的序列化方式:
优点:好处是比较简单通用,只要对象实现了 Serializable 接口即可;
缺点:效率比较低,而且如果用户没有指定 serialVersionUID的话,很容易出现作业重新编译后,之前的数据无法反序列化出来的情况(这也是 Spark Streaming Checkpoint 的一个痛点,在业务使用中经常出现修改了代码之后,无法从 Checkpoint 恢复的问题)
对于分布式计算来讲,数据的传输效率非常重要。好的序列化框架可以通过较低的序列化时间和较低的内存占用大大提高计算效率和作业稳定性。
在数据序列化上,Flink 和 Spark 采用了不同的方式
Spark 对于所有数据默认采用 Java 原生序列化方式,用户也可以配置使用 Kryo;相比于 Java 原生序列化方式,无论是在序列化效率还是序列化结果的内存占用上,Kryo 则更好一些(Spark 声称一般 Kryo 会比 Java 原生节省 10x 内存占用);Spark 文档中表示它们之所以没有把 Kryo 设置为默认序列化框架的唯一原因是因为 Kryo 需要用户自己注册需要序列化的类,并且建议用户通过配置开启 Kryo。
Flink 则是自己实现了一套高效率的序列化方法。
2.3 复用对象
比如如下代码:
stream
.apply(new WindowFunction<WikipediaEditEvent, Tuple2<String, Long>, String, TimeWindow>() {
@Override
public void apply(String userName, TimeWindow timeWindow, Iterable<WikipediaEditEvent> iterable, Collector<Tuple2<String, Long>> collector) throws Exception {
long changesCount = ...
// A new Tuple instance is created on every execution
collector.collect(new Tuple2<>(userName, changesCount));
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
这种做法其实还间接创建了Long类的实例。
为了解决这个问题,Flink有许多所谓的value class:IntValue、LongValue、StringValue、FloatValue等。下面介绍一下如何使用它们:
stream .apply(new WindowFunction<WikipediaEditEvent, Tuple2<String, Long>, String, TimeWindow>() { // Create a mutable count instance private LongValue count = new LongValue(); // Assign mutable count to the tuple private Tuple2<String, LongValue> result = new Tuple<>("", count); @Override // Notice that now we have a different return type public void apply(String userName, TimeWindow timeWindow, Iterable<WikipediaEditEvent> iterable, Collector<Tuple2<String, LongValue>> collector) throws Exception { long changesCount = ... // Set fields on an existing object instead of creating a new one result.f0 = userName; // Update mutable count value count.setValue(changesCount); // Reuse the same tuple and the same LongValue instance collector.collect(result); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
2.4 数据倾斜
我们的flink程序中如果使用了keyBy等分组的操作,很容易就出现数据倾斜的情况,数据倾斜会导致整体计算速度变慢,有些子节点甚至接受不到数据,导致分配的资源根本没有利用上。
带有窗口的操作
○带有窗口的每个窗口中所有数据的分布不平均,某个窗口处理数据量太大导致速率慢
○导致Source数据处理过程越来越慢
○再导致所有窗口处理越来越慢
不带有窗口的操作
○有些子节点接受处理的数据很少,甚至得不到数据,导致分配的资源根本没有利用上
WebU查看数据倾斜体现:
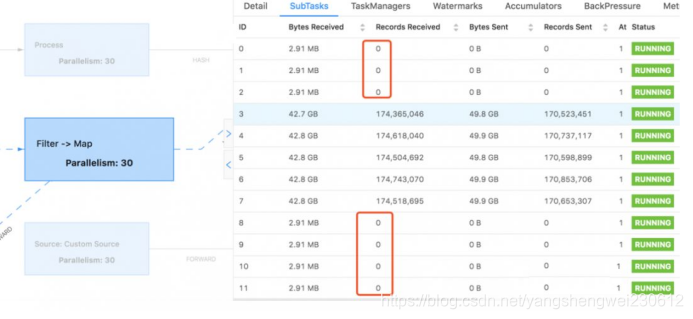
WebUI中Subtasks中打开每个窗口可以看到每个窗口进程的运行情况:如上图,数据分布很不均匀,导致部分窗口数据处理缓慢
优化方式:
对key进行均匀的打散处理(hash,加盐等)
自定义分区器
使用Rebalabce
注意:Rebalance是在数据倾斜的情况下使用,不倾斜不要使用,否则会因为shuffle产生大量的网络开销
3. Flink-内存管理
总结-面试
- 减少full gc时间:因为所有常用数据都在Memory Manager里,这部分内存的生命周期是伴随TaskManager管理的而不会被GC回收。其他的常用数据对象都是用户定义的数据对象,这部分会快速的被GC回收
- 减少OOM:所有的运行时的内存应用都从池化的内存中获取,而且运行时的算法可以在内存不足的时候将数据写到堆外内存
- 节约空间:由于Flink自定序列化/反序列化的方法,所有的对象都以二进制的形式存储,降低消耗
- 高效的二进制操作和缓存友好:二进制数据以定义好的格式存储,可以高效地比较与操作。另外,该二进制形式可以把相关的值,以及hash值,键值和指针等相邻地放进内存中。这使得数据结构可以对CPU高速缓存更友好,可以从CPU的 L1/L2/L3 缓存获得性能的提升,也就是Flink的数据存储二进制格式符合CPU缓存的标准,非常方便被CPU的L1/L2/L3各级别缓存利用,比内存还要快!
3.1 问题引入
Flink本身基本是以Java语言完成的,理论上说,直接使用JVM的虚拟机的内存管理就应该更简单方便,但Flink还是单独抽象出了自己的内存管理
因为Flink是为大数据而产生的,而大数据使用会消耗大量的内存,而JVM的内存管理管理设计是兼顾平衡的,不可能单独为了大数据而修改,这对于Flink来说,非常的不灵活,而且频繁GC会导致长时间的机器暂停应用,这对于大数据的应用场景来说也是无法忍受的。
JVM在大数据环境下存在的问题:
1.Java 对象存储密度低。在HotSpot JVM中,每个对象占用的内存空间必须是8的倍数,那么一个只包含 boolean 属性的对象就要占用了16个字节内存:对象头占了8个,boolean 属性占了1个,对齐填充占了7个。而实际上我们只想让它占用1个bit。
2.在处理大量数据尤其是几十甚至上百G的内存应用时会生成大量对象,Java GC可能会被反复触发,其中Full GC或Major GC的开销是非常大的,GC 会达到秒级甚至分钟级。
3.OOM 问题影响稳定性。OutOfMemoryError是分布式计算框架经常会遇到的问题,当JVM中所有对象大小超过分配给JVM的内存大小时,就会发生OutOfMemoryError错误,导致JVM崩溃,分布式框架的健壮性和性能都会受到影响。
3.2 内存划分
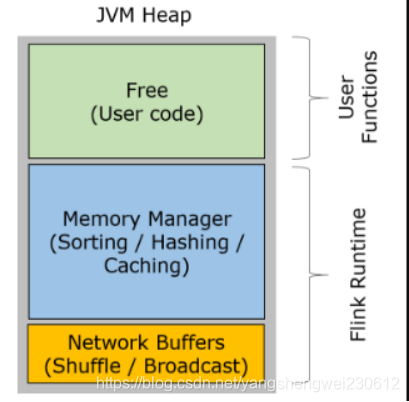
注意:Flink的内存管理是在JVM的基础之上,自己进行的管理,但是还没有逃脱的JVM,具体怎么实现,现阶段我们搞不定
- 网络缓冲区Network Buffers:这个是在TaskManager启动的时候分配的,这是一组用于缓存网络数据的内存,每个块是32K,默认分配2048个,可以通过“taskmanager.network.numberOfBuffers”修改
- 内存池Memory Manage pool:大量的Memory Segment块,用于运行时的算法(Sort/Join/Shufflt等),这部分启动的时候就会分配。默认情况下,占堆内存的70% 的大小。
- 用户使用内存Remaining (Free) Heap: 这部分的内存是留给用户代码以及 TaskManager的数据使用的。
3.3 堆外内存
除了JVM之上封装的内存管理,还会有个一个很大的堆外内存,用来执行一些IO操作
启动超大内存(上百GB)的JVM需要很长时间,GC停留时间也会很长(分钟级)。
使用堆外内存可以极大地减小堆内存(只需要分配Remaining Heap),使得 TaskManager 扩展到上百GB内存不是问题。
进行IO操作时,使用堆外内存(可以理解为使用操作系统内存)可以zero-copy,使用堆内JVM内存至少要复制一次(需要在操作系统和JVM直接进行拷贝)。
堆外内存在进程间是共享的。
总结:
Flink相对于Spark,堆外内存该用还是用, 堆内内存管理做了自己的封装,不受JVM的GC影响
3.4 序列化与反序列化
Flink除了对堆内内存做了封装之外,还实现了自己的序列化和反序列化机制
序列化与反序列化可以理解为编码与解码的过程。序列化以后的数据希望占用比较小的空间,而且数据能够被正确地反序列化出来。为了能正确反序列化,序列化时仅存储二进制数据本身肯定不够,需要增加一些辅助的描述信息。此处可以采用不同的策略,因而产生了很多不同的序列化方法。
Java本身自带的序列化和反序列化的功能,但是辅助信息占用空间比较大,在序列化对象时记录了过多的类信息。
Flink实现了自己的序列化框架,使用TypeInformation表示每种数据类型,所以可以只保存一份对象Schema信息,节省存储空间。又因为对象类型固定,所以可以通过偏移量存取。
TypeInformation 支持以下几种类型:
BasicTypeInfo: 任意Java 基本类型或 String 类型。
BasicArrayTypeInfo: 任意Java基本类型数组或 String 数组。
WritableTypeInfo: 任意 Hadoop Writable 接口的实现类。
TupleTypeInfo: 任意的 Flink Tuple 类型(支持Tuple1 to Tuple25)。Flink tuples 是固定长度固定类型的Java Tuple实现。
CaseClassTypeInfo: 任意的 Scala CaseClass(包括 Scala tuples)。
PojoTypeInfo: 任意的 POJO (Java or Scala),例如,Java对象的所有成员变量,要么是 public 修饰符定义,要么有 getter/setter 方法。
GenericTypeInfo: 任意无法匹配之前几种类型的类。(除了该数据使用kyro序列化.上面的其他的都是用二进制)
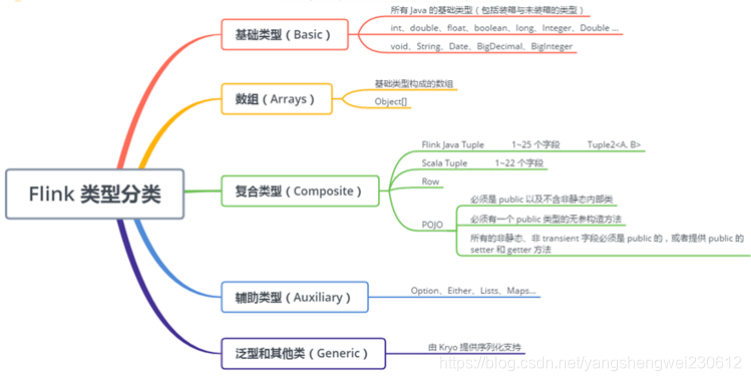
针对前六种类型数据集,Flink皆可以自动生成对应的TypeSerializer,能非常高效地对数据集进行序列化和反序列化。对于最后一种数据类型,Flink会使用Kryo进行序列化和反序列化。每个TypeInformation中,都包含了serializer,类型会自动通过serializer进行序列化,然后用Java Unsafe接口(具有像C语言一样的操作内存空间的能力)写入MemorySegments。

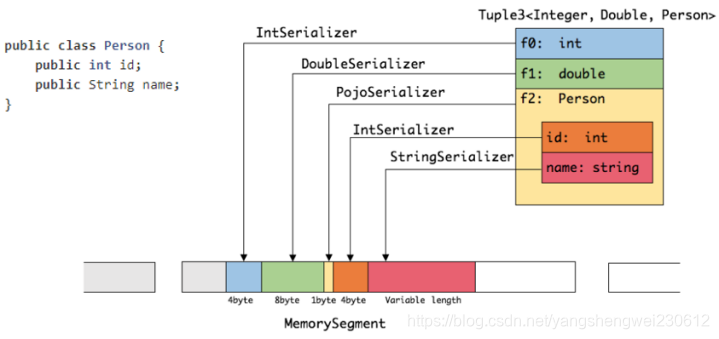
3.5 操纵二进制数据
Flink中的group、sort、join 等操作可能需要访问海量数据。以sort为例。
首先,Flink 会从 MemoryManager 中申请一批 MemorySegment,用来存放排序的数据。
这些内存会分为两部分:
一个区域是用来存放所有对象完整的二进制数据。
另一个区域用来存放指向完整二进制数据的指针以及定长的序列化后的key(key+pointer)。
将实际的数据和point+key分开存放有两个目的:
第一,交换定长块(key+pointer)更高效,不用交换真实的数据也不用移动其他key和pointer。
第二,这样做是缓存友好的,因为key都是连续存储在内存中的,可以增加cache命中。 排序会先比较 key 大小,这样就可以直接用二进制的 key 比较而不需要反序列化出整个对象。访问排序后的数据,可以沿着排好序的key+pointer顺序访问,通过 pointer 找到对应的真实数据。
在交换过程中,只需要比较key就可以完成sort的过程,只有key1 == key2的情况,才需要反序列化拿出实际的对象做比较,而比较之后只需要交换对应的key而不需要交换实际的对象

4. Flink VS Spark
应用场景
Spark:主要用作离线批处理 , 对延迟要求不高的实时处理(微批) ,DataFrame和DataSetAPI 也支持 “流批一体”
Flink:主要用作实时处理 ,注意Flink1.12开始支持真正的流批一体
Spark :
SparkStreaming: 微批
StructuredStreaming: 微批(连续处理在实验中)
Flink : 是真真正正的流式处理, 只不过对于低延迟和高吞吐做了平衡
早期就确定了后续的方向:基于事件的流式数据处理框架!
flink的批处理,计算是试试按流处理,只是处理后的数据攒够一批再发给下游。只计算一次,性能高于spark

- 1
- 2
- 3
- 4
想提高flink的实时性调小下面两个参数,想要高吞吐,调大,一般默认即可
env.setBufferTimeout - 默认100ms
taskmanager.memory.segment-size - 默认32KB
- 1
- 2
API
Spark : RDD(不推荐) /DSteam(不推荐)/DataFrame和DataSet
Flink : DataSet(1.12软弃用) 和 DataStream /Table&SQL(快速发展中)
核心角色/流程原理
Flink
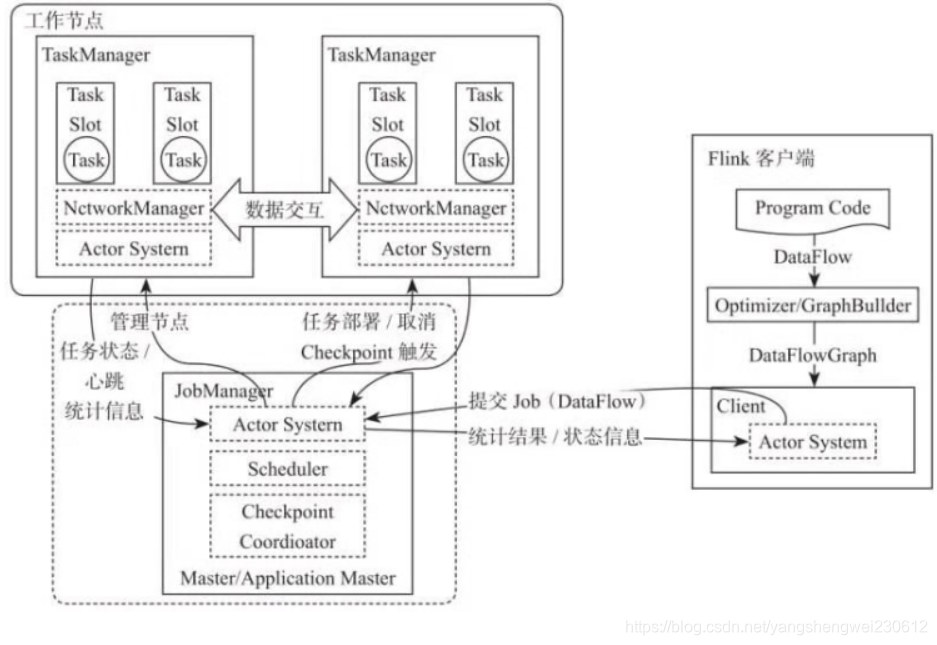
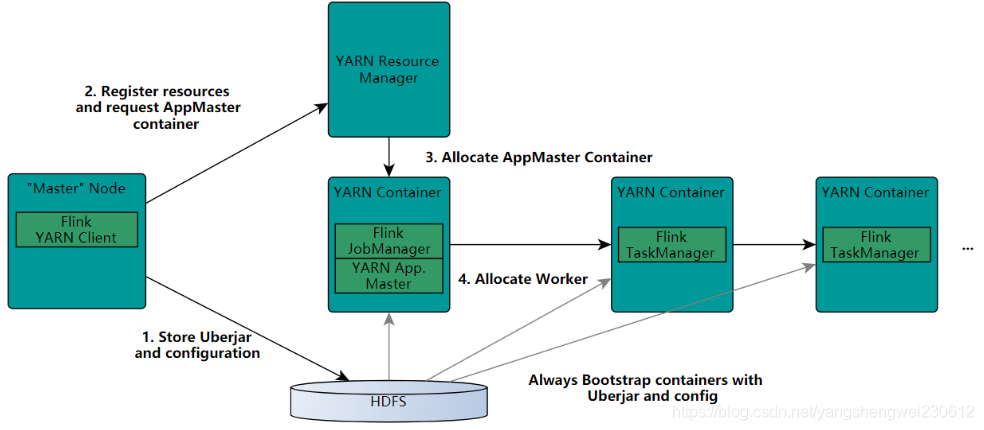
时间机制
Spark : SparkStreaming只支持处理时间 StructuredStreaming开始支持事件时间
Flink : 直接支持事件时间 /处理时间/摄入时间
容错机制
Spark : 缓存/持久化 +Checkpoint(应用级别) StructuredStreaming中的Checkpoint也开始借鉴Flink使用Chandy-Lamport algorithm分布式快照算法
Flink: State + Checkpoint(Operator级别) + 自动重启策略 + Savepoint
窗口
Spark中的支持基于时间/数量的滑动/滚动 要求windowDuration和slideDuration必须是batchDuration的倍数
Flink中的窗口机制更加灵活/功能更多
支持基于时间/数量的滑动/滚动 和 会话窗口
整合Kafka
SparkStreaming整合Kafka: 支持offset自动维护/手动维护 , 支持动态分区检测 无需配置
props.setProperty(“flink.partition-discovery.interval-millis”,“5000”);//会开启一个后台线程每隔5s检测一下Kafka的分区情况,实现动态分区检测
props.setProperty("flink.partition-discovery.interval-millis","5000");//会开启一个后台线程每隔5s检测一下Kafka的分区情况,实现动态分区检测
- 1
其他的
源码编程语言
Flink的高级功能 : Flink CEP可以实现 实时风控…
4.1 运行角色
Spark Streaming 运行时的角色(standalone 模式)主要有:
Master:主要负责整体集群资源的管理和应用程序调度;
Worker:负责单个节点的资源管理,driver 和 executor 的启动等;
Driver:用户入口程序执行的地方,即 SparkContext 执行的地方,主要是 DAG 生成、stage 划分、task 生成及调度;
Executor:负责执行 task,反馈执行状态和执行结果。
Flink 运行时的角色(standalone 模式)主要有:
Jobmanager: 协调分布式执行,他们调度任务、协调 checkpoints、协调故障恢复等。至少有一个 JobManager。高可用情况下可以启动多个 JobManager,其中一个选举为 leader,其余为 standby;
Taskmanager: 负责执行具体的 tasks、缓存、交换数据流,至少有一个 TaskManager;
Slot: 每个 task slot 代表 TaskManager 的一个固定部分资源,Slot 的个数代表着 taskmanager 可并行执行的 task 数。
4.2 生态

4.3 运行模型
Spark Streaming 是微批处理,运行的时候需要指定批处理的时间,每次运行 job 时处理一个批次的数据,流程如图所示:

Flink 是基于事件驱动的,事件可以理解为消息。事件驱动的应用程序是一种状态应用程序,它会从一个或者多个流中注入事件,通过触发计算更新状态,或外部动作对注入的事件作出反应。
4.4 编程模型对比
编程模型对比,主要是对比 flink 和 Spark Streaming 两者在代码编写上的区别。
Spark Streaming
Spark Streaming 与 kafka 的结合主要是两种模型:
基于 receiver dstream;
基于 direct dstream。
以上两种模型编程机构近似,只是在 api 和内部数据获取有些区别,新版本的已经取消了基于 receiver 这种模式,企业中通常采用基于 direct Dstream 的模式。
al Array(brokers, topics) = args// 创建一个批处理时间是2s的context
val sparkConf = new SparkConf().setAppName("DirectKafkaWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(2))
// 使用broker和topic创建DirectStream
val topicsSet = topics.split(",").toSet
val kafkaParams = Map[String, String]("metadata.broker.list" -> brokers)
val messages = KafkaUtils.createDirectStream[String, String]( ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String, String](topicsSet, kafkaParams))
// Get the lines, split them into words, count the words and print
val lines = messages.map(_.value)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1L)).reduceByKey(_ + _)
wordCounts.print() // 启动流
ssc.start()
ssc.awaitTermination()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
通过以上代码我们可以 get 到:
设置批处理时间
创建数据流
编写transform
编写action
启动执行
Flink
接下来看 flink 与 kafka 结合是如何编写代码的。Flink 与 kafka 结合是事件驱动,大家可能对此会有疑问,消费 kafka 的数据调用 poll 的时候是批量获取数据的(可以设置批处理大小和超时时间),这就不能叫做事件触发了。而实际上,flink 内部对 poll 出来的数据进行了整理,然后逐条 emit,形成了事件触发的机制。
下面的代码是 flink 整合 kafka 作为 data source 和 data sink:
treamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.getConfig().disableSysoutLogging(); env.getConfig().setRestartStrategy(RestartStrategies.fixedDelayRestart(4, 10000)); // create a checkpoint every 5 seconds env.enableCheckpointing(5000); // make parameters available in the web interface env.getConfig().setGlobalJobParameters(parameterTool); env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); // ExecutionConfig.GlobalJobParameters env.getConfig().setGlobalJobParameters(null); DataStream<KafkaEvent> input = env .addSource(new FlinkKafkaConsumer010<>( parameterTool.getRequired("input-topic"), new KafkaEventSchema(), parameterTool.getProperties()) .assignTimestampsAndWatermarks(new CustomWatermarkExtractor())) .setParallelism(1).rebalance() .keyBy("word") .map(new RollingAdditionMapper()).setParallelism(0); input.addSink(new FlinkKafkaProducer010<>(parameterTool.getRequired("output-topic"), new KafkaEventSchema(), parameterTool.getProperties())); env.execute("Kafka 0.10 Example");
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
从 Flink 与 kafka 结合的代码可以 get 到:
注册数据 source
编写运行逻辑
注册数据 sink
调用 env.execute
相比于 Spark Streaming 少了设置批处理时间,还有一个显著的区别是 flink 的所有算子都是 lazy 形式的,调用 env.execute 会构建 jobgraph。client 端负责 Jobgraph 生成并提交它到集群运行;而 Spark Streaming的操作算子分 action 和 transform,其中仅有 transform 是 lazy 形式,而且 DGA 生成、stage 划分、任务调度是在 driver 端进行的,在 client 模式下 driver 运行于客户端处。
4.5 任务调度原理
Spark 任务调度
Spark Streaming 任务如上文提到的是基于微批处理的,实际上每个批次都是一个 Spark Core 的任务。对于编码完成的 Spark Core 任务在生成到最终执行结束主要包括以下几个部分:
构建 DGA 图;
划分 stage;
生成 taskset;
调度 task。
对于 job 的调度执行有 fifo 和 fair 两种模式,Task 是根据数据本地性调度执行的。 假设每个 Spark Streaming 任务消费的 kafka topic 有四个分区,中间有一个 transform操作(如 map)和一个 reduce 操作,如图所示:
Flink 任务调度
对于 flink 的流任务客户端首先会生成 StreamGraph,接着生成 JobGraph,然后将 jobGraph 提交给 Jobmanager 由它完成 jobGraph 到 ExecutionGraph 的转变,最后由 jobManager 调度执行。
如图所示有一个由 data source、MapFunction和 ReduceFunction 组成的程序,data source 和 MapFunction 的并发度都为 4,而 ReduceFunction 的并发度为 3。一个数据流由 Source-Map-Reduce 的顺序组成,在具有 2 个TaskManager、每个 TaskManager 都有 3 个 Task Slot 的集群上运行。
可以看出 flink 的拓扑生成提交执行之后,除非故障,否则拓扑部件执行位置不变,并行度由每一个算子并行度决定,类似于 storm。而 spark Streaming 是每个批次都会根据数据本地性和资源情况进行调度,无固定的执行拓扑结构。 flink 是数据在拓扑结构里流动执行,而 Spark Streaming 则是对数据缓存批次并行处理。
4.6 时间机制对比
流处理的时间
流处理程序在时间概念上总共有三个时间概念:
处理时间
处理时间是指每台机器的系统时间,当流程序采用处理时间时将使用运行各个运算符实例的机器时间。处理时间是最简单的时间概念,不需要流和机器之间的协调,它能提供最好的性能和最低延迟。然而在分布式和异步环境中,处理时间不能提供消息事件的时序性保证,因为它受到消息传输延迟,消息在算子之间流动的速度等方面制约。
事件时间
事件时间是指事件在其设备上发生的时间,这个时间在事件进入 flink 之前已经嵌入事件,然后 flink 可以提取该时间。基于事件时间进行处理的流程序可以保证事件在处理的时候的顺序性,但是基于事件时间的应用程序必须要结合 watermark 机制。基于事件时间的处理往往有一定的滞后性,因为它需要等待后续事件和处理无序事件,对于时间敏感的应用使用的时候要慎重考虑。
注入时间
注入时间是事件注入到 flink 的时间。事件在 source 算子处获取 source 的当前时间作为事件注入时间,后续的基于时间的处理算子会使用该时间处理数据。
相比于事件时间,注入时间不能够处理无序事件或者滞后事件,但是应用程序无序指定如何生成 watermark。在内部注入时间程序的处理和事件时间类似,但是时间戳分配和 watermark 生成都是自动的。
Spark 时间机制
Spark Streaming 只支持处理时间,Structured streaming 支持处理时间和事件时间,同时支持 watermark 机制处理滞后数据。
Flink 时间机制
flink 支持三种时间机制:事件时间,注入时间,处理时间,同时支持 watermark 机制处理滞后数据。
4.7 kafka 动态分区检测
Spark Streaming
对于有实时处理业务需求的企业,随着业务增长数据量也会同步增长,将导致原有的 kafka 分区数不满足数据写入所需的并发度,需要扩展 kafka 的分区或者增加 kafka 的 topic,这时就要求实时处理程序,如 SparkStreaming、flink 能检测到 kafka 新增的 topic 、分区及消费新增分区的数据。
接下来结合源码分析,Spark Streaming 和 flink 在 kafka 新增 topic 或 partition 时能否动态发现新增分区并消费处理新增分区的数据。 Spark Streaming 与 kafka 结合有两个区别比较大的版本,如图所示是官网给出的对比数据:
4.8 容错机制及处理语义
本节内容主要是想对比两者在故障恢复及如何保证仅一次的处理语义。这个时候适合抛出一个问题:实时处理的时候,如何保证数据仅一次处理语义?
Spark Streaming 保证仅一次处理
对于 Spark Streaming 任务,我们可以设置 checkpoint,然后假如发生故障并重启,我们可以从上次 checkpoint 之处恢复,但是这个行为只能使得数据不丢失,可能会重复处理,不能做到恰一次处理语义。
对于 Spark Streaming 与 kafka 结合的 direct Stream 可以自己维护 offset 到 zookeeper、kafka 或任何其它外部系统,每次提交完结果之后再提交 offset,这样故障恢复重启可以利用上次提交的 offset 恢复,保证数据不丢失。但是假如故障发生在提交结果之后、提交 offset 之前会导致数据多次处理,这个时候我们需要保证处理结果多次输出不影响正常的业务。
由此可以分析,假设要保证数据恰一次处理语义,那么结果输出和 offset 提交必须在一个事务内完成。在这里有以下两种做法:
repartition(1) : Spark Streaming 输出的 action 变成仅一个 partition,这样可以利用事务去做:
个操作完成,不会数据丢失,也不会重复处理。故障恢复的时候可以利用上次提交结果带的 offset。
Flink 与 kafka 0.11 保证仅一次处理
若要 sink 支持仅一次语义,必须以事务的方式写数据到 Kafka,这样当提交事务时两次 checkpoint 间的所有写入操作作为一个事务被提交。这确保了出现故障或崩溃时这些写入操作能够被回滚。
在一个分布式且含有多个并发执行 sink 的应用中,仅仅执行单次提交或回滚是不够的,因为所有组件都必须对这些提交或回滚达成共识,这样才能保证得到一致性的结果。Flink 使用两阶段提交协议以及预提交(pre-commit)阶段来解决这个问题。
本例中的 Flink 应用如图 11 所示包含以下组件:
一个source,从Kafka中读取数据(即KafkaConsumer)
一个时间窗口化的聚会操作
一个sink,将结果写回到Kafka(即KafkaProducer)
5. Flink-网络流控及反压
背压/反压
back pressure
Spark: PIDRateEsimator ,PID算法实现一个速率评估器(统计DAG调度时间,任务处理时间,数据条数等, 得出一个消息处理最大速率, 进而调整根据offset从kafka消费消息的速率),
Flink: 基于credit – based 流控机制,在应用层模拟 TCP 的流控机制(上游发送数据给下游之前会先进行通信,告诉下游要发送的blockSize, 那么下游就可以准备相应的buffer来接收, 如果准备ok则返回一个credit凭证,上游收到凭证就发送数据, 如果没有准备ok,则不返回credit,上游等待下一次通信返回credit)
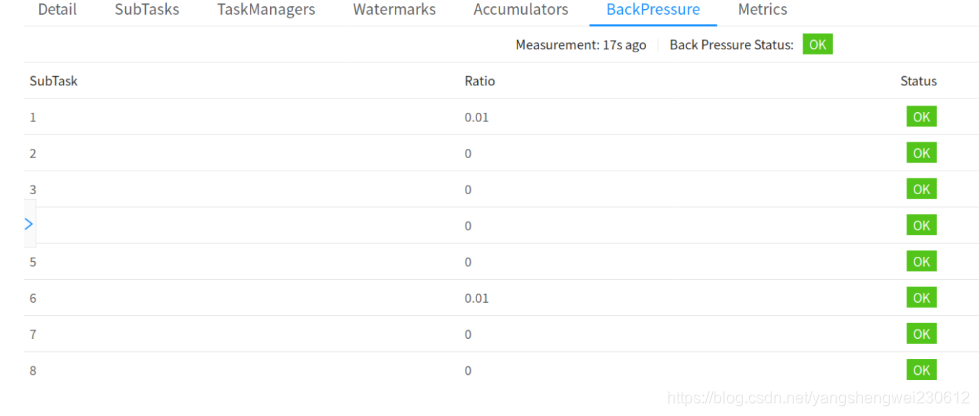
阻塞占比在 web 上划分了三个等级:
OK: 0 <= Ratio <= 0.10,表示状态良好;
LOW: 0.10 < Ratio <= 0.5,表示有待观察;
HIGH: 0.5 < Ratio <= 1,表示要处理了(增加并行度/subTask/检查是否有数据倾斜/增加内存…)。
例如,0.01,代表着100次中有一次阻塞在内部调用
5.1.6 总结
网络流控是为了在上下游速度不匹配的情况下,防止下游出现过载
网络流控有静态限速和动态反压两种手段
Flink 1.5 之前是基于 TCP 流控 + bounded buffer 实现反压
Flink 1.5 之后实现了自己托管的 credit – based 流控机制,在应用层模拟 TCP 的流控机制
就是每一次 ResultSubPartition 向 InputChannel 发送消息的时候都会发送一个 backlog size 告诉下游准备发送多少消息,下游就会去计算有多少的 Buffer 去接收消息,算完之后如果有充足的 Buffer 就会返还给上游一个 Credit 告知他可以发送消息
思考
有了动态反压,静态限速是不是完全没有作用了?
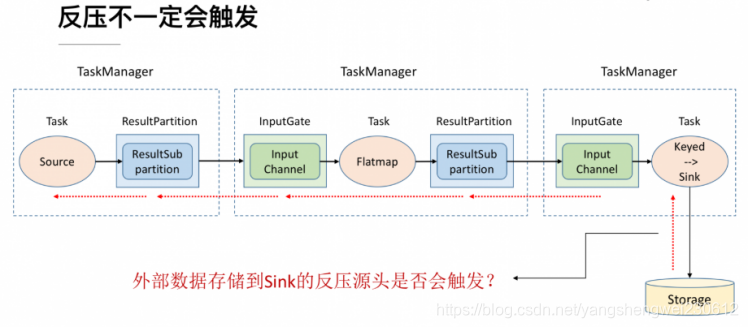
实际上动态反压不是万能的,我们流计算的结果最终是要输出到一个外部的存储(Storage),外部数据存储到 Sink 端的反压是不一定会触发的,这要取决于外部存储的实现,像 Kafka 这样是实现了限流限速的消息中间件可以通过协议将反压反馈给 Sink 端,但是像 ES 无法将反压进行传播反馈给 Sink 端,这种情况下为了防止外部存储在大的数据量下被打爆,我们就可以通过静态限速的方式在 Source 端去做限流。所以说动态反压并不能完全替代静态限速的,需要根据合适的场景去选择处理方案
5.1.7 背压状态查看
如果您看到任务的状态为“ 正常 ”,则表明没有背压。高,另一方面意味着任务是背压力。


5.1.8 背压指标含义
为了判断是否进行反压,jobmanager会每50ms触发100次stack traces。
Web界面中显示阻塞在内部方法调用的stacktraces占所有的百分比。
例如,0.01,代表着100次中有一次阻塞在内部调用。
OK: 0 <= Ratio <= 0.10
LOW: 0.10 < Ratio <= 0.5
HIGH: 0.5 < Ratio <= 1
- 1
- 2
- 3
- 4
- 5
- 6
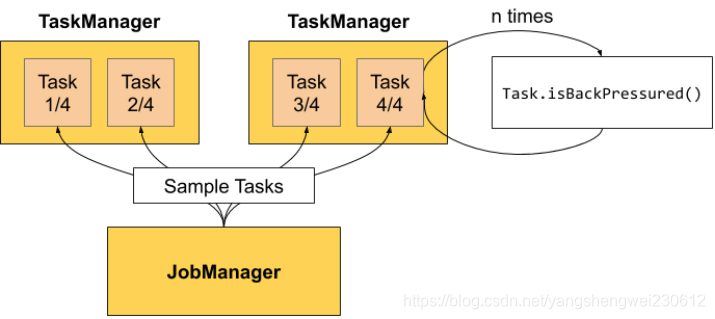
可以使用以下配置为作业管理器配置样本数:
web.backpressure.refresh-interval:不推荐使用的统计信息将在此之前过期,需要刷新(默认值:60000ms)。
web.backpressure.num-samples:用来确定背压的样本数量(默认值:100)。
web.backpressure.delay-between-samples:样品之间的延迟以确定背压(默认值:50 ms)
5.1 网络流控的概念与背景
5.1.1 为什么需要网络流控
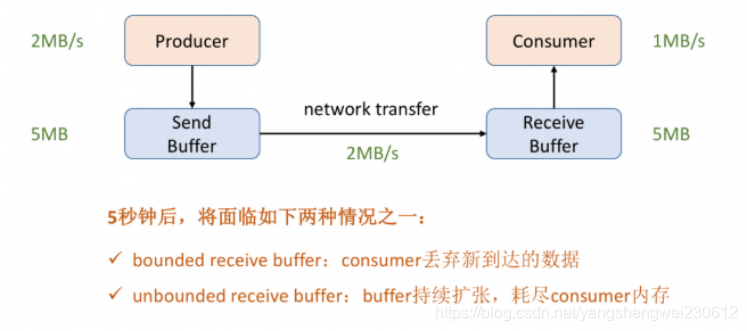
首先我们可以看下这张最精简的网络流控的图,Producer 的吞吐率是 2MB/s,Consumer 是 1MB/s,这个时候我们就会发现在网络通信的时候我们的 Producer 的速度是比 Consumer 要快的,有 1MB/s 的这样的速度差,假定我们两端都有一个 Buffer,Producer 端有一个发送用的 Send Buffer,Consumer 端有一个接收用的 Receive Buffer,在网络端的吞吐率是 2MB/s,过了 5s 后我们的 Receive Buffer 可能就撑不住了,这时候会面临两种情况:
如果 Receive Buffer 是有界的,这时候新到达的数据就只能被丢弃掉了。
如果 Receive Buffer 是无界的,Receive Buffer 会持续的扩张,最终会导致 Consumer 的内存耗尽。
5.1.2 网络流控的实现:静态限速
为了解决这个问题,我们就需要网络流控来解决上下游速度差的问题,传统的做法可以在 Producer 端实现一个类似 Rate Limiter 这样的静态限流,Producer 的发送速率是 2MB/s,但是经过限流这一层后,往 Send Buffer 去传数据的时候就会降到 1MB/s 了,这样的话 Producer 端的发送速率跟 Consumer 端的处理速率就可以匹配起来了,就不会导致上述问题。但是这个解决方案有两点限制:
事先无法预估 Consumer 到底能承受多大的速率
Consumer 的承受能力通常会动态地波动
5.1.3 网络流控的实现:动态反馈/自动反压
针对静态限速的问题我们就演进到了动态反馈(自动反压)的机制,我们需要 Consumer 能够及时的给 Producer 做一个 feedback,即告知 Producer 能够承受的速率是多少。动态反馈分为两种:
负反馈:接受速率小于发送速率时发生,告知 Producer 降低发送速率
正反馈:发送速率小于接收速率时发生,告知 Producer 可以把发送速率提上来
让我们来看几个经典案例
5.1.3.1 案例一:Storm 反压实现

上图就是 Storm 里实现的反压机制,可以看到 Storm 在每一个 Bolt 都会有一个监测反压的线程(Backpressure Thread),这个线程一但检测到 Bolt 里的接收队列(recv queue)出现了严重阻塞就会把这个情况写到 ZooKeeper 里,ZooKeeper 会一直被 Spout 监听,监听到有反压的情况就会停止发送,通过这样的方式匹配上下游的发送接收速率。
5.1.3.2 案例二:Spark Streaming 反压实现
Spark Streaming 里也有做类似这样的 feedback 机制,上图 Fecher 会实时的从 Buffer、Processing 这样的节点收集一些指标然后通过 Controller 把速度接收的情况再反馈到 Receiver,实现速率的匹配。
5.1.3.3 疑问:为什么 Flink(before V1.5)没有用类似的方式实现 feedback 机制?
首先在解决这个疑问之前我们需要先了解一下 Flink 的网络传输是一个什么样的架构
这张图就体现了 Flink 在做网络传输的时候基本的数据的流向,发送端在发送网络数据前要经历自己内部的一个流程,会有一个自己的 Network Buffer,在底层用 Netty 去做通信,Netty 这一层又有属于自己的 ChannelOutbound Buffer,因为最终是要通过 Socket 做网络请求的发送,所以在 Socket 也有自己的 Send Buffer,同样在接收端也有对应的三级 Buffer。学过计算机网络的时候我们应该了解到,TCP 是自带流量控制的。
实际上 Flink (before V1.5)就是通过 TCP 的流控机制来实现 feedback 的。
5.1.3.4 TCP 流控机制
根据下图我们来简单的回顾一下 TCP 包的格式结构。首先,他有 Sequence number 这样一个机制给每个数据包做一个编号,还有 ACK number 这样一个机制来确保 TCP 的数据传输是可靠的,除此之外还有一个很重要的部分就是 Window Size,接收端在回复消息的时候会通过 Window Size 告诉发送端还可以发送多少数据。
接下来我们来简单看一下这个过程。
TCP 流控:滑动窗口
TCP 的流控就是基于滑动窗口的机制,现在我们有一个 Socket 的发送端和一个 Socket 的接收端,目前我们的发送端的速率是我们接收端的 3 倍,这样会发生什么样的一个情况呢?假定初始的时候我们发送的 window 大小是 3,然后我们接收端的 window 大小是固定的,就是接收端的 Buffer 大小为 5。
首先,发送端会一次性发 3 个 packets,将 1,2,3 发送给接收端,接收端接收到后会将这 3 个 packets 放到 Buffer 里去。

接收端一次消费 1 个 packet,这时候 1 就已经被消费了,然后我们看到接收端的滑动窗口会往前滑动一格,这时候 2,3 还在 Buffer 当中 而 4,5,6 是空出来的,所以接收端会给发送端发送 ACK = 4 ,代表发送端可以从 4 开始发送,同时会将 window 设置为 3 (Buffer 的大小 5 减去已经存下的 2 和 3),发送端接收到回应后也会将他的滑动窗口向前移动到 4,5,6。
这时候发送端将 4,5,6 发送,接收端也能成功的接收到 Buffer 中去。
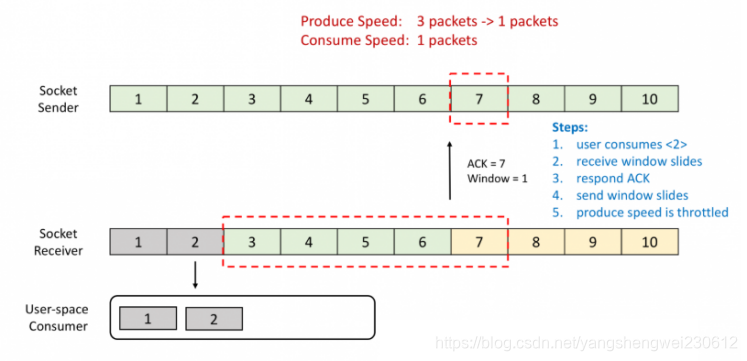
到这一阶段后,接收端就消费到 2 了,同样他的窗口也会向前滑动一个,这时候他的 Buffer 就只剩一个了,于是向发送端发送 ACK = 7、window = 1。发送端收到之后滑动窗口也向前移,但是这个时候就不能移动 3 格了,虽然发送端的速度允许发 3 个 packets 但是 window 传值已经告知只能接收一个,所以他的滑动窗口就只能往前移一格到 7 ,这样就达到了限流的效果,发送端的发送速度从 3 降到 1。

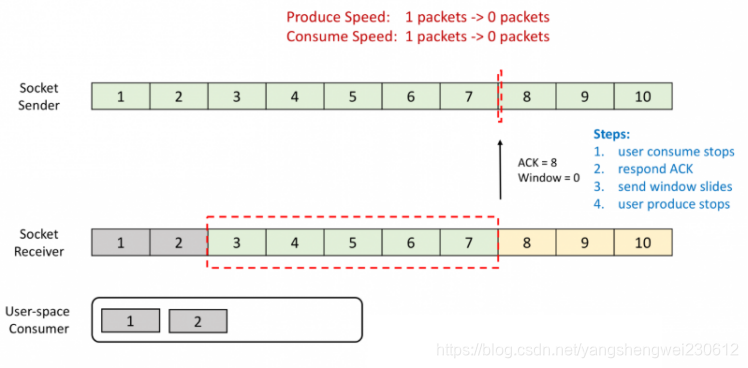
我们再看一下这种情况,这时候发送端将 7 发送后,接收端接收到,但是由于接收端的消费出现问题,一直没有从 Buffer 中去取,这时候接收端向发送端发送 ACK = 8、window = 0 ,由于这个时候 window = 0,发送端是不能发送任何数据,也就会使发送端的发送速度降为 0。这个时候发送端不发送任何数据了,接收端也不进行任何的反馈了,那么如何知道消费端又开始消费了呢?