
- 1MybatisPlus存在 sql 注入漏洞(CVE-2023-25330)解决办法
- 2spss安装后 python_python从入门到入土教程(7)——用python实现SPSS的各种功能
- 3ERROR [internal] load metadata for docker.io/library/node:20-alpine
- 4字节跳动大规模实践埋点自动化测试框架设计_web 埋点 框架
- 5SwiftUI简单基础知识学习
- 6输出多分类模型的混淆矩阵(R语言)_如何在训练后,输出混淆矩阵
- 7EfficientSAM:小模型也能万物分割!Meta改进SAM,参数仅为原版5%
- 8SpringCloud项目日志接入ELK实战_如何将log.info日志推送到elk
- 9C++11特性《 右值引用-<完美转发>、lambda表达式》
- 10鸿蒙DevEco Studio 4.1 Release-模拟器启动方式错误
2024深圳杯数学建模C题完整思路+配套解题代码+半成品参考论文持续更新_2024深圳杯c题优秀论文
赞
踩
所有资料持续更新,最晚我们将于5.9号更新参考论文。
【无水印word】2024深圳杯A题成品论文23页+mtlab(python)双版本代码![]() https://www.jdmm.cc/file/2710565
https://www.jdmm.cc/file/2710565
2024深圳杯数学建模C题完整思路+配套解题代码+半成品参考论文持续更新![]() https://www.jdmm.cc/file/2710545
https://www.jdmm.cc/file/2710545

深圳杯数学建模挑战赛2024C题
编译器版本的识别问题
随着程序设计语言的不断变化,编译器也会不断更新。例如,GCC(the GNU Compiler Collection)就已经更新到了13.2.0版本[1]。不同版本的编译器在编译同一程序脚本时,编译结果会存在一定的差异;相同版本的编译器在使用不同编译选项时,编译结果也会出现差异。能否利用编译结果差异区分编译器的版本?
难点:1、切换编译器得到编译结果;2、选择编译结果的主要特征。
2000年全国大学生数学建模竞赛A题DNA序列分类问题
给定20个已知类别的DNA序列,其中序列标号1-10 为A类,11-20为B类。请从中提取特征,构造分类方法,并用这些已知类别的序列,衡量你的方法是否足够好。然后用你认为满意的方法,对另外20个未标明类别的人工序列(标号21—40)进行分类 ,例如下面三个序列
atggataacggaaacaaaccagacaaacttcggtagaaatacagaagcttagatgcatatgttttttaaataaaatttgtattattatggtatcataaaaaaaggttgcga A类
gtattacaggcagaccttatttaggttattattattatttggattttttttttttttttttttaagttaaccgaattattttctttaaagacgttacttaatgtcaatgc B类
ccattagggtttatttacctgtttattttttcccgagaccttaggtttaccgtactttttaacggtttacctttgaaatttttggactagcttaccctggatttaacggc ?
- GCC编译器的安装教程(Windows环境):GCC编译器的安装教程(Windows环境)_gcc编译器安装教程-CSDN博客;
- GCC使用教程:浅显易懂的GCC使用教程——初级篇_gcc -ddebug-CSDN博客
- 附件中提供的是源码,参考源码安装GCC(Linux环境),构建Linux环境可以通过创建虚拟机或者电脑上再安装Linux系统。
- 利用mingw安装GCC:Index of /mingw
- 在VScode 中使用EASYX详细教程:在VScode 中使用EASYX详细教程(VScode+MSVC+Easy X)_easyx vscode 使用方法-CSDN博客
附件中提供的.cpp 文件是C++编程的源代码文件,包含了程序员编写的程序逻辑。为了能够在计算机上运行这个程序,我们需要将源代码编译成机器可以理解的指令,这个过程就是编译。
编译过程通常由编译器完成,如GCC。编译器读取 .cpp 文件,检查语法错误,将源代码转换成机器码,并可能进行一些优化。这个过程结束后,编译器会生成一个或多个文件,其中在Windows系统上通常是一个 .exe 文件(可执行文件)。.exe 文件包含了程序运行所需的所有机器码和可能的数据,它是源代码经过编译后的最终产品。可以直接运行这个 .exe 文件来执行程序。
- 对于整个编译过程
-
步骤一:预处理(预编译):编译处理宏定义等宏命令,生成后缀为“.i”的文件
步骤二:编译:将预处理后的文件转换成汇编语言,生成后缀为“.s”的文件
步骤三:汇编:由汇编生成的文件翻译为二进制目标文件,生成后缀为“.o”的文件
步骤四:连接:多个目标文件(二进制)结合库函数等综合成的能直接独立执行的执行文件,生成后缀为“.exe”的文件
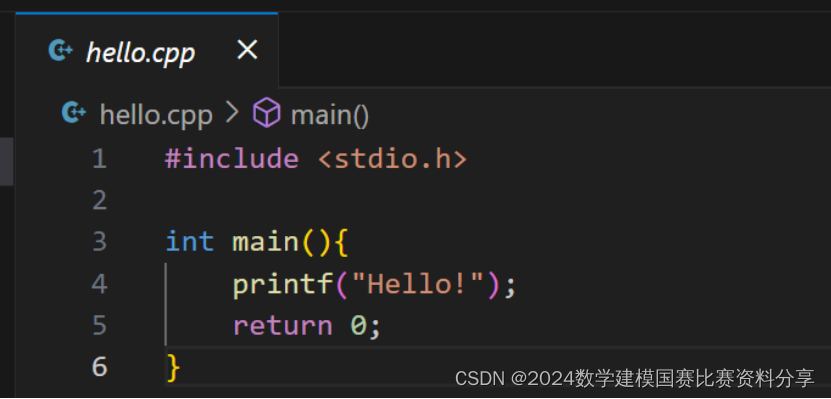
举个例子:输出“Hello!”的代码
步骤一:g++ -E hello.cpp -o hello.i // 预处理

问题4 给出几条提高由编译结果区分编译器版本的判别函数性能的建议,包括区分度和对原代码的泛化性。
- 特征选择:
- 编译选项和标志:不同的编译器和版本可能支持不同的编译选项和标志。收集这些选项作为特征,可以提高区分度。
- 警告和错误信息:编译器在编译过程中产生的警告和错误信息往往包含了关于编译器版本的线索。可以分析这些文本信息,提取关键词或模式作为特征。
- 生成的代码特征:比较不同编译器版本生成的汇编代码或机器代码,寻找其中的差异作为特征。例如,指令集、优化级别、代码布局等。
- 算法优化:
- 使用机器学习算法:可以利用机器学习算法(如决策树、随机森林、神经网络等)来训练判别函数。这些算法可以自动学习从特征到编译器版本的映射关系。
- 特征降维:如果特征数量过多,可以考虑使用主成分分析(PCA)、自编码器等技术进行特征降维,减少计算复杂度并提高泛化能力。
- 参数调优:对于使用的机器学习算法,进行参数调优以找到最佳性能。这可以通过交叉验证、网格搜索等方法实现。
- 数据增强:
- 增加样本多样性:收集更多不同编译器版本和设置下的编译结果样本,以增加判别函数的泛化能力。
- 数据扩充:通过对已有样本进行变换或扰动(如添加噪声、改变字体大小等),生成新的样本,以增加数据的丰富性。
- 模型评估与反馈:
- 评估指标:选择合适的评估指标(如准确率、召回率、F1分数等)来评估判别函数的性能。
- 反馈循环:在实际应用中,不断收集新的编译结果数据,对判别函数进行迭代更新和优化,以提高其性能。
- 考虑编译器特性:
- 编译器特定的元信息:某些编译器可能在编译结果中包含特定的元信息,如版本字符串、时间戳等。提取这些信息可以显著提高区分度。
- 编译器兼容性:考虑到不同编译器之间的兼容性问题,判别函数应尽可能避免依赖于特定编译器的特性,以提高泛化性。
- 集成方法:
- 结合多个判别函数:可以训练多个判别函数,并将它们的输出进行集成(加权平均等),以提高整体的性能和稳定性。

