
热门标签
热门文章
- 1计算机图形图像技术(OpenCV核心功能、图像变换与图像平滑处理)_dft处理的复数数组双通道结果
- 2Datax入门使用_datax使用
- 3iOS 真机调试 No profile for team xxxx matching xx found_no profile for team 'jinquan wang (personal team)'
- 4ecc加解密算法 c++_ECC相关算法解析
- 5从零开始使用UEC++创建一个简易的AI_ue aicontroller类
- 6Python基础知识点梳理_python知识体系
- 7C++第五章——多态与虚函数_静态函数可以是虚函数吗
- 8k8s-CCE创建工作负载变量引用
- 9字节跳动(抖音)软件测试月薪23K岗、技术总监三面面试题最新出炉_it技术总监面试题
- 10mysql的去重添加ing_SQL从入门到不放弃(ing)
当前位置: article > 正文
Mozilla发布最大公共语音数据集Common Voice
作者:正经夜光杯 | 2024-07-02 06:21:12
赞
踩
sharing-our-common-voices-mozilla-releases-the-largest-to-date-public-domain
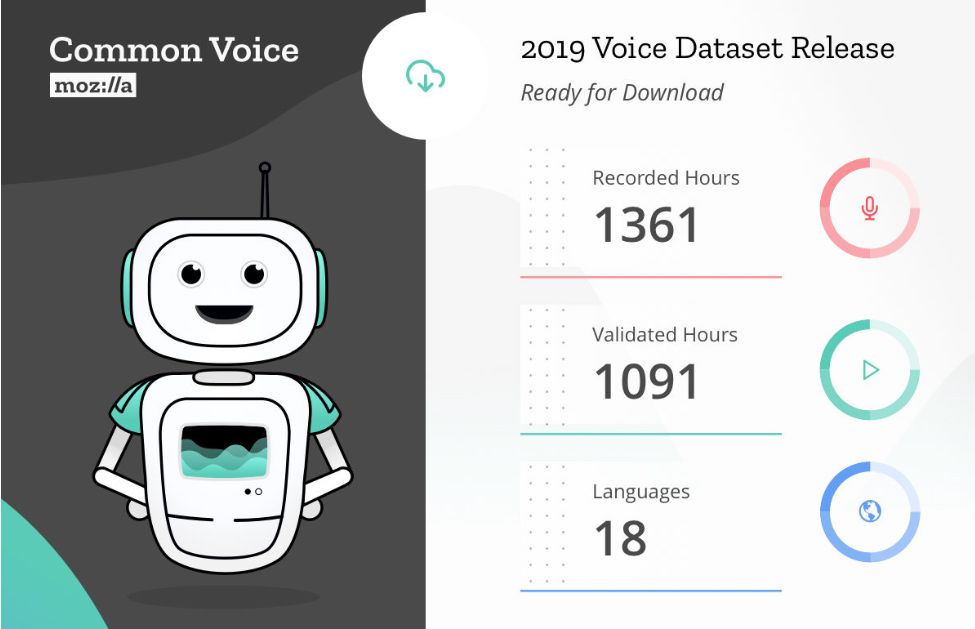
近日,Mozilla发布了当前可使用的,规模最大的公共语音数据集Common Voice,数据集涵盖18种语言,由42000多名贡献者提供的近1400小时的语音数据构成。
文 / George Roter
翻译 / 咪宝
原文
https://blog.mozilla.org/blog/2019/02/28/sharing-our-common-voices-mozilla-releases-the-largest-to-date-public-domain-transcribed-voice-dataset/
Mozilla发布了可供使用的最大人类语音数据集,包括18种不同的语言,累计记录了超过42,000多名贡献者的近1,400小时的语音数据。
从一开始,我们对Common Voice的愿景就是构建世界上最多样化的语音数据集,为构建语音技术进行优化。我们还做出了开放的承诺:向初创公司、研究人员以及对语音技术感兴趣的任何人公开我们收集到的高质量语音数据。
今天,我们很高兴与大家分享我们的第一个多语种数据集,其中包含18种语言。包括英语、法语、德语和普通话(繁体),以及威尔士语和卡比尔语。总的来说,新的数据集囊括了超过42000人的大约1400个小时的语音片段。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/正经夜光杯/article/detail/778803
推荐阅读
相关标签

