
- 1vue父子组件通信实现模糊搜索功能
- 2《动手学深度学习》学习笔记(十)自然语言处理_动手学深度学习从哪一节介绍自然语言处理
- 3第05课:服务注册与发现_第05课:服务注册与发现
- 4java token redis生成算法_java秒杀系列(1)- 秒杀方案总体思路
- 5利用cmd查看WIFI密码_找不到下列命令 wlan show profiles name
- 6python马尔可夫链_Python中的马尔可夫链(初学者)
- 7Spring AI 第二讲 之 Chat Model API 第十节MiniMax Chat_flux
stream = chat.stream(prompt); - 8【收藏】十款免费BT下载神器
- 9基于机器学习的多模态检索研究_多模态图像检索算法流程图解
- 10docker-compose部署 kafka 3.7 启用账号密码认证_docker kafka 开启认证 yml 文件
浅谈树形结构的特性和应用(上):多叉树,红黑树,堆,Trie树,B树,B+树......
赞
踩
点击上方“方志朋”,选择“设为星标”
回复”666“获取新整理的面试文章

上篇文章我们主要介绍了线性数据结构,本篇233酱带大家看看 无所不在的非线性数据结构之一:树形结构的特点和应用。
树形结构,是指:数据元素之间的关系像一颗树的数据结构。我们看图说话:
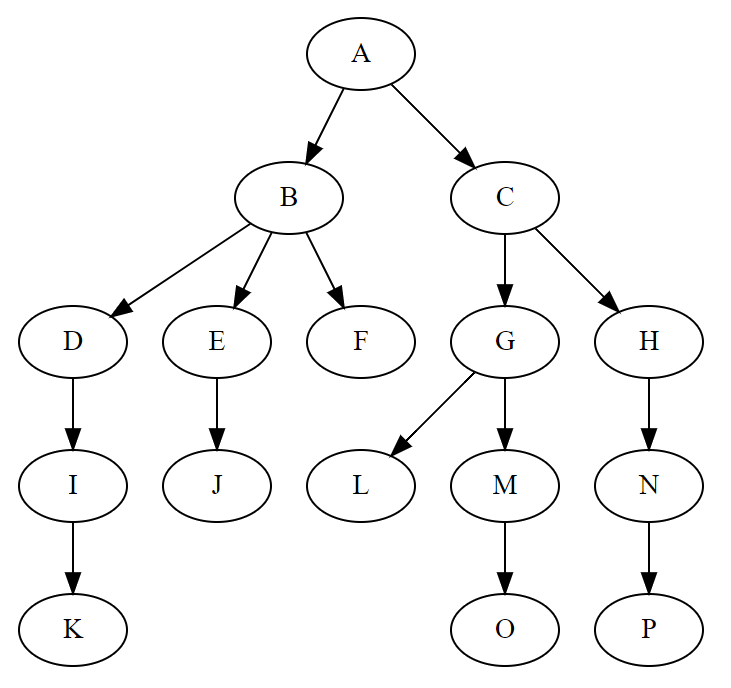
它具有以下特点:
每个节点都只有有限个子节点或无子节点;
没有父节点的节点称为根节点;
每一个非根节点有且只有一个父节点;
除了根节点外,每个子节点可以分为多个不相交的子树;
树里面没有环路(cycle)
维基百科中列举了计算机科学中树形结构的种类
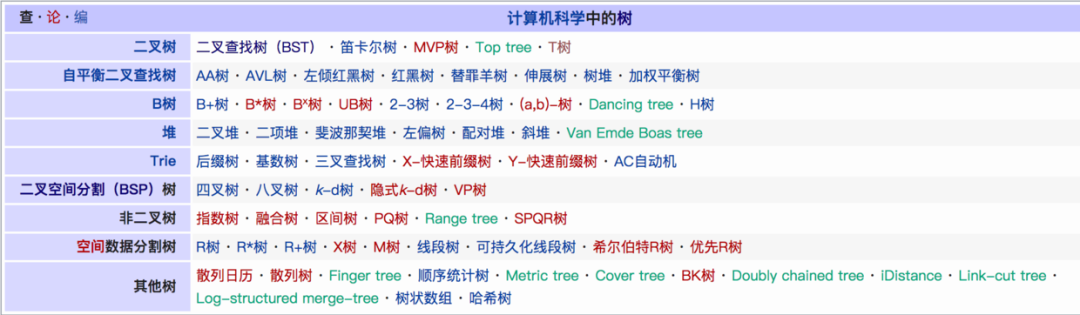
233酱当然不会一个个讲,我们只挑一些熟悉的面孔:多叉树,二叉树,二叉查找树,红黑树,堆,Trie树,B树,B+树,LSM Tree,了解他们在对不同规模的数据 增,删,改,查 时所起到的作用就够了。
限于篇幅,本文主要介绍非LSM Tree的内容。
多叉树
树体现了一种 继承 的关系,节点之间为父子关系。多叉树 是指一个父节点可以有多个子节点。也就是:爸爸可以有多个儿子,儿子只能有一个爸爸。
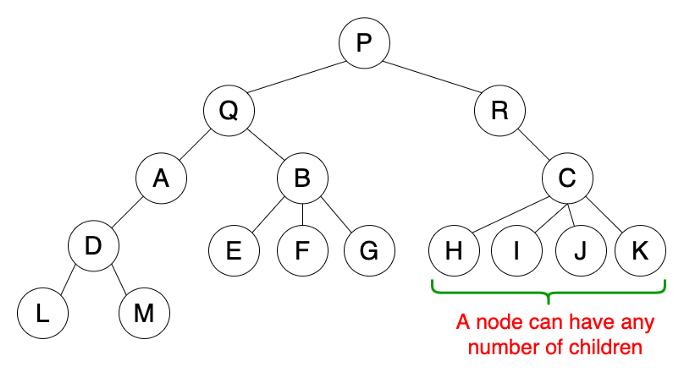
当需要这种分层,继承的场景下均可以考虑用树结构来实现,可以简化我们对数据关系的描述。
此外,节点的每个分支也代表着一种选择,可以用来做决策。
应用场景:
1.Linux文件系统
2.组织关系表示,如公司的组织架构,角色权限系统等。
3.XML/HTML数据。
4.类的继承关系
5.决策,如游戏中怪物使用的技能选择,机器学习…
二叉树
二叉树(Binary tree)是每个节点最多只有两个分支(即不存在分支度大于2的节点)的树结构,也就是说 爸爸 最多只能有 两个儿子。
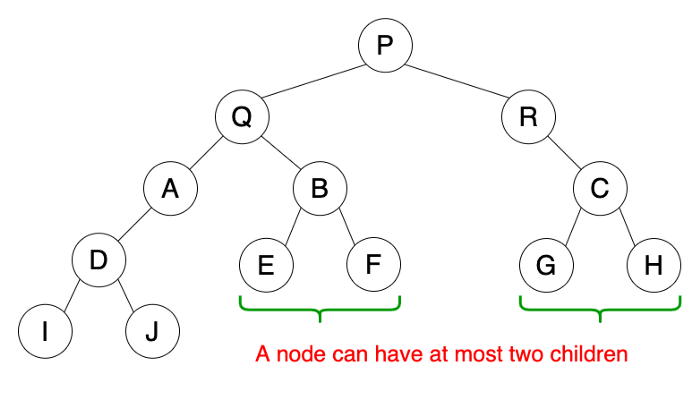
因为计算机应用中存在很多“非黑即白”的场景,同样我们可以利用 不是走左分支,就是走右分支 这种结构选择来做一些决策。
另外,利用每个节点下参与方最多为两个,也可以做一些事情。
应用场景:
1.编译器的语法树构造。
2.表达式求值和判断:非叶子节点为操作符,叶子节点为数值。
3.Boolean求值,如(a and b)or (c or d)。
4.霍夫曼编码
5.IPv4路由表的存储…
在我们的日常开发中,经常需要对数据进行增删改查,每一个步骤的时间空间效率决定了应用最终的性能。
时间效率 体现在 能否快速定位到要操作的数据元素,核心在于 索引的好坏;
空间效率 体现在 能否占用 更小的内存空间,能否利用计算机各层介质的缓存性能提高访问速度(访问速度:CPU>> 内存>>磁盘)。
在以下树形结构的讨论中,希望小伙伴能多从 索引,所占用内存空间,操作的介质 这些方面考虑数据的增删改查性能。
二叉查找树
二叉查找树(Binary Search Tree)首先是二叉树,同时满足一定的有序性:节点的左子节点比自己小,节点的右子节点比自己大。

这样当我们定位一个元素的位置时,从根节点开始查找,小于节点左拐,大于节点右拐。等于节点排序值就刚好找到。二分的索引思想就体现在其中。
应用场景:
二叉查找树的有序性是它能够广泛应用的原因。但是能否高效二分体现在树的高度合理性上。下面要讲的 红黑树/堆结构才是其广泛应用。
红黑树
二叉查找树的缺点在于:只限制了节点的有序性,但有序树的构造有好坏。一颗“坏”的有序树直接会被拉成 “有序链表”。所以需要通过一定的条件保证树的平衡性。
树的平衡性是指整棵树的最高子树和最矮子树相差不大,这样整棵树的高度相对来说低一些,相应的增,删,改,查操作的效率较高较稳定(与树高有关)。
红黑树(Red–black tree)是应用很广泛的一种平衡树,是面试官的装X利器。我们来看一下它保证平衡性的一些特性:
节点是红色或黑色。
根是黑色。
所有叶子都是黑色(叶子是NIL节点)。
每个红色节点必须有两个黑色的子节点。(从每个叶子到根的所有路径上不能有两个连续的红色节点。)
从任一节点到其每个叶子的所有简单路径都包含相同数目的黑色节点。
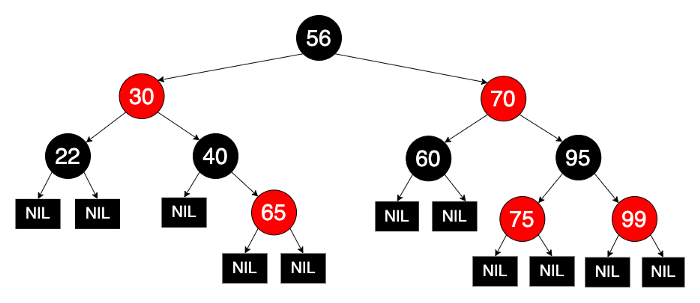
这些约束确保了红黑树的关键特性:从根到叶子的最长路径不多于最短路径的两倍长(根据性质4和性质5)。从而整棵树的高度比较稳定,相应的增、删、改、查操作的效率较高较稳定,而不同于普通的二叉查找树。
此外相比其他的平衡树:如高度平衡树AVL树,红黑树的增删改效率较高,同时查找性能没有下降很多也比较稳定。所以工业级应用更为广泛。
应用场景:适合排序,查找的场景。
1.容器的基本组成,如Java中的HashMap/TreeMap.
2.Linux内核的完全公平调度器
3.Linux中epoll机制的实现…
堆
堆是一种特殊的数据结构,它满足两个特性:
堆是一个完全二叉树;
堆中每一个节点的排序值都必须大于等于(或小于等于)其左右子节点的排序值。
这里解释一下完全二叉树。它是指:除了最后一层,其他层的节点个数都是满的,最后一层的节点都靠左排列。
这样我们就可以用数组来存储。
假设根节点在i=0的位置:如果父节点的数组下标为i,则左子节点的数组下标为2 * i+1,右子节点的数组下标为 2 * i + 2。数组比链表的存储好处上篇文章233酱提过了,这里就不赘述了。
针对第2点,如果每个节点的值都大于等于子树中每个节点值的堆,叫做“大顶堆”。反之叫做“小顶堆”。
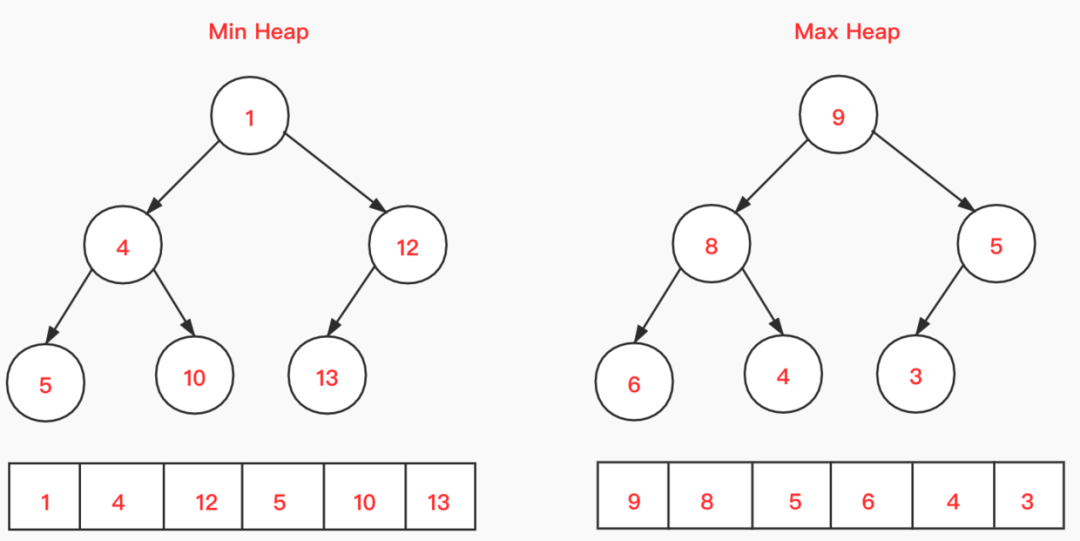
堆这种结构相对有序,且堆顶元素要么最小,要么最大。且利用了 数组和自身特性 增删改查的时间复杂度较低。
应用场景:
1.堆排序
2.TopK,求中位数,求
3.合并多个有序小文件或集合
4.优先队列,如定时任务的存储等…
Trie树
Trie树 又称前缀树或字典树,它是一种专门处理字符串匹配的数据结构,用来解决在一组字符串集合中快速查找某个字符串的问题。
它的特性为:
根节点不包含字符,除根节点外的每一个子节点都包含一个字符。
从根节点到某一节点,路径上经过的字符连接起来,就是该节点对应的字符串。
每个字符串的公共前缀作为一个字符节点保存。
如果我们有and,as,at,cn,com这些关键词,那么构建的trie树如下:
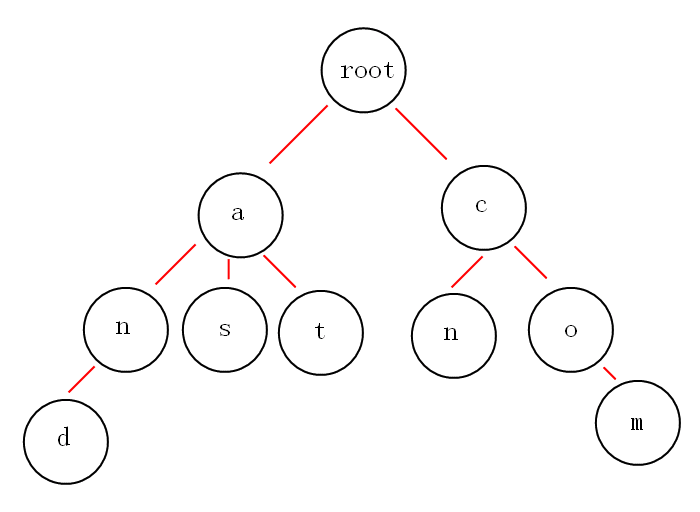
Trie 树的本质,就是利用字符串之间的公共前缀,将重复的前缀合并在一起。这样当我们查找某个字符串时,只需要在Trie树上匹配字符串的每个字符,比较次数仅和 字符串的长度 有关。
但是Trie 树的缺点就是构造Trie树需要很大的内存空间。因为父子字符节点之间用 指针关联。如果用数组保存这些指针,这意味着子节点的数组需要穷举出每一种可能。如子节点字符为a-z,就需要分配长度为26的数组来存储这些可能的子节点。
改进内存分配的措施有:
1.子节点指针改为用:有序数组、跳表、散列表、红黑树来存储。
2.子节点合并,如原来 hello存储为:h->e->l->l->o ,现在可存储为:h->e->llo
Trie 树毕竟比较浪费空间,所以它在字符串的查找中,适合用于:1.字符集不能太大 2.字符串的公共前缀较多 的场景。
应用场景:
1.关键词匹配,提示,纠错。
2.最长公共前缀匹配。
3.命令自动补全,如zsh.
4.网址浏览历史记录。
5.手机号码簿查询…
B树、B+树 是数据库中经常出现的数据结构。对于数据库的增删改查效率,需要考虑的首要因素是:磁盘的IO访问次数。
如何减少IO访问次数?
前文我们已经提到了索引,但是IO一次不容易,从磁盘中获取数据通常是以块为单位的。如果对于上千万条数据,我们只建立一层索引结构的话,那索引的数据量也是巨大的。
如何降低索引量?
假设我们到全世界找一个人,我们是按照 国家/省/市/区/街道/小区的顺序来定位。同理,随着数据量的增大,我们需要一层层的建立 多级索引 。越上层的索引每个块中表示的数据范围越大。
如何保证我们建立的多级索引 是“合适”的?
这个合适主要指:存储的数据量大并且树高小。同红黑树一样,我们需要一些 限制条件 来保证树高。这也就是以下数据结构的限制条件原因了。
B树
一个m阶(该树每个节点最多有 M 个子节点)的B树具有以下特征:
1.根节点至少有两个子女。
2.每个中间节点都包含k-1个元素和k个孩子,其中 m/2 <= k <= m
3.每一个叶子节点都包含k-1个元素,其中 m/2 <= k <= m
4.所有的叶子节点都位于同一层。
5.每个节点中的元素从小到大排列,节点当中k-1个元素正好是k个子节点包含的元素的值域分划。
一个3阶的B树插入示意图如下:
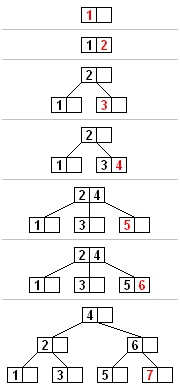
应用场景:MongoDB
B+树
一个m阶的B+树具有以下特征:
1.有k个子树的中间节点包含有k个元素(B树中是k-1个元素),每个元素不保存数据,只用来索引,所有数据都保存在叶子节点。
2.所有的叶子节点中包含了全部元素的信息,及指向含这些元素记录的指针,且叶子节点本身依关键字的大小自小而大顺序链接。
3.所有的中间节点元素都同时存在于子节点,在子节点元素中是最大(或最小)元素。
看不懂没关系,我们只需要知道这些限制条件是为了让B+树数据“矮而胖”就好。
这里我直接放张掘金小册《从根儿上理解MYSQL》B+树主键索引的示意图:
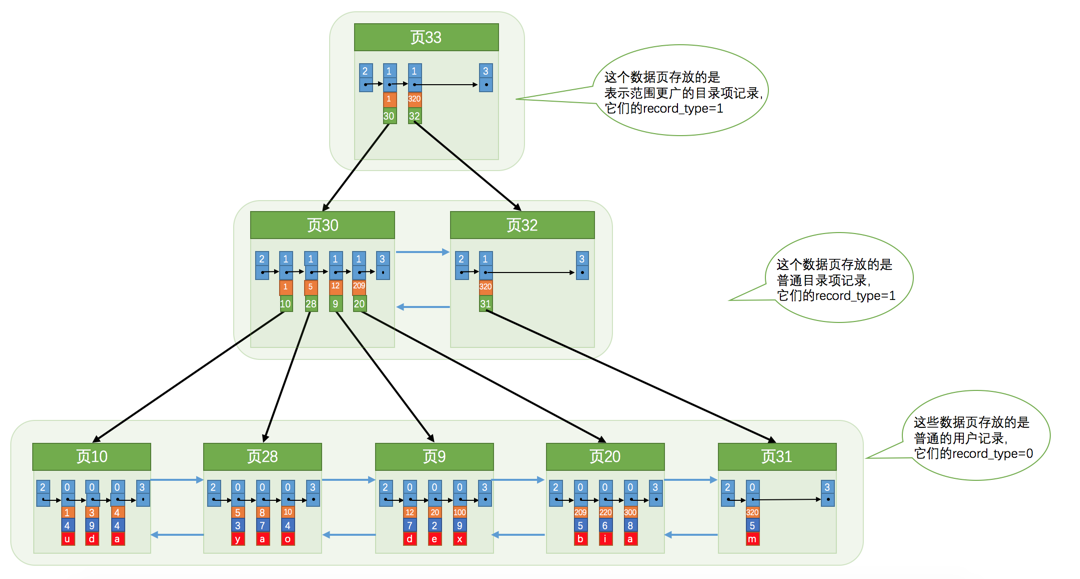
应用场景
1.Mysql InnoDB存储引擎。
看到这里常考面试题来了:B树和B+树有什么区别?为什么Mongo用B树?为什么Mysql用B+树?
B树 vs B+树
看图说话,B树 和 B+树显著不同的地方是:
1.B树非叶子节点即是索引,也是数据;B+树非叶子节点仅是索引,数据全部存储在叶子节点。
2.B+树叶子节点的数据之间是用链表链接的。
这会导致:
B+树相比B树:
1.数据的连续性:B+树叶子节点上一页存储的数据是连续的,当需要一个节点上的数据时,B+树可以增大缓存的命中率。
2.叶子节点之间的连接性:当作范围或全文扫描时,B+树可以依赖叶子节点做线性顺序扫描,而B树只能在每一层的节点上做扫描。B+树同样可以增大缓存的命中率。
B树相比B+树:
当作单一数据查询时,B树的节点平均离根节点更近,平均查询效率比B+树快。
总结一下:B+树相比B树,前者更适合范围查询,后者更适合单一数据查询。
Mongo是非关系型数据库,数据之间的关系用嵌套解决。它的主要使用场景是:追求 单个读写记录的性能。
Mysql是关系型数据库,数据之间的关系用共同的索引键,Join解决。它的使用场景:不仅存在大量的单一数据查询,也存在大量的范围查询。
所以上面的问题可以简单扯一扯了吧。
下篇文章233酱准备介绍近几年数据库中经常出现的角色:LSM Tree。觉得本文有收获 or 期待下篇 请四连【关注,点赞,在看,转发】支持下233吧~
参考资料:
[1].维基百科
[2].https://www.youtube.com/watch?v=OJ5NYq1Eii8
[3].https://time.geekbang.org/column/article/72414
[4].https://towardsdatascience.com/8-useful-tree-data-structures-worth-knowing-8532c7231e8c
[5].https://draveness.me/whys-the-design-mongodb-b-tree/
- 热门内容:面试官扎心一问:数据量很大,分页查询很慢,有什么优化方案?你说,一个Java字符串到底有多少个字符?
- 在Java项目中打印错误日志的正确姿势,排查问题更方便,非常实用!一款vue编写的功能强大的swagger-ui,有点秀(附开源地址)BeanUtils 是用 Spring 的还是 Apache 的好?因用了Insert into select语句,美女同事被开除了!
-
-
- 最近面试BAT,整理一份面试资料《Java面试BAT通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。获取方式:点“在看”,关注公众号并回复 666 领取,更多内容陆续奉上。
- 明天见(。・ω・。)ノ♡

