
- 1windos 2008 R2安装mysql 8.0具体方法_windows server 2008 r2mysql
- 2数据库系统概论 ---知识点大全(期末复习版)
- 3基于MediaPipe的人体摔倒检测_mediapipe检测目标步骤图
- 4RAG笔记:常见问题以及解决方法_rag问题
- 5oracle自增字段--序列值获取、修改、设置当前值问题_oracle设置自增序列初始值
- 6探索未来计算的钥匙:Ray教育材料项目深度解读
- 72024Guitar Pro 8.1 Mac 最新下载、安装、激活、换机图文教程_guitar pro for mac
- 8JMeter 参数化策略_jmeter参数化取值策略
- 9OCR识别常见开源库_ocr识别开源库
- 10【你也能从零基础学会网站开发】(了解)关系型数据库的基本架构体系结构与概念理解
大数据Hadoop之——数据同步工具Sqoop_sqoop mysql hive提高同步速度
赞
踩
一、概述
Apache Sqoop(SQL-to-Hadoop)项目旨在协助RDBMS(Relational Database Management System:关系型数据库管理系统)与Hadoop之间进行高效的大数据交流。用户可以在 Sqoop 的帮助下,轻松地把关系型数据库的数据导入到 Hadoop 与其相关的系统 (如HBase和Hive)中;同时也可以把数据从 Hadoop 系统里抽取并导出到关系型数据库里。
Sqoop是一个在结构化数据和Hadoop之间进行批量数据迁移的工具,结构化数据可以是MySQL、Oracle等RDBMS。Sqoop底层用MapReduce程序实现抽取、转换、加载,MapReduce天生的特性保证了并行化和高容错率,而且相比Kettle等传统ETL工具,任务跑在Hadoop集群上,减少了ETL服务器资源的使用情况。在特定场景下,抽取过程会有很大的性能提升。
官网:https://sqoop.apache.org/
官方文档:https://sqoop.apache.org/docs/1.99.7/index.html
GitHub:https://github.com/apache/sqoop
二、架构
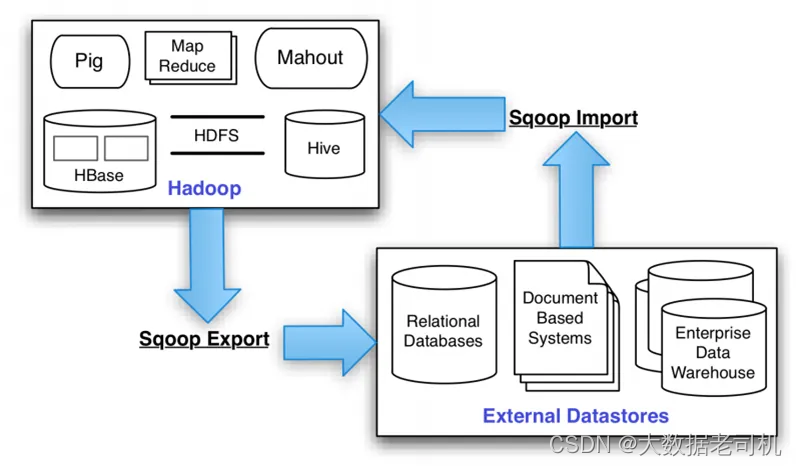
sqoop的底层实现是mapreduce,所以sqoop依赖于hadoop,sqoop将导入或导出命令翻译成MapReduce程序来实现,在翻译出的MapReduce 中主要是对InputFormat和OutputFormat进行定制。
1)数据导入(RDBMS->Haoop)
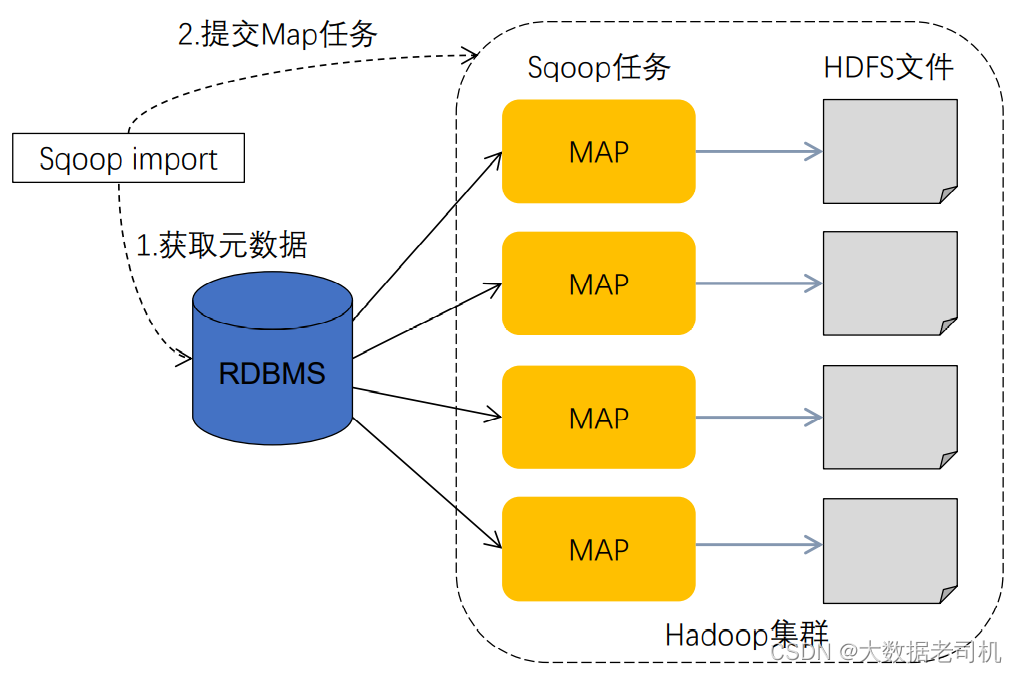
- sqoop会通过jdbc来获取需要的数据库的元数据信息,例如:导入的表的列名,数据类型。
- 这些数据库的数据类型会被映射成为java的数据类型,根据这些信息,sqoop会生成一个与表名相同的类用来完成序列化工作,保存表中的每一行记录。
- sqoop开启MapReduce作业
- 启动的作业在input的过程中,会通过jdbc读取数据表中的内容,这时,会使用sqoop生成的类进行序列化。
- 最后将这些记录写到hdfs上,在写入hdfs的过程中,同样会使用sqoop生成的类进行反序列化。
2)数据导出(Haoop->RDBMS)
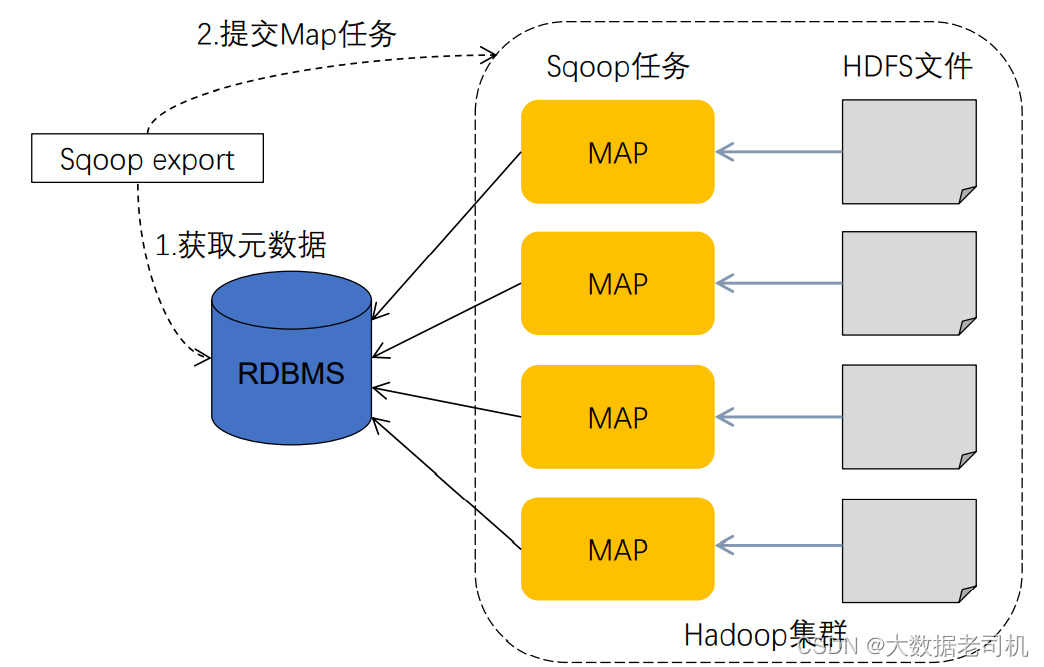
- 首先sqoop通过jdbc访问关系型数据库获取需要导出的信息的元数据信息
- 根据获取的元数据信息,sqoop生成一个Java类,用来承载数据的传输,该类必须实现序列化
- 启动MapReduce程序
- sqoop利用生成的这个类,并行从hdfs中获取数据
- 每个map作业都会根据读取到的导出表的元数据信息和读取到的数据,生成一批insert 语句,然后多个map作业会并行的向MySQL中插入数据。
三、安装
因为Sqoop依赖于hadoop服务,可以参考我之前的文章:大数据Hadoop原理介绍+安装+实战操作(HDFS+YARN+MapReduce)
Sqoop 作为一个二进制包发布,包含两个独立的部分——客户端和服务端。
- 服务端——您需要在集群中的单个节点上安装服务端。该节点将作为所有 Sqoop 客户端的入口点。
- 客户端——客户端可以安装在任意数量的机器上。
将 Sqoop 安装包复制到要运行 Sqoop 服务端的机器上。Sqoop 服务器充当 Hadoop 客户端,因此 Hadoop 库(Yarn、Mapreduce 和 HDFS jar 文件)和配置文件(core-site.xml、mapreduce-site.xml,…)必须在此节点上可用。
1)下载
下载地址:http://archive.apache.org/dist/sqoop/
$ cd /opt/bigdata/hadoop/software/
$ wget http://archive.apache.org/dist/sqoop/1.99.7/sqoop-1.99.7-bin-hadoop200.tar.gz
$ tar -xf sqoop-1.99.7-bin-hadoop200.tar.gz -C /opt/bigdata/hadoop/server/
- 1
- 2
- 3
2)配置环境变量
# 创建第三方 jar包存放路径
$ mkdir $SQOOP_HOME/lib
# 配置环境变量/etc/profile
export SQOOP_HOME=/opt/bigdata/hadoop/server/sqoop-1.99.7-bin-hadoop200
export PATH=$SQOOP_HOME/bin:$PATH
export SQOOP_SERVER_EXTRA_LIB=$SQOOP_HOME/lib
# 如果已经配置好了$HADOOP_HOME,就可以不用配置下面的环境变量了,sqoop会自动去找
# sqoop hadoop环境配置
export HADOOP_COMMON_HOME=$HADOOP_HOME/share/hadoop/common
export HADOOP_HDFS_HOME=$HADOOP_HOME/share/hadoop/hdfs
export HADOOP_MAPRED_HOME=$HADOOP_HOME/share/hadoop/mapreduce
export HADOOP_YARN_HOME=$HADOOP_HOME/share/hadoop/yarn
$ source /etc/profile
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
3)配置sqoop代理用户
先配置hadoop sqoop的代理用户
$ vi $HADOOP_HOME/etc/hadoop/core-site.xml
<property>
<name>hadoop.proxyuser.sqoop2.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.sqoop2.groups</name>
<value>*</value>
</property>
# 重新加载配置
$ hdfs dfsadmin -refreshSuperUserGroupsConfiguration
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
如果您在所谓的系统用户下运行 Sqoop 2 服务器(用户 ID 小于min.user.id - 默认情况下为 1000),则默认情况下 YARN 将拒绝运行 Sqoop 2 作业。您需要将运行 Sqoop 2 服务器的用户名(很可能是用户sqoop2)添加到container-executor.cfg的allowed.system.users属性中。
当服务器在sqoop2用户下运行时,需要存在于container-executor.cfg文件中的示例片段:
# 创建sqoop2用户
$ useradd sqoop2
# 添加配置
$ vi $HADOOP_HOME/etc/hadoop/container-executor.cfg
allowed.system.users=sqoop2
- 1
- 2
- 3
- 4
- 5
4)安装JDBC
mysql驱动下载地址:https://repo1.maven.org/maven2/mysql/mysql-connector-java/,根据自己的mysql版本下载对应的驱动
$ cd $SQOOP_HOME/lib
$ wget https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.26/mysql-connector-java-8.0.26.jar
$ wget https://jdbc.postgresql.org/download/postgresql-42.3.4.jar
- 1
- 2
- 3
5)修改conf/sqoop.properties
org.apache.sqoop.submission.engine.mapreduce.configuration.directory=/opt/bigdata/hadoop/server/hadoop-3.3.1/etc/hadoop/
- 1
6)存储库初始化
首次启动 Sqoop 2 服务器之前,需要初始化元数据存储库。使用升级工具初始化存储库:
$ sqoop2-tool upgrade
- 1
【问题】derby的jar包版本过低报错
Caused by: java.lang.SecurityException: sealing violation: package org.apache.derby.impl.jdbc.authentication is sealed
【解决】
# 删掉sqoop2自带的derby jar包
$ rm -f $SQOOP_HOME/server/lib/derby-*.jar
# 把hive的lib的jar copy到sqoop2 server lib目录下
$ cp $HIVE_HOME/lib/derby-*.jar /$SQOOP_HOME/server/lib/
- 1
- 2
- 3
- 4
再初始化并验证
$ sqoop2-tool upgrade
#验证
$ sqoop2-tool verify
- 1
- 2
- 3
在当前目录下会生产db目录和log目录
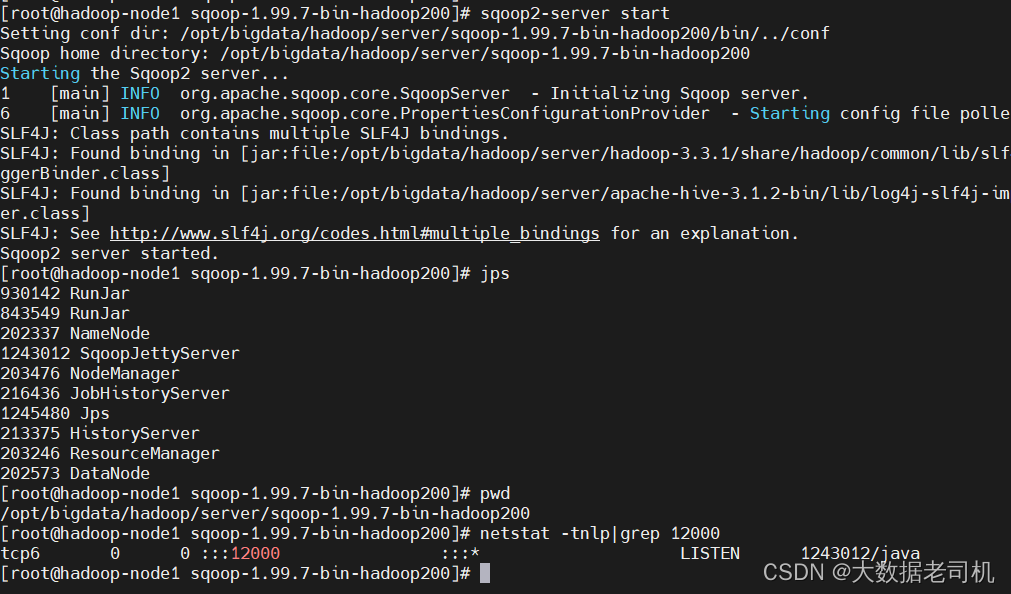
7)启动sqoop服务端
$ sqoop2-server start
# 执行sqoop2-server stop会停止sqoop
# 查看进程
$ jps
# 查看端口,默认是12000,可以修改conf/sqoop.properties的org.apache.sqoop.jetty.port字段来修改端口
$ netstat -tnlp|grep 12000
- 1
- 2
- 3
- 4
- 5
- 6
8)启动sqoop客户端
由于我现在是伪分布式,所以sqoop server和sqoop client都在一台机器上,直接执行sqoop2-shell命令即可启动sqoop客户端
$ sqoop2-shell
- 1
发现启动客户端报错了
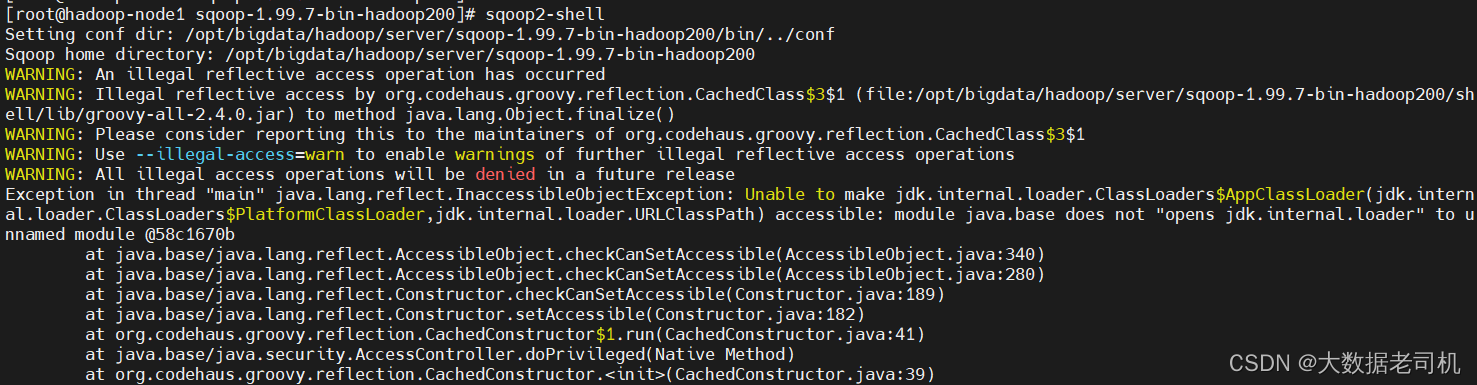
【原因&解决】是因为jdk版本不匹配,重新下载jdk安装
jdk下载地址:https://www.oracle.com/java/technologies/downloads/
$ cd /opt/bigdata/hadoop/software/
$ wget https://download.oracle.com/otn-pub/java/jdk/8u331-b09/165374ff4ea84ef0bbd821706e29b123/jdk-8u331-linux-x64.tar.gz
$ tar -xf jdk-8u331-linux-x64.tar.gz -C /opt/bigdata/hadoop/server/
# 在/etc/profile配置环境变量
export JAVA_HOME=/opt/bigdata/hadoop/server/jdk1.8.0_331
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
# 重新加载
$ source /etc/profile
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
重新启动sqoop客户端
$ sqoop2-shell
# 查看版本
show version --all
# 查看帮助
help
- 1
- 2
- 3
- 4
- 5

9)设置客户端的各种属性
Set 命令允许设置客户端的各种属性。与辅助命令类似,set 不需要连接到 Sqoop 服务器。设置命令不用于重新配置 Sqoop 服务器。
# 将sqoop包copy到其它机器,当作客户端
$ scp -r /opt/bigdata/hadoop/server/sqoop-1.99.7-bin-hadoop200 hadoop-node2:/opt/bigdata/hadoop/server/
# 配置环境变量/etc/profile
export SQOOP_HOME=/opt/bigdata/hadoop/server/sqoop-1.99.7-bin-hadoop200
export PATH=$SQOOP_HOME/bin:$PATH
$ source /etc/profile
$ sqoop2-shell
# 设置端口,host,默认端口12000
set server --host hadoop-node1 --port 12000 --webapp sqoop
# 或者如下:
set server --url http://hadoop-node1:12000/sqoop
# 查看设置
show server --all
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
【温馨提示】注意:当给出–url选项时,–host、–port或–webapp选项将被忽略。
| 参数 | 默认值 | 描述 |
|---|---|---|
| -h, --host | localhost | 运行 Sqoop 服务器的服务器名称 (FQDN) |
| -p, --port | 12000 | 端口 |
| -w, --webapp | sqoop | Jetty 的 Web 应用程序名称 |
| -u, --url | url 格式的 Sqoop 服务器 |
四、简单使用
1)常用命令
$ sqoop2-shell
# 查看帮助
help
# 配置服务
set server --url http://hadoop-node1:12000/sqoop
show server --all
# 显示持久的作业提交对象
show submission
show submission --j jobName
show submission --job jobName --detail
# 显示所有链接
show link
# 显示连接器
show connector
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
2)数据从MYSQL导入到HDFS(Import)
1、 创建JDBC连接
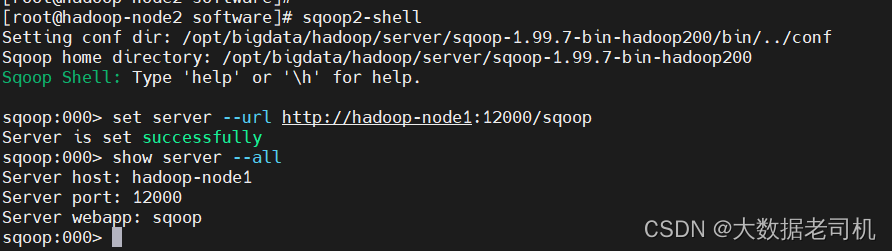
$ sqoop2-shell
sqoop:000> set server --url http://hadoop-node1:12000/sqoop
# 先查看connector
sqoop:000> show connector
# 创建mysql连接
sqoop:000> create link -connector generic-jdbc-connector
Creating link for connector with name generic-jdbc-connector
Please fill following values to create new link object
Name: mysql-jdbc-link
Database connection
Driver class: com.mysql.cj.jdbc.Driver
Connection String: jdbc:mysql://hadoop-node1:3306/azkaban?characterEncoding=utf8&useSSL=false&serverTimezone=UTC&rewriteBatchedStatements=true
Username: root
Password: ******
Fetch Size:
Connection Properties:
There are currently 0 values in the map:
entry#
SQL Dialect
Identifier enclose:
New link was successfully created with validation status OK and name mysql-jdbc-link
sqoop:000>
sqoop:000> show link
# 删除
sqoop:000> delete link --name mysql-jdbc-link
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
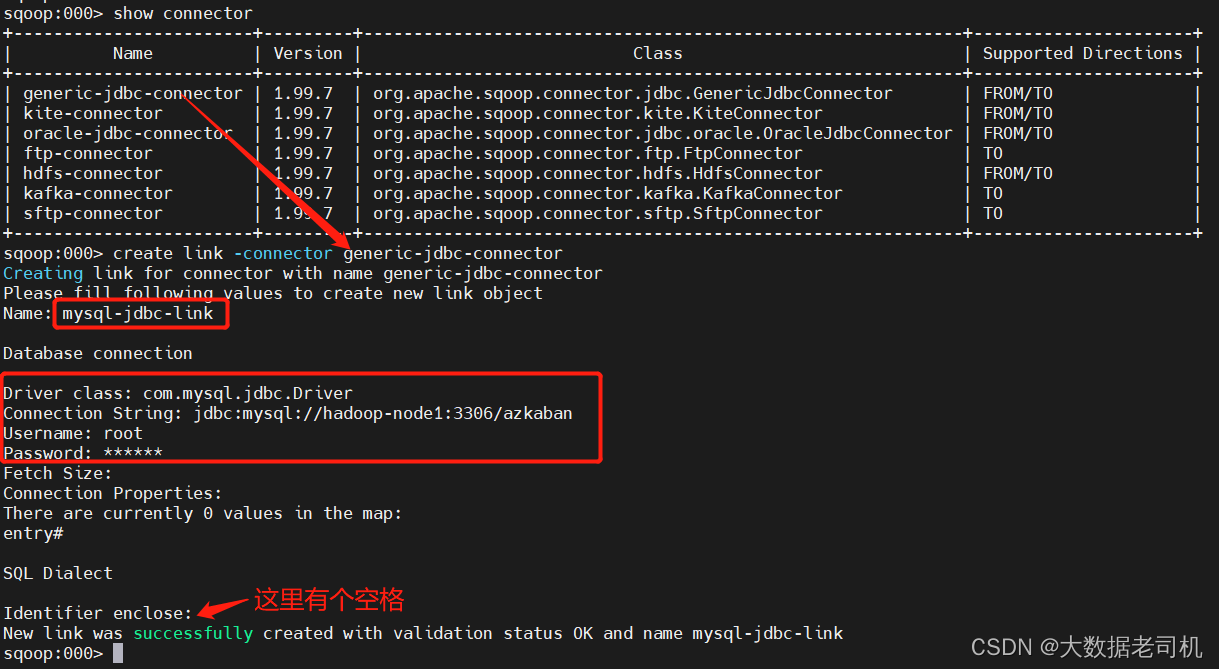
2、创建HDFS连接
sqoop:000> create link -connector hdfs-connector
Creating link for connector with name hdfs-connector
Please fill following values to create new link object
Name: hdfs-link
HDFS cluster
URI: hdfs://hadoop-node1:8082
Conf directory: /opt/bigdata/hadoop/server/hadoop-3.3.1/etc/hadoop/
Additional configs::
There are currently 0 values in the map:
entry#
New link was successfully created with validation status OK and name hdfs-link
sqoop:000> show link
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
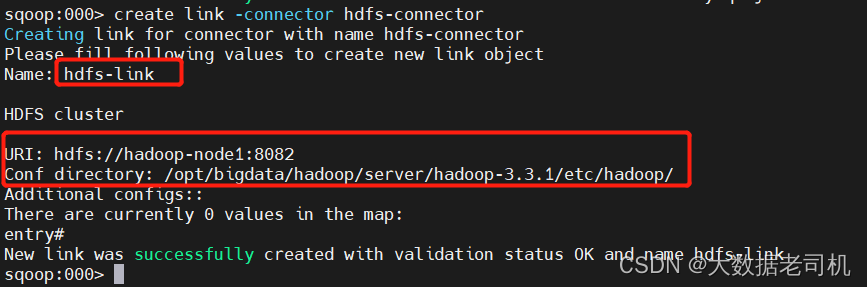
3、创建Job任务
首先先创建HDFS存储目录
$ hadoop fs -mkdir -p /user/sqoop2/output/
$ hadoop fs -chown -R sqoop2:sqoop2 /user/sqoop2/output/
- 1
- 2
再执行数据转换
$ sqoop2-shell
sqoop:000> set server --url http://hadoop-node1:12000/sqoop
sqoop:000> show link
sqoop:000> create job -f "mysql-jdbc-link" -t "hdfs-link"
Name: mysql2hdfs
sqoop:000> show job
- 1
- 2
- 3
- 4
- 5
- 6
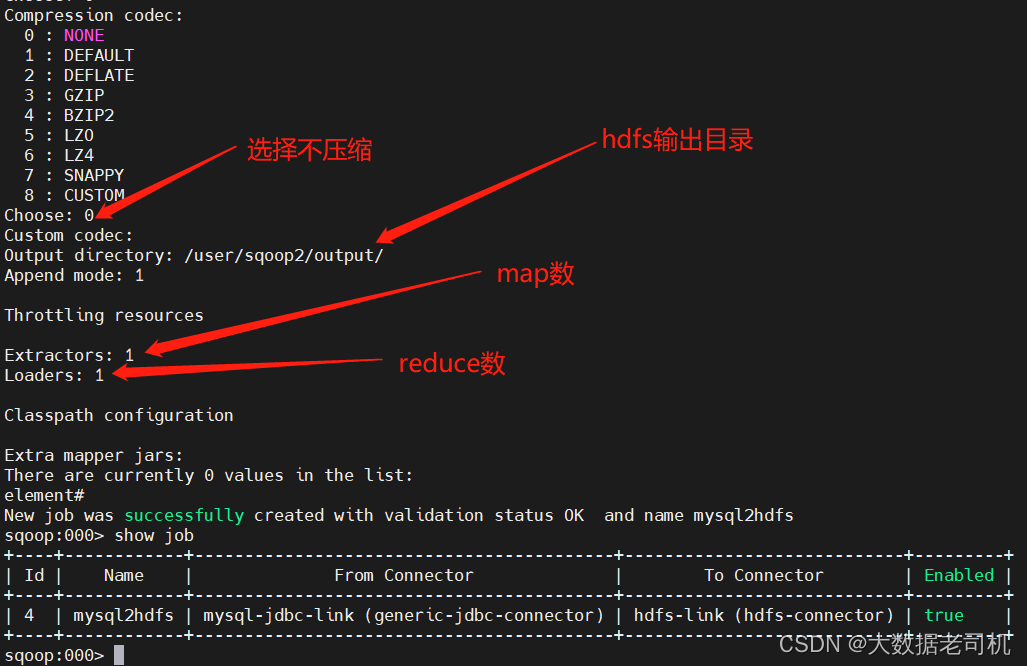
4、执行Job
sqoop:000> show job
sqoop:000> start job -n mysql2hdfs
- 1
- 2
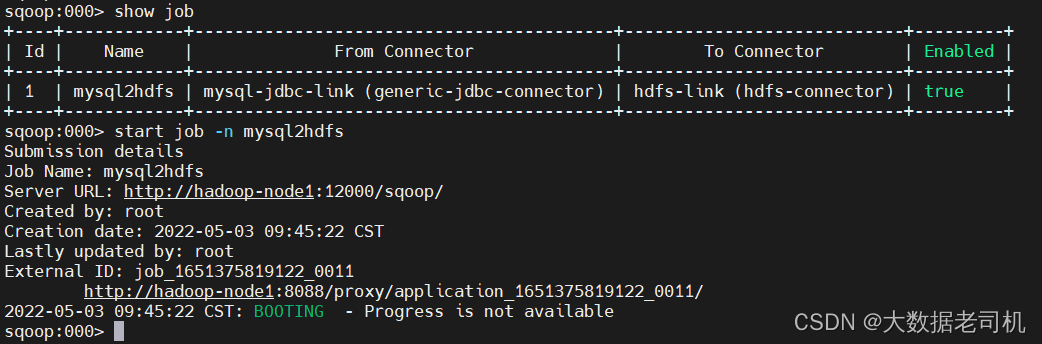
在yarn平台上查看
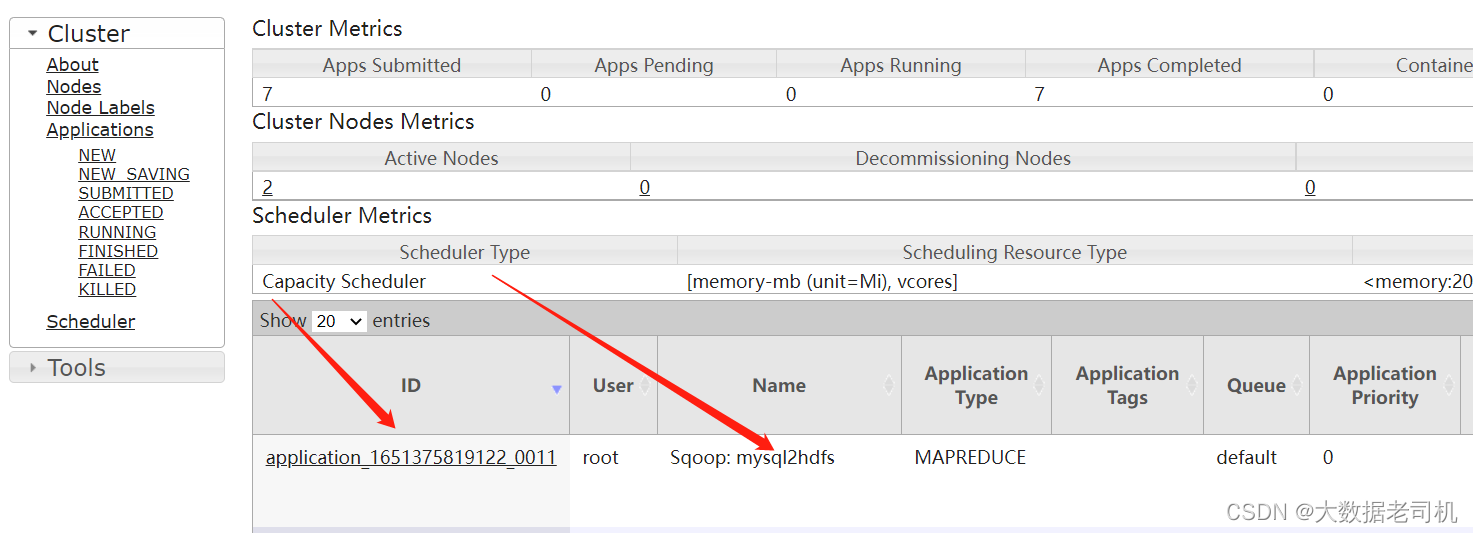
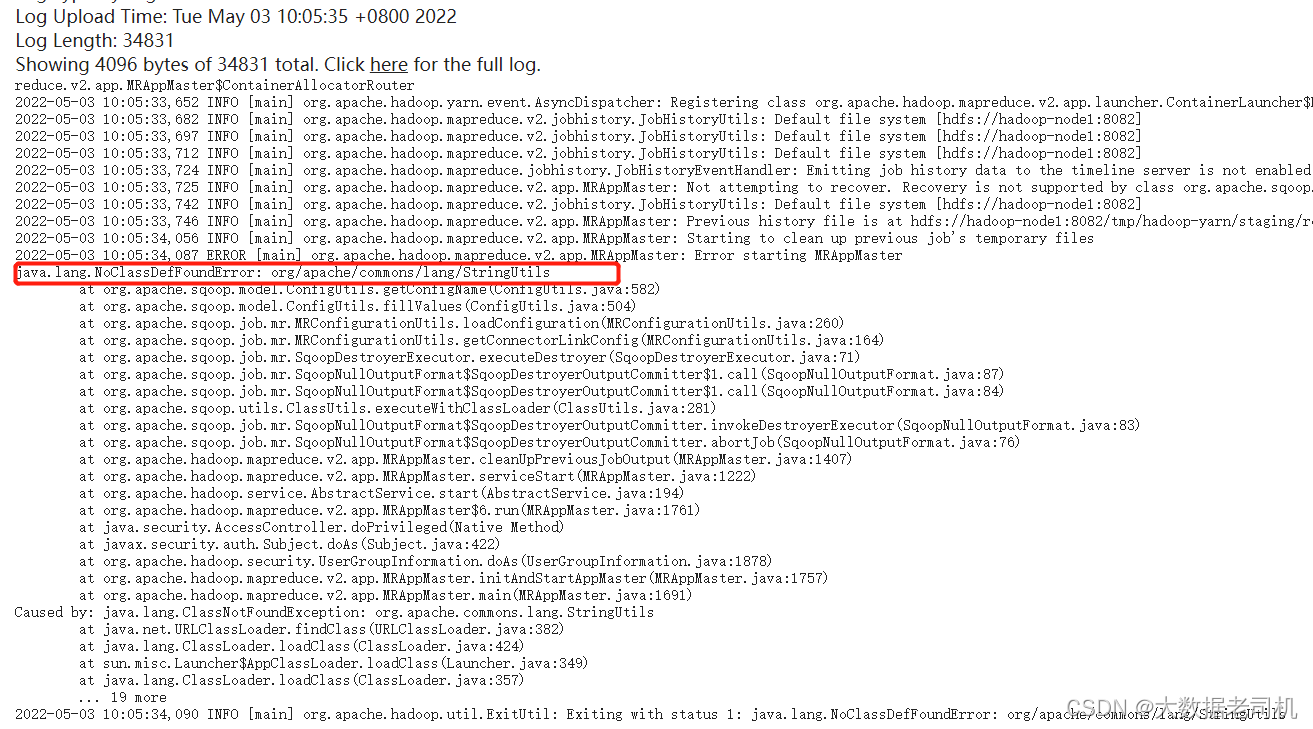
查看执行状态是失败的,查看有错误日志,主要日志如下:
【问题一】
java.lang.NoClassDefFoundError: org/apache/commons/lang/StringUtils
【解决】
下载地址:https://commons.apache.org/proper/commons-lang/download_lang.cgi
$ cd $SQOOP_HOME/lib/
$ wget https://mirrors.tuna.tsinghua.edu.cn/apache//commons/lang/binaries/commons-lang-2.6-bin.tar.gz
$ tar -xf commons-lang-2.6-bin.tar.gz
# 将jar包放在mapreduce lib目录,所有节点都得放,因为调度到哪台机器是随机的
$ cp commons-lang-2.6/commons-lang-2.6.jar $HADOOP_HOME/share/hadoop/mapreduce/
# 网上说放在sqoop lib目录下,应该也是可以的,但是也是所有节点需要放
# $ cp commons-lang-2.6/commons-lang-2.6.jar .
$ rm -fr commons-lang-2.6-bin.tar.gz commons-lang-2.6
# 重启sqoop server
$ cd $SQOOP_HOME
$ sqoop2-server stop;sqoop2-server start
# 设置执行用户
$ export HADOOP_USER_NAME=sqoop2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
【问题二】hdfs账号不允许假扮root用户
Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: hdfs is not allowed to impersonate root
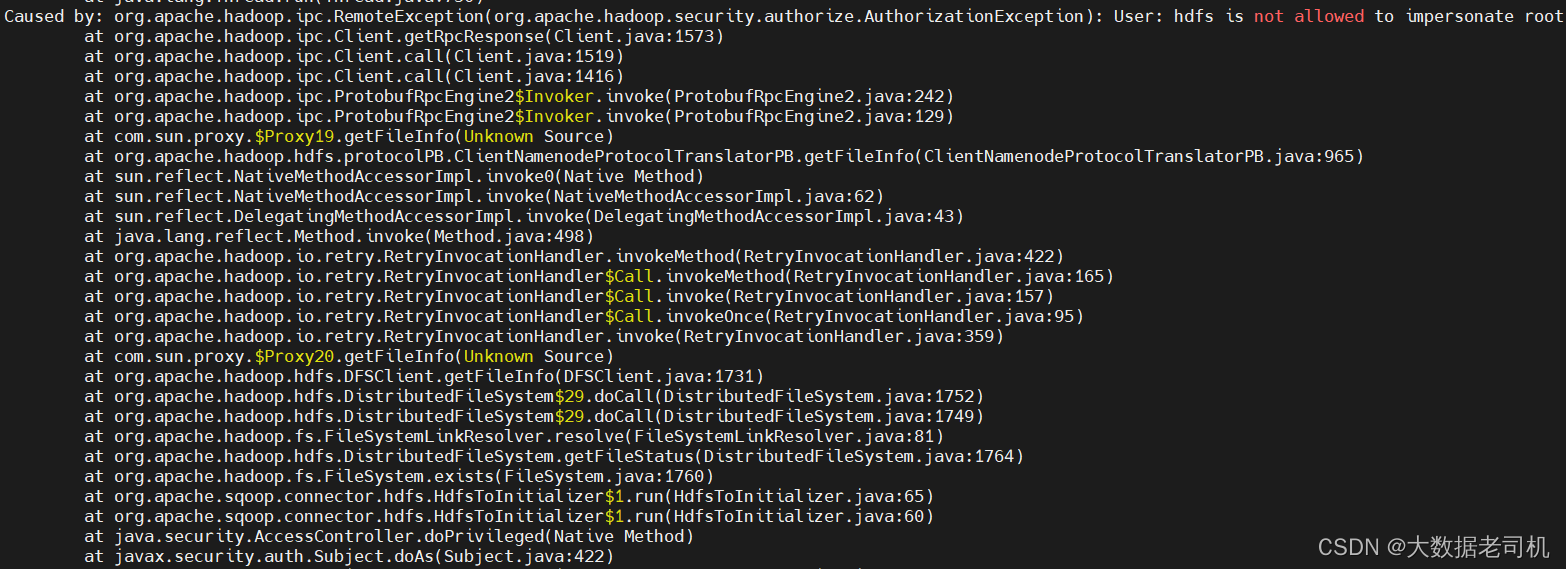
【解决】在core-sit-xml配置hdfs代理用户
<property>
<name>hadoop.proxyuser.hdfs.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hdfs.groups</name>
<value>*</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
重新加载配置生效
$ hdfs dfsadmin -refreshSuperUserGroupsConfiguration
- 1
再执行job
start job -n mysql2hdfs
# 查看状态
status job -n mysql2hdfs
# 停止job
#stop job -n mysql2hdfs
- 1
- 2
- 3
- 4
- 5
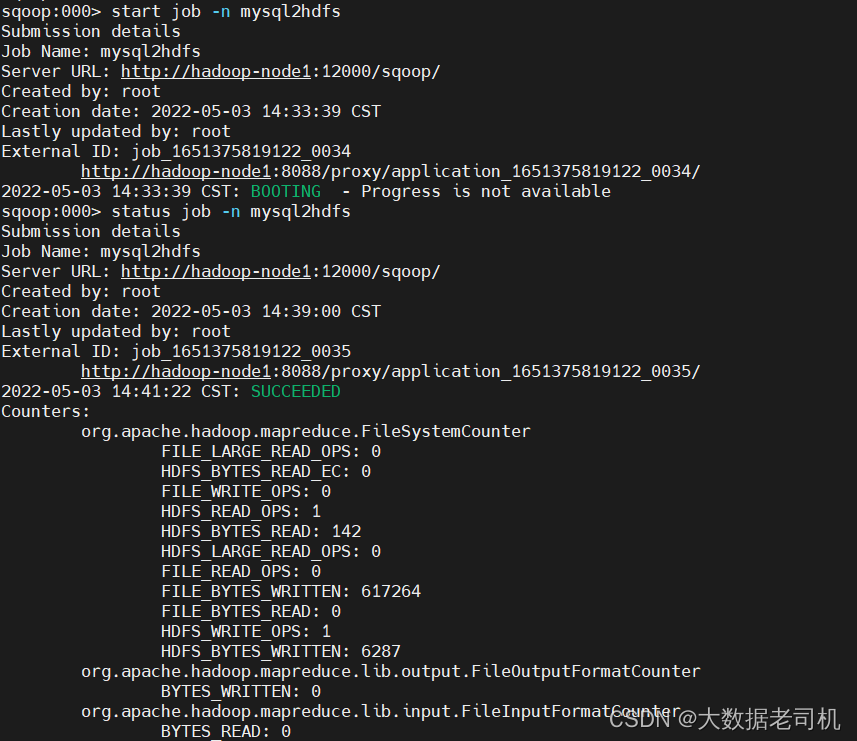
去Yarn上查看执行情况
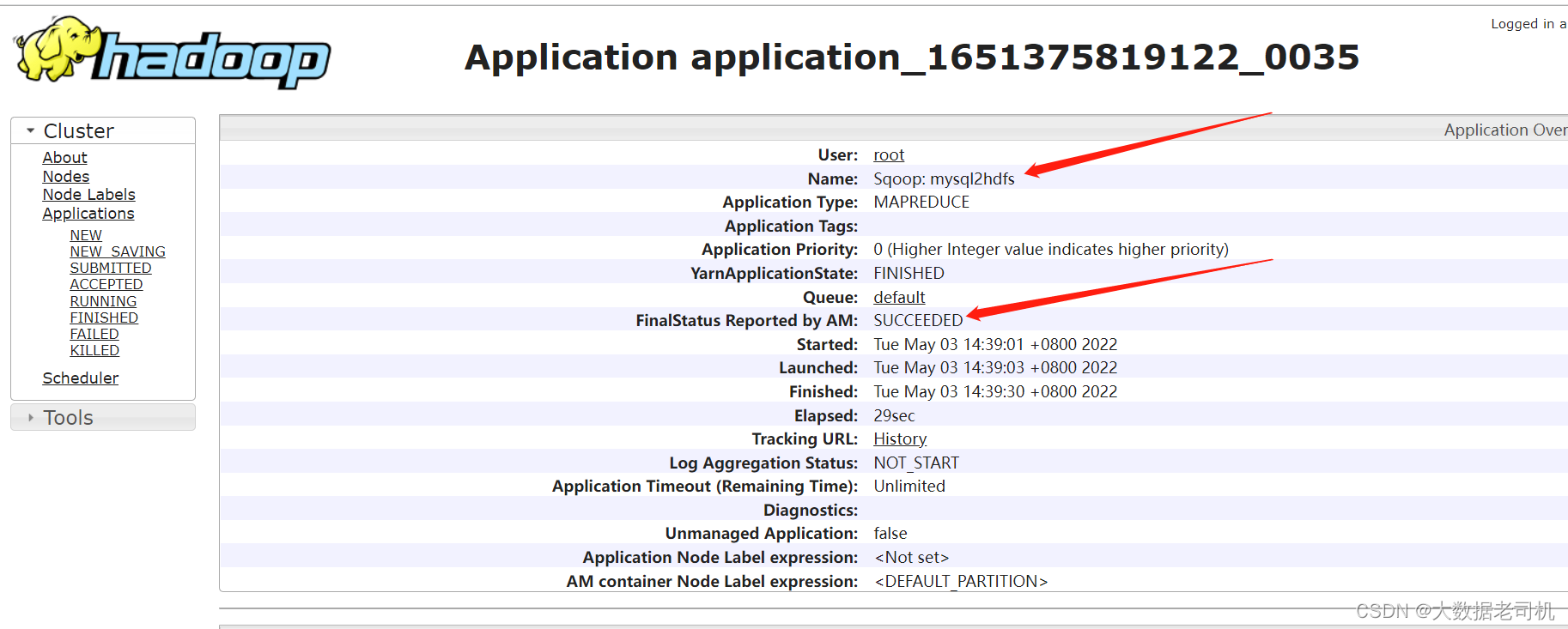
去HDFS上查看输出
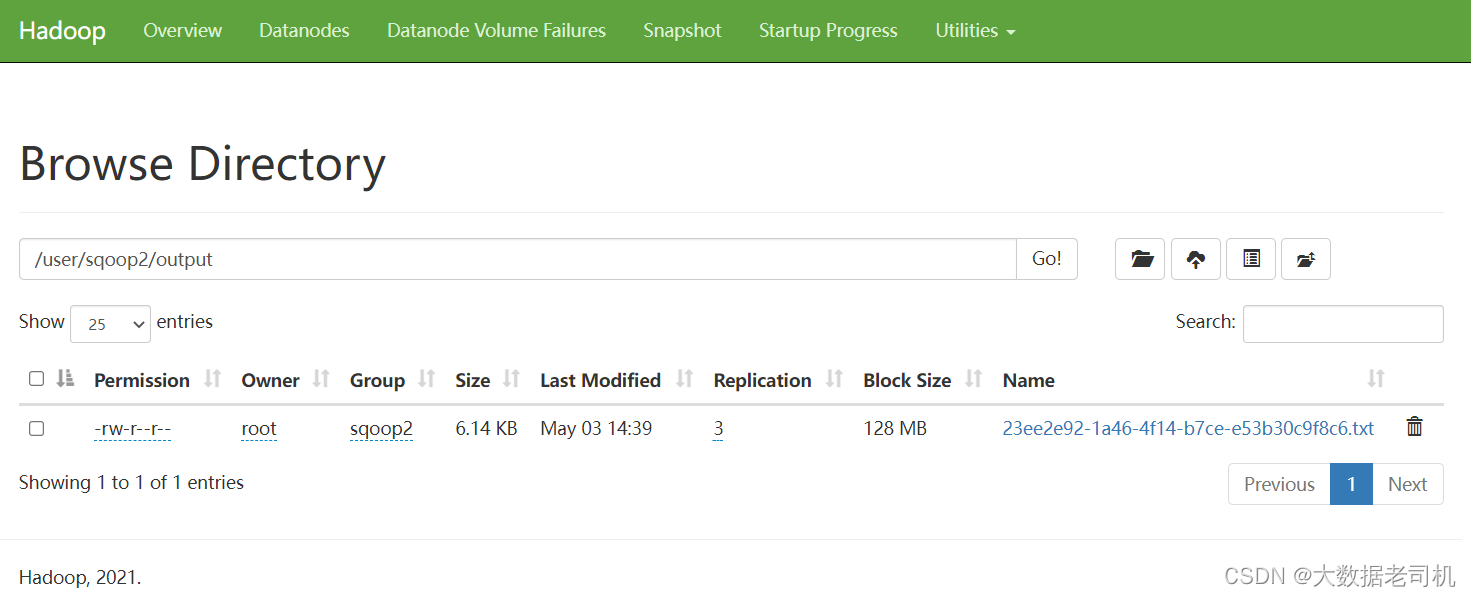
3)从HDFS导出到MYSQL(Export)
本来是想通过hive去转换,但是现在没有了hive的连接器了,所以这里选择通过hive去创建HDFS数据文件,通过HDFS转出到mysql,当然也可以一步到位。
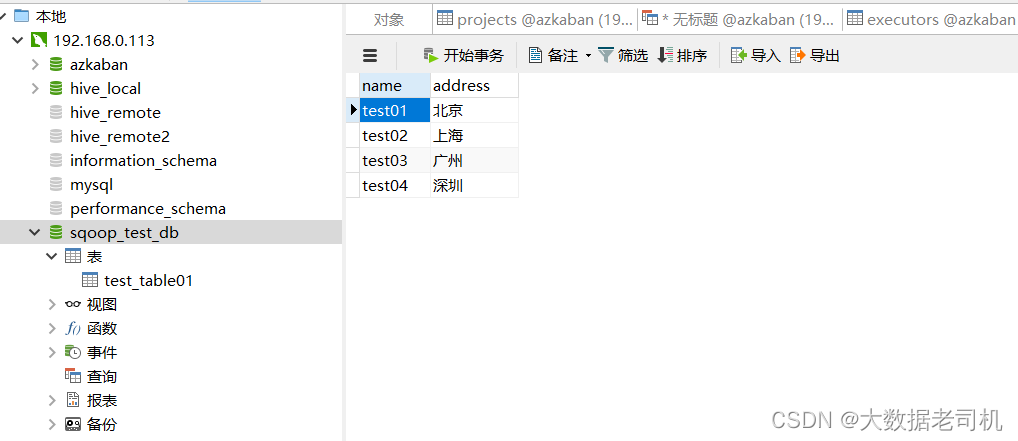
1、创建集群测试表和数据
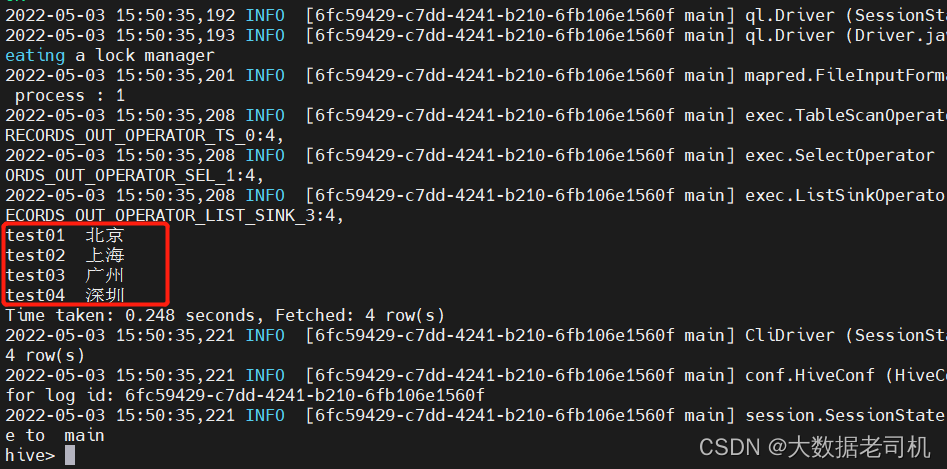
# 准备数据文件
$ vi /tmp/sqoop-test-data
test01,北京
test02,上海
test03,广州
test04,深圳
$ hive
- 1
- 2
- 3
- 4
- 5
- 6
- 7
sql语句如下:
-- hive创建测试库
create database hive_sqoop_test_db;
-- hive创建一张表,默认是textfile类型的,通过逗号分隔字段
create table hive_sqoop_test_db.test_table01(name string,address string) row format delimited fields terminated by ',';
# 从local加载数据,这里的local是指hs2服务所在机器的本地linux文件系统
load data local inpath '/tmp/sqoop-test-data' into table hive_sqoop_test_db.test_table01;
select * from hive_sqoop_test_db.test_table01;
-- 当然也可以通过下面方式创建,但是不提倡,因为很慢很慢
-- hive创建一张表,默认是textfile类型的
create table if not exists hive_sqoop_test_db.test_table01
(
name string,
address string
);
# -- 创建测试数据
insert into hive_sqoop_test_db.test_table01 values('test01','北京');
insert into hive_sqoop_test_db.test_table01 values('test02','上海');
insert into hive_sqoop_test_db.test_table01 values('test02','广州');
insert into hive_sqoop_test_db.test_table01 values('test02','深圳');
# 查询验证
select * from hive_sqoop_test_db.test_table01;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
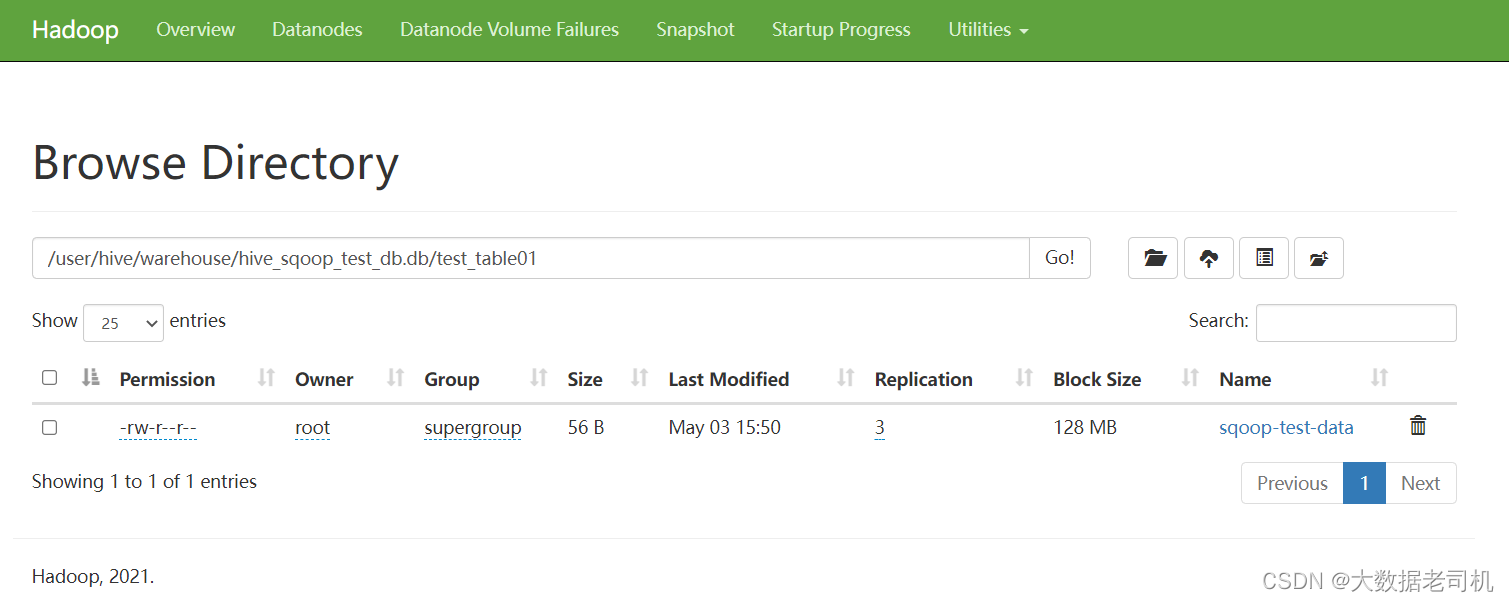
对应HDFS的文件:/user/hive/warehouse/hive_sqoop_test_db.db/test_table01/sqoop-test-data
2、创建MYSQL接收表
-- 创建测试库
create database sqoop_test_db
-- 创建接收表
create table sqoop_test_db.test_table01
(
name varchar(10),
address varchar(10)
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
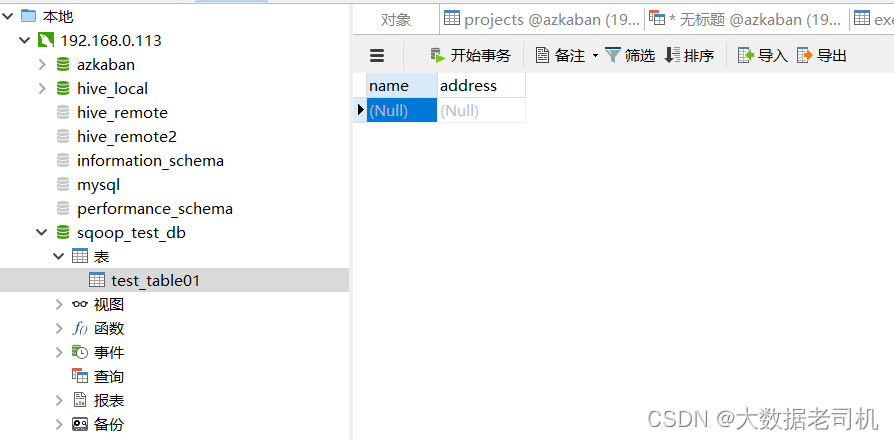
3、创建MYSQL连接
$ sqoop2-shell
sqoop:000> set server --url http://hadoop-node1:12000/sqoop
sqoop:000> show connector
sqoop:000> create link -connector generic-jdbc-connector
Name: hive2mysql-mysql-link
Driver class: com.mysql.cj.jdbc.Driver
Connection String: jdbc:mysql://hadoop-node1:3306/sqoop_test_db?characterEncoding=utf8&useSSL=false&serverTimezone=UTC&rewriteBatchedStatements=true
Username: root
Password: 123456
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
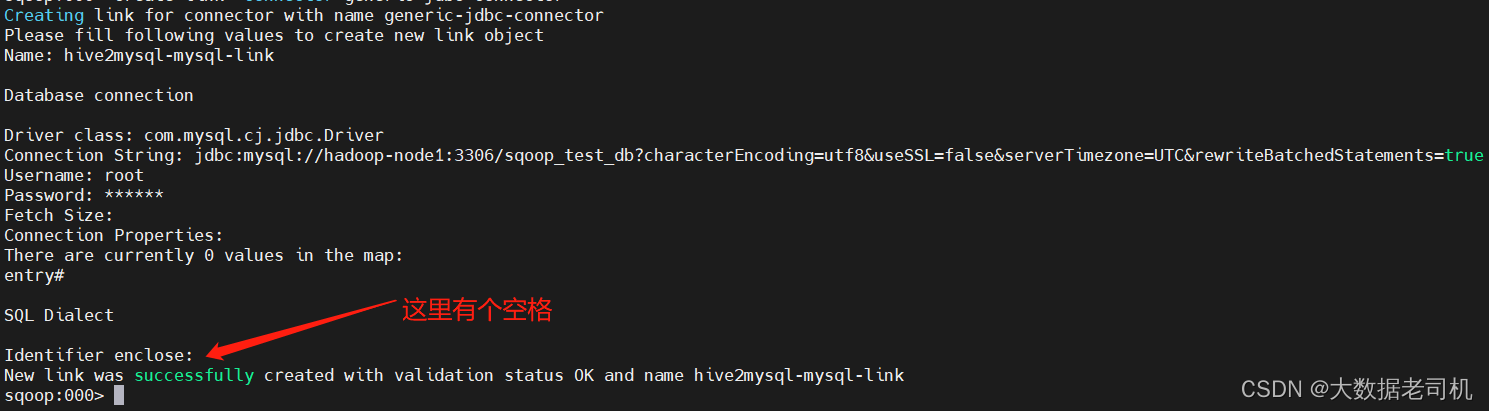
4、创建HDFS连接
sqoop:000> create link -connector hdfs-connector
Name: hdfs2mysql-hdfs-link
URI: hdfs://hadoop-node1:8082
Conf directory: /opt/bigdata/hadoop/server/hadoop-3.3.1/etc/hadoop/
- 1
- 2
- 3
- 4
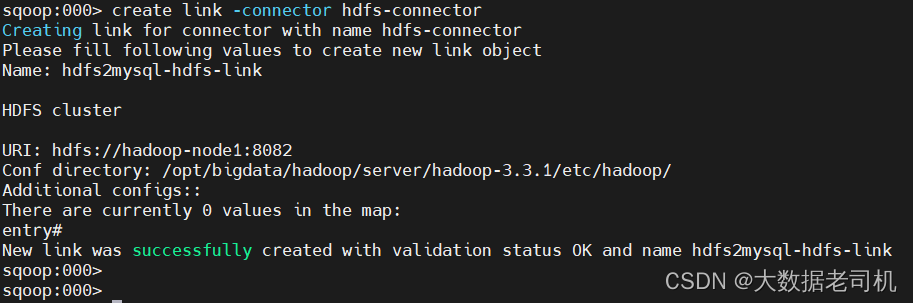
5、创建Job
sqoop:000> show link
sqoop:000> create job -f "hdfs2mysql-hdfs-link" -t "hive2mysql-mysql-link"
Name: hdfs2mysql-job
Input directory: hdfs://hadoop-node1:8082/user/hive/warehouse/hive_sqoop_test_db.db/test_table01/
Choose: 0
Schema name: sqoop_test_db
Table name: test_table01
Extractors: 1
Loaders: 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
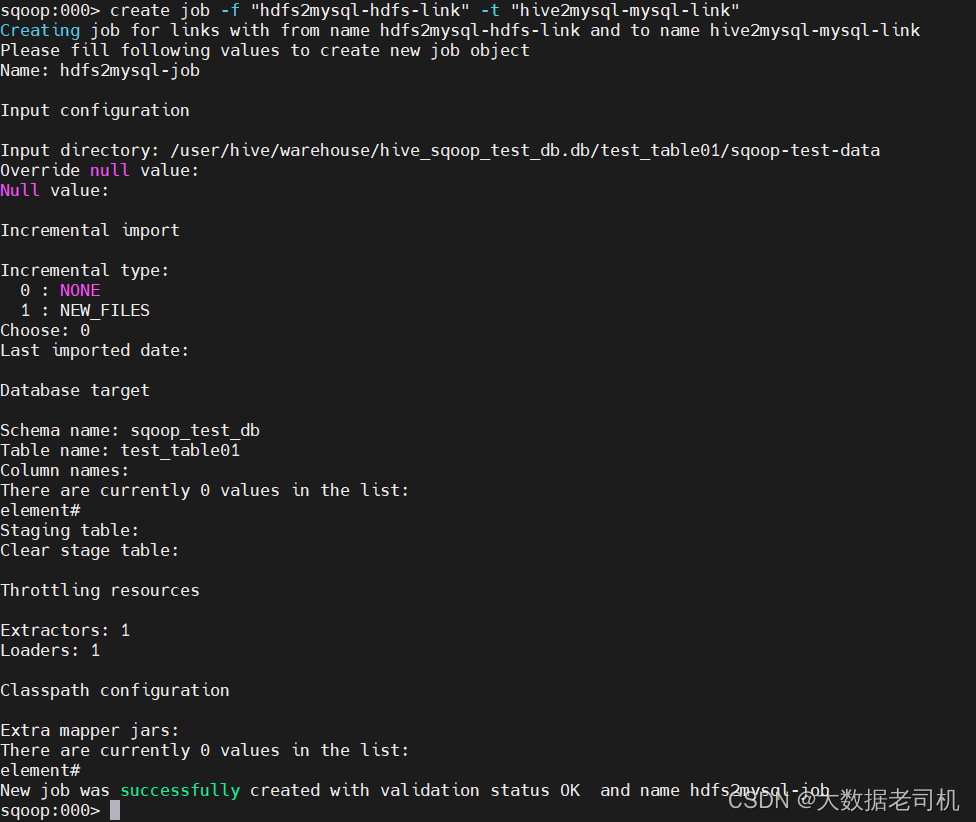
6、开始执行Job
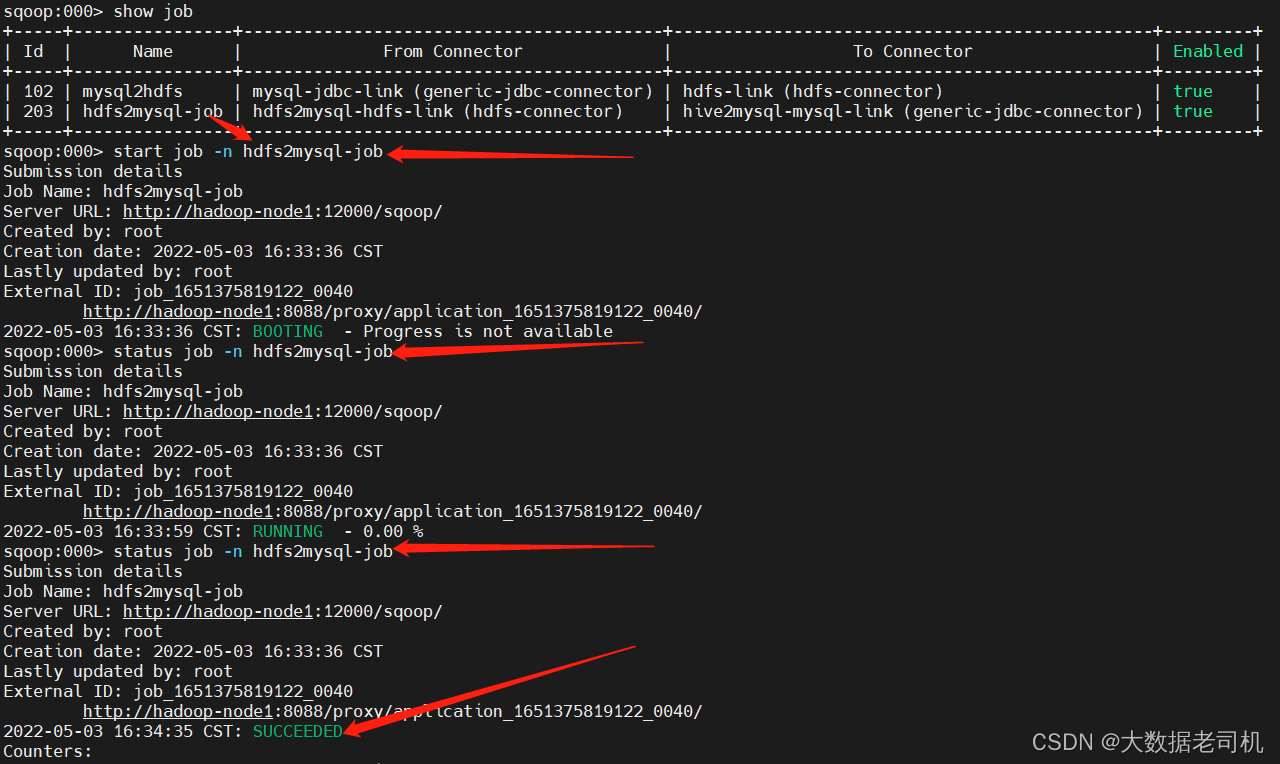
sqoop:000> start job -n hdfs2mysql-job
sqoop:000> status job -n hdfs2mysql-job
- 1
- 2
YARN上查看任务
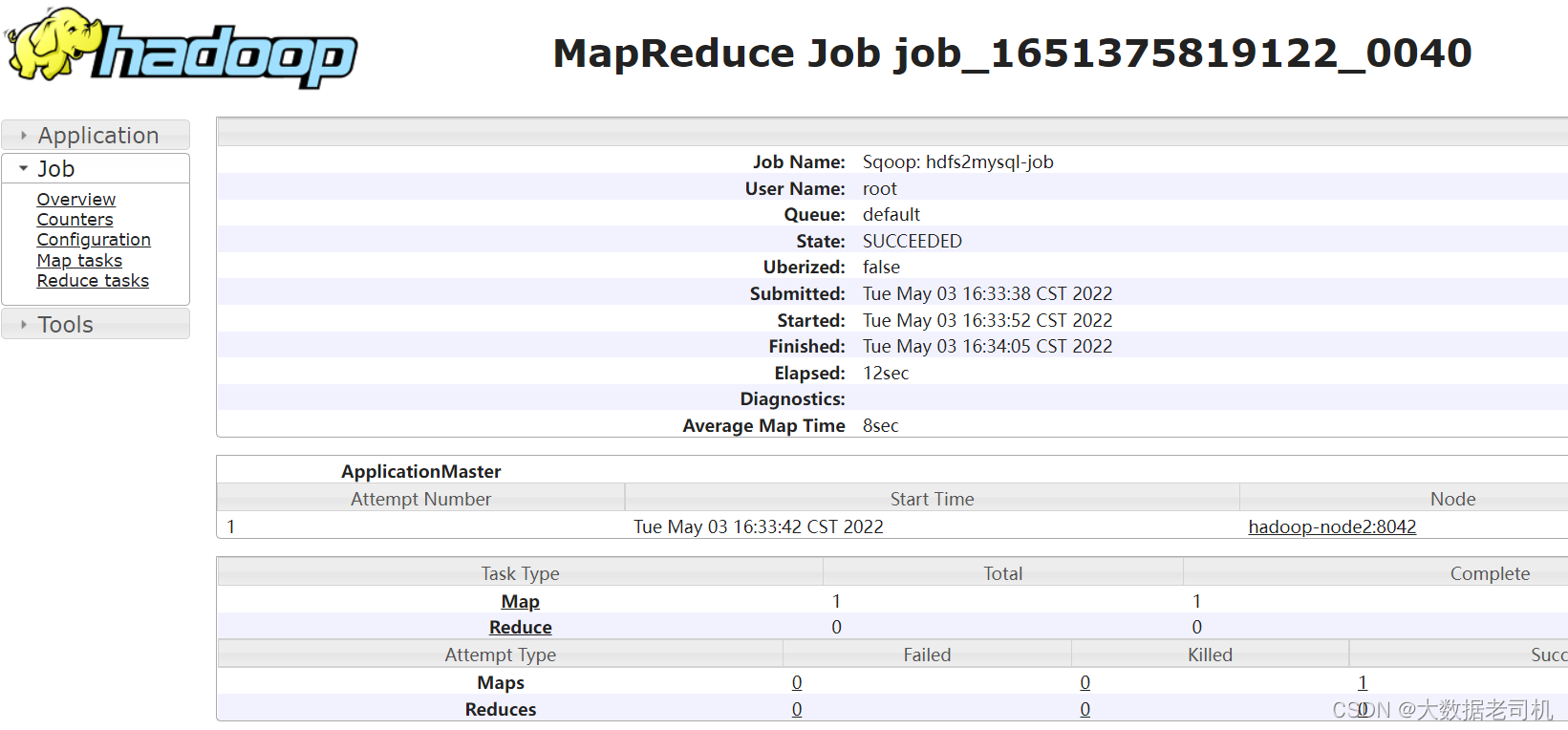
去mysql上查看数据
4)通过JAVA实现数据从MYSQL导入到HDFS(Import)
1、先准备好数据源
CREATE DATABASE sqoop_test_db;
-- 必须设置一个主键,要不然会报错
create table if not exists sqoop_test_db.test_table01
(
id INT Unsigned Primary Key AUTO_INCREMENT,
name VARCHAR(20),
address VARCHAR(20)
);
# -- 创建测试数据
insert into sqoop_test_db.test_table01 values(1,'test01','北京');
insert into sqoop_test_db.test_table01 values(2,'test02','上海');
insert into sqoop_test_db.test_table01 values(3,'test03','广州');
insert into sqoop_test_db.test_table01 values(4,'test04','深圳');
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
2、添加项目依赖
<dependency>
<groupId>org.apache.sqoop</groupId>
<artifactId>sqoop-client</artifactId>
<version>1.99.7</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
3、编写java代码
这里实现的是HDFS=》MYSQL的数据转换
import org.apache.commons.io.filefilter.FalseFileFilter;
import org.apache.sqoop.client.SqoopClient;
import org.apache.sqoop.common.SqoopException;
import org.apache.sqoop.model.*;
import org.apache.sqoop.validation.Status;
import javax.sound.midi.Soundbank;
import java.util.List;
import java.util.ResourceBundle;
/**
* Import
* mysql数据 导出 HDFS
*
*/
public class Mysql2HDFS {
public static void main(String[] args) {
String url = "http://hadoop-node1:12000/sqoop/";
SqoopClient client = new SqoopClient(url);
String mysql_link_name = "java-mysql-link";
String hdfs_link_name = "java-hdfs-link";
// 获取所有link
List<MLink> links = client.getLinks();
boolean mysql_link_isexist = Boolean.FALSE;
boolean hdfs_link_isexist = Boolean.FALSE;
for (MLink link : links) {
if (!mysql_link_isexist && link.getName().equals(mysql_link_name)){
mysql_link_isexist = Boolean.TRUE;
}
if (!hdfs_link_isexist && link.getName().equals(hdfs_link_name)){
hdfs_link_isexist = Boolean.TRUE;
}
if (mysql_link_isexist && hdfs_link_isexist){
break;
}
}
/**
* 1、创建mysql link
*/
MLink mysql_link = client.createLink("generic-jdbc-connector");
mysql_link.setName("java-mysql-link");
mysql_link.setCreationUser("root");
// 如果不存在就创建link
if (!mysql_link_isexist){
MLinkConfig mysql_linkConfig = mysql_link.getConnectorLinkConfig();
System.out.println(mysql_linkConfig);
// fill in the link config values
mysql_linkConfig.getStringInput("linkConfig.jdbcDriver").setValue("com.mysql.cj.jdbc.Driver");
mysql_linkConfig.getStringInput("linkConfig.connectionString").setValue("jdbc:mysql://hadoop-node1:3306/sqoop_test_db?characterEncoding=utf8&useSSL=false&serverTimezone=UTC&rewriteBatchedStatements=true");
mysql_linkConfig.getStringInput("linkConfig.username").setValue("root");
mysql_linkConfig.getStringInput("linkConfig.password").setValue("123456");
mysql_linkConfig.getStringInput("dialect.identifierEnclose").setValue(" ");
// 设置 primary key
// mysql_linkConfig.getStringInput("linkConfig.partitionColumn").setValue("id");
// save the link object that was filled
Status mysql_status = client.saveLink(mysql_link);
// 查看属性
// describe(client.getConnector("generic-jdbc-connector").getLinkConfig().getConfigs(), client.getConnectorConfigBundle("generic-jdbc-connector"));
if(mysql_status.canProceed()) {
System.out.println("Created Link with Link Name : " + mysql_link.getName());
} else {
System.out.println("Something went wrong creating the link");
}
}else {
System.out.println("Link Name : " + mysql_link.getName() + " is exist");
}
/**
* 2、创建hdfs link
*/
MLink hdfs_link = client.createLink("hdfs-connector");
hdfs_link.setName("java-hdfs-link");
hdfs_link.setCreationUser("root");
// 如果不存在就创建link
if (!hdfs_link_isexist){
// 创建hdfs link
MLinkConfig hdfs_linkConfig = hdfs_link.getConnectorLinkConfig();
hdfs_linkConfig.getStringInput("linkConfig.uri").setValue("hdfs://hadoop-node1:8082");
hdfs_linkConfig.getStringInput("linkConfig.confDir").setValue("/opt/bigdata/hadoop/server/hadoop-3.3.1/etc/hadoop/");
Status hdfs_status = client.saveLink(hdfs_link);
if(hdfs_status.canProceed()) {
System.out.println("Created Link with Link Name : " + hdfs_link.getName());
} else {
System.out.println("Something went wrong creating the link");
}
}else {
System.out.println("Link Name : " + hdfs_link.getName() + " is exist");
}
/**
* 3、创建job
*/
String job_name = "java-mysql2hdfs";
List<MJob> jobs = client.getJobs();
boolean job_isexist = Boolean.FALSE;
for (MJob job : jobs) {
if (job.getName().equals(job_name)){
job_isexist = Boolean.TRUE;
break;
}
}
MJob job = client.createJob(mysql_link_name, hdfs_link_name);
job.setName("java-mysql2hdfs");
job.setCreationUser("root");
if (!job_isexist){
// set the "FROM" link job config values
MFromConfig fromJobConfig = job.getFromJobConfig();
System.out.println(fromJobConfig);
fromJobConfig.getStringInput("fromJobConfig.schemaName").setValue("sqoop_test_db");
fromJobConfig.getStringInput("fromJobConfig.tableName").setValue("test_table01");
// set the "TO" link job config values
MToConfig toJobConfig = job.getToJobConfig();
// 导出目录是需要不存在的
toJobConfig.getStringInput("toJobConfig.outputDirectory").setValue("hdfs://hadoop-node1:8082/tmp/output/");
toJobConfig.getEnumInput("toJobConfig.outputFormat").setValue("TEXT_FILE");
toJobConfig.getEnumInput("toJobConfig.compression").setValue("NONE");
toJobConfig.getBooleanInput("toJobConfig.overrideNullValue").setValue(true);
// set the driver config values
MDriverConfig driverConfig = job.getDriverConfig();
// System.out.println(driverConfig);
driverConfig.getIntegerInput("throttlingConfig.numExtractors").setValue(1);
// driverConfig.getIntegerInput("throttlingConfig.numLoaders").setValue(0);
Status status = client.saveJob(job);
if(status.canProceed()) {
System.out.println("Created Job with Job Name: "+ job.getName());
} else {
System.out.println("Something went wrong creating the job");
System.exit(0);
}
} else {
System.out.println("Job Name : " + job.getName() + " is exist");
}
/**
* 4、启动job
*/
MSubmission submission = client.startJob(job.getName());
System.out.println("Job Submission Status : " + submission.getStatus());
if(submission.getStatus().isRunning() && submission.getProgress() != -1) {
System.out.println("Progress : " + String.format("%.2f %%", submission.getProgress() * 100));
}
System.out.println("Hadoop job id :" + submission.getExternalJobId());
System.out.println("Job link : " + submission.getExternalLink());
}
/**
* 输出属性信息
* @param configs
* @param resource
*/
public static void describe(List<MConfig> configs, ResourceBundle resource) {
for (MConfig config : configs) {
System.out.println(resource.getString(config.getLabelKey())+":");
List<MInput<?>> inputs = config.getInputs();
for (MInput input : inputs) {
System.out.println(resource.getString(input.getLabelKey()) + " : " + input.getValue());
}
System.out.println();
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
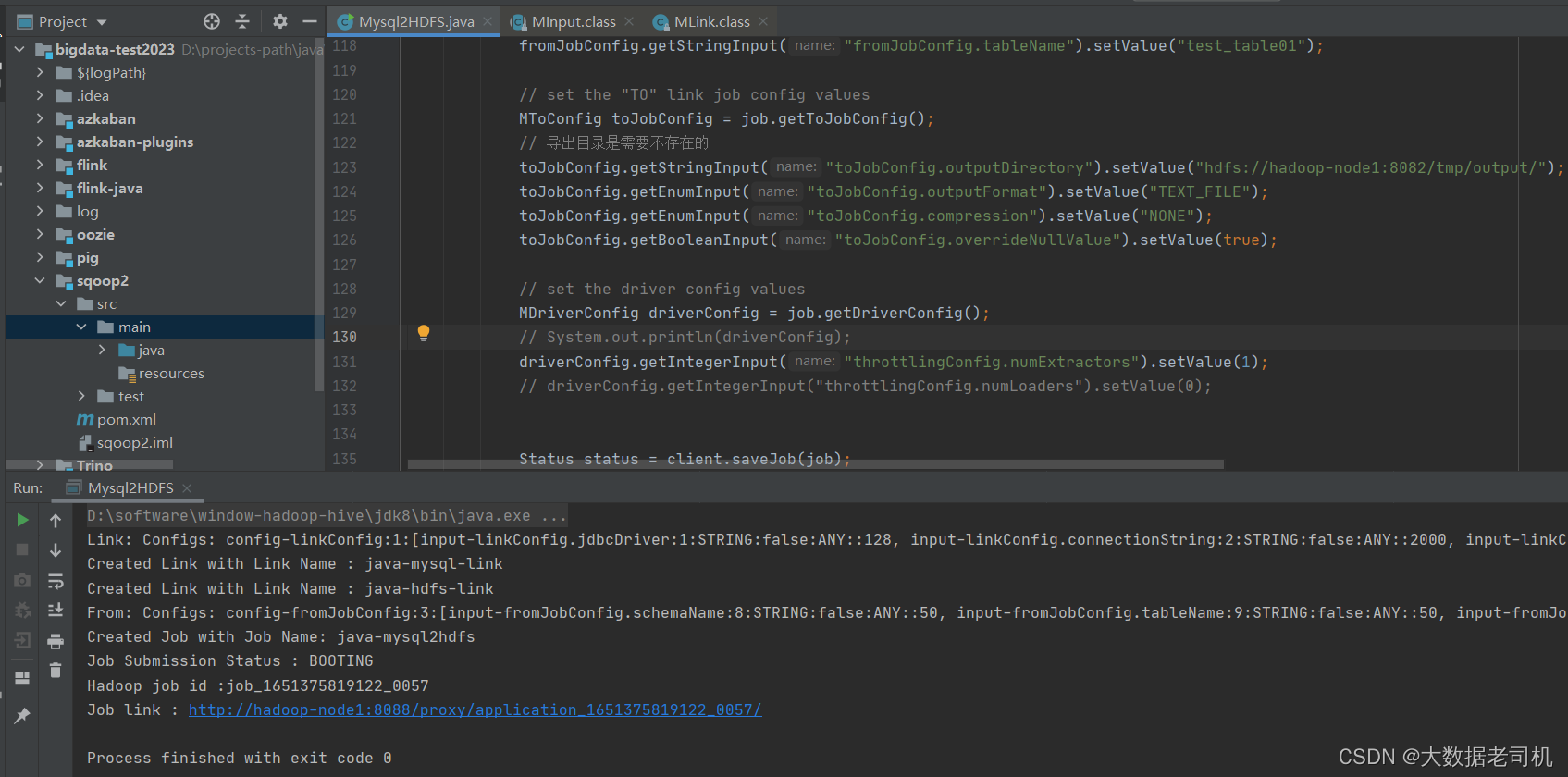
查看AYRN任务
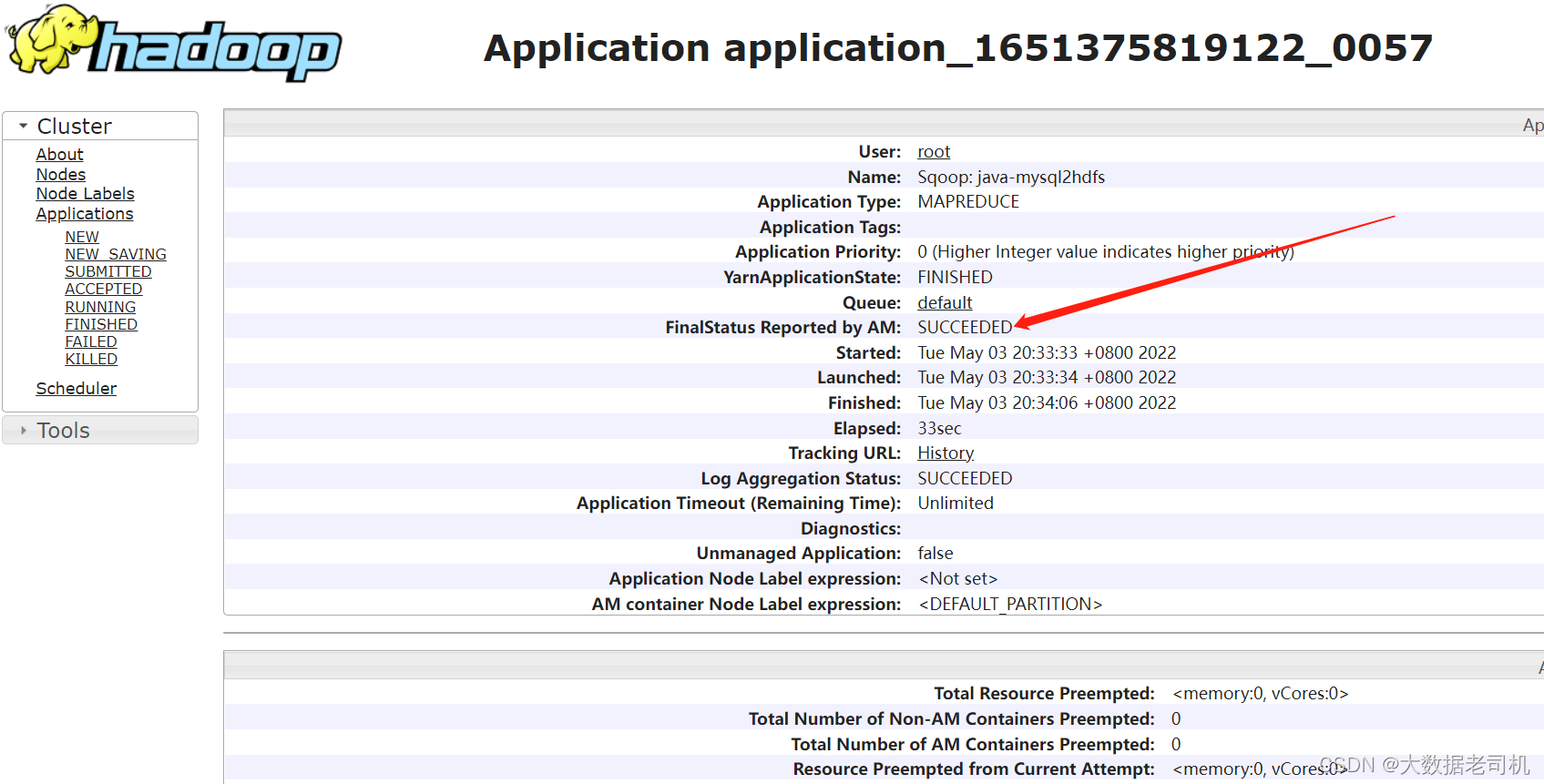
查看HDFS
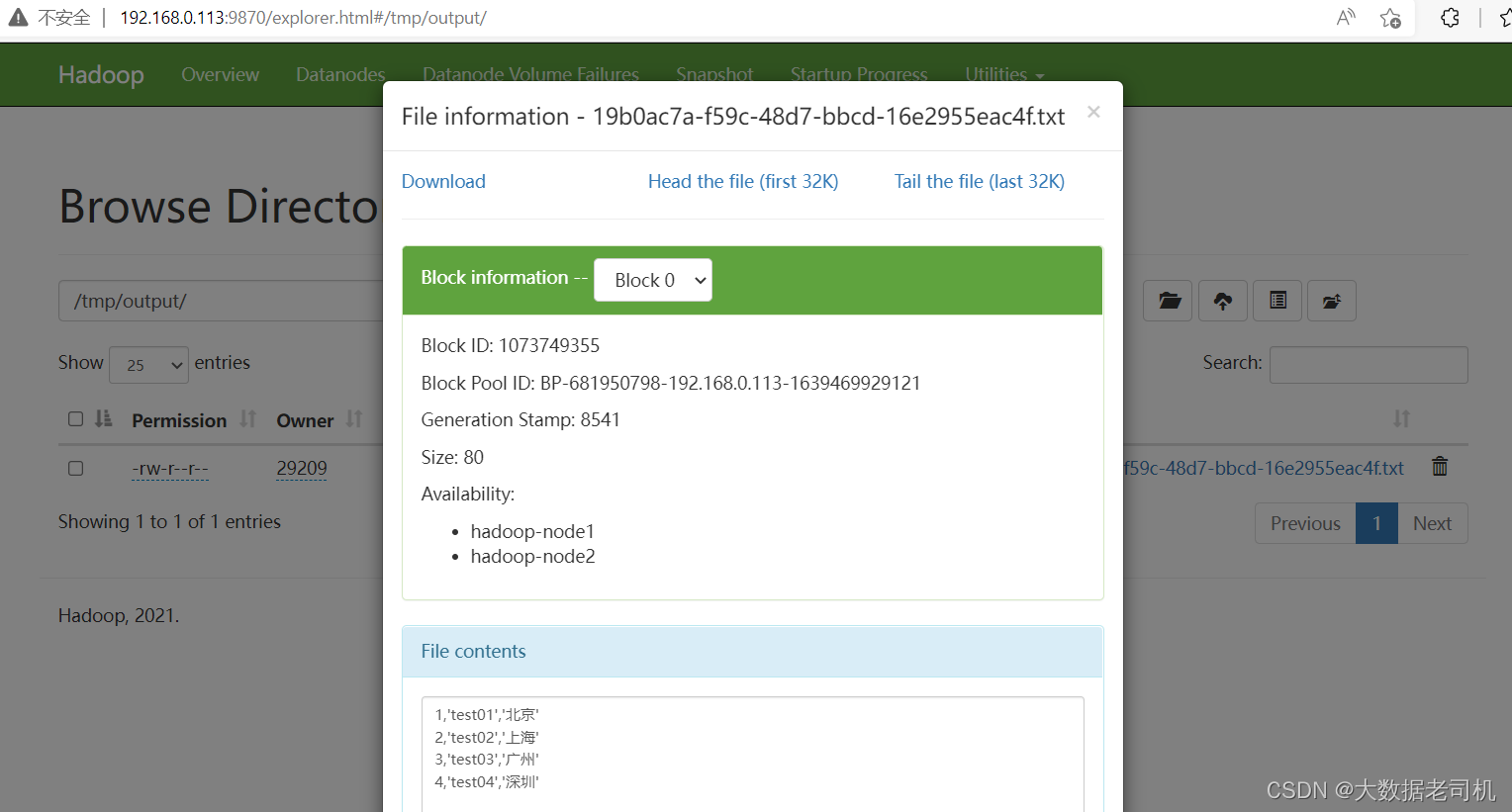
这里只用java代码实现了MYSQL-》HDFS的转换,HDFS-》MYSQL的转换就留给小伙伴试试,其实也很简单,稍微把我上面的代码改一下就ok了,也可以对照上面第三个示例。有疑问的小伙伴欢迎给我留言,后续会有更多大数据相关的文章,请小伙伴耐心等待~

