
- 1构建云原生湖仓:Apache Iceberg与Amoro的结合实践_浙江电信基于 amoro + apache iceberg 构建实时湖仓实践
- 2基于JavaWeb+MySQL的图书管理系统_javaweb图书管理系统
- 3seata2.0 下载安装部署,使用nacos为配置中心、注册中心_seata 2.0
- 4Springboot项目Github Action生成Docker镜像_在页面提交代码打包成镜像的项目
- 5量化交易:开发传统趋势策略之---双均线策略_algoplus接口双均线策略
- 6微信群机器人(仿真企业微信群机器人)
- 7区块链项目构建指南(二)_入门区块链项目
- 8【Python--XML文件读写】XML文件读写详解_python读写xml文件
- 9在linux服务器上离线安装mysql_linux离线安装mysql
- 10使用MySQL进行图像数据存储与处理的实践经验_mysql 保存图片 优化查询
搭建 canal 监控mysql数据到RabbitMQ_canal监听mysql,那mysql需要做什么配置_canal.mq.topic rabbitmq
赞
踩
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)

正文
使用canal监控mysql某个库某个表,或者多个库,多个表---- update/inster/create 操作,
| 系统版本 | mysql版本 | java版本 | canal版本 | rabbitMQ版本 |
|---|---|---|---|---|
| Rocky 9.2 | MySQL 8.0.26 | openjdk 11.0.22 | 1.1.6 | rabbitmq-server 3.12.4 |
mysql 配置搭建
作者使用的mysql配置文件是上述文章里面 { mysql 主从同步 主节点 配置文件 }
MySQL 配置
开启 binlog 首先在 mysql 的配置文件目录中查找配置文件 my.cnf
(mysql如果有主从的话,这一步可略过,canal 在mysql 主库搭建)
vim my.cnf
server-id=1 #master端的ID号【必须是唯一的】;
log\_bin=mysql-bin #同步的日志路径,一定注意这个目录要是mysql有权限写入的
binlog-format=row #行级,记录每次操作后每行记录的变化。
mysql 创建canal用户
CREATE USER canal IDENTIFIED BY 'canal'; #创建用户名和密码都为 canal 的用户
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%'; #授予该用户对所有数据库和表的查询、复制主节点数据的操作权限
FLUSH PRIVILEGES; #重新加载权限
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
canal软件下载
## canal-deploy:
可以直接监听MySQL的binlog,把自己伪装成MySQL的从库,只负责接收数据,并不做处理。
## canal-admin:
为canal提供整体配置管理、节点运维等面向运维的功能,提供相对友好的WebUI操作界面,
方便更多用户快速和安全的操作。
## canal-adapter:相当于canal的客户端,会从canal-server中获取数据,然后对数据进行同步,
可以同步到MySQL、Elasticsearch和HBase等存储中去。在1.1.8版本中 canal-adapter 文件不更新了
## canal.example: 示例程序。
# 组件下载canal-deploy、canal-admin
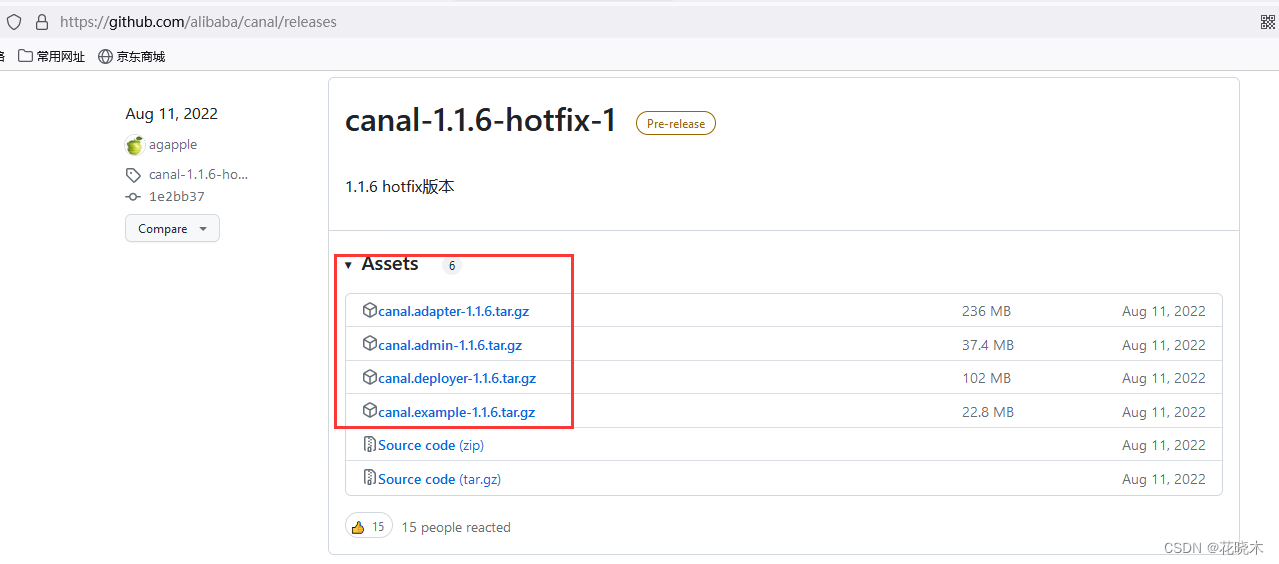
wget https://github.com/alibaba/canal/releases/download/canal-1.1.6-alpha-2/canal.deployer-1.1.6-SNAPSHOT.tar.gz
wget https://github.com/alibaba/canal/releases/download/canal-1.1.6-alpha-2/canal.admin-1.1.6-SNAPSHOT.tar.gz
wget https://github.com/alibaba/canal/releases/download/canal-1.1.6-alpha-1/canal.example-1.1.6-SNAPSHOT.tar.gz
目前环境只用到了 canal-deploy 及 canal-admin
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
https://github.com/alibaba/canal/releases/
环境部署
安装canal-admin
安装 java
yum -y install java
安装canal
将下载好的安装包 解压到/usr/local/下
mkdir /usr/local/canal-admin/
mkdir /usr/local/canal/
tar -xf canal.deployer-1.1.6-SNAPSHOT.tar.gz -C /usr/local/canal/
tar -xf canal.admin-1.1.6-SNAPSHOT.tar.gz -C /usr/local/canal-admin/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
配置环境:
cd /usr/local/canal-admin/ vim conf/application.yml server: port: 8089 #网页访问端口 spring: jackson: date-format: yyyy-MM-dd HH:mm:ss time-zone: GMT+8 spring.datasource: address: 127.0.0.1:3306 # 数据库端口 database: canal_manager # canal的数据库 username: root #数据库账号,这个账号必须有增删改查的权限,因为要往里面写数据。 password: 123456 # 数据库密码 driver-class-name: com.mysql.jdbc.Driver url: jdbc:mysql://${spring.datasource.address}/${spring.datasource.database}?useUnicode=true&characterEncoding=UTF-8&useSSL=false&allowPublicKeyRetrieval=true hikari: maximum-pool-size: 30 minimum-idle: 1 # canal 这个类似于 api接口使用的 需要和 canal中的conf/canal.properties 对应上 # canal.properties 中是密文 canal: adminUser: admin adminPasswd: admin :wq (保存退出) # 将canal\_manager库导入到mysql表中 mysql -uroot -p123456 source /usr/local/canal-admin/conf/canal_manager.sql 导入完成,退出mysql 启动 canal-admin ./bin/startup.sh tail -f logs/admin.log 访问:http://IP:8089 账号:admin 密码:123456 默认

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
安装canal
修改配置一:
cd /usr/local/canal vim conf/canal.properties ################################################# ######### common argument ############# ################################################# # tcp bind ip canal.ip = # register ip to zookeeper canal.register.ip = # Canal 服务的主要端口,通常用于数据库变更事件的监听和同步。 canal.port = 11111 # Canal 用于指标拉取的端口,用于监控和收集指标数据 canal.metrics.pull.port = 11112 # canal instance user/passwd # canal.user = canal # canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458 # canal admin config #Canal-admin 访问IP及端口 #canal.admin.manager = 127.0.0.1:8089 canal.admin.port = 11110 # Canal 管理端口,用于管理和配置 Canal 实例。 canal.admin.user = admin # 对应上面application.yml 配置 # 4ACF~441 则是admin 密文 # canal.admin.passwd = 6bb4837eb74329105ee4568dda7dc67ed2ca2ad9 123456 canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441 # admin auto register #canal.admin.register.auto = true # 是否开启自动注册模式 #canal.admin.register.cluster = #canal.admin.register.name = canal.zkServers = # flush data to zk canal.zookeeper.flush.period = 1000 canal.withoutNetty = false # tcp, kafka, rocketMQ, rabbitMQ # 修改为rabbitmq 下来就直接修改最后几条配置即可 canal.serverMode = rabbitMQ # flush meta cursor/parse position to file canal.file.data.dir = ${canal.conf.dir} canal.file.flush.period = 1000 ## memory store RingBuffer size, should be Math.pow(2,n) canal.instance.memory.buffer.size = 16384 ## memory store RingBuffer used memory unit size , default 1kb canal.instance.memory.buffer.memunit = 1024 ## meory store gets mode used MEMSIZE or ITEMSIZE canal.instance.memory.batch.mode = MEMSIZE canal.instance.memory.rawEntry = true ## detecing config canal.instance.detecting.enable = false #canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now() canal.instance.detecting.sql = select 1 canal.instance.detecting.interval.time = 3 canal.instance.detecting.retry.threshold = 3 canal.instance.detecting.heartbeatHaEnable = false # support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery canal.instance.transaction.size = 1024 # mysql fallback connected to new master should fallback times canal.instance.fallbackIntervalInSeconds = 60 # network config canal.instance.network.receiveBufferSize = 16384 canal.instance.network.sendBufferSize = 16384 canal.instance.network.soTimeout = 30 # binlog filter config canal.instance.filter.druid.ddl = true canal.instance.filter.query.dcl = false canal.instance.filter.query.dml = false canal.instance.filter.query.ddl = false canal.instance.filter.table.error = false canal.instance.filter.rows = false canal.instance.filter.transaction.entry = false canal.instance.filter.dml.insert = false canal.instance.filter.dml.update = false canal.instance.filter.dml.delete = false # binlog format/image check canal.instance.binlog.format = ROW,STATEMENT,MIXED canal.instance.binlog.image = FULL,MINIMAL,NOBLOB # binlog ddl isolation canal.instance.get.ddl.isolation = false # parallel parser config canal.instance.parser.parallel = true ## concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors() #canal.instance.parser.parallelThreadSize = 16 ## disruptor ringbuffer size, must be power of 2 canal.instance.parser.parallelBufferSize = 256 # table meta tsdb info canal.instance.tsdb.enable = true canal.instance.tsdb.dir = ${canal.file.data.dir:../conf}/${canal.instance.destination:} canal.instance.tsdb.url = jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL; canal.instance.tsdb.dbUsername = canal canal.instance.tsdb.dbPassword = canal # dump snapshot interval, default 24 hour canal.instance.tsdb.snapshot.interval = 24 # purge snapshot expire , default 360 hour(15 days) canal.instance.tsdb.snapshot.expire = 360 ################################################# ######### destinations ############# ################################################# canal.destinations = # conf root dir canal.conf.dir = ../conf # auto scan instance dir add/remove and start/stop instance canal.auto.scan = true canal.auto.scan.interval = 5 # set this value to 'true' means that when binlog pos not found, skip to latest. # WARN: pls keep 'false' in production env, or if you know what you want. canal.auto.reset.latest.pos.mode = false canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml #canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xml canal.instance.global.mode = manager canal.instance.global.lazy = false canal.instance.global.manager.address = ${canal.admin.manager} #canal.instance.global.spring.xml = classpath:spring/memory-instance.xml canal.instance.global.spring.xml = classpath:spring/file-instance.xml #canal.instance.global.spring.xml = classpath:spring/default-instance.xml ################################################## ######### MQ Properties ############# ################################################## # aliyun ak/sk , support rds/mq canal.aliyun.accessKey = canal.aliyun.secretKey = canal.aliyun.uid= canal.mq.flatMessage = true canal.mq.canalBatchSize = 50 canal.mq.canalGetTimeout = 100 # Set this value to "cloud", if you want open message trace feature in aliyun. canal.mq.accessChannel = local canal.mq.database.hash = true canal.mq.send.thread.size = 30 canal.mq.build.thread.size = 8 ################################################## ######### Kafka ############# ################################################## kafka.bootstrap.servers = 127.0.0.1:6667 kafka.acks = all kafka.compression.type = none kafka.batch.size = 16384 kafka.linger.ms = 1 kafka.max.request.size = 1048576 kafka.buffer.memory = 33554432 kafka.max.in.flight.requests.per.connection = 1 kafka.retries = 0 kafka.kerberos.enable = false kafka.kerberos.krb5.file = "../conf/kerberos/krb5.conf" kafka.kerberos.jaas.file = "../conf/kerberos/jaas.conf" ################################################## ######### RocketMQ ############# ################################################## rocketmq.producer.group = test rocketmq.enable.message.trace = false rocketmq.customized.trace.topic = rocketmq.namespace = rocketmq.namesrv.addr = 127.0.0.1:9876 rocketmq.retry.times.when.send.failed = 0 rocketmq.vip.channel.enabled = false rocketmq.tag = ################################################## ######### RabbitMQ ############# ################################################## # MQ地址及端口 rabbitmq.host = 127.0.0.1:5672 # 虚拟主机 rabbitmq.virtual.host = canal # 交换机名称 rabbitmq.exchange = ex_canal # mq账号 rabbitmq.username = canal # mq 密码 rabbitmq.password = canal # 以上几个值是在MQ中自建的值 如下图示例 rabbitmq.deliveryMode =
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
修改配置二:
vim conf/canal_local.properties # register ip canal.register.ip = # canal admin config canal.admin.manager = 127.0.0.1:8089 #Canal-admin 访问IP及端口 canal.admin.port = 11110 # Canal 管理端口,用于管理和配置 Canal 实例。 canal.admin.user = admin # 对应上面application.yml 配置 canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441 # 4ACF~441 则是admin 密文 #canal.admin.passwd = 6bb4837eb74329105ee4568dda7dc67ed2ca2ad9 # admin auto register canal.admin.register.auto = true canal.admin.register.cluster = canal.admin.register.name =
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
修改配置三:
vim conf/example/instance.properties ################################################# ## mysql serverId , v1.0.26+ will autoGen # canal.instance.mysql.slaveId=0 # enable gtid use true/false canal.instance.gtidon=false # position info canal.instance.master.address=127.0.0.1:3306 # 监控mysql的地址,可以换成其他地址 canal.instance.master.journal.name= canal.instance.master.position= canal.instance.master.timestamp= canal.instance.master.gtid= # rds oss binlog canal.instance.rds.accesskey= canal.instance.rds.secretkey= canal.instance.rds.instanceId= # table meta tsdb info canal.instance.tsdb.enable=true #canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb #canal.instance.tsdb.dbUsername=canal #canal.instance.tsdb.dbPassword=canal #canal.instance.standby.address = #canal.instance.standby.journal.name = #canal.instance.standby.position = #canal.instance.standby.timestamp = #canal.instance.standby.gtid= # username/password canal.instance.dbUsername=canal # mysql 账户 canal.instance.dbPassword=canal # mysql 密码 # 如果账户密码没有,根据上面的命令创建 canal.instance.connectionCharset = UTF-8 # enable druid Decrypt database password canal.instance.enableDruid=false #canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ== # table regex # canal.instance.filter.regex=.*\\..* # canal.instance.filter.regex=dt\\.orders,dt\\.user,dt\\.user_equity_summary,dt\\.user_statistics,dt\\.user_equity_summary,dt_logs\\..* # 如上注释:监控dt库下的orders表,dt库下的user表..... dt_logs库下的所有表 canal.instance.filter.regex=dt_test\\..* # 需要监控的数据库,监控dt_test库下面的所有表 # table black regex # 排除一些不需要同步的数据库表,避免不必要的数据传输和处理,提高性能和效率。 # 注解:排除mysql库中的slave_.* 开头的表 canal.instance.filter.black.regex=mysql\\.slave_.* # table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2) #canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch # table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2) #canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch # mq config # 配置 canal.mq.topic 属性,指定 Canal 将数据变更事件发送到消息队列时所使用的主题名称。 # canal.mq.topic=canal_crm # dynamic topic route by schema or table regex #canal.mq.dynamicTopic=mytest1.user,topic2:mytest2\\..*,.*\\..* #canal.mq.dynamicTopic=dt:dt\\..*,dt:dt_.*\\..* # Canal 将根据一定的规则动态生成主题名称,并将数据变更事件发送到对应的动态主题中。 # 将以 dt_test. 开头的表名映射到MQ名为 canal 的 topic 上,多个已逗号分割,如上 canal.mq.dynamicTopic=canal:dt_test\\..* canal.mq.partition=0 # hash partition config #canal.mq.enableDynamicQueuePartition=false #canal.mq.partitionsNum=3 #canal.mq.dynamicTopicPartitionNum=test.*:4,mycanal:6 #canal.mq.partitionHash=test.table:id^name,.*\\..* #################################################
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
创建rabbitMQ队列及关联关系
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
alse
#canal.mq.partitionsNum=3
#canal.mq.dynamicTopicPartitionNum=test.:4,mycanal:6
#canal.mq.partitionHash=test.table:id^name,.\…*
#################################################
### 创建rabbitMQ队列及关联关系
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)**
[外链图片转存中...(img-sgnhkirt-1713194678435)]
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

