
- 1java毕业设计——基于JSP+sqlserver的销售管理系统设计与实现(毕业论文+程序源码)——销售管理系统_jsp销售管理中心有网状图
- 2PyQt5之QObject API学习_pyqt5receivers
- 3微信小程序获取手机号隐私权限问题处理方案_【小程序负责人手机号码】不允许被多人使用
- 4算法在计算机专业的应用案例,多维优化案例推理检索算法研究计算机应用技术专业论文.docx...
- 5云计算数据中心(一)_计算中心 csnd
- 6Vue v-show命令_vue isshow
- 7Go 开发者调查 2024 年结果(AI相关)
- 8Git实用篇---从零入门到实战_学习git从入门到实践
- 9vue将页面导出pdf。_vue将长网页转为pdf并显示
- 10mapreduce是什么_mapreduce 漫画
Transformer代码从零解读【Pytorch官方版本】_transformer 源码分析
赞
踩
1、Transformer大致有3大应用
1、机器翻译类应用:Encoder和Decoder共同使用,
2、只使用Encoder端:文本分类BERT和图片分类VIT,
3、只使用Decoder端:生成类模型,
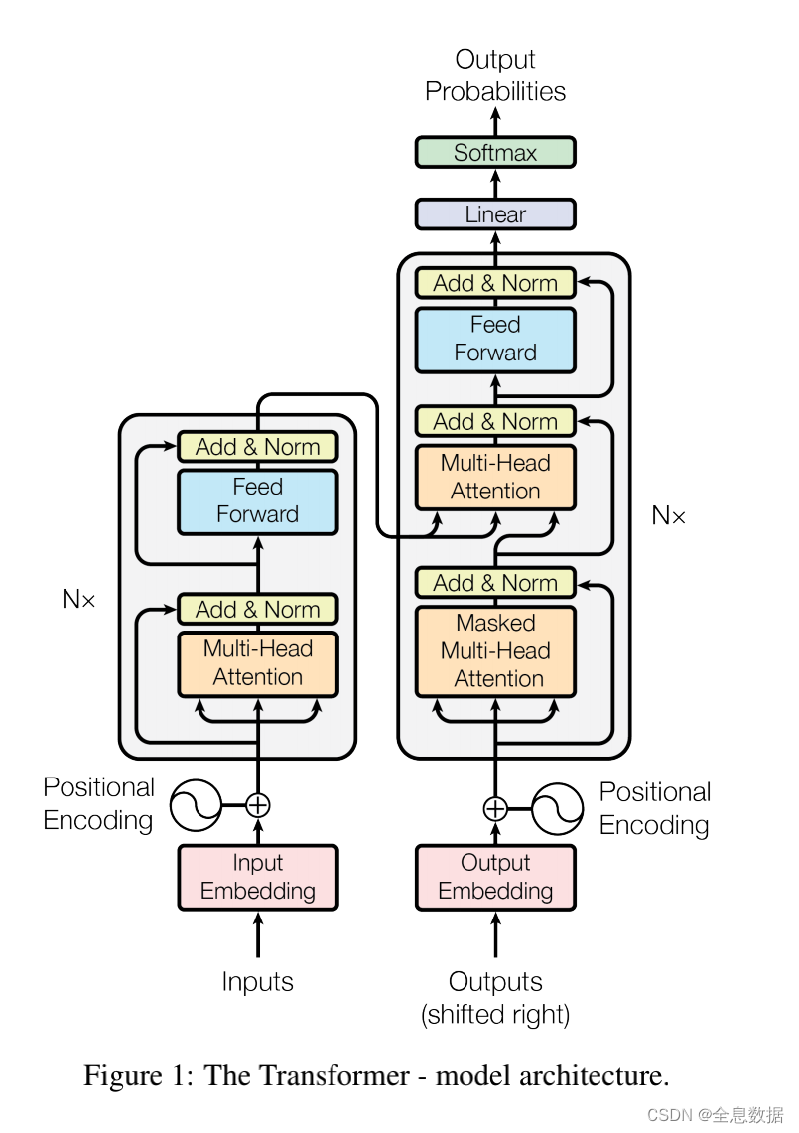
2、Transformer的整体结构图
Transformer整体结构有2个输入,1个输出,具体过程可参考这个链接:详情请点击,
如下图,左边是Encoder,右边是Decoder,2个输入分别是Encoder的输入,Decoder的输入,
先看左边的Encoder,输入经过词向量层和位置编码层,得到最终的输入,通过多头注意力机制和前馈神经网络得到Encoder的输出,该输出会与Decoder进行交互,
再看右边的Decoder,输入经过词向量层和位置编码层,得到最终的输入,通过掩码注意力机制,然后交互注意力机制与Encoder的输出做交互,Encoder的输出做K矩阵、V矩阵,Decoder的值做Q矩阵,再经过前馈神经网络层,得到Decoder的输出,
如下图一共有2个输入,分别是“我爱你”和“S I LOVE YOU”,“我爱你”这个句子是3个token,token翻译成词元,“S I LOVE YOU”中的 S 是特殊字符,“I LOVE YOU E”是解码端的真实标签,与输出结果计算损失,
解码端是没法并行的,因为输入【S】,输出【I】,然后输出的【I】作为下一阶段的输入,这一次的输入取决于上一次的输出,所以解码端无法并行,
但是为了加快训练速度和收敛速度,我们使用Teacher forcing,就是把真实标签作为一种输入,把当前输入单词后面所有的单词全部 mask 掉,

“ich mochte ein bier P”是编码端的德语输入,“S i want a beer"是解码端的英语输入,“i want a beer E”是解码端的真实标签,一般在训练时为了加快训练速度,需要增加batch-size,

3、如何处理batch-size句子长度不一致问题
以中文为例,batch-size为4,如下图所示每一行句子代表每个batch-size中的第一个句子,代表Encoding的输入,Decoding的输入和标签值下图已省略,
1个batch在被模型处理的时候,为了加快速度常使用矩阵的方式来计算,但是如果一个batch中句子长度不一致,就组不成一个有效的矩阵,为了解决这个问题,一个常规的操作就是给每个句子设置 max-length,

假设设置max-length为8,句子的长度大于8的删除,小于8的用P替换,如下图,
需要注意的是,PAD这种方法不仅用在在Encoder的输入,也用在Decoder的输入,

位置编码公式:
P
E
(
p
o
s
,
2
i
)
=
s
i
n
(
p
o
s
/
1000
0
2
i
/
d
m
o
d
e
l
)
PE(pos,2i)=sin(pos/10000^{2i/d_{model}})
PE(pos,2i)=sin(pos/100002i/dmodel)
P
E
(
p
o
s
,
2
i
+
1
)
=
c
o
s
(
p
o
s
/
1000
0
2
i
/
d
m
o
d
e
l
)
PE(pos,2i+1)=cos(pos/10000^{2i/d_{model}})
PE(pos,2i+1)=cos(pos/100002i/dmodel)
两个共有的部分:
e
−
(
2
i
)
/
d
m
o
d
e
l
∗
l
o
g
(
10000
)
=
1
/
1000
0
2
i
/
d
m
o
d
e
l
e^{-(2i)/d_{model}*log(10000)}=1/10000^{2i/d_{model}}
e−(2i)/dmodel∗log(10000)=1/100002i/dmodel,这里POS代表的是每个字符在整个句子中的索引,512是整个句子最大长度,和2i对应的Embedding维度512要区分开,位置编码和Embedding相加即可得到整个输出的内容,
位置编码公式代码如下:
class PositionalEncoding(nn.Module): def __init__(self, d_model, dropout=0.1, max_len=5000): super(PositionalEncoding, self).__init__() # 位置编码的实现其实很简单,直接对照着公式去敲代码就可以,下面这个代码只是其中一种实现方式; # 从理解上来讲,需要注意的就是偶数和奇数在公式上有一个共同部分,我们使用log函数把次方拿下来,方便计算; # pos代表的是单词在句子中的索引,这点需要注意;比如max_len是128个,那么索引就是从0,1,2,...,127 # 假设我的d_model是512,2i那个符号中i从0取到了255,那么2i对应取值就是0,2,4,...,510 self.dropout = nn.Dropout(p=dropout) pe = torch.zeros(max_len, d_model) position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # shape:[max_len,1] div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)) # shape:[d_model/2] pe[:, 0::2] = torch.sin(position * div_term) # 这里需要注意的是pe[:, 0::2]这个用法,就是从0开始到最后面,步长为2,其实代表的就是偶数位置 pe[:, 1::2] = torch.cos(position * div_term) # 这里需要注意的是pe[:, 1::2]这个用法,就是从1开始到最后面,步长为2,其实代表的就是奇数位置 # 上面代码获取之后得到的pe.shape:[max_len, d_model] # 下面这个代码之后,我们得到的pe形状是:[max_len, 1, d_model] pe = pe.unsqueeze(0).transpose(0, 1) self.register_buffer('pe', pe) # 定一个缓冲区,其实简单理解为这个参数不更新就可以 def forward(self, x): """ x: [src_len, batch_size, d_model] """ x = x + self.pe[:x.size(0), :] return self.dropout(x)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
为什么需要告诉后面模型哪些位置被PAD填充
注意力机制公式:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dk QKT)V
下图是 Q K T QK^T QKT相乘后的矩阵,还没有经过softmax计算,表示每个单词和其他所有单词的相似性,应该能看到不应该把PAD参与计算,

如何去掉PAD信息?利用符号矩阵,不是PAD置为0,是PAD的置为1,

代码:
把PAD为0的元素置为True,
# 比如说,我现在的句子长度是5,在后面注意力机制的部分,我们在计算出来QK转置除以根号之后,softmax之前,我们得到的形状
# len_input * len*input 代表每个单词对其余包含自己的单词的影响力
# 所以这里我需要有一个同等大小形状的矩阵,告诉我哪个位置是PAD部分,之后在计算计算softmax之前会把这里置为无穷大;
# 一定需要注意的是这里得到的矩阵形状是batch_size x len_q x len_k,我们是对k中的pad符号进行标识,并没有对k中的做标识,因为没必要
# seq_q 和 seq_k 不一定一致,在交互注意力,q来自解码端,k来自编码端,所以告诉模型编码这边pad符号信息就可以,解码端的pad信息在交互注意力层是没有用到的;
def get_attn_pad_mask(seq_q, seq_k):
batch_size, len_q = seq_q.size()
batch_size, len_k = seq_k.size()
# eq(zero) is PAD token
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # batch_size x 1 x len_k, one is masking
return pad_attn_mask.expand(batch_size, len_q, len_k) # batch_size x len_q x len_k
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
4、MultiHeadAttention(多头注意力机制)
如下图,batch-size为1,src_len为2(即有2个单词), d m o d e l d_{model} dmodel为4,

代码:
class MultiHeadAttention(nn.Module):
def __init__(self):
super(MultiHeadAttention, self).__init__()
# 输入进来的QKV是相等的,我们会使用映射linear做一个映射得到参数矩阵Wq, Wk, Wv
self.W_Q = nn.Linear(d_model, d_k * n_heads)
self.W_K = nn.Linear(d_model, d_k * n_heads)
self.W_V = nn.Linear(d_model, d_v * n_heads)
self.linear = nn.Linear(n_heads * d_v, d_model)
self.layer_norm = nn.LayerNorm(d_model)
def forward(self, Q, K, V, attn_mask):
# 这个多头分为这几个步骤,首先映射分头,然后计算atten_scores,然后计算atten_value;
# 输入进来的数据形状: Q: [batch_size x len_q x d_model], K: [batch_size x len_k x d_model],声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/正经夜光杯/article/detail/838758Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

