
- 12021计算机浙软华师保研经验帖_华东师范大学计算机保研经验贴
- 2Python操作文件的读取和写入,详解和案例介绍_python文件读写保存操作的示例代码
- 3Auto.js安卓脚本自动化app的代码语句大全_autojs脚本代码大全
- 4Pytorch/paddle单机多卡RTX 3060×2的Ubuntu深度学习训练环境配置+代码模板+常见问题解决_paddle 多显卡
- 5Gitlab介绍
- 6通透理解 Elasticsearch 的六大顶级核心应用场景_es全文检索 应用场景
- 7prim算法求最小生成树
- 8关于uni-app中云打包成apk包在手机上运行无法使用uni.chooseLocation获取定位_uniapp 离线打包资源后权限不见了
- 9Linux上安装sqlserver2017_linux sql server2017数据库下载
- 10Win11上安卓设备与MTKClient连接失败,问题汇总,终极方法
[python+nltk] 自然语言处理简单介绍和NLTK坏境配置及入门知识(一)
赞
踩
此篇文章主要参考书籍《Natural Language Processing with Python》Python自然语言处理,希望对大家有所帮助。 书籍下载地址:
官方网页版书籍:http://www.nltk.org/book/
CSDN下载地址:http://download.csdn.net/detail/eastmount/8601705
一. 自然语言处理简单介绍
所谓“自然语言”,是指人们日常交流使用的语言,如英语、印地语随着不断演化,很难用明确的规则来刻画。
从广义上,“自然语言处理”(Natural Language Processing简称NLP)包含所有计算机对自然语言进行的操作,从最简单的通过计数词出现的频率来比较不同的写作风格到最复杂的完全“理解”人所说的话。
基于NLP的技术应用日益广泛,如手机和手持电脑支持输入法联想提示(predictive text)和手写识别、网络搜索引擎能搜到非结构化文本中的信息、机器翻译能把中文文本翻译成西班牙文等。
通过使用Python程序设计语言和自然语言工具包(NLTK,Natural Language Toolkit)的开源函数库,本书包括自然语言处理的实际经验。本书可以自学,也可以作为自然语言处理或计算机语言学课程的教科书,或是人工智能、文本挖掘、语料库语言学课程的补充读物。
本书为什么使用Python呢?
Python是一种简单功能强大的变成语言,非常适合处理语言数据。
作为解释语言,Python便于交互式变成;作为面向对象语言,Python允许数据和方法被方面的封装和重用。作为动态语言,Python允许属性等程序运行时才被添加到对象,允许变量自动类型转换,提高开发效率。Python自带强大的标准库,包括图像编程、数值处理和网络连接等组件。
章节介绍包括:如何使用很短的Python程序分析感兴趣的文本信息(1-3章)、结构化程序设计章节(第4章)、语言处理的主要内容:标注、分类和信息提取(5-7章)、探索分析句子、识别句法结构和构建表示句意的方法(8-10章)、最后一章讲述如何有效管理语言数据(第11章)。

二. NLTK环境配置
首先安装Python,可在官网https://www.python.org/下载。
Python对用户友好的一个方式是你可以在交互式解释器运行你的程序,通过一个简单的交互式开发坏境(Interactive DeveLopment Environment,简称IDLE)的图形接口访问Python解释器。后面配置NLTK就是在IDLE环境下进行。
然后下载NLTK,资料如下:
官网链接:http://www.nltk.org/
安装步骤:http://www.nltk.org/install.html
下载地址:https://pypi.python.org/pypi/nltk
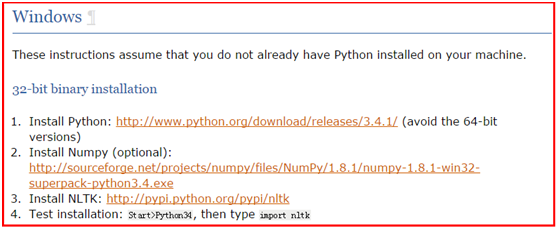
由于我的电脑是windows系统,安装的步骤如下图所示:
- >>> import nltk
- >>> nltk.download()
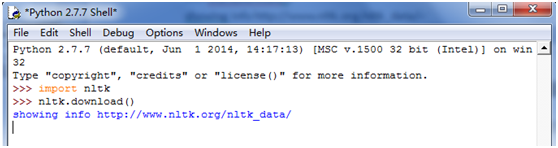
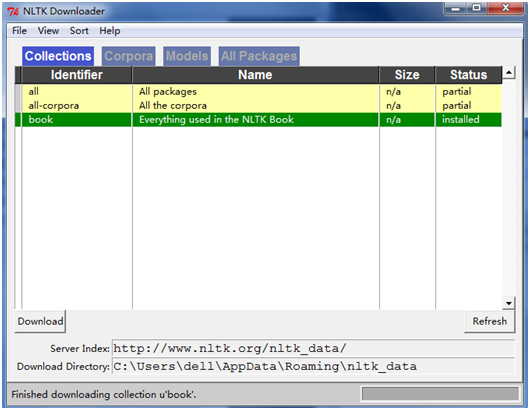
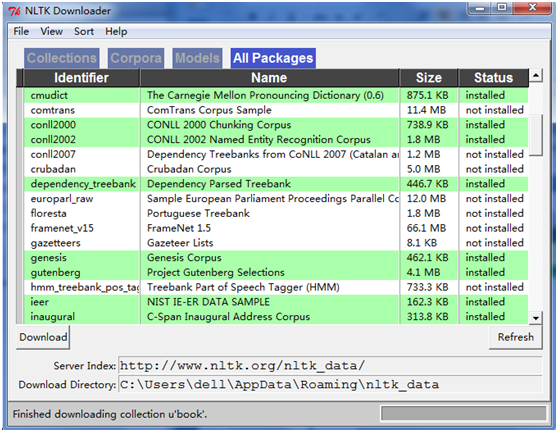
下载NLTK图书集:使用nltk.download()浏览可用的软件包,下载器上的Collections选项卡显示软件包如何被打包分组;选择book标记所在行,获取本书的例子和联系所需的全部数据。可参考资料。

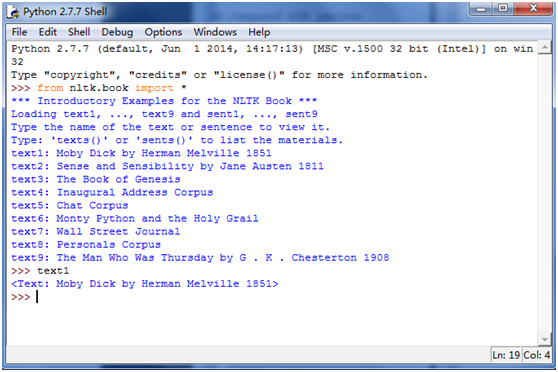
当数据下载到机器后,你可以使用Python解释器加载其中一些,在Python提示符后输入”from nltk.book import *”告诉解释器从NLTK的book加载所有的文本,输入text1找到相应的文本名字。如下图所示:
三. 自然语言处理常用方法
1.concordance函数
功能:搜索文本,在text1中输入函数concordance(),查找《白鲸记》中的词语monstrous。
>>> text1.concordance("monstrous")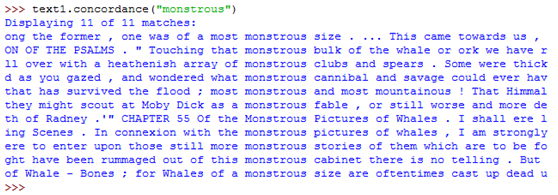
2.similar函数
功能:通过函数similar()可以查询括号中相关词在上下文中相似的词语。词语索引使我们看到此的上下文,如monstrous出现的上下文,如the_pictures和the_size。
>>> text1.similar("monstrous") 可以发现与monstrous(丑陋的)相似的大部分都是形容词:curious(好奇的)、impalpable(无形的)、perilous(危险的)、lazy(懒惰的)等。

我的怀疑应该是和上下文语义结构有关,却没有“理解”它具体的词义。如:the Monstrous Pictures、more monstrous stories、a monstrous size。很显然monstrous充当修饰名词的形容词结构——冠词+monstrous+名词。
3.common_contexts函数
功能:函数common_contexts允许我们研究两个或两个以上的词共同的上下文,如monstrous和very。
- >>> text2.common_contexts(["monstrous","very"])
- a_pretty is_pretty a_lucky am_glad be_glad
必须用方括号和圆括号把这些词括起来,中间用逗号分隔。个人理解:似乎similar是与之相关的词语,而common_contexts是相似的结构。

4.generate函数
功能:通过函数generate()产生一些随机文本自动生成文章。
>>> text3.generate()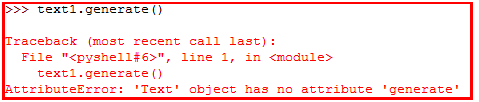


总结:最后希望这篇入门文章对大家有所帮助,如果有错误或不足之处,亲海涵!后面还会深入的讲解自然语言处理和Python挖掘相关知识;同时包括NLTK的更广泛应用及理解。建议大家购买正版书籍阅读,挺不错的书籍《Python自然语言处理》作者:Steven Bird, Ewan Klein & Edward Loper。

