
- 1Java自带的GUI性能监控工具Jconsole以及JisualVM简介_jconsole能看fgc次数和时间吗
- 2Apollo分布式配置中心在java的简单实现_怎么使用java代码修改apollo配置
- 3用AidLux跑老人摔倒检测项目,看AI助老轻松落地_ai 预判摔倒训练
- 4照片动起来的软件叫什么名字?快把这些软件收好_照片背景动态的软件叫什么m开头
- 5AI 文本转视频(视频生产工具分享)_ai 根据脚本生产视频
- 6骆驼式命名法_printemployeepaychecks
- 7mysql数据库创建及用户添加和权限管理_在mysql数据库中添加用户访问权限
- 8鸿蒙Harmony应用开发—ArkTS声明式开发(容器组件:Row)_arkts组件 > row
- 9推荐开源项目:深度网络的集成梯度解释(Integrated Gradients)
- 10git,svn,github,码云之间联系区别_svnhub
Flink系列四:Flink中并行度、算子链、任务槽详解_flink的并行度
赞
踩
一、并行度(Parallelism)
1、并行子任务和并行度
当要处理的数据量非常大时,我们可以把一个算子操作,“复制”多份到多个节点,数据来了之后就可以到其中任意一个执行。这样一来,一个算子任务就被拆分成了多个并行的“子任务”(subtasks),再将它们分发到不同节点,就真正实现了并行计算。
在Flink执行过程中,每一个算子(operator)可以包含一个或多个子任务(operator subtask),这些子任务在不同的线程、不同的物理机或不同的容器中完全独立地执行。
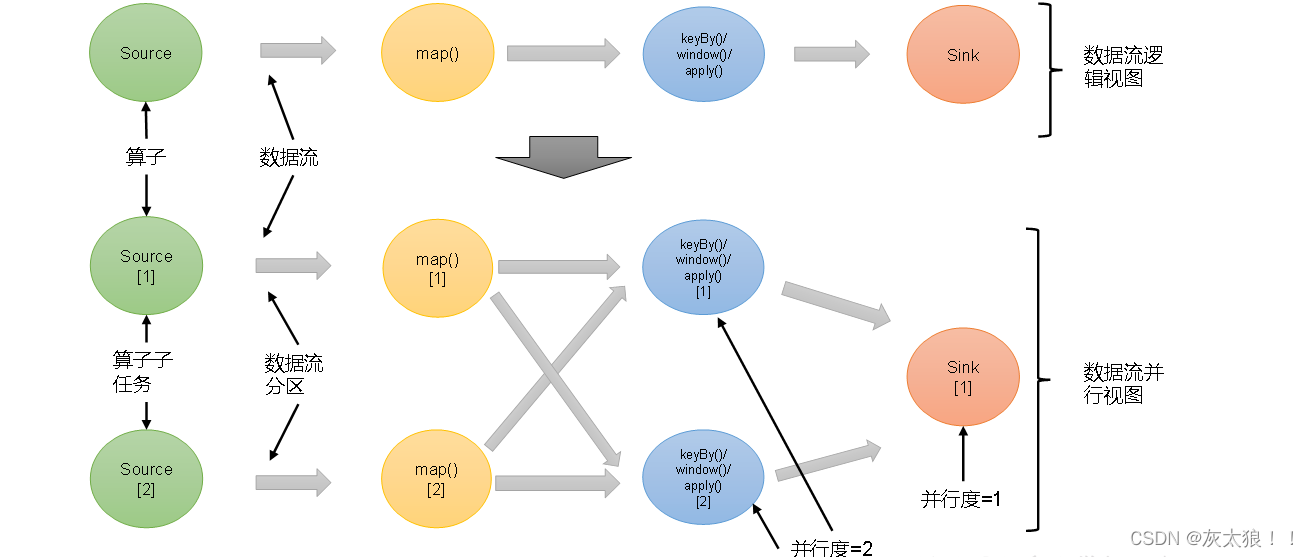
一个特定算子的子任务(subtask)的个数被称之为其并行度(parallelism)。这样,包含并行子任务的数据流,就是并行数据流,它需要多个分区(stream partition)来分配并行任务。一般情况下,一个流程序的并行度,可以认为就是其所有算子中最大的并行度。一个程序中,不同的算子可能具有不同的并行度。
例如:如上图所示,当前数据流中有source、map、window、sink四个算子,其中sink算子的并行度为1,其他算子的并行度都为2。所以这段流处理程序的并行度就是2。
2、并行度的设置
2.1 代码中设置
2.1.1 算子单独设置并行度
stream.map(word -> Tuple2.of(word, 1L)).setParallelism(2);
这种方式设置的并行度,只针对当前算子有效
2.1.2 全局设定并行度
直接调用执行环境的setParallelism()方法
env.setParallelism(2);
这样代码中所有算子,默认的并行度就都为2了。我们一般不会在程序中设置全局并行度,因为如果在程序中对全局并行度进行硬编码,会导致无法动态扩容。
这里要注意的是,由于keyBy不是算子,所以无法对keyBy设置并行度。
2.2 命令行提交时设置
在使用flink run命令提交应用时,可以增加-p参数来指定当前应用程序执行的并行度,它的作用类似于执行环境的全局设置。
以在yarn的会话模式为例:
flink run -t yarn-session -p 3 -Dyarn.application.id=application_1717039073374_0009 -c com.shujia.flink.state.Demo5ExactlyOnceSInkKafka flink-1.0.jar
如果我们直接在Web UI上提交作业,也可以在对应输入框中直接添加并行度。
2.3 配置文件中设置
直接在集群的配置文件flink-conf.yaml中直接更改默认并行度:
parallelism.default: 2
在没有指定并行度的时候,就会采用配置文件中的集群默认并行度1
3、并行度的优先级
优先级:算子后指定>env(全局指定)>命令行指定>配置文件指定
如果不指定并行度,默认并行度就是当前机器的CPU核心数。
二、 算子链(Operator Chain)
1、算子间的数据传输
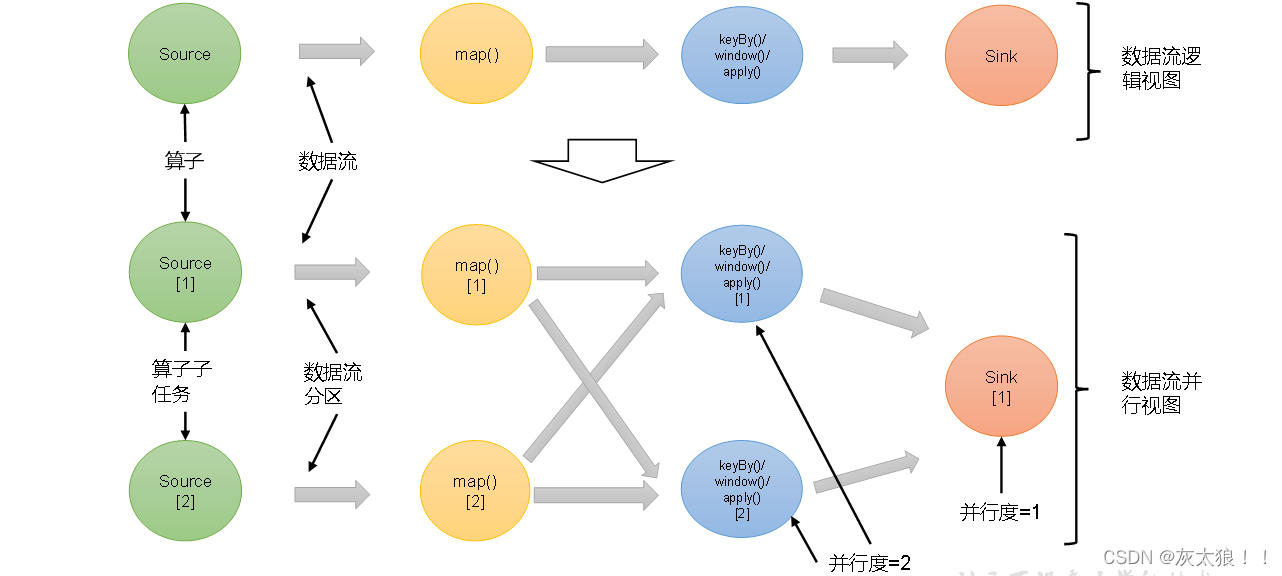
一个数据流在算子之间传输数据的形式可以是一对一(one-to-one)的直通(forwarding)模式,也可以是打乱的重分区(redistributing)模式,具体是哪一种形式,取决于算子的种类。
(1)一对一(One-to-one,forwarding)
这种模式下,数据流维护着分区以及元素的顺序。比如图中的source和map算子,source算子读取数据之后,可以直接发送给map算子做处理,它们之间不需要重新分区,也不需要调整数据的顺序。这就意味着map 算子的子任务,看到的元素个数和顺序跟source 算子的子任务产生的完全一样,保证着“一对一”的关系。map、filter、flatMap等算子都是这种one-to-one的对应关系。这种关系类似于Spark中的窄依赖。
(2)重分区(Redistributing)
在这种模式下,数据流的分区会发生改变。比如图中的map和后面的keyBy/window算子之间,以及keyBy/window算子和Sink算子之间,都是这样的关系。每一个算子的子任务,会根据数据传输的策略,把数据发送到不同的下游目标任务。这些传输方式都会引起重分区的过程,这一过程类似于Spark中的shuffle。
2、合并算子链
2.1 算子链理解
在Flink中,并行度相同的一对一(one to one)算子操作,可以直接链接在一起形成一个“大”的任务(task),这样原来的算子就成为了真正任务里的一部分,如下图所示。每个task会被一个线程执行。这样的技术被称为“算子链”(Operator Chain)。
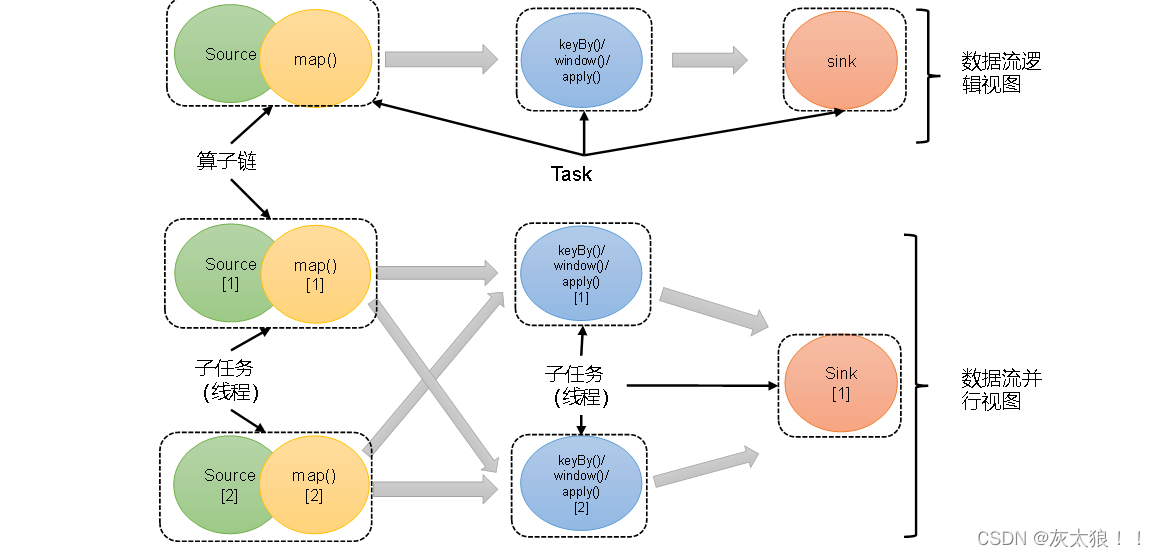
上图中Source和map之间满足了算子链的要求,所以可以直接合并在一起,形成了一个任务;因为并行度为2,所以合并后的任务也有两个并行子任务。这样,这个数据流图所表示的作业最终会有5个任务,由5个线程并行执行。
将算子链接成task是非常有效的优化:可以减少线程之间的切换和基于缓存区的数据交换,在减少时延的同时提升吞吐量。
2.2 算子链的设置
Flink默认会按照算子链的原则进行链接合并,如果我们想要禁止合并或者自行定义,也可以在代码中对算子做一些特定的设置:
// 禁用算子链
.map(word -> Tuple2.of(word, 1L)).disableChaining()
// 从当前算子开始新链
.map(word -> Tuple2.of(word, 1L)).startNewChain()
三、任务槽(Task Slots)
1、概念
Flink中每一个TaskManager都是一个JVM进程,它可以启动多个独立的线程,来并行执行多个子任务(subtask)。
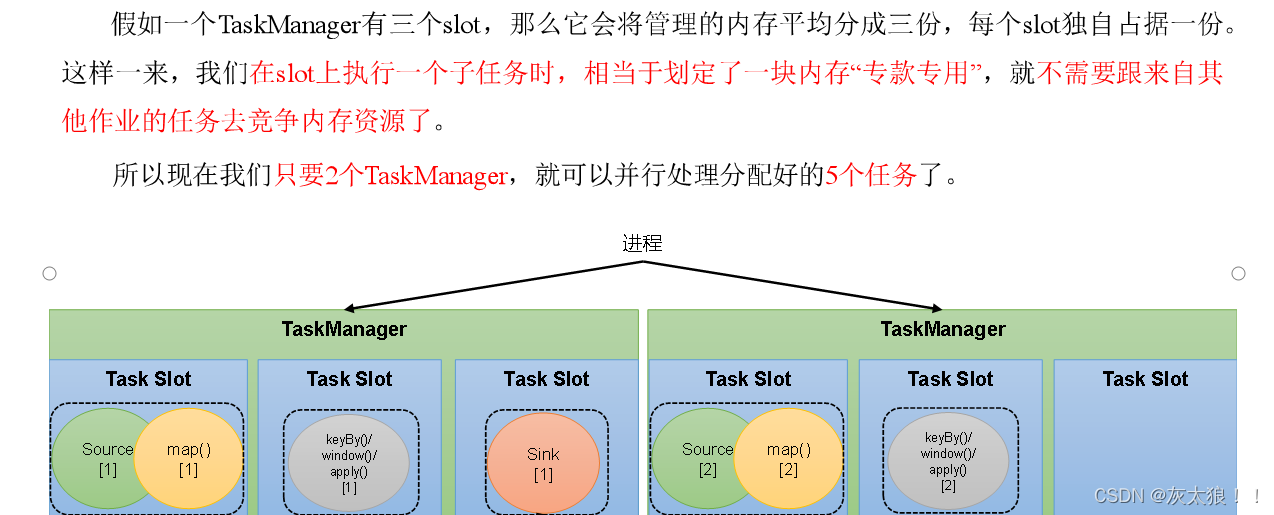
很显然,TaskManager的计算资源是有限的,并行的任务越多,每个线程的资源就会越少。那一个TaskManager到底能并行处理多少个任务呢?为了控制并发量,我们需要在TaskManager上对每个任务运行所占用的资源做出明确的划分,这就是所谓的任务槽(task slots)。
每个任务槽(task slot)其实表示了TaskManager拥有计算资源的一个固定大小的子集。这些资源就是用来独立执行一个子任务的。
2、图解
3、任务槽数量的设置
可以在flink-conf.yaml中设置任务槽数量,默认是1个slot
taskmanager.numberOfTaskSlots: 3
4、共享任务槽
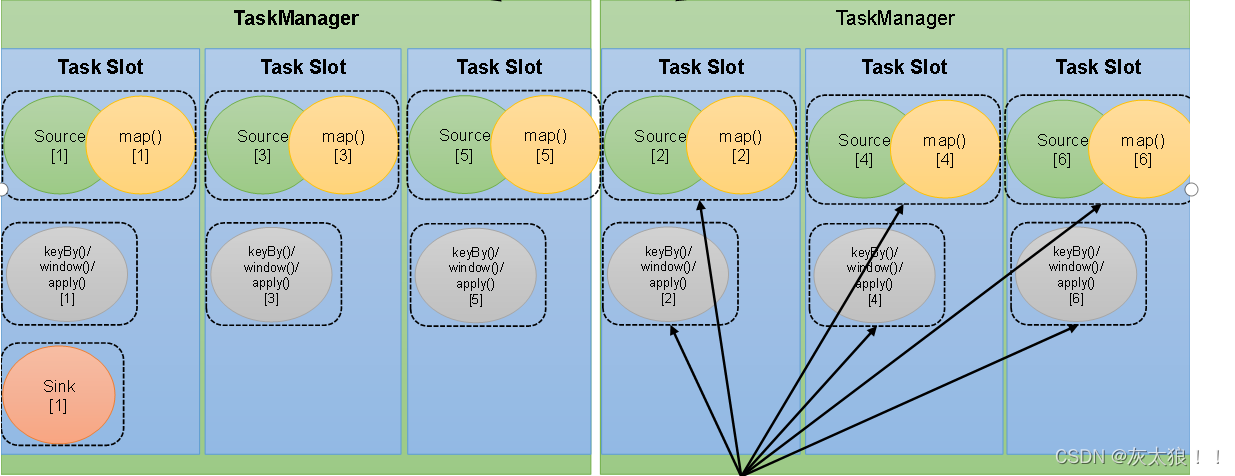
在同一个作业中,对于不同任务节点(算子)的并行子任务,就可以放到同一个slot上执行
5、slot共享组
Flink默认是允许slot共享的,如果希望某个算子对应的任务完全独占一个slot,或者只有某一部分算子共享slot,我们也可以通过设置“slot共享组”手动指定:
.map(word -> Tuple2.of(word, 1L)).slotSharingGroup("1");
这样,只有属于同一个slot共享组的子任务,才会开启slot共享;不同组之间的任务是完全隔离的,必须分配到不同的slot上。在这种场景下,总共需要的slot数量,就是各个slot共享组最大并行度的总和。
四、总结



