
- 1史上最详细的PyCharm安装教程,小白建议收藏!
- 2AI人工智能核心算法原理与代码实例讲解:智能机器
- 3铁路智能化巡检,RFID电子锁剪锁报警保障铁路设备安全
- 4一份网络攻防渗透测试的学习路线,不藏私了_学渗透应该先写什么
- 5纯血鸿蒙APP适配已超4000款,开发者们距离“薪”篇章不远了!_纯鸿蒙应用app有哪些
- 6华为仓颉|新一代高性能编程语言_ubuntu如何按照仓颉编程语言进行编程
- 7SQL中in和not in用法_数据库not in的用法
- 8值得推荐的13款可视化软件,快收藏!
- 9千亿大模型来了!通义千问110B模型开源!_通义还发布开源模型qwen1.5-110b
- 10获取C#WPF中的ComboBox_c# combox wpf
浅谈人工智能_弱人工智能是拟人吗
赞
踩
目录
为啥很多人不懂人工智能
人工智能这么火,但是很多人不了解什么是人工智能,不了解相关的概念,原因有三个:
- 觉得对自己没用:人工智能技术所包含的思想对每个人都极有用,但可惜的是大多数人都“不知道自己应该知道这些知识”
- 专业知识门槛高
- 很难通过简单的例子以故事的形式将给大众听,知识被交流的前提是互相拥有共同的经验
根据上述第一点原因我们可以得出结论,搞懂人工智能是对我们有意的,不仅可以让我们了解这个行业进入这个行业,拔高个人技能层次,更可以通过反思人类智能,改善我们的思考过程。
如何入门人工智能呢?人工智能是非常复杂的一个知识系统,无论多复杂的知识系统拆解起来就是这三要素:概念、概念之间的关系、利用概念和关系解决问题的方法。
概念:

什么是人工智能
人工智能其实就是模拟人的行为,俗称拟人。
人工智能按照阶段可分为强人工智能和弱人工智能,目前我们所处的阶段是弱人工智能。
弱人工智能只能处理特定任务,比如人脸识别识别不了猫狗
强人工智能是真正意义上的智能,但是非常遥远,谁也不知道什么时候到来,可能就是类似科幻电影里技术发展突然出现奇点跨越,机器产生自主意识,正真的就像一个人存在了,但是会引来伦理和安全等一些列问题。
什么是机器学习
机器学习就是根据已有的经验(数据 data),总结(算法 algorithm)规律(模型 model),用于预测(predict)未知的数据。
数据+算法=模型====>预测
数据
数据的类型多样:文本、图像、声音,最终会处理成数字形式带入算法训练,数据处理的过程叫做特征工程。
算法
算法就是方法的意思,我们程序员可以认为它是一个函数,或者学生可以认为他是一个公式,比如二元一次方程(当然实际要复杂的多),例如y=ax+b。
模型
模型是二元一次方程的参数a和b。
模型的好与坏,取决于数据质量是不是好(特征工程),取决于设定的算法是不是合适(不同场景需要设计不同的算法)。
预测的任务分类
预测按任务类型分,分为分类任务和回归任务。
分类任务模型输出的是离散型数据,回归任务模型输出的是连续性的数据。离散型数据例如(0,1)、对错、高中低、男女,连续性的比如收入、价格、温度。
什么是学习什么是训练
从特殊到一般的归纳过程,是学习。
比如你家的猫有四条腿,邻居家的也有四条腿,那么我们人类就会归纳出一个结论,世界上的猫都是四条腿,从数据到规律的归纳过程就是学习的过程。但是有一个误区经常大家分不清楚,比如你只给机器数据没有告诉它方法他是总结不出规律的,比如还拿猫的腿这件事来说,你只提供给机器100个猫都是四条腿,机器能做的只是存储,超出这100个猫后它猜不到第101个猫是不是四条腿。再举个例子,你看到张三花15元买了10斤西瓜,李四30元买了20斤西瓜,很快就归纳出西瓜重量与总价的关系是Y=1.5X,即西瓜1.5元/斤。但是机器只能储存所有西瓜重量和对应的总价情况,无法自己归纳出Y=1.5X这样的函数关系,除非你先告诉机器这件事是一个二元一次方程就可以解决的,然后机器可以基于数据找规律知道参数应该是多大。
这里提一下大数据和人工智能的区别和关系,人工智能依赖大数据训练,从海量数据中找解决问题的规律,而大数据实际上是提供了一种数据吞吐的能力,从应用角度上来说,大数据主要体现在快速检索应用上,就是数据库里有的系统可以提供结果数据库里没有的系统猜不出来结果,而人工智能的应用是预测,主要表现在数据库里没有,但是系统知道数据规律,可以根据规律返回给用户系统猜出来的可能性最大的结果。
回过头来做一个小总结,所谓学习,是指通过你所见过的例子归纳总结规律的过程,目的是利用规律解决你没有见过的类似问题,以此来抵御千变万化的外界环境伴随的不确定性,从而维持自身存活状态的确定性。正因为人有限的一生不可能穷尽所有情况,所以才需要利用学习,把有限的例子总结成规律,去解决无限的相似问题。人类为什么要进化出后天的学习能力?是因为靠先天植入的本能不足以应对环境中千变万化的问题,这是一种更高级的能力。学习还可以让人将海量的信息压缩成规律储存起来,大幅节省大脑的储存空间。
而机器学习,就是想办法让机器拥有上述自主归纳规律的能力,也叫拟合能力(上边说到的拟人),这里的规律往往是一种函数或者映射关系,从而让机器能够解决没有见过的问题。
机器学习,基于经验数据,基于认为设定的方法的。学习的过程就是训练的过程,机器从经验数据中找规律,也就是找到合适的参数,最终要的模型就是参数的集合所构建的公式。使用的时候就是将新的数据带入已经训练好的公式里得出的结果就是预测的结果。
机器如何实现学习
一些名词
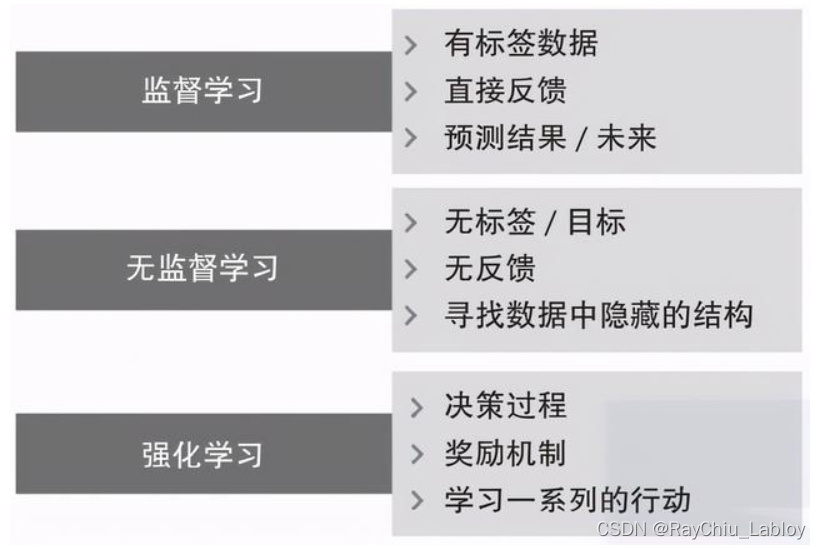
首先说机器学习按照任务划分还可以分为,监督学习、非监督学习。
拿监督学习举例来认识一些名词,有一个鸢尾花分类的数据集如下图所示:

样本:上图中包括特征和标签的每一行数据就是一个样本。
数据集(DataSet):用于训练和测试模型的原始数据。数据集通常都是被处理为一张大宽表。
训练集(training set):主要用于训练模型的数据集。训练集通常是原始数据的2/3-3/4.
测试集(testing set):主要用于验证模型性能好坏的数据集。
训练集和测试集那么通常是从原始数据集中采用分层抽样或者随机抽样的方式来获取的。
输入数据(input data):测试集中除去目标列的数据。用X表示,通常是m*n的矩阵
输出数据(output data):数据集给模型的输出结果。用y_hat表示,通常是m*1矩阵。
标签(label)或者是类标签(class label):模型预测的目标列---真实数据。用y来表示,通常是m*1。
简单的学习场景:一元线性回归
我们拿上边买西瓜的例子来讲,凭经验我们知道这是一个回归任务,而且有两个变量,一个自变量一个因变量,整理一下思路我们发现解决这个问题的方法就是一个一元一次函数:y = ax +b
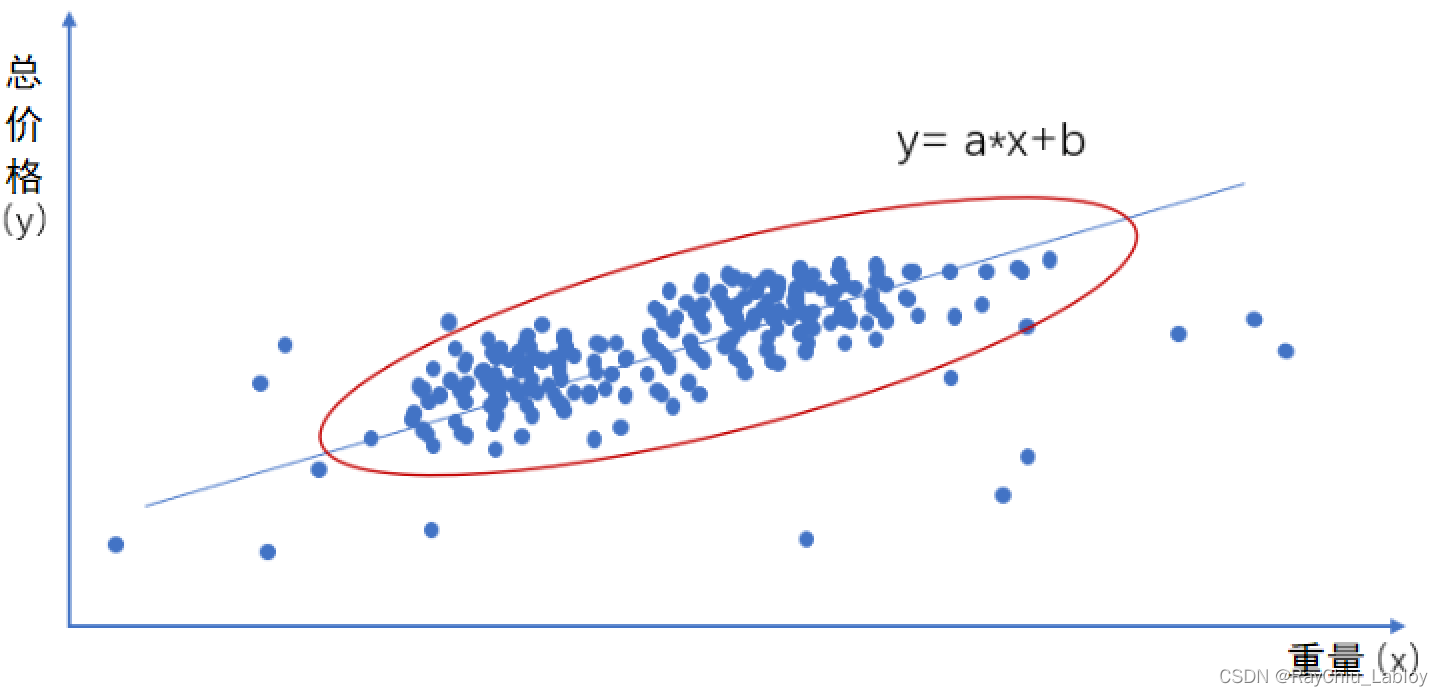
横坐标x为在市场上不同商家买到西瓜的重量,纵坐标y为对应的总价格,两者对应的关系大致上可以拟合成一条线,我们找到最优的这条线,那么就可以猜出下一次买不同重量的西瓜应该是多少钱了,也就是我们知道了市场上西瓜大致的价格是多少了
我们称这样的拟合一条直线的任务为:一元线性回归任务。
我们知道这是一个一元线性回归的任务了,剩下就是给机器提供数据,让机器找规律就行,我们可以把从市场上买西瓜的数据搜集来这里成下面的格式:
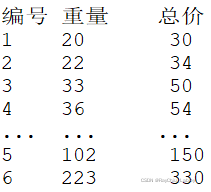
假象一下对应到上边坐标系图上,我们要做的是找到一条最优的线来拟合市场上的规律,怎么找到最优的线呢?
loss损失函数
实际情况是我们想得到的“线”不能够完全拟合市场数据,最好的情况就是尽量让误差最小化,从误差角度考虑肯定要综合所有样本和实际数据的误差,让误差和最小的线就是最优的线,根据这个思路我们可以得到一个总的Loss损失函数,

梯度下降
我们要做的就是求J在w和b在什么值的情况下最小,有两种计算方法,一种是解析式公式求解,一种是梯度下降,由于考虑到计算资源一般都是采用梯度下降算法,为什么能用梯度下降?因为我们是求的上式凸函数的极值。

机器将从Loss 函数曲线上的随机一个点开始求导数(即切线), 寻找的方向为梯度的反方向,即向着导数更接近0(即切线坡度更缓)的方向滑动,假设每次滑动的距离可以自定义,那么用不了多久,机器就可以尝试从随机点位A滑动到目标点位T,从而取得Loss函数的最小值。如果是多个变量,则分别求各个变量的偏导数,直至找出整体导数为零的Loss最低点,这个时候我们得到的那一组参数(a,b)就是最好的一组参数了,参数就是模型,带入前边已知的y = ax +b,ax+b就是我们模型的应用方式,来一组新的数据我们就可以得到一个预测结果y,这个y是最贴近市场规律的值。
补充一些概念
泛化能力:就是把参数模型应用到新的数据上“预测”表现能力如何,是评价模型是否 拥有“举一反三”的能力。
欠拟合:就是训练学习的时候loss就很大,没学会,那自然新数据也预测不好
过拟合:就是训练学习的时候loss很小了,但是新数据的预测不好,没学通,泛化能力差。
复杂的学习场景
上边我们举例的是比较简单的线性回归场景,比较复杂的还有:
样本特征非常多
一元一次代表样本只有一个特征x,实际上机器学习一条样本会包含大量的特征或者组合特征,式子可能会成这样:Y=a1X1+a2X2+a3X3+a4X4+a5X5…
可能不是线性的场景
 |  |
实际的场景可能向上图的情况,或者其他更复杂的场景
输入和输出可能不是数值型

但不管形式怎么变,基本原理都一样。
深度学习
我们从计算机视觉的应用图像识别为例,介绍一下深度学习,其实大致还可以将深度学习想象成一个函数,一个很长的函数,把数据向量X输入进去就可以得到预测为每一类的概率,那对于图像识别来说会面临三个问题。
如何用数字表达图像数据
上文提到训练的输入数据都是数值型,对于图像我们怎么作为输入灌入算法学习?图像其实就是由一个一个像素组成的嘛,
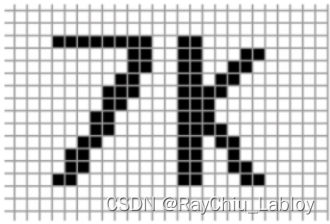
最简单的方式就是把图像拉伸成一条由像素点组成的向量。

如何构建函数
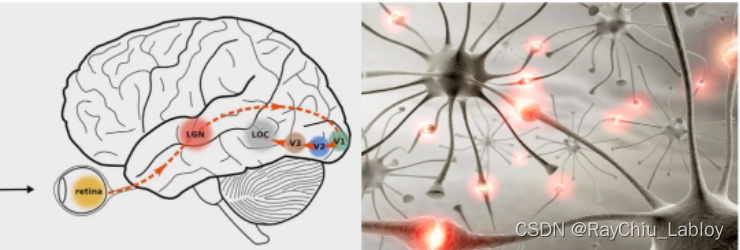
因为我们并不知道该构建什么样的函数去解决这个问题,所以科学家想到模仿人类的图像识别过程。人类看到并识别物体的原理,是通过物体发出或者反射的光进入眼睛,然后投影到视网膜上成像,视网膜上的感光细胞会将图像转化为神经冲动传递到大脑,大脑最初接受视觉信号的神经皮层叫做初级皮层V₁,它所获得的是一大堆基础的点、线。随后,V₁皮层会把处理过的信号传递到V₂皮层,V₂皮层会得到图像的角点、边缘、方向等信息;V₂皮层再次对信号进行处理,进入V₃皮层,在这里神经元会获得物体的轮廓、细节等信息…信号经过多个皮层的传递和不同感受野或粒度的特征提取,最终抽象出物体的特征表达,从而做出判断。
通过模仿这个过程,我们构建了神经网络结构,用数学方法模仿了这种多层神经元网络的链接方法,如下图全连接神经网络所示:

除了上图的全连接神经网络,还有两种常见的网络:卷积神经网络和循环神经网络,循环神经网络在语音识别和自然语言处理上用得比较多,这里不做过多介绍。
全连接神经网络
参考上图,结构上可分为三种,输入层、隐藏层、输出层。
其中最左侧就是输入层X,中间的每一层中每个圆圈代表一个神经元细胞,每个神经元细胞都从上一层细胞接受输入信息X,并将运算结果Y输出至下一层细胞,作为下一层细胞的X。每层细胞之间两两相连,例如细胞B2和上一层细胞的关系就是:B2=a1A1+a2A2+…+aNAN ,其中a是参数,每个A是上一层细胞的运算输出Y。通过每一层这样简单的运算,很多层链接起来,就可以生成无数种极其复杂的函数公式,这种被叫做全连接神经网络(fully connected neural network),其中神经元的层数越多,我们就说这个神经网络深度越深,也叫深度神经网络(deep neural network)。
然而我们具体应该设计多少层神经网络,每一层应该有多少个神经细胞,只能试,经验告诉我们网络越宽越深,计算的结果可能会越好(但也不一定),当然消耗的算力也就越大,系统稳定性下降,即十个人削十个苹果,效率和稳定性会上升,但十个人同时削一个苹果,则效率和稳定性急剧下降,有些小型的算法有10来层,大型的算法有1000多层,需要消耗大量的算力。
通过照猫画虎模拟大脑的神经,我们的全连接神经网络可以识别一些小的、简单的图片,如手写数字识别。

但是图片分辨率变大,或者图片变得很复杂时全连接神经网络的泛化能力就不够用了,这是就得用卷积神经网络了。
卷积神经网络
从上边全连接神经网络图中可以看到相邻两层之间,每个神经元要接收上一层每一个神经元的输出,对于图片来说相当于“胡子眉毛一把抓”,同时塞进全部信息去计算,计算量大,还抓不到重点。而人是通过扫描图上的一些特征来识别图像的,比如我们是通过识别鸟嘴、鸟翅膀、鸟眼睛、鸟爪子这些特征,来识别出一只鸟。因此后来的研究人员模拟这个过程提出了卷积神经网络CNN,

从上图中可以看到相邻层不再是全部连接,而是每个神经元接收上一层局部的输出信息,也就是每一个神经元的感受野只有一部份区域,并且靠近输入层的隐藏层提取的都是低级语义,类似边、角等基本轮廓,越靠近输出层的语义会更加高级。具体操作是定义了一个数学矩阵小方块,然后让小方块扫过整张图片,同时与每个被扫描的区域发生计算关系,计算后只输出一个数值给下一层神经元。
这是卷积神经网络最基本的组成单元之一卷积,另外还有一些池化、dropout等基本单元,这些组件像堆积木一样拼接就组成了卷积神经网络。

模型参数的训练
深度学习训练参数过程和上文中说到的线性回归思路类似,先准备一堆打好标签的图像数据分成训练集、验证集、测试集,具体就是人工给图像标记上哪一张图片是猫是狗或者是什么东西,然后让计算机通过这些训练集的这些例子找出里面的规律。微观层面就是通过回归计算和梯度下降法尝试出适合这套神经网络最优的参数,这个训练的过程,就是深度学习中的监督学习过程,训练后生成的参数确定的函数,就可以用于推断。
小插曲:无监督学习和强化学习
深度学习的瓶颈
1.可解释性太差
2.泛化能力有限,只能处理单一场景
3.容易受干扰和攻击
4.难以模仿人的注意力
现在人工智能说白了就是有多少人工有多少智能,你给他什么数据他能学到什么东西,换个应用场景就不灵了,什么时候真正能突破奇点达到真正意义上的人工智能,即上文中所定义的强人工智能阶段,谁也不知道。
人工智能如何指导生活
1) 对学习含义的误解
许多人多年来都没有真正理解学习的意义,还在用“看读了多少书、背了多少古诗、知道多少冷知识”评价学习能力,学习不是比拼记忆力,而是看你能否根据有限的例子发现规律,去解决无限的问题。比如牛顿就通过有限的例子总结出了运动三大定律,解释了世间所有宏观的运动问题。
2) 对记忆机制的误解
人类进化出记忆,是让你记住规律的,而不是记住所有信息。其实人脑完全可以做到记住所有信息(例如超忆症),但这种情况下储存的信息量太大了,信息提取就变得非常困难,所以超忆症才成为了一种病,患者一般连生活都不能自理。你可以想象一个庞大的图书馆如果被弄得乱七八糟,其用途就远不如一个小型但井井有条的图书馆,而这个让它井井有条的过程,就是你的思考加工过程。
另外,脑神经细胞就那么多,固定连接用来记忆的细胞越多,自由活跃用来归纳规律的细胞就越少。遗忘机制可以通过遗忘不重要的内容,让神经细胞断开固有连接,重新变得活跃并参与思考。大脑就像一个既要生产又要堆放存货的车间,你的思考越深入,生产出的存货(即规律)越高级,它的用途就越多,占用空间就越少,并且你发现它有错误又要重新拿出来返工的可能性就越小,尤其这个返工,是很难的,大部分人都会选择错着用下去,外在表现就是偏执。
3) 问对问题比得到答案重要
人们在归纳规律的时候,经常找错X和Y。比如我们之前在非洲工作,经常被当地人盗窃或抢劫,让许多同事对黑人产生了敌意,认为黑人=懒+危险,这就是典型的X和Y错配,在某种经济发展程度、人口结构、政府能力和文化影响下,犯罪率就会上升,任何人种都一样,因此对的问题也许是寻找经济发展程度、警察数量与犯罪率之间的关系。
4) 人难免会犯“过拟合”的错误
文章较长,首先复习一下过拟合的概念:如果用于训练模型的数据都来自单一环境,那么该模型就只对该环境中的任务效果好,换个环境效果就会很差。或者由于训练集数据不足,导致拟合出的模型与实际情况相差很大,这两种情况都非常容易出现。
先说第一种,人们就很容易把自己生活中小环境的样子,当成这个世界的样子,把自己面临的情况,当成别人面临的情况,因此好为人师,对别人的生活指指点点,这属于训练集数据单一产生的过拟合,也叫井底之蛙。
再说第二种,比如有的人被背叛一次就失去了相信人的能力,被抛弃一次就怨憎世界,这就属于训练集数据不够产生的过拟合,由于错误的认知模型丢掉了宝贵的品质,也为自己的未来盖上了天花板。
所以从人工智能的角度讲,我的毕生目标就是尽量尝试不同事物,拓展自己的见识,积累最丰富的数据训练集,防止思维过拟合,从而回归出一个泛化能力最强的认知模型,我觉得这应该就是大家追求的智慧。
5)认知模型一旦形成很难更改,即使它有问题
人会本能地捍卫自己的认知模型,不惜为此而破口大骂,相互攻击。因为模型是我们生存于世的工具,是认知上的手足,自己的模型受到他人的否定,感觉就像被砍掉了手足。越是坚信自己模型的人,一旦被证明模型是错的,精神伤害就越大。《悲惨世界》里的警察沙威,在被冉阿让用行动摧毁了坚信一辈子认知模型后,在精神上就已经死了,因此投河自尽。



