
- 1SSL/TLS协议核心原理解析与实战_计算机密码学应用 ssl tls
- 2大数据笔记--SparkStreaming_spark 对于数据流的处理的流程图
- 3idea插件推荐--GsonFormat (json对象化) ,Rainbow Brackets(括号颜色显示)_idea json插件
- 4nginx与waf配合对应用安全加固_nginx使用nga平台并打开waf应用程序保护
- 5字节跳动是如何落地微前端的_字节 微前端
- 6579. 查询员工的累计薪水 难度:困难_力扣579
- 7VMware Workstation 17.5.2 Pro 发布,产品订阅模式首个重大变更_vmware workstation pro 17.5.2
- 8asp 500错误 asp.net 500错误 iis asp 500 asp.net http 500
- 9保研/考研复试-数据结构_数据结构保研复试
- 10消息队列(RabbitMQ)_消息队列reb
【数据结构(邓俊辉)学习笔记】二叉树02——遍历
赞
踩
0.概述
学习下先序遍历、中序遍历、后续遍历和层次遍历。
~
对二叉树的访问多可抽象为:按照某种约定的次序,对节点各访问一次且仅一次。
~
~
求解问题策略——不要从轮子造起,而是要善于利用此前的工作成果。
如何将二叉树这样地半线性结构,转换为向量或列表这样的线性结构?——按照某种事先约定的原则,在二叉树所有节点之间,定义某种明确的线性次序,而具体的转换手法,就是接下来要介绍的。
实际这样的策略贯穿整个课程,比如图结构是典型的非线性结构,同样面临的问题,如何将非线性结构转换为半线性结构,处理手法依然是遍历。
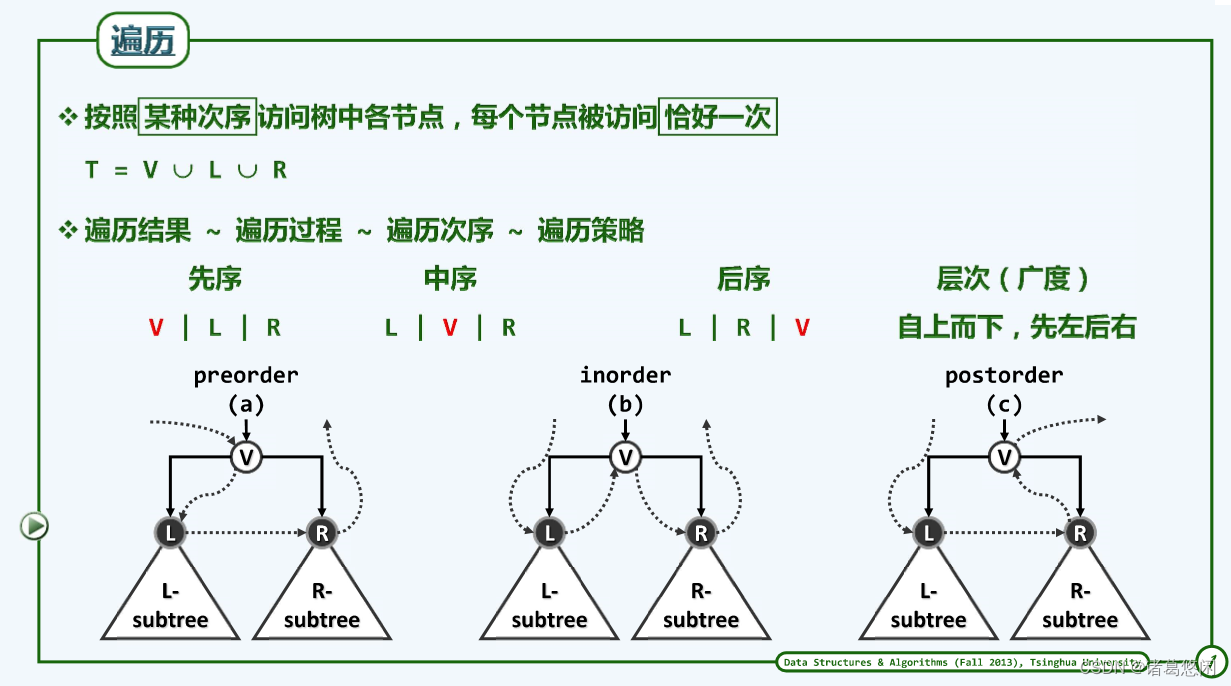
二叉树本身并不具有天然的全局次序,故为实现遍历,首先需要在各节点与其孩子之间约定某种局部次序,从而间接地定义出全局次序。按惯例左孩子优先于右孩子,故若将节点及其孩子分别记作V、L和R,则如图所示,局部访问的次序有VLR、LVR和LRV三种选择。根据节点V在其中的访问次序,这三种策略也相应地分别称作先序遍历、中序遍历和后序遍历。
1. 先序遍历
1.1 递归版
1.1.1 实现
 递归角度看,以上三种典型的遍历策略都并不难实现,因为他们的定义本身就是递归式的。
递归角度看,以上三种典型的遍历策略都并不难实现,因为他们的定义本身就是递归式的。
~
只需短短的四句就可以忠实的实现先序遍历整体策略。
第一句:是为退化情况,也就是递归基来做处理对于任何一个递归函数来说这都是非常重要的,而且是首当其冲的。
第二句:既然是先序遍历,首先将根节点取出并进行访问,
第三句:接下来以左孩子为根的那棵子树进行遍历,
第四句:以及再递归地对以右孩子为根地那棵子树进行遍历。
从而整体地完成对整树地遍历。

1.1.2 时间复杂度
可以严格证明,这个算法具有线性地时间复杂度。
T(n) = O(1) + T(a) + T(n-a-1) = O(n)
甚至可以说,这已经是不能再好的结果了,的确如此,然而这只具有渐进意义。
1.1.3 问题
在实际的运行过程中,由于递归程序的实现机制,并不可能做到针对具体的问题来量体裁衣,而只能采用通用的方法。
在运行栈中,尽管每一个递归实例都的确只对应于一帧,但是因为它们必须具有通用格式,所以并不能做到足够的小。而针对具体的问题,只要我们能够进行精巧的设计,完全是可以使得每一帧做到足够小。
尽管从大O意义上讲这两种策略所对应的每一帧都可以认为是常数O(1),但是这种常数的差异实际上是非常巨大的。因此作为树算法的重要基石,遍历算法非常有必要从递归形式改写成迭代形式。从学习者角度,经过这样的改写之后,可以对整个遍历算法的过程以及原理获得更加深刻的认识。
稍加观察,不难发现,后两句的递归调用都非常类似于我们所谓的尾递归,此递归非常容易化解为迭代形式,只需引入一个栈。
1.2 迭代版1
- 迭代思路
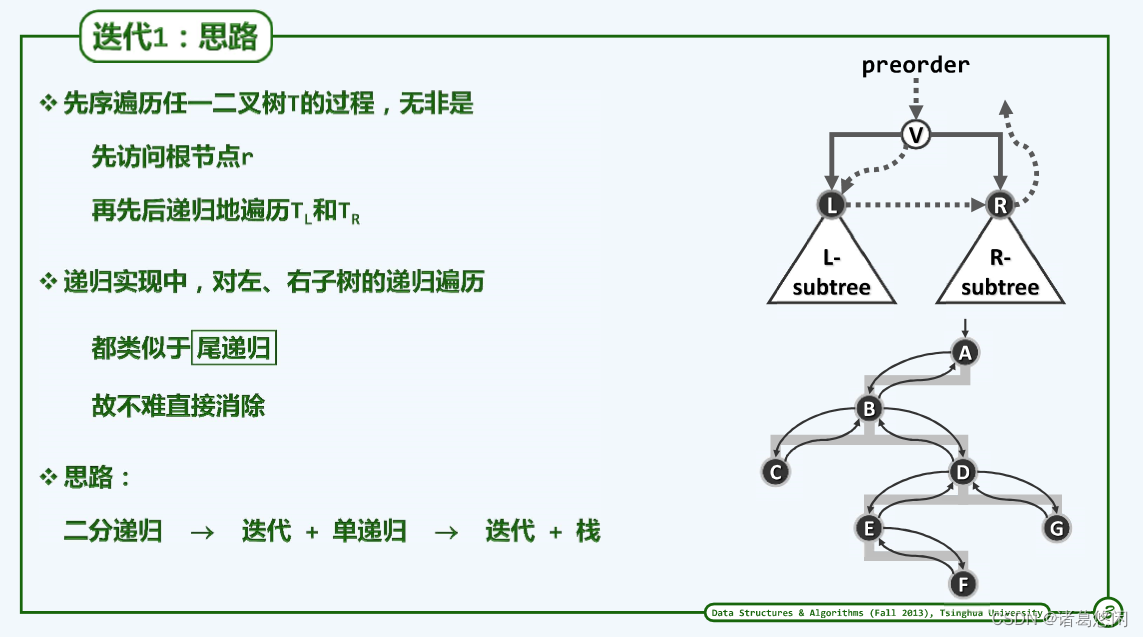
尾递归,引入一个栈,即可实现迭代版本。 - 迭代实现

- 作为初始化取一个栈S,用以存放树节点的位置,即他们的引用。
- 首先我们将当前的树根x推入栈中。
- 以下进入一个主体的循环。每次弹出当前的节点,并且随即对它进行访问。此后,如果当前这个节点拥有右孩子,就将右孩子推入栈中。如果有左孩子,左孩子也会随后入栈。此后整个循环又进入下一步迭代,直到整个栈变空。
注意: 左右孩子入栈次序是先右后左,这是因为包括先序遍历在内的所有遍历都先遍历左子树,再去遍历右子树。在这样一个算法模式中,既然每个节点都是在被弹出栈的时刻才接受访问,所以根据栈后进先出的特性,自然应该将希望后出栈的右子树先入栈了。
- 实例
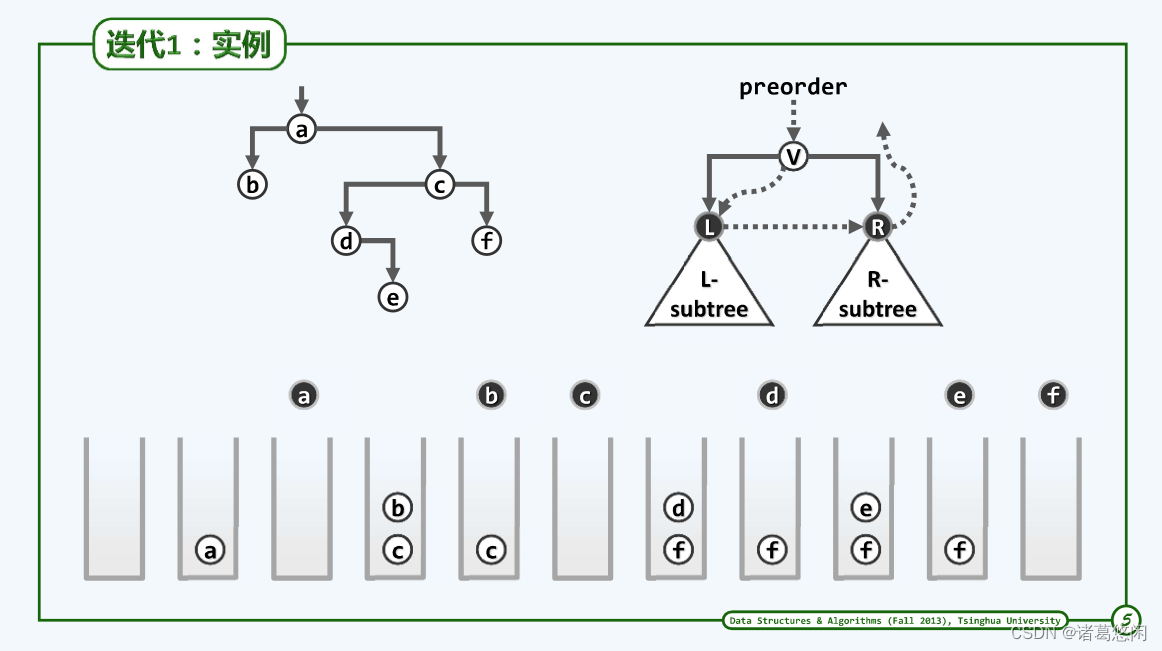
实例如图,按照先序遍历原则,在任何局部都是先访问根,再遍历左子树,再遍历右子树,最终才能完成任何一个局部的整体遍历。综观整个算法输出的节点序列,不难验证它们恰好就是我们所希望得到的先序遍历序列。
迭代版1算法非常简明,然而很遗憾,这种算法策略并不容易直接推广到此后要研究的中序乃至后续遍历算法。因此或许应该另辟蹊径,寻找其他等效的策略。
1.3 迭代版2
1.3.1 思路
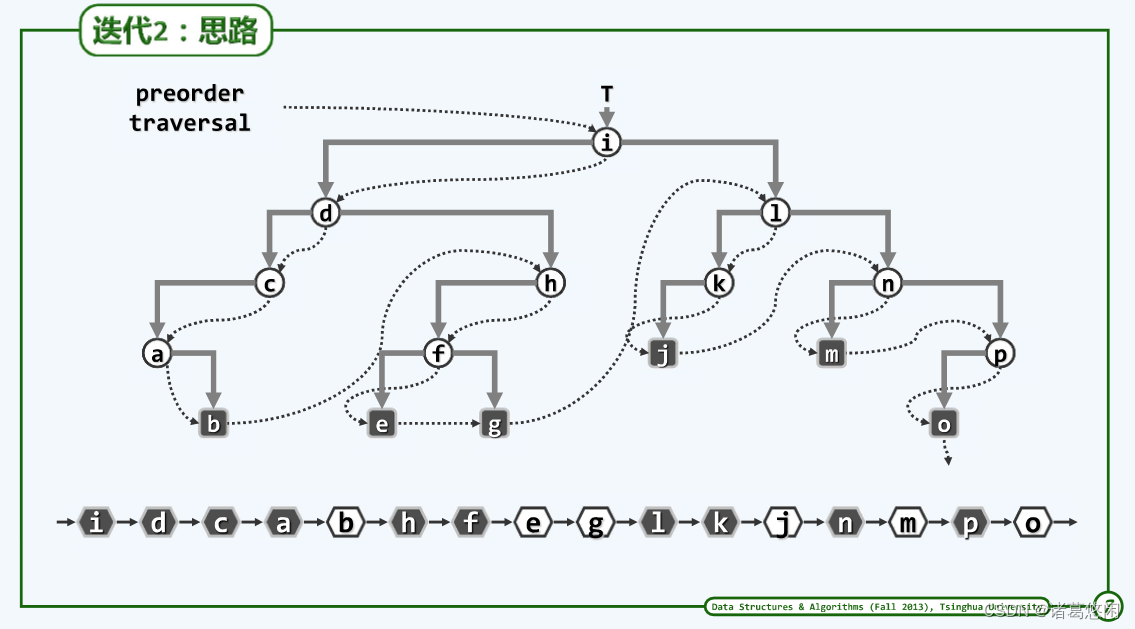
从一个规模略大同时也更具一般性的例子入手,观察上述规律。
对于任何一棵子树,在起始的若干拍中,接受访问的节点分别是谁?首先是根,接下来是根的左孩子,再接下来是左孩子的左孩子,等等。这样的规律在任何局部都是成立的。
对于任何一棵子树,我们都将起始于树根的接下来总是沿着左侧孩子分支不断下行的这样一条链,称作是当前这棵子树的左侧链,而算法呢,就是沿着左侧链逐渐展开。

不妨将每一条这样的左侧链(left branch)突出地绘制出来。假设长度为d,终止于 L d L_d Ld。沿途的每个节点也应该各自有一个右孩子以及右子树,尽管右孩子或者右子树根本就不存在,也不妨将其折叠起来,统一画成上述形式。
不难说服自己,任何一棵二叉树都可以抽象地表示为这样的一个沿左侧链不断下行,同时其他部门分别地归入于左侧链上沿途各个节点的右子树形式。经过这样抽象,就很清楚地看到 整个先序遍历地次序和脉络了。
的确可以看到,在任何这样的一棵树的局部,我们的访问都是首先沿着这样一个左侧的分支,依次的去访问这个节点。第一批被访问的节点必然是左侧分支上。这样一个过程必然会终止于刚才我们所约定的那个 L d L_d Ld,的确如此,整个遍历故事在这个地方情节发生了转折,因为接下来从宏观上看,我们应该调转方向,自底而上的依次去遍历刚才所定义的这一系列的右子树——最低的右子树,稍高一些的右子树,更高一些,乃至再高一些,以至最高的右子树。对于这些右子树,我们需要做什么呢?同样的是做遍历。
总结一下,整个过程分为两个阶段,首先是自顶而下的依次访问左侧链上的沿途节点。再倒过来,自底而上地依次遍历各个层次上的每一棵右子树。这是我们整个先序遍历的宏观过程。我们的算法就是这样一个思路来进行设计。
1.3.2 实现

需要首先实现标准地例程——visitLAlongLeftBranch,它地任务是实现从根节点开始沿着left branch不断下行依次访问沿途所有节点地这样一过程。如果起始根节点是x,它要做地事情——while迭代:每次都只需直接访问x节点,将其右孩子入栈,再转入左孩子,直到这个左孩子为空——抵达了left branch的终点。
每当向下前行一步,都会相应地将x当前的右孩子推入到事先准备好的栈中,不难看出,依次进栈右孩子是根节点的右孩子、根节点左孩子的右孩子,依此类推,直到末端节点 L d L_d Ld的右孩子。
接下来,按照自底而上地遍历右子树,对于栈而言,就应该是自顶而向底的,所以接下来一系列的顺序pop操作,恰好可以忠实还原所需要的这样一种访问的次序,这样次序如何兑现呢?看下面主算法。
~
~
算法思路:反复地在每一个局部调用visitLAlongLeftBranch这个例程来实现。

反复调用visitLAlongLeftBranch例程,而且传入的这个栈都是大家公用的。每一步迭代,都可以认为是从这个栈中弹出一个当前的节点,并且命名为x,从语义上可以理解为进入了以x为根节点的那样一棵子树,因此按照算法逻辑应该紧接下来调用visitLAlongLeftBranch例程对子树x的那个左侧分支进行访问,同时还会将相应的一系列的右子树树根通过栈逆向地收纳起来,仅此而已,一旦栈变空,算法随即退出。
1.3.3 实例
通过实例对算法进行更加具体认识。
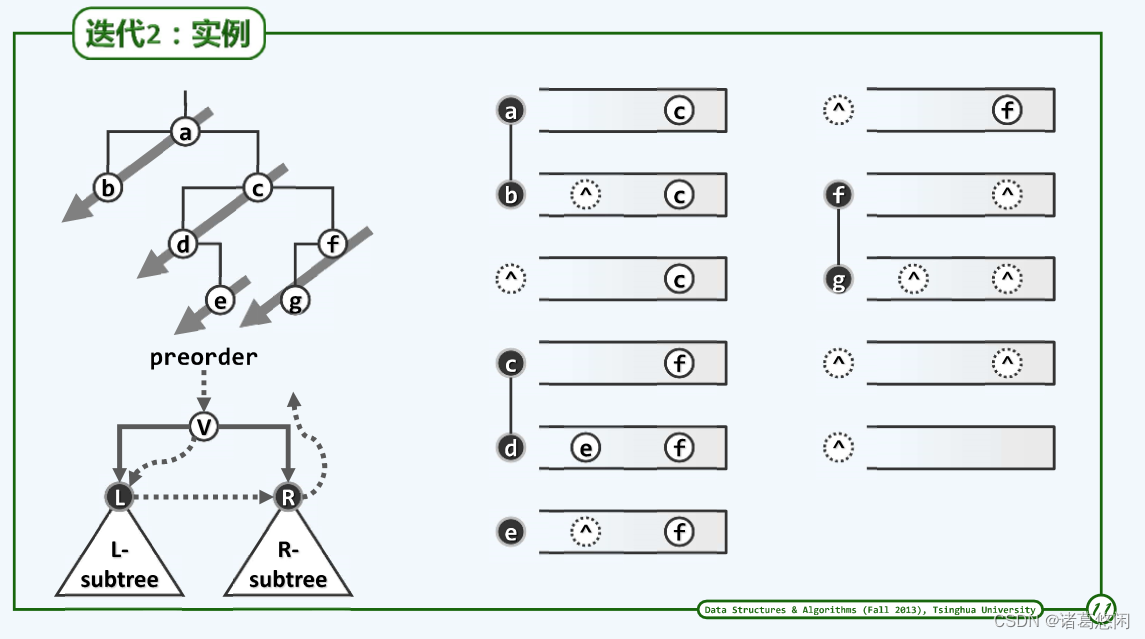
2. 中序遍历
2.1 递归形式
递归角度不难理解并实现遍历算法。

同样只需四句,第一句是处理递归基,此后三句依次遍历左子树、访问根节点以及继而遍历右子树。
同样作为非常基本的算法框架,我们对采用通常方法所实现的递归版效率并不满意,也需要在常系数意义上对算法进行改进。这种改进在实际中意义是非常大的。
难点
如何将这样一种递归的形式改写为迭代形式?不难看出相对于先序遍历,中序遍历的难度要增加几分,其原因在于对于右子树的递归调用如果还可以继续称作是尾递归,那么对于左子树的这句递归调用却因为中间嵌套了一句对根节点的访问却严格不是。

2.2 迭代形式
2.2.1 观察
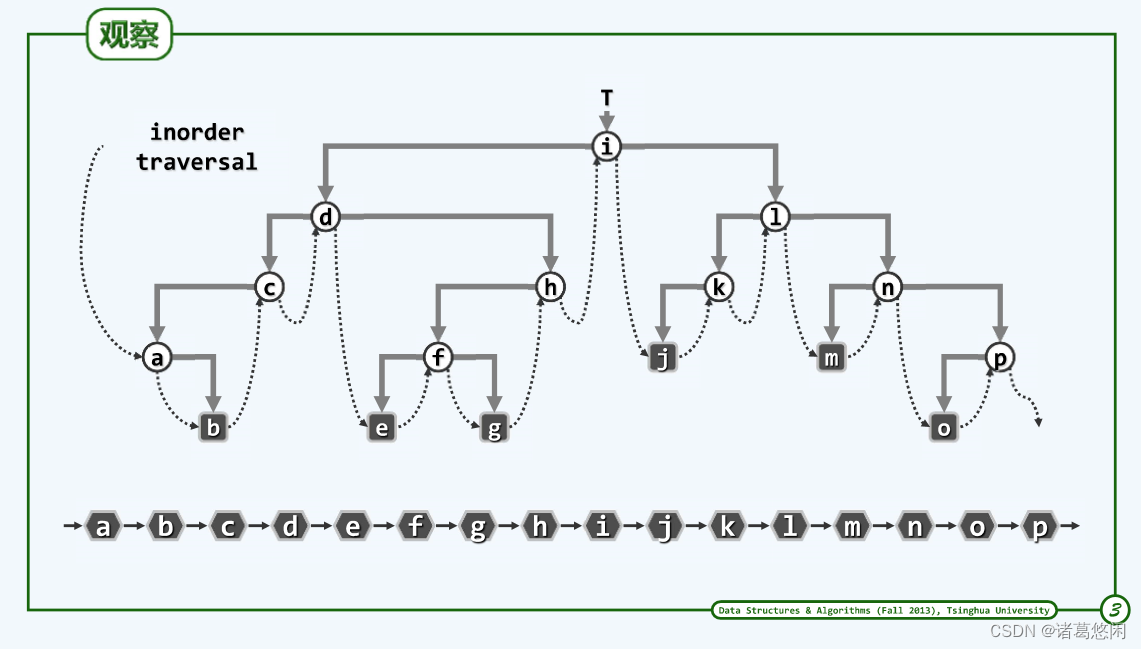
与设计算法解决很多问题的过程一样,我们首先要做的未必是动手,而是深入观察进而发现其中蕴含的规律。通过观察上述具有一定规模且一般性的实例。
首先第一个接受访问的是哪个节点?没错是a。
为什么是a?需要回到算法的基本策略——左中右次序。
~
回顾在此前各层节点逐层谦让的过程,可理解为控制权最开始在树根i,进而转让给它的左孩子d,d转让给左孩子c,c转让给它的左孩子a,a无从转让,所以才轮到它自己接受访问。
规律:与先序遍历非常类似,整个中序遍历过程的序曲总是一样的——从根节点开始,一直沿着左侧分支逐层向下,直到末端不能再向下的那个节点。 注意这里再次遇到左侧分支left branch 。站在这个视角,可以将整个中序遍历分解为在不同尺度下的一系列的对左侧分支的逐步处理。

2.2.2 思路(抽象总结)
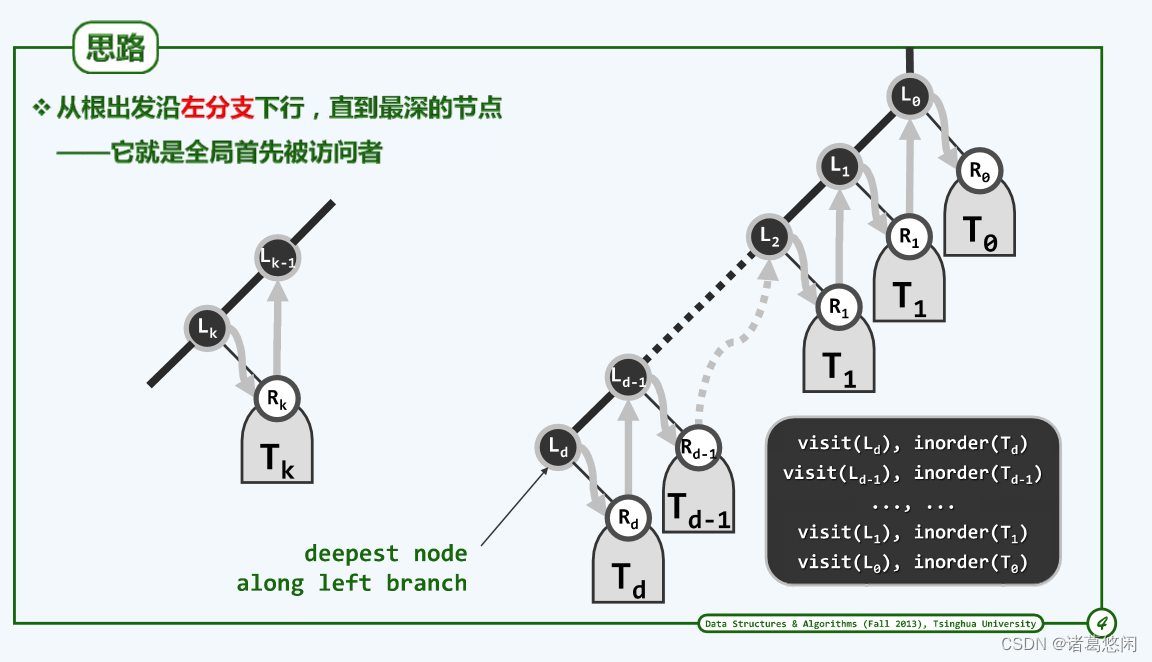
与先序遍历同理,可以将任何一棵二叉树抽象地规范为上图形式——整棵树必然可以分解为一条起自根节点地左侧链,以及左侧链上各节点所对应地右孩子右子树,同样其中某些右孩子可能并不存在或者等效地认为某些右子树可能是空的,但这并不要紧。
局部访问模式
在任何一个局部当控制权转移至当前地树根节点 L k − 1 L_{k-1} Lk−1,这个节点并不是立即接受访问,它会将控制权谦让给它的左孩子 L k L_{k} Lk,直到左孩子 L k L_{k} Lk访问之后,才会继续深入到 L k L_{k} Lk的右子树中,而接下来只有这棵右子树也被遍历完毕之后控制权才会重新回到此前的根节点处 L k − 1 L_{k-1} Lk−1,这时候这个根节点才会欣然接受访问。
整棵树访问模式
首先接受访问的是沿着左侧链向下行进的终点 L d L_{d} Ld,它被访问之后,继而它的右子树 T d T_{d} Td将被遍历,此后控制权重新回到此前谦让 L d L_{d} Ld的上层节点 L d − 1 L_{d-1} Ld−1。在节点 L d − 1 L_{d-1} Ld−1重新接过控制权这个时刻 L d L_{d} Ld以及它的右子树 T d T_{d} Td都已经被访问完毕——等效于 L d L_{d} Ld以及它的右子树 T d T_{d} Td未曾存在过。
2.2.3 构思 + 实现
整个遍历可分为若干阶段,整个左侧链有多长就有多少阶段——左侧链上每个节点都对应于一个阶段,而每个阶段情节都是雷同的,访问左侧链对应得这个节点,然后再遍历它对应得右子树,直到访问根节点,再遍历全局的右子树,如此而已。
如何通过代码实现?
访问过程存在逆序,最初访问起点是根节点处,可是最先访问的是它左侧链对应的末端节点。如果说整个谦让过程是自顶而下的话,个节点实际被访问的次序大体而言是呈一种自下而上的过程。对应数据结构栈的特性LIFO。

算法思想
- 首先构建功能子函数——goAlongLeftBranch,与先序遍历中的例程相比较只不过将visitAlong改成goAlong,言下之意执行的正是上述分析过程——在当前的节点x沿着左侧不断下行的过程中每遇到一个x都随即将它推入到总体的一个栈中。
- 主算法依然引入一个全局栈,然后反复迭代,每抵达一个节点x,等效认为进入了以它为根的子树,按照刚才推理,
首先调用goAlongLeftBranch例程将这棵子树对应的左侧链悉数的逆序推入栈中,然后从栈中弹出栈顶的节点,再将控制权转让到右孩子对应的右子树。从而在接下来的一轮迭代中依然可以等效地认为是进入了以新的x为根的子树中。只不过这个x实际上相对于此前的x是一棵右子树而已。- 整个算法不断迭代,直到某个时刻栈变空,此时所有节点都已访问完毕。
- 实例
结合实例理解上述算法
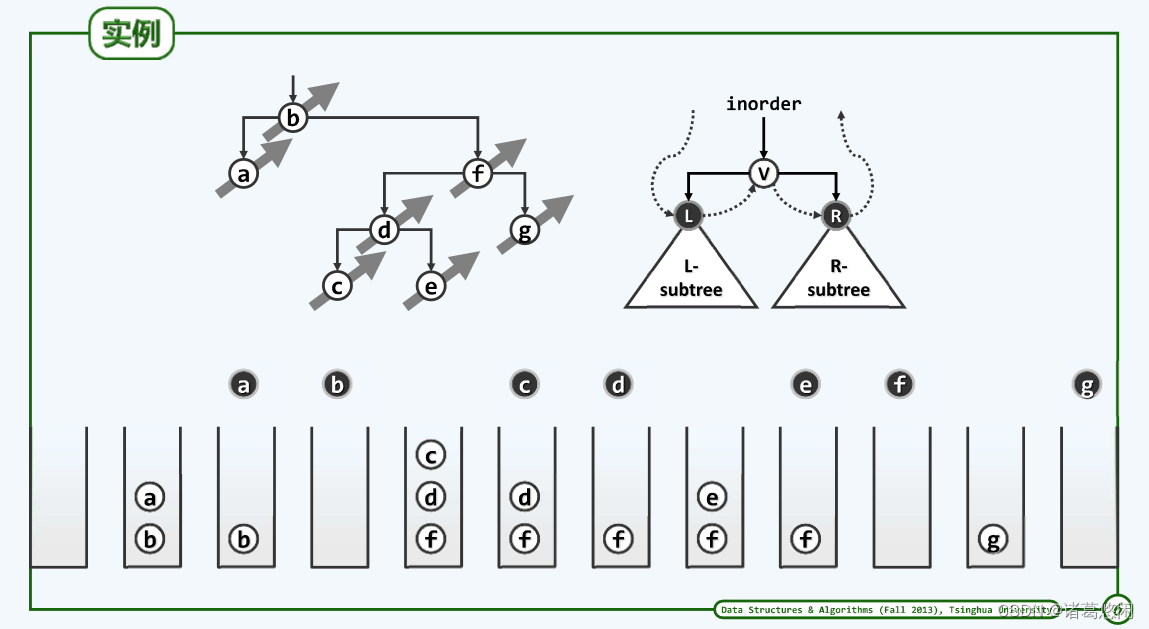
2.2.4 分摊分析
效率怎么样?

这个算法需要运行多长时间?
- 递归版
递归版本可以简明实现O(n)复杂度,尽管常系数非常之大。
- 迭代版
从结构上看大体呈现一个循环while以及内部隐含着还嵌套了一个循环goAlongLeftBranch中的while。外循环总共需要执行O(n),因为它必须对每个节点都至少访问一次, 内循环在最坏情况下本身也可能就是O(n)。试想这样一种最坏情况——从某一个节点开始,沿着左侧链下行,累计包含的点数就已经达到了与n相当的地步,比如说n/2或n/4。如此说来两个规模分别为O(n)的循环彼此嵌套后难道总体复杂度是O( n 2 n^2 n2)吗?这个结论虽然并不错误,但是从界的估计来看却远远地不紧。
~
~
没错,整个算法的确是呈一个迭代形式,而且在每一步迭代中所对应地那样一个goAlongLeftBranch过程可能距离会或长或短,甚至最长的的确会达到刚才我们说的Ω(n)量级。
|--------- L1
|------------- L2
|------------------------- L3 Ω(n)
|— L4
但是不难发现,所有这些左侧链的长度合在一起也无非是O(n),即L1 + L2 +L3 +L4 = O(n)。
~
~
goAlongLeftBranch中的while入栈操作,每个节点至多参与一次入栈,即左侧链的累计长度就是push操作的累计次数,累计次数不会操作所有的节点数O(n)。因此,O( n 2 n^2 n2)结果只不过是一个假象,这一估计远远不紧。形象地说,这就犹如我们在估计的时候,使用了n * n方框,里面有很多或长或短的长条,他们累计不过这个方框面积——O( n 2 n^2 n2),而更准确说,他们累计长度也只不过是与n在同一数量级的O(n)。
———————n————————
|--------- L1
|------------- L2
|------------------------- L3 Ω(n) ~~~~~~~~~~~~ n
|— L4
————————————————
~
结论:整个这样迭代版本运行时间依然是线性的。而且更重要的是,相对于此前递归版本线性,这里从程序结构上更为复杂,但从常系数的意义而言却要远胜于递归的版本。
3. 后序遍历
3.1 递归版
 如何改写成迭代版本?难点在哪?
如何改写成迭代版本?难点在哪?

3.2 迭代版
3.2.1 观察

首先通过观察上述具有一定规模且一般性的实例,深入观察进而发现其中蕴含的规律。

3.2.2 思路
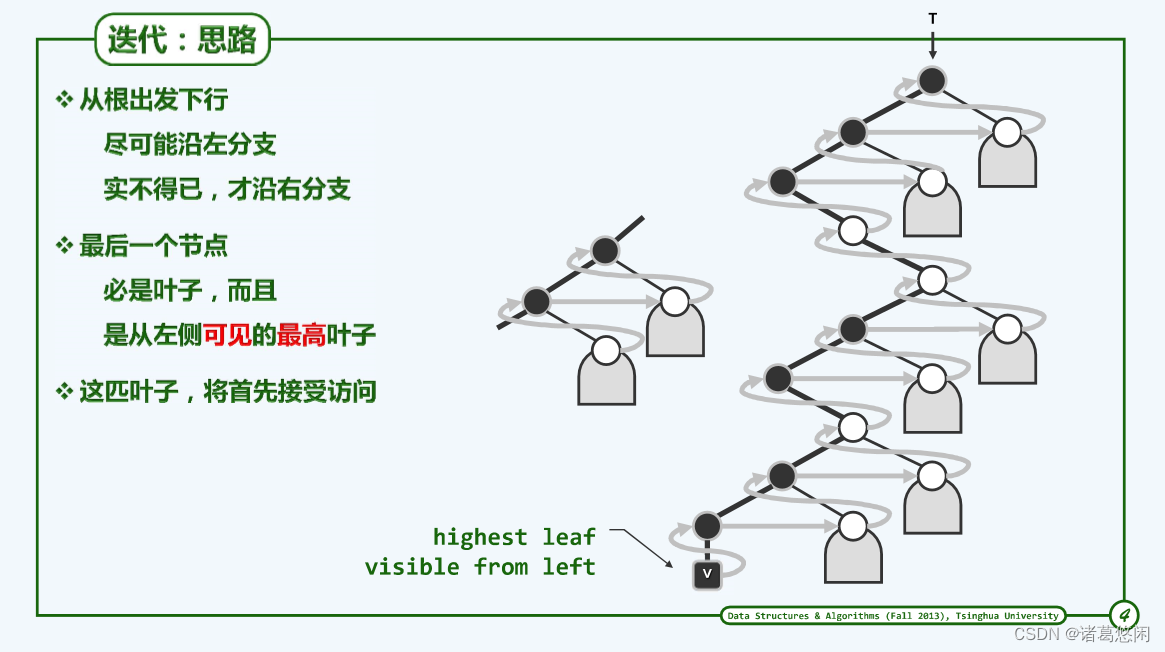
3.2.3 实现 + 实例
首先构建功能子函数——gotoHLVFL

算法思想:
- 查看栈顶元素x,若栈顶元素x不为空
- 判断x是否有左孩子和右孩子
- 若x有左孩子,go left,在此过程中x若有右孩子,将右孩子入栈,再将左孩子入栈。
- 若x没有左孩子,go right,将右孩子入栈。
- 弹出栈顶元素。
主体算法

算法思想:
- 主算法依然引入一个全局栈,按照刚才推理,x首先入栈,若栈不为空则反复迭代。
- 首先判断栈顶元素是否为当前节点的父亲,若不是当前节点的父亲,则必为栈顶元素的右兄弟(不理解可以看下面实例)。则调用功能子函数gotoHLVFL。
3.若顶元素是当前节点的父亲, 弹出栈顶元素。
整个算法不断迭代,直到某个时刻栈变空,此时所有节点都已访问完毕。
- 实例

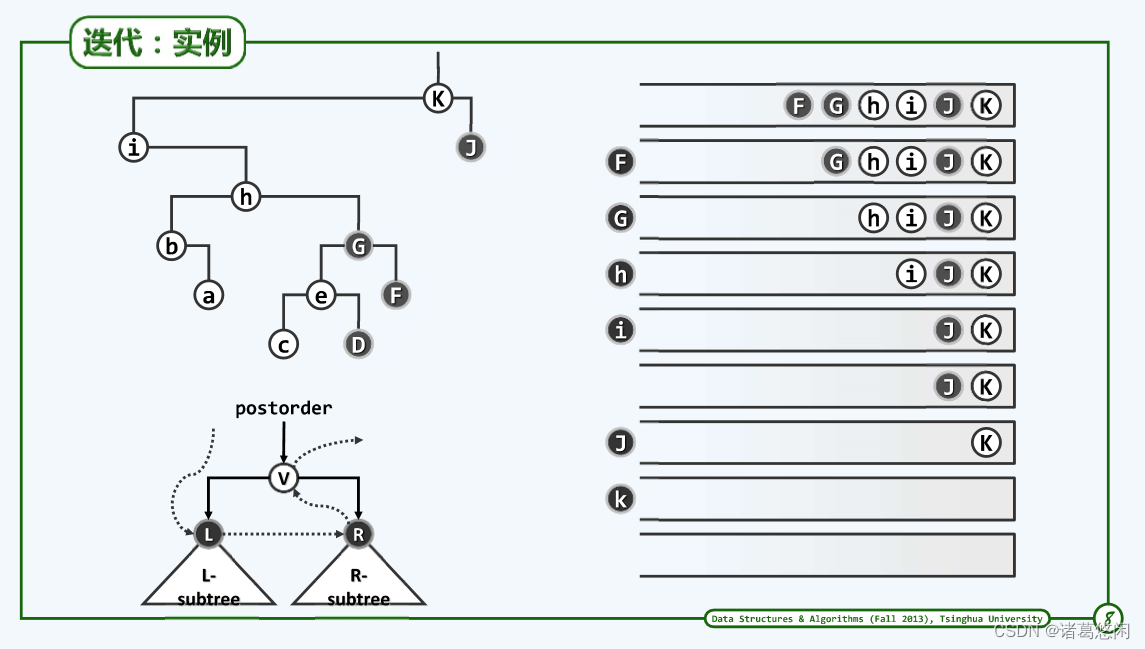
3.2.4 效率

将递归版改成迭代版的主要目的是将空间复杂度降低,那时间复杂度呢?直接给出结论。
整个这样迭代版本运行时间依然是线性的。而且更重要的是,相对于此前递归版本线性,这里从程序结构上更为复杂,但从常系数的意义而言却要远胜于递归的版本。
4. 层次遍历
4.1 分析
我们讨论的都是有根有序树——所有二叉树都被指定了一个特殊节点,即根节点。由此就可以在垂直方向按照深度将所有节点划分为若干个等价类。因此可以认为所谓的有根性对应的就是垂直方向的次序。进一步地,位于同一深度,也属于同一等价类内部的所有节点,又当如何定义次序?

所有的同辈节点,也可以分出次序,比如对于二叉树完全可以通过左右的明确定义,给出同辈节点之间的相对次序。因此可认为所谓的有序也恰好给出了沿水平方向的一个次序。因此按照垂直方向和水平方向的次序,完全可以在所有节点之间定义一个整体的次序,并进而对它进行遍历。
4.2 遍历策略
具体来说将自高向低,而在每一层自左向右逐一访问树中的每一个节点。如此定义的遍历策略即过程称为层次遍历。
这样策略该如何实现并落实为代码呢?为此我们应该使用什么样的数据结构呢?
回顾此前三种典型的遍历策略,无论是先序、中序抑或是后序都不能保证所有的节点严格地按照深度次序来接受访问。在这三种遍历策略中,都有后代先于祖先被访问的现象,也就是所谓的逆序。因此在实现这些遍历策略的时候,无论是显式的还是隐式的都需要借助栈结构。
反过来,在层次遍历中,所有的节点都将严格地按照深度次序由高至低接受访问,即严格满足顺序性。因此不难理解,在这样一种场合,与栈完全对称地数据结构——队列,将大显身手。
4.3 实现 + 实例

算法思想:
- 在内部引入队列Q,用以存放一系列节点地位置。
- 作为初始化,首先将this,即起始根节点,加入栈中。
- 接下来进入循环,每次取出队首节点,并随机访问它。接下来同样需要向下方左顾右盼,如果该节点有左孩子,就令左孩子入队,同样地如果有右孩子令右孩子入队。做完这样处理后循环又重新进入下一步迭代,只有当队列重新变空时,循环才退出,算法终止。
- 实例
通过下面实例,加深对上面层次遍历理解。


4.4 复杂度


