
- 1hyper-v安装的CentOS7配置静态IP_hyper ipv6
- 2Arduino开发板DIY简易机械臂_arduino机械臂
- 3初始化k8s时,报错[kubelet-check] It seems like the kubelet isn‘t running or healthy._[kubelet-check] it seems like the kubelet isn't ru
- 4【Web UI自动化】Python+Selenium 环境配置_python webui 自动化 selenium
- 5ubuntu中PyCharm导入虚拟环境pytorch / TensorFlow_ubuntu pycharm tensorflow
- 6世界的本质就是Unsafe,美好需要我们共同创造
- 7docker 安装maxkb_csdn maxkb 安装
- 8软件测试面试05:接口自动化面试提问答案_软件测试自动化request面试
- 9基于用户画像的PythonDjango框架的电影推荐系统设计与实现_基于用户画像的广告推荐系统
- 10AI大模型基础——情感分析模块解析(上)_情感分析大模型
Qwen2-Audio产品说明
赞
踩
产品特点
- 两种交互模式:Qwen2-Audio有两种不同的音频交互模式——语音聊天模式和音频分析模式。在语音聊天模式下,用户可以与Qwen2-Audio自由进行语音互动,无需文本输入。在音频分析模式下,用户可以提供音频和文本指令进行分析。
- 智能理解:Qwen2-Audio能够智能理解音频内容并遵循语音命令进行适当响应。例如,在一个同时包含声音、多说话者对话和语音命令的音频片段中,Qwen2-Audio可以直接理解命令并提供对音频的解释和响应。
- 自然语言指令:与复杂的层次化标签相比,Qwen2-Audio 通过使用自然语言提示来简化预训练过程,以适应不同的数据和任务。这使得模型能够更好地理解和执行用户的指令。
- 大规模数据训练:Qwen2-Audio 在预训练过程中使用了大规模的数据集,这有助于提高模型的性能和泛化能力。
- 指令遵循能力:Qwen2-Audio 在指令遵循方面进行了优化,能够更好地理解音频内容并根据语音指令做出适当的响应。
- 性能优势:通过DPO(直接偏好优化)优化模型的性能,使其在事实性和期望行为的遵循方面表现更好。根据 AIR-Bench 的评估结果,Qwen2-Audio 在音频中心的指令遵循能力方面超过了之前的 SOTA 模型,如 Gemini-1.5-pro。
- 简化预训练过程:通过使用自然语言提示,简化了不同数据和任务的预训练过程。
- 开源:Qwen2-Audio是开源的,旨在促进多模态语言社区的发展。
产品如何打造
模型架构
Qwen2-Audio的模型架构主要由两个主要部分组成:音频编码器(Audio Encoder)和大型语言模型(Large Language Model)。
音频编码器(Audio Encoder)
音频编码器是Qwen2-Audio中专门用于处理音频信号的组件。它基于Whisper-large-v3模型进行初始化,该模型是一种用于自动语音识别(ASR)的预训练模型。音频编码器的主要功能是将原始音频信号转换为固定长度的向量表示,以便后续的处理和分析。
在Qwen2-Audio中,音频编码器的具体实现包括以下几个步骤:
- 预处理:将输入的音频信号进行预处理,包括重采样到16kHz的频率,并转换为128通道的Mel频谱图。
- 特征提取:使用预训练的Whisper-large-v3模型对预处理后的音频信号进行特征提取,得到固定长度的向量表示。
- 池化:为了减少计算量和内存占用,对提取的特征进行池化操作,得到更短的向量表示。
大型语言模型(Large Language Model)
大型语言模型是Qwen2-Audio中负责理解和生成自然语言的组件。它基于Qwen-7B模型构建,该模型是一种具有70亿个参数的大型语言模型。大型语言模型的主要功能是理解输入的文本信息,并根据输入的音频和文本信息生成相应的文本响应。
在Qwen2-Audio中,大型语言模型的具体实现包括以下几个步骤:
- 文本编码:将输入的文本信息进行编码,得到固定长度的向量表示。
- 上下文建模:使用Transformer模型对编码后的文本向量进行上下文建模,得到更丰富的语义表示。
- 解码:根据上下文建模的结果和音频编码器的输出,使用Transformer解码器生成相应的文本响应。
参数大小
Qwen2-Audio的总参数量为82亿个参数,其中音频编码器和大型语言模型的参数量分别为22亿个参数和60亿个参数。这个参数量相对较大,能够提供足够的模型容量来处理复杂的音频和语言任务。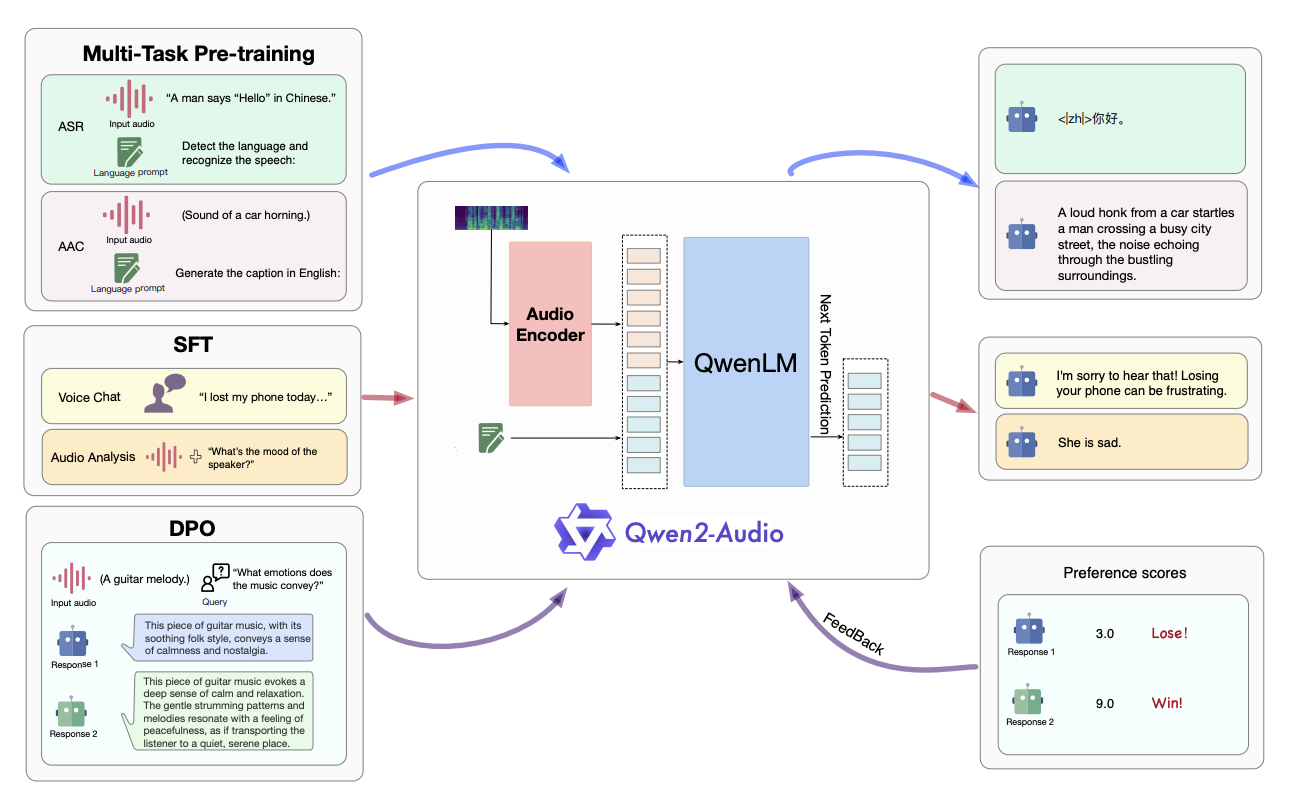
训练过程
- 预训练:Qwen2-Audio 的预训练阶段主要关注于提高模型的指令遵循能力。通过使用自然语言提示来代替层次化标签,模型能够更好地理解和执行各种数据和任务。
- 监督微调:在预训练的基础上,Qwen2-Audio 还进行了监督微调,以进一步提高模型的指令遵循能力。微调过程中使用了高质量的 SFT(监督微调)数据,并实施了严格的质量控制程序。
- 直接偏好优化:为了进一步优化模型以遵循人类偏好,Qwen2-Audio 还使用了 DPO(直接偏好优化)技术。通过使用包含输入音频和人类标注的良好和不良响应的三元组数据,模型能够学习到更符合人类期望的响应方式。
训练任务设计
Qwen2-Audio的模型训练主要包括以下三个阶段,每个阶段都涉及不同的任务:
1. 预训练阶段(Pre-training)
在预训练阶段,Qwen2-Audio的目标是学习通用的音频和语言表示,以提高其在各种任务上的性能。具体任务包括:
- 音频编码:学习将原始音频信号转换为固定长度的向量表示,以便后续的处理和分析。
- 文本编码:学习将输入的文本信息转换为固定长度的向量表示,以便与音频信息进行对齐和融合。
- 上下文建模:学习对编码后的音频和文本向量进行上下文建模,以捕捉更丰富的语义信息。
- 指令遵循:学习根据输入的音频和文本指令生成相应的文本响应,以提高模型的交互能力和任务适应性。
2. 监督微调阶段(Supervised Fine-tuning)
在监督微调阶段,Qwen2-Audio的目标是进一步提高其在特定任务上的指令遵循能力。具体任务包括:
- 语音识别:在自动语音识别(ASR)任务上进行微调,以提高模型在将语音转换为文本方面的准确性。
- 语音翻译:在语音到文本翻译(S2TT)任务上进行微调,以提高模型在将语音从一种语言翻译成另一种语言方面的准确性。
- 情感识别:在语音情感识别(SER)任务上进行微调,以提高模型在识别语音中情感状态方面的准确性。
- 声分类:在发声声分类(VSC)任务上进行微调,以提高模型在对不同的发声声进行分类方面的准确性。
3. 直接偏好优化阶段(Direct Preference Optimization)
在直接偏好优化阶段,Qwen2-Audio的目标是优化模型以更好地遵循人类偏好。具体任务包括:
- 偏好学习:使用包含输入音频和人类标注的良好和不良响应的三元组数据进行训练,以学习到更符合人类期望的响应方式。
- 策略优化:根据学习到的偏好模型,优化模型的策略以生成更符合人类偏好的响应。
通过以上三个阶段的训练,Qwen2-Audio能够逐步提高其在各种音频和语言任务上的性能,并最终实现高效的音频理解和交互功能。
训练数据
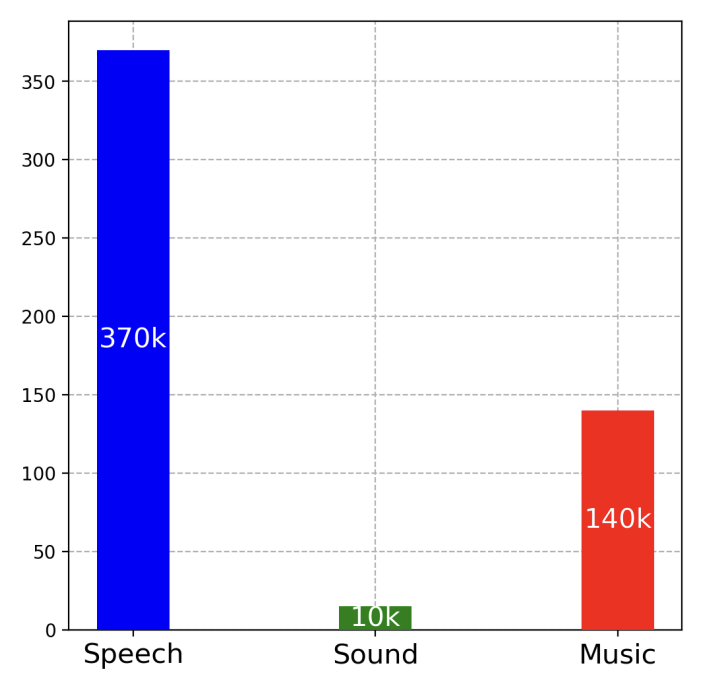
Qwen2-Audio的训练数据来源包括了多种数据集,这些数据集覆盖了自动语音识别(ASR)、语音到文本翻译(S2TT)、语音情感识别(SER)、人声声音分类(VSC)等多个任务。具体的训练数据来源包括:
- Librispeech:一个英语语音识别数据集。
- Aishell2:一个中文语音识别数据集。
- CoVoST2:一个语音到文本翻译数据集。
- Meld:一个用于语音情感识别的数据集。
- VocalSound:一个用于人声声音分类的数据集。
- AIR-Bench:一个用于评估模型在语音、声音、音乐和混合音频方面表现的基准测试。
- Common Voice:一个开源的语音识别数据集。
- Fisher:一个用于语音情感识别的数据集。
- SpokenWOZ:一个用于语音情感识别的数据集。
- IEMOCAP:一个用于语音情感识别的数据集。
- MusicCaps:一个用于音乐情感识别的数据集。
- AudioCaps:一个用于音频情感识别的数据集。
这些数据集被用来训练Qwen2-Audio模型,以提高其在各种任务上的性能,包括语音识别、语音翻译、情感识别和声音分类等。通过这些多样化的数据来源,Qwen2-Audio能够处理和理解各种类型的音频信号。
模型测评
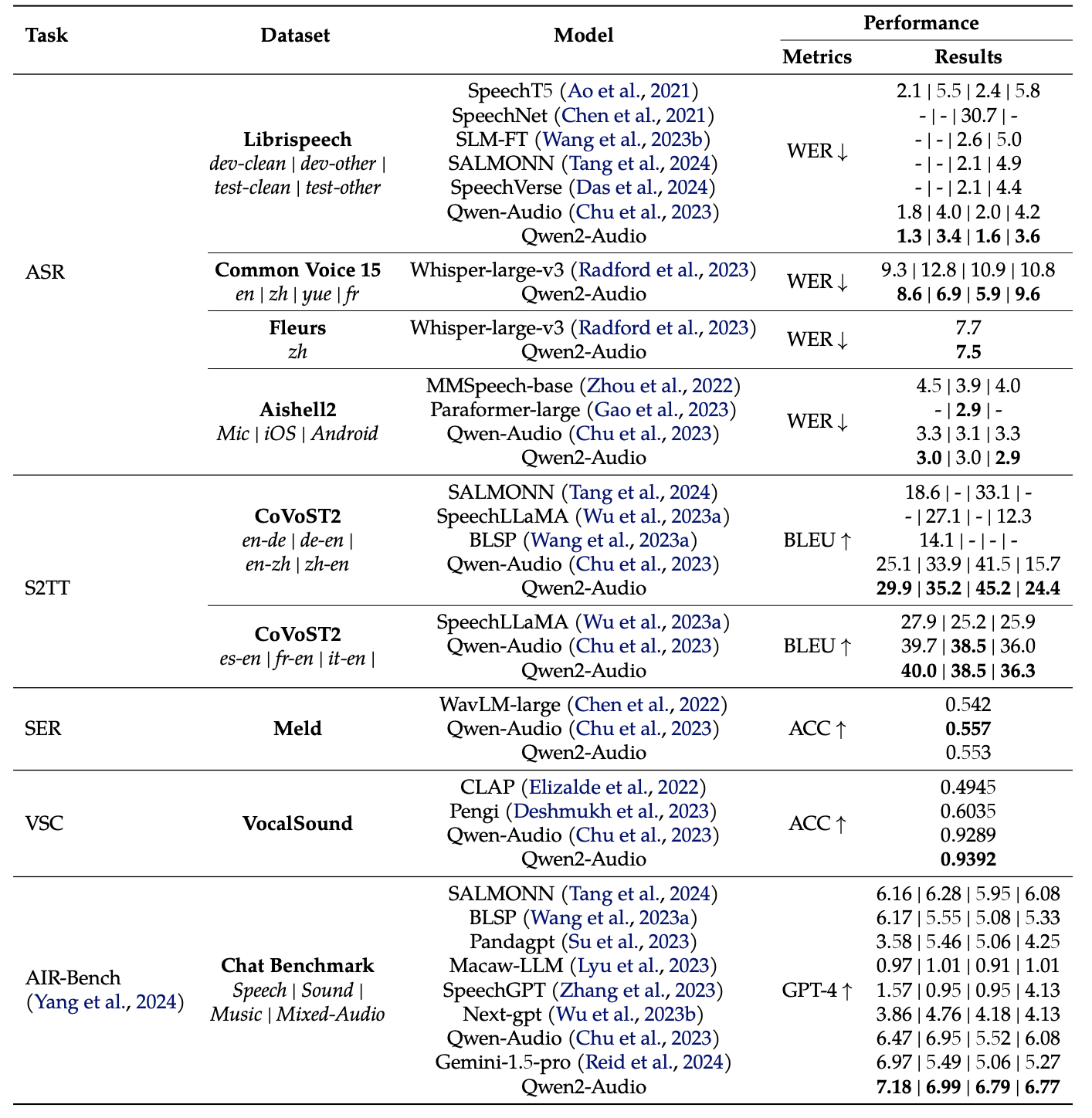
Qwen2-Audio在多个测评基准上进行了评估,以验证其在各种音频和语言任务上的性能。以下是一些关键的测评结果:
自动语音识别(ASR)
在自动语音识别任务上,Qwen2-Audio在多个数据集上进行了评估,包括Librispeech、Aishell2和Common Voice等。评估指标为词错率(WER),较低的WER表示更好的性能。
- Librispeech:在Librispeech数据集上,Qwen2-Audio在test-clean和test-other子集上分别取得了1.6%和3.6%的WER,优于先前的多任务学习模型。
- Aishell2:在Aishell2数据集上,Qwen2-Audio在Mic、iOS和Android子集上分别取得了3.0%、3.0%和2.9%的WER,优于先前的模型。
- Common Voice:在Common Voice数据集上,Qwen2-Audio在15种语言的子集上取得了优于Whisper-large-v3的性能,尽管不是在零样本设置下进行评估。
语音到文本翻译(S2TT)
在语音到文本翻译任务上,Qwen2-Audio在CoVoST2数据集上进行了评估。评估指标为BLEU分数,较高的BLEU分数表示更好的性能。
- CoVoST2:在CoVoST2数据集上,Qwen2-Audio在所有7种翻译方向上都取得了显著的性能提升,超过了先前的基线模型。
语音情感识别(SER)和发声声分类(VSC)
在语音情感识别和发声声分类任务上,Qwen2-Audio在Meld和VocalSound数据集上进行了评估。评估指标为准确率(ACC),较高的ACC表示更好的性能。
- Meld:在Meld数据集上,Qwen2-Audio取得了0.553的ACC,优于先前的模型。
- VocalSound:在VocalSound数据集上,Qwen2-Audio取得了0.9392的ACC,优于先前的模型。
AIR-Bench聊天基准
在AIR-Bench聊天基准上,Qwen2-Audio在涉及语音、声音、音乐和混合音频等多个维度的聊天任务上进行了评估。评估指标为GPT-4自动评估的分数,较高的分数表示更好的性能。
- AIR-Bench聊天基准:在AIR-Bench聊天基准上,Qwen2-Audio在语音、声音、音乐和混合音频等多个维度上都取得了显著的性能提升,超过了先前的模型。
综上所述,Qwen2-Audio在多个测评基准上都取得了出色的性能,尤其是在指令遵循能力和交互模式的灵活性方面。这些结果表明,Qwen2-Audio是一种具有潜力的音频-语言模型,可以应用于各种实际场景中的音频理解和交互任务。

