
- 1短视频去水印解析接口 可测试
- 2网络安全工具100套_网络安全小工具
- 3Linux下安装Spark_linux 安装spork
- 4@font-face字体文件过大导致页面加载缓慢_uniapp 使用字体 慢
- 5Python学习笔记之:threading.Thread 类的继承和改造_python龟兔赛跑用继承threading.thread的run方法
- 6飞机大战python代码
- 7叮当外卖单体项目SpringBoot+Mybatis-Plus+Redis(附源码)_springboot+mybatisplus+redis,涉及分页、缓存等
- 8Python处理日期方法大全、三十种方法_python 时间
- 9CVPR2023 best paper: Planning-oriented Autonomous Driving 解析
- 10android连接mysql
Linux项目自动化构建工具——make/Makefile(基础)_make linux
赞
踩
1. 背景
在VS下我们可以随意创建.h、.c/.cpp文件,在进行编译的时候,我们只需要包含头文件然后再按下Ctrl+F5,预处理->编译->编译->汇编->链接这些工作编译器自动就帮我做好了,但是在Linux下,如果我们有非常多个.c文件需要去执行,难道还需要我们一个个的gcc filename去执行吗?这种方法显然不太可取的。
会不会写Makefile,从侧面说明了一个人是否具备完成大型工程的能力。
make是一条命令,Makefile是一个在当前目录下存在的一个具有特定格式的文本文件,两个搭配使用,完成项目自动化构建。
- 一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,Makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂
的功能操作。- Makefile带来的好处就是——“自动化编译”,一旦写好,只需要一个
make命令,整个工程完全自动编译,极大的提高了软件开发的效率。make是一个命令工具,是一个解释makefile中指令的命令工具,一般来说,大多数的IDE都有这个命令,比如:Delphi的make,Visual C++的nmake,Linux下GNU的make。可见,Makefile都成为了一种在工程方面的编译方法。
2. make/makefile
在上面我们提到Makefile是一个文本文件,所以先touch Makefile/makefile(名字必须是makefile!首字母可以大写,这里建议大写)
2.1 项目构建
这里来实现一个最简单的Makefile:
要形成的可执行程序的名字:(冒号的左右两侧可以带空格) 该可执行程序从哪个源文件编译过来
以tab键开头(不能是自己手动输入的空格!这是语法约定形成的)如何形成该可执行程序gcc/g++命令
如下:
mybin(目标文件): code.c(依赖文件列表) //依赖关系
gcc code.c -o mybin //依赖方法
gcc -o mybin code.c // 这种写法也可以了,只要保证-o后面紧跟的是可执行程序文件即可
- 1
- 2
- 3
注:在依赖关系中如果有多个依赖文件,文件与文件之间的分隔符是空格 。
此时,我们不再需要输入gcc/g++命令了,直接输入make命令即可。
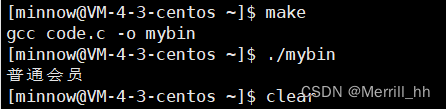
并且make会自动识别文件的新旧,如果我们的文件没有改变直接make,会发生这样的情况:
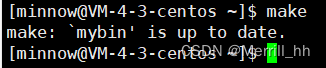
如果我们修改一下,则就会重新生成一个可执行文件。
2.2 项目清理
那么我们如何清理对应的临时文件包括可执行程序呢?
.PHONY:clean
clean:
rm -f mybin
- 1
- 2
- 3
执行一下make clean
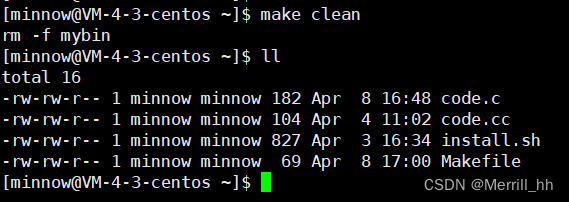
发现此时可执行程序文件被删除了。
make命令会自顶向下自动扫描第一个按照依赖方法形成的目标文件,也就是说,如果我们修改一下Makefile的写法,使用make命令就会发生一丢丢的变化!
如: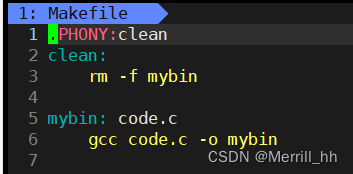
make一下:
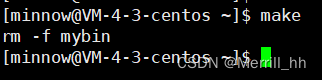
此时make命令就发生改变,变成清理可执行程序文件了。
2.3 一些使用makefile时产生的问题
这里解释一下上面所提到过的.PHONY
.PHONY把一个目标文件修饰成为伪目标,伪目标总是被执行的,不会被任何情况拦截。
这时候可能又会产生一个问题了,为什么在我们编译代码的时候,Makefile和make为什么不让我们重新编译未修改的代码呢?
其实程序的编译是一个非常耗时的过程,如果一个项目里有非常多的源代码,并且每个都去重新进行预处理、编译、汇编、链接的话,那么编译的效率会大打折扣,所以说makefile和make不让我们重新编译未修改的代码本质上就是为了提高编译效率的。
那么make是如何识别该文件是否被修改过的呢?
首先我们知道一个文件具有文件属性,那么它的修改时间也一目了然,但时间其实不本质,通过时间对比出来的新旧才是本质。
源文件和谁的时间对比,才能体现源文件的新旧呢?
答案显而易见,和我们所形成的可执行程序对比,因为可执行程序也是一个文件。重新编译的本质就是重新写入一个二进制可执行文件,它的修改时间也随之而改变。

查询时间,也就是查询文件状态的命令:
stat filename
如:

众所周知:文件 = 内容 + 属性
Access:表示该文件的最近访问时间。
Modify:修改,表示对文件的内容修改的时间。
Change:改变,表示对文件的属性更改的时间。
- 当
Change改变,也就是文件的属性改变时,文件的内容,也就是Modify不一定改变。例如:修改文件的权限。 - 当
Modify改变,也就是文件的内容改变时,文件的属性,也就是Chang会联动改变。
当我们不断cat filename时,我们发现Access并不是每次都发生改变的,这是为什么捏?
一般而言,我们所看到的文件都是在磁盘存放的,更改时间的本质其实就是访问磁盘。Linux系统充满大量的访问磁盘的IO操作,如果每次查看访问都要更改
Access,那么效率会变得非常低下,也就变相的减慢了系统效率。
此时我们可以回到上面所提到过的问题,源文件通过对比Modify来检测文件是否需要重新编译。那么,我们有没有办法可以不通过修改文件内容来直接修改Modify呢?
touch命令,不仅仅可以创建空文件,也可以更新文件的时间。
选项-a和-m虽然说只更改Access和Modify,但是修改了Access和Modify,也相当于修改了文件的属性,所以Change也随之改变。
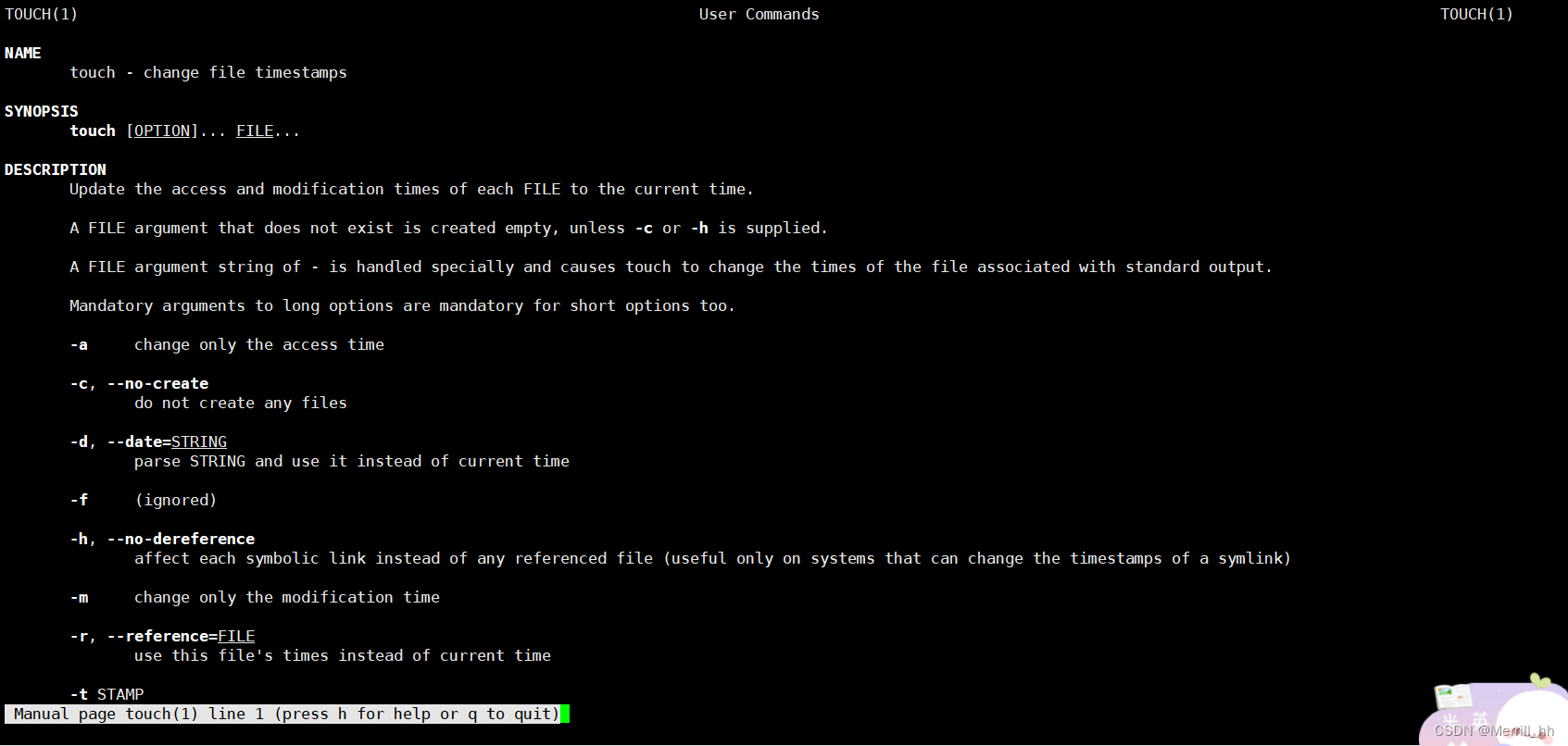
当我们使用touch修改Modify后,我们也就能在不修改文件内容的情况下make了。
3. 原理
3.1 make/makefile的依赖性推导能力
make/makefile是具有依赖性推导能力的。
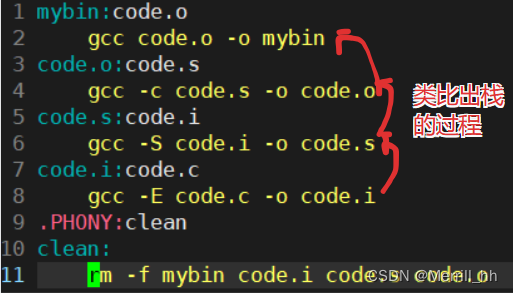
根据上面的示例,实际上我们生成的可执行程序文件mybin是依赖于.o文件的,于是我们的Makefile文件可以这样写:
mybin:code.o
gcc code.o -o mybin
code.o:code.s
gcc -c code.s -o code.o
code.s:code.i
gcc -S code.i -o code.s
code.i:code.c
gcc -E code.c -o code.i
.PHONY:clean
clean:
rm -f mybin code.i code.s code.o
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
它们的依赖关系:
mybin依赖code.o
code.o依赖code.s
code.s依赖code.i
code.i依赖code.c
这种写法就好像把它们放在一个栈里,一个个进行压栈的过程。
此时我们使用make命令,就会这样:
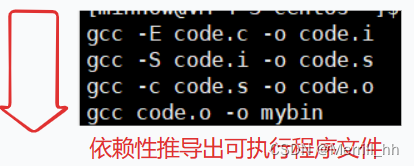
3.2 make工作原理的简述
make是如何工作的,在默认的方式下,也就是我们只输入make命令。那么,
- make会在当前目录下找名字叫“Makefile”或“makefile”的文件。
- 如果找到,它会找文件中的第一个目标文件(target),在上面的例子中,他会找到
mybin这个文件,并把这个文件作为最终的目标文件。- 如果
mybin文件不存在,或是hello所依赖的后面的code.o文件的文件修改时间要比mybin这个文件新(可以用touch修改文件的Modify),那么,他就会执行后面所定义的命令来生成mybin这个文件。- 如果
mybin所依赖的code.o文件不存在,那么make会在当前文件中找目标为hello.o文件的依赖性,如果找到则再根据那一个规则生成code.o文件。(这有点像一个堆栈的过程)- 当然,你的C文件和H文件是存在的啦,于是make会生成
code.o文件,然后再用code.o文件声明make的终极任务,也就是执行文件mybin了。- 这就是整个
make的依赖性,make会一层又一层地去找文件的依赖关系,直到最终编译出第一个目标文件。- 在找寻的过程中,如果出现错误,比如最后被依赖的文件找不到,那么
make就会直接退出,并报错,而对于所定义的命令的错误,或是编译不成功,make根本不理。make只管文件的依赖性,即,如果在我找了依赖关系之后,冒号后面的文件还是不在,那么对不起,我就不工作啦。
3.3 makefile的一些语法细节
- 当我们在
make的时候,命令行中会自动回显我们所要执行的依赖方法,如果我们不想回显,只需在依赖方法前添加一个@符号。也就是:
@依赖方法
如:
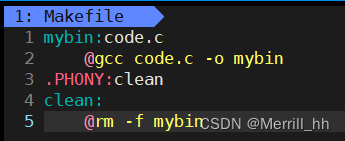
此时我们再make,屏幕就不会打印依赖方法了。但是这有什么用呢?
- 我们可以在make中添加一些输出信息:
echo "你要输出的信息"
比如:
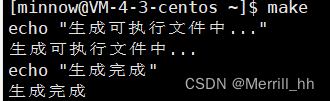
这时候我们发现屏幕打印了echo语句,此时@的作用就体现出来了,只需在echo前加个@,屏幕将不再打印echo语句了。
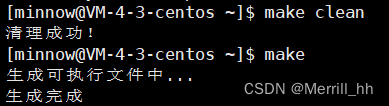
- 在Makefile中是允许我们编写变量(当成宏来理解)的(定义变量时不建议带空格),也就是支持变量替换的。
$(定义后的变量)
例如:
compiler=gcc
src=code.c
target=mybin
$(target):$(src)
$(compiler) $(src) -o $(target)
.PHONY:clean
clean:
rm -f $(target)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
这样写的好处是当我们需要更换依赖关系和依赖方法时,直接替换定义的变量即可,就和我们在C语言中学习的宏替换的作用相仿。
- 在Makefile中支持对依赖关系的简写
mybin:code.c
gcc $^ -o $@
.PHONY:clean
clean:
rm -f mybin
- 1
- 2
- 3
- 4
- 5
$@:代表依赖关系中:左侧中你所要形成的目标文件。
$^:代表依赖关系中:右侧的所有内容,也就是依赖文件列表。

