- 1whisper 实现语音转文字
- 2Python网络爬虫实战6—下一页,模拟用户点击,切换窗口
- 3Python多线程模块_运用thread实现n的阶乘
- 4VUE的安装_vue一开始的镜像源是哪个
- 5# 2020年三无选手的计算机保研之路(武大,中山,哈深_哈深被鸽
- 6微信小程序:实现微信小程序应用首页开发 (本地生活首页)_写个微信小程序主页
- 7gitea设置仓库权限_gitea 使用者需要添加权限吗
- 8Python大数据分析、Python统计分析在医疗中的应用_python在医疗行业的应用
- 9Github运行Python代码_github上下载的python项目代码怎么运行起来
- 10Django使用https协议配置_django配置ssl证书
中间件之Kafka实用篇_kafka maven
赞
踩
目录标题
- 一、一些定义
- (一)设计kafka的初衷
- (二)消息的持久化
- (三)sendfile 技术(零拷贝)
- 二、获取kafka
- 三、卡夫卡客户端工具
- 四、kafka核心API(功能)
- 五、spring 使用 Kafka
- (一)Topic
- (二)发送消息(生产者)
- (三)接收消息(消费者)
- (四)获取消费者group.id
- (五)@KafkaListener作为元注释
- (六)@KafkaListener 注解属性表
- (七)@KafkaListener在类上
- (八)转发侦听器结果@SendTo
- (九)序列化、反序列化和消息转换
- (十)事务
- (十一)Apache Kafka 流支持
- (十二)消除幂等(filter 属性的使用)
- (十三)异常处理
- 六、spring boot使用Kafka
- (一)导入pom依赖
- (二)配置yml
- (三)生产者
- (四)消费者
- 七、其他
一、一些定义
来源官方文档。以下都是文档翻译过来的,英文好的可以直接阅读文档。
(一)设计kafka的初衷
我们设计 Kafka 是为了能够充当一个统一的平台来处理大公司可能拥有的所有实时数据馈送。为此,我们必须考虑一系列相当广泛的用例。
它必须具有高吞吐量才能支持高容量事件流,例如实时日志聚合。
它需要优雅地处理大型数据积压工作,以便能够支持来自离线系统的定期数据加载。
这也意味着系统必须处理低延迟交付,以处理更传统的消息传递用例。
我们希望支持对这些源进行分区、分布式、实时处理,以创建新的派生源。这激发了我们的分区和消费者模型。
最后,在将流馈送到其他数据系统进行服务的情况下,我们知道系统必须能够在机器故障的情况下保证容错。
支持这些用途使我们的设计具有许多独特的元素,更类似于数据库日志,而不是传统的消息传递系统。我们将在以下部分中概述设计的一些元素。
(二)消息的持久化
Kafka 严重依赖文件系统来存储和缓存消息。人们普遍认为“磁盘很慢”,这使人们怀疑持久结构能否提供有竞争力的性能。 事实上,磁盘的速度比人们预期的要慢得多,也快得多,这取决于它们的使用方式;设计得当的磁盘结构通常可以与网络一样快。
关于磁盘性能的关键事实是,在过去十年中,硬盘驱动器的吞吐量一直与磁盘寻道的延迟不同。因此,在具有六个 7200rpm SATA RAID-5 阵列的 JBOD 配置上,线性写入(顺序读写磁盘的速度会快很多)的性能约为 600MB/秒,但随机写入的性能仅为约 100k/秒,相差超过 6000 倍。这些线性读写是最多的 可预测所有使用模式,并经过操作系统的大量优化。现代操作系统提供预读和后写技术,以大块倍数和 将较小的逻辑写入分组为大型物理写入。有关此问题的进一步讨论,请参阅此 ACM 队列文章;他们实际上发现顺序磁盘访问在某些情况下可能比随机内存访问更快!
为了弥补这种性能差异,现代操作系统在使用主内存进行磁盘缓存方面变得越来越积极。现代操作系统将很乐意将所有可用内存转移到 磁盘缓存,回收内存时性能损失很小。所有磁盘读取和写入都将通过此统一缓存。如果不使用直接 I/O,则无法轻松关闭此功能,因此即使 如果进程维护数据的进程内缓存,则此数据可能会在操作系统页面缓存中复制,从而有效地将所有内容存储两次。
此外,我们正在 JVM 之上构建,任何花时间使用 Java 内存的人都知道两件事:
对象的内存开销非常高,通常会使存储的数据大小翻倍(或更糟)。
随着堆内数据的增加,Java 垃圾收集变得越来越繁琐和缓慢。
由于这些因素,使用文件系统和依赖页面缓存优于维护内存中缓存或其他结构 — 通过自动访问,我们至少使可用缓存翻倍 到所有可用内存,并且可能通过存储紧凑的字节结构而不是单个对象再次翻倍。这样做将导致在 28GB 的计算机上缓存高达 30-32GB,而不会受到 GC 处罚。 此外,即使服务重新启动,此缓存也将保持温暖,而进程内缓存将需要在内存中重建(对于 10GB 缓存可能需要 10 分钟),否则将需要启动 使用完全冷缓存(这可能意味着糟糕的初始性能)。这也大大简化了代码,因为用于维护缓存和文件系统之间一致性的所有逻辑现在都在操作系统中, 这往往比一次性的进程内尝试更有效、更正确地做到这一点。如果您的磁盘使用率有利于线性读取,则预读有效地预填充此缓存,每个缓存上的有用数据 磁盘读取。
这表明了一个非常简单的设计:当我们空间不足时,我们不是在内存中尽可能多地维护并将其全部刷新到文件系统,而是将其反转。所有数据立即 写入文件系统上的持久日志,而不必刷新到磁盘。实际上,这只是意味着它被传输到内核的页面缓存中。
这种以页面缓存为中心的设计风格在一篇关于 Varnish 设计的文章中进行了描述(以及健康的傲慢)。
(三)sendfile 技术(零拷贝)
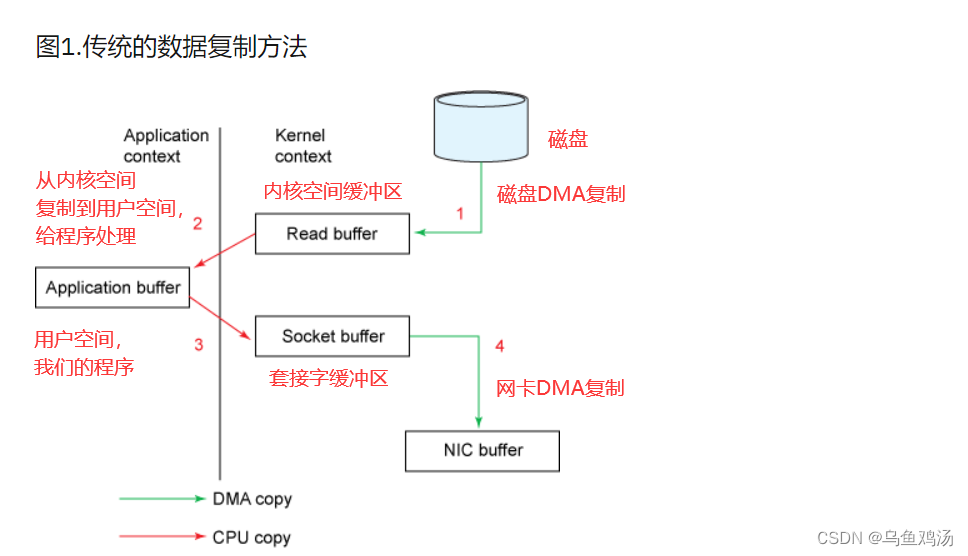
代理维护的消息日志本身只是一个文件目录,每个文件都由一系列消息集填充,这些消息集以生产者和使用者使用的相同格式写入磁盘。 保持这种通用格式可以优化最重要的操作:持久日志块的网络传输。现代 unix 操作系统为数据传输提供了高度优化的代码路径 从页面缓存到套接字;在 Linux 中,这是通过 sendfile system 调用完成的。
要了解 sendfile 的影响,了解将数据从文件传输到套接字的通用数据路径非常重要:
- 操作系统将数据从
磁盘读取到内核空间中的页面缓存中 - 应用程序将数据从
内核空间读取到用户空间缓冲区中 - 应用程序将数据写回
内核空间到套接字缓冲区中 - 操作系统将数据从
套接字缓冲区复制到 NIC 缓冲区,并通过网络发送数据
这显然是低效的,有四个副本和两个系统调用。使用 sendfile,通过允许操作系统将数据从页面缓存直接发送到网络来避免这种重新复制。所以在这个优化 路径,则只需要到 NIC 缓冲区的最终副本。
我们希望一个常见的用例是在一个主题上有多个使用者。使用上面的零拷贝优化,数据只复制到页面缓存中一次,并在每次使用时重复使用,而不是存储在内存中 并在每次读取时复制到用户空间。这允许以接近网络连接限制的速率使用消息。
页面缓存和发送文件的这种组合意味着,在使用者大多被赶上 Kafka 集群上,您将在磁盘上看到任何读取活动,因为它们将完全从缓存中提供数据。
传统数据传输:
二、获取kafka
-
下载地址:
下载最新的 Kafka 版本 -
解压安装:
$ tar -xzf kafka_2.13-3.4.0.tgz
$ cd kafka_2.13-3.4.0
- 1
- 2
- 启动环境:需要安装 jdk 8;
- 启动方式:两种
- 配合zk
- 配和KRaft

bin/kafka-server-start.sh config/server.properties
- 1
三、卡夫卡客户端工具
Kafka 通过与语言无关的协议公开其所有功能,该协议具有许多编程语言的可用客户端。然而,只有Java客户端作为Kafka主项目的一部分进行维护(导入maven kafka依赖就能直接使用。ps:java才是主流。。。),其他客户端作为独立的开源项目提供。此处提供了非 Java 客户机的列表。
四、kafka核心API(功能)
Kafka 包含五个核心 API:
- 生产者 API 允许应用程序向 Kafka 集群中的主题发送数据流。(
生产者和消费者都是kafka的客户端) - 消费者者 API 允许应用程序从 Kafka 集群中的主题读取数据流。
- 流 API 允许将数据流从输入主题转换为输出主题。
- Connect API 允许实现连接器,这些连接器不断从某个源系统或应用程序拉取到 Kafka,或者从 Kafka 推送到某个接收器系统或应用程序。
- 管理 API 允许管理和检查主题、代理和其他 Kafka 对象。
五、spring 使用 Kafka
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>3.3.1</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
(一)Topic
Kafka 操作Topic的常用命令
- 查看所有topic
[root@gc01011301 kafka_2.13-3.4.0]~ bin/kafka-topics.sh --bootstrap-server 10.8.3.78:9092 --list
__consumer_offsets
my-lihua-topic
my_topic_name
topic001
topic002
topic111
topic123
topic666
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 查看一个topic
[root@gc01011301 kafka_2.13-3.4.0]~ bin/kafka-topics.sh --bootstrap-server 10.8.3.78:9092 --list --topic topic123
topic123
[root@gc01011301 kafka_2.13-3.4.0]~ bin/kafka-topics.sh --bootstrap-server 10.8.3.78:9092 --list --topic topic1234
# 不存在会显示空白
- 1
- 2
- 3
- 4
- 新增topic
[root@gc01011301 kafka_2.13-3.4.0]~ bin/kafka-topics.sh --bootstrap-server 10.8.3.78:9092 --create --topic topic123
Created topic topic123.
- 1
- 2
- 删除topic
[root@gc01011301 kafka_2.13-3.4.0]~ bin/kafka-topics.sh --bootstrap-server 10.8.3.78:9092 --delete --topic topic123
[root@gc01011301 kafka_2.13-3.4.0]~ bin/kafka-topics.sh --bootstrap-server 10.8.3.78:9092 --list
__consumer_offsets
my-lihua-topic
my_topic_name
topic001
topic002
topic111
topic666
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 修改topic
# 将topic的分区修改为 40
[root@gc01011301 kafka_2.13-3.4.0]~ bin/kafka-topics.sh --bootstrap-server 10.8.3.78:9092 --alter --topic my_topic_name --partitions 40
- 1
- 2
以上是Kafka 3.0以上版本操作topic的命令,以下版本的命令有一些差别。可以参考官网
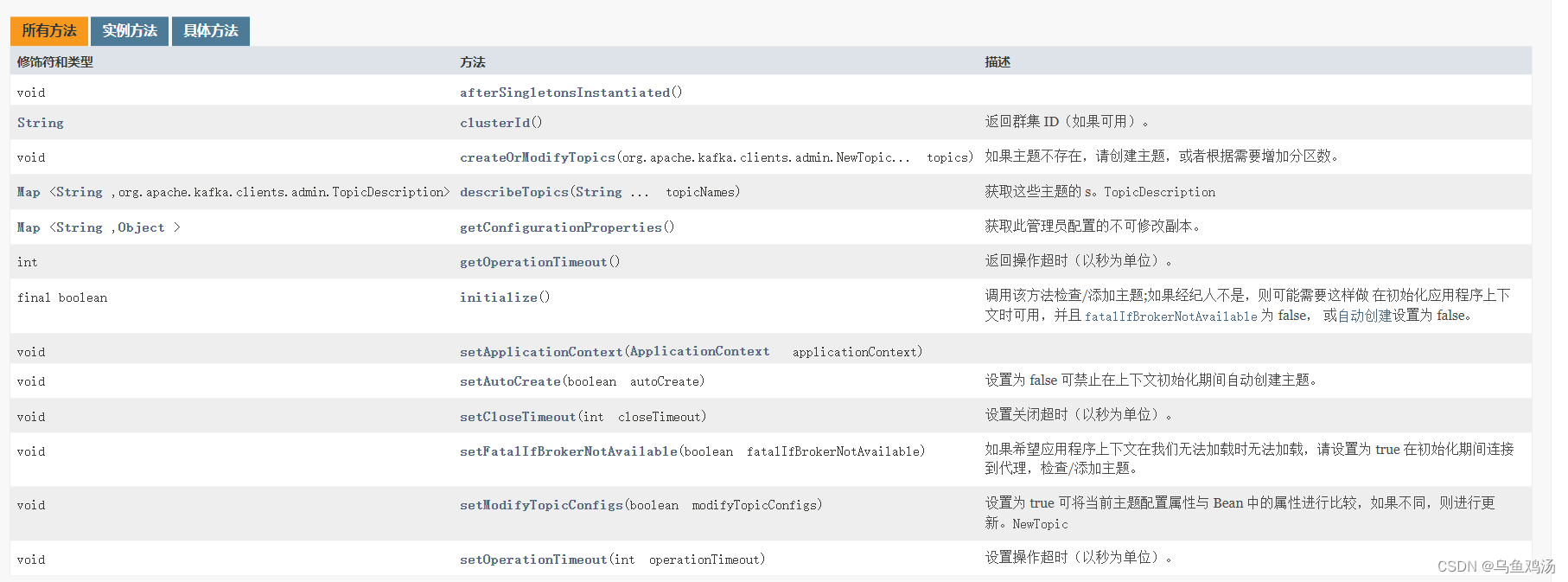
AdminClient类的作用
当然你也可以使用AdminClient类提供的方法操作topic。当然它还有其他的功能,具体查看它方法。
@Bean
public KafkaAdmin admin() {
Map<String, Object> configs = new HashMap<>();
configs.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, "10.8.3.78:9092");
return new KafkaAdmin(configs);
}
@Bean
public AdminClient adminClient(KafkaAdmin admin){
return AdminClient.create(admin.getConfigurationProperties());
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
/** * @author lihua * @date 2023/2/24 15:26 **/ @RestController public class KafkaController { @Autowired private KafkaAdmin kafkaAdmin; @Autowired private AdminClient client; @RequestMapping("/send") public void send() { kafkaTemplate.send("lihua123", 0 , 1, "this is a msg"); } @RequestMapping("/getTopics") public void getTopics() throws ExecutionException, InterruptedException { //查询所有topic ListTopicsResult listTopicsResult = client.listTopics(); Set<String> topicList = listTopicsResult.names().get(); topicList.forEach(System.out::println); } @RequestMapping("/deleteTopicAll") public void deleteTopicAll() throws ExecutionException, InterruptedException { ListTopicsResult listTopicsResult = client.listTopics(); Set<String> topicList = listTopicsResult.names().get(); client.deleteTopics(topicList); } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
KafkaAdmin类的作用
使用TopicBuilder创建topic
这种方式只要启动系统就会创建topic
/** * @author lihua * @date 2023/2/24 14:01 * 创建topic **/ @Configuration public class TopicConfig { @Bean public KafkaAdmin admin() { Map<String, Object> configs = new HashMap<>(); configs.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, "10.8.3.78:9092"); return new KafkaAdmin(configs); } @Bean public AdminClient adminClient(KafkaAdmin admin){ return AdminClient.create(admin.getConfigurationProperties()); } @Bean public NewTopic topic4() { return TopicBuilder.name("defaultBoth") .build(); } @Bean public NewTopic topic5() { return TopicBuilder.name("defaultPart") .replicas(1) .build(); } @Bean public NewTopic topic6() { return TopicBuilder.name("defaultRepl") .partitions(3) .build(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
值得注意的是,一般不会使用上面这种方式创建topic。topic不需要我们特意去创建,
当生产者发送消息时,如果topic不存在,会自动创建它。
(二)发送消息(生产者)
配置 KafkaTemplate,配置后,通过KafkaTemplate 生产消息。注意:如果是spring boot,那么配置了yml后,spring boot会自动根据配置文件装配KafkaTemplate Bean,直接注入就能使用。
/** * @author lihua * @date 2023/2/24 15:15 * * 配置生产者,生产者通过KafkaTemplate 模板向Kafka发送消息 **/ @Configuration public class KafkaTemplateConfig { @Bean public ProducerFactory<Integer, String> producerFactory() { return new DefaultKafkaProducerFactory<>(producerConfigs()); } @Bean public Map<String, Object> producerConfigs() { Map<String, Object> props = new HashMap<>(); props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "10.8.3.78:9092"); //压缩key、value。相当于序列化 props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, IntegerSerializer.class); props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class); // See https://kafka.apache.org/documentation/#producerconfigs for more properties return props; } @Bean public KafkaTemplate<Integer, String> kafkaTemplate() { return new KafkaTemplate<>(producerFactory()); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
同步
/**
* @author lihua
* @date 2023/2/24 10:12
* 生产者
**/
@RestController
public class KafkaProducerController {
@Autowired
private KafkaTemplate<Integer, String> kafkaTemplate;
@RequestMapping("/send")
public void send() {
kafkaTemplate.send("topicName", 0 , 1, "this is a msg").get();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
异步
//异步 @RequestMapping("/sendAsync") public void sendAsync() { ProducerRecord<Integer, String> record = new ProducerRecord<>("topicName", "hello!"); ListenableFuture<SendResult<Integer, String>> future = kafkaTemplate.send(record); future.addCallback(success -> { try { Thread.sleep(3000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("发送成功:" + success.toString()); }, failure -> { System.out.println("发送失败:" + failure.getMessage()); }); System.out.println("非阻塞!!!"); //future.addCallback(); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
(三)接收消息(消费者)
配置KafkaListenerContainerFactory ,通过监听工厂,获取Kafka push的消息。结合@KafkaListener注解 注解使用
/** * @author lihua * @date 2023/2/24 16:32 * * 配置消费者,push(监听器)模式,由Kafka推消息给消费者 **/ @Configuration //开启这个注解,会自动使用KafkaListenerContainerFactory 工厂。搭配@KafkaListener(topics = KafkaTopicConstant.TEST_1,groupId = "MyGroup2")使用,如果不使用注解需要使用containerFactory = "myKafkaContainerFactory"属性进行绑定 @EnableKafka public class KafkaConsumerConfig { @Bean //@Bean("myKafkaContainerFactory") KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<Integer, String>> kafkaListenerContainerFactory() { ConcurrentKafkaListenerContainerFactory<Integer, String> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.setConcurrency(3); factory.getContainerProperties().setPollTimeout(3000); return factory; } @Bean public ConsumerFactory<Integer, String> consumerFactory() { return new DefaultKafkaConsumerFactory<>(consumerConfigs()); } @Bean public Map<String, Object> consumerConfigs() { Map<String, Object> props = new HashMap<>(); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "10.8.3.78:9092"); //与生产者差不多,这里相当于将key,value的值反序列化 props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, IntegerDeserializer.class); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); return props; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
@EnableKafka 注解的作用:让 @KafkaListener 绑定@EnableKafka标注的KafkaListenerContainerFactory Bean
push的方式(推送)
/** * @author lihua * @date 2023/2/24 11:37 * 消费者 **/ @RestController public class KafkaConsumerController { @KafkaListener(topics = KafkaTopicConstant.TEST_1,groupId = "MyGroup1") //不使用@EnableKafka注解,根据containerFactory 绑定 //@KafkaListener(topics = KafkaTopicConstant.TEST_1,groupId = "MyGroup1",containerFactory = "myKafkaContainerFactory") public void listen(String data) { System.out.println(data); } @KafkaListener(topics = "topicName",groupId = "MyGroup2") public void listenGroup1(ConsumerRecord<Integer, String> record) { String value = record.value(); System.out.println(value); System.out.println(record); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
pull的方式(拉取)
@Autowired private ConsumerFactory<Integer, String> consumerFactory; @GetMapping("/pull") public void pullTest() { Consumer<Integer, String> consumer = consumerFactory.createConsumer("g1","111"); consumer.subscribe(Collections.singletonList("pull")); while (true) { /* * poll() API 是拉取消息的⻓轮询 */ ConsumerRecords<Integer, String> records = consumer.poll(Duration.ofMillis(1000)); for (ConsumerRecord<Integer, String> record : records) { System.out.printf("收到消息:partition = %d,offset = %d, key =%s, value = %s%n", record.partition(), record.offset(), record.key(), record.value()); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
(四)获取消费者group.id
topicPattern 可以使用通配符格式
.+匹配一个字符.*匹配多个
@KafkaListener(id = "bar", topicPattern = "topic.+")
public void listener(@Payload String foo,
@Header(KafkaHeaders.GROUP_ID) String groupId) {
System.out.println("Payload:"+foo);
System.out.println("GROUP_ID:"+groupId);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
(五)@KafkaListener作为元注释
从版本 2.2 开始,您现在可以用作元注释。 以下示例演示如何执行此操作:@KafkaListener
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
@KafkaListener
public @interface MyThreeConsumersListener {
@AliasFor(annotation = KafkaListener.class, attribute = "id")
String id();
@AliasFor(annotation = KafkaListener.class, attribute = "topics")
String[] topics();
@AliasFor(annotation = KafkaListener.class, attribute = "concurrency")
String concurrency() default "3";
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
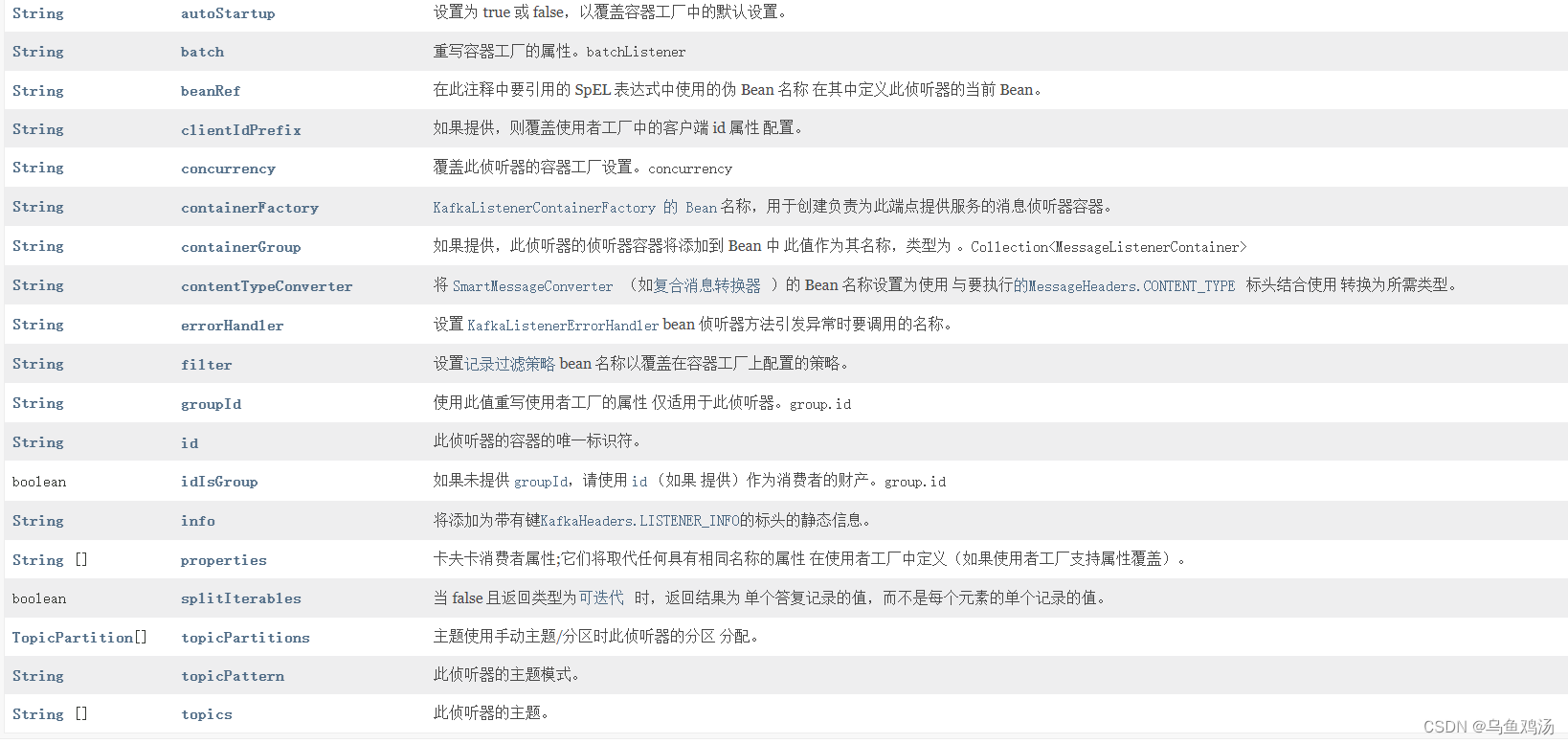
(六)@KafkaListener 注解属性表
(七)@KafkaListener在类上
从版本 2.1.3 开始,可以将方法指定为默认方法,如果其他方法不匹配,则调用该方法。 最多可以指定一种方法。 使用方法时,有效负载必须已转换为域对象(以便可以执行匹配)。 使用自定义反序列化程序、 或 ,并将其设置为 。
/** * @author lihua * @date 2023/2/27 11:43 * @KafkaListener 标注在类上,会根据消息类型(String\Integer)选择KafkaHandler * 重要的是要了解,当消息到达时,方法选择 取决于有效负载类型。类型与单个非批注参数匹配, 或用@Payload注释的注释。 不能有歧义——系统 必须能够根据有效负载类型仅选择一种方法。 * * 注意:isDefault = true 属性,只能标注一个,并且它不是代表默认使用这个Handler,恰好相反,可以将方法指定为默认方法,如果其他方法不匹配,则调用该方法(兜底的方法) **/ @Component @KafkaListener(id = "multi", topics = "myTopic") public class MultiListenerBean { @KafkaHandler public void listen(String foo) { System.out.println("foo:"+foo); } @KafkaHandler public void listen(Integer bar) { System.out.println("bar:"+bar); } @KafkaHandler(isDefault = true) public void listen(Object object) { String s = (String) object; System.out.println("object:"+s); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
(八)转发侦听器结果@SendTo
将一个主题接收到的消息转发给其他主题。
配置:
/** * @author wuyuj */ @Configuration public class KafkaConfig{ @Bean public ProducerFactory<Integer, String> producerFactory() { DefaultKafkaProducerFactory<Integer, String> factory = new DefaultKafkaProducerFactory<>(producerConfigs()); return factory; } @Bean public Map<String, Object> producerConfigs() { Map<String, Object> props = new HashMap<>(); props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "10.8.3.78:9092"); //压缩key、value。相当于序列化 props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, IntegerSerializer.class); props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class); return props; } @Bean public KafkaTemplate<Integer, String> kafkaTemplate() { return new KafkaTemplate<>(producerFactory()); } @Bean KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<Integer, String>> kafkaListenerContainerFactory() { ConcurrentKafkaListenerContainerFactory<Integer, String> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.setConcurrency(3); factory.getContainerProperties().setPollTimeout(3000); factory.setReplyTemplate(kafkaTemplate()); return factory; } @Bean public ConsumerFactory<Integer, String> consumerFactory() { return new DefaultKafkaConsumerFactory<>(consumerConfigs()); } @Bean public Map<String, Object> consumerConfigs() { Map<String, Object> props = new HashMap<>(); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "10.8.3.78:9092"); //与生产者差不多,这里相当于将key,value的值反序列化 props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, IntegerDeserializer.class); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); return props; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
使用:
@KafkaListener(id = "test1", topics = "sendToTopic123")
@SendTo("Topic123")
public String sendToTest(String data) {
System.out.println("转发人:"+data);
return data;
}
@KafkaListener(topics = "Topic123", groupId = "Topic123")
public void sendTo(String data) {
System.out.println("目的地:" + data);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
(九)序列化、反序列化和消息转换
在配置producerConfigs和consumerConfigs 添加 。
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, IntegerDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
...
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, IntegerSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
- 1
- 2
- 3
- 4
- 5
(十)事务
注意:开启了事务后,生产者发消息都需要使用事务。
配置事务
@Bean
public ProducerFactory<Integer, String> producerFactory() {
DefaultKafkaProducerFactory<Integer, String> factory = new DefaultKafkaProducerFactory<>(producerConfigs());
factory.transactionCapable();
factory.setTransactionIdPrefix("tran-");
return factory;
}
@Bean
public KafkaTransactionManager<Integer,String> transactionManager() {
return new KafkaTransactionManager<>(producerFactory());
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
使用
//方式一: @GetMapping("/transaction1") @Transactional(rollbackFor = RuntimeException.class) public void transaction1() { kafkaTemplate.send("transaction1", "hello"); kafkaTemplate.send("transaction2", "hello"); int i = 1 / 0; } //方式二; @GetMapping("/transaction2") @Transactional(rollbackFor = RuntimeException.class) public void transaction2() { boolean result = kafkaTemplate.executeInTransaction(t -> { t.send("transaction1", "hello"); t.send("transaction1", "hello"); int i = 1 / 0; return true; }); } @KafkaListener(topics = "transaction1", groupId = "transaction1") public void transaction1(String data) { System.out.println("事务:" + data); } @KafkaListener(topics = "transaction2", groupId = "transaction2") public void transaction2(String data) { System.out.println("事务:" + data); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
出现以下结果说明配置成功:
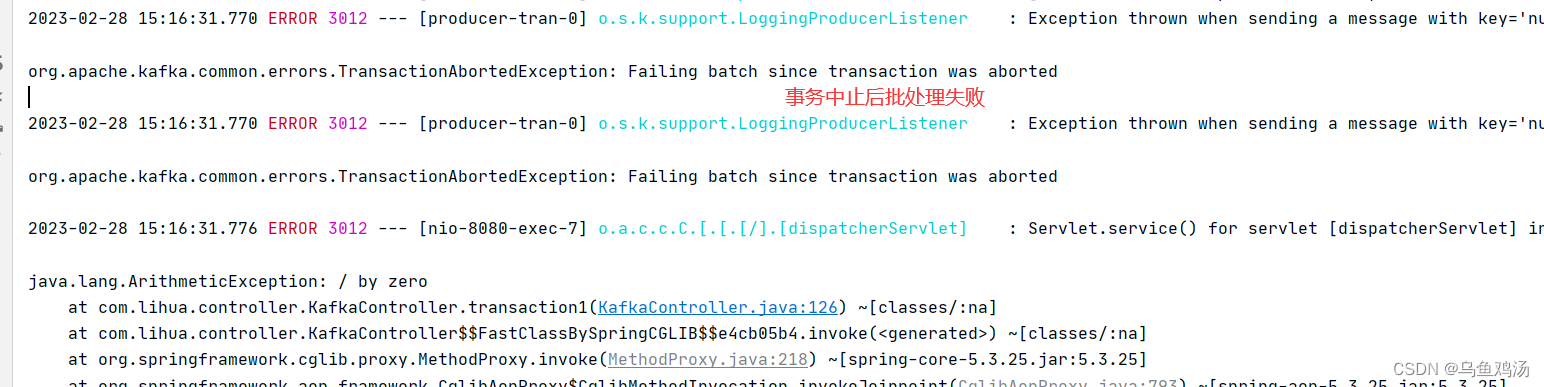
如果配置了事务没有回滚,还是接收到消息。可能是Kafka的问题,多请求几次看看。
(十一)Apache Kafka 流支持
(十二)消除幂等(filter 属性的使用)
在某些情况下(如重新平衡),可能会重新传递已处理的邮件。 框架无法知道此类消息是否已被处理。 这会产生幂等问题。可以通过消息过滤器消除幂等。
从版本 2.8.4 开始,可以使用侦听器注释上的属性来覆盖侦听器容器工厂的默认值。RecordFilterStrategy filter 。注意:filter = “differentFilter” 属性存在默认的过滤器,可以通过Bean name更改。
@KafkaListener(id = "filtered", topics = "topic", filter = "differentFilter")
public void listen(Thing thing) {
...
}
- 1
- 2
- 3
- 4
实例:
配置:过滤器
@Bean("myDifferentFilter")
public RecordFilterStrategy<Integer,String> recordFilterStrategy(){
return consumerRecord -> {
//如果这个key(消息)已经被处理过,则过滤掉消息。
int serviceId = 666; //业务Id一般从redis中获取
if(consumerRecord.key()==serviceId){
return true;
}
return false;
};
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
使用过滤器:
key = 666,就是幂等消息。过滤掉它
@RequestMapping("/sendKey")
public void send(String topic,Integer key) {
kafkaTemplate.send(topic, 0, key, "this is a msg");
}
- 1
- 2
- 3
- 4
@KafkaListener(topics = "differentFilter", groupId = "differentFilter",filter = "myDifferentFilter")
public void differentFilter(String data) {
//如果指定key已经被处理,那么不接收消息
System.out.println("幂等:" + data);
}
- 1
- 2
- 3
- 4
- 5
(十三)异常处理
常见错误处理程序 Summery
- DefaultErrorHandler
- CommonContainerStoppingErrorHandler
- CommonDelegatingErrorHandler
- CommonLoggingErrorHandler
- CommonMixedErrorHandler
他们都实现了CommonErrorHandler 接口 。因此,如果想要自定义异常处理,那么你需要实现这个接口。
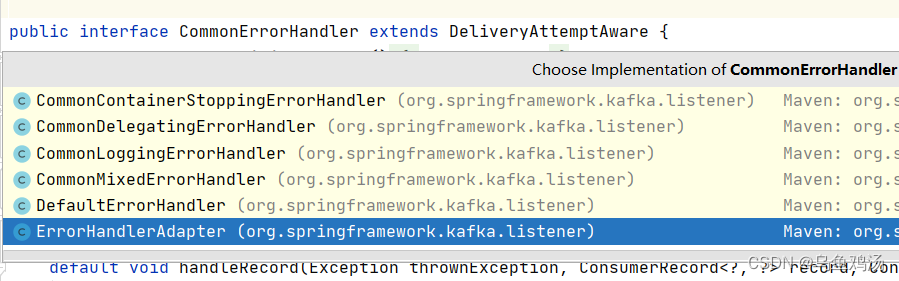
消费者异常处理
@Bean("errorHandler") public KafkaListenerErrorHandler errorHandler() { return new KafkaListenerErrorHandler(){ @Override public Object handleError(Message<?> message, ListenerExecutionFailedException e) { System.out.println("message: "+message.getPayload()); System.out.println("e: "+e.toString()); return null; } @Override public Object handleError(Message<?> message, ListenerExecutionFailedException exception, Consumer<?, ?> consumer) { System.out.println("consumer: "+consumer.toString()); System.out.println("exception: "+exception.toString()); return null; } }; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
@KafkaListener(topics = "error", groupId = "Error", errorHandler="errorHandler")
public void errorHandler(String data) {
int i=1/0;
System.out.println("消费者异常处理:" + data);
}
- 1
- 2
- 3
- 4
- 5
六、spring boot使用Kafka
(一)导入pom依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
- 1
- 2
- 3
- 4
- 5
(二)配置yml
application.yml
server: port: 8080 spring: kafka: bootstrap-servers: 172.16.253.21: 9092 producer: # 生产者 retries: 3 # 设置大于 0 的值,则客户端会将发送失败的记录重新发送 batch-size: 16384 buffer-memory: 33554432 acks: 1 # 指定消息key和消息体的编解码方式 key-serializer: org.apache.kafka.common.serialization.StringSerializer value-serializer: org.apache.kafka.common.serialization.StringSerializer consumer: group-id: default-group enable-auto-commit: false auto-offset-reset: earliest key-deserializer: org.apache.kafka.common.serialization.StringDeserializer value-deserializer: org.apache.kafka.common.serialization.StringDeserializer max-poll-records: 500 listener: # 当每一条记录被消费者监听器(ListenerConsumer)处理之后提交 # RECORD # 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后提交 # BATCH # 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后,距离上次提交时间大于TIME时提交 # TIME # 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后,被处理record数量大于等于COUNT时提交 # COUNT # TIME | COUNT 有一个条件满足时提交 # COUNT_TIME # 当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后, 手动调用Acknowledgment.acknowledge()后提交 # MANUAL # 手动调用Acknowledgment.acknowledge()后立即提交,一般使用这种 # MANUAL_IMMEDIATE ack-mode: MANUAL_IMMEDIATE
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
(三)生产者
注意:如果运行时,报错——>
Error while fetching metadata with correlation id 1 : {my-topic=LEADER_NOT_AVAILABLE}。那么你需要看一下你的Kafka配置文件server.properties是否正确配置。如下:
你可能需要添加、修改以下配置:(单机版)
# 不存在topic时是否自动创建 auto.create.topics.enable=true # 修改Kafka服务监听的ip:port ############################# Socket Server Settings ############################# # The address the socket server listens on. If not configured, the host name will be equal to the value of # java.net.InetAddress.getCanonicalHostName(), with PLAINTEXT listener name, and port 9092. # FORMAT: # listeners = listener_name://host_name:port # EXAMPLE: # listeners = PLAINTEXT://your.host.name:9092 注意:ip与application.yml 中 bootstrap-servers的配置一致。 listeners=PLAINTEXT://10.8.3.78:9092 # Listener name, hostname and port the broker will advertise to clients. # If not set, it uses the value for "listeners". advertised.listeners=PLAINTEXT://10.8.3.78:9092
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
更多Kafka配置,查看官网
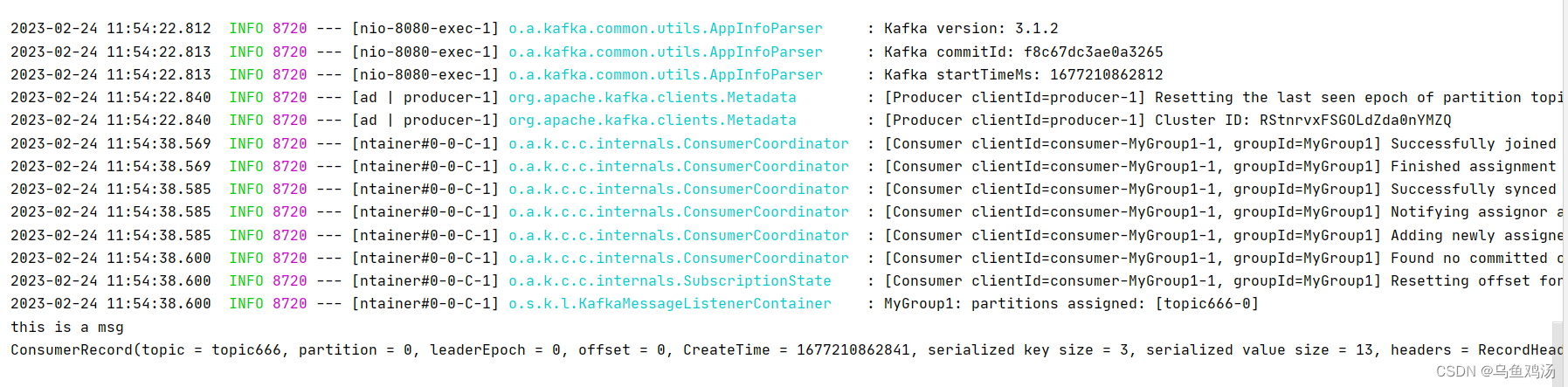
/** * @author lihua * @date 2023/2/24 10:12 * 生产者 **/ @RestController public class KafkaProducerController { /**spring boot 根据配置文件自动装配的Bean*/ @Autowired private KafkaTemplate<String, String> kafkaTemplate; @RequestMapping("/send") public void send() { kafkaTemplate.send(KafkaTopicConstant.TEST_1, 0 , "key", "this is a msg"); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
(四)消费者
/** * @author lihua * @date 2023/2/24 11:37 * 消费者 **/ @RestController public class KafkaConsumerController { @KafkaListener(topics = KafkaTopicConstant.TEST_1,groupId = "MyGroup1") public void listenGroup(ConsumerRecord<String, String> record, Acknowledgment ack) { String value = record.value(); System.out.println(value); System.out.println(record); //手动提交offset ack.acknowledge(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
主题:
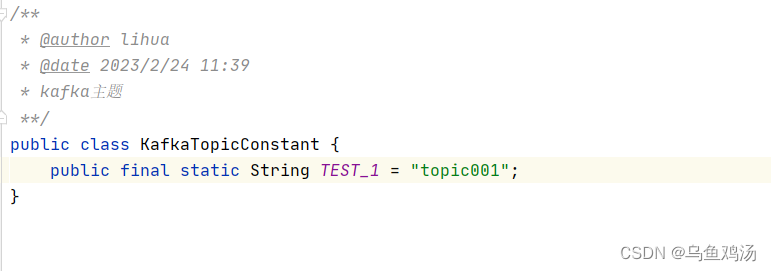
测试: http://localhost:8080/send