
- 1stremlit学习前骤_streamlit需要什么编译器
- 2大语言模型微调实践——LoRA 微调细节_lora微调的原理 旁路
- 3基线巡检脚本-启动服务_基线脚本
- 4【Ubuntu】Ubuntu安装微信_微信 ubuntu
- 5PyCharm配置GitHub_pycharm怎么建github
- 6nlp开源库与开源数据集_nlp语义识别 开源
- 7CNN(卷积神经网络)详解
- 8检测图片中的目标尺寸_《图解目标检测》系列之八:目标检测中的Label Assignment...
- 9《Bug系列 2》:完美解决pycharm能在github上创建仓库却无法push的问题_pycharm已经commit但没push的文件怎么push
- 10MTK芯片技术资料大全,各个型号都有,包括原理图数据表等
机器学习实战第七章 集成学习_机器学习 集成学习
赞
踩
集成学习
什么是集成学习
所谓三个臭皮匠顶个诸葛亮,类似的思想就是集成学习的核心思想。集成学习是通过将多个弱学习器(Weak Learners)组合在一起,形成一个更强大的学习模型。成学习通过结合多个学习器的预测结果,可以达到比单个学习器更好的性能和泛化能力。
- 弱学习器:的主要特点是:错误率略高于随机猜测,也就是说二分类问题中正确率略高于50%这样子。
集成学习的主要类别
集成学习主要有两种类别:
Bagging:
- 通过有放回的抽取样本(类似于概率论中都做过的题目,抽完小球再放回去,然后再抽)生成多个采样集。
- 每个采样集用于单独训练一个弱学习器,弱学习器之间没有依赖关系(这说明可以并行训练)
- 通过对弱学习器的预测结果进行投票(分类问题)或平均(回归问题),来确定最终的集成模型的预测结果
- 根据我的理解的话,每个弱学习器都有一定的误差,然而多个弱学习器取平均值(或者是投票取最多的?反正大概就这么个意思吧),最终得到的结果就是训练集的平均数据分布,应该是通过这样子来最终做出正确决定的
- 每个弱学习器都是在整个训练集上训练的
- 但是每个弱学习器都会根据前一个训练的弱学习器的结果去修改训练数据的权重。具体来讲,如果前一个训练好的弱学习器在A、B、C等几个样本上预测错误了,那么即将训练的下一个弱学习器将会着重对这几个样本训练。这一特性决定了AdaBoost方法只能串行训练,耗费的时间会比较长。
- 最后根据每个弱学习器的表现进行加权投票得到最终的结果。
下面我们将以AdaBoost为例展示算法实现的完整过程。
AdaBoost的具体实现
温馨提示:下面的代码实现是乱序的,根据正常人实现的思路去讲解的,但是不要紧,因为完整可运行的代码会在最后贴出。
弱学习分类器
首先呢,我们要构建弱学习分类器,有了它我们才能去构建AdaBoost。所以我们有了函数如下:
# 构建单层决策树,也就是弱分类器,用于后续构建adaboost # dataArr: 数据集 # classLabels: 标签列表 # D: 样本权重向量 # 返回最佳单层决策树的相关信息,最小误差,分类结果 def buildStump(dataArr,classLabels,D): # 将数据集和标签列表转换为矩阵形式 dataMatrix = mat(dataArr); labelMat = mat(classLabels).T m,n = shape(dataMatrix) # 步数 numSteps = 10.0 # 保存最佳单层决策树的相关信息 bestStump = {} # 初始化分类结果为1 bestClasEst = mat(zeros((m,1))) # 最小误差初始化为无穷大 minError = inf # 遍历每一个特征 for i in range(n): # 找到特征中最小值和最大值 rangeMin = dataMatrix[:,i].min() rangeMax = dataMatrix[:,i].max() # 计算步长 stepSize = (rangeMax - rangeMin)/numSteps # 遍历每一个步长 for j in range(-1,int(numSteps)+1): # 遍历大于和小于的情况 for inequal in ['lt', 'gt']: # 计算阈值 threshVal = (rangeMin + float(j)*stepSize) # 用单层决策树进行分类 predictedVals = stumpClassify(dataMatrix,i,threshVal,inequal) # 初始化误差矩阵 errArr = mat(ones((m,1))) # 分类正确的样本误差为0 errArr[predictedVals == labelMat] = 0 # 计算加权误差 weightedError = D.T*errArr # 找到误差最小的分类方式 if weightedError < minError: minError = weightedError bestClasEst = predictedVals.copy() # 保存最佳单层决策树的相关信息 bestStump['dim'] = i bestStump['thresh'] = threshVal bestStump['ineq'] = inequal # 返回最佳单层决策树的相关信息,最小误差,分类结果 return bestStump,minError,bestClasEst

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
然而前文中我们提到过,我们构造的学习器还要进行预测,以能够后续确定哪些样本需要重点关注在(这里不得不吐槽一句,如果用面向对象的思想去处理的话,我应该会把弱学习器封装成一个类,这两段代码我看了半天才搞懂在干嘛),因此,预测用(或者说是分类)用的函数如下:
# 该函数用于测试是否有某个值小于或大于我们正在测试的阈值,这些值将分别以1和-1标识
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):
# 初始化分类结果为1
retArray = ones((shape(dataMatrix)[0],1))
# 小于阈值的样本分类为-1
if threshIneq == 'lt':
retArray[dataMatrix[:,dimen] <= threshVal] = -1.0
# 大于阈值的样本分类为-1
else:
retArray[dataMatrix[:,dimen] > threshVal] = -1.0
return retArray
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
基础工具已经完整了,下面展示一下运行过程:
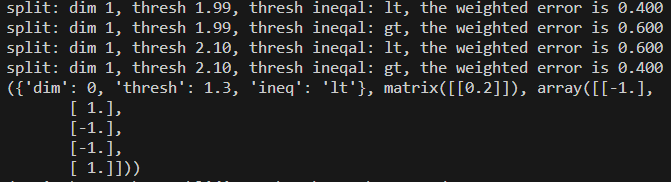
总而言之,就是不停的计算错误率,选出效果最好的那个,然后记录必要的信息。
基础代码准备完毕,下面可以开始构建AdaBoost了
AdaBoost
到了这一步反倒是没什么可说的了,主要就是生成弱学习器,然后更新权重然后再学习。重点已经全部写在注释里面了,详见代码:
# 基于弱学习器的AdaBoost训练过程 def adaBoostTrainDS(dataArr,classLabels,numIt=40): # 弱分类器相关信息列表 weakClassArr = [] m = shape(dataArr)[0] # 初始化权重向量 D = mat(ones((m,1))/m) # 记录每个数据点的类别估计累计值 aggClassEst = mat(zeros((m,1))) for i in range(numIt): # 构建单层决策树(就是弱分类器) bestStump,error,classEst = buildStump(dataArr,classLabels,D) # 计算弱分类器的权重 alpha = float(0.5*log((1.0-error)/max(error,1e-16))) # 保存弱分类器的权重 bestStump['alpha'] = alpha # 将弱分类器的相关信息加入列表 weakClassArr.append(bestStump) # 计算下一次迭代的权重向量D expon = multiply(-1*alpha*mat(classLabels).T,classEst) D = multiply(D,exp(expon)) D = D/D.sum() # 计算AdaBoost误差,当误差为0时,退出循环 aggClassEst += alpha*classEst aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T,ones((m,1))) errorRate = aggErrors.sum()/m if errorRate == 0.0: break # 返回弱分类器的相关信息列表 return weakClassArr,aggClassEst
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
训练好了之后我们需要用这个去进行分类了,具体来说也没什么,就是用弱分类器得到的结果与其权重相乘然后累加,最后输出最终结果,具体代码如下:
# AdaBoost分类函数 def adaClassify(datToClass,classifierArr): # 构建数据矩阵 dataMatrix = mat(datToClass) m = shape(dataMatrix)[0] # 初始化分类结果为0 aggClassEst = mat(zeros((m,1))) # 遍历所有弱分类器 for i in range(len(classifierArr)): # 用单层决策树进行分类 classEst = stumpClassify(dataMatrix,classifierArr[i]['dim'],\ classifierArr[i]['thresh'],\ classifierArr[i]['ineq']) # 累加分类结果 aggClassEst += classifierArr[i]['alpha']*classEst print(aggClassEst) # 返回分类结果 return sign(aggClassEst)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
最后来看一下运行效果吧,我现在是以(0,0)这个坐标为例,预测它是正的还是负的:
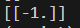
可以看到预测是正确的,这没什么问题,改为(3,3)呢?
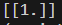
看起来也没什么问题,那么这就能说明,AdaBoost的预测效果还是很不错的。
实验
到此为止,理论已经跑通了,让我们在一个更大一些的数据集上再来测试一下吧。
我们使用的是前面章节用过的病马的数据集,代码无需改动,只需要便一家如何加载数据集即可:
def loadDataSet(fileName): # 获取特征数目 numFeat = len(open(fileName).readline().strip().split('\t')) # 初始化数据集和标签列表 dataMat = [] labelMat = [] # 打开文件 fr = open(fileName) # 遍历每一行 for line in fr.readlines(): # 初始化行列表 lineArr = [] # 获取当前行信息 curLine = line.strip().split('\t') # 遍历每一个特征 for i in range(numFeat-1): lineArr.append(float(curLine[i])) dataMat.append(lineArr) labelMat.append(float(curLine[-1])) # 返回数据集和标签列表 return dataMat, labelMat
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
最终测试结果如下:
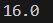
这说明错误率只有16%,这已经是一个很好的数字了,要进一步提升准确率的话可以考虑修改分类器个数,将分类器的数目从10提升的40后,错误率能够降低3%,但是数目增加到400后错误率反而来到了17%。因此,要进一步提升准确率的话,可以考虑使用高质量数据集,或者从弱学习器本身入手。
Bagging
本文不再介绍Bagging的具体实现,而是简要介绍下随机森林
随机森林
随机森林的主要特点包括以下几点:
- 决策树集合:随机森林由多个决策树组成,每个决策树都是独立构建的。
- 随机特征选择:在构建每个决策树时,随机森林会从原始特征集合中随机选择一部分特征,这样可以增加每个决策树的多样性。
- 随机样本选择:对于每个决策树的训练样本,随机森林会通过有放回的抽样方式从原始训练数据集中选择样本,这被称为自助采样法(bootstrap sampling)。
- 集体决策:随机森林通过对决策树的集体投票或平均预测来进行最终的预测。对于分类问题,使用投票法确定最终预测类别;对于回归问题,使用平均法确定最终预测值。
本文开始我们提到过,Bagging是随机抽取数据,然后并行训练模型,最后将这些模型放在一起进行投票得到最终的结果。
随机森林与其主要不同之处在于:随机森林会对特征也进行随机选择。每个基础模型中只是用了一部分样本的一部分特征来进行训练。
此外,随机森林比传统的bagging,再最终效果上有很大的提升。这应该主要是由于随机选择特征与样本导致的每个模型的差异都比较高,就好像说是做市场调研的时候最好把研发部门一起喊过来,如果只有销售的话最终得到的结果可能不会很好看。此外,由于特征是随机选择的,因此还能减少过拟合的风险,能够有很好的鲁棒性。
完整代码
from numpy import * def loadSimpData(): datMat = matrix([[1., 2.1], [2., 1.1], [1.3, 1.], [1., 1.], [2., 1.]]) classLabels = [1.0, 1.0, -1.0, -1.0, 1.0] return datMat,classLabels # 画图,展示测试数据,两类数据用圆点和方块表示 def plotDataSet(): import matplotlib.pyplot as plt dataMat, labelMat = loadSimpData() dataArr = array(dataMat) n = shape(dataArr)[0] xcord1 = [];ycord1 = [] xcord2 = [];ycord2 = [] for i in range(n): if int(labelMat[i]) == 1: # 第一类数据用圆点表示 xcord1.append(dataArr[i,0]);ycord1.append(dataArr[i,1]) else: # 第二类数据用方块表示 xcord2.append(dataArr[i,0]);ycord2.append(dataArr[i,1]) fig = plt.figure() ax = fig.add_subplot(111) # 画出两类数据的散点图 ax.scatter(xcord1,ycord1,s=30,c='red',marker='s') ax.scatter(xcord2,ycord2,s=30,c='blue') plt.xlabel('X1');plt.ylabel('X2') plt.show() # 该函数用于测试是否有某个值小于或大于我们正在测试的阈值,这些值将分别以1和-1标识 def stumpClassify(dataMatrix,dimen,threshVal,threshIneq): # 初始化分类结果为1 retArray = ones((shape(dataMatrix)[0],1)) # 小于阈值的样本分类为-1 if threshIneq == 'lt': retArray[dataMatrix[:,dimen] <= threshVal] = -1.0 # 大于阈值的样本分类为-1 else: retArray[dataMatrix[:,dimen] > threshVal] = -1.0 return retArray # 构建单层决策树,也就是弱分类器,用于后续构建adaboost # dataArr: 数据集 # classLabels: 标签列表 # D: 样本权重向量 # 返回最佳单层决策树的相关信息,最小误差,分类结果 def buildStump(dataArr,classLabels,D): # 将数据集和标签列表转换为矩阵形式 dataMatrix = mat(dataArr); labelMat = mat(classLabels).T m,n = shape(dataMatrix) # 步数 numSteps = 10.0 # 保存最佳单层决策树的相关信息 bestStump = {} # 初始化分类结果为1 bestClasEst = mat(zeros((m,1))) # 最小误差初始化为无穷大 minError = inf # 遍历每一个特征 for i in range(n): # 找到特征中最小值和最大值 rangeMin = dataMatrix[:,i].min() rangeMax = dataMatrix[:,i].max() # 计算步长 stepSize = (rangeMax - rangeMin)/numSteps # 遍历每一个步长 for j in range(-1,int(numSteps)+1): # 遍历大于和小于的情况 for inequal in ['lt', 'gt']: # 计算阈值 threshVal = (rangeMin + float(j)*stepSize) # 用单层决策树进行分类 predictedVals = stumpClassify(dataMatrix,i,threshVal,inequal) # 初始化误差矩阵 errArr = mat(ones((m,1))) # 分类正确的样本误差为0 errArr[predictedVals == labelMat] = 0 # 计算加权误差 weightedError = D.T*errArr # print("split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" \ # % (i, threshVal, inequal, weightedError)) # 找到误差最小的分类方式 if weightedError < minError: minError = weightedError bestClasEst = predictedVals.copy() # 保存最佳单层决策树的相关信息 bestStump['dim'] = i bestStump['thresh'] = threshVal bestStump['ineq'] = inequal # 返回最佳单层决策树的相关信息,最小误差,分类结果 return bestStump,minError,bestClasEst # 基于弱学习器的AdaBoost训练过程 def adaBoostTrainDS(dataArr,classLabels,numIt=40): # 弱分类器相关信息列表 weakClassArr = [] m = shape(dataArr)[0] # 初始化权重向量 D = mat(ones((m,1))/m) # 记录每个数据点的类别估计累计值 aggClassEst = mat(zeros((m,1))) for i in range(numIt): # 构建单层决策树(就是弱分类器) bestStump,error,classEst = buildStump(dataArr,classLabels,D) # 计算弱分类器的权重 alpha = float(0.5*log((1.0-error)/max(error,1e-16))) # 保存弱分类器的权重 bestStump['alpha'] = alpha # 将弱分类器的相关信息加入列表 weakClassArr.append(bestStump) # 计算下一次迭代的权重向量D expon = multiply(-1*alpha*mat(classLabels).T,classEst) D = multiply(D,exp(expon)) D = D/D.sum() # 计算AdaBoost误差,当误差为0时,退出循环 aggClassEst += alpha*classEst aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T,ones((m,1))) errorRate = aggErrors.sum()/m if errorRate == 0.0: break # 返回弱分类器的相关信息列表 return weakClassArr,aggClassEst # AdaBoost分类函数 def adaClassify(datToClass,classifierArr): # 构建数据矩阵 dataMatrix = mat(datToClass) m = shape(dataMatrix)[0] # 初始化分类结果为0 aggClassEst = mat(zeros((m,1))) # 遍历所有弱分类器 for i in range(len(classifierArr)): # 用单层决策树进行分类 print(classifierArr[i]['dim']) classEst = stumpClassify(dataMatrix,classifierArr[i]['dim'],\ classifierArr[i]['thresh'],\ classifierArr[i]['ineq']) # 累加分类结果 aggClassEst += classifierArr[i]['alpha']*classEst # print(aggClassEst) # 返回分类结果 return sign(aggClassEst) def loadDataSet(fileName): # 获取特征数目 numFeat = len(open(fileName).readline().strip().split('\t')) # 初始化数据集和标签列表 dataMat = [] labelMat = [] # 打开文件 fr = open(fileName) # 遍历每一行 for line in fr.readlines(): # 初始化行列表 lineArr = [] # 获取当前行信息 curLine = line.strip().split('\t') # 遍历每一个特征 for i in range(numFeat-1): lineArr.append(float(curLine[i])) dataMat.append(lineArr) labelMat.append(float(curLine[-1])) # 返回数据集和标签列表 return dataMat, labelMat if __name__ == '__main__': # dataArr,classLabels = loadSimpData() # classifierArr,aggClassEst = adaBoostTrainDS(dataArr,classLabels,9) # print(adaClassify([3,3],classifierArr)) # 加载训练集 dataArr,labelArr = loadDataSet('horseColicTraining2.txt') # 训练分类器 classifierArray,aggClassEst = adaBoostTrainDS(dataArr,labelArr,40) # 加载测试集 testArr,testLabelArr = loadDataSet('horseColicTest2.txt') # 对测试集进行预测 prediction10 = adaClassify(testArr,classifierArray) # 计算错误率 errArr = mat(ones((67,1))) print(errArr[prediction10 != mat(testLabelArr).T].sum())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201

