
- 1MySQL1045错误解决方法(ERROR 1045 (28000): Access denied for user ‘root‘@‘localhost‘ (using passwor:yes))_no connection. trying to reconnect... error 1045 (
- 2云上战场:ToDesk云电脑、青椒云、顺网云全面对决
- 3three.js 背景贴图有点失真_csdn three 贴图模糊
- 4Scikit-Learn (从入门到放弃)
- 5AIGC绘画设计基础:全网最全Midjourney出图关键词咒语汇总_midjourney垫图关键词
- 6已解决AttributeError: ‘str‘ object has no attribute ‘decode‘_str' object has no attribute 'decode
- 7MySQL数据库与java代码的连接_mysql连接java的包
- 8FPGA——Verilog基础语法_fpga assign
- 9[Algorithm][动态规划][01背包问题][目标和][最后一块石头的重量Ⅱ]详细讲解
- 105大经典排序算法在淘宝“有好货”场景的实践
【图像分类】【深度学习】【Pytorch版本】GoogLeNet(InceptionV3)模型算法详解
赞
踩
【图像分类】【深度学习】【Pytorch版本】GoogLeNet(InceptionV3)模型算法详解
前言
GoogLeNet(InceptionV3)是由谷歌的Szegedy, Christian等人在《Rethinking the Inception Architecture for Computer Vision【CVPR-2016】》【论文地址】一文中提出的带有Factorized Convolutions(分解卷积)的改进模型,即在InceptionV2的基础上将标准的卷积操作分解为1xN卷积和Nx1卷积两个步骤,这种分解模式可以显著降低参数量和计算量,同时在一定程度上保持了特征提取的能力。
GoogLeNet(InceptionV3)讲解
GoogLeNet团队在给出了一些通用的网络设计准则,以期望在不提高网络参数量的前提下提升网络的表达能力:
- 避免特征图(feature map)表达瓶颈:从理论上讲,尺寸(seize)才包含了相关结构等重要因素,维度(channel)仅仅提供了信息内容的粗略估计,因此特征图的尺寸应该从输入到输出慢慢减小,避免使用极端压缩。
- 更高的维度特征图更容易获得网络的局部表达:在卷积网络结构中,增加非线性能够使得更多的特征解耦合,相互独立的特征更多,输入的信息就被分解的更彻底,分解的子特征间相关性低,子特征内部相关性高,因此高维特征带有更多的判别信息,会更容易收敛。
- 在低维特征上的空间聚合(池化)不会(极少)损失太多信息:相邻的位置的信息具有强相关性,即使进行了降维,也不会带来太多的损失,并且维数的降低,也能够加速网络学习。
- 平衡网络的宽度与深度:最优的网络应该在每一层网络宽度和网络深度之间有个很好的平衡。
Factorized Convolutions卷积分解
分解卷积的主要目的是为了减少网络中的参数,主要方法有:大卷积分解成小卷积,小卷积分解为非对称卷积。

大卷积分解成小卷积: 大尺度的卷积可以获得更大的感受野,但是也带来参数量的增加,VggNet表明使用大于大卷积核(大于3×3)完全可以由一系列的3×3卷积核来替代,即使用小卷积核串联来替代大卷积核。因此在InceptionV2中已经通过堆叠两层3×3的卷积核的方式替代一层5×5的卷积核,这样的连接方式在保持感受野范围的同时又减少了参数量,不会造成表达缺失,降低网络性能,并且可以避免表达瓶颈,加深非线性表达能力。
小卷积分解为非对称卷积: 3x3卷积是能够完全获取上下文信息(上、下、左、右)的最小卷积核,是否能把小卷积核分解的更小呢?在InceptionV3中,GoogLeNet团队考虑了非对称卷积分解,引入了将一个较大的二维卷积拆成两个较小的一维卷积的做法,即任意n×n的卷积都可以通过1×n卷积后接n×1卷积来替代,非对称卷积能够降低运算量,并且不会降低模型的整体表征能力。
InceptionV3结构Ⅰ
与InceptionV2结构相同,即5x5卷积使用两个3x3的卷积代替,目的是减少参数量和计算量——大卷积分解成小卷积。

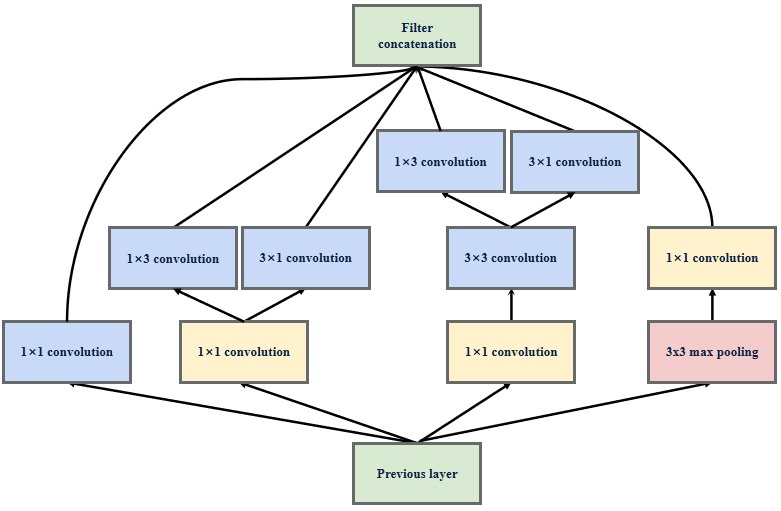
InceptionV3结构Ⅱ
将InceptionV2结构中3x3的卷积使用1x3和3x1的卷积组合来代替,5x5的卷积使用俩个1x3和3x1的卷积组合来代替,目的也是减少参数量和计算量———小卷积分解为非对称卷积。

采用这种分解在模型的早期网络层上不能有效发挥作用,但是在中等特征图大小(m×m,其中m在12和20之间的范围)上取得了非常好的效果。
使用3x3的卷积代替5x5的卷积,输出512通道特征图,输出128通道特征图:
参数量:512×3×3×128+128×3×3×128=737280
计算量:512×3×3×128×W×H+128×3×3×128×W×H=737280×W×H
W×H是特征图尺寸,假设卷积层的输入输出特征图尺寸保持一致
使用1x3和3x1的卷积组合代替5x5的卷积,输出512通道特征图,输出128通道特征图:
参数量:512×1×3×128+128×3×1×128+128×1×3×128+128×3×1×128=344064
计算量:512×1×3×128×W×H+128×3×1×128×W×H+128×1×3×128×W×H+128×3×1×128×W×H=344064×W×H
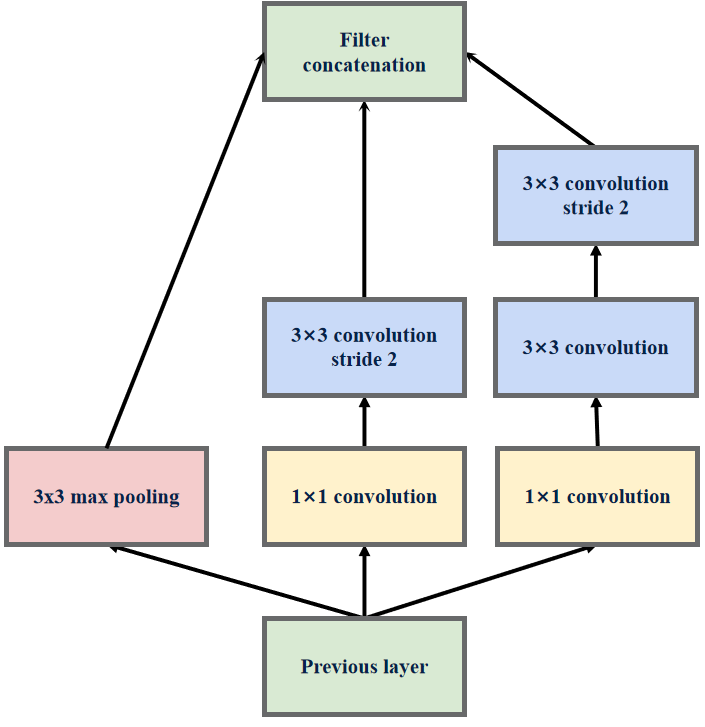
InceptionV3结构Ⅲ
该结构主要用于扩充通道数,网络变得更宽,该结构被放置在所以放在GoogLeNet(InceptionV3)的最后。
InceptionV3特殊结构
在传统方法中,卷积神经网络使用池化等操作以减小特征图大小。先池化再进行卷积升维会导致瓶颈结构,过程中将丢失很多信息,对于后面输出的特征图提取的图像中的特征将会更少;先卷积升维再进行池化,计算量将增加三倍,增加了计算成本:

GoogLeNet(InceptionV3)的改进方案采用一种并行的降维结构,在扩充通道数的同时下采样减小特征图大小,既减少计算量保证了计算效率又避免了瓶颈结构。
替换GoogLeNet(InceptionV1)模型中的MaxPool。
辅助分类器
GoogLeNet(InceptionV1)引入了辅助分类器的概念,最初的动机是为了将有用的梯度反向传递到网络低层,解决梯度消失的问题,提高网络的收敛能力,保证网络训练正常进行。
GoogLeNet(InceptionV3)的实验则发现1.辅助分类器并不能保证收敛更快,并且有无辅助分类器,训练过程基本保持一致,只有在训练的最后阶段,有辅助分类器略微高于无辅助分类器的网络;2.位于网络低层的辅助分类器对最终结果没有影响;3.辅助分类器充当了正则化器,如果辅助分类器带有BN或Dropout层那么主分类器性能会更好。

GoogLeNet(InceptionV3)中的辅助分类器同样不直接用于最终的预测结果。在训练过程中,辅助分类器的损失函数会被加权,并与主分类器的损失函数相结合。在推理阶段,辅助分类器被舍弃,仅使用主分类器进行预测。
GoogLeNet(InceptionV3)模型结构
下图是原论文给出的关于 GoogLeNet(InceptionV3)模型结构的详细示意图:
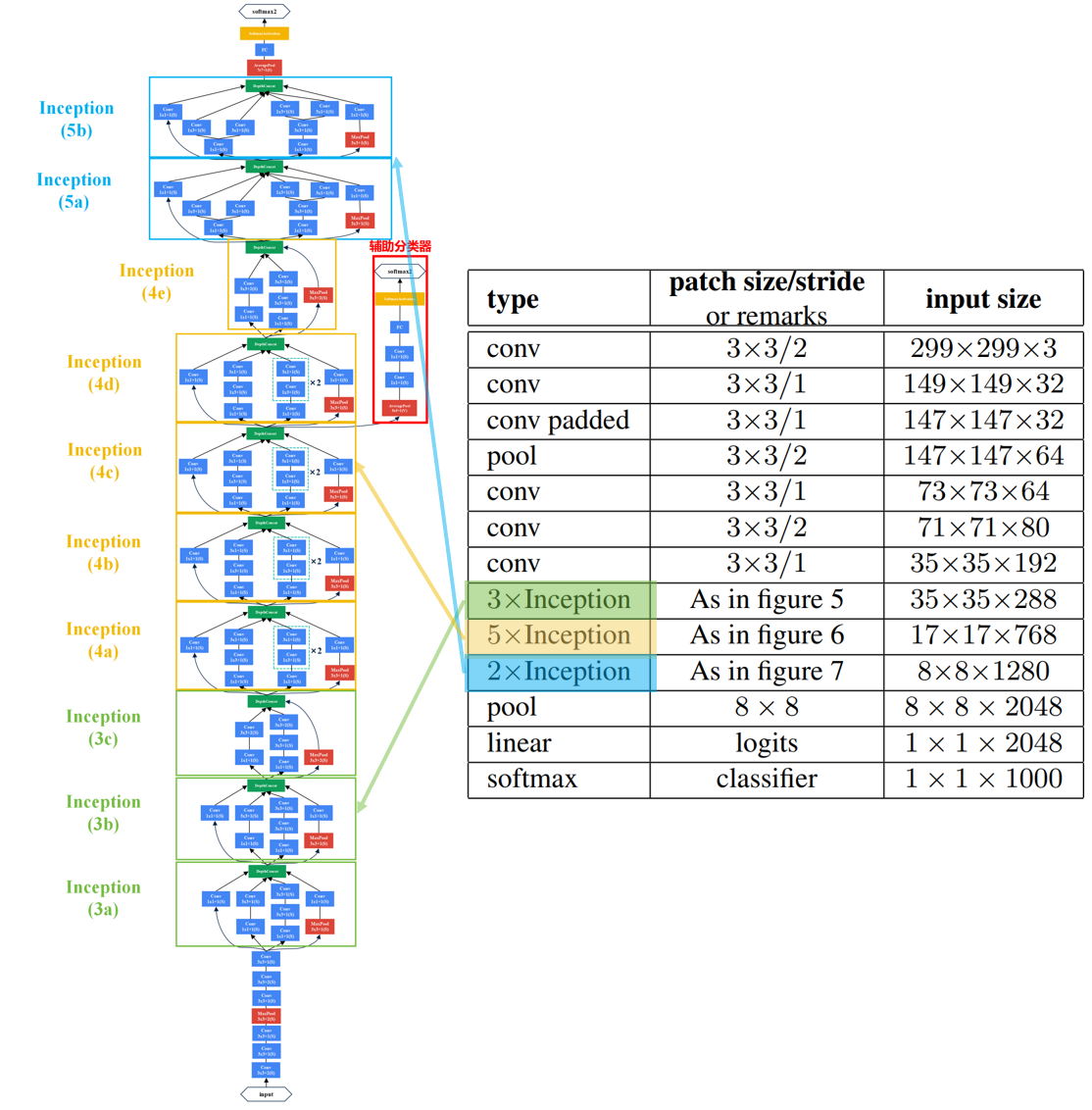
GoogLeNet(InceptionV3)在图像分类中分为两部分:backbone部分: 主要由InceptionV3模块、卷积层和池化层(汇聚层)组成,分类器部分: 由主分类器和辅助分类器组成。
博主仿造GoogLeNet(InceptionV1)的结构绘制了以下GoogLeNet(InceptionV3)的结构。

GoogLeNet(InceptionV3) Pytorch代码
卷积层组: 卷积层+BN层+激活函数
# 卷积组: Conv2d+BN+ReLU
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
self.bn = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
InceptionV3模块Ⅰ: 卷积层组+池化层
就是原始的InceptionV2模块
# InceptionV3A:BasicConv2d+MaxPool2d class InceptionV3A(nn.Module): def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch3x3redX2, ch3x3X2, pool_proj): super(InceptionV3A, self).__init__() # 1×1卷积 self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1) # 1×1卷积+3×3卷积 self.branch2 = nn.Sequential( BasicConv2d(in_channels, ch3x3red, kernel_size=1), BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1) # 保证输出大小等于输入大小 ) # 1×1卷积++3×3卷积+3×3卷积 self.branch3 = nn.Sequential( BasicConv2d(in_channels, ch3x3redX2, kernel_size=1), BasicConv2d(ch3x3redX2, ch3x3X2, kernel_size=3, padding=1), BasicConv2d(ch3x3X2, ch3x3X2, kernel_size=3, padding=1) # 保证输出大小等于输入大小 ) # 3×3池化+1×1卷积 self.branch4 = nn.Sequential( nn.MaxPool2d(kernel_size=3, stride=1, padding=1), BasicConv2d(in_channels, pool_proj, kernel_size=1) ) def forward(self, x): branch1 = self.branch1(x) branch2 = self.branch2(x) branch3 = self.branch3(x) branch4 = self.branch4(x) # 拼接 outputs = [branch1, branch2, branch3, branch4] return torch.cat(outputs, 1)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
InceptionV3模块Ⅱ: 卷积层组+池化层
# InceptionV3B:BasicConv2d+MaxPool2d class InceptionV3B(nn.Module): def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch3x3redX2, ch3x3X2, pool_proj): super(InceptionV3B, self).__init__() # 1×1卷积 self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1) # 1×1卷积+1×3卷积+3×1卷积 self.branch2 = nn.Sequential( BasicConv2d(in_channels, ch3x3red, kernel_size=1), BasicConv2d(ch3x3red, ch3x3, kernel_size=[1, 3], padding=[0, 1]), BasicConv2d(ch3x3, ch3x3, kernel_size=[3, 1], padding=[1, 0]) # 保证输出大小等于输入大小 ) # 1×1卷积+1×3卷积+3×1卷积+1×3卷积+3×1卷积 self.branch3 = nn.Sequential( BasicConv2d(in_channels, ch3x3redX2, kernel_size=1), BasicConv2d(ch3x3redX2, ch3x3X2, kernel_size=[1, 3], padding=[0, 1]), BasicConv2d(ch3x3X2, ch3x3X2, kernel_size=[3, 1], padding=[1, 0]), BasicConv2d(ch3x3X2, ch3x3X2, kernel_size=[1, 3], padding=[0, 1]), BasicConv2d(ch3x3X2, ch3x3X2, kernel_size=[3, 1], padding=[1, 0]) # 保证输出大小等于输入大小 ) # 3×3池化+1×1卷积 self.branch4 = nn.Sequential( nn.MaxPool2d(kernel_size=3, stride=1, padding=1), BasicConv2d(in_channels, pool_proj, kernel_size=1) ) def forward(self, x): branch1 = self.branch1(x) branch2 = self.branch2(x) branch3 = self.branch3(x) branch4 = self.branch4(x) # 拼接 outputs = [branch1, branch2, branch3, branch4] return torch.cat(outputs, 1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
InceptionV3模块Ⅲ: 卷积层组+池化层
# InceptionV3C:BasicConv2d+MaxPool2d class InceptionV3C(nn.Module): def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch3x3redX2, ch3x3X2, pool_proj): super(InceptionV3C, self).__init__() # 1×1卷积 self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1) # 1×1卷积+1×3卷积+3×1卷积 self.branch2_0 = BasicConv2d(in_channels, ch3x3red, kernel_size=1) self.branch2_1 = BasicConv2d(ch3x3red, ch3x3, kernel_size=[1, 3], padding=[0, 1]) self.branch2_2 = BasicConv2d(ch3x3red, ch3x3, kernel_size=[3, 1], padding=[1, 0]) # 1×1卷积+3×3卷积+1×3卷积+3×1卷积 self.branch3_0 = nn.Sequential( BasicConv2d(in_channels, ch3x3redX2, kernel_size=1), BasicConv2d(ch3x3redX2, ch3x3X2, kernel_size=3, padding=1), ) self.branch3_1 = BasicConv2d(ch3x3X2, ch3x3X2, kernel_size=[1, 3], padding=[0, 1]) self.branch3_2 = BasicConv2d(ch3x3X2, ch3x3X2, kernel_size=[3, 1], padding=[1, 0]) # 3×3池化+1×1卷积 self.branch4 = nn.Sequential( nn.MaxPool2d(kernel_size=3, stride=1, padding=1), BasicConv2d(in_channels, pool_proj, kernel_size=1) ) def forward(self, x): branch1 = self.branch1(x) branch2_0 = self.branch2_0(x) branch2 = torch.cat([self.branch2_1(branch2_0), self.branch2_2(branch2_0)], dim=1) branch3_0 = self.branch3_0(x) branch3 = torch.cat([self.branch3_1(branch3_0), self.branch3_2(branch3_0)], dim=1) branch4 = self.branch4(x) # 拼接 outputs = [branch1, branch2, branch3, branch4] return torch.cat(outputs, 1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
InceptionV3特殊模块(三分支): 卷积层组+池化层
# InceptionV3D:BasicConv2d+MaxPool2d class InceptionV3D(nn.Module): def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch3x3redX2, ch3x3X2, pool_proj): super(InceptionV3D, self).__init__() # ch1x1:没有1×1卷积 # 1×1卷积+3×3卷积,步长为2 self.branch1 = nn.Sequential( BasicConv2d(in_channels, ch3x3red, kernel_size=1), BasicConv2d(ch3x3red, ch3x3, kernel_size=3, stride=2) ) # 1×1卷积+3×3卷积+3×3卷积,步长为2 self.branch2 = nn.Sequential( BasicConv2d(in_channels, ch3x3redX2, kernel_size=1), BasicConv2d(ch3x3redX2, ch3x3X2, kernel_size=3, padding=1), # 保证输出大小等于输入大小 BasicConv2d(ch3x3X2, ch3x3X2, kernel_size=3, stride=2) ) # 3×3池化,步长为2 self.branch3 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=2)) # pool_proj:池化层后不再接卷积层 def forward(self, x): branch1 = self.branch1(x) branch2 = self.branch2(x) branch3 = self.branch3(x) # 拼接 outputs = [branch1,branch2, branch3] return torch.cat(outputs, 1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
辅助分类器: 池化层+卷积层组+全连接层+dropout
# 辅助分类器:AvgPool2d+BasicConv2d+Linear+dropout class InceptionAux(nn.Module): def __init__(self, in_channels, out_channels): super(InceptionAux, self).__init__() self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3) self.conv1 = BasicConv2d(in_channels=in_channels, out_channels=128, kernel_size=1) self.conv2 = BasicConv2d(in_channels=128, out_channels=768, kernel_size=5, stride=1) self.dropout = nn.Dropout(p=0.7) self.linear = nn.Linear(in_features=768, out_features=out_channels) def forward(self, x): # N x 768 x 17 x 17 x = self.averagePool(x) # N x 768 x 5 x 5 x = self.conv1(x) # N x 128 x 5 x 5 x = self.conv2(x) # N x 768 x 1 x 1 x = x.view(x.size(0), -1) # N x 768 out = self.linear(self.dropout(x)) # N x num_classes return out
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
完整代码
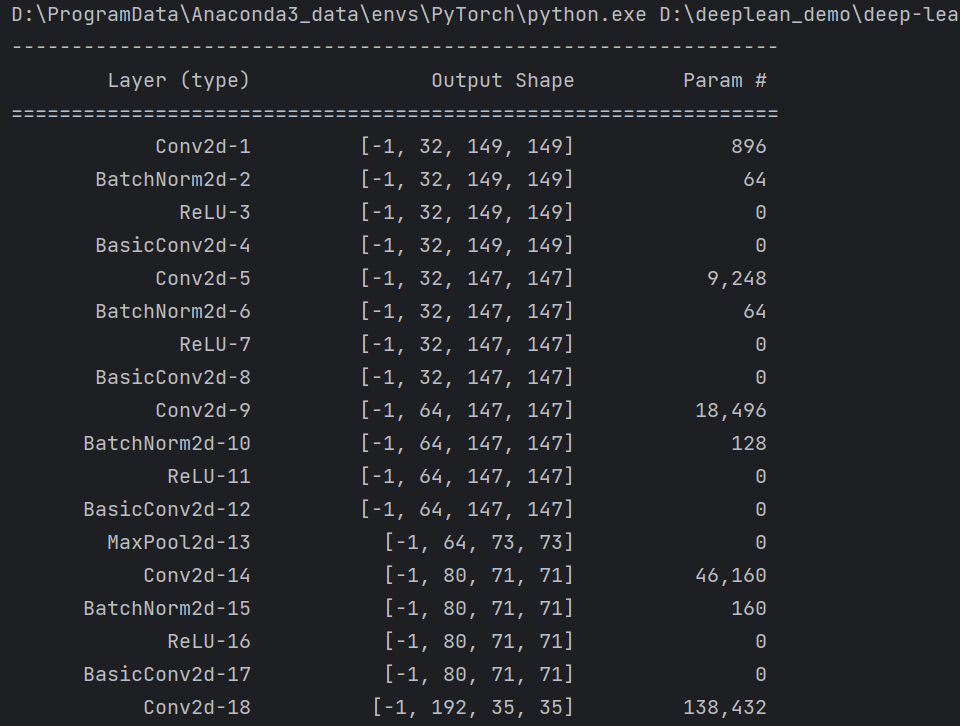
GoogLeNet(InceptionV3)的输入图像尺寸是299×299
import torch.nn as nn import torch from torchsummary import summary class GoogLeNetV3(nn.Module): def __init__(self, num_classes=1000, aux_logits=True, init_weights=False): super(GoogLeNetV3, self).__init__() self.aux_logits = aux_logits # 3个3×3卷积替代7×7卷积 self.conv1_1 = BasicConv2d(3, 32, kernel_size=3, stride=2) self.conv1_2 = BasicConv2d(32, 32, kernel_size=3, stride=1) self.conv1_3 = BasicConv2d(32, 64, kernel_size=3, stride=1, padding=1) # 池化层 self.maxpool1 = nn.MaxPool2d(3, stride=2, ceil_mode=True) self.conv2 = BasicConv2d(64, 80, kernel_size=3) self.conv3 = BasicConv2d(80, 192, kernel_size=3, stride=2) self.conv4 = BasicConv2d(192, 192, kernel_size=3, padding=1) self.inception3a = InceptionV3A(192, 64, 48, 64, 64, 96, 32) self.inception3b = InceptionV3A(256, 64, 48, 64, 64, 96, 64) self.inception3c = InceptionV3A(288, 64, 48, 64, 64, 96, 64) self.inception4a = InceptionV3D(288, 0, 384, 384, 64, 96, 0) self.inception4b = InceptionV3B(768, 192, 128, 192, 128, 192, 192) self.inception4c = InceptionV3B(768, 192, 160, 192, 160, 192, 192) self.inception4d = InceptionV3B(768, 192, 160, 192, 160, 192, 192) self.inception4e = InceptionV3D(768, 0, 384, 384, 64, 128, 0) if self.aux_logits == True: self.aux = InceptionAux(in_channels=768, out_channels=num_classes) self.inception5a = InceptionV3C(1280, 320, 384, 384, 448, 384, 192) self.inception5b = InceptionV3C(2048, 320, 384, 384, 448, 384, 192) self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) self.dropout = nn.Dropout(0.5) self.fc = nn.Linear(2048, num_classes) if init_weights: self._initialize_weights() def forward(self, x): # N x 3 x 299 x 299 x = self.conv1_1(x) # N x 32 x 149 x 149 x = self.conv1_2(x) # N x 32 x 147 x 147 x = self.conv1_3(x) # N x 32 x 147 x 147 x = self.maxpool1(x) # N x 64 x 73 x 73 x = self.conv2(x) # N x 80 x 71 x 71 x = self.conv3(x) # N x 192 x 35 x 35 x = self.conv4(x) # N x 192 x 35 x 35 x = self.inception3a(x) # N x 256 x 35 x 35 x = self.inception3b(x) # N x 288 x 35 x 35 x = self.inception3c(x) # N x 288 x 35x 35 x = self.inception4a(x) # N x 768 x 17 x 17 x = self.inception4b(x) # N x 768 x 17 x 17 x = self.inception4c(x) # N x 768 x 17 x 17 x = self.inception4d(x) # N x 768 x 17 x 17 if self.training and self.aux_logits: # eval model lose this layer aux = self.aux(x) # N x 768 x 17 x 17 x = self.inception4e(x) # N x 1280 x 8 x 8 x = self.inception5a(x) # N x 2048 x 8 x 8 x = self.inception5b(x) # N x 2048 x 7 x 7 x = self.avgpool(x) # N x 2048 x 1 x 1 x = torch.flatten(x, 1) # N x 1024 x = self.dropout(x) x = self.fc(x) # N x 1000(num_classes) if self.training and self.aux_logits: # 训练阶段使用 return x, aux return x # 对模型的权重进行初始化操作 def _initialize_weights(self): for m in self.modules(): if isinstance(m, nn.Conv2d): nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu') if m.bias is not None: nn.init.constant_(m.bias, 0) elif isinstance(m, nn.Linear): nn.init.normal_(m.weight, 0, 0.01) nn.init.constant_(m.bias, 0) # InceptionV3A:BasicConv2d+MaxPool2d class InceptionV3A(nn.Module): def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch3x3redX2, ch3x3X2, pool_proj): super(InceptionV3A, self).__init__() # 1×1卷积 self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1) # 1×1卷积+3×3卷积 self.branch2 = nn.Sequential( BasicConv2d(in_channels, ch3x3red, kernel_size=1), BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1) # 保证输出大小等于输入大小 ) # 1×1卷积++3×3卷积+3×3卷积 self.branch3 = nn.Sequential( BasicConv2d(in_channels, ch3x3redX2, kernel_size=1), BasicConv2d(ch3x3redX2, ch3x3X2, kernel_size=3, padding=1), BasicConv2d(ch3x3X2, ch3x3X2, kernel_size=3, padding=1) # 保证输出大小等于输入大小 ) # 3×3池化+1×1卷积 self.branch4 = nn.Sequential( nn.MaxPool2d(kernel_size=3, stride=1, padding=1), BasicConv2d(in_channels, pool_proj, kernel_size=1) ) def forward(self, x): branch1 = self.branch1(x) branch2 = self.branch2(x) branch3 = self.branch3(x) branch4 = self.branch4(x) # 拼接 outputs = [branch1, branch2, branch3, branch4] return torch.cat(outputs, 1) # InceptionV3B:BasicConv2d+MaxPool2d class InceptionV3B(nn.Module): def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch3x3redX2, ch3x3X2, pool_proj): super(InceptionV3B, self).__init__() # 1×1卷积 self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1) # 1×1卷积+1×3卷积+3×1卷积 self.branch2 = nn.Sequential( BasicConv2d(in_channels, ch3x3red, kernel_size=1), BasicConv2d(ch3x3red, ch3x3, kernel_size=[1, 3], padding=[0, 1]), BasicConv2d(ch3x3, ch3x3, kernel_size=[3, 1], padding=[1, 0]) # 保证输出大小等于输入大小 ) # 1×1卷积+1×3卷积+3×1卷积+1×3卷积+3×1卷积 self.branch3 = nn.Sequential( BasicConv2d(in_channels, ch3x3redX2, kernel_size=1), BasicConv2d(ch3x3redX2, ch3x3X2, kernel_size=[1, 3], padding=[0, 1]), BasicConv2d(ch3x3X2, ch3x3X2, kernel_size=[3, 1], padding=[1, 0]), BasicConv2d(ch3x3X2, ch3x3X2, kernel_size=[1, 3], padding=[0, 1]), BasicConv2d(ch3x3X2, ch3x3X2, kernel_size=[3, 1], padding=[1, 0]) # 保证输出大小等于输入大小 ) # 3×3池化+1×1卷积 self.branch4 = nn.Sequential( nn.MaxPool2d(kernel_size=3, stride=1, padding=1), BasicConv2d(in_channels, pool_proj, kernel_size=1) ) def forward(self, x): branch1 = self.branch1(x) branch2 = self.branch2(x) branch3 = self.branch3(x) branch4 = self.branch4(x) # 拼接 outputs = [branch1, branch2, branch3, branch4] return torch.cat(outputs, 1) # InceptionV3C:BasicConv2d+MaxPool2d class InceptionV3C(nn.Module): def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch3x3redX2, ch3x3X2, pool_proj): super(InceptionV3C, self).__init__() # 1×1卷积 self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1) # 1×1卷积+1×3卷积+3×1卷积 self.branch2_0 = BasicConv2d(in_channels, ch3x3red, kernel_size=1) self.branch2_1 = BasicConv2d(ch3x3red, ch3x3, kernel_size=[1, 3], padding=[0, 1]) self.branch2_2 = BasicConv2d(ch3x3red, ch3x3, kernel_size=[3, 1], padding=[1, 0]) # 1×1卷积+3×3卷积+1×3卷积+3×1卷积 self.branch3_0 = nn.Sequential( BasicConv2d(in_channels, ch3x3redX2, kernel_size=1), BasicConv2d(ch3x3redX2, ch3x3X2, kernel_size=3, padding=1), ) self.branch3_1 = BasicConv2d(ch3x3X2, ch3x3X2, kernel_size=[1, 3], padding=[0, 1]) self.branch3_2 = BasicConv2d(ch3x3X2, ch3x3X2, kernel_size=[3, 1], padding=[1, 0]) # 3×3池化+1×1卷积 self.branch4 = nn.Sequential( nn.MaxPool2d(kernel_size=3, stride=1, padding=1), BasicConv2d(in_channels, pool_proj, kernel_size=1) ) def forward(self, x): branch1 = self.branch1(x) branch2_0 = self.branch2_0(x) branch2 = torch.cat([self.branch2_1(branch2_0), self.branch2_2(branch2_0)], dim=1) branch3_0 = self.branch3_0(x) branch3 = torch.cat([self.branch3_1(branch3_0), self.branch3_2(branch3_0)], dim=1) branch4 = self.branch4(x) # 拼接 outputs = [branch1, branch2, branch3, branch4] return torch.cat(outputs, 1) # InceptionV3D:BasicConv2d+MaxPool2d class InceptionV3D(nn.Module): def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch3x3redX2, ch3x3X2, pool_proj): super(InceptionV3D, self).__init__() # ch1x1:没有1×1卷积 # 1×1卷积+3×3卷积,步长为2 self.branch1 = nn.Sequential( BasicConv2d(in_channels, ch3x3red, kernel_size=1), BasicConv2d(ch3x3red, ch3x3, kernel_size=3, stride=2) ) # 1×1卷积+3×3卷积+3×3卷积,步长为2 self.branch2 = nn.Sequential( BasicConv2d(in_channels, ch3x3redX2, kernel_size=1), BasicConv2d(ch3x3redX2, ch3x3X2, kernel_size=3, padding=1), # 保证输出大小等于输入大小 BasicConv2d(ch3x3X2, ch3x3X2, kernel_size=3, stride=2) ) # 3×3池化,步长为2 self.branch3 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=2)) # pool_proj:池化层后不再接卷积层 def forward(self, x): branch1 = self.branch1(x) branch2 = self.branch2(x) branch3 = self.branch3(x) # 拼接 outputs = [branch1,branch2, branch3] return torch.cat(outputs, 1) # 辅助分类器:AvgPool2d+BasicConv2d+Linear+dropout class InceptionAux(nn.Module): def __init__(self, in_channels, out_channels): super(InceptionAux, self).__init__() self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3) self.conv1 = BasicConv2d(in_channels=in_channels, out_channels=128, kernel_size=1) self.conv2 = BasicConv2d(in_channels=128, out_channels=768, kernel_size=5, stride=1) self.dropout = nn.Dropout(p=0.7) self.linear = nn.Linear(in_features=768, out_features=out_channels) def forward(self, x): # N x 768 x 17 x 17 x = self.averagePool(x) # N x 768 x 5 x 5 x = self.conv1(x) # N x 128 x 5 x 5 x = self.conv2(x) # N x 768 x 1 x 1 x = x.view(x.size(0), -1) # N x 768 out = self.linear(self.dropout(x)) # N x num_classes return out # 卷积组: Conv2d+BN+ReLU class BasicConv2d(nn.Module): def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0): super(BasicConv2d, self).__init__() self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding) self.bn = nn.BatchNorm2d(out_channels) self.relu = nn.ReLU(inplace=True) def forward(self, x): x = self.conv(x) x = self.bn(x) x = self.relu(x) return x if __name__ == '__main__': device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") model = GoogLeNetV3().to(device) summary(model, input_size=(3, 299, 299))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
summary可以打印网络结构和参数,方便查看搭建好的网络结构。
总结
尽可能简单、详细的介绍了小卷积分解为非对称卷积的原理和在卷积神经网络中的作用,讲解了GoogLeNet(InceptionV3)模型的结构和pytorch代码。

