
- 1win7安装spacy_spacy 依赖包
- 2【软件评测师】软件评测师教程(第2版):目录脑图_软件测评师教程第二版电子版
- 3关于Mysql的日期时间类型区分、比较和常用函数_mysql时间比较函数
- 4【阿里云原生架构】二、云原生架构的原则和模式_云原生架构本身作为一种架构,也有若干架构原则作为应用架构的核心架构控制面,通过
- 5怎样使用git add命令将当前修改的两个乃至多个文件一次性全部加入暂存区,不包括未跟踪的文件_git add.后没有全部进入缓存区
- 6面经|顺丰科技-大数据挖掘与数据分析工程师|一面|30min_顺丰科技nlp
- 7Sourcetree 克隆仓库,提交代码使用_sourcetree克隆仓库
- 8FS312 PD诱骗器芯片_fs312诱骗芯片
- 9Git、GitHub和GitLab的区别_gitlab和github的区别
- 10关系型数据库和非关系型数据库
从原理到实现教你搞定大模型在线推理架构
赞
踩
▼最近直播超级多,预约保你有收获
今晚直播:《大模型在线推理架构设计与实践》
—1—
大模型在线推理工程架构设计
LLM 大模型整体架构由离线和在线两部分构成(架构如下图所示),离线部分主要是基于 Transformer 架构的预训练(Pre-training)和微调(Fine-tuning),在线部分核心是在线工程推理架构。
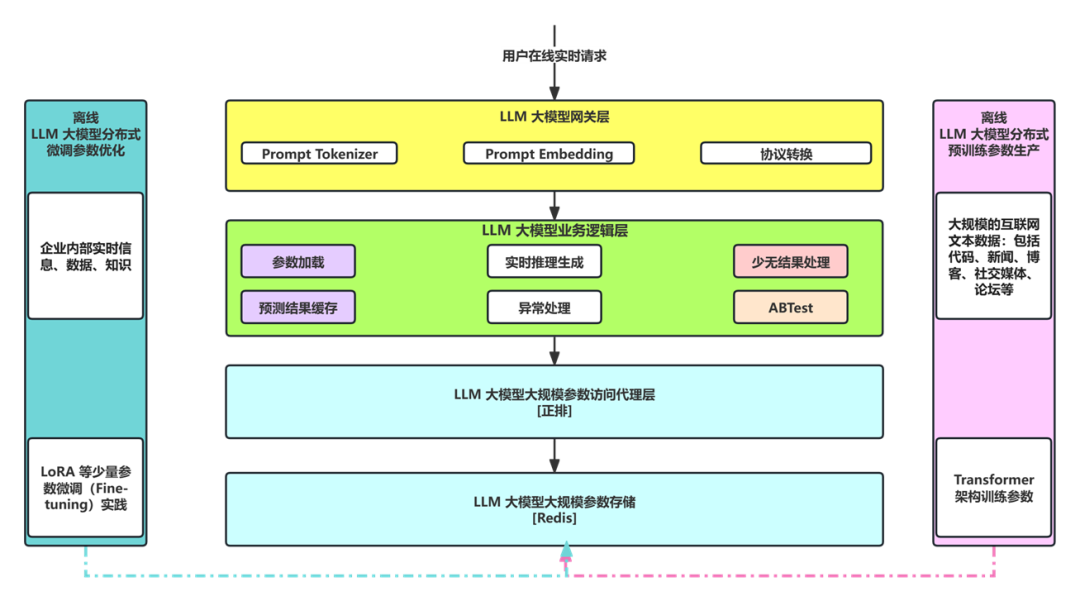
在线工程推理架构负责根据用于输入的 Prompt 提示词(比如:双12马上到了,应该给程序员提供什么样的学习福利?)给出准确的答复(比如:AIGC 学习计划)。
我们详细剖析下在线推理架构是如何实现整个流程的?
第一步:LLM 大模型网关层收到用户的 Prompt(比如:双12马上到了,应该给程序员提供什么样的学习福利?),把 Prompt 进行 Tokenizer 分词,并编码成对应的 Token(比如:“双12”对应 token 为 88、“马上”对应 token 为 1205、“到了”对应 token 为 2024 等等),进一步把 tokens Embedding 成对应的向量(比如:采用 ChatGPT 的 text-embedding-ada-002 模型来向量化,每个 token 生成 1536 维的向量)。
第二步:LLM 大模型业务逻辑层接收到 LLM 大模型网关层的 Request 请求(向量数据),对接收到的向量数据基于 Transformer 架构进行自回归推理,不断预测出下一个 token,直到预测出 EOS(End Of Sentence)结束符,比如:针对上一步的预测答复为:AIGC 学习计划。
LLM 大模型业务逻辑层除了完成自回归的结果实时预测生成外,还需要加载大模型海量的参数(比如:GPT 3 有 1750 个 Float 参数组成,需要 700G的显存)、预测结果缓存、少无结果处理、异常处理以及 ABTest。
LLM 大模型业务逻辑层在启动时需要动态 RPC 请求 LLM 大模型大规模参数访问代理层,访问代理层会进一步远程访问 LLM 大模型大规模存储层(比如:分布式缓存 Redis 集群)获取到海量参数数据。
由于参数量比较大,这里有两大工程架构难点:如何快速加载完毕?如何并行计算呢?我会在今晚的直播中和同学们详细剖析,请同学们点击以下按钮免费预约。
大模型业务逻辑层缓存预测结果会大大降低 GPU 的推理成本,这里也有一大难点,同样在今晚的直播中和同学们一一详细剖析。
—2—
大模型在线推理工程架构几个核心技术设计
第一、大模型在线推理工程架构高可用如何设计?
架构高可用设计的核心是服务的无状态化(Stateless)设计,做到了冗余部署的服务完全对等,也就做到了服务的无状态化,从而实现了大模型在线架构的高可用。
第二、大模型在线推理工程架构高性能如何设计?
大模型在线架构的高性能有两个考核指标:吞吐量(Throughput)和平均响应延迟(Response Time)。
通过加大在线服务数量可以大幅提升大模型的吞吐量,那么平均响应延迟如何降低呢?
第三、大模型在线推理工程架构设计和选型?
大模型在线推理工程架构是否可以才能用微服务架构来设计?具体设计的原则是什么?选型为 Spring Cloud 微服务开发框架是否可以?
第四、大模型在线推理工程架构服务治理如何设计?
大模型在线推理服务部署是否可以采用云原生架构来部署治理?可观测性架构是否可以选用 Prometheus?
第五、大模型在线推理工程架构部署机器如何选型?
大模型网关层、业务逻辑层、数据访问层、数据存储层都各需要什么类型的机器?需要 CPU 类型的机器还是 GPU 类型的机器?机器需要什么样的配置?
相信同学们很想知道答案和实践落地步骤,今晚20点的直播中详细剖析,请同学们点击免费预约。
总之,掌握好 LLM 大模型在线推理工程架构和落地实现,对于 IT 人来说是一项非常重要的技能。
—3—
纯干货 LLM 大模型在线推理技术实战直播
为了帮助同学们掌握好 LLM 大模型在线推理工程技术架构和落地实现,今晚20点,我会开一场直播和同学们深度聊聊:
第一、LLM 大模型在线推理总体架构设计;
第二、LLM 大模型在线推理核心技术设计剖析;
第三、基于大模型构建企业级推荐系统案例实战;
请同学点击下方按钮预约直播,咱们今晚20点直播间!
今晚直播:《大模型在线推理架构设计与实践》
END

