
- 1C++:在“替代”中迎来“转机”的 2022 年!_c++23发布时间
- 2nginx location中uri的截取的实现方法_nginx location获取uri的第一部分
- 3taro转rn-ios(个人记录,第一次搞,有误请指正:))_taro rn
- 4【python】PyQt5控件尺寸大小位置,内容边距等API调用方法实战解析_pyqt5 控件位置
- 5拥抱AI 时代:《LangChain入门指南》高清PDF免费分享!_langchain入门指南pdf版
- 6【技术分享】在RK3568上如何烧录MAC_usb烧录mac地址
- 7PySide6/PyQT多线程之 编程入门指南:基础概念和最佳实践_pyside多线程
- 8树莓派玩转openwrt软路由:5.OpenWrt防火墙配置及SSH连接_openwrt防火墙设置
- 9ethercat驱动器接线_协作机器人、关节模组驱动器推荐
- 10flask修改密码功能的实现_flask appbuilder中的resetpassword
Generative AI for Beginners_generative-ai-for-beginners
赞
踩
Generative AI for Beginners 微软推出的面向初学者的免费生成式人工智能课程。
| 课程章节 | 相关教学内容 | 学习目标 |
|---|---|---|
| 课程介绍和学习环境设置 | 学习环境配置和课程结构 | 在学习本课程的同时帮助您取得成功 |
| 生成式人工智能和 LLMs 介绍 | 知识点: 生成式人工智能以及我们如何适应当前的技术格局 | 了解什么是生成式人工智能 以及 LLMs 的工作原理。 |
| 探索和比较不同的 LLMs | 知识点: 测试、迭代和比较不同的 LLMs 模型 | 为您的应用场景选择正确的模型 |
| 负责任地使用生成式人工智能 | 知识点: 了解基础模型的局限性和人工智能背后的风险 | 了解如何负责任地构建生成式人工智能应用程序 |
| 提示工程基础 | 代码/知识点: 提示工程最佳实践 | 了解提示结构和用法 |
| 创建高级的提示工程技巧 | 代码/知识点: 通过在提示中应用不同的技术来扩展您的提示工程知识 | 应用提示工程技术来改善提示结果。 |
| 创建文本生成应用 | 代码: 使用 Azure OpenAI 构建文本生成应用程序 | 了解如何有效地使用令牌和温度来改变模型的输出 |
| 创建聊天应用 | 代码: 有效构建和集成聊天应用程序的技术。 | 确定关键指标和注意事项,以有效监控和维护人工智能聊天应用程序的质量 |
| 创建搜索应用 | 代码: 语义搜索与关键字搜索。 什么是文本嵌入以及它们如何应用于搜索 | 创建一个使用嵌入来搜索数据的应用程序。 |
| 创建图像生成应用 | 代码: 图像生成及其在构建应用程序中的作用 | 构建图像生成应用程序 |
| 创建低代码的人工智能应用 | 低代码: Power Platform 中的生成式 AI 简介 | 使用低代码为我们的教育初创公司构建学生作业跟踪应用程序 |
| 为生成式 AI 添加 function calling | 代码: 什么是 Function Calling 及其在应用程序中的使用示例 | 设置 Function Calling 以从外部 API 检索数据 |
| 为人工智能应用程序添加用户体验 | 知识点: 设计人工智能应用程序以实现信任和透明度 | 开发生成式人工智能应用时用户体验设计的相关原则 |
| 拓展学习 | 包含每章内容的的拓展链接! | 掌握生成式人工智能相关技能 |
文档:microsoft.github.io/generative-ai-for-beginners
git地址:github.com/microsoft/generative-ai-for-beginners
其他学习途径:哈佛cs50课程
课程准备
课程整体有18章节,如下图,
在cn的readme中有详细的课程步骤,比如创建虚拟环境或者直接使用jupyter notebook环境。
Jupyter Notebook 的本质是一个 Web 应用程序,便于创建和共享程序文档,支持实时代码,数学方程,可视化和 markdown。可以看作是一个支持40多种编程语言的web编辑器。
生成式人工智能和 LLMs(Large Language Model) 介绍
有微软的导学视频:introduction to generative AI and LLMs
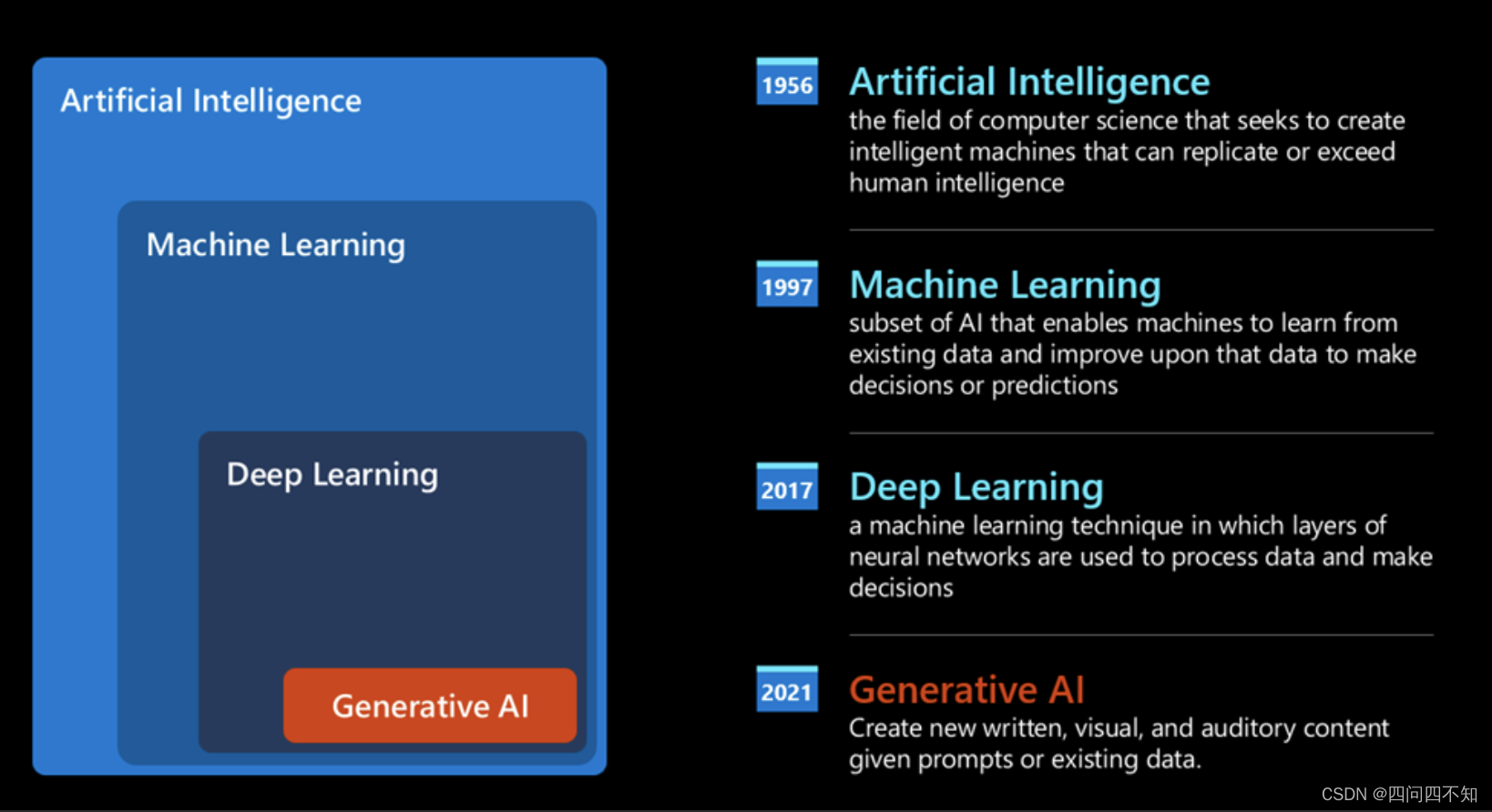
人工智能的诞生
它可以看作是深度学习的一个子集。
LLMs如何工作?
在下一章中,我们将探索不同类型的生成式 AI 模型,但现在让我们看看大型语言模型是如何工作的,重点是 OpenAI GPT(生成式预训练 Transformer)模型。
-
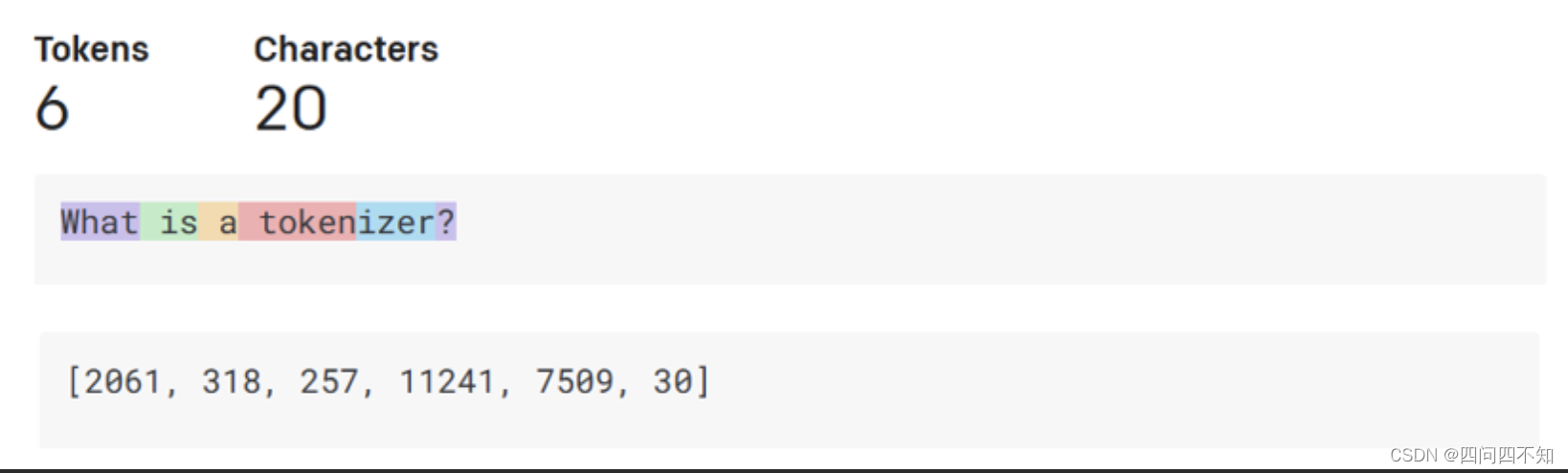
分词器,文本到数字:大型语言模型接收文本作为输入并生成文本作为输出。 然而,作为统计模型,它们对数字的处理效果对比起文本序列的处理效果要好得多。 这就是为什么模型的每个输入在被核心模型使用之前都由分词器处理。 标记是一段文本——由可变数量的字符组成,因此标记器的主要任务是将输入分割成标记数组。 然后,每个令牌都映射有一个令牌索引,该索引是原始文本块的整数编码。
-
预测输出标记:给定 n 个标记作为输入(最大 n 因模型而异),模型能够预测一个标记作为输出。 然后,该标记会以扩展窗口模式合并到下一次迭代的输入中,从而获得一个(或多个)句子作为答案,生成结果有更好的用户体验。 这解释了为什么如果您曾经使用过 ChatGPT,您可能会注意到有时它在生成结果时在句子中间出现停顿。
-
选择过程,概率分布:模型根据其在当前文本序列之后出现的概率来选择输出标记。 这是因为该模型预测了根据其训练计算出的所有可能的“下一个标记”的概率分布。 然而,并不总是从结果分布中选择概率最高的标记。 这种选择增加了一定程度的随机性,模型以非确定性方式运行——对于相同的输入,我们不会得到完全相同的输出。 添加这种程度的随机性是为了模拟人类创造性思维的过程,您可以使用称为温度的模型参数进行调整。
“Our startup” 如何利用 LLMs ?
现在我们对 LLMs 的内部工作有了更好的了解,让我们看看它们可以很好地执行的最常见任务的一些实际示例,并着眼于我们的业务场景。 我们说过, LLMs 的主要功能是从头开始生成文本,从文本输入开始,用自然语言编写。
但是是什么样的文本输入和输出呢? 大型语言模型的输入称为提示,而输出称为补全,术语指的是生成下一个标记来完成当前输入的模型机制。 我们将深入探讨什么是提示以及如何设计它以充分和我们的模型进行交流。 但现在,我们假设提示可能包括:
通过一条指令,指定我们期望模型输出的类型。 该指令有时可能会嵌入一些示例或一些附加数据。
-
i. 文章、书籍、产品评论等的总结,以及从非结构化数据中提取见解。
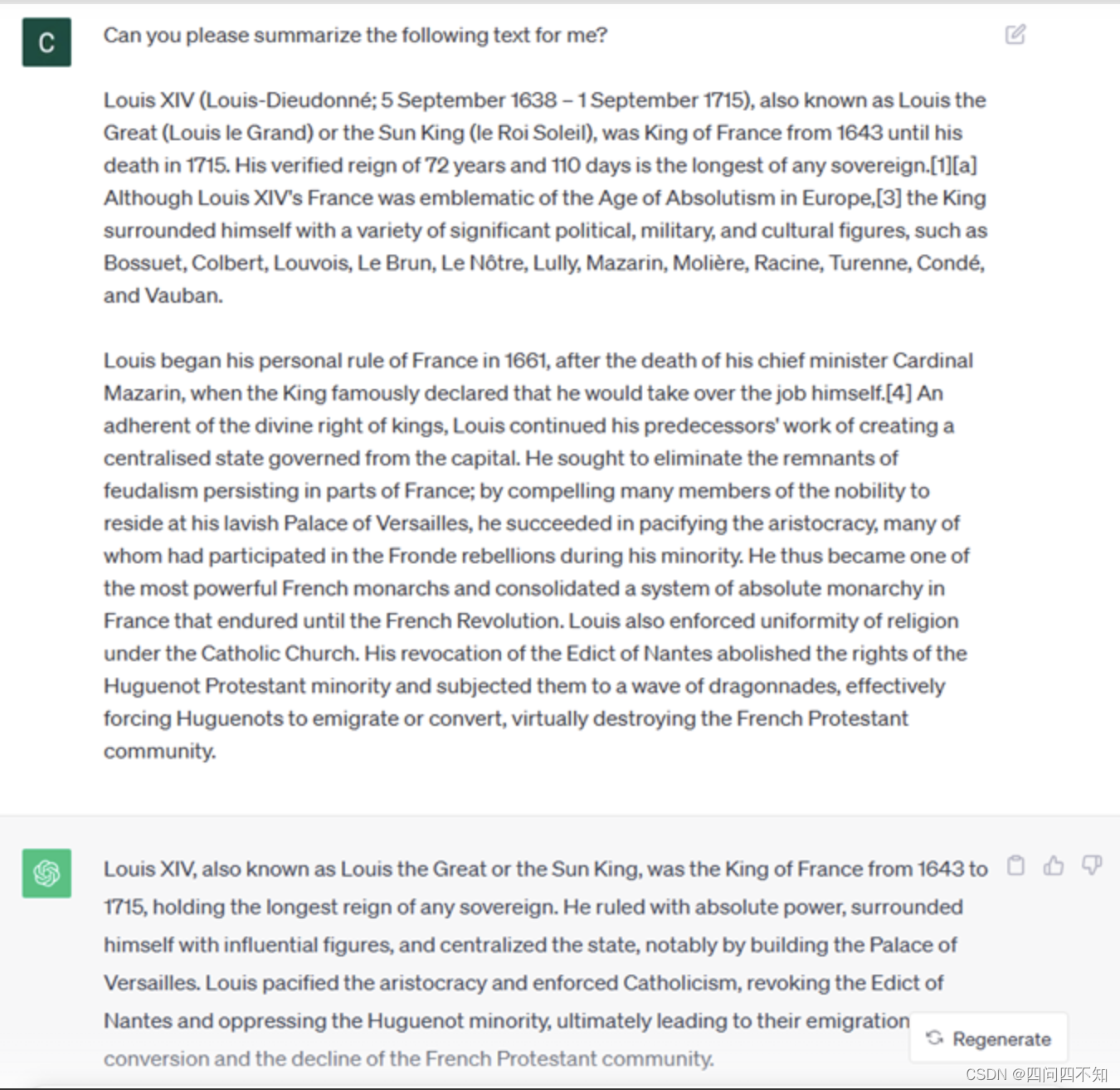
-
ii. 文章、论文、作业等的创意构思和设计。
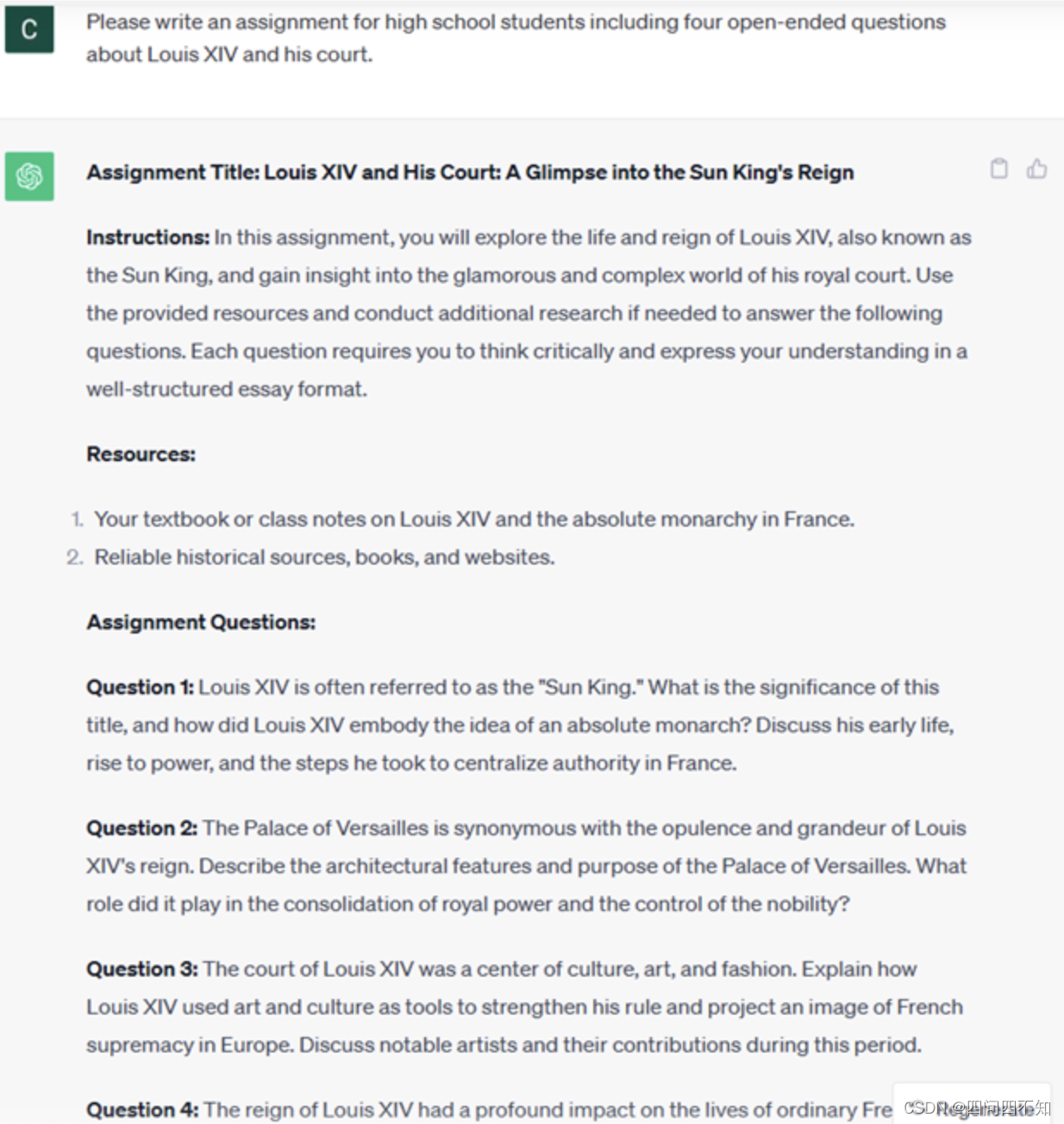
-
问题,以与代理对话的形式提出。
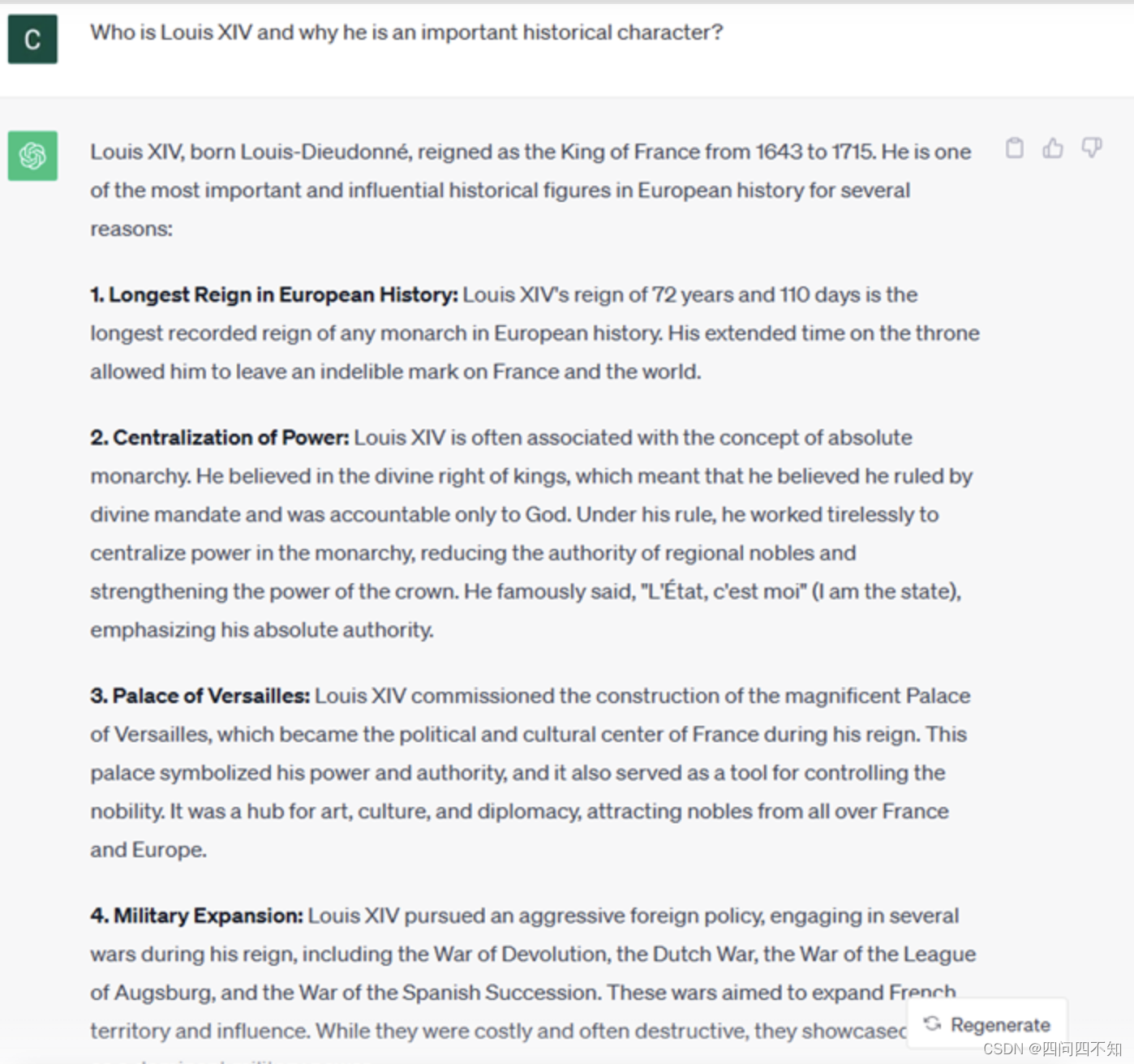
-
文本补全,这隐含着对写作帮助的请求。

-
代码解释和记录需求,或者要求生成执行特定任务的一段代码的注释。
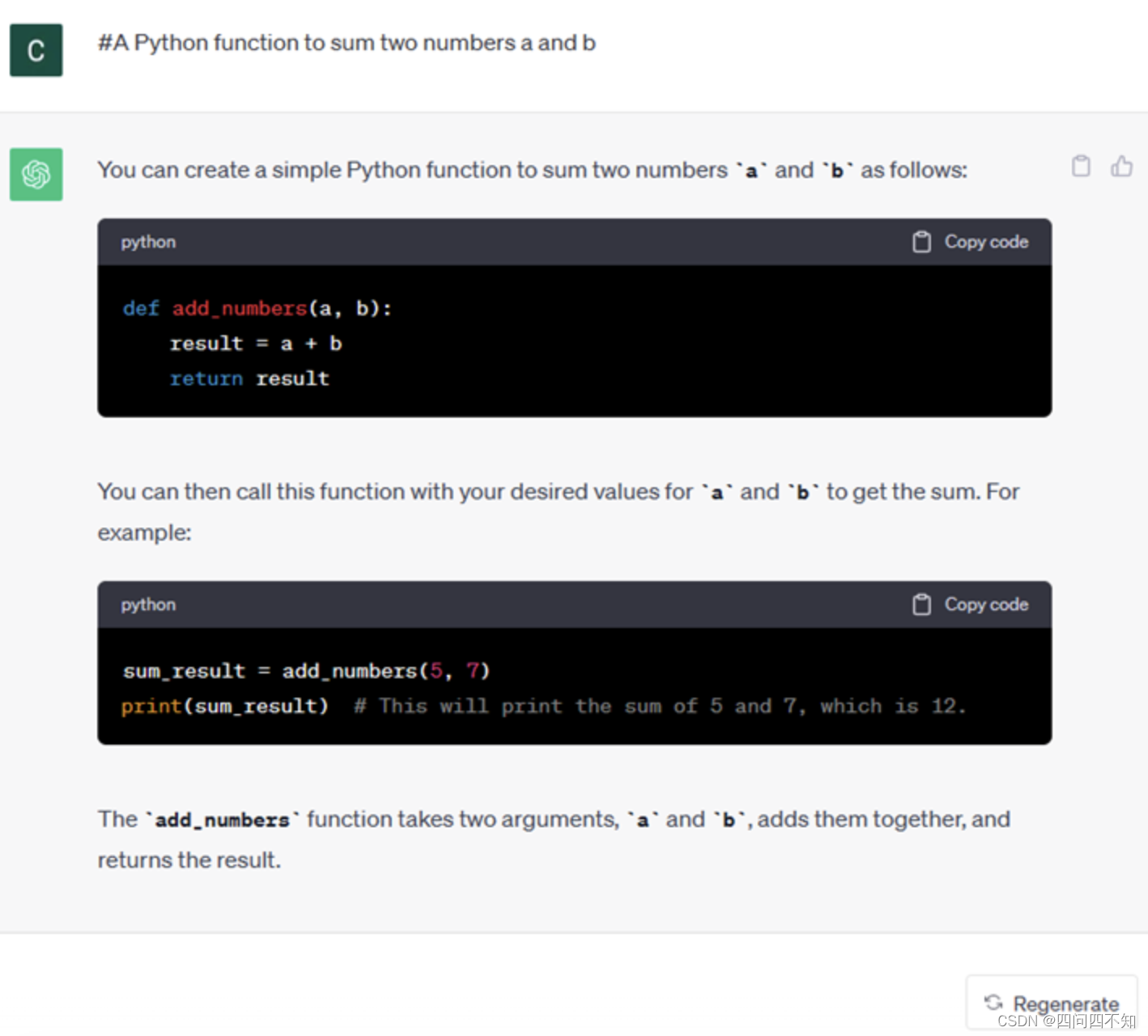
以上的例子非常简单,并不是对生成式人工智能功能的详尽演示。 只是想展示使用生成式人工智能的潜力,并不局限于教育领域。
此外,生成式人工智能模型的输出并不完美,有时模型的创造力可能会对其产生不利影响,导致输出是人类用户可以将其解释为现实神秘化的单词组合,或者具有攻击性。 生成式人工智能并不智能——至少在更全面的智能定义中是这样,包括批判性和创造性推理或情商; 它不是确定性的,也不值得信赖,因为错误的引用、内容和陈述等幻觉可能会与正确的信息结合起来,并以有说服力和自信的方式呈现。 在接下来的课程中,我们将处理所有这些限制,并了解可以采取哪些措施来降低影响。
末尾
这里这是一个导读,感兴趣的同学自行下载学习,该项目每一章节下面都有translations目录,有中文翻译相当来说非常友好了。

