
- 1三.ubuntu中安装RabbitMQ_ubuntu 下安装rabbitmq3.13.4
- 2大语言模型智能体(LLM Agents)入门指南
- 3总结一下:运维工程师面试的经历及面试相关问题_移动网络运维面试
- 4人工智能学习笔记(一)Agent_简单反射agent
- 5Flutter 学习步骤_flutter学习顺序
- 6java八股面试文(带答案,万字总结,精心打磨,建议收藏)堪称2024最强_java面试八股文
- 7vscode与vs for Mac有兼容问题!关于vs扩展商店无法连接且非网络端口问题的解决心得。所谓的鱼和熊掌不能兼得!_苹果电脑vscode兼容性
- 82020形式化方法复习笔记_消去是e还是i
- 9在项目如何解除idea和Git的绑定_idea项目取消git关联
- 10watchOS 2教程(一):开始吧_ios开发 iphone app 启动 watchos
性能优化之高通cDSP开发意识流-DSP技术概论以及发展史_adsp cdsp
赞
踩
哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈
诗词鉴赏:《定风波·莫听穿林打叶声》 【宋】 苏轼
原文:
三月七日,沙湖道中遇。雨具先去,同行皆狼狈,余独不觉。已而遂晴,故作此词。
莫听穿林打叶声,何妨吟啸且徐行。竹杖芒鞋轻胜马,谁怕?一蓑烟雨任平生。
料峭春风吹酒醒,微冷,山头斜照却相迎。回首向来萧瑟处,归去,也无风雨也无晴。
释义:
三月七日,在沙湖道上赶上了下雨。雨具先前被带走了,同行的人都觉得很狼狈,只有我不这么觉得。过了一会儿天晴了,就创作了这首词。
不用注意那穿林打叶的雨声,不妨一边吟咏长啸着,一边悠然地行走。竹杖和草鞋轻捷得胜过骑马,有什么可怕的?一身蓑衣任凭风吹雨打,照样过我的一生。
春风微凉,将我的酒意吹醒,寒意初上,山头初晴的斜阳却应时相迎。回头望一眼走过来遇到风雨的地方,回去吧,对我来说,既无所谓风雨,也无所谓天晴。
个人释义:
生活中我们总会遇到各种各种的问题,有时候是大环境使然亦或者自己所导致处于不利的境遇,若无法改变,何不如保持原来的节奏去感受这世间纷繁,做自己该做的事,看该看的风景。没有雨具,雨中漫步又何尝不是一种惬意与悠然自得呢。那"穿林打叶声”,可以看作那些总想影响你的人或事,不用太在意也不要因此乱了节奏哈哈哈哈哈哈
话说很有趣,今天在图书馆三楼写帖子,大约下午五点左右图书馆五楼有人烧书产生了很大的烟雾,大家纷纷收拾座位就离开了,而我问了一句图书馆管理员需要撤吗?小姐姐说不用,那我直接坐下来听这歌儿急需写~~ 这点烟雾算啥?莫听穿林打叶生!何妨吟啸且徐行!!!
哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈
DSP简介
DSP,从个人的角度出发,有两种解释。
- 其一是Digital Signal Processing, 作为数字信号处理来解释,它是一种处理信号与数据的方法,目的在于通过增强、更改、分析信号以确定其中包含的具体信息,主要处理从现实世界中转换而成的方法[^1]。
- 其二是Digital Singal Processor,作为数字信号处理器来解释,它此时作为一种微处理器来解释。它是一种实时计算各种数字信号处理算法、含有硬件加乘器及倒序寻址等专用结构的微处理器,具有高速、可编程、低功耗等特点,广泛用于处理、通信与信息系统、自动控制、雷达、航空航天等领域[^2]。
数字信号处理器是实现数字信号处理的载体,其实两种英文释义均可,后续本文泛指DSP处理器。
DSP发展历史
关于DSP的发展大致在上个世纪七八十年代,有人说拉开DSP芯片发展序幕的是AMI于1978年推出的S2811信号处理设备,该信号处理设备带有一个12位硬件乘法器、一个16位ALU(Arithmetric Logic Unit)和一个16位输入输出端口的DSP[^2]。
也有人说第一个DSP芯片是TI公司于1982年发布的[^3]。 1982年2月,TI在著名的“国际固态电路研讨会”上以一篇《一种具有数字信号处理能力的微计算机》的论文将DSP设计结果公之于众[^3],具体见下图硬件框图。
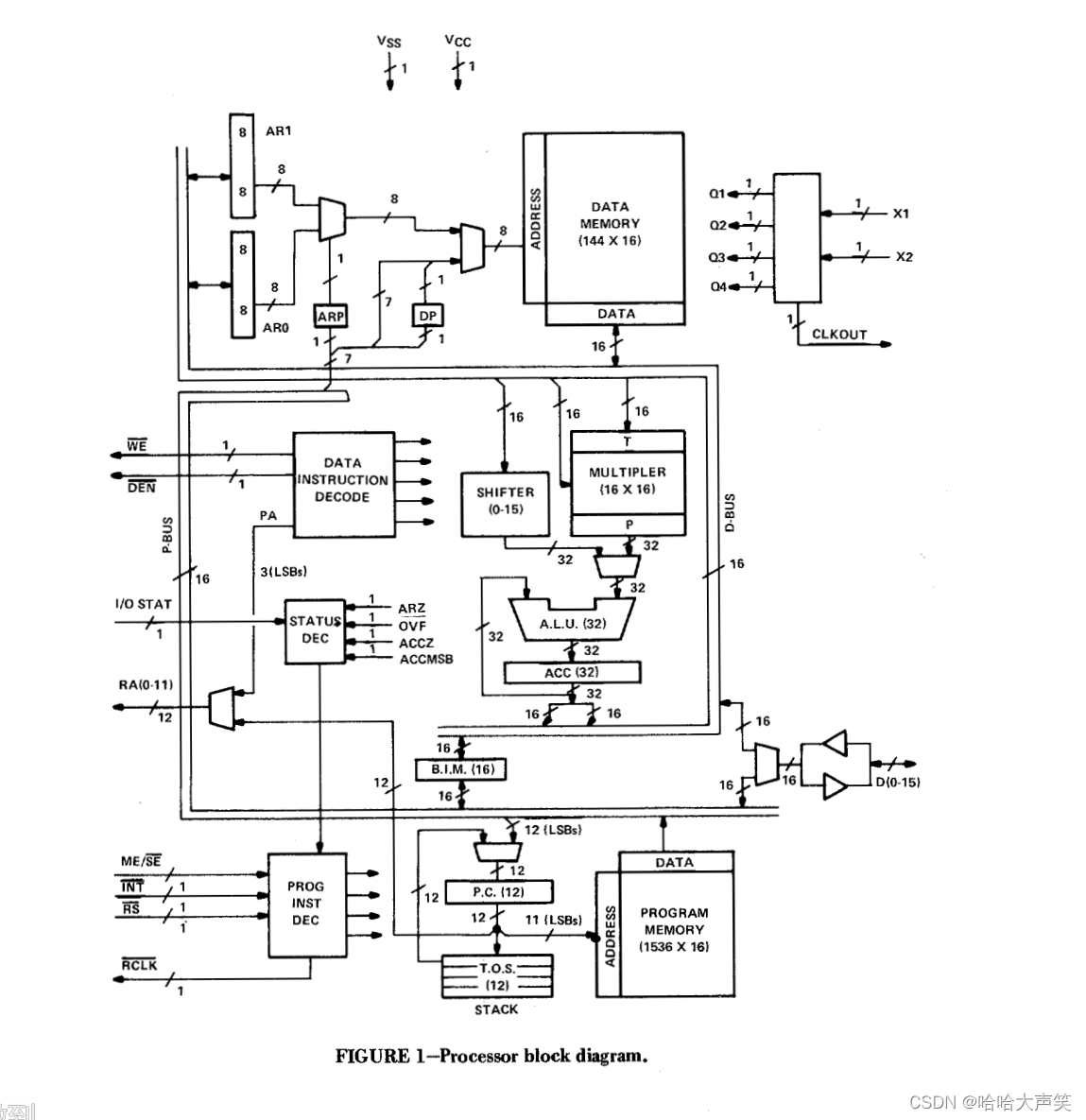
在1982年4月,TI公司发布了第一代DSP芯片TMS32010,它是基于哈佛架构,数据和程序通过不同的总线进行控制,相比于传统的冯诺依曼架构来说,个人理解其最大的优点是将解决了取指与取数据之间的矛盾,进一步提高了执行效率。
此处推荐一个bilibili链接,北京航空航天大学王俊讲的DSP体系架构:link。该系列视频讲解了提高DSP计算能力的原因以及技术手段、如超标量、VLIW、DLX等;
具体的哈佛架构与冯诺依曼可以参考该博客:link
在过去的几十年中,从初代的DSP架构不断进行体系架构不断演进,至今已有一系列较为成熟的DSP体系架构和产品。在技术的发展中,DSP的内部结构发生了很多变化,比如与通用处理器的结合、并行化和专业化等[^4]。
- 与通用处理器的结合。在DSP芯片内部,用DSP的内核做运算密集型数字信号处理的运算,在芯片内同同时有通用的处理器内核做管理运算,形成新的DSP产品,强强联合;
- 并行化。是为了高性能和高速运算而设计,体现在多个方面,其中就是片内多运算器的结构,在保持单一指令流与比较简单的编程技术的情况下,达到了高速并行处理能力,较为典型的就是超长指令字VLIW。
- 专业化。针对特定产品而优化的DSP,比如针对多媒体、MODEM等,如高通Qualcomm的DSP会分为aDSP、cDSP、mDSP、sDSP。其中cDSP就是后续会介绍的专门用于计算的DSP。
其中DSP的巨头有美国的TI公司、马萨诸塞州的亚德诺Analog Devices、荷兰的恩智浦(NXP)、意法半导体STMicroelectronics、高通Qualcomm等;
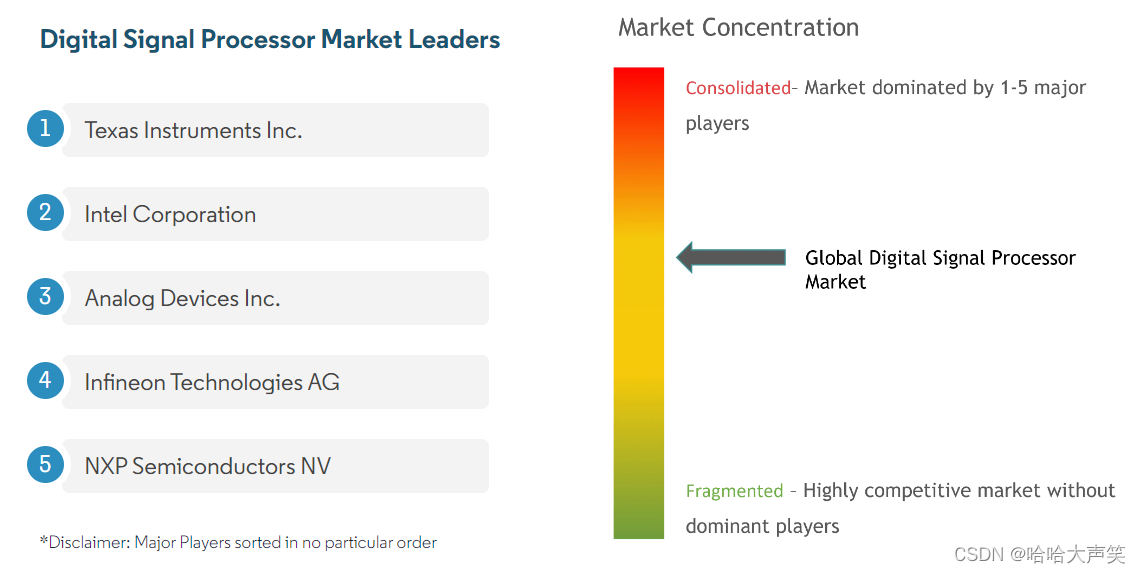
具体的DSP全球市场份额可以查看对应的该份报告:link.
TI是美国德州仪器,是世界上最知名的DSP芯片生产厂商,其铲平应用最广泛、市场占有率高,如主系列C6000(TMS320C62xxx)等;
ADI 的处理器型号有TigerSHARC ADSP-TS201S,支持VLIW指令集;
Qualcomm的DSP 有Hexagon 680 DSP,同样支持VLIW指令集;
DSP的特点
个人理解以下三点是DSP的主要表现特点,即高性能、低功耗、数据并行度高,外在表现特点由内在体系架构所支撑。
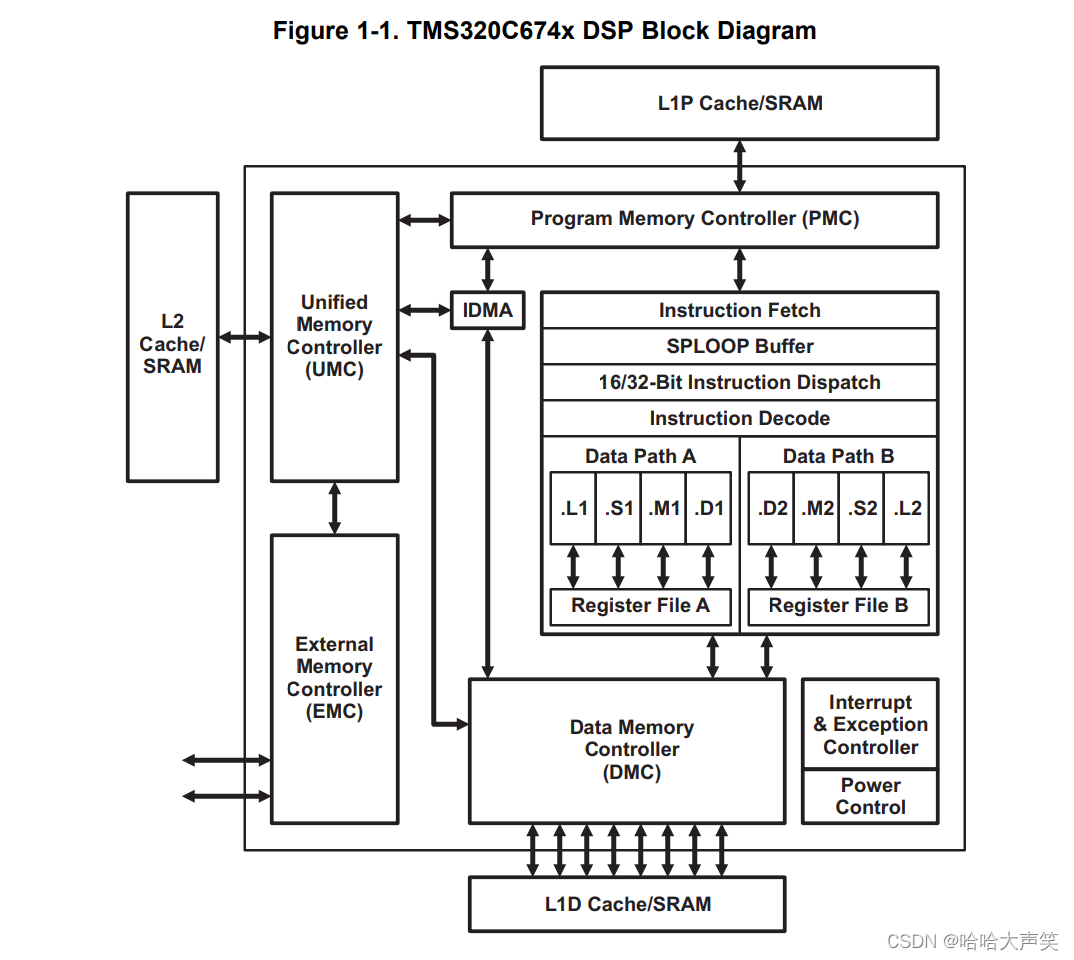
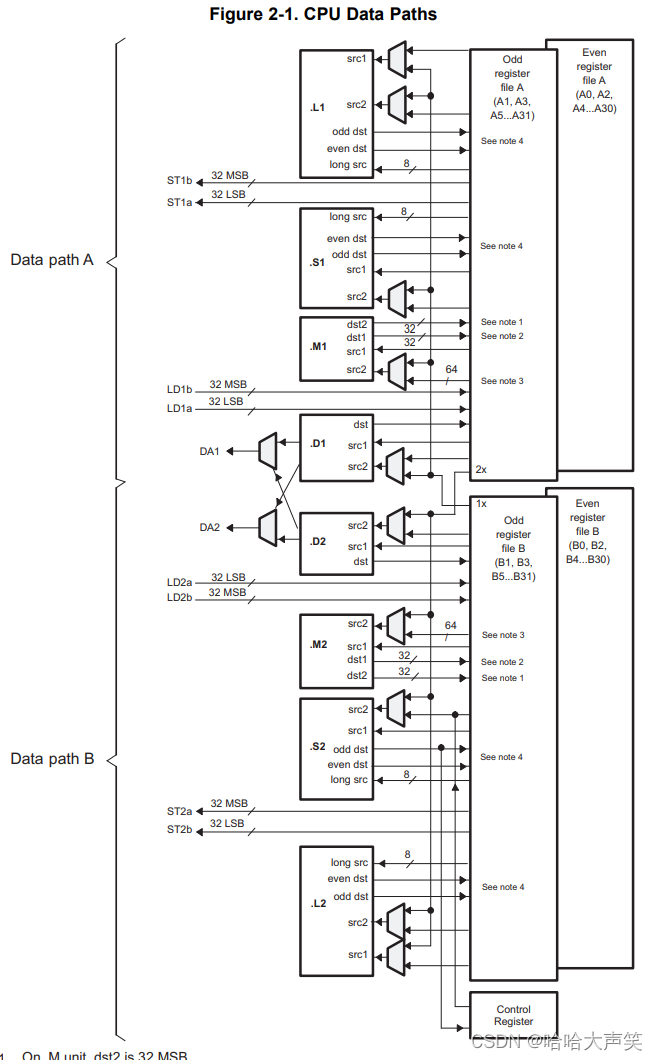
上图两图分别TMS320C674x DSP的架构图以及其寄存器数据图,可以看到为了实现高性能、低功耗做了多个考虑。
- 哈佛结构;实现数据和程序的分开存储;
- 内存方面的优化;存在两级cache以及DMA等单元,如L2 cache、L1 Data cache、L1 Program cache等;
- 专门的Power控制的单元;如Power Control单元;
- 硬件循环;如SPLOOP BUFFER等;
- 多个执行单元;如DataPathA, DataPathB;
- 多个执行单元并执行,通过硬件电路控制同时读取数据、同时执行、同时写数据;
同时外在表现的要求也对体系架构的变化提供了指导方针,即在单周期内执行更多指令,在单指令内执行更多operation。下面主要介绍以下几种技术用来提升数据处理能力。
VLIW
现代的处理器架构有多种形式的指令级并行(Instruction Level Parallelism, ILP)。线代的DSP有超长的指令字(Very Long Insruction Word, VLIW)结构。这些DSP通过组合多条指令(加、乘、加载和存储)使其在一个处理周期中执行。Hexagon 680DSP采用4路VLIW结构,4路是因为Hexagon 单个单元context 包含四个处理单元Slot。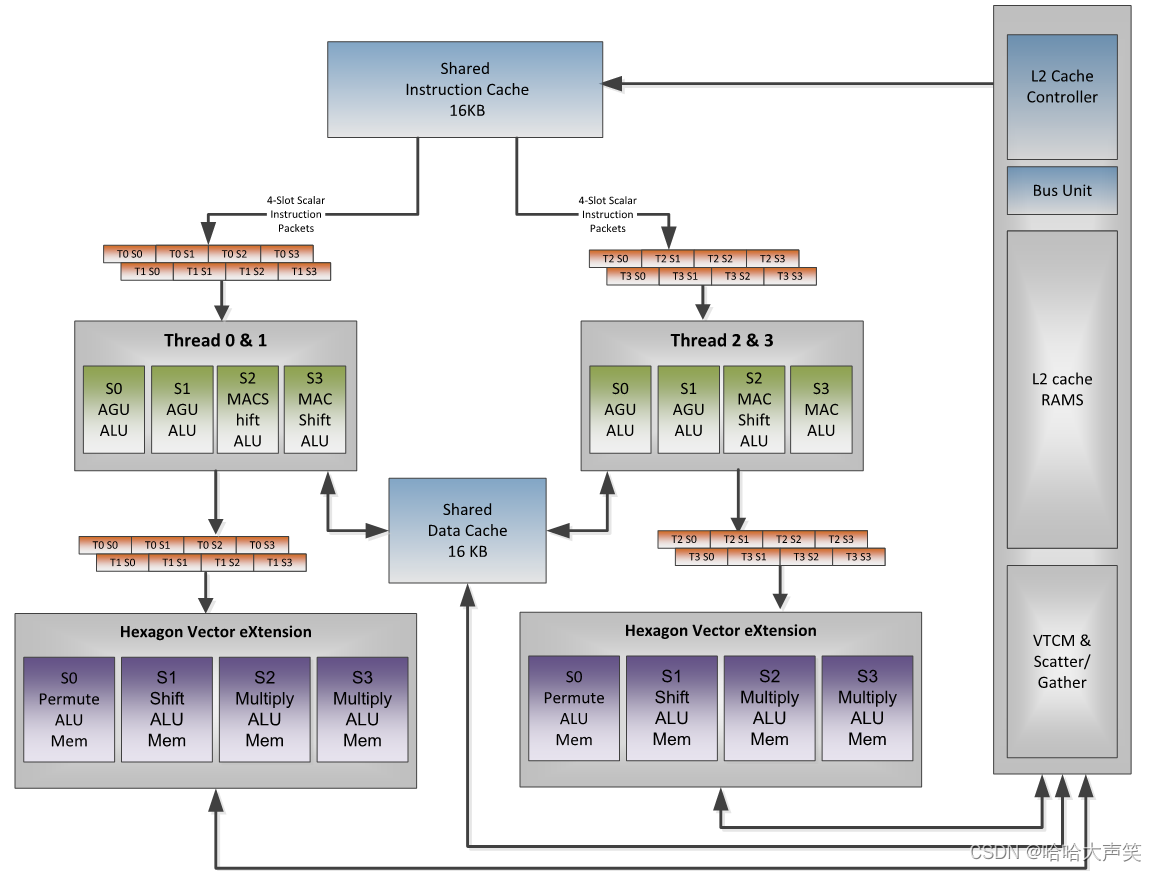
.falign .Gaussian5x5u8PerRowLOOP: { sLine0 = VMEM(iptr0++#1) //[1] 加载数据 sVsum0 = VLALIGN(sVsumv1E,sVsumv0E,#2) //[2] 两个矢量偏移 sVsum2a4.h = VADD(sVsum2.h,sVsum4.h) //[3] 两个矢量做加法 sSumE.w += VMPYI(sVsum2.w,const6.b) //[3] 两个矢量做乘法 } { sLine1 = VMEM(iptr1++#1) //[1] sVsum1 = VLALIGN(sVsumv1O,sVsumv0O,#2) //[2] sSumO.w += VMPYI(sVsum3.w,const6.b) //[3] sSumE.w += VMPYI(sVsum1a3.w,const4.b) //[3] } { sLine4 = VMEM(iptr4++#1) //[1] sVsumv0E = sVsumv1E //[1] sVsum4 = VALIGN( sVsumv2E,sVsumv1E,#2) //[2] sSumO.w += VMPYI(sVsum2a4.w,const4.b) //[3] }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
通过上述硬件单元可以看到最多同时执行4条指令,在Hexagon DSP中每个指令包是以{}标识。在用户编程阶段是不需要去处理每个包中指令的顺序,该顺序以及其他限制因素会在编译的阶段实现排序以及指令检查等;当然每个指令包需要满足多种限制条件,如资源限制,1个指令包中最多两个Load指令。
VLIW的并行执行,不需要硬件动态调度,主要靠编译器找到N个独立的操作,如果无法找到便在包中插入NOP指令补成完整的VLIW结构。
SIMD
许多的数字吸纳后处理算法(如傅里叶变换、卷积、滤波等)所需要操作的数据具有高度的并行性,都需要对数据进行一系列的乘累加操作,因此可以增加处理单元的数量,如乘加单元,通过单指令就可以实现多数据的并行执行。SIMD技术就是技术数据通路上并行的MAC数量。
Hexagon 680 DSP内有1个矢量处理单元,矢量处理单元内部有多个Context, 每个Context都有R0-R31合计32个1024Bit的矢量处理器。

前面说过Hexagon 680 DSP可以执行一个VLIW指令包,指令包中最多有4条指令,每条指令可以操作1024bit数据,因此每周期可以处理4*1024bit数据。
每周期执行一个package, 是通过流水线技术实现,一条指令实际执行是需要多个cycle的,即如下图以及下表所示。通过流水线并行技术,可以实现1个cyle执行多条指令在流水线技术中,每个周期会执行一个package,其中每个指令会经过不同阶段的处理,例如取指、译码、执行、访存和写回。这样可以实现多条指令在不同阶段并行执行,从而提高整体的执行效率和性能。流水线技术的优势在于能够充分利用硬件资源,减少指令执行的等待时间,使处理器能够更加高效地工作。。
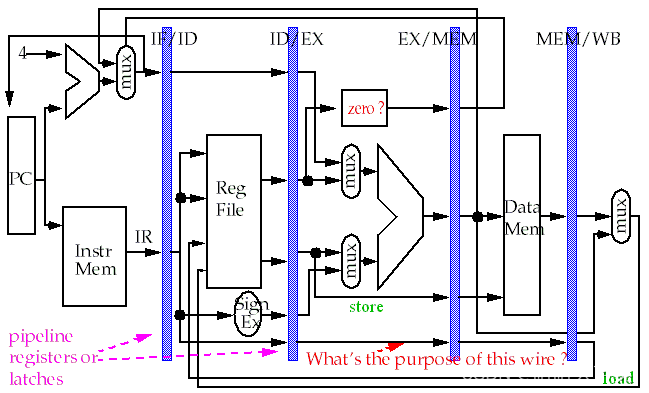

如下图是TI的TMS320C674x的关于流水线Pipeline的介绍。它分为三个部分:fetch、decode、execute;每个部分又有多个pahse,其中execute是变化的phases,取决于执行的指令数。
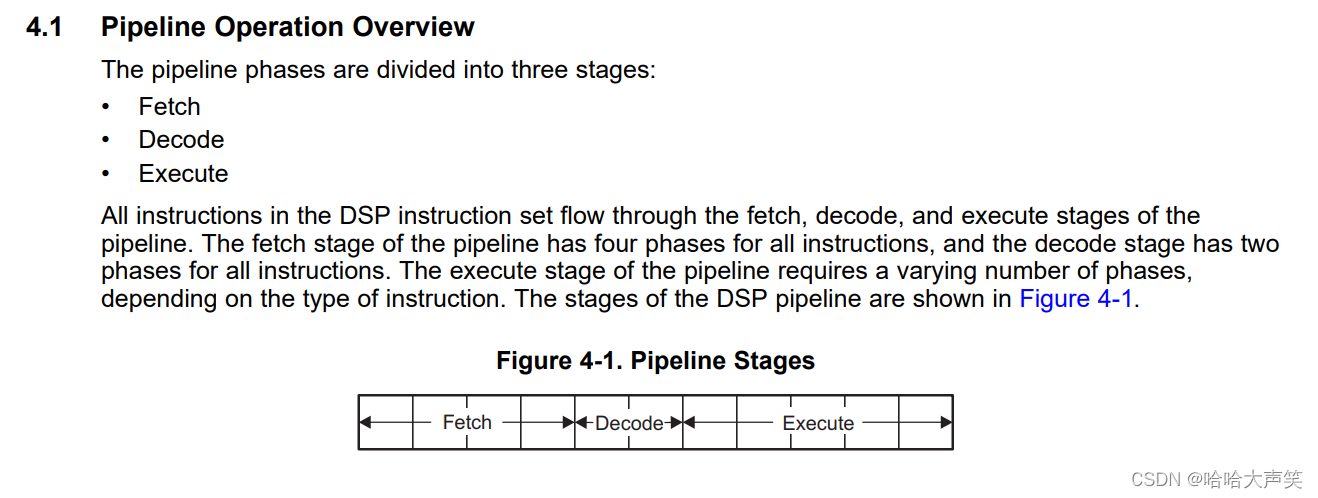
关于流水线的相关介绍会在后续的Blog中继续更新。
超标量
超标量和VLIW具有相似的功能,它们都是为了并发的执行多条指令,不同的是超标量处理器发出的多条指令之间可能存在资源上的冲突,它将指令调度从编译器转移到了硬件上,从而增加了硬件开销以及功耗增加。
| 方法 | 优点 | 缺点 |
|---|---|---|
| 超标量 | 代码量小 | 硬件开销大、功耗高 |
| VLIW | 硬件开销小、功耗低 | 代码量大 |
DSP现状以及未来的发展方向
近年来,DSP在计算机视觉、自然语言处理、模式识别等领域的处理性能优势,越来越多的以卷积网络CNN为典型算法的深度神经网络部署在硬件计算平台上。DSP具有高性能、低功耗、编程简单(相比于FPGA)的特点,包含大量MAC单元,支持矩阵等运算。如Hexagon DSP有一个专门的矩阵处理HMX, 可以用来做神经网络的推理加速。就模型推理相比于GPU来说,DSP性能功耗可能会更逊色。
所以具备一定AI计算能力和实时计算优势的DSP在AI大规模崛起的时代会有足够的市场潜力。
附录
[1]: 宋文娜 DSP体系结构发展综述
[2]:张旭东 D S P 技术综述((2 0 3 嵌入式世界研讨暨展示会的讲话整理))
[3]:Robert Oshana DSP嵌入式实时系统权威指南
[4]:路锦正 C674x-DSP 嵌入式开发与实践

