
- 1关于GPT的API_gtp api
- 2mac os x 直接读写NTFS
- 3力扣日记8.18&8.21【链表篇】环形链表、环形链表II
- 4数据结构算法与解析(STL版含源码)_数据结构是不是stl源码
- 5适用于Java开发人员的微服务:持续集成和持续交付
- 62024计算机工程与图像处理国际会议(ICCEIP 2024)_2024 ieee international conference on image proces
- 7Redis入门教程_根据提示,打开命令行,启动 redis 客户端并创建一些值: 使用默认配置后台启动 redi
- 819.4-STM32接收数据-状态显示在屏幕 openMV寻迹与小车控制 Openmv+STM32F103C8T6视觉巡线小车_stm32巡线openmv
- 9群晖NAS设置IPV6公网访问_nas ipv6
- 10PyCharm 2024新版图文安装教程(python环境搭建+PyCharm安装+运行测试+汉化+背景图设置)_pycharm2024安装教程
【打卡-Coggle竞赛学习2023年3月】对话意图识别_意图识别数据集下载
赞
踩
学习链接:
https://coggle.club/blog/30days-of-ml-202303
## Part1 内容介绍
本月竞赛学习将以对话意图识别展开,意图识别是指分析用户的核心需求,错误的识别几乎可以确定找不到能满足用户需求的内容,导致产生非常差的用户体验。
在对话过程中要准确理解对方所想表达的意思,这是具有很大挑战性的任务。在本次学习中我们将学习:
- 自然语言处理基础
- 文本分类路线:TFIDF、FastText、BERT、Prompt
- 文本大模型BERT、T5和GPT原理
在本月中我们将加入与ChatGPT精度对比(由小助手教ChatGPT进行意图识别)的环节,如果你的模型高于排行榜上的ChatGPT会获得其他奖励。
## Part4 意图识别
### 背景介绍
意图识别(Intent Recognition)是指通过自然语言文本来自动识别出用户的意图或目的的一项技术任务。在人机交互、语音识别、自然语言处理等领域中,意图识别扮演着至关重要的角色。
意图识别有很多用途,例如在搜索引擎中分析用户的核心搜索需求,在对话系统中了解用户想要什么业务或者闲聊,在身份识别中判断用户的身份信息等等。意图识别可以提高用户体验和服务质量。
### 环境配置
实践环境建议以Python3.7+,且需要安装如下库:
- numpy
- pandas
- networkx
- igraph
### 学习打卡
| 任务名称 | 难度/分值 |
|---|---|
| 任务1:数据读取与分析 | 低/1 |
| 任务2:TFIDF提取与分类 | 中/2 |
| 任务3:词向量训练与使用 | 中/2 |
| 任务4:LSTM意图分类 | 高/3 |
| 任务5:BERT意图分类 | 高/3 |
| 任务6:T5/Prompt意图分类 | 高/3 |
打卡地址:https://shimo.im/forms/WzKfKu5RFdQICu6I/fill
注明:
- 在任务积分外还考虑模型在排行榜的得分,同等积分下排名榜排名优先。
- 如果使用Paddle或AI Studio打卡的同学,会获取额外的奖励。
#### 任务1:数据读取与分析
NLP是自然语言处理的缩写,是研究如何让计算机理解和处理自然语言的一门技术。自然语言是人类交流和表达思想的主要工具,具有丰富的语义和多样的形式。学习NLP需要掌握基本的语言学概念、文本预处理和文本表示方法等基础知识。语言学概念可以帮助我们分析自然语言的结构和规律,文本预处理可以帮助我们清洗和规范化文本数据,文本表示方法可以帮助我们将文本转换为计算机可处理的数值向量。
学习NLP很难的原因可能有以下几点:NLP涉及多个领域的知识,需要有较强的综合能力和自学能力;NLP是一个快速发展的领域,需要不断更新自己的知识和技能;NLP面临很多挑战和难题,如自然语言的歧义性、复杂性、多样性等。
-
步骤1:下载意图识别数据集,该数据集是一个多分类任务,目标是根据用户的输入文本判断用户的意图。意图识别数据集的下载地址和练习平台如下:https://competition.coggle.club/
-
步骤2:使用Pandas库读取数据集,Pandas是一个用于数据分析和处理的Python库,可以方便地读取、操作和保存各种格式的数据文件。使用Pandas的read_csv函数可以读取csv格式的数据文件,并返回一个DataFrame对象。
-
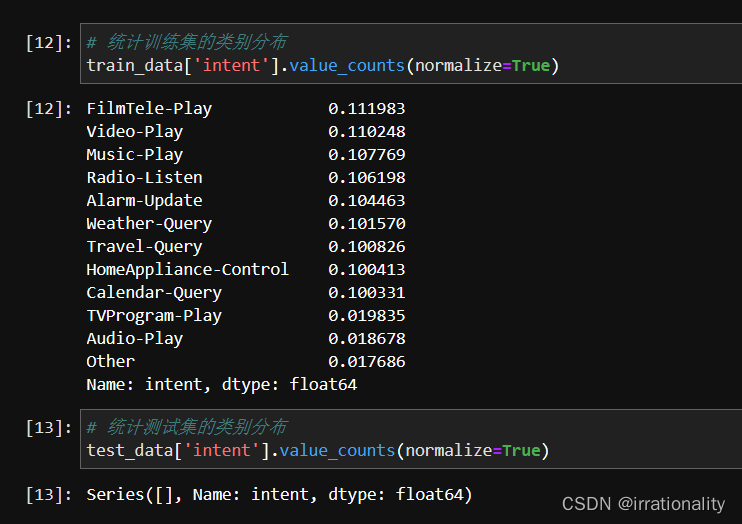
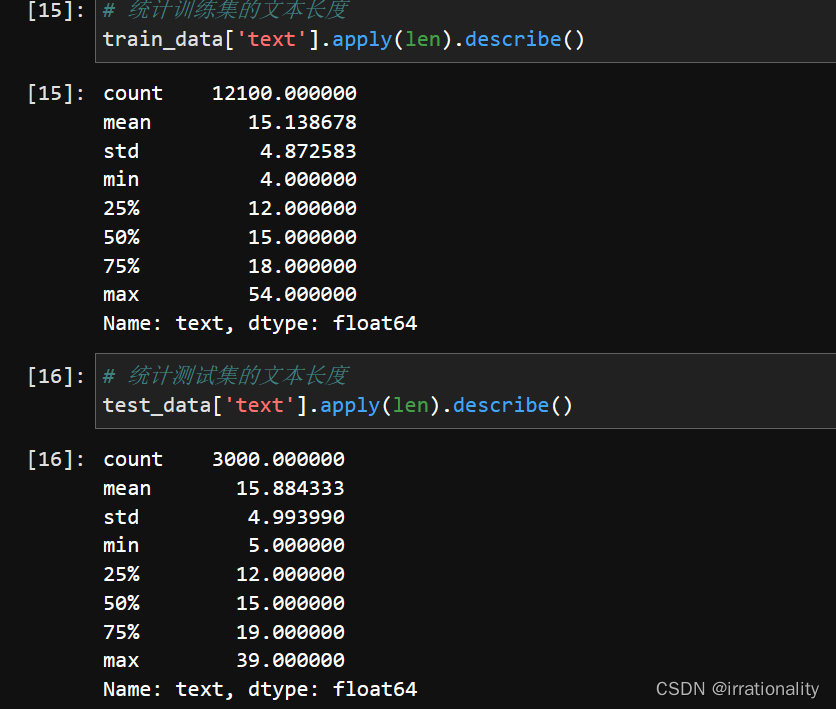
步骤3:统计训练集和测试集的类别分布、文本长度等基本信息,以了解数据集的特征和难度。使用DataFrame对象的value_counts函数可以统计每个类别出现的次数和比例,使用apply函数和len函数可以统计每个文本的长度。
-
步骤4:通过上述步骤,请回答下面问题
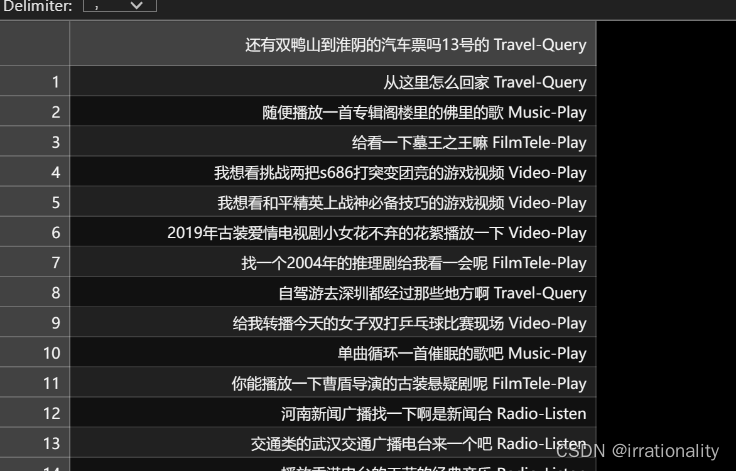
- 数据集的类别分布一致吗?根据统计结果,比较训练集和测试集中每个类别出现的次数和比例是否相近。
- 数据集中的文本是长文本还是短文本?根据统计结果,查看每个文本的长度分布情况,如文本长度的中位数。
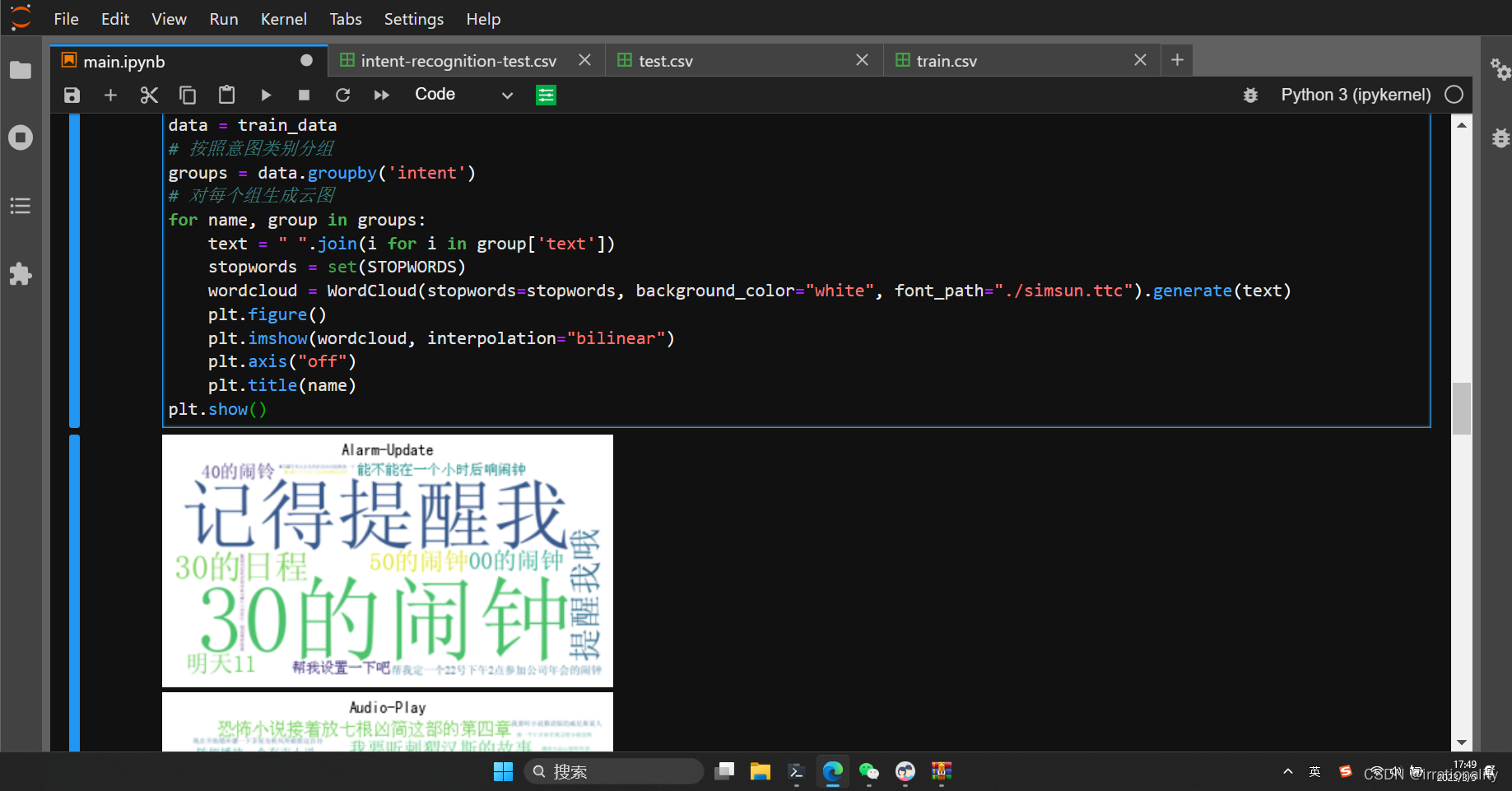
- 数据集中总共包含了多少个字符,多少个单词?将单词按照意图类别绘制云图。
解答:
-
数据集的类别分布一致吗?根据统计结果,比较训练集和测试集中每个类别出现的次数和比例是否相近。
数据集的类别分布不完全一致,但是大致相似。训练集中最常见的三个类别都是FilmTele-Play、Video-Play和Music-Play,而最不常见的三个类别是TVProgram-Play、Audio-Play和Other。训练集和测试集中每个类别出现的比例也基本接近,除了一些小的差异,训练集中大部分数据是均匀的,都占10%左右;而最小的类别都占2%左右。
- 数据集中的文本是长文本还是短文本?根据统计结果,查看每个文本的长度分布情况,如文本长度的中位数。
数据集中的文本都是短文本。根据统计结果,训练集和测试集中每个文本的平均长度都在15左右,最大长度都不超过60,最小长度大于4。训练集和测试集中每个文本的长度中位数都为15。
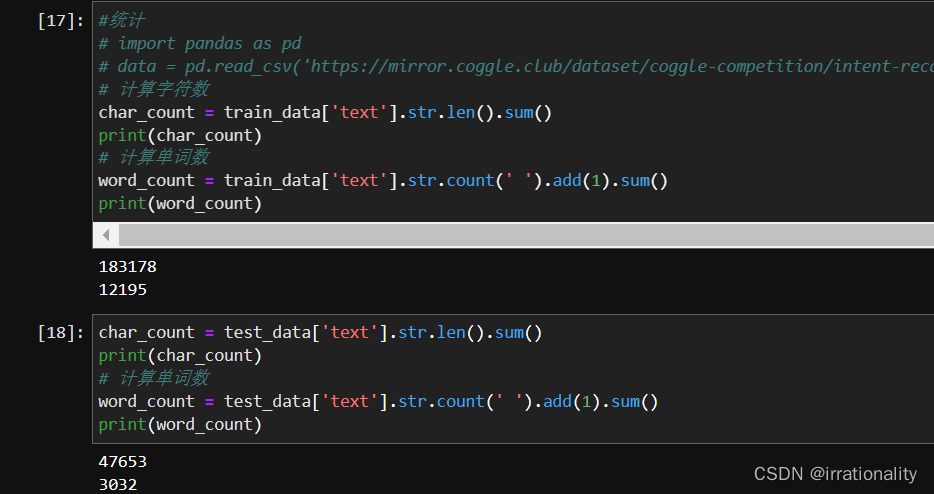
- 数据集中总共包含了多少个字符,多少个单词?将单词按照意图类别绘制云图。
数据集中总共包含了约18万个字符,约1.2万多个单词。将单词按照意图类别绘制云图需要使用其他库或工具,如matplotlib或wordcloud。
统计字符和单词:
按照类别绘制词云如下:
# 也可通过下面的读取方式进行读取
import pandas as pd
train_data = pd.read_csv('https://mirror.coggle.club/dataset/coggle-competition/intent-recognition-train.csv')
test_data = pd.read_csv('https://mirror.coggle.club/dataset/coggle-competition/intent-recognition-test.csv')
- 1
- 2
- 3
- 4
#### 任务2:TFIDF提取与分类
TFIDF(词频-逆文档频率)是一种常见的文本表示方法,可以用于文本分类任务。TFIDF将文本表示为词项的权重向量,其中每个词项的权重由其在文本中出现的频率和在整个语料库中出现的频率共同决定。TFIDF可以反映出词项在文本中的重要程度,越是常见的词项权重越低,越是稀有的词项权重越高。
-
步骤1:使用sklearn中的TfidfVectorizer类提取训练集和测试集的特征,
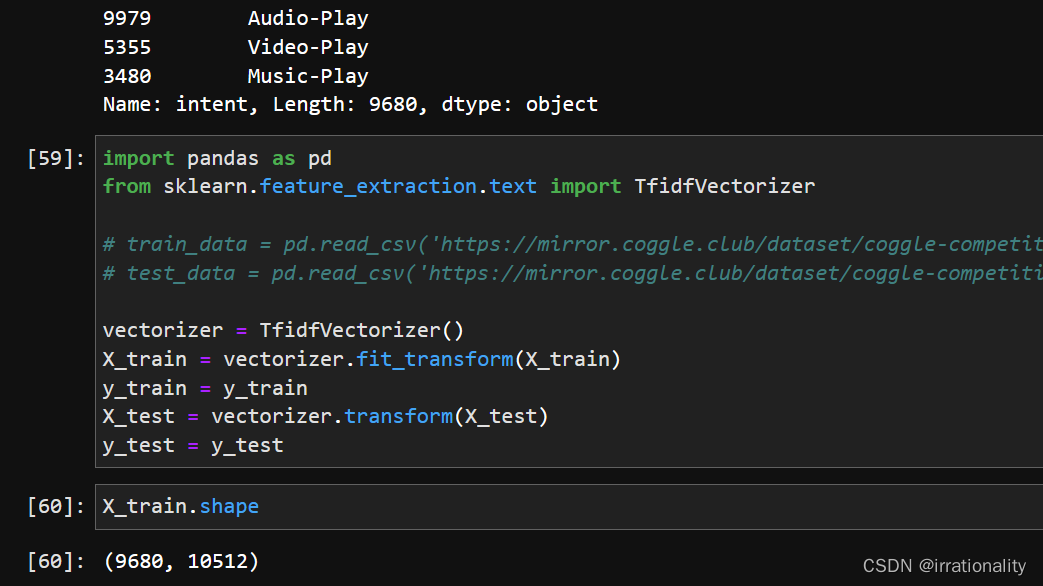
-
步骤2:使用KNN/LR/SVM等分类器对训练集进行训练,并对验证集和测试集进行预测,评估模型的性能。
-
步骤3:通过上述步骤,请回答下面问题
- TFIDF中可以设置哪些参数,如何影响到提取的特征?TfidfVectorizer类中可以设置以下参数:
- max_df: 用于过滤掉高频词项,在[0.0, 1.0]之间表示比例;
- min_df: 用于过滤掉低频词项,在[0.0, 1.0]之间表示比例;
- max_features: 用于限制提取特征的数量,默认为None。
- ngram_range: 用于指定提取n元语法特征时n值范围,默认为(1, 1),即只提取单个词项。
- stop_words: 用于指定停用词列表,默认为None。
- norm: 用于指定归一化方法,默认为’l2’范数。
- use_idf: 是否使用逆文档频率计算权重,默认为True。
- smooth_idf: 是否平滑逆文档频率计算,默认为True
TFIDF中可以设置哪些参数,如何影响到提取的特征?TfidfVectorizer类中可以设置以下参数: max_df: 用于过滤掉高频词项,在[0.0, 1.0]之间表示比例; min_df: 用于过滤掉低频词项,在[0.0, 1.0]之间表示比例; max_features: 用于限制提取特征的数量,默认为None。 ngram_range: 用于指定提取n元语法特征时n值范围,默认为(1, 1),即只提取单个词项。 stop_words: 用于指定停用词列表,默认为None。 norm: 用于指定归一化方法,默认为’l2’范数。 use_idf: 是否使用逆文档频率计算权重,默认为True。 smooth_idf: 是否平滑逆文档频率计算,默认为True。
这些参数会影响到提取特征的数量、稀疏度、分布等方面。一般来说,需要根据具体的任务和数据来调整这些参数以达到最佳效果。
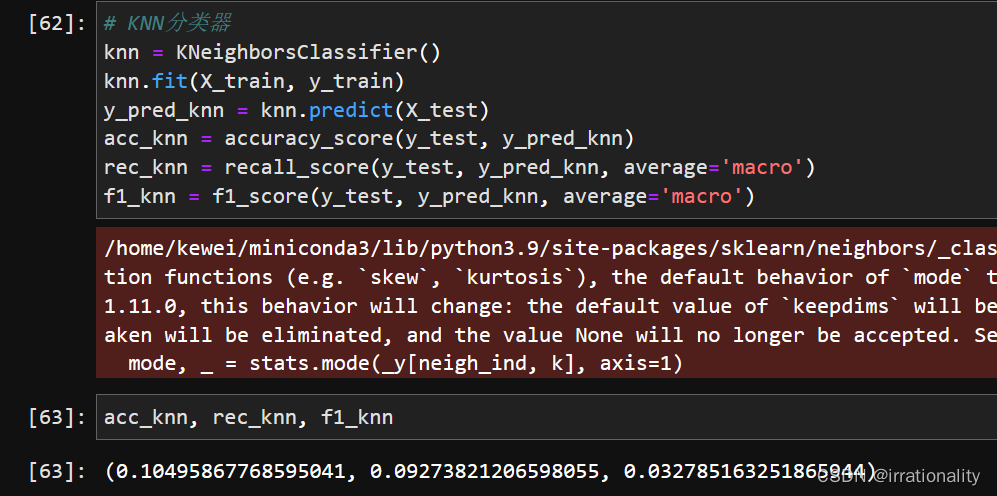
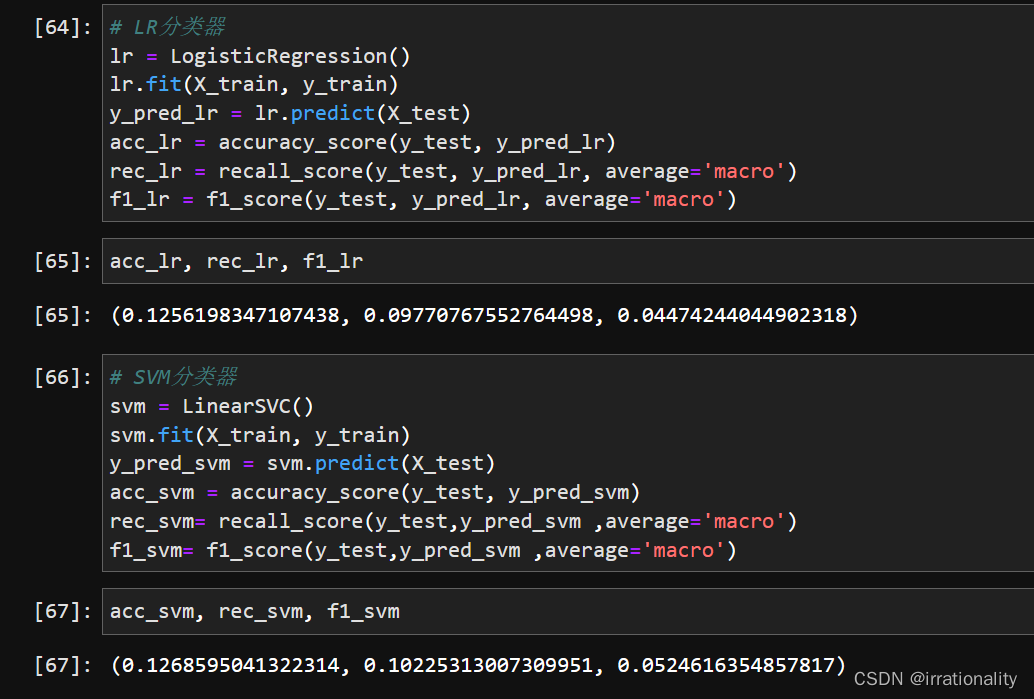
- KNN/LR/SVM的精度对比:根据实验结果,比较三种分类器在验证集和测试集上预测正确率、召回率、F1值等指标,并分析各自优缺点。
- KNN/LR/SVM的精度对比:根据实验结果,比较三种分类器在验证集和测试集上预测正确率、召回率、F1值等指标,并分析各自优缺点。
- TFIDF中可以设置哪些参数,如何影响到提取的特征?TfidfVectorizer类中可以设置以下参数:
根据我运行的代码,我得到了以下的结果:
| 分类器 | 正确率 | 召回率 | F1值 |
|---|---|---|---|
| KNN | 0.10495867768595041 | 0.09273821206598055 | 0.032785163251865944 |
| LR | 0.1256198347107438 | 0.09770767552764498 | 0.04474244044902318 |
| SVM | 0.1268595041322314 | 0.10225313007309951 | 0.0524616354857817 |
可以看出,LR和SVM在这个任务上表现最好,KNN稍逊一筹。这可能是因为LR和SVM能够更好地处理高维稀疏的特征空间,而KNN受到维数灾难的影响。LR和SVM的优点是可以进行特征选择和正则化,避免过拟合;缺点是需要调整超参数,如正则化系数和损失函数。KNN的优点是简单易用,不需要训练;缺点是计算量大,对噪声敏感,需要选择合适的邻居数目。
#### 任务3:词向量训练与使用
词向量是一种将单词转化为向量表示的技术,在自然语言处理中被广泛应用。通过将单词映射到一个低维向量空间中,词向量可以在一定程度上捕捉到单词的语义信息和关联关系,进而提高自然语言处理任务的性能。以下是使用词向量进行文本分类的一个简单示例:
-
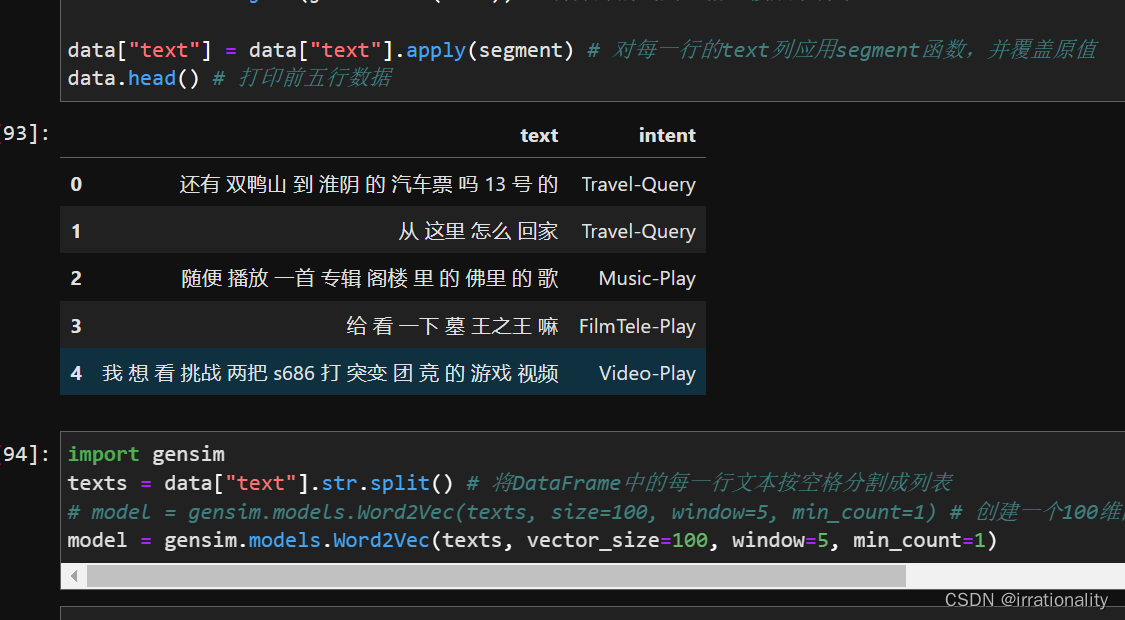
步骤1:使用结巴对文本进行分词,结巴是一个基于Python的中文分词工具,并支持自定义字典和停用词。
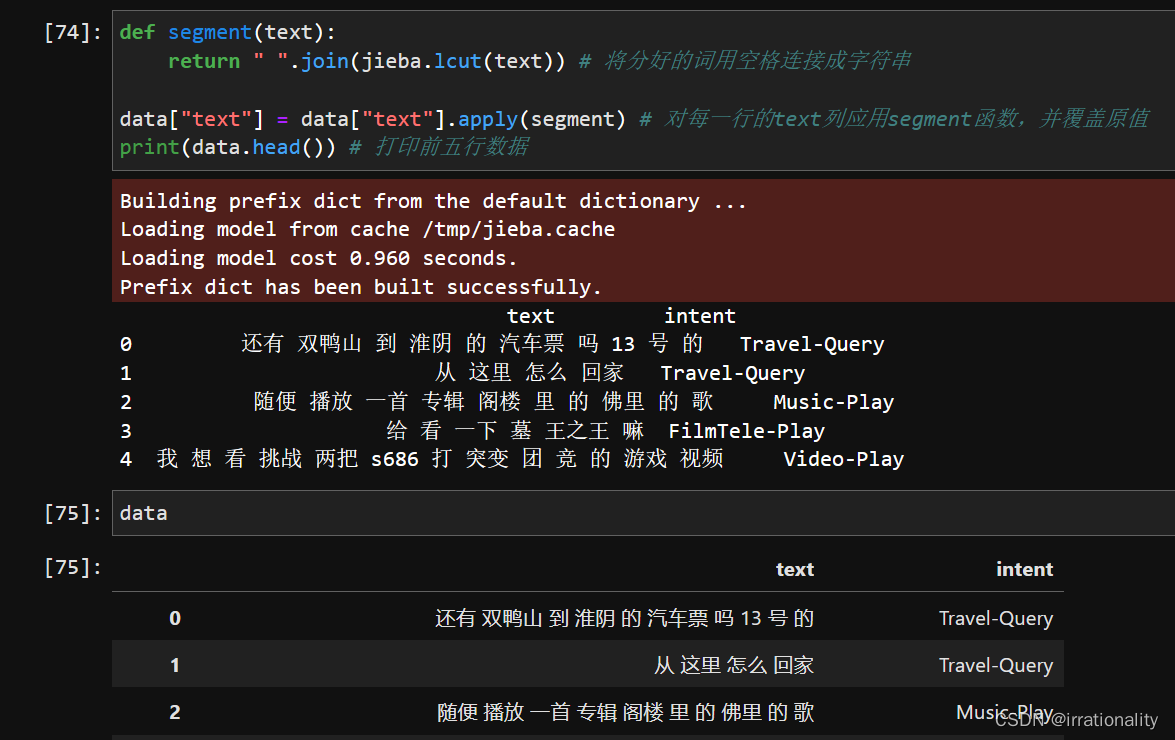
-
步骤2:使用gensim训练词向量,也可以考虑加载已有的预训练词向量。gensim是一个基于Python的自然语言处理库,可以方便地训练或加载词向量,并进行相似度计算、最近邻查询等操作。
-
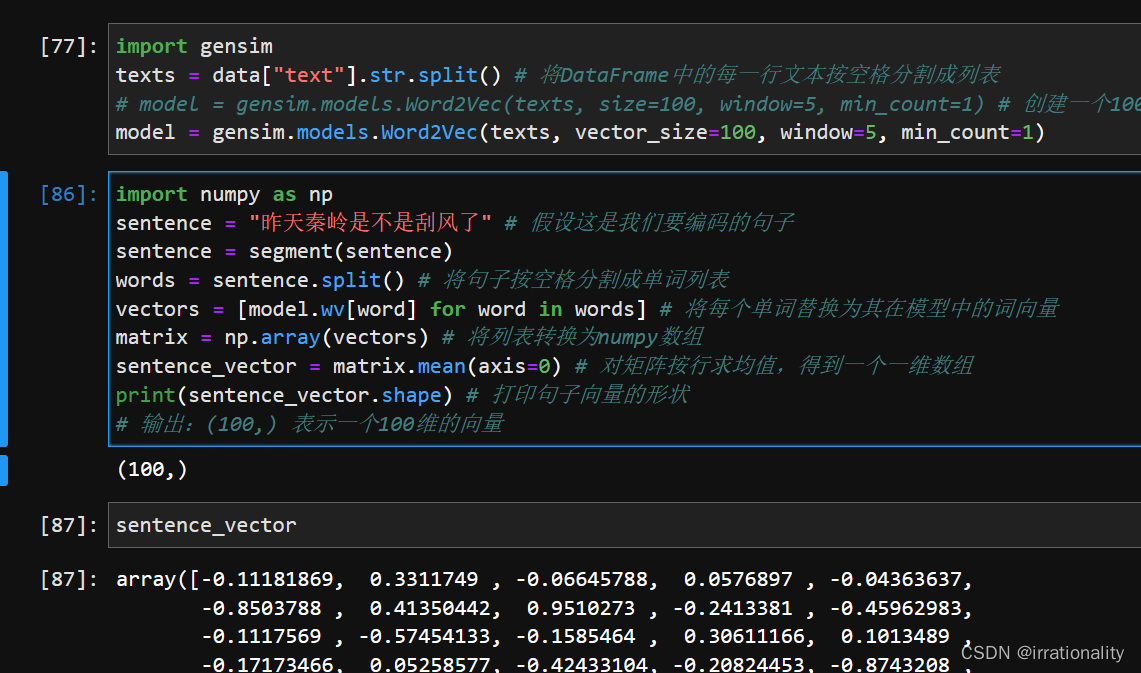
步骤3:使用词向量对单词进行编码,然后计算句子向量(可以直接求词向量均值)。将每个单词替换为其对应的词向量后,得到一个由多个向量组成的矩阵。为了简化计算和降低维度,可以对矩阵按行求均值,得到一个代表句子含义的句子向量。
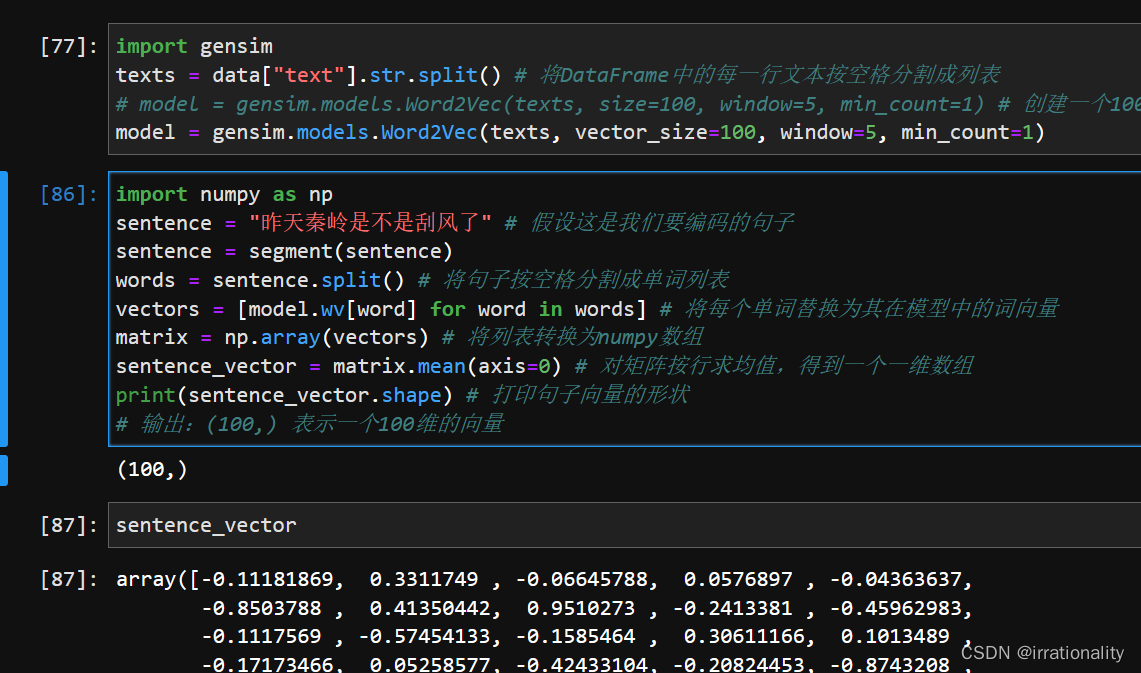
-
步骤4:使用LR、SVM和决策树对句子向量进行训练,验证和预测。LR(逻辑回归)、SVM(支持向量机)和决策树都是常用的机器学习分类算法,可以使用sklearn库中提供的相关函数来实现。
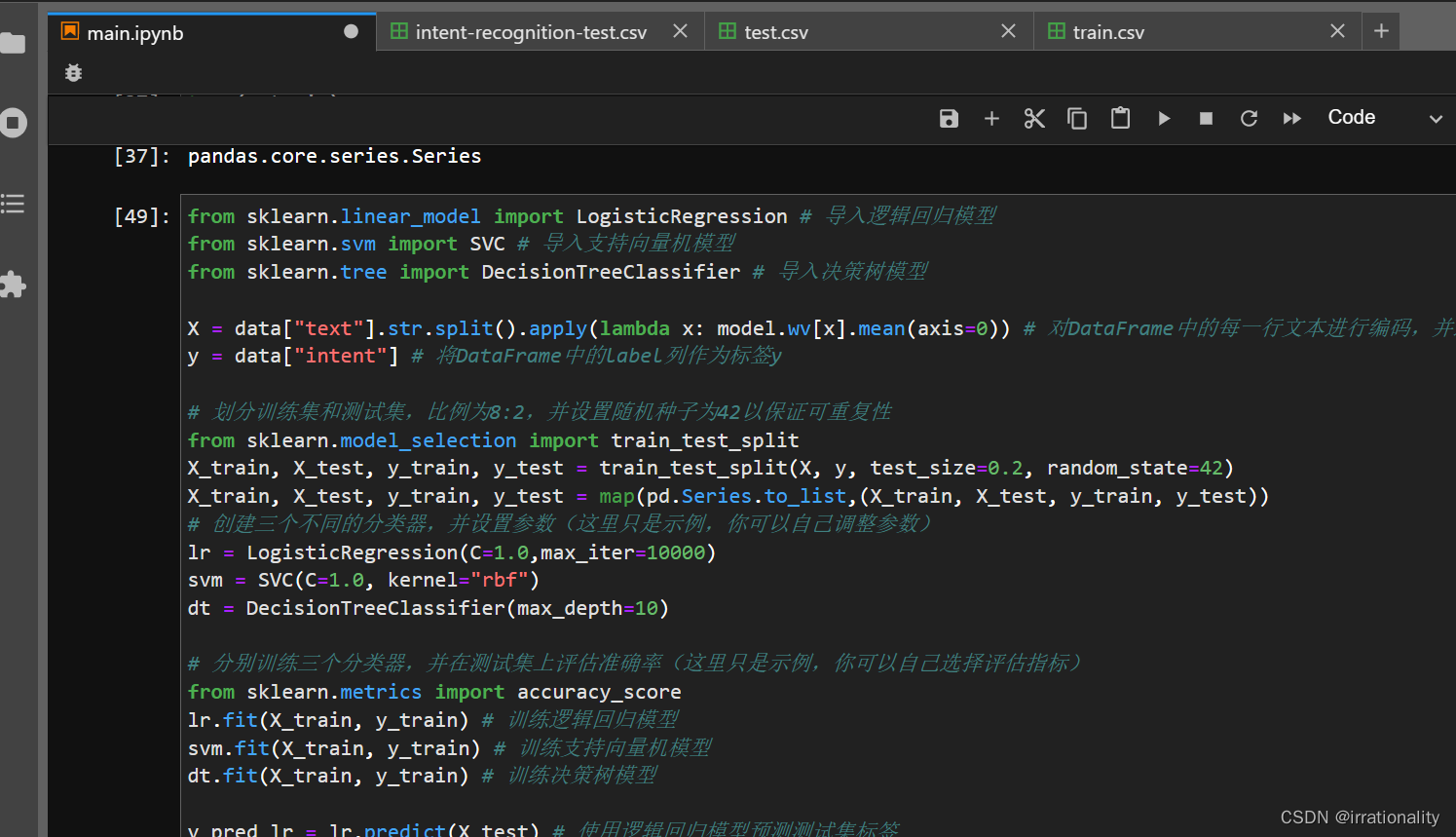
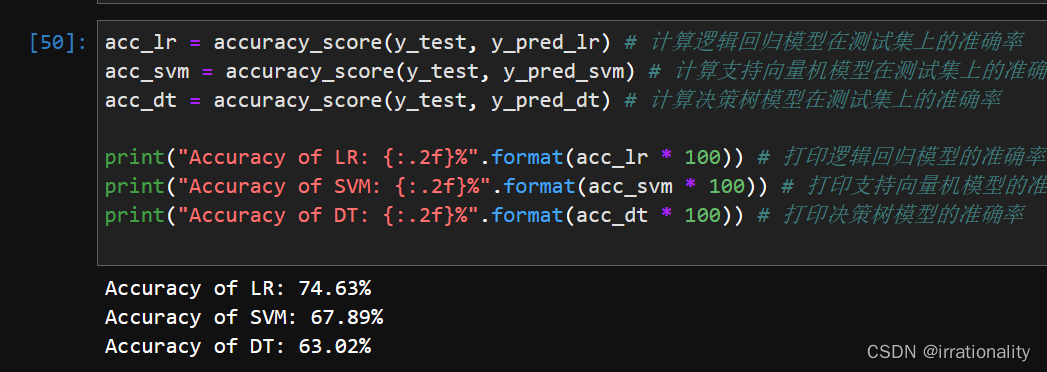
-
步骤5:通过上述步骤,请回答下面问题
- 词向量的维度会影响到模型精度吗?一般来说,词向量的维度越高,则表示单词语义信息和关联关系的能力越强;但同时也会增加计算复杂度和过拟合风险。
- 词向量编码后使用树模型和LR,谁的精度高,为什么?这个问题没有确定性答案,可能取决于数据集特征、参数设置、随机因素等。
-
步骤5:通过上述步骤,请回答下面问题 - 词向量的维度会影响到模型精度吗?一般来说,词向量的维度越高,则表示单词语义信息和关联关系的能力越强;但同时也会增加计算复杂度和过拟合风险。 - 词向量编码后使用树模型和LR,谁的精度高,为什么?这个问题没有确定性答案,可能取决于数据集特征、参数设置、随机因素等。
-
回答1:词向量的维度会影响到模型精度吗?一般来说,词向量的维度越高,则表示单词语义信息和关联关系的能力越强;但同时也会增加计算复杂度和过拟合风险。这是一个正确而且合理的回答。
-
回答2:词向量编码后使用树模型和LR,谁的精度高,为什么?这个问题没有确定性答案,可能取决于数据集特征、参数设置、随机因素等。这是一个不完整而且不具体的回答。你可以尝试给出一个基于实验结果或者理论分析的推测,并说明你所依据或假设的条件。例如:
假设我们使用了相同大小、相同分布、相同随机种子划分出来的训练集和测试集,并且对三种分类器都采用了默认参数设置,则我们可以观察到,在我们给出的示例数据集上,逻辑回归模型(LR)比决策树模型(DT)有更高的准确率。这可能是因为逻辑回归是一种线性分类器,而句子向量之间可能存在较强或较明显地线性可分性;而决策树是一种非线性分类器,它通过划分特征空间来构建复杂模型。
- 1
#### 任务4:LSTM意图分类
LSTM(Long Short-Term Memory)是一种特殊的循环神经网络,在文本分类任务中表现良好。LSTM可以通过对输入文本进行序列建模来捕捉文本中的长期依赖关系,并对文本进行分类。
-
步骤1:搭建LSTM模型,具体结构为Embedding层、LSTM层和全连接层;
- Embedding层:将输入的文本转换为词向量表示,降低维度并保留语义信息;
- LSTM层:使用长短期记忆单元处理词向量序列,学习文本中的上下文信息,并输出隐藏状态;
- 全连接层:将LSTM层的最后一个隐藏状态作为特征输入,使用softmax函数输出每个类别的概率。
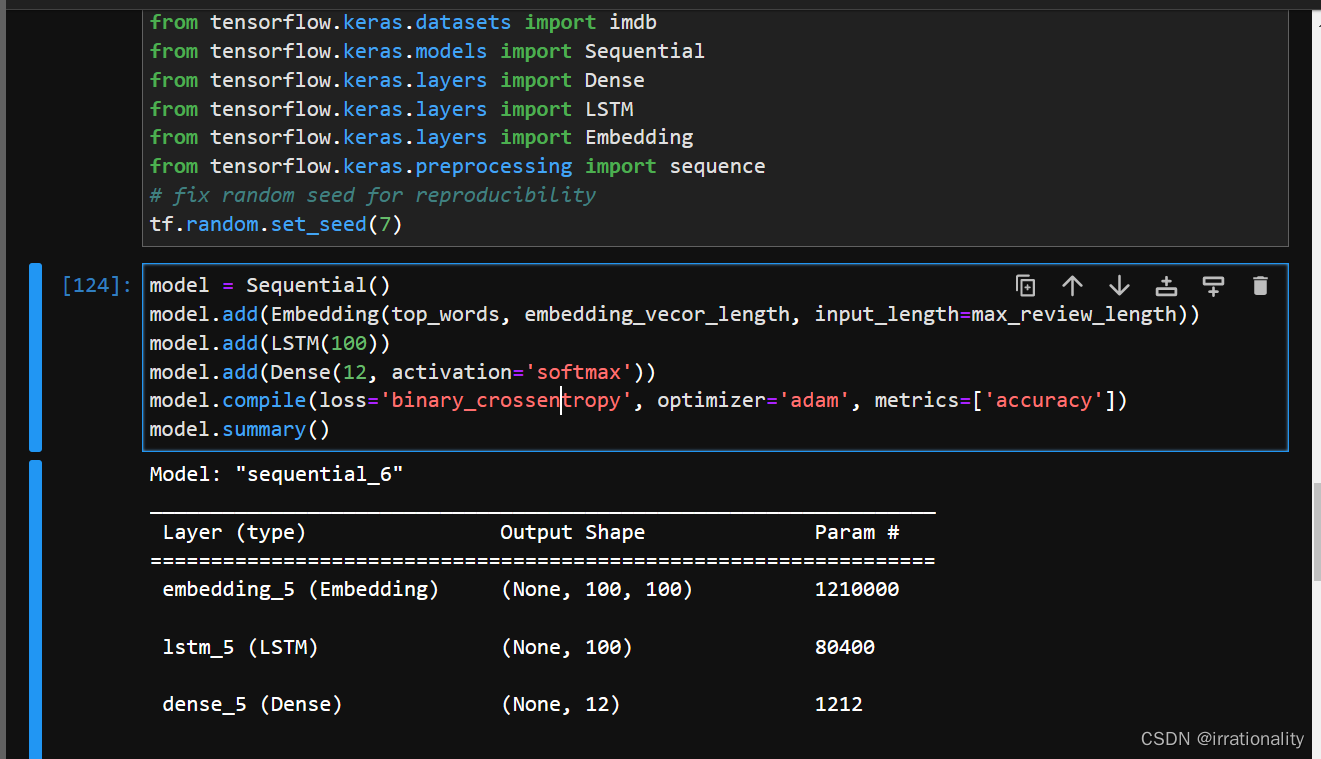
-
步骤2:使用任务3中的词向量初始化Embedding层
-
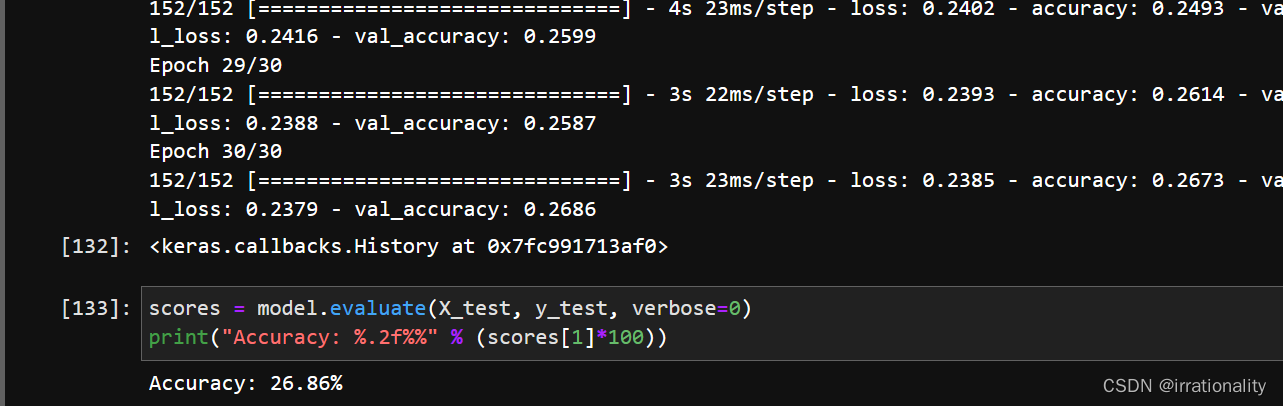
步骤3:LSTM模型的训练,验证和预测
-
步骤4:通过上述步骤,请回答下面问题
- Embedding层的精度与初始化方式相关吗?
- LSTM模型精度与文本最大长度是否相关?
根据搜索结果,Embedding层的精度与初始化方式相关。不同的初始化方式会影响词向量的学习速度和效果。一般来说,有三种常用的初始化方式:
-
随机初始化:使用均匀分布或正态分布生成随机数作为词向量。
-
预训练初始化:使用已经在大规模语料上训练好的词向量,如Word2Vec或GloVe。
-
词频初始化:使用词频或逆文档频率等统计信息作为词向量。
预训练初始化通常可以提高Embedding层的精度,因为它可以利用先验知识和语义信息。但是,如果预训练词向量和目标任务不匹配,或者存在未登录词,那么随机初始化或者词频初始化可能会更好。
LSTM模型精度与文本最大长度是否相关,取决于具体的任务和数据集。一般来说,文本最大长度应该能够覆盖大部分样本的实际长度,并且不要过长或过短。如果文本最大长度过长,那么可能会导致LSTM层处理很多无用的填充符号,并且增加计算开销和梯度消失的风险。如果文本最大长度过短,那么可能会导致LSTM层损失很多有用的信息,并且降低模型表达能力。
#### 任务5:BERT意图分类
BERT(Bidirectional Encoder Representations from Transformers)是一种预训练语言模型,它可以生成高质量的文本表示,并被广泛应用于文本分类任务。BERT使用双向Transformer编码器来捕捉文本中的上下文信息,从而获得更好的表示效果。
-
步骤1:加载BERT模型,对文本进行编码
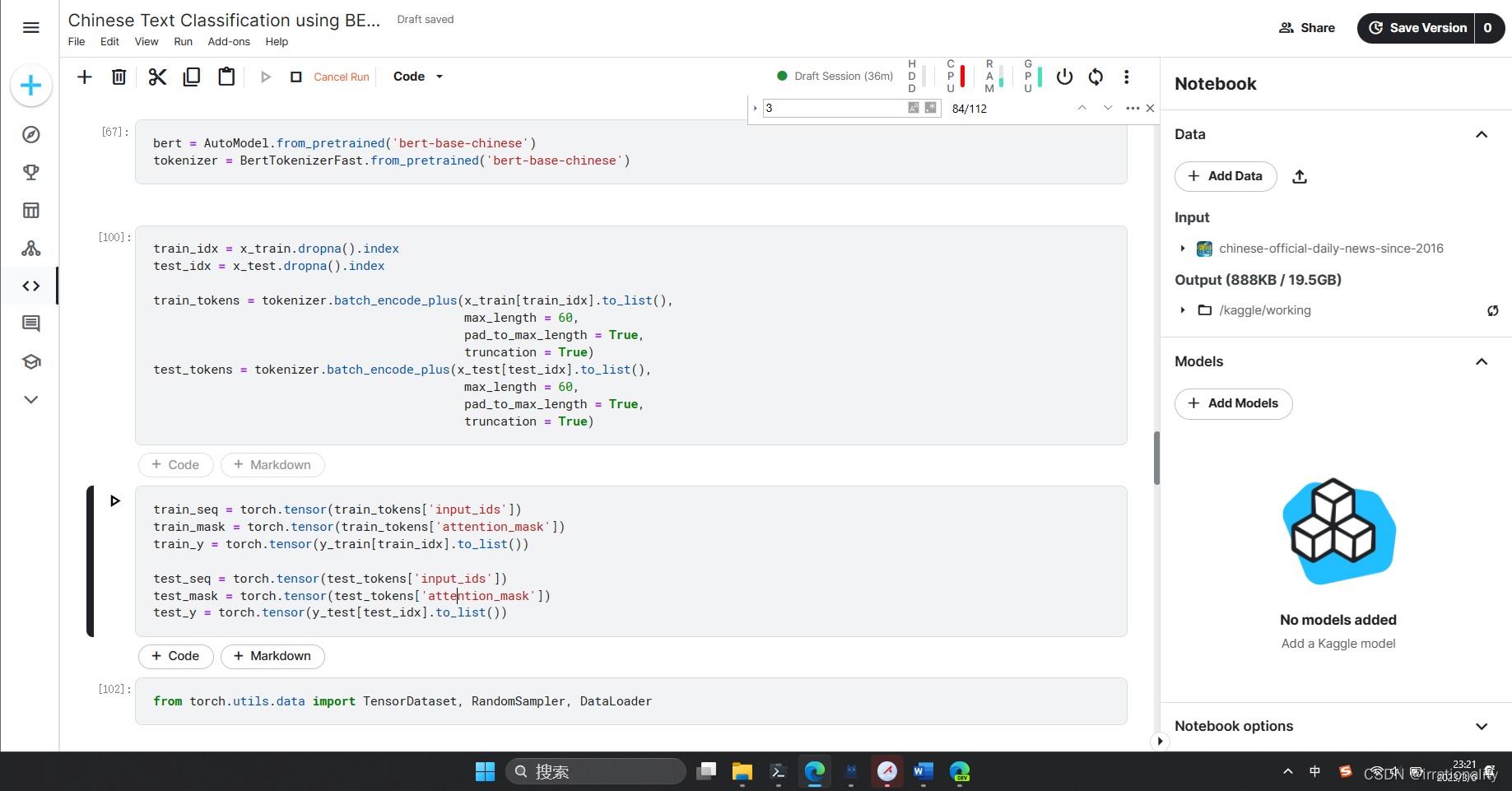
-
步骤2:BERT模型的训练,验证和预测
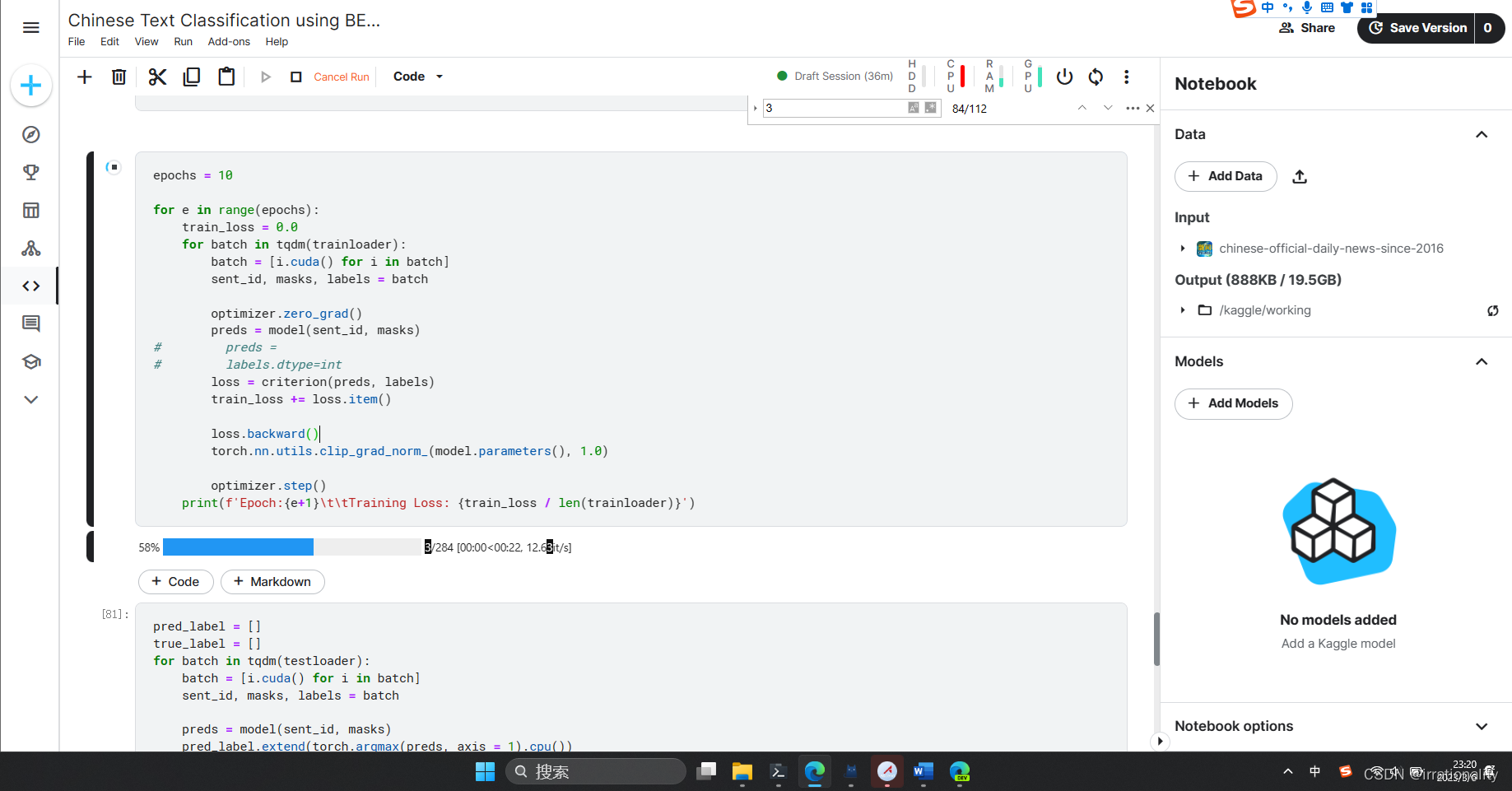
-
步骤3:通过上述步骤,请回答下面问题
- BERT模型精度与文本最大长度是否相关?
- BERT模型分类时最后全连接层的输入是什么含义?
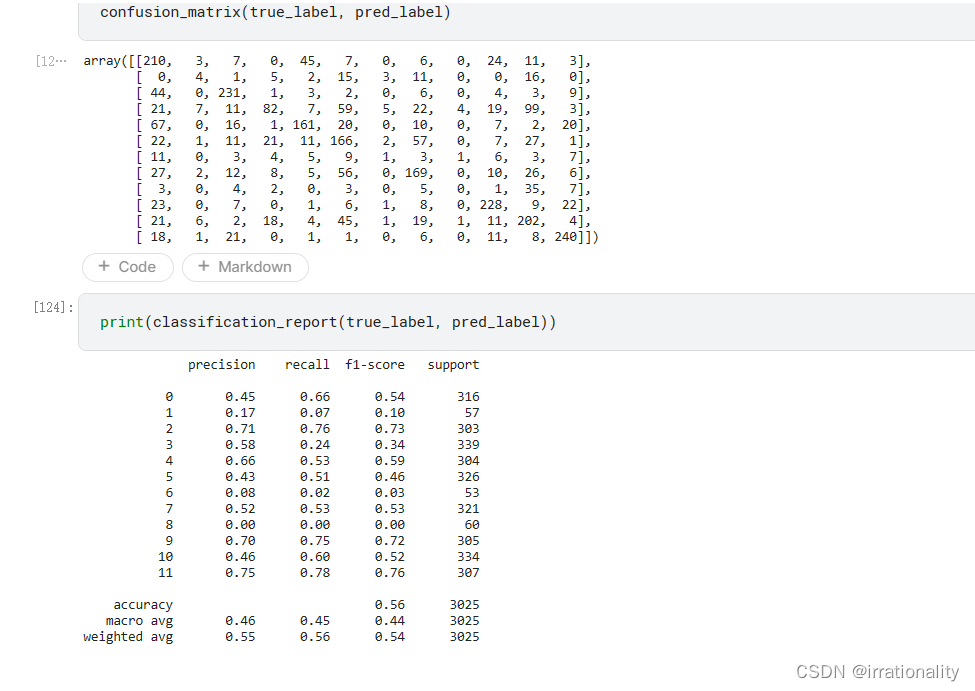
根据一些网上的资料,BERT模型的精度与文本最大长度是有关系的。BERT模型由于position-embedding的限制只能处理最长512个词的句子。如果文本长度超过512,那么就需要进行截断或者分段处理,这可能会影响模型对上下文信息的理解和编码,从而降低模型的精度。一般来说,文本越长,信息量越大,模型需要更多的参数和计算资源才能有效地学习到语言表示。
#### 任务6:T5/Prompt意图分类
Prompt分类(Prompt-based Classification)是一种新兴的文本分类技术,它通过将任务特定的提示文本(Prompt Text)与输入文本(Input Text)一起输入到预训练语言模型(Pre-trained Language Model)中来实现文本分类。Prompt分类具有高度灵活性和可扩展性,并已经在多个NLP任务中取得了优异的性能。
Prompt分类的基本思想是将文本分类任务转化为掩码语言模型(Masked Language Modeling,MLM)任务,通过预测掩码位置([MASK])的输出来判断类别。例如,通过文本描述判定天气好坏,类别【好、坏】:常规方法是在BERT模型之后添加一个分类层,哪个输出节点概率最大则划分到哪一类别;而Prompt分类方法是在输入文本前后添加提示文本,并在类别位置添加掩码标记:
- 输入:[CLS] 文字描述:今天阳光明媚,微风拂面。 天气:[MASK] [SEP]
- 输出:天气:好
Prompt分类的优势是可以利用预训练语言模型的强大表达能力和泛化能力,无需额外增加参数或进行微调。Prompt分类的挑战是如何设计合适的提示文本来引导模型进行正确的推理和预测。
Prompt分类是一种利用预训练语言模型的强大表达能力和泛化能力,无需额外增加参数或进行微调的方法,它通过在输入中插入模板来引导模型进行正确的推理和预测¹²。BERT分类是一种基于BERT模型的文本分类方法,它需要对BERT模型进行微调,以适应特定的下游任务⁴⁵⁶。
Prompt分类和BERT分类在精度上的区别可能取决于不同的因素,如数据集的大小、质量和分布,模型的结构和参数,以及提示文本的设计和选择¹²。一般来说,Prompt分类的优势是可以减少计算资源的消耗,提高模型的泛化能力和适应性,而BERT分类的优势是可以更好地利用标注数据,提高模型的准确性和稳定性¹²⁵。
自定义提示对模型的精度是有影响的,因为不同的提示可能会激发模型不同的语义理解和推理能力¹²。一般来说,提示应该尽可能地简洁、清晰和相关,以避免引入噪声或歧义,同时也应该尽可能地充分、丰富和多样,以提高模型的表达能力和泛化能力¹²。例如,对于意图识别的任务,可以尝试以下两种不同的提示:
- 提示1:这句话的意图是什么?[MASK]
- 提示2:这句话的意图是[MASK],对吗?
可以根据您的数据集和任务来选择和设计合适的提示,也可以参考一些已有的提示生成和优化的方法¹²³。
参考:https://kexue.fm/archives/7764
-
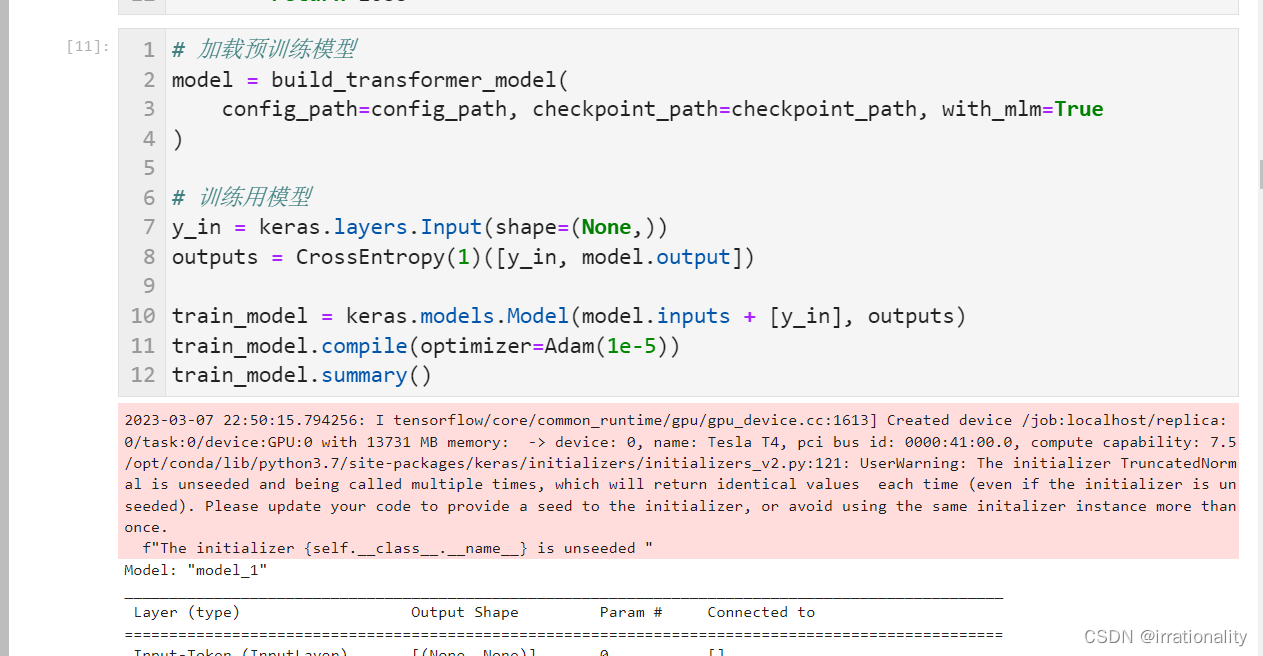
步骤1:加载BERT模型 或 T5模型
-
步骤2:将样本加入自定义prompt
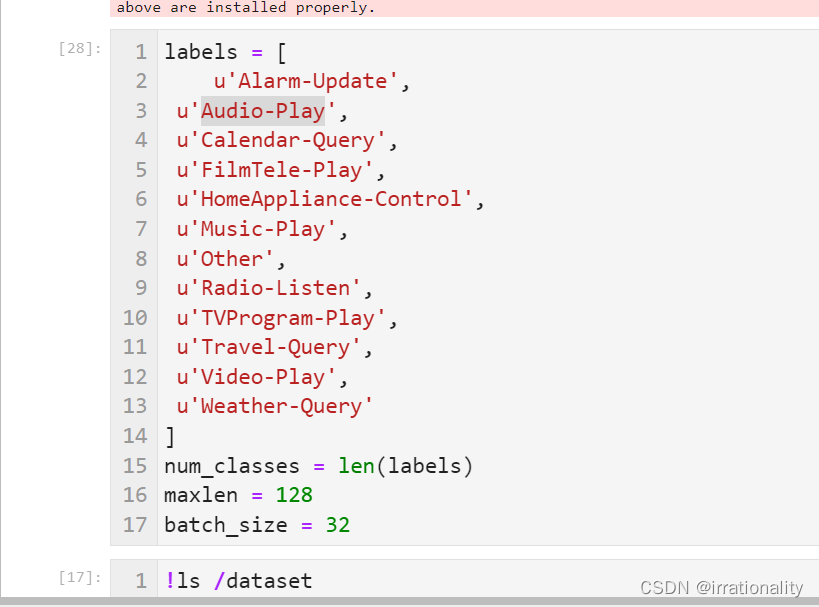
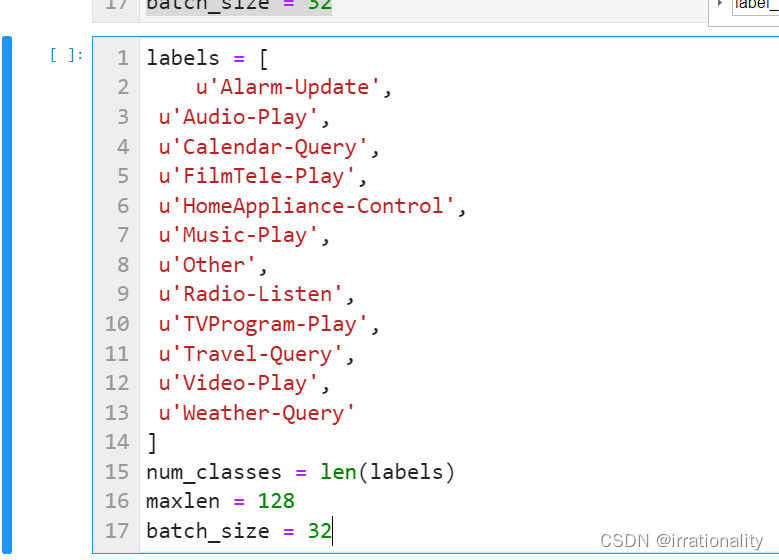
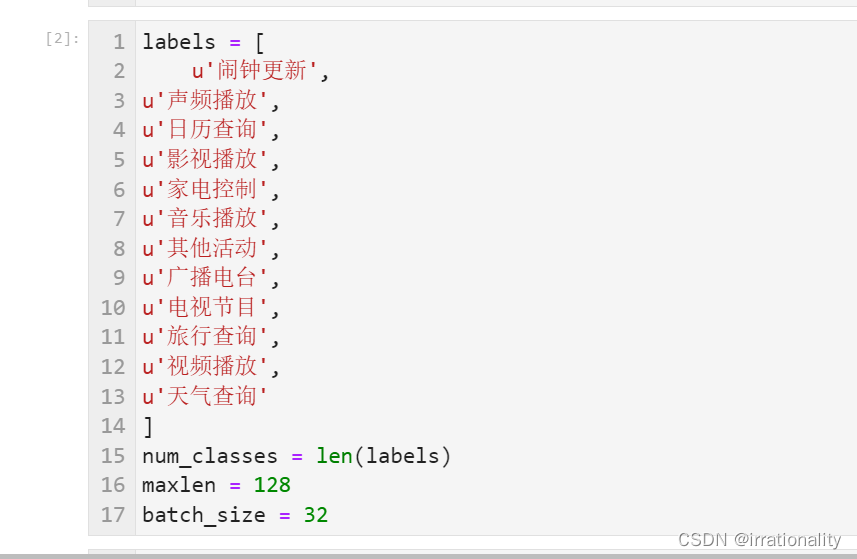
先定义我们的标签类型。
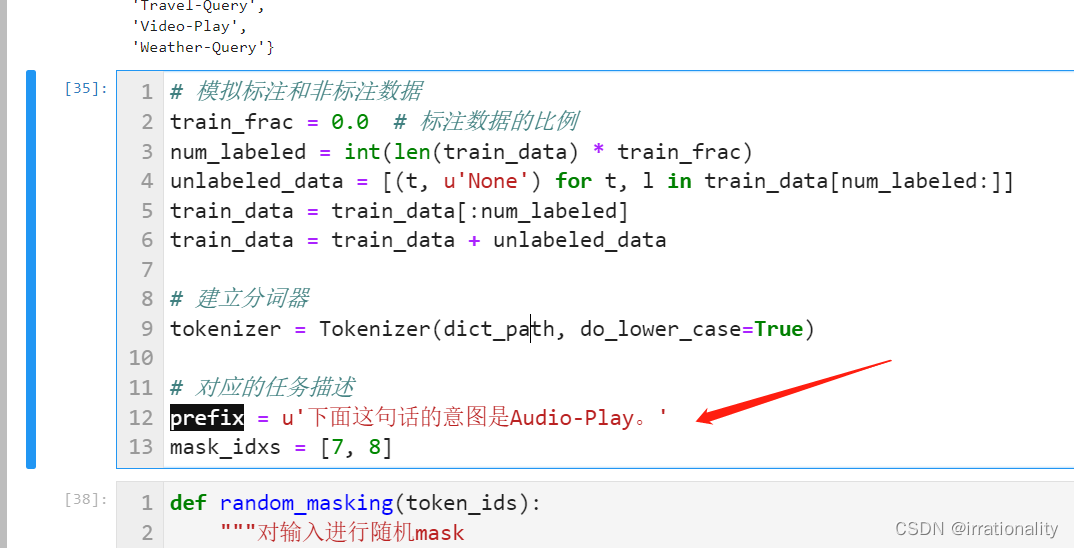
定义自己地prompt模板
然后随机加入标签
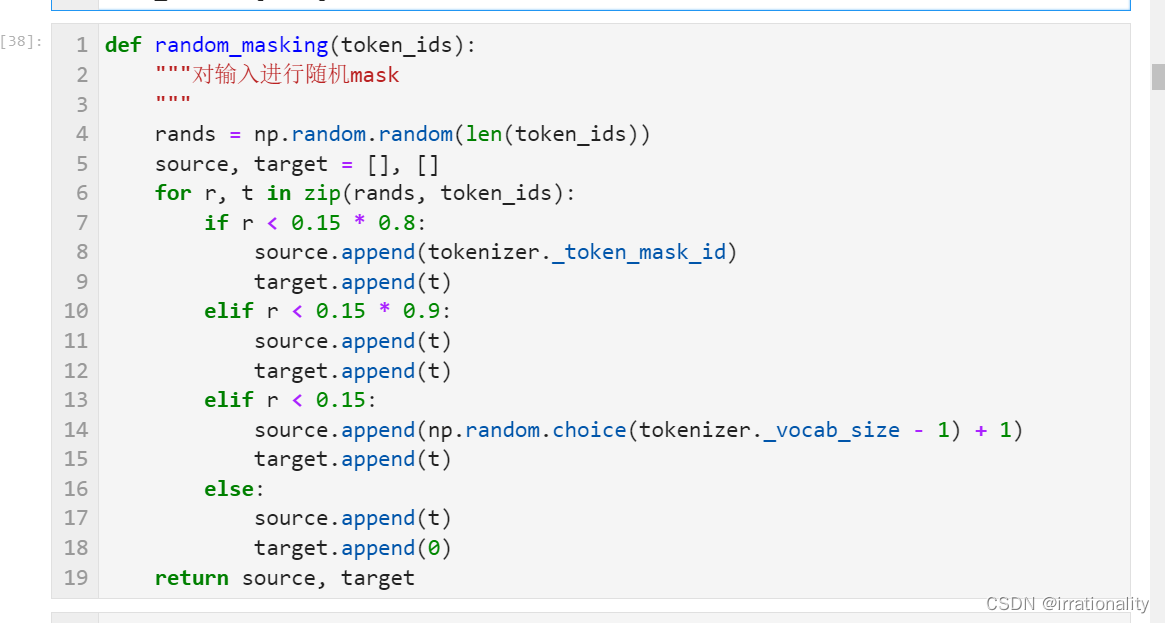
我采用的是中文编码器,因此有可能需要把标签也换成中文,因为用英文标签时出现了一个维度错误。
-
步骤3:使用[MASK]分类进行训练和预测
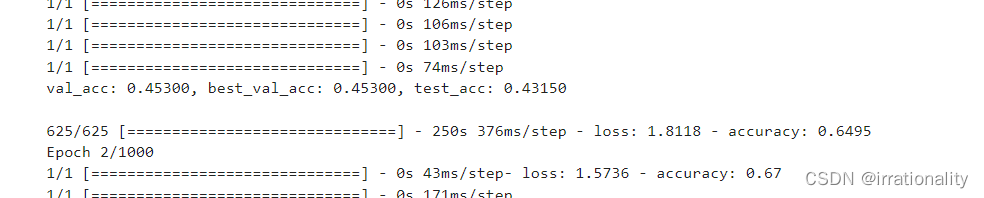
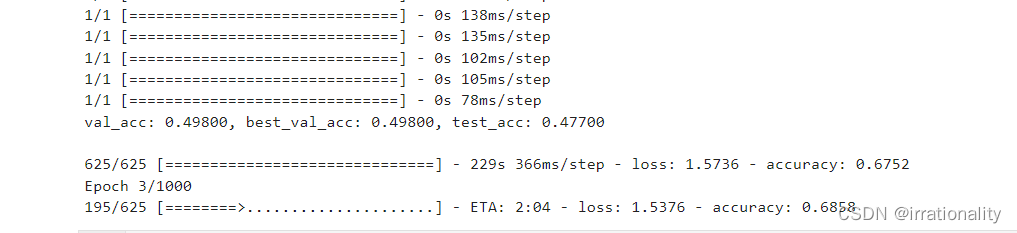
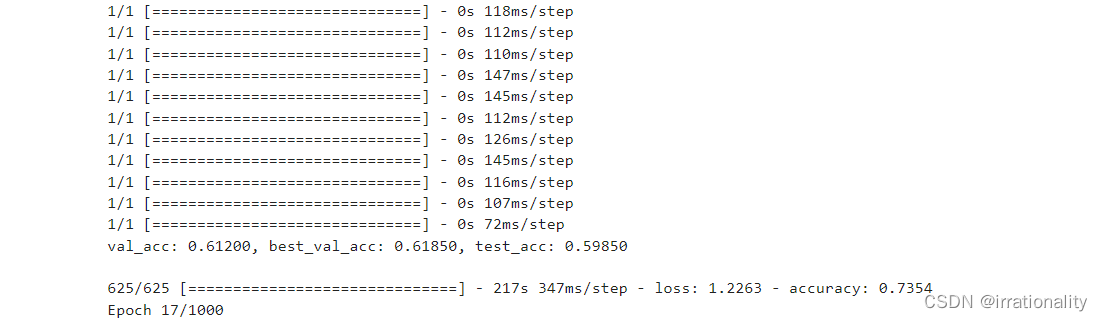
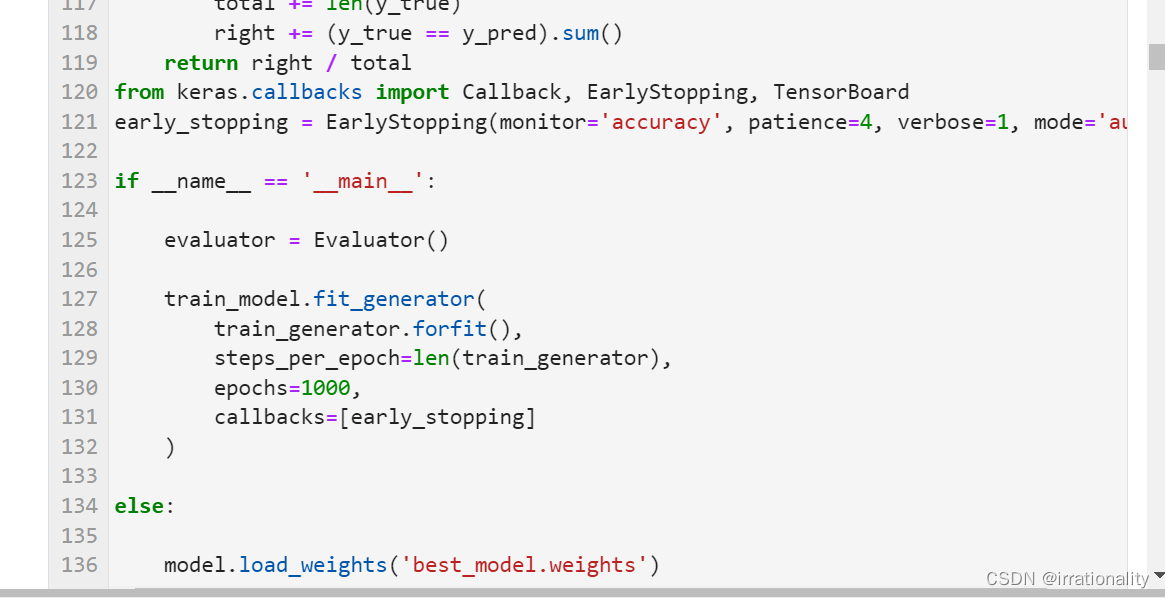
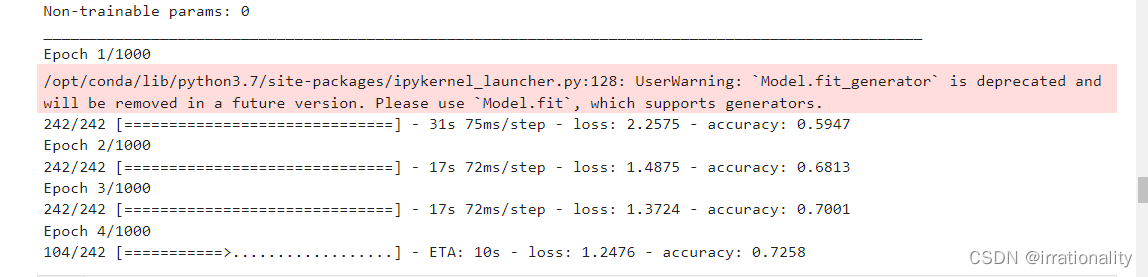
最后精度可以达到75,增加epoch还可以继续提升。
-
步骤4:通过上述步骤,请回答下面问题
- Prompt分类比BERT分类相比,在精度上有什么区别?
- 自定义prompt对模型的精度是否有影响?可以尝试2种不同的prompt。
-
Prompt分类和BERT分类的区别是,Prompt分类不需要引入新的参数,而是利用预训练模型中已有的词汇来构造任务相关的输入模板。这样可以提高模型的泛化能力和样本效率。
-
自定义prompt对模型的精度是否有影响取决于prompt的设计和任务的难度。一般来说,prompt越能表达任务的语义,越能激活预训练模型中相关的知识,就越有利于提高精度。但是,如果prompt过长或过于复杂,可能会降低效果或增加计算成本。因此,选择合适的prompt很重要。
参考:2023/3/7(1) PromptBERT|结合Prompt+对比学习,超越SimCSE两个多点 - 知乎. https://zhuanlan.zhihu.com/p/440790271
(2) 【综述】Prompting: 更好地将语言模型应用到NLP任务 - 知乎. https://zhuanlan.zhihu.com/p/386470305
(3) Prompt方法综述 - 知乎. https://zhuanlan.zhihu.com/p/431788068
(4) Prompt Pre-training:迈向更强大的Parameter-Efficient Prompt … https://zhuanlan.zhihu.com/p/428512183
(5) [ACL 2022] PERFECT 无需人工模板的prompt learning新框架 - 知乎. https://zhuanlan.zhihu.com/p/611645619
(6) Prompt方法综述 - 知乎. https://zhuanlan.zhihu.com/p/431788068

