
- 1JavaScript高级程序设计(红宝书)学习笔记_javascript程序设计
- 2微信扫码授权登录手游的原理和问题(你使用的浏览器暂不支持微信登录)
- 3关于如何调节Mahony AHRS算法的参数_mahoney算法不准确
- 4用JAVA和SPRINGBOOT点亮智慧公寓管理系统之路_公寓管理系统 java
- 56.3 表格结构_一个简单的表格结构可以没有
- 6<Healing Psoriasis The Natural Alternative>笔记(持续进行中)_蓖麻油热敷肝脏
- 7训练数据集(一):真实场景下采集的煤矸石目标检测数据集,可直接用于YOLOv5/v6/v7/v8训练_煤矸石数据集下载
- 8docker使用,Dockerfile构建示例_dockerfile文件示例
- 9论文开题报告生成器(智能AI写文献综述免费)_投喂论文生成综述
- 10探秘高效开源任务管理系统:[Daodao97/Oms](https://gitcode.com/daodao97/oms?utm_source=artical_gitcode)
LLMs之ChatGLM-2:ChatGLM2-6B的简介、安装、使用方法之详细攻略
赞
踩
LLMs之ChatGLM-2:ChatGLM2-6B的简介、安装、使用方法之详细攻略
导读:2023年06月25日,清华大学开源了 ChatGLM2-6B 模型,是 ChatGLM 模型的升级版本。ChatGLM2-6B 在多个方面有显著提升:模型性能更强,在各种测试集上的表现更好;支持更长的上下文,最大上下文长度提升到 32k;推理速度提高42%,能支持更长的生成;开源许可更加开放,允许商业使用。ChatGLM2-6B在多个维度的能力上取得了巨大提升,包括数理逻辑、知识推理和长文档理解。
模型性能提升主要来自升级的基座模型、混合了 GLM 目标函数、使用 FlashAttention 和Multi-Query Attention 技术。它整合了最新技术,在推理速度、生成长度、知识涵盖等方面取得突破,使人机对话能力更强大。
>> 更强大的性能=混合目标函数+1.4T中英标识符
>> 更长的上下文=Flash Attention技术+上下文长度扩展到32K+8K训练+多轮对话
>> 更高效的推理=Multi-Query Attention技术+INT4量化
>> 更开放的协议
目录
LLMs之GLM-130B/ChatGLM-1:《GLM-130B: AN OPEN BILINGUAL PRE-TRAINED MODEL》翻译与解读
LLMs之ChatGLM-2:ChatGLM2-6B的简介、安装、使用方法之详细攻略
LLMs之ChatGLM-3:ChatGLM3/ChatGLM3-6B的简介(多阶段增强+多模态理解+AgentTuning技术)、安装、使用方法之详细攻略
LLMs之GLM-4:GLM-4的简介(全覆盖【对话版即ChatGLM4的+工具调用+多模态文生图】能力→Agent)、安装和使用方法、案例应用之详细攻略
MLM之GLM-4:GLM-4-9B的简介、安装和使用方法、案例应用之详细攻略
LLMs之ChatGLM:ChatGLM Efficient Tuning(一款高效微调ChatGLM-6B/ChatGLM2-6B的工具【LoRA/P-Tunin】)的简介、安装、使用方法之详细攻略
LLMs之ChatGLM2:基于ChatGLM Efficient Tuning(微调工具包)实现对ChatGLM2进行LoRA微调并进行推理测试图文教程之详细攻略
LLMs:LangChain-Chatchat(一款可实现本地知识库问答应用)的简介、安装、使用方法之详细攻略
GLM模型系列
LLMs之GLM-130B/ChatGLM-1:《GLM-130B: AN OPEN BILINGUAL PRE-TRAINED MODEL》翻译与解读
LLMs之GLM-130B/ChatGLM:《GLM-130B: AN OPEN BILINGUAL PRE-TRAINED MODEL》翻译与解读-CSDN博客
LLMs之ChatGLM-2:ChatGLM2-6B的简介、安装、使用方法之详细攻略
LLMs之ChatGLM2:ChatGLM2-6B的简介、安装、使用方法之详细攻略_一个处女座的程序猿的博客-CSDN博客
LLMs之ChatGLM-3:ChatGLM3/ChatGLM3-6B的简介(多阶段增强+多模态理解+AgentTuning技术)、安装、使用方法之详细攻略
LLMs之ChatGLM3:ChatGLM3/ChatGLM3-6B的简介(多阶段增强+多模态理解+AgentTuning技术)、安装、使用方法之详细攻略-CSDN博客
LLMs之GLM-4:GLM-4的简介(全覆盖【对话版即ChatGLM4的+工具调用+多模态文生图】能力→Agent)、安装和使用方法、案例应用之详细攻略
LLMs之GLM-4:GLM-4的简介(全覆盖【对话版即ChatGLM4的+工具调用+多模态文生图】能力→Agent)、安装和使用方法、案例应用之详细攻略-CSDN博客
MLM之GLM-4:GLM-4-9B的简介、安装和使用方法、案例应用之详细攻略
MLM之GLM-4:GLM-4-9B的简介、安装和使用方法、案例应用之详细攻略-CSDN博客
实战案例
LLMs:从头到尾手把手教大家利用ChatGLM-6B模型实现训练、部署、推理(CLI/Gradio交互界面)、微调(两个提效技巧【混合精度+ZeRO零冗余提效】+三种微调方法【fine-tuning/P-tuning v2改变参数分布/LoRA低秩近似降低要更新参数量】)图文教程之详细攻略
https://yunyaniu.blog.csdn.net/article/details/120249551
LLMs之ChatGLM:基于Langchain框架利用text2vec-large-chinese+ChatGLM大模型(Docker 部署)接入本地知识库(生成本地知识库/分割/向量化+基于问题【Embdding+向量化+匹配TopK作为上下文】=生成Prompt喂给大模型→LLMs响应)实现问答响应项目(CLI/WebUI/VUE)图文教程之详细攻略
https://yunyaniu.blog.csdn.net/article/details/130998758
LLMs之ChatGLM:ChatGLM Efficient Tuning(一款高效微调ChatGLM-6B/ChatGLM2-6B的工具【LoRA/P-Tunin】)的简介、安装、使用方法之详细攻略
LLMs之ChatGLM2:ChatGLM2-6B本地部署之单机推理(API/CLI/GUI)、低成本部署(GPU量化部署/CPU及其量化部署/Mac部署/多卡部署)、有限资源下高效微调(全参/P-tuning v2)、模型评估和推理之图文教程之详细攻略
LLMs之ChatGLM2:基于ChatGLM Efficient Tuning(微调工具包)实现对ChatGLM2进行LoRA微调并进行推理测试图文教程之详细攻略
LLMs:LLaMA Efficient Tuning(一款可高效微调【全参数/LoRA/QLoRA】主流大模型【ChatGLM2/LLaMA2/Baichuan等】的高效工具【预训练+指令监督微调+奖励模型训练+PPO 训练+DPO 训练】)的简介、安装、使用方法之详细攻略
LLMs:LangChain-Chatchat(一款可实现本地知识库问答应用)的简介、安装、使用方法之详细攻略
LLMs:LangChain-Chatchat(一款可实现本地知识库问答应用)的简介、安装、使用方法之详细攻略_一个处女座的程序猿的博客-CSDN博客
LLMs之ChatGLM2:ChatGLM-Finetuning的简介、使用方法(四种微调方法(Freeze方法/Lora方法/P-Tuning方法/全量参数)+单卡/多卡训练设置+显存资源占用对比)、案例应用之详细攻略
https://yunyaniu.blog.csdn.net/article/details/132613495
LLMs之ChatGLM2:ChatGLM-Finetuning之源码解读(train.py文件)—解析命令行(模型路径+数据集相关【最大序列长度/最大输入长度】+训练参数相关【批次大小/学习率/权重衰减系数/训练轮数/梯度累计步数/学习率预热比例】+结果输出相关【输出路径/训练方式【四种方式微调,如Freeze/Lora/P-Tuning/全量参数】/进程标志/loss频率/保存模型频率】+否启用梯度检查点+DeepSpeed配置+LoRA/Freeze/P-tuning配置)及初始化设置(是否启用分布式GPU+加载DeepSpeed配置参数+日志写入器)→加载数据(加载tokenizer/训练集)→模型训练(载入优化器和学习率调度器并设置参数+判断启用梯度检查点+将模型和优化器包装到deepspeed中【DeepSpeed封装数据并行】+执行模型训练【训练epoch循环+迭代训练数据+计算loss+反向传播+梯度裁剪技术】)+模型保存(定期显示训练损失并保存模型,判断zero3训练时其模型参数需要合并保存)
| 链接 | GitHub地址:GitHub - THUDM/ChatGLM2-6B: ChatGLM2-6B: An Open Bilingual Chat LLM | 开源双语对话语言模型 huggingface地址:https://huggingface.co/THUDM/chatglm2-6b |
| 时间 | 2023年06月25日 |
| 作者 | 清华大学 |
ChatGLM2-6B的简介
ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性:
>> 更强大的性能=混合目标函数+1.4T中英标识符:基于 ChatGLM 初代模型的开发经验,我们全面升级了 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用了 GLM 的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,评测结果显示,相比于初代模型,ChatGLM2-6B 在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
>> 更长的上下文=Flash Attention技术+上下文长度扩展到32K+8K训练+多轮对话:基于 Flash Attention 技术,我们将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话。但当前版本的 ChatGLM2-6B 对单轮超长文档的理解能力有限,我们会在后续迭代升级中着重进行优化。
>> 更高效的推理=Multi-Query Attention技术+INT4量化:基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
>> 更开放的协议:ChatGLM2-6B 权重对学术研究完全开放,在获得官方的书面许可后,亦允许商业使用。如果您发现我们的开源模型对您的业务有用,我们欢迎您对下一代模型 ChatGLM3 研发的捐赠。
GitHub地址:https://github.com/THUDM/ChatGLM2-6B
huggingface地址:https://huggingface.co/THUDM/chatglm2-6b
1、对比:ChatGLM-6B、ChatGLM2-6B
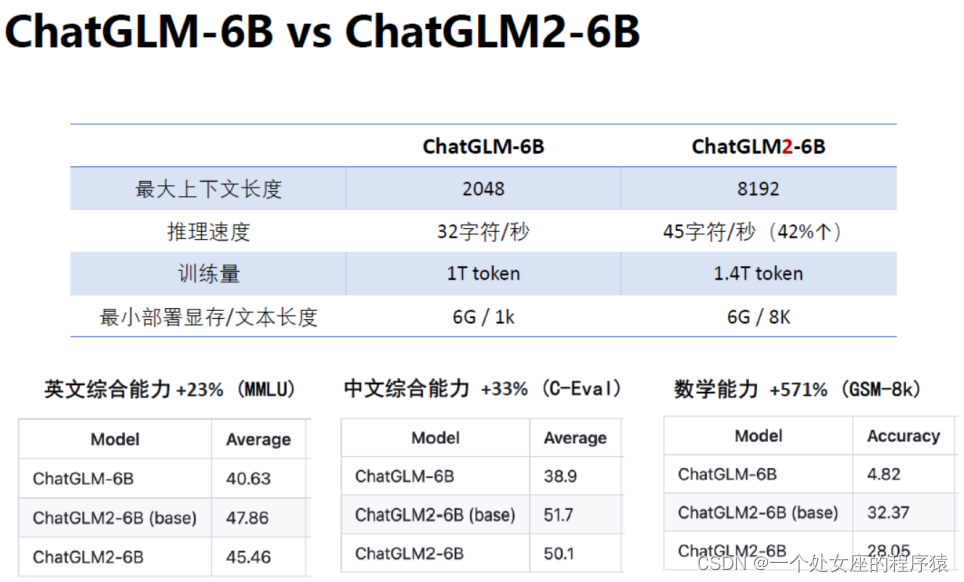
>>充分的中英双语预训练: ChatGLM2-6B 在 1:1 比例的中英语料上训练了 1.4T的token 量(*4倍≈5G的语料),兼具双语能力,相比于ChatGLM-6B初代模型,性能大幅提升。
>>较低的部署门槛: FP16 半精度下,ChatGLM-6B 需要至少13GB 的显存进行推理,结合模型量化技术,这一需求可以进一步降低到10GB(INT8)和 6GB(INT4), 使得 ChatGLM-6B 可以部署在消费级显卡上。
>>更长的序列长度: 相比GLM-10B(序列长度1024), ChatGLM-6B序列长度达 2048,ChatGLM2-6B序列 长度达8192(≈1万多的文字),支持更长对话和应用。
>>人类意图对齐训练: 使用了监督微调、反馈自助、人类反馈强化学习等方式,使模型初具理解人类指令意图的能力。
ChatGLM2-6B的安装
1、环境安装
(1)、首先需要下载本仓库
- git clone https://github.com/THUDM/ChatGLM2-6B
-
- cd ChatGLM2-6B
(2)、然后使用 pip 安装依赖
pip install -r requirements.txt其中 transformers 库版本推荐为 4.30.2,torch 推荐使用 2.0 以上的版本,以获得最佳的推理性能。
ChatGLM2-6B的使用方法
1、基础用法
(1)、代码调用
可以通过如下代码调用 ChatGLM2-6B 模型来生成对话:
- >>> from transformers import AutoTokenizer, AutoModel
- >>> tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
- >>> model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True, device='cuda')
- >>> model = model.eval()
- >>> response, history = model.chat(tokenizer, "你好", history=[])
- >>> print(response)
- 你好声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/煮酒与君饮/article/detail/862731推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

