
- 1win7安装spacy_spacy 依赖包
- 2【软件评测师】软件评测师教程(第2版):目录脑图_软件测评师教程第二版电子版
- 3关于Mysql的日期时间类型区分、比较和常用函数_mysql时间比较函数
- 4【阿里云原生架构】二、云原生架构的原则和模式_云原生架构本身作为一种架构,也有若干架构原则作为应用架构的核心架构控制面,通过
- 5怎样使用git add命令将当前修改的两个乃至多个文件一次性全部加入暂存区,不包括未跟踪的文件_git add.后没有全部进入缓存区
- 6面经|顺丰科技-大数据挖掘与数据分析工程师|一面|30min_顺丰科技nlp
- 7Sourcetree 克隆仓库,提交代码使用_sourcetree克隆仓库
- 8FS312 PD诱骗器芯片_fs312诱骗芯片
- 9Git、GitHub和GitLab的区别_gitlab和github的区别
- 10关系型数据库和非关系型数据库
2024年Go最全Golang常见面试题及解答_golang面试题(1),2024年最新2024最新大厂Golang面经_golang面试题2024
赞
踩

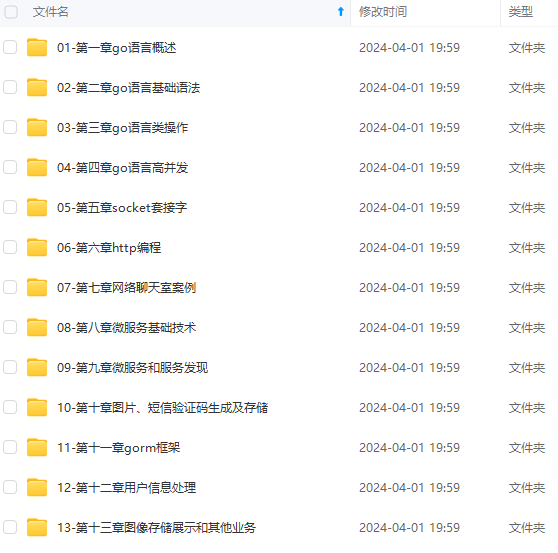
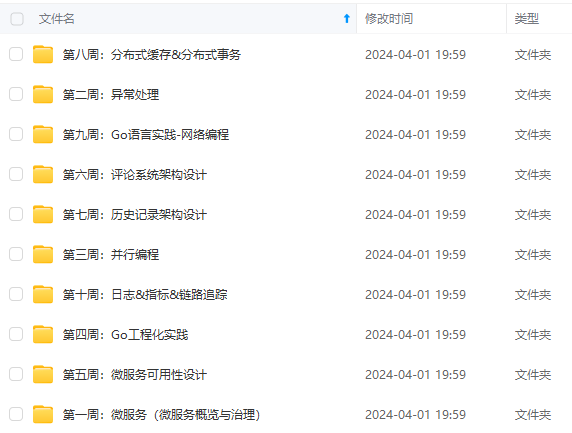
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
参考1:channel的应用场景
应用场景:
- select case实现多路通信监听
当我们要进行多goroutine通信时,则会使用select写法来管理多个channel的通信数据。 - 超时处理
select {
case <-time.After(time.Second):
- 1
- 2
- 3
- 定时任务
select {
case <- time.Tick(time.Second)
- 1
- 2
- 3
- 解耦生产者和消费者
生产者只需要往channel发送数据,而消费者只管从channel中获取数据。 - 控制并发数
可以通过channel来控制并发规模,使用的是有缓冲的channel,比如同时支持5个并发任务:
ch := make(chan int, 5)
for \_, url := range urls {
go func() {
ch <- 1
worker(url)
<- ch
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
4.2 channel的数据结构
channel的底层结构实现是hchan,所在位置:src/runtime/chan.go。
type hchan struct { qcount uint // total data in the queue dataqsiz uint // size of the circular queue buf unsafe.Pointer // points to an array of dataqsiz elements elemsize uint16 closed uint32 elemtype \*_type // element type sendx uint // send index recvx uint // receive index recvq waitq // list of recv waiters sendq waitq // list of send waiters // lock protects all fields in hchan, as well as several // fields in sudogs blocked on this channel. // // Do not change another G's status while holding this lock // (in particular, do not ready a G), as this can deadlock // with stack shrinking. lock mutex }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
可以看到hchan最后有一个mutex(锁)类型的lock字段,所有的发送和读取之前都要加锁,所以channel是线程安全的。
hchan各字段解读:
qcount:channel中环形队列当前存在的元素总数,len()返回该值。dataqsiz:环形队列的长度,即缓冲区可以容纳的元素数量,make时指定,cap()返回该值。buf:是一个指针,指向实际存储数据的缓冲区,缓存区基于环形队列实现,是一个连续的内存区域,用于存储channel中的元素。elemsize:单个元素的字节大小,用于确定每个元素在缓冲区中占用的空间。closed:channel关闭标志,用于表示channel是否已经关闭。当channel被关闭时,这个字段的值会被设置为非零。elemtype:元素的类型信息,包括元素的大小和对齐方式等。sendx:向channel发送数据时,写入的位置索引。recvx:从channel读数据时,读取的位置索引。recvq:buf空时,用于接收数据的goroutine等待队列,存储的是等待从channel接收数据的goroutine。sendq:buf满时,用于发送数据的goroutine等待队列,存储等待向channel发送数据的goroutine。lock:互斥锁,所有发送和读取之前都要加锁,保证同一时刻,只允许一个协程操作,所以channel是线程安全的。
channel在进行读写数据时,会根据无缓冲、有缓冲设置进行对应的阻塞唤起动作,它们之间还是有区别的。
总结: 有缓冲channel和无缓冲channel 的读写基本相差不大,只是多了缓冲数据区域的判断而已。
4.3 无缓冲channel的读写
无缓冲的channel(也称为阻塞式channel)是一种用于在协程之间进行同步的通信方式。无缓冲的channel的读写操作具有阻塞特性,这意味着在特定条件下,读写先后顺序不同,处理也会有所不同,所以还得再进一步区分:
4.3.1 无缓冲channel先写再读
在这里,我们暂时认为有 2 个goroutine在使用channel通信,按先写再读的顺序,则具体流程如下:

可以看到,由于channel是无缓冲的,所以G1暂时被挂在sendq队列里,然后G1调用了gopark休眠了起来。
接着,又有goroutine G2来channel读取数据了:

此时G2发现sendq等待队列里有goroutine存在,于是直接从G1 copy数据过来,并且会对G1设置goready函数,这样下次调度发生时,G1就可以继续运行,并且会从等待队列里移除掉。
4.3.2 无缓冲channel先读再写
先读再写的流程跟上面一样。【只是流程一样】

G1暂时被挂在了recvq队列,然后休眠起来。
G2在写数据时,发现recvq队列有goroutine存在,于是直接将数据发送给G1。同时设置G1 goready函数,等待下次调度运行。

4.4 有缓冲channel的读写
在分析完了无缓冲channel的读写后,我们继续看看有缓冲channel的读写。同样的,我们分为 2种情况。
4.4.1 有缓冲channel先写再读
这一次会优先判断缓冲数据区域是否已满,如果未满,则将数据保存在缓冲数据区域,即环形队列里。如果已满,则和之前的流程是一样的。

当G2要读取数据时,会优先从缓冲数据区域去读取,并且在读取完后,会检查sendq队列,如果goroutine有等待队列,则会将它上面的data补充到缓冲数据区域,并且也对其设置goready函数。

4.4.2 有缓冲channel先读再写
此种情况和无缓冲的先读再写是一样流程,此处不再重复说明。
4.5 channel的创建
4.5.1 无缓冲的channel
ch := make(chan T)
- 1
- 2
无缓冲的channel是阻塞式的:
- 当有发送端往channel中发送数据,但无接收端从channel中取数据时,发送端阻塞。
- 当无发送端往channel中发送数据,但有接收端从channel中取数据时,接收端阻塞。
4.5.2 有缓冲的channel
ch := make(chan T, 2)
- 1
- 2
第二个参数表示channel中可缓冲类型T的数据容量。只要当前channel里的元素总数不大于这个可缓冲容量,则当前的goroutine就不会被阻塞住。
4.5.3 为nil的channel
参考1:golang 系列:channel 全面解析
创建这样一个nil的channel是没有意义,读、写channel都将会被阻塞住。一般为nil的channel主要用在select 上,让select不再从这个channel里读取数据,达到屏蔽case的目的。
ch1 := make(chan int) ch2 := make(chan int) go func() { if !ok { // 某些原因,设置 ch1 为 nil ch1 = nil } }() for { select { case <-ch1: // 当 ch1 被设置为 nil 后,将不会到达此分支了。 doSomething1() case <-ch2: doSomething2() } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
4.6 关闭channel
当我们不再使用channel的时候,可以对其进行关闭:
close(ch)
- 1
- 2
提示:有缓冲的通道和无缓冲的channel关闭结果都是一样的。
4.6.1 往一个关闭的channel读写会怎样
- 当channel被关闭后,如果继续往里面写数据,会引起
panic: send on closed channel,然后退出程序。 - 读取关闭后的channel,不会产生pannic,还是可以读到数据。关闭后的channel缓冲中如果有数据,读取到缓冲中的数据,channel缓冲中如果没有数据,再继续读取将得到零值,即对应类型的默认值。
4.6.2 如何判断channel是否关闭
判断channel是否关闭可以通过返回状态是false或true来确定,返回false代表已经关闭。
if v, ok := <-ch; !ok {
fmt.Println("channel 已关闭,读取不到数据")
}
- 1
- 2
- 3
- 4
4.6.3 重复(多次)关闭channel会怎么样
重复(多次)关闭channel会报panic: close of closed channel(关闭已关闭的channel)。
4.6.4 关闭channel的时候应该怎么关闭,有什么注意事项吗?
关闭通道的注意事项有以下几点:
- 关闭后的通道不可再发送值:一旦通道被关闭,就不能再向其发送值。尝试向已关闭的通道发送值将导致
panic。 - 关闭后的通道仍可接收值:已关闭的通道仍然可以接收之前被发送到通道的值,直到通道中的所有值都被接收。尝试从已关闭的空通道接收值将会得到零值,并且不会导致阻塞。
- 重复关闭通道会导致panic:尝试关闭已经关闭的通道将导致
panic。因此,在关闭通道之前,建议检查通道是否已经关闭。 - 关闭通道是一个广播操作:通道的关闭是一个广播操作,所有从该通道接收数据的协程都将在接收到通道关闭的消息后立即结束。这是用于通知接收方不再有值可用的一种机制。
- 使用range遍历通道:通过使用
range可以方便地遍历通道,当通道被关闭时,range循环将会结束。
4.6.5 关闭channel的时候如果里面的值就是零值,这个该怎么判断是否要关闭?
在Golang中,关闭一个通道时,通道中的值会被正常接收,即接收方会收到通道中的零值。因此,当关闭通道时,接收方无法通过接收到的零值来判断是否是因为通道关闭而接收到的。
通常来说,在Golang中关闭通道时,是通过发送一个信号值告知接收方通道已经关闭。这样的信号值可以是某个特定的值,也可以通过额外的信息来传递。以下是一种常见的模式,使用一个额外的布尔类型的通道来表示是否关闭:
ch := make(chan int) closeSignal := make(chan bool) go func() { // 一些业务逻辑,将结果发送到通道 ch result := 42 ch <- result // 关闭通道 close(ch) // 发送关闭信号 closeSignal <- true }() // 接收结果 result := <-ch fmt.Println(result) // 等待关闭信号 <-closeSignal fmt.Println("Channel closed")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
在这个例子中,closeSignal是一个用于传递关闭信号的通道。当通道ch关闭时,会先发送结果值,然后再发送关闭信号。接收方先接收结果值,然后再等待关闭信号。这样可以确保接收方在接收到结果值后知道通道已经关闭。
总的来说,通常不依赖通道中的零值来判断通道是否关闭,而是使用额外的机制(如关闭信号通道)来明确地表示通道的关闭状态。这样可以更加清晰和可靠地处理通道的关闭。
4.7 channel的deadlock(死锁)或channel一直阻塞会怎样
参考1:golang 系列:channel 全面解析
不论是有缓冲通道和无缓冲通道,往channel里读写数据时是有可能被阻塞住的,一旦被阻塞,则需要其他的goroutine执行对应的读写操作,才能解除阻塞状态。
如果阻塞状态一直没有被解除,Go可能会报 fatal error: all goroutines are asleep - deadlock! 错误,所以在使用channel时要注意goroutine的一发一取,避免goroutine永久阻塞!
4.8 不要通过共享内存来通信,要通过通信来共享内存
- 使用共享内存的话在多线程的场景下为了处理竞态,需要加锁,使用起来比较麻烦。另外使用过多的锁,容易使得程序的代码逻辑艰涩难懂,并且容易使程序死锁,死锁了以后排查问题相当困难,特别是很多锁同时存在的时候。
- go语言的channel保证同一个时间只有一个goroutine能够读写channel里的数据,为开发者提供了一种优雅简单的工具,所以go原生的做法就是使用channel来通信,而不是使用共享内存来通信。
4.9 往一个只声明未初始化的channel里写入数据会怎样
参考1:对未初始化的的chan进行读写,会怎么样?为什么?
综合:4.5.3 为nil的channel和4.7 channel的deadlock(死锁)或channel一直阻塞会怎样。
只声明未初始化的channel说的就是为nil时的情况,它会阻塞读写,如果一直处于阻塞状态会报死锁fatal error: all goroutines are asleep - deadlock!。
答:读写未初始化的 chan 都会阻塞。
报 fatal error: all goroutines are asleep - deadlock!
为什么对未初始化的 chan 就会阻塞呢?
- 对于写的情况
- 未初始化的 chan 此时是等于 nil,当它不能阻塞的情况下,直接返回 false,表示写 chan 失败。
- 当 chan 能阻塞的情况下,则直接阻塞 gopark(nil, nil, waitReasonChanSendNilChan, traceEvGoStop, 2), 然后调用 throw(s string) 抛出错误,其中 waitReasonChanSendNilChan 就是刚刚提到的报错 “chan send (nil chan)”。
- 对于读的情况
- 未初始化的 chan 此时是等于 nil,当它不能阻塞的情况下,直接返回 false,表示读 chan 失败
- 当 chan 能阻塞的情况下,则直接阻塞 gopark(nil, nil, waitReasonChanReceiveNilChan, traceEvGoStop, 2), 然后调用 throw(s string) 抛出错误,其中 waitReasonChanReceiveNilChan 就是刚刚提到的报错 “chan receive (nil chan)”。
4.10 哪些场景有使用到Goroutine、channel
并发处理。有缓冲的channel可以控制并发数目,从而实现多线程并发处理。
4.11 在select case中如何屏蔽已关闭的channel
首先判断channel是否关闭了,判断是关闭的channel后将这个通道设置为nil,因为设置为nil,这个通道就阻塞住了,select会选择其他没有阻塞的channel来执行,这样达到一个屏蔽的效果。
4.12 有缓冲通道和无缓冲通道的区别
无缓冲的通道实质是通道容量为0,这是它和有缓冲通道的表象区别。实质区别从4.2 channel 的数据结构到4.3 无缓冲channel的读写和4.4 有缓冲channel的读写。
无缓冲的channel可以用来同步通信、超时等。有缓冲的channel可以用来解耦生产者、消费者,并发控制。
4.13 哪些场景下使用channel会导致panic
参考1:https://jishuin.proginn.com/p/763bfbd381cb
- 关闭一个 nil 值 channel 会引发 panic。
- 关闭一个已关闭的 channel 会引发 panic。
- 向一个已关闭的 channel 发送数据。
综合1、2、3可知,在操作为nil或关闭的channel会导致panic。
4.14 channel怎么做到线程安全的
channel底层的结构是hchan,hchan最后有一个mutex(锁)类型的lock字段,所有的发送和读取之前都要加锁,所以channel是线程安全的。
4.15 channel取值的时候,左值既可以一个值,又可以两个值?go是怎么实现的?
是通过Go语言的通道特性和多重返回值的机制来实现的。
5 map
5.1 map的基本操作
package main import "fmt" func main() { //1、初始化 m1 := map[string]int{} m2 := make(map[string]int, 10) //2、插入数据 m1["AA"] = 10 m1["BB"] = 20 m1["CC"] = 30 m2["AA"] = 10 m2["BB"] = 20 m2["CC"] = 30 //3、访问数据 fmt.Println("m1 AA=", m1["AA"]) fmt.Println("m2 BB=", m2["BB"]) fmt.Println() //4、删除 delete(m1, "AA") delete(m2, "BB") fmt.Println("m1 AA=", m1["AA"]) fmt.Println("m2 BB=", m2["BB"]) fmt.Println() //5、遍历 for key, value := range m1 { fmt.Println("m1 Key=", key, ";Value=", value) } fmt.Println() for key, value := range m2 { fmt.Println("m2 Key=", key, ";Value=", value) } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
5.1.1 map初始化
未初始化的map的值是nil,使用函数len() 可以获取map中键值对的数目。
- 使用字面量初始化,类似于JSON对象的初始化。
m1 := map[string]int{}
//或
person := map[string]string{
"name": "John",
"age": "30",
"city": "New York",
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 使用make初始化,cap是可选字段,用于提前声明了map的初始容量,可以避免频繁的扩容操作,提高性能。
m2 := make(map[string]int, cap)
- 1
- 2
注意: 可以使用 make(),但不能使用 new() 来构造 map,如果错误的使用 new() 分配了一个引用对象,会获得一个空引用的指针,相当于声明了一个未初始化的变量并且取了它的地址。
5.1.2 map插入数据
map[key] = value
- 1
- 2
5.1.3 访问数据map中的数据
map[key]
- 1
- 2
5.1.4 删除map中的数据
delete(map, key)
- 1
- 2
5.1.5 清空map中所有数据
Go语言中并没有为 map 提供任何清空所有元素的函数、方法,清空map的唯一办法就是重新 make一个新的map,不用担心垃圾回收的效率,Go语言中的并行垃圾回收效率比写一个清空函数要高效的多。
5.1.6 遍历map
for key, value := range map {
fmt.Println("map Key=", key, ";Value=", value)
}
- 1
- 2
- 3
- 4
map创建后实际是返回了hmap结构体,是使用数组+链表的形式实现的,使用拉链法消除hash冲突。
5.2 哈希表的两种实现方式
参考1:Golang源码探究 — map
开放寻址法、拉链法。
5.2.1 开放寻址法
参考1:开放寻址法(有更详细的介绍)
开放寻址法是一种将所有的键值对都存储在一个大数组中的方法。当发生哈希冲突(多个键映射到同一个位置)时,开放寻址法会尝试在数组中的其他位置继续寻找空闲槽位,直到找到一个空槽位或者遍历整个数组。开放寻址法有几种不同的策略,包括线性寻址、二次寻址和双重哈希寻址。
- 线性寻址:当需要插入元素的位置被占用时,顺序向后寻址,如果到数组最后也没找到一个空闲位置,则从数组开头寻址,直到找到一个空闲位置插入数据。线性寻址的每次寻址步长是1,寻址公式hash(key)+n(n是寻址的次数)。
- 二次方寻址:就是线性寻址的总步长的二次方,即hash(key)+n^2。
- 双重哈希寻址:顾名思义就是多次哈希直到找到一个不冲突的哈希值。
5.2.2 拉链法(map使用的方式)
拉链法是一种在哈希表的每个槽位中存储一个链表(或其他数据结构,比如红黑树),用于存储冲突的键值对。当发生哈希冲突时,新的键值对会被添加到对应槽位的链表中。这样,每个槽位可以存储多个键值对,并且链表的操作可以在冲突的情况下更加高效。
拉链法可以扩展到更复杂的数据结构,如平衡二叉搜索树,以提高在冲突时的查找效率。
5.2.3 两种方式的总结
- 在实际应用中,选择使用哪种哈希表实现方式取决于多种因素,包括哈希函数的选择、负载因子、内存分配等。
- 开放寻址法:通常在存储空间效率方面更加高效,因为它避免了链表节点的额外开销。然而,当负载因子较高时,开放寻址法的性能可能会下降,因为冲突的频率会增加。
- 拉链法:通常在处理冲突时更加稳定,并且可以处理负载因子较高的情况,但它可能会导致额外的内存开销。选择适合场景的哈希表实现方式可以在性能和资源使用方面取得平衡。
5.3 map的数据结构
参考1:Golang 中 map 探究
参考2:golang map实现原理浅析
参考3:Golang Map原理(底层结构、查找/新增/删除、扩缩容)
map的底层实现是一个哈希表,因此实现map的过程实际上就是实现哈希表的过程。在这个哈希表中,主要出现的结构体有两个,一个叫hmap(a header for a go map),一个叫bmap(a bucket for a Go map,通常叫其bucket)。
map底层的数据结构是由hmap实现的,hmap的结构体是在runtime/map.go:
// A header for a Go map. type hmap struct { // Note: the format of the hmap is also encoded in cmd/compile/internal/reflectdata/reflect.go. // Make sure this stays in sync with the compiler's definition. count int // # live cells == size of map. Must be first (used by len() builtin) flags uint8 B uint8 // log\_2 of # of buckets (can hold up to loadFactor \* 2^B items) noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details hash0 uint32 // hash seed buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0. oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated) extra \*mapextra // optional fields }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
hmap各字段解读:
count:当前map中的键值对数量,调用len(map)返回这个值。flags:标志位,用于表示map的状态。B:2^B表示bucket的数量,B表示取hash后多少位来做bucket的分组,再多就要扩容了。noverflow:溢出桶的个数。hash0:hash seed(hash 种子)一般是一个素数,用于计算哈希值。buckets:指向bucket数组的指针(存储key val);大小:2^B,如果没有元素存入,这个字段可能为nil。oldbuckets:在扩容期间,将旧的bucket数组放在这里,新buckets会是oldbuckets的两倍大,用于实现平滑的扩容操作。nevacuate:即将迁移的旧桶编号,可以作为搬迁进度,小于nevacuate的表示已经搬迁完成。extra:用于存储额外的信息,如迭代器状态等。
bucket数组里存储的是bmap,bmap在runtime/map.go中,它的所有字段如下:
// A bucket for a Go map.
type bmap struct {
// tophash generally contains the top byte of the hash value
// for each key in this bucket. If tophash[0] < minTopHash,
// tophash[0] is a bucket evacuation state instead.
tophash [bucketCnt]uint8
// Followed by bucketCnt keys and then bucketCnt elems.
// NOTE: packing all the keys together and then all the elems together makes the
// code a bit more complicated than alternating key/elem/key/elem/... but it allows
// us to eliminate padding which would be needed for, e.g., map[int64]int8.
// Followed by an overflow pointer.
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
但这只是表面,实际上在golang runtime时,编译器会动态为bmap创建一个新结构:
type bmap struct {
topbits [8]uint8 //高位哈希值数组
keys [8]keytype // 存储key的数组
values [8]valuetype // 存储val的数组
pad uintptr // 内存对齐使用,可能不需要
overflow uintptr // bucket的8个key存满了之后,指向当前bucket的溢出桶
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
bmap就是hmap中的的bucket(桶)的底层数据结构,一个桶中可以存放最多8个key/value,map使用hash函数得到hash值决定分配到哪个桶,然后又会根据hash值的高8位来寻找放在桶的哪个位置,具体的map的组成结构如下图所示:

5.4 map的扩容
参考1:Golang Map 底层实现
参考2:Golang底层实现系列——map的底层实现
参考3:golang笔记——map底层原理
参考4:Golang源码探究 —— map
5.4.1 map为什么需要扩容
- 首先就是当可用空间不足时就需要扩容。
- 当哈希碰撞比较严重时,很多数据都会落在同一个桶中,那么就会导致越来越多的溢出桶被链接起来。这样的话,查找的时候最坏的情况就是要遍历整个链表,时间复杂度很高,效率很低。而且当删除了很多元素后,可能会导致虽然有很多溢出桶,但是桶中的元素很稀疏。
5.4.2 map扩容的时机
Golang源码探究 —— map
golang笔记——map底层原理
- 达到最大的负载因子(源码里定义的阈值是 6.5,也就是平均每个桶中k-v的数量大于6.5)(翻倍扩容)
- 溢出桶的数量太多。频繁的对map增删,会导致未被使用的
overflow的bucket数量过多:(等量扩容)
- 当B < 15,也就是
bucket总数 2^ B小于2^15时,如果overflow的bucket数量超过 2^B(未用于存储的bucket数量过多),就会触发扩容;【即bucket数目不大于2 ^ 15,但是使用overflow数目超过2^B就算是多了。】 - 当B >= 15,也就是
bucket总数2^ B大于等于2^15,如果overflow的bucket数量超过 2^ 15,就会触发扩容。【即bucket数目大于2^ 15,那么使用overflow数目一旦超过2^15就算是多了。】
- 针对 1:我们知道,每个bucket有8个空位,在没有溢出,且所有的桶都装满了的情况下,负载因子算出来的结果是8。因此当负载因子超过6.5时,表明很多bucket都快要装满了,查找效率和插入效率都变低了。在这个时候进行扩容是有必要的。
- 针对2:是对第1点的补充。就是说在负载因子比较小的情况下,这时候map的查找和插入效率也很低,而第1点识别不出来这种情况。表面现象就是计算负载子的分子比较小,即map里元素总数少,但是bucket数量多(真实分配的bucket数量多,包括大量的overflow bucket)。
不难想像造成2. 溢出桶的数量太多。这种情况的原因:不停地插入、删除元素。先插入很多元素,导致创建了很多bucket,但是负载因子达不到第 1 点的临界值,未触发扩容来缓解这种情况。之后,删除元素降低元素总数量,再插入很多元素,导致创建很多的overflow bucket,但就是不会触发第1点的规定,你能拿我怎么办?overflow bucket 数量太多,导致 key 会很分散,查找插入效率低得吓人,因此出台第2点规定。这就像是一座空城,房子很多,但是住户很少,都分散了,找起人来很困难。
在mapassign中会判断是否要扩容:Golang源码探究 —— map
//触发扩容的时机
func mapassign(t \*maptype, h \*hmap, key unsafe.Pointer) unsafe.Pointer {
...
// If we hit the max load factor or we have too many overflow buckets,
// and we're not already in the middle of growing, start growing.
// 如果达到了最大的负载因子或者有太多的溢出桶
// 或是是已经在扩容中
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
判断负载因子超过 6.5:golang笔记——map底层原理
func overLoadFactor(count int, B uint8) bool {
return count > bucketCnt && uintptr(count) > loadFactorNum\*(bucketShift(B)/loadFactorDen)
}
- 1
- 2
- 3
- 4
判断overflow buckets 太多:golang笔记——map底层原理
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
// If the threshold is too low, we do extraneous work.
// If the threshold is too high, maps that grow and shrink can hold on to lots of unused memory.
// "too many" means (approximately) as many overflow buckets as regular buckets.
// See incrnoverflow for more details.
if B > 15 {
B = 15
}
// The compiler doesn't see here that B < 16; mask B to generate shorter shift code.
return noverflow >= uint16(1)<<(B&15)
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
5.4.3 map扩容的类型:翻倍扩容、等量扩容
map的两个扩容的时机,都会发生扩容。但是扩容的策略并不相同,毕竟两种条件应对的场景不同。但map扩容采用的都是渐进式,桶被操作(增删改)时才会重新分配。
Golang Map 底层实现

翻倍扩容:针对的是 达到最大的负载因子 的情况,扩容后桶的数量为原来的两倍。Golang源码探究 —— map
对于达到最大的负载因子的扩容,它是因为元素太多,而bucket数量太少,解决办法很简单:将B加 1,bucket 最大数量(2^ B)直接变成原来bucket数量的2倍。于是,就有新老bucket了。
注意: 这时候元素都在老bucket里,还没迁移到新的bucket来。而且,新bucket只是最大数量变为原来最大数量(2^ B)的 2 倍(2^B * 2)。golang笔记——map底层原理
等量扩容:针对的是溢出桶的数量太多的情况,溢出桶太多了,导致查询效率低。扩容时,桶的数量不增加。Golang源码探究 —— map
对于溢出桶的数量太多的扩容,其实元素没那么多,但是overflow bucket数特别多,说明很多bucket都没装满。解决办法就是开辟一个新bucket空间,将老bucket中的元素移动到新bucket,使得同一个bucket 中的key排列地更紧密。这样,原来在overflow bucket中的key可以移动到bucket中来。节省空间,提高bucket利用率,map的查找和插入效率自然就会提升。golang笔记——map底层原理
5.4.4 map扩容的步骤
Golang源码探究 —— map
步骤一:
- 创建一组新桶。
- oldbuckets指向原有的桶数组。
- buckets指向新的桶的数组。
- map标记为扩容状态。
步骤二:迁移数据
- 将所有的数据从旧桶驱逐到新桶。
- 采用渐进式驱逐。
- 每次操作一个旧桶时(插入、删除数据),将旧桶数据驱逐到新桶。
- 读取时不进行驱逐,只判断读取新桶还是旧桶。
步骤三:所有旧桶驱逐完成后,回收所有旧桶(oldbuckets)。
5.4.5 map为什么采用渐进式扩容
golang笔记——map底层原理
由于map扩容需要将原有的key/value重新搬迁到新的内存地址,如果有大量的key/value需要搬迁,会非常影响性能。因此Go map的扩容采取了一种称为“渐进式”地方式,每次最多只会搬迁2个bucket。
5.4.6 翻倍扩容、等量扩容中Key的变化
翻倍扩容(达到最大的负载因子):【可能会变,也可能不会变】因为新的buckets数量是之前的一倍,所以在迁移时要重新计算 key的哈希,才能决定它到底落在哪个bucket。例如,原来 B = 5,计算出key的哈希后,只用看它的低 5 位,就能决定它落在哪个bucket。扩容后,B变成了 6,因此需要多看一位,它的低 6 位决定key落在哪个bucket。因此,某个key在搬迁前后bucket序号可能和原来相等,也可能是相比原来加上 2^B(原来的 B 值),取决于hash值 第6位bit位是 0 还是 1。golang笔记——map底层原理
等量扩容(溢出桶的数量太多):【可能会变,也可能不会变】从老的buckets搬迁到新的buckets,由于bucktes数量不变,因此可以按序号来搬,比如原来在0号bucktes,到新的地方后,仍然放在0号buckets。【如果迁移后是紧密的按顺序排列,则不变;如果不按顺序排列,会变】golang笔记——map底层原理
5.5 map为什么是无序的
5.5.1 map不扩容的时候for循环取值,为什么每次取到的都是无序
参考1:为什么说Go的Map是无序的?
首先是For ... Range ... 遍历Map的索引的起点是随机的。
其次,往map中存入时就不是按顺序存储的,所以是无序的。
翻倍扩容和等量扩容都可能会发生无序的情况,原因看 5.3.6 翻倍扩容、等量扩容中Key的变化。
map在扩容后,会发生key的搬迁,原来落在同一个bucket中的key,搬迁后,有些key就要远走高飞了(bucket序号加上了 2^B)。而遍历的过程,就是按顺序遍历bucket,同时按顺序遍历bucket中的key。搬迁后,key的位置发生了重大的变化,有些 key飞上高枝,有些key则原地不动。这样,遍历map的结果就不可能按原来的顺序了。
当我们在遍历go中的map时,并不是固定地从0号bucket开始遍历,每次都是从一个随机值序号的bucket开始遍历,并且是从这个 bucket的一个随机序号的cell开始遍历。这样,即使你是一个写死的map,仅仅只是遍历它,也不太可能会返回一个固定序列的 key/value对了。
5.6 float类型是否可以作为map的key
从语法上看,是可以的。Go 语言中只要是可比较的类型都可以作为 key。除开 slice,map,functions 这几种类型,其他类型都是 OK 的。具体包括:布尔值、数字、字符串、指针、通道、接口类型、结构体、只包含上述类型的数组。这些类型的共同特征是支持 == 和 != 操作符,k1 == k2 时,可认为 k1 和 k2 是同一个 key。如果是结构体,只有 hash 后的值相等以及字面值相等,才被认为是相同的 key。很多字面值相等的,hash出来的值不一定相等,比如引用。
float 型可以作为 key,但是由于精度的问题,会导致一些诡异的问题,慎用之。
5.7 map可以遍历的同时删除吗
map 并不是一个线程安全的数据结构。多个协程同时读写同时读写一个 map,如果被检测到,会直接 panic。
如果在同一个协程内边遍历边删除,并不会检测到同时读写,理论上是可以这样做的。但是,遍历的结果就可能不会是相同的了,有可能结果遍历结果集中包含了删除的 key,也有可能不包含,这取决于删除 key 的时间:是在遍历到 key 所在的 bucket 时刻前或者后。
如果想要并发安全的读写,可以通过读写锁来解决:sync.RWMutex。
读之前调用 RLock() 函数,读完之后调用 RUnlock() 函数解锁;写之前调用 Lock() 函数,写完之后,调用 Unlock() 解锁。
5.8 可以对map元素取地址吗
无法对 map 的 key 或 value 进行取址,将无法通过编译。
如果通过其他 hack 的方式,例如 unsafe.Pointer 等获取到了 key 或 value 的地址,也不能长期持有,因为一旦发生扩容,key 和 value 的位置就会改变,之前保存的地址也就失效了。
5.9 如何比较两个map是否相等
- 都为 nil。
- 非空、长度相等,指向同一个 map 实体对象。
- 相应的 key 指向的 value “深度”相等
直接将使用 map1 == map2 是错误的。这种写法只能比较 map 是否为 nil。
因此只能是遍历map 的每个元素,比较元素是否都是深度相等。
5.10 map是线程安全的吗
不安全,只读是线程安全的,主要是不支持并发写操作的,原因是 map 写操作不是并发安全的,当尝试多个 Goroutine 操作同一个 map,会产生报错:fatal error: concurrent map writes。所以map适用于读多写少的场景。
解决办法:要么加锁,要么使用sync包中提供了并发安全的map,也就是sync.Map,其内部实现上已经做了互斥处理。
5.11 map底层是hash,它是如何解决冲突的
golang的map用的是hashmap,是使用数组+链表的形式实现的,使用拉链法消除hash冲突。拉链法见:5.2.2 拉链法(map使用的方式)
5.12 map如何判断是否并发写的
参考1:https://www.jianshu.com/p/1132055d708b
map是检查是否有另外线程修改h.flag来判断,是否有并发问题。
// 在更新map的函数里检查并发写
if h.flags&hashWriting == 0 {
throw("concurrent map writes")
}
// 在读map的函数里检查是否有并发写
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
5.13 map并发读写会panic吗
参考1:http://c.biancheng.net/view/34.html
map 在并发情况下,只读是线程安全的,同时读写是线程不安全的。会报panic:fatal error: concurrent map read and map write,因为Go语言原生的map并不是并发安全的,对它进行并发读写操作的时候,需要加锁。
5.14 map遍历是否有序
参考1:golang对map排序
golang中map元素是随机无序的,所以在对map range遍历的时候也是随机的,如果想按顺序读取map中的值,可以结合切片来实现。
5.15 map怎么变得有序
如果想按顺序读取map中的值,可以结合切片来实现。
5.16 多个协程读写map的panic可以被捕获吗
参考1:https://www.cnblogs.com/wuchangblog/p/16393070.html
不能,每个协程只能捕获到自己的 panic 不能捕获其它协程。
6 sync.Map
sync.Map是并发安全的。底层通过分离读写map和原子指令来实现读的近似无锁,并通过延迟更新的方式来保证读的无锁化。
6.1 sync.Map的基本操作
sync.Map特性:
- 无须初始化,直接声明即可使用。
- sync.Map不能使用普通map的方法进行读写操作,而是使用sync.Map自己的方法进行操作,Store表示存储,Load表示读取,Delete表示删除。
- 使用Range配合一个回调函数进行遍历操作,通过回调函数返回内部遍历出来的值,Range参数中回调函数的返回值在需要继续遍历时,需要返回true,终止遍历时,返回false。
sync.Map的基本操作的完整代码:
package main import ( "fmt" "sync" ) func main() { //1、初始化 var sMap sync.Map //2、插入数据 sMap.Store(1,"a") sMap.Store("AA",10) sMap.Store("BB",20) sMap.Store(3,"CC") //3、访问数据 fmt.Println("Load方法") //Load:①如果待查找的key存在,则返回key对应的value,true; lv1,ok1 := sMap.Load(1) fmt.Println(ok1,lv1) //输出结果:true a //Load:②如果待查找的key不存在,则返回nil,false lv2,ok2 := sMap.Load(2) fmt.Println(ok2,lv2) //输出结果:false <nil> fmt.Println() fmt.Println("LoadOrStore方法") //LoadOrStore:①如果待查找的key存在,则返回key对应的value,true; losv1,ok1 := sMap.LoadOrStore(1,"aaa") fmt.Println(ok1,losv1) //输出结果:true a //LoadOrStore:②如果待查找的key不存在,则返回添加的value,false losv2,ok2 := sMap.LoadOrStore(2,"bbb") fmt.Println(ok2,losv2) //输出结果:false bbb fmt.Println() fmt.Println("LoadAndDelete方法") //LoadAndDelete:①如果待查找的key存在,则返回key对应的value,true,同时删除该key-value; ladv1,ok1 := sMap.LoadAndDelete(1) fmt.Println(ok1,ladv1) //输出结果:true a //LoadAndDelete:②如果待查找的key不存在,则返回nil,false ladv2,ok2 := sMap.LoadAndDelete(1) fmt.Println(ok2,ladv2) //输出结果:false <nil> //4、删除 fmt.Println() fmt.Println("Delete方法") sMap.Delete(2) fmt.Println() fmt.Println("Range方法") // 5、遍历所有sync.Map中的键值对 sMap.Range(func(k, v interface{}) bool { fmt.Println("k-v:", k, v) return true }) }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
6.1.1 sync.Map初始化
sync.Map无须初始化,直接声明即可使用。
var sMap sync.Map
- 1
- 2
6.1.2 sync.Map插入数据
sync.Map插入数据使用自带的Store(key,value)。源码解读 Golang 的 sync.Map 实现原理 有对Store的源码分析。
sMap.Store(1,"a")
sMap.Store("AA",10)
- 1
- 2
- 3
注意:Store(key, value interface{})参数都是interface{}类型,所以同一个sync.Map能存储不同类型的数据。源码:
func (m \*Map) Store(key, value interface{}) {
}
- 1
- 2
- 3
6.1.3 访问sync.Map中的数据
sync.Map访问有三个方法:Load()、LoadOrStore()、LoadAndDelete()
Load(key interface{}) (value interface{}, ok bool)源码解读 Golang 的 sync.Map 实现原理 有对Load的源码分析。
- 如果待查找的key存在,则返回key对应的value,true;
lv1,ok1 := sMap.Load(1)
fmt.Println(ok1,lv1) //输出结果:true a
- 1
- 2
- 3
- 如果待查找的key不存在,则返回nil,false;
lv2,ok2 := sMap.Load(2)
fmt.Println(ok2,lv2) //输出结果:false <nil>
- 1
- 2
- 3
LoadOrStore(key, value interface{}) (actual interface{}, loaded bool)
- 如果待查找的key存在,则返回key对应的value,true,不会修改原来key对应的value;
losv1,ok1 := sMap.LoadOrStore(1,"aaa")
fmt.Println(ok1,losv1) //输出结果:true a
- 1
- 2
- 3
- 如果待查找的key不存在,则返回添加的value,false;
losv2,ok2 := sMap.LoadOrStore(2,"bbb")
fmt.Println(ok2,losv2) //输出结果:false bbb
- 1
- 2
- 3
LoadAndDelete(key interface{}) (value interface{}, loaded bool)
- 如果待查找的key存在,则返回key对应的value,true,同时删除该key-value;
ladv1,ok1 := sMap.LoadAndDelete(1)
fmt.Println(ok1,ladv1) //输出结果:true a
- 1
- 2
- 3
- 如果待查找的key不存在,则返回nil,false;
ladv2,ok2 := sMap.LoadAndDelete(1)
fmt.Println(ok2,ladv2) //输出结果:false <nil>
- 1
- 2
- 3
6.1.4 删除sync.Map中的数据
sync.Map删除用 Delete(key interface{}),查看源码会发现它是调用的LoadAndDelete(key)最终来实现的。源码解读 Golang 的sync.Map实现原理 有对Delete的源码分析。
源码:
func (m \*Map) Delete(key interface{}) {
m.LoadAndDelete(key)
}
- 1
- 2
- 3
- 4
6.1.5 清空sync.Map中的数据
同map一样,Go语言也没有为sync.Map提供任何清空所有元素的函数、方法,清空sync.Map的唯一办法就是重新声明一个新的sync.Map。
6.1.6 遍历sync.Map
sync.Map使用Range配合一个回调函数进行遍历操作,通过回调函数返回内部遍历出来的值,Range参数中回调函数的返回值在需要继续迭代遍历时,返回 true,终止迭代遍历时,返回 false。
sMap.Range(func(k, v interface{}) bool {
fmt.Println("k-v:", k, v)
return true
})
- 1
- 2
- 3
- 4
- 5
6.2 sync.Map的数据结构
6.2.1 sync.Map底层是如何保证线程安全(实现原理)
sync.Map 的实现原理可概括为:
- 通过read和dirty两个字段将读写分离,读取的数据在只读字段read上,写入的数据则存在dirty字段上。
- 读取时会先查询read,read中不存在时,再查询dirty,写入时则只写入dirty。
- 读取read并不需要加锁,因为read只负责读,而读或写dirty都需要加锁。
- 另外有misses字段来统计read被穿透的次数(被穿透指当从Map中读取entry的时候,如果read中不包含这个entry,需要读dirty的情况),超过一定次数则将dirty晋升为read 。(
保证读写一致) - 延迟删除,删除一个key值时只是打标记,只有在将dirty晋升为read后的时候才清理数据。对于删除数据则直接通过标记来延迟删除。
6.2.2 sync.Map的数据结构
参考1:源码解读 Golang 的 sync.Map 实现原理
参考2:Golang的Map并发性能以及原理分析
sync.Map是在sync/map.go:
type Map struct {
mu Mutex
read atomic.Pointer[readOnly]
dirty map[any]\*entry
misses int
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
sync.Map各字段解读:
mu:互斥锁,保护dirty字段,当涉及到dirty数据的操作的时候,需要使用这个锁。read:只读的数据,实际数据类型为readOnly,也是一个map,因为只读,所以不会有读写冲突。实际上,实际也会更新read的entries,如果entry是未删除的(unexpunged),并不需要加锁。如果entry已经被删除了,需要加锁,以便更新dirty数据。dirty:dirty中的数据除了包含当前的entries,它也包含最新的entries(包括read中未删除的数据,虽有冗余,但是提升dirty字段为read的时候非常快,不用一个一个的复制,而是直接将这个数据结构作为read字段的一部分),有些数据还可能没有移动到read字段中(即直接将dirty晋升为read)。
- 对于dirty的操作需要加锁,因为对它的操作可能会有读写竞争。
- 当dirty为空的时候,比如初始化或者刚提升完,下一次的写操作会复制read字段中未删除的数据到这个数据中。
misses:当从Map中读取entry的时候,如果read中不包含这个entry,会尝试从dirty中读取,这个时候会将misses加一,当misses累积到dirty的长度的时候, 就会将dirty晋升为read,避免从dirty中miss太多次。因为操作dirty需要加锁。【保证读写一致】
readOnly结构体:
type readOnly struct {
m map[interface{}]\*entry
amended bool
}
- 1
- 2
- 3
- 4
- 5
readOnly各字段解读:
m:内建map,m的value的类型为*entry。
amended:用于判断dirty里是否存在read里没有的key,通过该字段决定是否加锁读dirty,如果有则为true。
readOnly.m和Map.dirty存储的值类型是*entry,它包含一个指针p,指向用户存储的value值。
entry 数据结构则用于存储sync.Map中值的指针:
type entry struct {
p unsafe.Pointer // 等同于 \*interface{}
}
- 1
- 2
- 3
- 4
当p指针指向expunged这个指针的时候,则表明该元素被删除,但不会立即从map中删除,如果在未删除之前又重新赋值则会重新使用该元素。
entry各字段解读:
p:指向用户存储的value值,p有三种状态。
- nil: 键值已经被删除,且m.dirty == nil。
- expunged: 键值已经被删除,但是m.dirty!=nil且m.dirty不存在该键值(expunged 实际是空接口指针)。
- 除以上情况,则键值对存在,存在于m.read中,如果m.dirty!=nil则也存在于m.dirty。
6.2.3 read map与dirty map的关系
参考1:Golang的Map并发性能以及原理分析

从图中可以看出,read map和dirty map中含有相同的一部分entry,我们称作是normal entries,是双方共享的。状态是p的值为nil和unexpunged时。
但是read map中含有一部分entry是不属于dirty map的,而这部分entry就是状态为expunged状态的entry。而dirty map中有一部分entry 也是不属于read map的,而这部分其实是来自Store操作形成的(也就是新增的 entry),换句话说就是新增的entry是出现在dirty map中的。
读取数据时首先从m.read中读取,不存在的情况下,并且m.dirty中有新数据,对m.dirty加锁,然后从m.dirty中读取。
6.2.4 read map、dirty map的作用
read map:是用来进行lock free操作的(其实可以读写,但是不能做删除操作,因为一旦做了删除操作,就不是线程安全的了,也就无法 lock free)。
dirty map:是用来在无法进行lock free操作的情况下,需要lock来做一些更新工作的对象。
6.3 sync.Map的缺陷
当需要不停地新增和删除的时候,会导致dirty map不停地更新,甚至在misses过多之后,导致dirty成为nil,并进入重建的过程,所以sync.Map适用于读多写少的场景。
6.4 sync.Map与map的区别
是否支持多协程并发安全。
6.5 sync.Map的使用场景
参考1:sync.Map详解
sync.Map 适用于读多写少的场景。对于写多的场景,会导致不断地从dirty map中读取,导致dirty map晋升为read map,这是一个 O(N) 的操作,会进一步降低性能。
7 interface接口
7.1 interface的数据结构
接口的底层实现结构有两个结构体iface和eface,区别在于iface类型的接口包含方法,而eface则是不包含任何方法的空接口:interface{}。这两个结构体都在runtime/runtime2.go中。(Golang之接口底层分析)
7.1.1 接口之iface
iface结构体,是在runtime/runtime2.go中,它的所有字段如下:
type iface struct {
tab \*itab
data unsafe.Pointer
}
- 1
- 2
- 3
- 4
- 5
iface 各字段解读:
tab:指针类型,指向一个itab实体,它表示接口的类型以及赋给这个接口的实体类型。data:则指向接口具体的值,一般而言是一个指向堆内存的指针。
itab结构体,是在runtime/runtime2.go中,它的所有字段如下:
type itab struct {
inter \*interfacetype
_type \*_type
hash uint32 // copy of \_type.hash. Used for type switches.
\_ [4]byte
fun [1]uintptr // variable sized. fun[0]==0 means \_type does not implement inter.
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
itab各字段解读:
inter:接口自身定义的类型信息,用于定位到具体interface类型。_type:接口实际指向值的类型信息,即实际对象类型,用于定义具体interface类型;hash:_type.hash的拷贝,是类型的哈希值,用于快速查询和判断目标类型和接口中类型是否一致。fun:动态数组,接口方法实现列表(方法集),即函数地址列表,按字典序排序,如果数组中的内容为空表示_type没有实现inter接口。
itab.inter是interface的类型元数据,它里面记录了这个接口类型的描述信息,接口要求的方法列表就记录在interfacetype.mhdr里。
interfacetype结构体,是在runtime/type.go中,它的所有字段如下:
type interfacetype struct {
typ _type
pkgpath name
mhdr []imethod
}
- 1
- 2
- 3
- 4
- 5
- 6
interfacetype各字段解读:
typ:接口的信息。pkgpath:接口的包路径。mhdr:接口要求的方法列表。
iface结构体详解:
tab._type就是接口的动态类型,也就是被赋给接口类型的那个变量的类型元数据。itab中的_type和iface中的data能简要描述一个变量。_type是这个变量对应的类型,data是这个变量的值。
itab.fun记录的是动态类型实现的那些接口要求的方法的地址,是从方法元数据中拷贝来的,为的是快速定位到方法。如果itab._type对应的类型没有实现这个接口,则itab.fun[0]=0,这在类型断言时会用到。
当fun[0]为0时,说明_type并没有实现该接口,当有实现接口时,fun存放了第一个接口方法的地址,其他方法依次往下存放,这里就简单用空间换时间,其实方法都在_type字段中能找到,实际在这记录下,每次调用的时候就不用动态查找了。
7.1.2 接口之eface
eface 结构体,是在runtime/runtime2.go中,它的所有字段如下:
type eface struct {
_type \*_type
data unsafe.Pointer
}
- 1
- 2
- 3
- 4
- 5
eface 各字段解读:
_type:类型信息。data:数据信息,指向数据指针。
_type结构体,是在runtime/type.go中,它的所有字段如下:
type _type struct { size uintptr ptrdata uintptr // size of memory prefix holding all pointers hash uint32 tflag tflag align uint8 fieldAlign uint8 kind uint8 // function for comparing objects of this type // (ptr to object A, ptr to object B) -> ==? equal func(unsafe.Pointer, unsafe.Pointer) bool // gcdata stores the GC type data for the garbage collector. // If the KindGCProg bit is set in kind, gcdata is a GC program. // Otherwise it is a ptrmask bitmap. See mbitmap.go for details. gcdata \*byte str nameOff ptrToThis typeOff }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
_type 各字段解读:
size:类型占用内存大小。ptrdata:包含所有指针的内存前缀大小。hash:类型hash。tflag:标记位,主要用于反射。align:对齐字节信息。fieldAlign:当前结构字段的对齐字节数。kind:基础类型枚举值。equal:比较两个形参对应对象的类型是否相等。gcdata:GC类型的数据。str:类型名称字符串在二进制文件段中的偏移量。ptrToThis:类型元信息指针在二进制文件段中的偏移量。
重点说明:
- kind:这个字段描述的是如何解析基础类型。在Go语言中,基础类型是一个枚举常量,有26个基础类型,如下。枚举值通过
kindMask取出特殊标记位。
const ( kindBool = 1 + iota kindInt kindInt8 kindInt16 kindInt32 kindInt64 kindUint kindUint8 kindUint16 kindUint32 kindUint64 kindUintptr kindFloat32 kindFloat64 kindComplex64 kindComplex128 kindArray kindChan kindFunc kindInterface kindMap kindPtr kindSlice kindString kindStruct kindUnsafePointer kindDirectIface = 1 << 5 kindGCProg = 1 << 6 kindMask = (1 << 5) - 1 )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
str和ptrToThis,对应的类型是nameoff和typeOff。分表表示name和type针对最终输出文件所在段内的偏移量。在编译的链接步骤中,链接器将各个.o文件中的段合并到输出文件,会进行段合并,有的放入.text段,有的放入.data段,有的放入.bss段。nameoff和typeoff就是记录了对应段的偏移量。
7.2 接口的nil判断(interface可以和nil比较吗)
参考1:Go语言接口的nil判断
答:可以比较,因为nil在Go语言中只能被赋值给指针和接口。接口在底层的实现主要考虑eface结构体,它有两个部分:type和data。
两种情况:
- 显式地将
nil赋值给接口时,接口的type和data都将为nil。此时,接口与nil值判断是相等的。 - 将一个带有类型的
nil赋值给接口时,只有data为nil,而type不为nil,此时,接口与nil判断将不相等。
7.3 两个interface可以比较吗
参考1:golang中接口值(interface)的比较
这个问题,接口在底层的实现主要考虑eface 结构体,它有两个部分:type和data。interface可以使用==或!=比较。
2个interface 相等有以下 2 种情况:
- 两个interface均等于nil(此时V和T都处于unset状态)
- 类型T相同,且对应的值V相等。
8 Golang中的Context
8.1 Context 简介
参考1:golang的context
在Golang的http包的Server中,每一个请求都有一个对应的goroutine负责处理,请求处理函数通常会启动额外的goroutine去处理,当一个请求被取消或者超时,所有用来处理该请求的goroutine都应该及时退出,这样系统才能释放这些goroutine占用的资源,就不会有大量的goroutine去占用资源。
注意:go1.6及之前版本请使用golang.org/x/net/context。go1.7及之后已移到标准库context。
8.2 Context 原理
参考1:golang 系列:context 详解
参考2:快速掌握 Golang context 包,简单示例
- 从
Context的功能可以看出来,它是用来传递信息的。这种传递并不仅仅是将数据塞给被调用者,它还能进行链式传递,通过保存父子Context关系,不断的迭代遍历来获取数据。 - 因为
Context可以链式传递,这就使得goroutine之间能够进行链式的信号通知了,从而进而达到自上而下的通知效果。例如通知所有跟当前context有关系的goroutine进行取消处理。 - 因为
Context的调用是链式的,所以通过WithCancel,WithDeadline,WithTimeout或WithValue派生出新的Context。当父Context被取消时,其派生的所有Context都将取消。 - 通过
context.WithXXX都将返回新的Context和CancelFunc。调用CancelFunc将取消子代,移除父代对子代的引用,并且停止所有定时器。未能调用CancelFunc将泄漏子代,直到父代被取消或定时器触发。go vet工具检查所有流程控制路径上使用CancelFuncs。
8.3 使用场景
参考1:https://www.qycn.com/xzx/article/9390.html 本文中的四种使用场景的分析和相关代码同参考1完全相同。
- RPC调用
- PipeLine:pipeline模式就是流水线模型。
- 超时请求
- HTTP服务器的request互相传递数据
1. RPC调用
在主goroutine上有4个RPC,RPC2/3/4是并行请求的,我们这里希望在RPC2请求失败之后,直接返回错误,并且让RPC3/4停止继续计算。这个时候,就使用的到Context。
代码:
package main import ( "context" "sync" "github.com/pkg/errors" ) func Rpc(ctx context.Context, url string) error { result := make(chan int) err := make(chan error) go func() { // 进行RPC调用,并且返回是否成功,成功通过result传递成功信息,错误通过error传递错误信息 isSuccess := true if isSuccess { result <- 1 } else { err <- errors.New("some error happen") } }() select { case <- ctx.Done(): // 其他RPC调用调用失败 return ctx.Err() case e := <- err: // 本RPC调用失败,返回错误信息 return e case <- result: // 本RPC调用成功,不返回错误信息 return nil } } func main() { ctx, cancel := context.WithCancel(context.Background()) // RPC1调用 err := Rpc(ctx, "http://rpc\_1\_url") if err != nil { return } wg := sync.WaitGroup{} // RPC2调用 wg.Add(1) go func(){ defer wg.Done() err := Rpc(ctx, "http://rpc\_2\_url") if err != nil { cancel() } }() // RPC3调用 wg.Add(1) go func(){ defer wg.Done() err := Rpc(ctx, "http://rpc\_3\_url") if err != nil { cancel() } }() // RPC4调用 wg.Add(1) go func(){ defer wg.Done() err := Rpc(ctx, "http://rpc\_4\_url") if err != nil { cancel() } }() wg.Wait() }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
这里使用了waitGroup来保证main函数在所有RPC调用完成之后才退出。
在Rpc函数中,第一个参数是一个CancelContext,这个Context形象的说,就是一个传话筒,在创建CancelContext的时候,返回了一个听声器(ctx)和话筒(cancel函数)。所有的goroutine都拿着这个听声器(ctx),当主goroutine想要告诉所有goroutine要结束的时候,通过cancel函数把结束的信息告诉给所有的goroutine。当然所有的goroutine都需要内置处理这个听声器结束信号的逻辑(ctx->Done())。我们可以看Rpc函数内部,通过一个select来判断ctx的done和当前的rpc调用哪个先结束。
这个WaitGroup和其中一个RPC调用就通知所有RPC的逻辑,其实有一个包已经帮我们做好了。errorGroup。具体这个errorGroup包的使用可以看这个包的test例子。
有人可能会担心我们这里的cancel()会被多次调用,context包的cancel调用是幂等的。可以放心多次调用。
我们这里不妨品一下,这里的Rpc函数,实际上我们的这个例子里面是一个“阻塞式”的请求,这个请求如果是使用http.Get或者http.Post来实现,实际上Rpc函数的Goroutine结束了,内部的那个实际的http.Get却没有结束。所以,需要理解下,这里的函数最好是“非阻塞”的,比如是http.Do,然后可以通过某种方式进行中断。
比如像这篇文章Cancel http.Request using Context中的这个例子:
func httpRequest( ctx context.Context, client \*http.Client, req \*http.Request, respChan chan []byte, errChan chan error ) { req = req.WithContext(ctx) tr := &http.Transport{} client.Transport = tr go func() { resp, err := client.Do(req) if err != nil { errChan <- err } if resp != nil { defer resp.Body.Close() respData, err := ioutil.ReadAll(resp.Body) if err != nil { errChan <- err } respChan <- respData } else { errChan <- errors.New("HTTP request failed") } }() for { select { case <-ctx.Done(): tr.CancelRequest(req) errChan <- errors.New("HTTP request cancelled") return case <-errChan: tr.CancelRequest(req) return } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
它使用了http.Client.Do,然后接收到ctx.Done的时候,通过调用transport.CancelRequest来进行结束。
我们还可以参考net/dail/DialContext。
换而言之,如果希望实现的包是“可中止/可控制”的,那么在包实现的函数里面,最好是能接收一个Context函数,并且处理了Context.Done。
2. PipeLine
pipeline模式就是流水线模型,流水线上的几个工人,有n个产品,一个一个产品进行组装。其实pipeline模型的实现和Context并无关系,没有context我们也能用chan实现pipeline模型。但是对于整条流水线的控制,则是需要使用上Context的。这篇文章Pipeline Patterns in Go的例子是非常好的说明。这里就大致对这个代码进行下说明。
runSimplePipeline的流水线工人有三个,lineListSource负责将参数一个个分割进行传输,lineParser负责将字符串处理成int64,sink根据具体的值判断这个数据是否可用。他们所有的返回值基本上都有两个chan,一个用于传递数据,一个用于传递错误。(<-chan string, <-chan error)输入基本上也都有两个值,一个是Context,用于传声控制的,一个是(in <-chan)输入产品的。
我们可以看到,这三个工人的具体函数里面,都使用switch处理了case <-ctx.Done()。这个就是生产线上的命令控制。
func lineParser(ctx context.Context, base int, in <-chan string) ( <-chan int64, <-chan error, error) { ... go func() { defer close(out) defer close(errc) for line := range in { n, err := strconv.ParseInt(line, base, 64) if err != nil { errc <- err return } select { case out <- n: case <-ctx.Done(): return } } }() return out, errc, nil }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
3. 超时请求
我们发送RPC请求的时候,往往希望对这个请求进行一个超时的限制。当一个RPC请求超过10s的请求,自动断开。当然我们使用CancelContext,也能实现这个功能(开启一个新的goroutine,这个goroutine拿着cancel函数,当时间到了,就调用cancel函数)。
鉴于这个需求是非常常见的,context包也实现了这个需求:timerCtx。具体实例化的方法是 WithDeadline 和 WithTimeout。
具体的timerCtx里面的逻辑也就是通过time.AfterFunc来调用ctx.cancel的。
官方的例子:
package main import ( "context" "fmt" "time" ) func main() { ctx, cancel := context.WithTimeout(context.Background(), 50\*time.Millisecond) defer cancel() select { case <-time.After(1 \* time.Second): fmt.Println("overslept") case <-ctx.Done(): fmt.Println(ctx.Err()) // prints "context deadline exceeded" } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
在http的客户端里面加上timeout也是一个常见的办法。
uri := "https://httpbin.org/delay/3"
req, err := http.NewRequest("GET", uri, nil)
if err != nil {
log.Fatalf("http.NewRequest() failed with '%s'\n", err)
}
ctx, \_ := context.WithTimeout(context.Background(), time.Millisecond\*100)
req = req.WithContext(ctx)
resp, err := http.DefaultClient.Do(req)
if err != nil {
log.Fatalf("http.DefaultClient.Do() failed with:\n'%s'\n", err)
}
defer resp.Body.Close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
在http服务端设置一个timeout如何做呢?
package main import ( "net/http" "time" ) func test(w http.ResponseWriter, r \*http.Request) { time.Sleep(20 \* time.Second) w.Write([]byte("test")) } func main() { http.HandleFunc("/", test) timeoutHandler := http.TimeoutHandler(http.DefaultServeMux, 5 \* time.Second, "timeout") http.ListenAndServe(":8080", timeoutHandler) }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
我们看看TimeoutHandler的内部,本质上也是通过context.WithTimeout来做处理。
func (h \*timeoutHandler) ServeHTTP(w ResponseWriter, r \*Request) { ... ctx, cancelCtx = context.WithTimeout(r.Context(), h.dt) defer cancelCtx() ... go func() { ... h.handler.ServeHTTP(tw, r) }() select { ... case <-ctx.Done(): ... } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- HTTP服务器的request互相传递数据
context还提供了valueCtx的数据结构。这个valueCtx最经常使用的场景就是在一个http服务器中,在request中传递一个特定值,比如有一个中间件,做cookie验证,然后把验证后的用户名存放在request中。
我们可以看到,官方的request里面是包含了Context的,并且提供了WithContext的方法进行context的替换。
package main import ( "net/http" "context" ) type FooKey string var UserName = FooKey("user-name") var UserId = FooKey("user-id") func foo(next http.HandlerFunc) http.HandlerFunc { return func(w http.ResponseWriter, r \*http.Request) { ctx := context.WithValue(r.Context(), UserId, "1") ctx2 := context.WithValue(ctx, UserName, "yejianfeng") next(w, r.WithContext(ctx2)) } } func GetUserName(context context.Context) string { if ret, ok := context.Value(UserName).(string); ok { return ret } return "" } func GetUserId(context context.Context) string { if ret, ok := context.Value(UserId).(string); ok { return ret } return "" } func test(w http.ResponseWriter, r \*http.Request) { w.Write([]byte("welcome: ")) w.Write([]byte(GetUserId(r.Context()))) w.Write([]byte(" ")) w.Write([]byte(GetUserName(r.Context()))) } func main() { http.Handle("/", foo(test)) http.ListenAndServe(":8080", nil) }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
在使用ValueCtx的时候需要注意一点,这里的key不应该设置成为普通的String或者Int类型,为了防止不同的中间件对这个key的覆盖。最好的情况是每个中间件使用一个自定义的key类型,比如这里的FooKey,而且获取Value的逻辑尽量也抽取出来作为一个函数,放在这个middleware的同包中。这样,就会有效避免不同包设置相同的key的冲突问题了。
8.4 Context使用规则
参考1:快速掌握 Golang context 包,简单示例
- 不要将
Context放入结构体,相反context应该作为第一个参数传入,命名为ctx。func DoSomething(ctx context.Context,arg Arg)error { // ... use ctx ... }。 - 即使函数允许,也不要传入
nil的Context。如果不知道用哪种Context,可以使用context.TODO()。 - 使用
context的Value相关方法只应该用于在程序和接口中传递的和请求相关的元数据,不要用它来传递一些可选的参数。 - 相同的
Context可以传递给在不同的goroutine;Context是并发安全的。 context的Done()方法往往需要配合select { case }使用,以监听退出。- 一旦
context执行取消动作,所有派生的context都会触发取消。
8.5 Context的数据结构
参考1:快速掌握 Golang context 包,简单示例
参考2:golang 系列:context 详解
参考3:golang的context
Context是一个接口,是在context/context.go中,它的所有抽象方法如下:
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{}
Err() error
Value(key interface{}) interface{}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
Context接口中抽象方法解读:
Deadline():返回截止时间和ok。
- 如果有截止时间的话,到了这个时间点,Context会自动触发Cancel动作,返回对应
deadline时间,同时ok为true是表示设置了截止时间; - 如果没有设置截止时间,则ok的值为false是表示没有设置截止时间,就要手动调用cancel函数取消Context。
Done():返回一个只读channel(只有在被cancel后才会返回),它的数据类型是struct{},一个空结构体。当times out或者父级Context调用cancel方法后,将会close channel来进行通知,但是不会涉及具体数据传输,根据这个信号,开发者就可以做一些清理动作,比如退出goroutine。多次调用Done方法会返回的是同一个Channel。
Err():返回一个错误。如果上面的Done()的channel没被close,则error为nil;如果channel已被close,则error将会返回close的原因,说明该context为什么被关掉,比如超时或手动取消。
Value():返回被绑定到Context的值,是一个键值对,所以要通过一个Key才可以获取对应的值,这个值一般是线程安全的。对于同一个上下文来说,多次调用Value并传入相同的Key会返回相同的结果,该方法仅用于传递跨API和进程间请求域的数据。
8.6 Context的具体实现类型
参考1:golang中的context
参考2:golang的context
参考3:golang 系列:context 详解
Background()&TODO()
Background():是所有派生Context的根Context,该Context通常由接收request的第一个goroutine创建。它不能被取消、没有值、也没有过期时间,常作为处理request的顶层context存在。
TODO():也是返回一个没有值的Context,目前不知道它具体的使用场景,如果我们不知道该传什么类型的Context的时候,可以使用这个。
Background()和TODO()本质上是emptyCtx结构体类型,是一个不可取消,没有设置截止时间,没有携带任何值的空Context,是直接return默认值,没有具体功能代码。一般的将它们作为Context的根,往下派生。
2. WithCancel(parent Context) (ctx Context, cancel CancelFunc):用来取消通知用的context。
返回一个继承的Context和CancelFunc取消方法,在父协程context的Done函数被关闭时会关闭自己的Done通道,或者在执行了CancelFunc取消方法之后,会关闭自己的Done通道。这种关闭的通道可以作为一种广播的通知操作,告诉所有context相关的函数停止当前的工作直接返回。通常使用场景用于主协程用于控制子协程的退出,用于一对多处理。
3. WithDeadline(parent Context, d time.Time) (Context, CancelFunc):timerCtx类型的context,用来超时通知。
参数是传递一个上下文,等待超时时间,超时后,会返回超时时间,并且会关闭context的Done通道,其他传递的context收到Done关闭的消息的,直接返回即可。同样用户通知消息出来。
以下三种情况会取消该创建的context:
1、到达指定时间点;
2、调用了CancelFunc取消方法;
3、父节点context关闭。
4. WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc):timerCtx类型的context,用来超时通知。
WithTimeout()里是直接调用并返回的WithDeadline(),所以它和WithDeadline()功能是一样,只是传递的时间是从当前时间加上超时时间。
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc) {
return WithDeadline(parent, time.Now().Add(timeout))
}
- 1
- 2
- 3
- 4
WithValue(parent Context, key, val interface{}) Context:valueCtx类型的context,用来传值的context。
传递上下文的信息,将需要传递的信息从一个协程传递到另外协程。
每个context都可以放一个key-value对, 通过WithValue方法可以找key对应的value值,如果没有找到,就从父context中找,直到找到为止。
WithCancel、WithDeadline、 WithTimeout、WithValue四个方法在创建的时候都会要求传父级context进来,以此达到链式传递信息的目的。
8.7 context并发安全吗
参考1:https://blog.csdn.net/weixin_38664232/article/details/123663759
context本身是线程安全的,所以context携带value也是线程安全的。
context包提供两种创建根context的方式:
- context.Backgroud()
- context.TODO()
又提供了四个函数(WithCancel、WithDeadline、WithTimeout、WithValue)基于父Context牌生,其中使用WithValue函数派生的context来携带数据,每次调用WithValue函数都会基于当前context派生一个新的子context,WithValue内部主要就是调用valueCtx类:
func WithValue(parent Context, key, val interface{}) Context {
if parent == nil {
panic("cannot create context from nil parent")
}
if key == nil {
panic("nil key")
}
if !reflectlite.TypeOf(key).Comparable() {
panic("key is not comparable")
}
return &valueCtx{parent, key, val}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
说明:参数中的parent是当前valueContext的父节点。
valueCtx结构如下:
type valueCtx struct {
Context
key, val interface{}
}
- 1
- 2
- 3
- 4
- 5
valueContext继承父Context,这种是采用匿名接口的继承实现方式,key、val用来存储携带的键值对。
通过上面的代码分析,可以发现:
- 添加键值对不是在原来的
父Context结构体上直接添加,而是以此context作为父节点,重新创建一个新的valueContext子节点,将键值对添加到子节点上,由此形成一条context链。 - 获取键值对的过程也是层层向上调用,直到首次设置key的父节点,如果没有找到首次设置key的父节点,会向上遍历直到根节点,如果根节点找到了key就会返回,否则就会找到最终的
根Context(emptyCtx)返回nil。如下图所示:

总结: context添加的键值对是一个链式的,会不断衍生新的context,所以context本身是不可变的,因此是线程安全的。
8.8 context为什么可以实现并发安全?
context包是Go语言中用于在协程之间传递取消信号、截止时间和共享数据的一种机制。context的并发安全性体现在以下几个方面:
- 不可变性(Immutability):
context的设计中鼓励不可变性,也就是说,一旦创建了context,它的值就不会被改变。这确保了在协程之间传递context时的线程安全性,因为不会有并发修改的情况。 - 值的复制:当一个协程创建一个新的
context时,它可以基于已有的context创建一个新的实例,并向其中添加或修改一些值。这个过程中,原始的context实例不会受到影响,保证了并发安全。 - 不可变的部分:一些
context的方法返回一个新的context,而不是修改原始的context。例如,WithValue方法就是返回一个带有新值的新context实例,而不是在原始的context上修改。这样的设计符合不可变性原则,从而确保并发安全。 - 取消信号的传递:通过
context的取消机制,一个协程可以通知其他协程停止工作。这是通过context的Done通道来实现的。当一个协程调用cancel函数时,Done通道会被关闭,所有基于该context的协程都能感知到取消信号。
总体来说,context的设计强调了不可变性和值的复制,这使得它在并发环境下能够提供一种安全而有效的机制,用于在协程之间传递相关信息,控制取消,以及传递截止时间等。在并发编程中,使用context能够更容易地管理和传递与协程相关的信息,同时避免了共享状态带来的并发安全性问题。
9 select语句
9.1 介绍、使用规则
参考1:go中select语句
select语句是用来监听和channel有关的IO操作的,当IO操作发生时,触发对应的case动作。有了select语句,可以实现main主线程与goroutine线程之间的互动。
//for {
select {
case <-ch1 : // 检测有没有数据可读
// 一旦成功读取到数据,则进行该case处理语句
case ch2 <- 1 : // 检测有没有数据可写
// 一旦成功向ch2写入数据,则进行该case处理语句
default:
// 如果以上都没有符合条件,那么进入default处理流程
}
}//
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
select语句外面可使用for循环来实现不断监听IO的目的。
注意事项:
select语句只能用于channel的IO操作,每个case都必须是一个channel。- 如果不设置
default条件,在没有IO操作发生时,select语句就会一直阻塞; 如果有一个或多个IO操作同时发生时,Go运行时会随机选择一个case执行,但此时将无法保证执行顺序;对于case语句,如果存在channel值为nil的读写操作,则该分支将被忽略,可以理解为相当于从select语句中删除了这个case;- 对于既不设置
default条件,又一直没有IO操作发生的情况,select语句会引起死锁(fatal error: all goroutines are asleep - deadlock!),如果不希望出现死锁,可以设置一个超时时间的case来解决; - 对于在
for中的select语句,不能添加default,否则会引起CPU占用过高的问题;
9.2 如何给select的case设定优先级
参考1:go语言中select实现优先级
在 9.1 注意事项3中已知无法保证执行顺序的情况。
问题描述:我们有一个函数会持续不间断地从ch1和ch2中分别接收任务1和任务2,如何确保当ch1和ch2同时达到就绪状态时,优先执行任务1,在没有任务1的时候再去执行任务2呢?
实现代码:
func worker2(ch1, ch2 <-chan int, stopCh chan struct{}) { for { select { case <-stopCh: return case job1 := <-ch1: fmt.Println(job1) case job2 := <-ch2: priority: for { select { case job1 := <-ch1: fmt.Println(job1) default: break priority } } fmt.Println(job2) } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
使用了嵌套的select,还组合使用了for循环和label来解决问题。上面的代码在外层select选中执行job2 := <-ch2时,进入到内层select循环继续尝试执行job1 := <-ch1,当ch1就绪时就会一直执行,否则跳出内层select,继续执行job2。
这是两个任务的情况,在任务数可数的情况下可以层层嵌套来实现对多个任务排序,对于有规律的任务可以使用递归的。
9.3 如何判断select的某个通道是关闭的
参考1:https://blog.csdn.net/eddycjy/article/details/122053524
注意:关闭的channel不是nil,所以在select语句中依然可以监听并执行对应的case,只不过在读取关闭后的channel时,读取到的数据是零值,ok是false。要想知道某个通道是否关闭,判断ok是否为false即可。
要想判断某个通道是否关闭,当返回的ok为false时,执行c = nil 将通道置为nil,相当于读一个未初始化的通道,则会一直阻塞。至于为什么读一个未初始化的通道会出现阻塞,可以看我的另一篇 对未初始化的的chan进行读写,会怎么样?为什么? 。select中如果任意某个通道有值可读时,它就会被执行,其他被忽略。则select会跳过这个阻塞case,可以解决不断读已关闭通道的问题。
9.4 如何屏蔽已关闭的channel
参考1:https://blog.csdn.net/eddycjy/article/details/122053524
要想屏蔽某个已经关闭的通道,判断通道的ok是false后,将channel置为nil,select再监听该通道时,相当于监听一个未初始化的通道,则会一直阻塞,select会跳过这个阻塞,从而达到屏蔽的目的。
9.5 select里只有一个已经关闭的channel会怎么样
参考1:https://blog.csdn.net/eddycjy/article/details/122053524
只有一个case的情况下,则会死循环。
关闭的channel不是nil,所以在select语句中依然可以监听并执行对应的case,只不过在读取关闭后的channel时,读取到的数据是零值,ok是false。
9.6 select里只有一个已经关闭的channel,且置为nil,会怎么样
参考1:https://blog.csdn.net/eddycjy/article/details/122053524
答:因为只有一个已经关闭的channel,且已经置为了nil,这时select会先阻塞,最后发生死锁(fatal error: all goroutines are asleep - deadlock!)。
对于既不设置default条件,又一直没有IO操作发生的情况,select语句会引起死锁(fatal error: all goroutines are asleep - deadlock!),如果不希望出现死锁,可以设置一个超时时间的case来解决;
10 defer
defer的作用就是把defer关键字之后的函数执行压入一个栈中延迟执行,多个defer的执行顺序是后进先出LIFO,也就是先执行最后一个defer,最后执行第一个defer。
10.1 使用场景
- 打开和关闭文件;
- 接收请求和回复请求;
- 加锁和解锁等。
在这些操作中,最容易忽略的就是在每个函数退出处正确地释放和关闭资源。
10.2 一个函数中多个defer的执行顺序【defer之间】
参考1:go defer、return的执行顺序
多个defer的执行顺序是后进先出LIFO,也就是先执行最后一个defer,最后执行第一个defer。
10.3 defer、return、返回值 的执行返回值顺序
参考1:go defer、return的执行顺序
参考2:Go语言中defer和return执行顺序解析
return返回值的运行机制:return并非原子操作,共分为赋值、返回值两步操作。
defer、return、返回值三者的执行是:return最先执行,先将结果写入返回值中(即赋值);接着defer开始执行一些收尾工作;最后函数携带当前返回值退出(即返回值)。
- 无名返回值(即函数返回值为没有命名的返回值)
如果函数的返回值是无名的(不带命名返回值),则go语言会在执行return的时候会执行一个类似创建一个临时变量作为保存return值的动作,所以defer里面的操作不会影响返回值。
package main import ( "fmt" ) func main() { fmt.Println("return:", Demo()) // 打印结果为 return: 0 } func Demo() int { var i int defer func() { i++ fmt.Println("defer2:", i) // 打印结果为 defer: 2 }() defer func() { i++ fmt.Println("defer1:", i) // 打印结果为 defer: 1 }() return i }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
代码示例,实际上一共执行了3步操作:
1)赋值,因为返回值没有命名,所以return 默认指定了一个返回值(假设为s),首先将i赋值给s,i初始值是0,所以s也是0。
2)后续的defer操作因为是针对i,进行的,所以不会影响s,此后因为s不会更新,所以s不会变还是0。
3)返回值,return s,也就是return 0
相当于:
var i int
s := i
return s
- 1
- 2
- 3
- 4
- 有名返回值(函数返回值为已经命名的返回值)
有名返回值的函数,由于返回值在函数定义的时候已经将该变量进行定义,在执行return的时候会先执行返回值保存操作,而后续的defer函数会改变这个返回值(虽然defer是在return之后执行的,但是由于使用的函数定义的变量,所以执行defer操作后对该变量的修改会影响到return的值)。
由于返回值已经提前定义了,不会产生临时零值变量,返回值就是提前定义的变量,后续所有的操作也都是基于已经定义的变量,任何对于返回值变量的修改都会影响到返回值本身。
package main import ( "fmt" ) func main() { fmt.Println("return:", Demo2()) // 打印结果为 return: 2 } func Demo2() (i int) { defer func() { i++ fmt.Println("defer2:", i) // 打印结果为 defer: 2 }() defer func() { i++ fmt.Println("defer1:", i) // 打印结果为 defer: 1 }() return i // 或者直接 return 效果相同 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
10.4 defer能否修改return的值
可以,在 10.2.2 defer、return、返回值 的执行返回值顺序下有名返回值(函数返回值为已经命名的返回值)的讲解中可以知道,可以更改。
有名返回值的函数,由于返回值在函数定义的时候已经将该变量进行定义,在执行return的时候会先执行返回值保存操作,而后续的defer函数会改变这个返回值(虽然defer是在return之后执行的,但是由于使用的函数定义的变量,所以执行defer操作后对该变量的修改会影响到return的值)。
由于返回值已经提前定义了,不会产生临时零值变量,返回值就是提前定义的变量,后续所有的操作也都是基于已经定义的变量,任何对于返回值变量的修改都会影响到返回值本身。
10.5 在循环打开很多个文件,怎么使用defer关闭文件,defer应该写在哪个位置
参考1:循环内部使用defer的正确姿势
重点是理解defer的执行机制,defer是在函数退出的时候才执行的,所以可以将打开关闭、文件等操作单独写到一个函数里,或者是写到匿名函数中。
11 Golang的反射
参考1:golang之反射
11.1 反射基础知识
反射基本介绍:
- 反射可以在运行时动态获取变量的各种信息,比如变量的类型(type),类别(kind)
- 如果是结构体变量,还可以获取到结构体本身的信息(包括结构体的字段,方法)。
- 通过反射,可以修改变量的值,可以调用关联的方法。
- 使用反射,需要导入reflect包。
反射重要的函数:
reflect.TypeOf(变量名),获取变量的类型,返回reflect.Type类型;reflect.ValueOf(变量名),获取变量的值,返回reflect.Value类型,reflect.Value是一个结构体类型。通过reflect.Value,可以获取到关于该变量的很多信息。- 变量、
interface{}和reflect.Value是可以相互转换的,这点在实际开发中,会经常使用到。
interface{} ——> reflect.Value:
rVal := reflect.ValueOf(b)
reflect.Value ——> interface{}:
iVal := rVal.Interface()
interface{} ——> 原来的变量(类型断言):
v := iVal.(Stu)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
反射的注意事项:
- reflect.Value.kind,获取变量的类别,返回的是一个常量。
- Type是类型,kind是类别,可能相同,也可能不相同。
//比如:
var num int = 10 //num的Type是int,Kind也是int
var stu Student //stu的Type是包名.Student,Kind是struct
- 1
- 2
- 3
- 4
- 通过反射可以让变量在
interface{}和Reflect.Value之间相互转换:
变量 <——> interface{} <——> reflect.Value
- 1
- 2
- 使用反射的方式来获取变量的值(并返回对应的类型),要求数据类型匹配,比如x是int,那么就应该使用
reflect.Value(x).Int(),而不能使用其它的,否则报painc。 - 通过反射来修改变量,注意当使用
SetXxx方法来设置需要通过对应的指针类型来完成,这样才能改变传入的变量的值,同时需要使用到reflect.Value.Elem()方法。
11.2 反射如何获取结构体中字段的jsonTag
参考1:Go语言反射(reflection)简述
看参考1的使用反射获取结构体的成员类型部分。
package main import ( "fmt" "reflect" ) func main() { // 声明一个空结构体 type cat struct { Name string // 带有结构体tag的字段 Type int `json:"type" id:"100"` } // 创建cat的实例 ins := cat{Name: "mimi", Type: 1} // 获取结构体实例的反射类型对象 typeOfCat := reflect.TypeOf(ins) // 遍历结构体所有成员 for i := 0; i < typeOfCat.NumField(); i++ { // 获取每个成员的结构体字段类型 fieldType := typeOfCat.Field(i) // 输出成员名和tag fmt.Printf("name: %v tag: '%v'\n", fieldType.Name, fieldType.Tag) } // 通过字段名, 找到字段类型信息 if catType, ok := typeOfCat.FieldByName("Type"); ok { // 从tag中取出需要的tag fmt.Println(catType.Tag.Get("json"), catType.Tag.Get("id")) } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
输出结果:
name: Name tag: ‘’
name: Type tag: ‘json:“type” id:“100”’
type 100
11.3 结构体里的变量不加tag能正常转成json里的字段吗
参考1:golang面试题:json包变量不加tag会怎么样?
- 若是变量首字母小写,则为
private。由于取不到反射信息,所以不能转成json。 - 若是变量首字母大写,则为
public,可以转为json:
- json不加tag,能够正常转为json里的字段,json内字段名跟结构体内字段原名一致。
- json加了tag,从struct转json的时候,json的字段名就是tag里的字段名,原字段名已经没用。
代码:
package main import ( "encoding/json" "fmt" ) type JsonTest struct { aa string //小写无tag bb string `json:"BB"` //小写+tag CC string //大写无tag DD string `json:"DJson"` //大写+tag } func main() { jsonTest := JsonTest{aa: "1", bb: "2", CC: "3", DD: "4"} fmt.Printf("转为json前jsonTest结构体的内容 = %+v\n", jsonTest) jsonInfo, \_ := json.Marshal(jsonTest) fmt.Printf("转为json后的内容 = %+v\n", string(jsonInfo)) }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
11.4 反射操作指针类型
typ := reflect.TypeOf(data).Elem() //指针类型需要加 Elem()
val := reflect.ValueOf(data).Elem() //指针类型需要加 Elem()
- 1
- 2
- 3
11.5 Golang反射的使用场景和限制。
使用场景:
- 通用数据处理:反射可以用于处理未知类型的数据,例如
JSON解析、数据库操作等。通过反射,可以动态地获取和修改数据的类型和值。 - 动态调用方法:反射可以用于动态调用结构体的方法,尤其在需要通过方法名字符串来调用方法时,反射提供了一种实现机制。
- 类型检查和类型转换:通过反射,可以在运行时获取变量的类型信息,进行类型检查和类型转换。这对于泛型编程和接口实现时可能很有用。
- 代码工具和框架:一些代码生成工具、
ORM框架、测试框架等利用反射来提供通用的、可扩展的功能。
限制和注意事项:
- 性能影响:反射操作通常比直接的类型断言和静态编码效率低,因为它需要在运行时进行类型检查。在性能敏感的代码中要谨慎使用反射。
- 可读性和维护性:反射的代码通常更加复杂和难以理解,可能会降低代码的可读性和维护性。因此,只有在确实需要在运行时获取类型信息或进行动态操作时才应该使用反射。
- 类型安全问题:反射可能会导致类型不安全的问题,因为在编译时无法检查反射操作的正确性。这可能导致一些潜在的运行时错误。
- 不支持编译时优化:由于反射的特性,Go编译器无法对涉及反射的代码进行很好的优化。这可能会导致一些性能上的损失。
在实际应用中,要慎重使用反射,并确保它真的是解决问题的最佳选择。在大多数情况下,通过静态编码和类型安全的方式实现更为清晰和高效。
12 Golang哪些情况会导致内存泄漏
12.1 内存泄漏的本质
参考1:内存泄漏
内存泄漏指因为疏忽或错误造成程序未能释放已经不再使用的内存的情况。内存泄漏并不是指内存在物理上的消失,而是应用程序分配某段内存后,因为设计错误,失去了对该段内存的控制,因而造成了内存的浪费。
内存泄漏的危害:
长期运行的程序出现内存泄漏,影响很大,如操作系统、后台服务等等,出现内存泄漏会导致响应越来越慢,最终卡死。
12.2 几种情况
- 定时器使用不当
- select阻塞
- channel阻塞
- goroutine导致的内存泄漏
- slice引起的内存泄漏
- 数组的值传递
12.3 定时器使用不当
12.3.1 time.After()的使用
默认的time.After()是会有内存泄露问题的,因为每次time.After(duration x)会产生NewTimer(),在duration x到期之前,新创建的timer不会被垃圾回收,到期之后才会垃圾回收。
随着时间推移,尤其是duration x很大的话,会产生内存泄露的问题,应特别注意。
for true {
select {
case <-time.After(time.Minute \* 3):
// do something
default:
time.Sleep(time.Duration(1) \* time.Second)
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
为了保险起见,使用NewTimer()或者NewTicker()代替的方式主动释放资源。
timer := time.NewTicker(time.Duration(2) \* time.Second)
defer timer.Stop()
for true {
select {
case <-timer.C:
// do something
default:
time.Sleep(time.Duration(1) \* time.Second)
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
12.3.2 time.NewTicker资源未及时释放
在使用time.NewTicker时需要手动调用Stop()方法释放资源,否则将会造成永久性的内存泄漏。
timer := time.NewTicker(time.Duration(2) \* time.Second)
// defer timer.Stop()
for true {
select {
case <-timer.C:
// do something
default:
time.Sleep(time.Duration(1) \* time.Second)
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
12.4 select阻塞
使用select时如果有case没有覆盖完全的情况且没有default分支进行处理,会出现阻塞,最终导致内存泄漏。
12.4.1 导致goroutine阻塞的情况
func main() {
ch1 := make(chan int)
ch2 := make(chan int)
ch3 := make(chan int)
go Getdata("https://www.baidu.com",ch1)
go Getdata("https://www.baidu.com",ch2)
go Getdata("https://www.baidu.com",ch3)
select{
case v:=<- ch1:
fmt.Println(v)
case v:=<- ch2:
fmt.Println(v)
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
上面代码中这种情况会阻塞在ch3的消费处导致内存泄漏。
12.4.2 循环空转导致CPU暴涨
func main() { fmt.Println("main start") msgList := make(chan int, 100) go func() { for { select { case <-msgList: default: } } }() c := make(chan os.Signal, 1) signal.Notify(c, os.Interrupt, os.Kill) s := <-c fmt.Println("main exit.get signal:", s) }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
上述for循环条件一旦命中default则会出现循环空转的情况,并最终导致CPU暴涨。
12.5 channel阻塞
channel阻塞主要分为写阻塞和读阻塞两种情况。
12.5.1 空channel
读写均会堵塞。
func channelTest() { //声明未初始化的channel读写都会阻塞 var c chan int //向channel中写数据 go func() { c <- 1 fmt.Println("g1 send succeed") time.Sleep(1 \* time.Second) }() //从channel中读数据 go func() { <-c fmt.Println("g2 receive succeed") time.Sleep(1 \* time.Second) }() time.Sleep(10 \* time.Second) }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
12.5.2 写阻塞
- 无缓冲channel的阻塞通常是写操作因为没有读而阻塞。
func channelTest() { var c = make(chan int) //10个协程向channel中写数据 for i := 0; i < 10; i++ { go func() { <- c fmt.Println("g1 receive succeed") time.Sleep(1 \* time.Second) }() } //1个协程丛channel读数据 go func() { c <- 1 fmt.Println("g2 send succeed") time.Sleep(1 \* time.Second) }() //会有写的9个协程阻塞得不到释放 time.Sleep(10 \* time.Second) }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 有缓冲的channel因为缓冲区满了,写操作阻塞。
func channelTest() { var c = make(chan int, 8) //10个协程向channel中写数据 for i := 0; i < 10; i++ { go func() { <- c fmt.Println("g1 receive succeed") time.Sleep(1 \* time.Second) }() } //1个协程丛channel读数据 go func() { c <- 1 fmt.Println("g2 send succeed") time.Sleep(1 \* time.Second) }() //会有写的几个协程阻塞写不进去 time.Sleep(10 \* time.Second) }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
12.5.3 读阻塞
从channel读数据,但是没有goroutine往进写数据。
func channelTest() { var c = make(chan int) //1个协程向channel中写数据 go func() { <- c fmt.Println("g1 receive succeed") time.Sleep(1 \* time.Second) }() //10个协程丛channel读数据 for i := 0; i < 10; i++ { go func() { c <- 1 fmt.Println("g2 send succeed") time.Sleep(1 \* time.Second) }() } //会有读的9个协程阻塞得不到释放 time.Sleep(10 \* time.Second) }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
12.6 goroutine导致的内存泄漏
12.6.1 申请过多的goroutine
例如在for循环中申请过多的goroutine来不及释放导致内存泄漏。
12.6.2 goroutine阻塞
12.6.2.1 I/O问题
I/O连接未设置超时时间,导致goroutine一直在等待,代码会一直阻塞。
12.6.2.2 互斥锁未释放
goroutine无法获取到锁资源,导致goroutine阻塞。
12.6.2.3 死锁
当程序死锁时其他goroutine也会阻塞。
func mutexTest() { m1, m2 := sync.Mutex{}, sync.RWMutex{} //g1得到锁1去获取锁2 go func() { m1.Lock() fmt.Println("g1 get m1") time.Sleep(1 \* time.Second) m2.Lock() fmt.Println("g1 get m2") }() //g2得到锁2去获取锁1 go func() { m2.Lock() fmt.Println("g2 get m2") time.Sleep(1 \* time.Second) m1.Lock() fmt.Println("g2 get m1") }() //其余协程获取锁都会失败 go func() { m1.Lock() fmt.Println("g3 get m1") }() time.Sleep(10 \* time.Second) }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
12.6.2.4 WaitGroup使用不当
WaitGroup的Add、Done和wait数量不匹配会导致wait一直在等待。
12.7 slice 引起的内存泄漏
当两个slice共享地址,其中一个为全局变量,另一个也无法被GC;
append slice后一直使用,没有进行清理。
var a []int
func test(b []int) {
a = b[:3]
return
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
12.8 数组的值传递
由于数组时Golang的基本数据类型,每个数组占用不通的内存空间,生命周期互不干扰,很难出现内存泄漏的情况,但是数组作为形参传输时,遵循的时值拷贝,如果函数被多个goroutine调用且数组过大时,则会导致内存使用激增。
//统计nums中target出现的次数
func countTarget(nums [1000000]int, target int) int {
num := 0
for i := 0; i < len(nums) && nums[i] == target; i++ {
num++
}
return num
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
因此对于大数组放在形参场景下通常使用切片或者指针进行传递,避免短时间的内存使用激增。
13 Golang的并发实现方式
参考1:https://www.jb51.net/article/243510.htm
一共四种:
- goroutine:Golang在语言层面对并发编程进行了支持, 使用go关键字来使用协程。
- channel:Golang语言在语言级别提供了对goroutine之间通信的支持,我们可以使用channel在两个或者多个goroutine之间进行信息传递,能过channel传递对像的过程和调用函数时的参数传递行为一样,可以传递普通参数和指针。
- select:当我们在实际开发中,我们一般同时处理两个或者多个channel的数据,我们想要完成一个那个channel先来数据,我们先来处理个那channel,避免等待。
- 传统的并发控制:sync.Mutex加锁和sync.WaitGroup等待组。
14 Golang里的结构体可以直接使用双等号作比较吗
参考1:Golang = 比较与赋值
参考2:golang中如何比较struct,slice,map是否相等以及几种对比方法的区别
- 结构体只能比较是否相等,但是不能比较大小。
- 相同类型的结构体才能够进行比较,结构体是否相同不但与属性类型有关,还与属性顺序相关,sn3 与 sn1 就是不同的结构体;
- 如果 struct 的所有成员都可以比较,则该 struct 就可以通过 == 或 != 进行比较是否相等,比较时逐个项进行比较,如果每一项都相等,则两个结构体才相等,否则不相等;(像切片、map、函数等是不能比较的)
15 Golang里有Set结构体吗?如果没有怎么设计一个Set结构体
//定义1个set结构体 内部主要是使用了map
type set struct {
elements map[interface{}]bool
}
- 1
- 2
- 3
- 4
- 5
16 Golang的runtime
参考1:说说Golang的runtime
runtime包含Go运行时的系统交互的操作,例如控制goruntine的功能。还有debug,pprof进行排查问题和运行时性能分析,tracer来抓取异常事件信息,如 goroutine的创建,加锁解锁状态,系统调用进入推出和锁定还有GC相关的事件,堆栈大小的改变以及进程的退出和开始事件等等;race进行竞态关系检查以及CGO的实现。总的来说运行时是调度器和GC。
17 Golang死锁的场景及解决办法
- 无缓存能力的管道,自己写完自己读。
会报死锁:fatal error: all goroutines are asleep - deadlock!解决办法很简单,开辟两条协程,一条协程写,一条协程读。
func main() {
ch := make(chan int, 0)
ch <- 666
x := <- ch
fmt.Println(x)
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 协程来晚了
func main() {
ch := make(chan int,0)
ch <- 666
go func() {
<- ch
}()
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
我们可以看到,这条协程开辟在将数字写入到管道之后,因为没有人读,管道就不能写,然后写入管道的操作就一直阻塞。这时候就有疑惑了,不是开辟了一条协程在读吗?但是那条协程开辟在写入管道之后,如果不能写入管道,就开辟不了协程。
- 管道读写时,相互要求对方先读/写
func main() { chHusband := make(chan int,0) chWife := make(chan int,0) go func() { select { case <- chHusband: chWife<-888 } }() select { case <- chWife: chHusband <- 888 } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 先来看看老婆协程,chWife只要能读出来,也就是老婆有钱,就给老公发个八百八十八的大红包。
- 再看看老公的协程,一看不得了,咋啦?老公也说只要他有钱就给老婆包个八百八十八的大红包。
- 两个人都说自己没钱,老公也给老婆发不了红包,老婆也给老公发不了红包,这就是死锁!
- 读写锁相互阻塞,形成隐形死锁
func main() { var rmw09 sync.RWMutex ch := make(chan int,0) go func() { rmw09.Lock() ch <- 123 rmw09.Unlock() }() go func() { rmw09.RLock() x := <- ch fmt.Println("读到",x) rmw09.RUnlock() }() for { runtime.GC() } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 这两条协程,如果第一条协程先抢到了只写锁,另一条协程就不能抢只读锁了,那么因为另外一条协程没有读,所以第一条协程就写不进。
- 如果第二条协程先抢到了只读锁,另一条协程就不能抢只写锁了,那么因为另外一条协程没有写,所以第二条协程就读不到。
18 Golang的僵尸进程
参考1:Go Exec 僵尸与孤儿进程
僵尸进程(zombie process)指:完成执行(通过exit系统调用,或运行时发生致命错误或收到终止信号所致),但在操作系统的进程表中仍然存在其进程控制块,处于“终止状态”的进程。
解决&预防:
收割僵尸进程的方法是通过kill命令手工向其父进程发送SIGCHLD信号。如果其父进程仍然拒绝收割僵尸进程,则终止父进程,使得init进程收养僵尸进程。init进程周期执行wait系统调用收割其收养的所有僵尸进程。
19 Golang函数的入参是值传递还是引用传递
值传递和引用传递都有,看入参的类型。
值传递:是指在调用函数时将实际参数复制一份传递到函数中,这样在函数中如果对参数进行修改,将不会影响到实际参数。
引用传递:引用传递是指在调用函数时将实际参数的地址传递到函数中,那么在函数中对参数所进行的修改,将影响到实际参数,由于引用类型(slice、map、interface、channel)自身就是指针,所以这些类型的值拷贝给函数参数,函数内部的参数仍然指向它们的底层数据结构。
20 Golang的引用类型有哪几种
参考1:https://www.jianshu.com/p/93e205e70e83
Golang的引用类型包括 slice、map 和 channel。
21 Golang的make和new的区别
参考1:make和new的区别
new 和 make 主要区别如下:
- make只能用来分配及初始化类型为slice、map、chan的数据。new可以分配任意类型的数据;
- new分配返回的是指针,即类型*Type。make返回引用,即Type;
- new分配的空间被清零。make分配空间后,会进行初始化;
在讲new和make的使用场景之前,先介绍一下golang中的值类型和引用类型。
引用类型和值类型
值类型: int、float、bool和string这些类型都属于值类型,使用这些类型的变量直接指向存在内存中的值,值类型的变量的值存储在栈中。当使用等号=将一个变量的值赋给另一个变量时,如 j = i ,实际上是在内存中将 i 的值进行了拷贝。可以通过 &i 获取变量 i 的内存地址。 (struct在方法中传参时是值类型而非引用类型)
引用类型:特指slice、map、channel这三种预定义类型。能够通过make()函数创建的都是引用类型,比如slice和map,slice虽然看起来像数组,但是他其实是一个指向数组内存空间的一个指针类型。
使用场景:
- 如果方法内部会修改当前对象的字段或改变其值,需要用指针。
- 由于值传递是(内存)复制,因此,如果对象比较大,应该使用指针(地址),避免内存拷贝(值类型等变量指向内存中的值,如果有值类型变量存放大量元素,或造成内存的大量拷贝)
22 Mutex读写锁和互斥锁的区别
参考1:互斥锁机制,互斥锁与读写锁区别
互斥锁和读写锁的区别:
- 读写锁区分读者和写者,而互斥锁不区分。
- 互斥锁同一时间只允许一个线程访问该对象,无论读写;读写锁同一时间内只允许一个写者,但是允许多个读者同时读对象。
23 NewTicker和NewTimer的区别
- NewTimer是延迟d时间后触发,如果需要循环则需要Reset。NewTimer的延迟时间并不是精确、稳定的,比如设置30ms,有可能会35、40ms后才触发,即使在系统资源充足的情况下,所以一个循环的timer在60ms内并不能保证会触发2两次,而ticker会。
- 它会调整时间间隔或者丢弃 tick 信息以适应反应慢的接者,所以回调触发不是稳定的,有可能在小于d的时间段触发,也有可能大于d的时间段触发,即使应用什么都不做。但在一段时间内,触发次数是保证的,比如在系统资源充足的情况下,设定触发间隔30ms,上一ticket触发间隔是44ms,下一触发间隔可能就是16ms,所以60ms内还是会触发两个ticket。
区别:
ticker的稳定性不如timer,一个空转的go程序,tickter也是不稳定的,触发间隔并不会稳定在d时间段,在ms级别上;而timer相对稳定,但也不是绝对的,timer也会在大于d的时间后触发。
24 遇到高并发场景怎么处理
回答:Golang语言上是使用多协程,还有架构设计方面等等。
25 哪些场景有使用到Goroutine、channel
答:并发处理。有缓冲的channel可以控制并发数目,从而实现多线程并发处理。
26 Golang把int转为string的方式(strconv包)
参考1:Go语言strconv包实现字符串和数值类型的相互转换
strconv包里有相关的转换方法:
- string 与 int 类型之间的转换
Itoa():整型转字符串。
Atoi():字符串转整型。 - Parse 系列函数
Parse系列函数用于将字符串转换为指定类型的值,其中包括ParseBool()、ParseFloat()、ParseInt()、ParseUint()。 - Format 系列函数
Format系列函数实现了将给定类型数据格式化为字符串类型的功能,其中包括FormatBool()、FormatInt()、FormatUint()、FormatFloat()。 - Append 系列函数
Append系列函数用于将指定类型转换成字符串后追加到一个切片中,其中包含AppendBool()、AppendFloat()、AppendInt()、AppendUint()。Append系列函数和Format系列函数的使用方法类似,只不过是将转换后的结果追加到一个切片中。
27 使用过Golang的sync包里哪些函数或方法
参考1:golang标准库-sync包使用和应用场景
参考2:Golang - sync包的使用
- Locker:Locker接口,包含Lock()和Unlock()两个方法,用于代表一个能被加锁和解锁的对象。
- Once:Once是只执行一次动作的对象,使用后不得复制,Once只有一个Do方法。
- Mutex:Mutex是一个互斥锁,可以创建为其他结构体的字段;零值为解锁状态。Mutex类型的锁和线程无关,可以由不同的线程加锁和解锁。实现了Locker()接口的UnLock()和Locker()方法,同一时刻一段代码只能被一个线程运行。
- RWMutex:读写互斥锁,该锁可以被同时多个读取者持有或唯一个写入者持有。
- WaitGroup:WaitGroup 对象内部有一个计数器,最初从0开始,它有三个方法:Add(), Done(), Wait() 用来控制计数器的数量。Add(n) 把计数器设置为n ,Done() 每次把计数器-1 ,wait() 会阻塞代码的运行,直到计数器的值减为0。
- Pool:Pool是一个可以分别存取的临时对象的集合,可以被看作是一个存放可重用对象的值的容器、过减少GC来提升性能,是Goroutine并发安全的。有两个方法 Get()、Set()。
WaitGroup、Once、Mutex、RWMutex、Cond、Pool、Map。
28 Golang实现字符串拼接有几种方式及其性能
参考1:golang 几种字符串的拼接方式
参考2:Golang的五种字符串拼接方式
+号
func BenchmarkAddStringWithOperator(b \*testing.B) {
hello := "hello"
world := "world"
for i := 0; i < b.N; i++ {
\_ = hello + "," + world
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
Golang里面的字符串都是不可变的,每次运算都会产生一个新的字符串,所以会产生很多临时的无用的字符串,不仅没有用,还会给GC带来额外的负担,所以性能比较差。
fmt.Sprintf()
func BenchmarkAddStringWithSprintf(b \*testing.B) {
hello := "hello"
world := "world"
for i := 0; i < b.N; i++ {
\_ = fmt.Sprintf("%s,%s", hello, world)
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
内部使用 []byte 实现,不像直接运算符这种会产生很多临时的字符串,但是内部的逻辑比较复杂,有很多额外的判断,还用到了 interface,所以性能也不是很好。
strings.Join()
func BenchmarkAddStringWithJoin(b \*testing.B) {
hello := "hello"
world := "world"
for i := 0; i < b.N; i++ {
\_ = strings.Join([]string{hello, world}, ",")
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
join会先根据字符串数组的内容,计算出一个拼接之后的长度,然后申请对应大小的内存,一个一个字符串填入,在已有一个数组的情况下,这种效率会很高,但是如果本来没有的话,去构造这个数据的代价也不小,效率也不高。
buffer.WriteString()
func BenchmarkAddStringWithBuffer(b \*testing.B) {
hello := "hello"
world := "world"
for i := 0; i < 1000; i++ {
var buffer bytes.Buffer
buffer.WriteString(hello)
buffer.WriteString(",")
buffer.WriteString(world)
\_ = buffer.String()
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
这个比较理想,可以当成可变字符使用,对内存的增长也有优化,如果能预估字符串的长度,还可以用 buffer.Grow() 接口来设置 capacity。
几种方式的性能:
- 在已有字符串数组的场合,使用
strings.Join()能有比较好的性能。 - 在一些性能要求较高的场合,尽量使用
buffer.WriteString()以获得更好的性能。 - 性能要求不太高的场合,直接使用运算符,代码更简短清晰,能获得比较好的可读性。
- 如果需要拼接的不仅仅是字符串,还有数字之类的其他需求的话,可以考虑
fmt.Sprintf()。
29 Golang的int和int32区别
参考1:Golang中int, int8, int16, int32, int64和uint区别
答:
- int类型的大小与操作系统有关
- int8类型大小为 1 字节【8代表8位】
- int16类型大小为 2 字节【16代表16位】
- int32类型大小为 4 字节【32代表32位】
- int64类型大小为 8 字节【64代表64位】
我们看一下官方文档
int is a signed integer type that is at least 32 bits in size. It is a distinct type, however, and not an alias for, say, int32.
意思是 int 是一个至少32位的有符号整数类型。但是,它是一个不同的类型,而不是int32的别名。int 和 int32 是两码事。
uint is a variable sized type, on your 64 bit computer uint is 64 bits wide.
uint 是一种可变大小的类型,在64位计算机上,uint 是64位宽的。uint 和 uint8 等都属于无符号 int 类型。uint 类型长度取决于 CPU,如果是32位CPU就是4个字节,如果是64位就是8个字节。
总结:
go语言中的int的大小是和操作系统位数相关的,32位操作系统,int类型的大小是4字节【int32类型】。64位操作系统,int类型的大小是8个字节【int64类型】。
30 go.sum和go.mod的区别
参考1:深入理解 Go Modules 的 go.mod 与 go.sum
go.mod:
go.mod:它用来标记一个 module 和它的依赖库以及依赖库的版本。会放在 module 的主文件夹下,一般以 go.mod 命名。
上面我们说到,Golang在做依赖管理时会创建两个文件,go.mod和go.sum。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
Once:Once是只执行一次动作的对象,使用后不得复制,Once只有一个Do方法。
3. Mutex:Mutex是一个互斥锁,可以创建为其他结构体的字段;零值为解锁状态。Mutex类型的锁和线程无关,可以由不同的线程加锁和解锁。实现了Locker()接口的UnLock()和Locker()方法,同一时刻一段代码只能被一个线程运行。
4. RWMutex:读写互斥锁,该锁可以被同时多个读取者持有或唯一个写入者持有。
5. WaitGroup:WaitGroup 对象内部有一个计数器,最初从0开始,它有三个方法:Add(), Done(), Wait() 用来控制计数器的数量。Add(n) 把计数器设置为n ,Done() 每次把计数器-1 ,wait() 会阻塞代码的运行,直到计数器的值减为0。
6. Pool:Pool是一个可以分别存取的临时对象的集合,可以被看作是一个存放可重用对象的值的容器、过减少GC来提升性能,是Goroutine并发安全的。有两个方法 Get()、Set()。
WaitGroup、Once、Mutex、RWMutex、Cond、Pool、Map。
28 Golang实现字符串拼接有几种方式及其性能
参考1:golang 几种字符串的拼接方式
参考2:Golang的五种字符串拼接方式
+号
func BenchmarkAddStringWithOperator(b \*testing.B) {
hello := "hello"
world := "world"
for i := 0; i < b.N; i++ {
\_ = hello + "," + world
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
Golang里面的字符串都是不可变的,每次运算都会产生一个新的字符串,所以会产生很多临时的无用的字符串,不仅没有用,还会给GC带来额外的负担,所以性能比较差。
fmt.Sprintf()
func BenchmarkAddStringWithSprintf(b \*testing.B) {
hello := "hello"
world := "world"
for i := 0; i < b.N; i++ {
\_ = fmt.Sprintf("%s,%s", hello, world)
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
内部使用 []byte 实现,不像直接运算符这种会产生很多临时的字符串,但是内部的逻辑比较复杂,有很多额外的判断,还用到了 interface,所以性能也不是很好。
strings.Join()
func BenchmarkAddStringWithJoin(b \*testing.B) {
hello := "hello"
world := "world"
for i := 0; i < b.N; i++ {
\_ = strings.Join([]string{hello, world}, ",")
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
join会先根据字符串数组的内容,计算出一个拼接之后的长度,然后申请对应大小的内存,一个一个字符串填入,在已有一个数组的情况下,这种效率会很高,但是如果本来没有的话,去构造这个数据的代价也不小,效率也不高。
buffer.WriteString()
func BenchmarkAddStringWithBuffer(b \*testing.B) {
hello := "hello"
world := "world"
for i := 0; i < 1000; i++ {
var buffer bytes.Buffer
buffer.WriteString(hello)
buffer.WriteString(",")
buffer.WriteString(world)
\_ = buffer.String()
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
这个比较理想,可以当成可变字符使用,对内存的增长也有优化,如果能预估字符串的长度,还可以用 buffer.Grow() 接口来设置 capacity。
几种方式的性能:
- 在已有字符串数组的场合,使用
strings.Join()能有比较好的性能。 - 在一些性能要求较高的场合,尽量使用
buffer.WriteString()以获得更好的性能。 - 性能要求不太高的场合,直接使用运算符,代码更简短清晰,能获得比较好的可读性。
- 如果需要拼接的不仅仅是字符串,还有数字之类的其他需求的话,可以考虑
fmt.Sprintf()。
29 Golang的int和int32区别
参考1:Golang中int, int8, int16, int32, int64和uint区别
答:
- int类型的大小与操作系统有关
- int8类型大小为 1 字节【8代表8位】
- int16类型大小为 2 字节【16代表16位】
- int32类型大小为 4 字节【32代表32位】
- int64类型大小为 8 字节【64代表64位】
我们看一下官方文档
int is a signed integer type that is at least 32 bits in size. It is a distinct type, however, and not an alias for, say, int32.
意思是 int 是一个至少32位的有符号整数类型。但是,它是一个不同的类型,而不是int32的别名。int 和 int32 是两码事。
uint is a variable sized type, on your 64 bit computer uint is 64 bits wide.
uint 是一种可变大小的类型,在64位计算机上,uint 是64位宽的。uint 和 uint8 等都属于无符号 int 类型。uint 类型长度取决于 CPU,如果是32位CPU就是4个字节,如果是64位就是8个字节。
总结:
go语言中的int的大小是和操作系统位数相关的,32位操作系统,int类型的大小是4字节【int32类型】。64位操作系统,int类型的大小是8个字节【int64类型】。
30 go.sum和go.mod的区别
参考1:深入理解 Go Modules 的 go.mod 与 go.sum
go.mod:
go.mod:它用来标记一个 module 和它的依赖库以及依赖库的版本。会放在 module 的主文件夹下,一般以 go.mod 命名。
上面我们说到,Golang在做依赖管理时会创建两个文件,go.mod和go.sum。
[外链图片转存中…(img-vBRnt2v1-1715368383788)]
[外链图片转存中…(img-fq0XrDkm-1715368383789)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

