
作者: 魔人逗逗 原文来源: https://tidb.net/blog/d93ee4ac
引言
目前 TiDB Vector 的功能已经推出,开源了 tidb-vector-python ,并在两个AI Agent 引擎中支持了它,具体可以看 LangChain 和 LlamaIndex 的文档。
但其实这两个开源框架对于非开发者还是略有难度和学习成本,本文介绍了通过 Dify 快速使用 TiDB Vector 搭建 AI Agent。
前期准备
创建 TiDB Vector
目前如果想使用 TiDB Vector 功能暂时还需要申请,预计会很快公测。申请地址是 https://tidb.cloud/ai
申请通过后会收到体验邀请的邮件,收到邮件后就可以登录 TiDB Cloud 来体验了。
首先让我们创建一个 TiDB Vector 实例:
- 登录 TiDB Cloud 并创建 cluster
- 选择
Serverless并设置 Region 为Frankfurt (eu-central-1) - 开启
Vector Search并设置集群名 - 创建集群
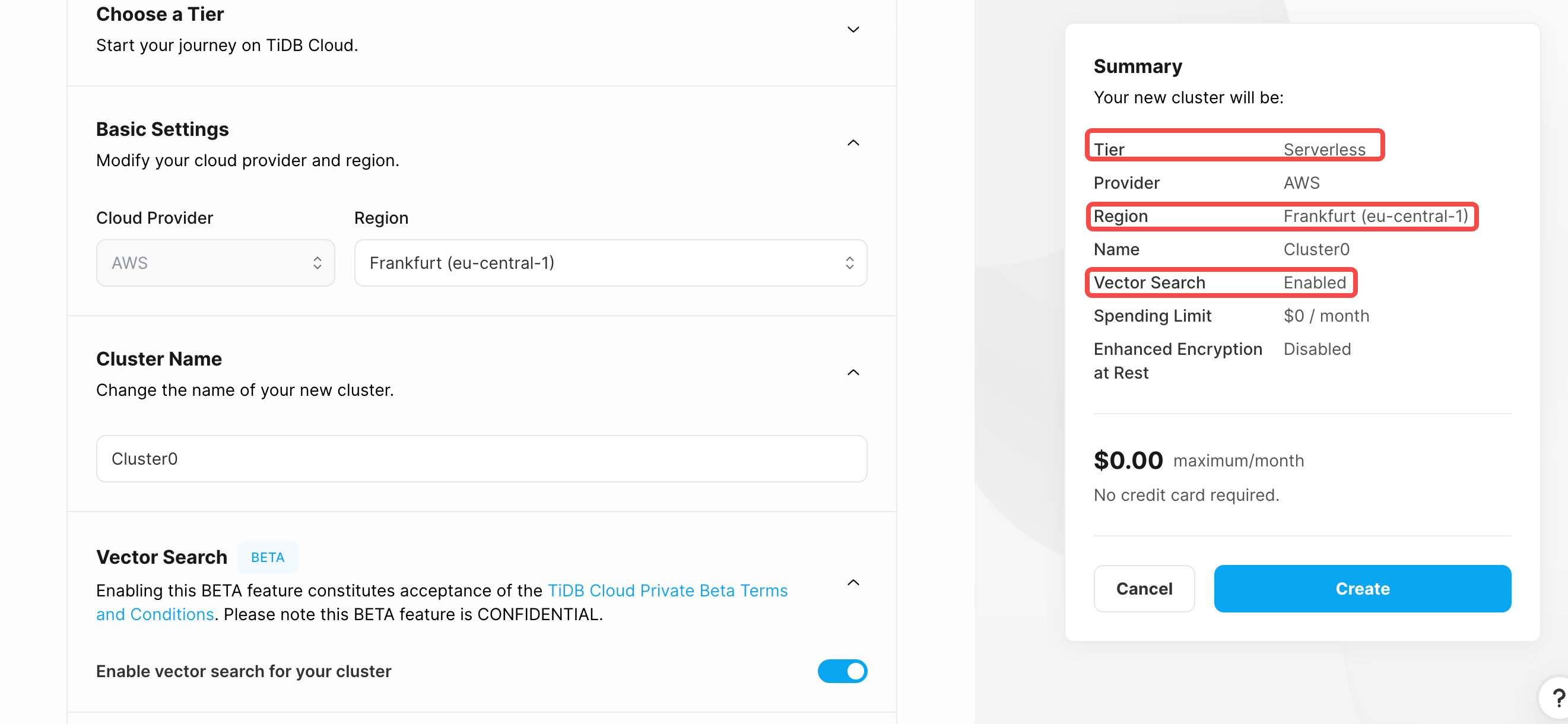
创建好集群后还需要创建一个 shema,执行如下语句
create schema dify;
至此,我们已经可以拿到对应数据库的连接配置,请保存下来
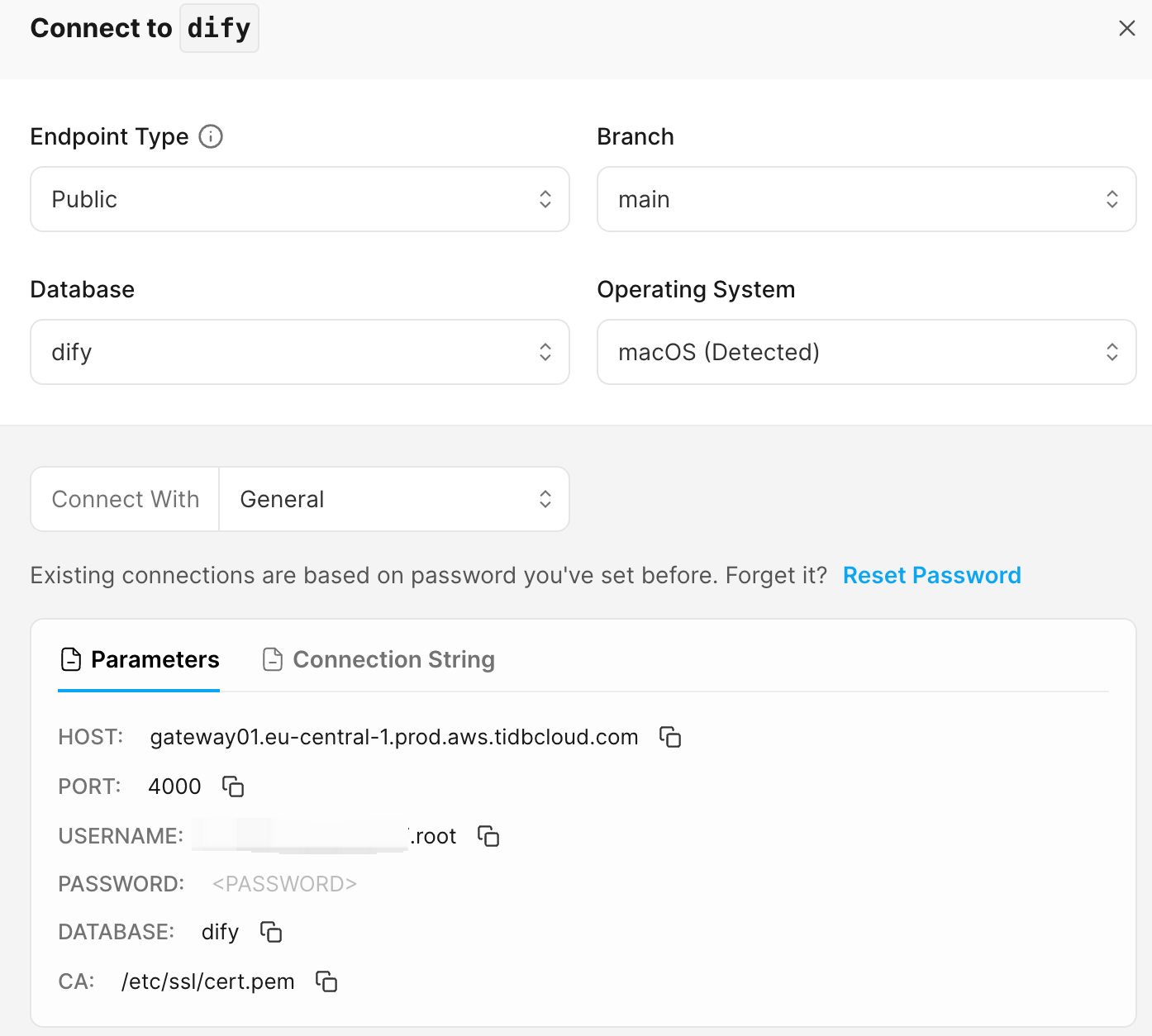
部署 Dify
先说说 Dify 是什么?Dify 是一个开源的 LLM 应用开发平台,通过简洁的界面用户可以进行模型管理、搭建 RAG 和 Agent等,除此之外 Dify 也提供了可观测功能,具体可以看 官方文档 。
作为个人如果想使用 Dify 有两种方式: 云服务 和 自托管社区版 。
Dify 云服务中默认使用的向量数据库是 weaviate ,所以如果想要将向量库切换成 TiDB Vector,需要是用社区开源版进行 自托管 。
当前 Dify v0.6.8 暂时还不支持,预计下个版本会支持,可以关注 GIthub Release
这里推荐用 Docker Compose 来部署 Dify,官方文档可以看 这里 。
Docker Compose 的 yaml 文件可以在 开源代码库找到: https://github.com/langgenius/dify/blob/main/docker/docker-compose.yaml
为了使用 TiDB Vector,我们需要修改 Docker Compose 中 api 和 worker 的环境变量:
- # 将 VECTOR_STORE 修改为 tidb_vector,文件中的默认值是 weaviate
- VECTOR_STORE: tidb_vector
-
- # 将以下配置改为保存好的连接 TiDB 配置
- TIDB_VECTOR_HOST: xxx.eu-central-1.prod.aws.tidbcloud.com
- TIDB_VECTOR_PORT: 4000
- TIDB_VECTOR_USER: xxx.root
- TIDB_VECTOR_PASSWORD: xxxxxx
- TIDB_VECTOR_DATABASE: dify
修改完毕后,执行启动命令:
docker compose up -d
部署成功后,在浏览器中输入 http://localhost 即可访问 Dify。
基于 Dify 创建 Agent
我们先复习一下用向量库增强大模型 (RAG) 的流程:
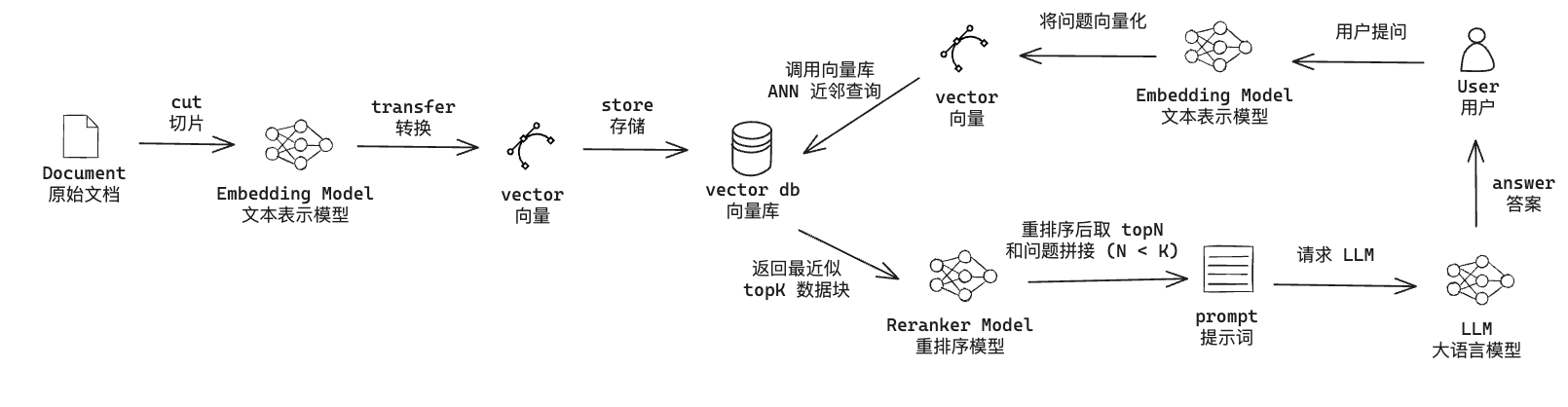
上面这张图主要分为左右两部分:
-
左半部分是用户上传文档到向量库
-
右半部分是用户使用向量库的数据增加大模型能力
- 用户提出问题
- 将用户的问题通过 Embedding 模型向量化
- 以问题向量化作为查询节点,对向量库进行ANN查询,返回 TopK 个近邻节点
- 将 用户问题和 TopK 节点的数据传递给 Reranker 模型进行重排序,并选择重排后的 TopN (N < K)
- 将问题和 TopN节点的内容拼接成 prompt 作为大模型的上下文
- 调用大模型
Reranker 模型是非必要的,主要是用于增强 RAG。
即使没有也不影响使用,直接将向量库ANN查询后的 TopK 拼接到 prompt 上下文即可。
知识库
在上面的准备工作中,我们已经配置好了 TiDB Vector,那么如何在 Dify 配置 Embedding 和 Reranker 模型?
访问 http://localhost ,选择知识库,上传文件并创建。然后进入知识库设置。
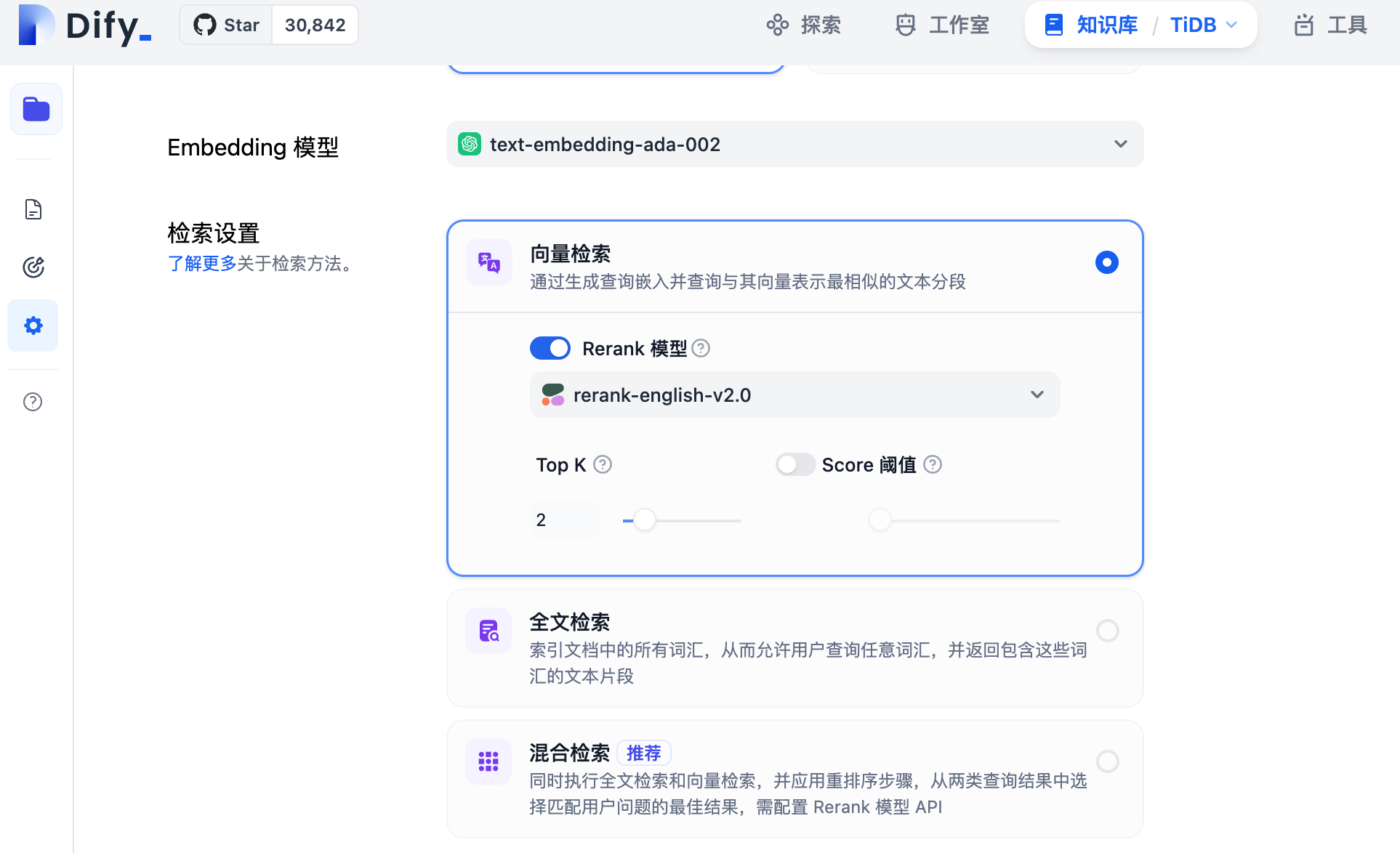
这里可以看到,Dify 针对向量库的检索主要分为3种模式:
- 向量检索 :基于 ANN 查询的检索,Reranker 模型为可选
- 全文检索 :基于 BM25 检索,Reranker 模型为可选(目前 TiDB Vector 类型未支持)
- 混合(向量+全文) :ANN + BM25 检索,Reranker 模型为必选
在使用 Embedding 和 Reranker 的时候,需要通过 token 授权。
Embedding 模型可以尝试 通义千问 、 MINIMAX 、 JINA 等等;Reranker 模型可以尝试 JINA 、 Cohere
智能体 Agent
配置知识库设置并上传文件后,我们就可以创建 Agent了。
在「工作室」中选择创建空白应用,选择 Agent 并设置图标、名称和描述信息。
进入 Agent 详情后,在上下文中添加我们刚刚创建的知识库。除了知识库之外,我们还可以设置大模型人设、工具等等。这部分操作这里就不在赘述, 官方文档 写的很全。
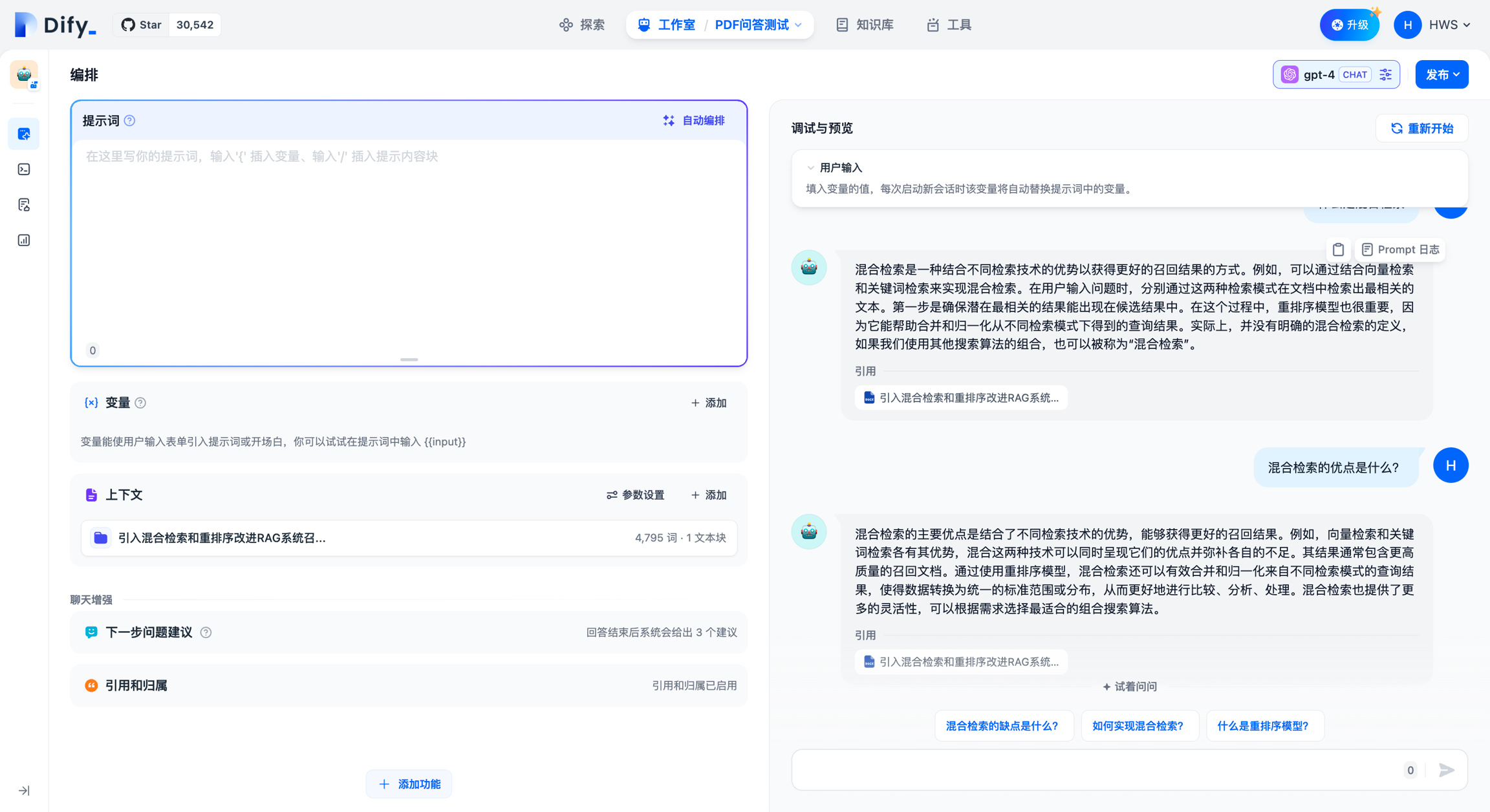
完成上面这些操作后,我们已经基于 TiDB Vector 创建好了Agent。
如果想要在别的平台或者网站使用,可以点击右上角的「发布」。目前 Dify 支持通过 script 、 iframe 或者 api 接口调用的方式使用 Agent。
源码分析:表结构 和 SQL
上面主要讲了操作流程,下面主要介绍一下 Dify 接入 TiDB Vector 后的表结构和SQL脚本。增删改查这里不做具体的描述,主要看一下表结构和查询语句。
首先我们看看 Dify 创建的表结构:
-
- CREATE TABLE IF NOT EXISTS ${collection_name} (
- # id: 这里的id是在 Dify 中生成 uuid
- id CHAR(36) PRIMARY KEY,
-
- # text: 分片后的文本内容
- text TEXT NOT NULL,
-
- # meta: 元数据,记录数据集id、文档id、知识库id等,用于条件查询
- meta JSON NOT NULL,
-
- # vector: 分片向量,需要设置向量维度
- vector VECTOR<FLOAT>(${dimension}) NOT NULL COMMENT "hnsw(distance=${distance_func})",
-
- create_time DATETIME DEFAULT CURRENT_TIMESTAMP,
- update_time DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
- );

-
${dimension}表示向量的维度,这个取决于选择的 Embedding 模型。 -
${distance_func}表示用户设置的距离度量方法,目前支持的值有**cosine** 和l2,目前仅支持**cosine** 。
用户输入问题后,查询 TiDB Vector 向量库的SQL 如下:
- SELECT meta, text FROM (
- SELECT meta, text, ${tidb_func}(vector, "${query_vector}") as distance
- FROM ${collection_name}
- ORDER BY distance
- LIMIT ${top_k}
- ) t WHERE distance < ${distance};
-
${query_vector}表示查询向量,即用户问题向量化后的结果 -
${tidb_func}表示 TiDB Vector 中支持的向量距离度量防范,目前支持的方法有Vec_Cosine_Distance和Vec_l2_Distance -
${top_k}表示结果 TopK 的具体个数 -
${distance}表示向量库中的节点离查询节点的距离,Dify 知识库可以设置距离/分数阈值
拓展
文档: Vector Search Indexes in TiDB

