
- 1【VUE3】Router安装及使用_vue3安装router
- 2全球首个开源AI数字人:DUIX数字人-打造你的AI伴侣_开源数智人
- 3er图用什么软件_使用mac一年后积累的这些软件,真香!
- 4示例代码:使用python进行flink开发_flink python开发
- 5安卓控件:TextClock 用法:设置当前的日期与时间_android textclock
- 6软件测试下的AI之路(5)
- 7抚州职业技术学院软件工程计算机毕业设计课题选题参考目录
- 8[MySQL][表的约束][二][主键][自增长][唯一键][外键]详细讲解_mysql 在已存在的表中添加非主键自增
- 9【2024软件测试面试必会技能】Charles(4):Charles证书的设置(抓HTTPS数据包)&SSL证书一年后过期解决办法_charles 证书
- 10Python爬虫中文乱码问题_python requests.get gbk
Go最全2024 年 8 个顶级开源 LLM(大语言模型)_开源llm,【好文推荐_go llm
赞
踩
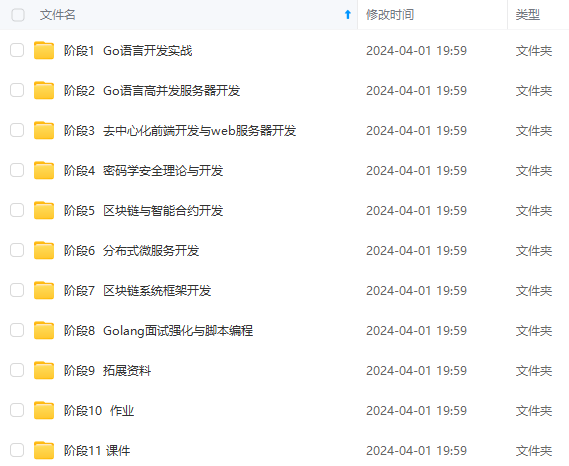
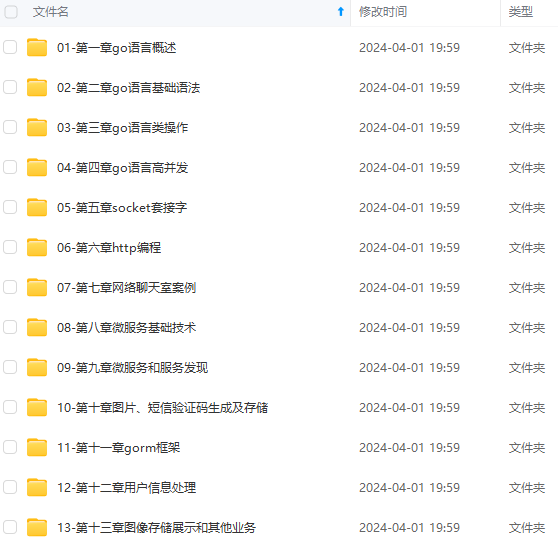
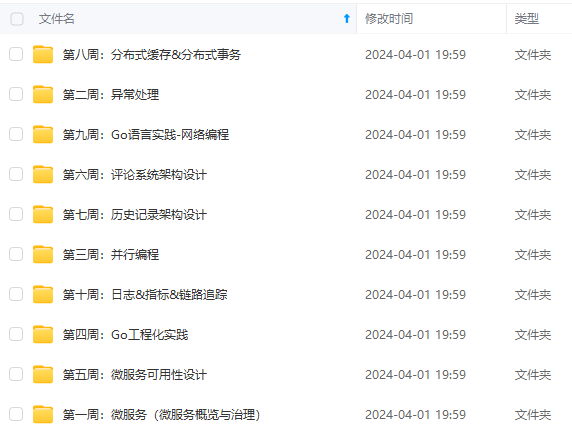
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果没有所谓的大型语言模型(LLM),当前的生成式人工智能革命就不可能实现。LLM 基于 transformers(一种强大的神经架构)是用于建模和处理人类语言的 AI 系统。它们之所以被称为“大”,是因为它们有数亿甚至数十亿个参数,这些参数是使用大量文本数据语料库预先训练的。
LLM 是流行且广泛使用的聊天机器人(如 ChatGPT 和 Google Bard)的基础模型。特别是,ChatGPT 由 OpenAI 开发和拥有的 LLM GPT-4 提供支持,而 Google Bard 则基于 Google 的 PaLM 2 模型。
ChatGPT 和 Bard 以及许多其他流行的聊天机器人都有一个共同点,即它们的基础 LLM 是专有的。这意味着它们归公司所有,只有在购买许可证后才能由客户使用。该许可证附带权利,但也对如何使用LLM进行了可能的限制,以及有关该技术背后机制的有限信息。
然而,LLM 领域的一个平行运动正在迅速加快步伐:开源 LLM。随着人们对主要由 Microsoft、Google 和 Meta 等大型科技公司控制的专有 LLM 缺乏透明度和有限可访问性的担忧日益加剧,开源 LLM 有望使快速增长的 LMM 和生成式 AI 领域更加可访问、透明和创新。
本文旨在探讨 2023 年可用的顶级开源 LLM。尽管自 ChatGPT 推出和(专有)LLM 普及以来仅一年,但开源社区已经取得了重要的里程碑,有大量开源 LLM 可用于不同目的。继续阅读以查看最受欢迎的!
使用开源 LLM 的好处
选择开源 LLM 而不是专有 LLM 有多种短期和长期好处。 下面,您可以找到最令人信服的理由列表:
增强数据安全性和隐私性
使用专有 LLM 的最大问题之一是 LLM 提供商泄露数据或未经授权访问敏感数据的风险。事实上,关于涉嫌将个人和机密数据用于培训目的,已经存在一些争议。
通过使用开源 LLM,公司将全权负责保护个人数据,因为他们将完全控制个人数据。
节省成本,减少对供应商的依赖
大多数专有的 LLM 需要许可证才能使用它们。从长远来看,这可能是一些公司,尤其是中小企业可能无法负担的重要费用。开源 LLM 并非如此,因为它们通常是免费使用的。
但是,需要注意的是,运行 LLM 需要大量资源,即使仅用于推理,这意味着您通常需要为使用云服务或强大的基础设施付费。
代码透明度和语言模型自定义
选择开源 LLM 的公司将可以访问 LLM 的工作原理,包括它们的源代码、架构、训练数据以及训练和推理机制。这种透明度是审查的第一步,也是定制的第一步。
由于每个人都可以访问开源 LLM,包括它们的源代码,因此使用它们的公司可以针对其特定用例对其进行自定义。
积极的社区支持和促进创新
开源运动有望使 LLM 和生成式 AI 技术的使用和访问民主化。允许开发人员检查 LLM 的内部工作是该技术未来发展的关键。通过降低全球编码人员的准入门槛,开源 LLM 可以通过减少偏见、提高准确性和整体性能来促进创新并改进模型。
解决人工智能对环境的影响
随着 LLM 的普及,研究人员和环境监管机构对运行这些技术所需的碳足迹和耗水量提出了担忧。专有的 LLM 很少发布有关培训和运营 LLM 所需资源的信息,也很少发布相关的环境足迹。
通过开源 LLM,研究人员有更多机会了解这些信息,这可以为旨在减少 AI 环境足迹的新改进打开大门。
2024 年 8 个顶级开源大语言模型
1. LLaMA 2

LLM 领域的大多数顶级参与者都选择闭门造车地建立他们的 LLM。但 Meta 正在采取行动成为一个例外。随着其强大的开源大型语言模型 Meta AI (LLaMA) 及其改进版本 (LLaMA 2) 的发布,Meta 正在向市场发出一个重要信号。
LLaMA 2 于 2023 年 7 月实现用于研究和商业用途,是一个预训练的生成文本模型,具有 7 到 700 亿个参数。它已通过来自人类反馈的强化学习 (RLHF) 进行了微调。它是一种生成文本模型,可以用作聊天机器人,可以适应各种自然语言生成任务,包括编程任务。Meta 已经推出了 LLaMA 2, Llama Chat, 和 Code Llama的开放定制版本。
2. BLOOM

BLOOM 于 2022 年推出,经过与来自 70+ 个国家的志愿者和 Hugging Face 的研究人员为期一年的合作项目,BLOOM 是一个自回归 LLM,经过训练,可以使用工业规模的计算资源在大量文本数据上从提示中连续文本化。
BLOOM 的发布标志着生成式 AI 民主化的一个重要里程碑。BLOOM 拥有 176 亿个参数,是最强大的开源 LLM 之一,能够以 46 种语言和 13 种编程语言提供连贯准确的文本。
透明度是 BLOOM 的支柱,在这个项目中,每个人都可以访问源代码和训练数据,以便运行、研究和改进它。
BLOOM 可以通过 Hugging Face 生态系统免费使用。
3. BERT

LLM 的底层技术是一种称为 transformer 的神经架构。它是由谷歌开发人员于 2017 年在论文《注意力是你所需要的一切》中提到的。测试 transformers 潜力的首批实验之一是 BERT。
BERT(Bidirectional Encoder Representations from Transformers)于 2018 年由 Google 作为开源 LLM 推出,在许多自然语言处理任务中迅速实现了最先进的性能。
由于其在 LLM 早期的创新功能及其开源性质,Bert 是最受欢迎和使用最广泛的 LLM 之一。例如,在 2020 年,谷歌宣布已通过 70 多种语言的 Google 搜索采用了 Bert。
目前有数以千计的开源、免费和预训练的 Bert 模型可用于特定用例,例如情感分析、临床笔记分析和有害评论检测。
4. Falcon 180B

如果说Falcon 40B 已经给开源 LLM 社区留下了深刻的印象(它在 Hugging Face 的开源大型语言模型排行榜上排名 #1),那么新的 Falcon 180B 表明专有和开源 LLM 之间的差距正在迅速缩小。
Falcon 180B 由阿拉伯技术创新研究所于 2023 年 9 月发布,可以接受 1800 亿个参数和 3.5 万亿个 Token。凭借这种令人印象深刻的计算能力, Falcon 180B 在各种 NLP 任务中已经超过了 LLaMA 3 和 GPT-5.2,而 Hugging Face 表明它可以与谷歌的 PaLM 2 相媲美,后者是为 Google Bard 提供支持的 LLM。
虽然免费用于商业和研究用途,但重要的是要注意 Falcon 180B 需要珍贵的计算资源才能运行。
5. OPT-175B

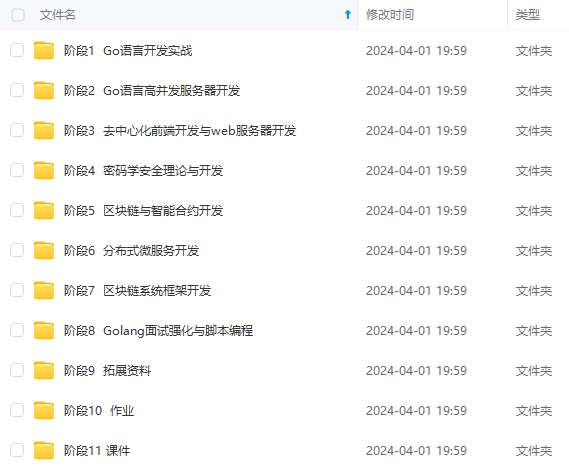
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
了95%以上Go语言开发知识点,真正体系化!**
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新

