
- 1Golang 中的 strings 包详解(二):strings.Reader_strings.newreader
- 22. 数据结构——单链表的主要操作(考研专业课学习)
- 3超前进位加法器(Verilog&数字IC)
- 4最新 【Navicat Premium 17.0.8】简体中文版破解激活永久教程_navicat17注册码
- 5文心一言、讯飞星火、KIMI、秘塔AI针对同一问题的回答_ai 文心一言 kimi 秘塔
- 6中文语法纠错全国大赛获奖分享:基于多轮机制的中文语法纠错_中文 lang8 数据集下载
- 7【MySQL编译安装】【设置MySQL centso 6操作方法】【MySQL数据库修改密码】_mysql cluster community 编译安装
- 8利用Jenkins pipeline配置测试工具_jenkins pipline jacoco
- 9cms 及其漏洞_cms漏洞
- 10Java二十三种设计模式-组合模式(11/23)
基于Transformer实现机器翻译_基于transformer的神经机器英语翻译实验
赞
踩
目录
1.实验内容
1.1编码器
在自然语言处理(NLP)领域,编码器通常指的是用于将文本数据转换为某种数值表示的模型或算法。这种数值表示可以用于下游的任务,如文本分类、情感分析、机器翻译等。
1.2Transfromer
Transformer是一种基于自注意力机制的深度学习模型。Transformer模型的核心是自注意力机制和多头注意力机制,这使得模型能够有效地捕捉序列数据中的长距离依赖关系。Transformer模型的一个关键特点是它可以并行处理序列数据,这极大地提高了计算效率。此外,由于它能够有效地捕捉长距离依赖关系,它在处理长文本时比传统的循环神经网络和长短期记忆网络等模型更为有效。
1.3贪婪解码
贪婪解码是一种解码策略,通常用于序列生成任务,如机器翻译、文本摘要和语音识别。在贪婪解码过程中,解码器在每一步都选择概率最高的词或标记作为输出,而不考虑后续步骤的可能性。这种方法的优点是简单且速度快,但缺点是它可能不会产生最优的输出序列。
1.4翻译函数
翻译函数"指的是用于机器翻译任务的函数或模型,它将一种语言的文本转换为另一种语言。在深度学习的背景下,这种翻译函数通常是由一个神经网络模型实现的。翻译函数通常是通过训练数据集来学习的。训练数据集包含成对的源语言和目标语言句子,模型通过这些数据学习如何将源语言映射到目标语言。
2.实现基于Transformer的机器翻译
2.1实验目的
机器翻译是指将一段文本从一种语言自动翻译到另一种语言。本次实验主要实现的是日文到中文的翻译。
2.2实验环境
本次实验用的是Kaggle带的GPU环境。

2.3实验流程
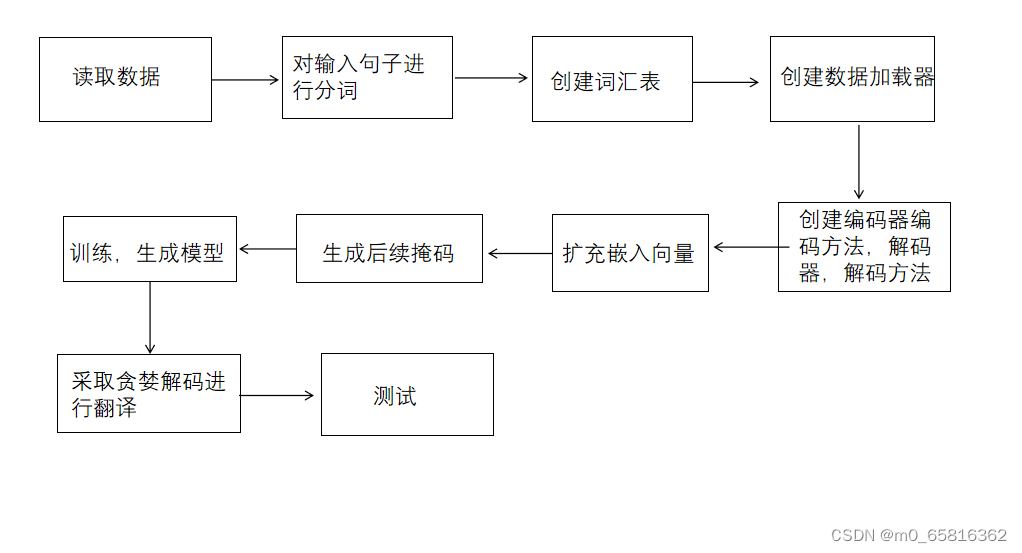
3.具体代码实现
3.1实验准备
读取数据集,创建一个对象,使其包含被加载相关的分词模型。使用分词器对输入的句子进行分词,测试。根据遍历的句子中的内容,创建词汇表,为之后的实验做准备。构建函数,包括的方法是将句子转换为整数索引张量。最后定义了一个函数generate_batch和一个数据加载器train_iter,用于处理和迭代机器翻译任务中的训练数据。对句子进行填充索引,连接张量等预处理工作,以便能够用于训练神经网络模型。
主要函数generate_batch和数据加载器train_iter代码:
-
- BATCH_SIZE = 8
- PAD_IDX = ja_vocab['<pad>']
- BOS_IDX = ja_vocab['<bos>']
- EOS_IDX = ja_vocab['<eos>']
- def generate_batch(data_batch):
- ja_batch, en_batch = [], []
-
- for (ja_item, en_item) in data_batch:
-
- ja_batch.append(torch.cat([torch.tensor([BOS_IDX]), ja_item, torch.tensor([EOS_IDX])], dim=0))
-
- en_batch.append(torch.cat([torch.tensor([BOS_IDX]), en_item, torch.tensor([EOS_IDX])], dim=0))
-
- ja_batch = pad_sequence(ja_batch, padding_value=PAD_IDX)
-
- en_batch = pad_sequence(en_batch, padding_value=PAD_IDX)
- return ja_batch, en_batch
-
- train_iter = DataLoader(train_data, batch_size=BATCH_SIZE,
- shuffle=True, collate_fn=generate_batch)

3.2实验过程
3.2.1编码器和解码器
创建编码器层,根据编码器层建立编码器。创建解码器层,根据解码器层建立解码器。再创建全连接层,位置编码层,源语言和目标语言的词嵌入层。定义函数,利用前向传播方法接收源和目标序列以及各种掩码,定义使得编码方法用于只运行编码器,解码方法用于只运行解码器,防止发生混乱导致结果出错。
- class Seq2SeqTransformer(nn.Module):
-
- def __init__(self, num_encoder_layers: int, num_decoder_layers: int,
- emb_size: int, src_vocab_size: int, tgt_vocab_size: int,
- dim_feedforward:int = 512, dropout:float = 0.1):
- super(Seq2SeqTransformer, self).__init__()
- encoder_layer = TransformerEncoderLayer(d_model=emb_size, nhead=NHEAD,
- dim_feedforward=dim_feedforward)
- self.transformer_encoder =TransformerEncoder(encoder_layer,num_layers=num_encoder_layers)
-
- decoder_layer = TransformerDecoderLayer(d_model=emb_size, nhead=NHEAD,
- dim_feedforward=dim_feedforward)
- self.transformer_decoder = TransformerDecoder(decoder_layer, num_layers=num_decoder_layers)
- self.generator = nn.Linear(emb_size, tgt_vocab_size)
- self.src_tok_emb = TokenEmbedding(src_vocab_size, emb_size)
- self.tgt_tok_emb = TokenEmbedding(tgt_vocab_size, emb_size)
- self.positional_encoding = PositionalEncoding(emb_size, dropout=dropout)
- def forward(self, src: Tensor, trg: Tensor, src_mask: Tensor,
- tgt_mask: Tensor, src_padding_mask: Tensor,
- tgt_padding_mask: Tensor, memory_key_padding_mask: Tensor):
- src_emb = self.positional_encoding(self.src_tok_emb(src))
- tgt_emb = self.positional_encoding(self.tgt_tok_emb(trg))
- memory = self.transformer_encoder(src_emb, src_mask, src_padding_mask)
-
- outs = self.transformer_decoder(tgt_emb, memory, tgt_mask, None,
- tgt_padding_mask, memory_key_padding_mask)
- return self.generator(outs)
-
- def encode(self, src: Tensor, src_mask: Tensor):
-
- return self.transformer_encoder(self.positional_encoding(
- self.src_tok_emb(src)), src_mask)
-
- def decode(self, tgt: Tensor, memory: Tensor, tgt_mask: Tensor):
-
- return self.transformer_decoder(self.positional_encoding(
- self.tgt_tok_emb(tgt)), memory,
- tgt_mask)
3.2.2常用组件
因为Transformer模型本身不具有处理序列顺序的能力,所以用PositionalEncoding类给模型的输入添加位置信息,它使用正弦和余弦函数根据词在序列中的位置生成位置嵌入。在前向传播中,它将位置嵌入加到词嵌入上,并通过dropout层。TokenEmbedding这个类定义了词嵌入层,它将词汇的索引映射到嵌入空间。在前向传播中,它将输入的词汇索引转换为嵌入向量,并进行缩放。generate_square_subsequent_mask函数生成一个方形后续掩码,用于在解码器层中屏蔽未来的位置,确保在预测一个词时不会考虑后面的词。它返回一个上三角矩阵,上三角部分的元素为负无穷大,这样在计算注意力分数时,被mask的位置将不会对输出产生影响。create_mask这个函数为源和目标序列创建掩码,包括后续掩码和填充掩码。后续掩码用于屏蔽解码器中的未来位置。填充掩码用于在计算注意力分数时忽略填充标记。
3.2.3训练过程
设置超参数,选择设备,损失函数以及优化器。将模型设置为训练模式,初始化变量,用于累加整个训练周期中的损失。遍历每个批次的数据,使用指定的设备进行训练,创建掩码,确保模型在训练过程中不会看到未来的信息,并且能够正确处理填充标记。前向传播,计算模型输出利用交叉熵损失函数,计算损失值,注意损失值是每一次累加计算,等最后一次训练完毕,计算平均值。进行反向传播,计算模型参数的梯度,再根据计算出的梯度更新模型参数。
- def train_epoch(model, train_iter, optimizer):
- model.train()
- losses = 0
- for idx, (src, tgt) in enumerate(train_iter):
- src = src.to(device)
- tgt = tgt.to(device)
- tgt_input = tgt[:-1, :]
- src_mask, tgt_mask, src_padding_mask, tgt_padding_mask = create_mask(src,tgt_input)
- logits = model(src, tgt_input, src_mask,tgt_mask,src_padding_mask,tgt_padding_mask, src_padding_mask)
- optimizer.zero_grad()
- tgt_out = tgt[1:,:]
- loss = loss_fn(logits.reshape(-1, logits.shape[-1]), tgt_out.reshape(-1))
- loss.backward()#反向传播
- optimizer.step()
- losses += loss.item()
-
- return losses / len(train_iter)
-
-
- def evaluate(model, val_iter):
- model.eval()
- losses = 0
- for idx, (src, tgt) in (enumerate(valid_iter)):
- src = src.to(device)
- tgt = tgt.to(device)
- tgt_input = tgt[:-1, :]
- src_mask, tgt_mask, src_padding_mask, tgt_padding_mask = create_mask(src, tgt_input)
- logits = model(src, tgt_input, src_mask, tgt_mask,src_padding_mask, tgt_padding_mask,src_padding_mask)
- tgt_out = tgt[1:,:]
- loss = loss_fn(logits.reshape(-1, logits.shape[-1]), tgt_out.reshape(-1))#计算损失值
- losses += loss.item()
-
- return losses / len(val_iter)
训练过程:


3.2.3解码以及翻译
定义了一个用于贪婪解码的函数greedy_decode和一个用于翻译句子的函数translate。greedy-decode函数使用贪婪解码策略来生成目标语言的句子。首先,它使用模型对源语言句子进行编码,生成一个编码后的记忆。初始化目标语言句子的第一个词,在一个循环中,它逐步生成目标语言的句子,每次生成一个词。之后为当前已生成的目标句子创建后续掩码,以确保在解码时不会考虑未来的位置。使用模型解码器生成下一个词的概率分布,选择概率最高的词作为下一个词。如果生成的词是结束标记EOS_IDX,则停止解码过程。最终,返回生成的目标语言句子的词索引序列。translate函数将源语言的句子翻译成目标语言的句子。首先将模型设置为评估模式,再将源句子转换为词索引序列,并添加开始和结束标记。创建源句子的张量和掩码。使用之前贪婪解码生成目标语言的句子的词索引序列。将目标句子的词索引序列转换为字符串,并移除开始和结束标记。最后返回翻译后的目标语言句子。
-
- def greedy_decode(model, src, src_mask, max_len, start_symbol):
- src = src.to(device)
- src_mask = src_mask.to(device)
- memory = model.encode(src, src_mask)
- ys = torch.ones(1, 1).fill_(start_symbol).type(torch.long).to(device)
- for i in range(max_len-1):
- memory = memory.to(device)
- memory_mask = torch.zeros(ys.shape[0], memory.shape[0]).to(device).type(torch.bool)
- tgt_mask = (generate_square_subsequent_mask(ys.size(0))
- .type(torch.bool)).to(device)
- out = model.decode(ys, memory, tgt_mask)
- out = out.transpose(0, 1)
- prob = model.generator(out[:, -1])
- _, next_word = torch.max(prob, dim = 1)
- next_word = next_word.item()
- ys = torch.cat([ys,torch.ones(1, 1).type_as(src.data).fill_(next_word)], dim=0)
- if next_word == EOS_IDX:
- break
- return ys
-
- def translate(model, src, src_vocab, tgt_vocab, src_tokenizer):
- model.eval()
- tokens = [BOS_IDX] + [src_vocab.stoi[tok] for tok in src_tokenizer.encode(src, out_type=str)]+ [EOS_IDX]
- num_tokens = len(tokens)
- src = (torch.LongTensor(tokens).reshape(num_tokens, 1) )
- src_mask = (torch.zeros(num_tokens, num_tokens)).type(torch.bool)
- tgt_tokens = greedy_decode(model, src, src_mask, max_len=num_tokens + 5, start_symbol=BOS_IDX).flatten()
- return " ".join([tgt_vocab.itos[tok] for tok in tgt_tokens]).replace("<bos>", "").replace("<eos>", "")
翻译结果:

3.2.4模型保存
通过调用torch.save等函数,将训练好的模型保存在自定义的文件夹中,方便之后的调用。
保存结果:

4.实验小结
通过本次实验,对于基于Transformer的机器翻译有了进一步的了解。再次熟悉了解码器,编码器等函数或组件的基本原理以及运用。了解了如何再网页上使用GPU运行代码。


