
- 1Spring Boot整合RabbitMQ详细教程_springboot整合rabbitmq
- 2未来已来!体验AI数字人客服系统带来的便利与智慧
- 3【python】tkinter+pyserial实现串口调试助手_串口调试工具 python
- 4数据库MongoDB启动方式(3种) - 方法总结篇_如何启动mongodb
- 5通过虚拟机安装Ubuntu系统到移动硬盘_vmware虚拟机移动到移动硬盘
- 6基于MATLAB的ZF、MMSE、THP线性预编码误码率仿真_zf预编码matlab代码
- 7自然语言处理(NLP)—— 置信度(Confidence)_感知层的置信度
- 8自然语言处理的实体识别:命名实体识别与关系抽取_使用自然语言处理进行人物关系抽取
- 9Python Tkinter教程之Event篇(1)_python tk event
- 10代码随想录day1 Java版
【分布式计算框架】Spark RDD五大属性剖析 | Action 和 Transformations 算子_spark action与
赞
踩

目录
一、RDD简介
目标
-
深入理解 RDD 的内在逻辑, 以及 RDD 的内部属性(RDD 由什么组成)
1.1. 案例
数据
- 190.217.63.59 - - [01/Nov/2017:00:00:15 +0000] "GET /axis2/services/WebFilteringService/getCategoryByUrl?app=chrome_antiporn&ver=0.19.7.1&url=https%3A//securepubads.g.doubleclick.net/static/3p_cookie.html&cat=business-and-economy HTTP/1.1" 200 133 "-" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36"
- 76.114.21.96 - - [01/Nov/2017:00:00:31 +0000] "GET /axis2/services/WebFilteringService/getCategoryByUrl?app=chrome_antiporn&ver=0.19.7.1&url=http%3A//tricolor.entravision.com/sacramento/escucha-en-vivo/&cat=business-and-economy HTTP/1.1" 200 133 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36"
- 206.126.121.204 - - [01/Nov/2017:00:00:46 +0000] "GET /axis2/services/WebFilteringService/getCategoryByUrl?app=chrome_antiporn&ver=0.19.7.1&url=http%3A//zone.msn.com/gameplayer/gameplayer.aspx%3Fgame%3Dfamilyfeud&cat=internet-portal HTTP/1.1" 200 133 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36"
- 154.121.8.18 - - [01/Nov/2017:00:01:01 +0000] "GET /axis2/services/WebFilteringService/getCategoryByUrl?app=firefox_AntiPorn&ver=0.19.6.9&url=https%3A%2F%2Fwww.google.dz%2Fsearch&cat=search-engine HTTP/1.1" 200 133 "-" "Mozilla/5.0 (Windows NT 5.1; rv:11.0) Gecko/20100101 Firefox/11.0"
- 190.238.37.217 - - [01/Nov/2017:00:01:17 +0000] "GET /axis2/services/WebFilteringService/getCategoryByUrl?app=chrome_antiporn&ver=0.19.7.1&url=https%3A//securepubads.g.doubleclick.net/static/3p_cookie.html&cat=business-and-economy HTTP/1.1" 200 133 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36"
- 147.147.163.182 - - [01/Nov/2017:00:01:31 +0000] "GET /axis2/services/WebFilteringService/getCategoryByUrl?app=firefox_AntiPorn&ver=0.19.6.9&url=https%3A%2F%2Fs-usweb.dotomi.com%2Frenderer%2FdelPublishersCookies.html&cat=business-and-economy HTTP/1.1" 200 133 "-" "Mozilla/5.0 (X11; Linux x86_64; rv:56.0) Gecko/20100101 Firefox/56.0"
- 200.78.93.132 - - [01/Nov/2017:00:01:45 +0000] "GET /axis2/services/WebFilteringService/getCategoryByUrl?app=chrome_antiporn&ver=0.19.7.1&url=https%3A//www.facebook.com/login/device-based/regular/login/&cat=social-networking HTTP/1.1" 200 133 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36"
- 24.200.173.170 - - [01/Nov/2017:00:01:59 +0000] "GET /axis2/services/WebFilteringService/getCategoryByUrl?app=chrome_antiporn&ver=0.19.7.1&url=https%3A//securepubads.g.doubleclick.net/static/glade.js&cat=business-and-economy HTTP/1.1" 200 133 "-" "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36"
- 189.252.185.4 - - [01/Nov/2017:00:02:15 +0000] "GET /axis2/services/WebFilteringService/getCategoryByUrl?app=firefox_AntiPorn&ver=0.19.6.9&url=https%3A%2F%2Fwww.google.cm%2Fblank.html&cat=internet-portal HTTP/1.1" 200 133 "-" "Mozilla/5.0 (Windows NT 6.1; rv:34.0) Gecko/20100101 Firefox/34.0"
- 190.90.22.125 - - [01/Nov/2017:00:02:29 +0000] "GET /axis2/services/WebFilteringService/getCategoryByUrl?app=chrome_antiporn&ver=0.19.7.1&url=http%3A//www.raicesdeeuropa.com/grandes-obras-de-los-principales-escritores-nacidos-durante-el-siglo-xix/&cat=unknown HTTP/1.1" 200 134 "-" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36"
- 181.64.62.158 - - [01/Nov/2017:00:02:45 +0000] "GET /axis2/services/WebFilteringService/getCategoryByUrl?app=chrome_antiporn&ver=0.19.7.1&url=https%3A//bancaporinternet.interbank.com.pe/Warhol/redireccionaInicioLogueo&cat=financial-service HTTP/1.1" 200 133 "-" "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36"
- 122.54.153.240 - - [01/Nov/2017:00:03:00 +0000] "GET /axis2/services/WebFilteringService/getCategoryByUrl?app=chrome_antiporn&ver=0.19.7.1&url=https%3A//securepubads.g.doubleclick.net/static/3p_cookie.html&cat=business-and-economy HTTP/1.1" 200 133 "-" "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36"
- 181.64.62.158 - - [01/Nov/2017:00:03:16 +0000] "GET /axis2/services/WebFilteringService/getCategoryByUrl?app=chrome_antiporn&ver=0.19.7.1&url=https%3A//www.google.com.pe/&cat=search-engine HTTP/1.1" 200 133 "-" "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36"
- 190.236.239.8 - - [01/Nov/2017:00:03:33 +0000] "GET /axis2/services/WebFilteringService/getCategoryByUrl?app=chrome_antiporn&ver=0.19.7.1&url=https%3A//www.google.com.pe/search%3Frlz%3D1C2AOHY_esPE760PE760%26source%3Dhp%26ei%3DUw_5WeGVA4TjmAHO8aCgDw%26q%3Dfb%26oq%3Dfb%26gs_l%3Dpsy-ab.3..0i131k1j0l4j0i131k1l2j0l3.1767.1916.0.2135.2.2.0.0.0.0.144.269.0j2.2.0....0...1.1.64.psy-ab..0.2.267....0.pWGbpZy6zwg%26safe%3Dhigh&cat=search-engine HTTP/1.1" 200 133 "-" "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36"
需求
- 给定一个网站的访问记录, 俗称 Access log
- 计算其中出现的独立 IP, 以及其访问的次数


针对这个小案例,提出互相关联但是又方向不同的五个问题
1. 假设要针对整个网站的历史数据进行处理, 量有 1T, 如何处理?
放在集群中, 利用集群多台计算机来并行处理
2.如何放在集群中运行?
简单来讲, 并行计算就是同时使用多个计算资源解决一个问题, 有如下四个要点
- 要解决的问题必须可以分解为多个可以并发计算的部分
- 每个部分要可以在不同处理器上被同时执行
- 需要一个共享内存的机制
- 需要一个总体上的协作机制来进行调度
3.如果放在集群中的话, 可能要对整个计算任务进行分解, 如何分解?
- 对于 HDFS 中的文件, 是分为不同的 Block 的
- 在进行计算的时候, 就可以按照 Block 来划分, 每一个 Block 对应一个不同的计算单元
RDD 并没有真实的存放数据, 数据是从 HDFS 中读取的, 在计算的过程中读取即可
RDD至少是需要可以 分片 的, 因为HDFS中的文件就是分片的,RDD分片的意义在于表示对源数据集每个分片的计算,RDD可以分片也意味着 可以并行计算
4.移动数据不如移动计算是一个基础的优化, 如何做到?
每一个计算单元需要记录其存储单元的位置, 尽量调度过去
5. 在集群中运行, 需要很多节点之间配合, 出错的概率也更高, 出错了怎么办?87
RDD1 → RDD2 → RDD3 这个过程中, RDD2 出错了, 有两种办法可以解决
- 缓存 RDD2 的数据, 直接恢复 RDD2, 类似 HDFS 的备份机制
- 记录 RDD2 的依赖关系, 通过其父级的 RDD 来恢复 RDD2, 这种方式会少很多数据的交互和保存
如何通过父级 RDD 来恢复?
- 记录 RDD2 的父亲是 RDD1 (Dependencies, )
- 记录 RDD2 的计算函数, 例如记录
RDD2 = RDD1.map(…),map(…)就是计算函数 - 当 RDD2 计算出错的时候, 可以通过父级 RDD 和计算函数来恢复 RDD2
6.假如任务特别复杂, 流程特别长, 有很多 RDD 之间有依赖关系, 如何优化
上面提到了可以使用依赖关系来进行容错, 但是如果依赖关系特别长的时候, 这种方式其实也比较低效, 这个时候就应该使用另外一种方式, 也就是记录数据集的状态
在 Spark 中有两个手段可以做到
- 缓存
- Checkpoint
1.2. 再谈 RDD
1.2.1. RDD 为什么会出现?
在 RDD 出现之前, 当时 MapReduce 是比较主流的, 而 MapReduce 如何执行迭代计算的任务呢?
多个 MapReduce 任务之间没有基于内存的数据 共享方式, 只能通过磁盘来进行共享
这种方式明显比较低效
RDD 如何解决迭代计算非常低效的问题呢?
在 Spark 中, 其实最终 Job3 从逻辑上的计算过程是: Job3 = (Job1.map).filter, 整个过程是共享内存的, 而不需要将中间结果存放在可靠的分布式文件系统中
这种方式可以在保证容错的前提下, 提供更多的灵活, 更快的执行速度,
1.2.2. RDD
RDD 不仅是数据集, 也是编程模型
RDD 即是一种数据结构, 同时也提供了上层 API, 同时 RDD 的 API 和 Scala 中对集合运算的 API 非常类似, 同样也都是各种算子
RDD 的算子大致分为两类:
- Transformation 转换操作, 例如
mapflatMapfilter等 - Action 动作操作, 例如
reducecollectshow等
执行 RDD 的时候, 在执行到转换操作的时候, 并不会立刻执行, 直到遇见了 Action 操作, 才会触发真正的执行, 这个特点叫做 惰性求值
RDD 可以分区
RDD 是一个分布式计算框架, 所以, 一定是要能够进行分区计算的, 只有分区了, 才能利用集群的并行计算能力
同时, RDD 不需要始终被具体化, 也就是说: RDD 中可以没有数据, 只要有足够的信息知道自己是从谁计算得来的就可以, 这是一种非常高效的容错方式
RDD 是只读的
RDD 是只读的, 不允许任何形式的修改. 虽说不能因为 RDD 和 HDFS 是只读的, 就认为分布式存储系统必须设计为只读的. 但是设计为只读的, 会显著降低问题的复杂度, 因为 RDD 需要可以容错, 可以惰性求值, 可以移动计算, 所以很难支持修改.
- RDD2 中可能没有数据, 只是保留了依赖关系和计算函数, 那修改啥?
- 如果因为支持修改, 而必须保存数据的话, 怎么容错?
- 如果允许修改, 如何定位要修改的那一行? RDD 的转换是粗粒度的, 也就是说, RDD 并不感知具体每一行在哪.
RDD 是可以容错的
RDD 的容错有两种方式
- 保存 RDD 之间的依赖关系, 以及计算函数, 出现错误重新计算
- 直接将 RDD 的数据存放在外部存储系统, 出现错误直接读取, Checkpoint
1.2.3. 什么叫做弹性分布式数据集
分布式
RDD 支持分区, 可以运行在集群中
弹性
- RDD 支持高效的容错
- RDD 中的数据即可以缓存在内存中, 也可以缓存在磁盘中, 也可以缓存在外部存储中
数据集
- RDD 可以不保存具体数据, 只保留创建自己的必备信息, 例如依赖和计算函数
- RDD 也可以缓存起来, 相当于存储具体数据
总结: RDD 的五大属性
首先整理一下上面所提到的 RDD 所要实现的功能:
- RDD 有分区
- RDD 可以通过依赖关系和计算函数进行容错
- RDD 要针对数据本地性进行优化
- RDD 支持 MapReduce 形式的计算, 所以要能够对数据进行 Shuffled
对于 RDD 来说, 其中应该有什么内容呢? 如果站在 RDD 设计者的角度上, 这个类中, 至少需要什么属性?
-
Partition List分片列表, 记录 RDD 的分片, 可以在创建 RDD 的时候指定分区数目, 也可以通过算子来生成新的 RDD 从而改变分区数目 -
Compute Function为了实现容错, 需要记录 RDD 之间转换所执行的计算函数 -
RDD DependenciesRDD 之间的依赖关系, 要在 RDD 中记录其上级 RDD 是谁, 从而实现容错和计算 -
Partitioner为了执行 Shuffled 操作, 必须要有一个函数用来计算数据应该发往哪个分区

二、RDD 的算子
分类
RDD 中的算子从功能上分为两大类
-
Transformation(转换) 它会在一个已经存在的 RDD 上创建一个新的 RDD, 将旧的 RDD 的数据转换为另外一种形式后放入新的 RDD
-
Action(动作) 执行各个分区的计算任务, 将的到的结果返回到 Driver 中
RDD 中可以存放各种类型的数据, 那么对于不同类型的数据, RDD 又可以分为三类
-
针对基础类型(例如 String)处理的普通算子
-
针对
Key-Value数据处理的byKey算子 -
针对数字类型数据处理的计算算子
特点
-
Spark 中所有的 Transformations 是 Lazy(惰性) 的, 它们不会立即执行获得结果. 相反, 它们只会记录在数据集上要应用的操作. 只有当需要返回结果给 Driver 时, 才会执行这些操作, 通过 DAGScheduler 和 TaskScheduler 分发到集群中运行, 这个特性叫做 惰性求值
-
默认情况下, 每一个 Action 运行的时候, 其所关联的所有 Transformation RDD 都会重新计算, 但是也可以使用
presist方法将 RDD 持久化到磁盘或者内存中. 这个时候为了下次可以更快的访问, 会把数据保存到集群上.
2.1. Transformations 算子
| Transformation function | 解释 |
|---|---|
|
| 作用
签名 参数
注意点
|
|
| 作用
调用 参数
注意点
|
|
| 作用
|
| RDD[T] ⇒ RDD[U] 和 map 类似, 但是针对整个分区的数据转换 |
|
| 和 mapPartitions 类似, 只是在函数中增加了分区的 Index |
|
| 作用
|
|
|
作用
参数
|
|
| |
|
| 作用
|
|
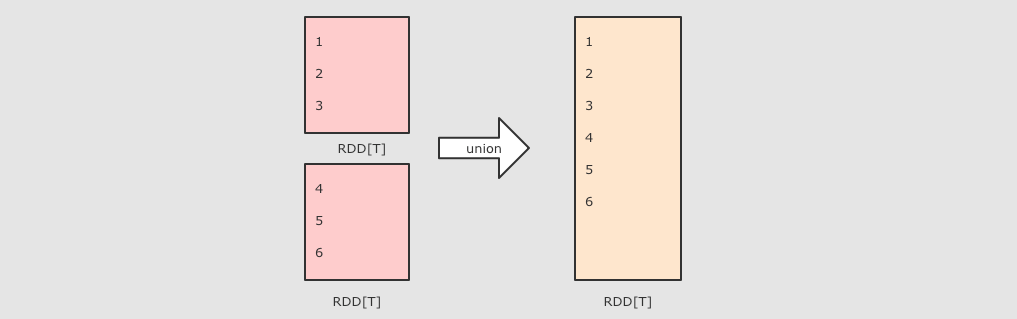
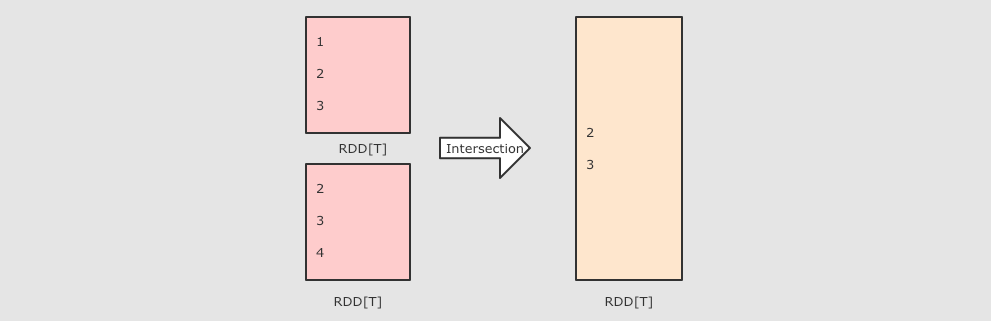
| (RDD[T], RDD[T]) ⇒ RDD[T] 差集, 可以设置分区数 |
|
| 作用
注意点
|
|
| 作
调用
参数
注意点
|
|
| 作用
注意点
|
|
| 作用
调用
参数
注意点
|
|
|
作用
调用
参数
注意点 * 为什么需要两个函数? aggregateByKey 运行将一个 和 reduceByKey 的区别:
|
|
作用
调用
参数
注意点
|
|
| 作用
调用
参数
注意点
|
|
| 作用
调用
参数
注意点
|
|
| (RDD[T], RDD[U]) ⇒ RDD[(T, U)] 生成两个 RDD 的笛卡尔积 |
|
| 作用
调用
参数
注意点
|
|
| 使用用传入的 partitioner 重新分区, 如果和当前分区函数相同, 则忽略操作 |
|
| 减少分区数 作用
调用
参数
注意点
|
|
| 重新分区 |
|
| 重新分区的同时升序排序, 在 |

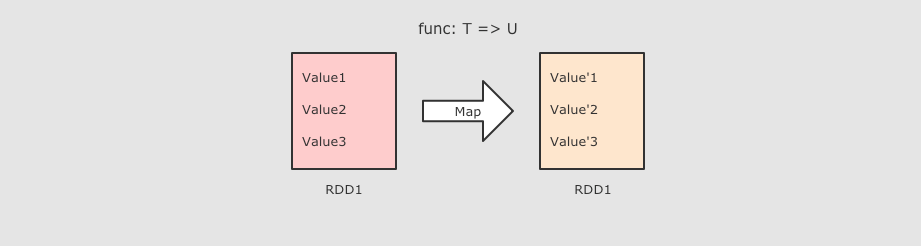
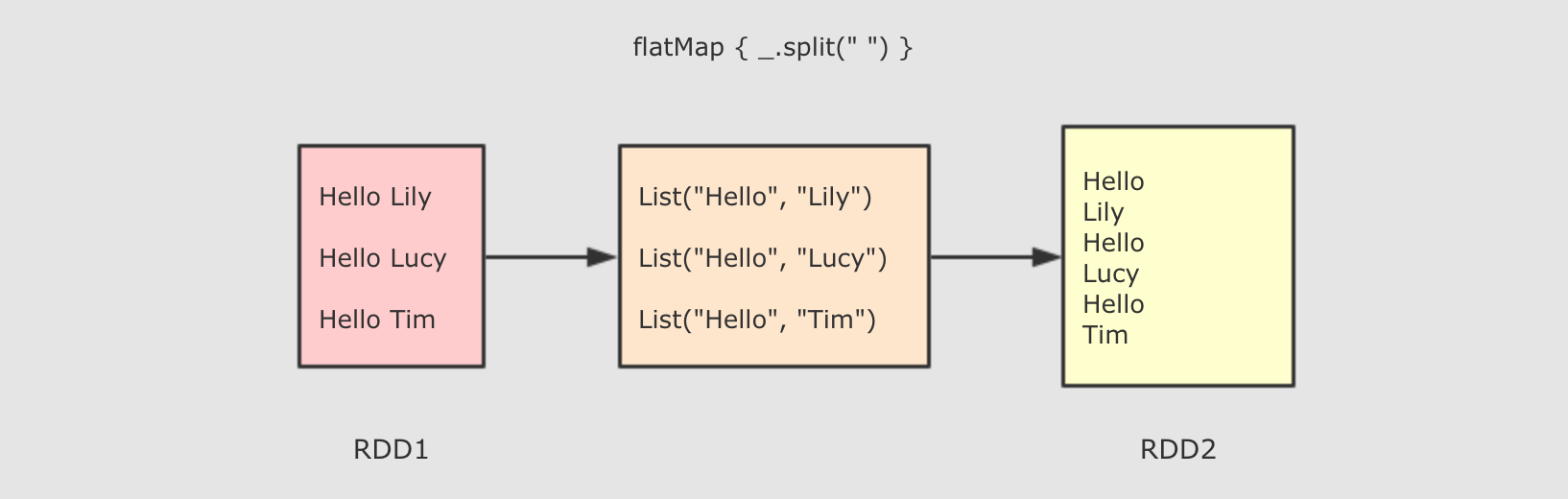

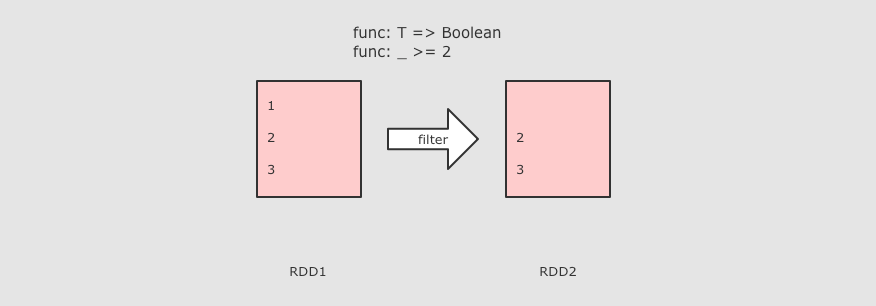
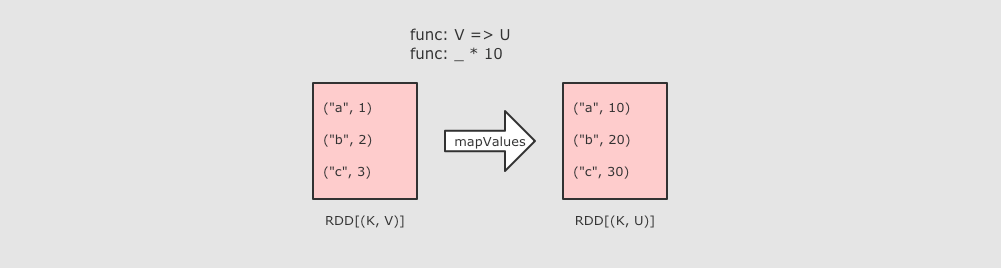





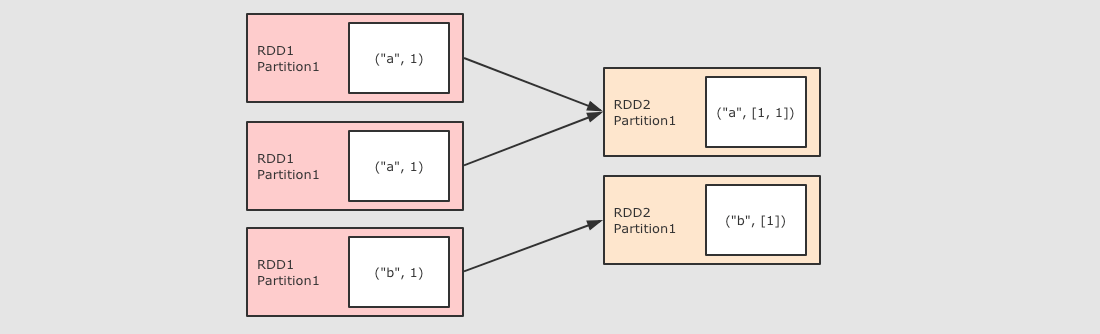


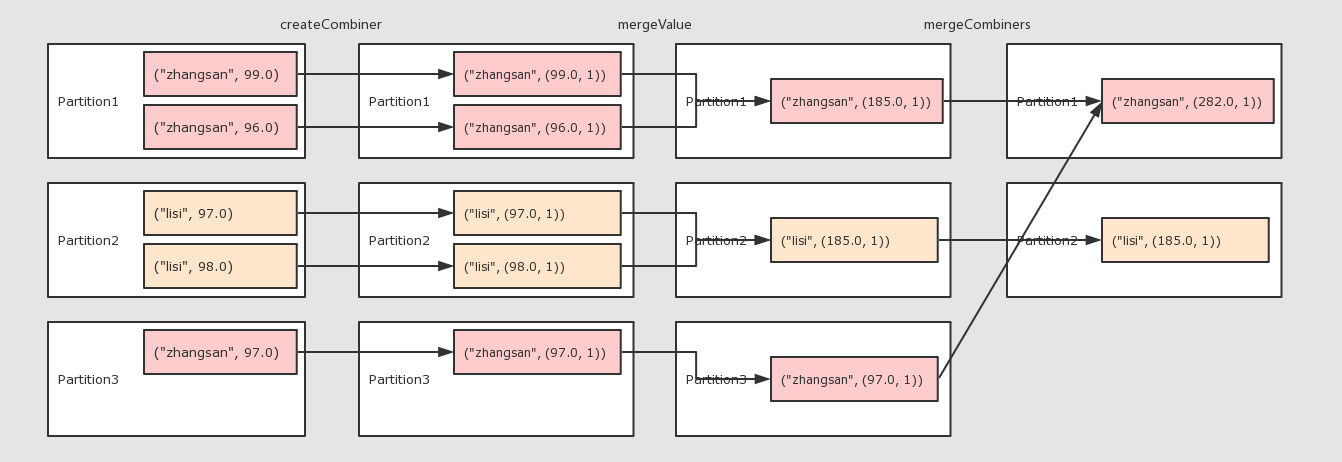

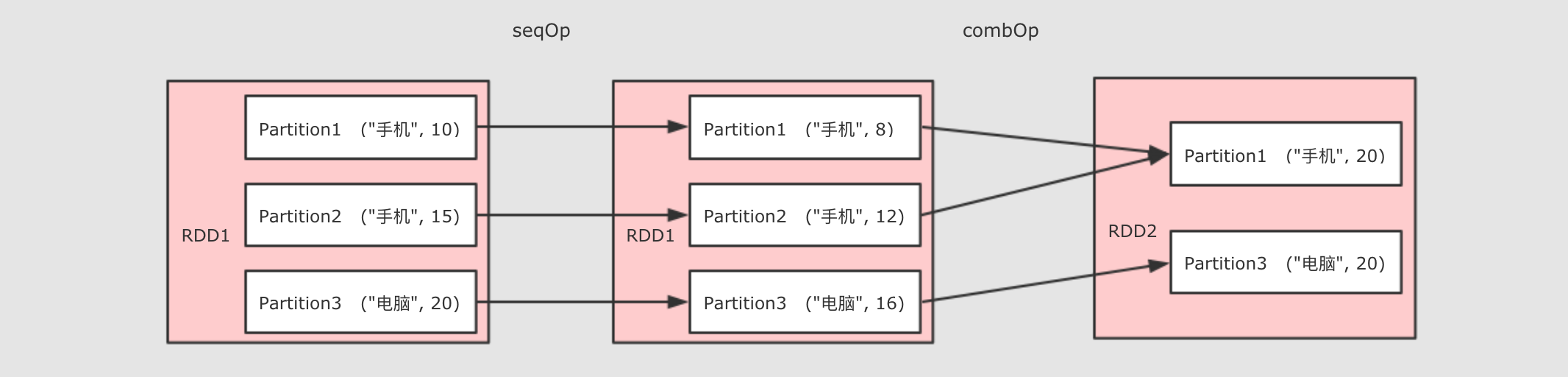

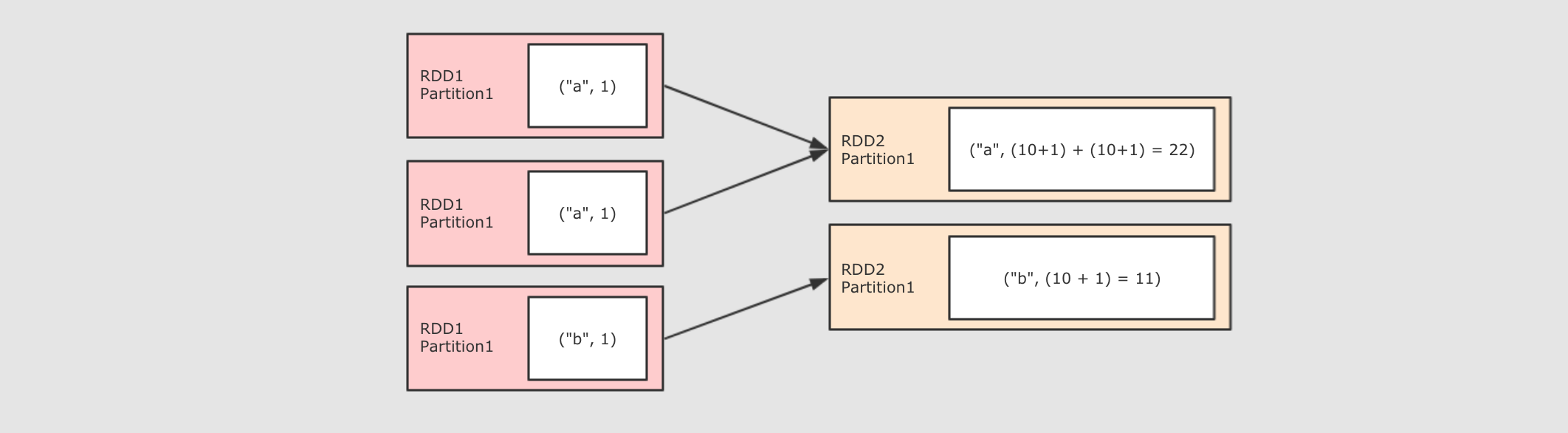
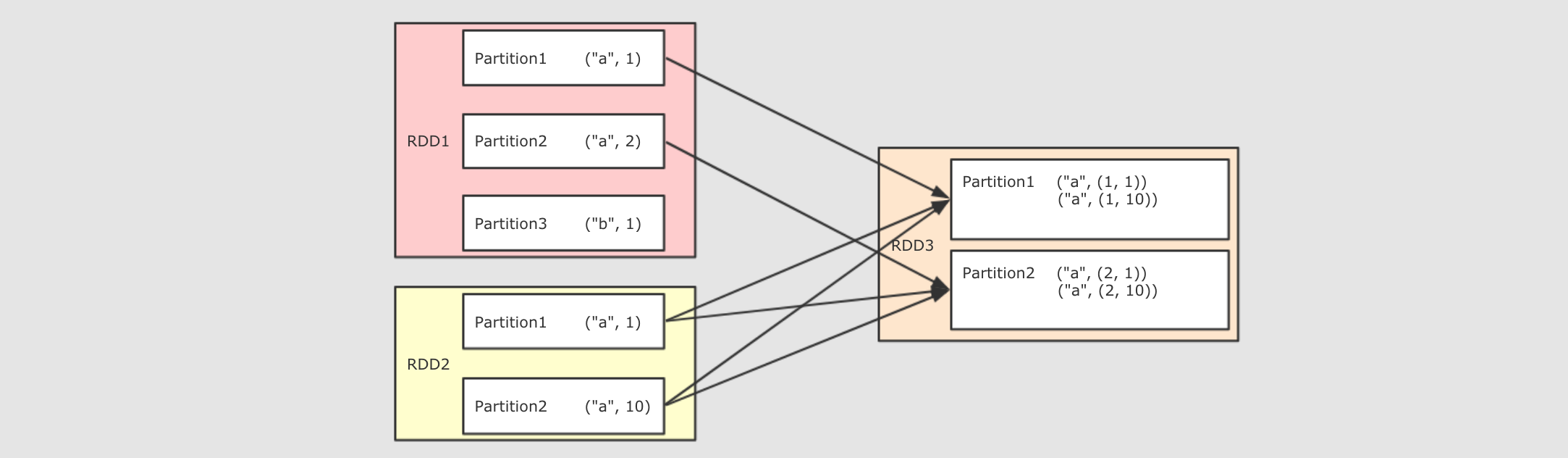

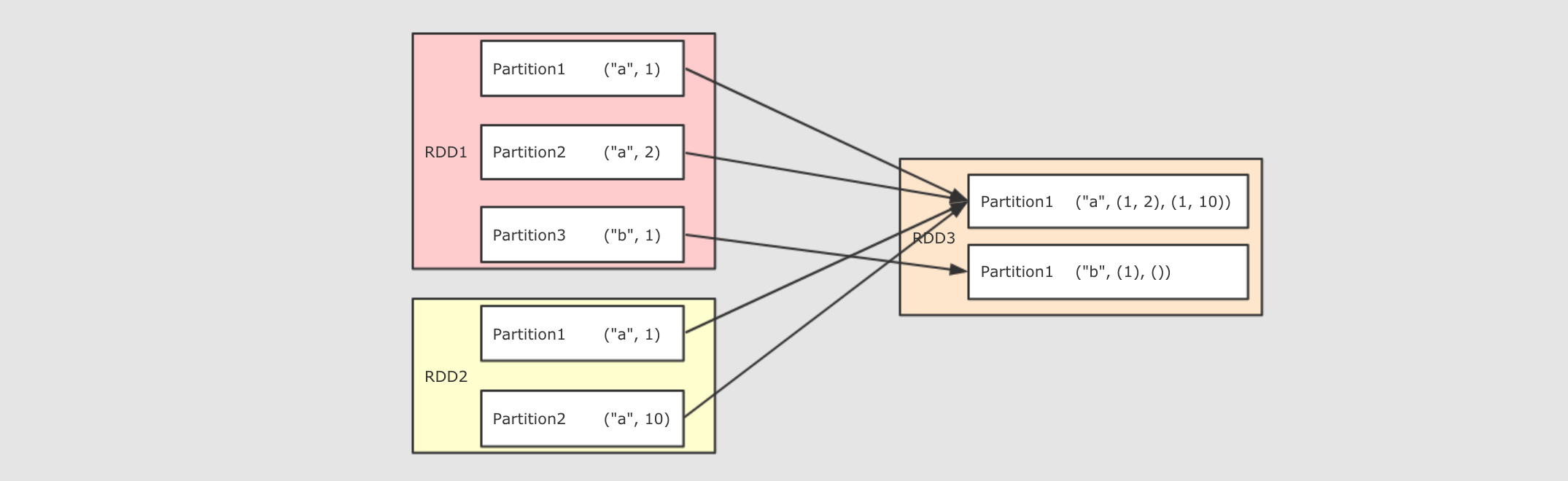
分区操作的算子补充:

2.2. Action 算子
| Action function | 解释 |
|---|---|
|
| 作用
调用
注意点
|
|
| 以数组的形式返回数据集中所有元素 |
|
| 返回元素个数 |
|
| 返回第一个元素 |
|
| 返回前 N 个元素 |
|
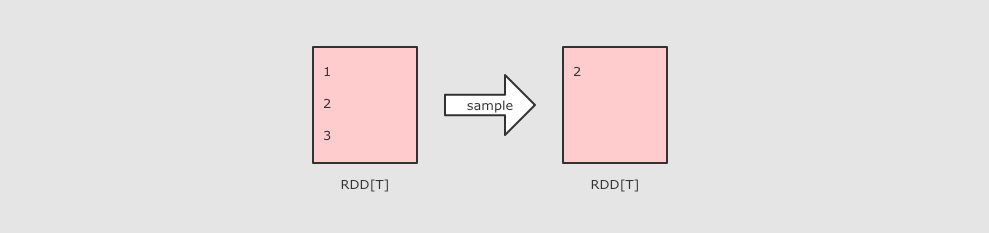
| 类似于 sample, 区别在这是一个Action, 直接返回结果 |
|
| 指定初始值和计算函数, 折叠聚合整个数据集 |
|
| 将结果存入 path 对应的文件中 |
|
| 将结果存入 path 对应的 Sequence 文件中 |
|
| 作用
注意点
|
|
| 遍历每一个元素 |
总结
RDD 的算子大部分都会生成一些专用的 RDD
map,flatMap,filter等算子会生成MapPartitionsRDD
coalesce,repartition等算子会生成CoalescedRDD常见的 RDD 有两种类型
转换型的 RDD, Transformation
动作型的 RDD, Action
常见的 Transformation 类型的 RDD
map
flatMap
filter
groupBy
reduceByKey
常见的 Action 类型的 RDD
collect
countByKey
reduce
2.3. RDD 对不同类型数据的支持
一般情况下 RDD 要处理的数据有三类
- 字符串
- 键值对
- 数字型
RDD 的算子设计对这三类不同的数据分别都有支持
- 对于以字符串为代表的基本数据类型是比较基础的一些的操作, 诸如 map, flatMap, filter 等基础的算子
- 对于键值对类型的数据, 有额外的支持, 诸如 reduceByKey, groupByKey 等 byKey 的算子
- 同样对于数字型的数据也有额外的支持, 诸如 max, min 等
2.3.1RDD 对键值对数据的额外支持
键值型数据本质上就是一个二元元组, 键值对类型的 RDD 表示为
RDD[(K, V)]RDD 对键值对的额外支持是通过隐式支持来完成的, 一个
RDD[(K, V)], 可以被隐式转换为一个PairRDDFunctions对象, 从而调用其中的方法.
既然对键值对的支持是通过
PairRDDFunctions提供的, 那么从PairRDDFunctions中就可以看到这些支持有什么
类别 算子 聚合操作
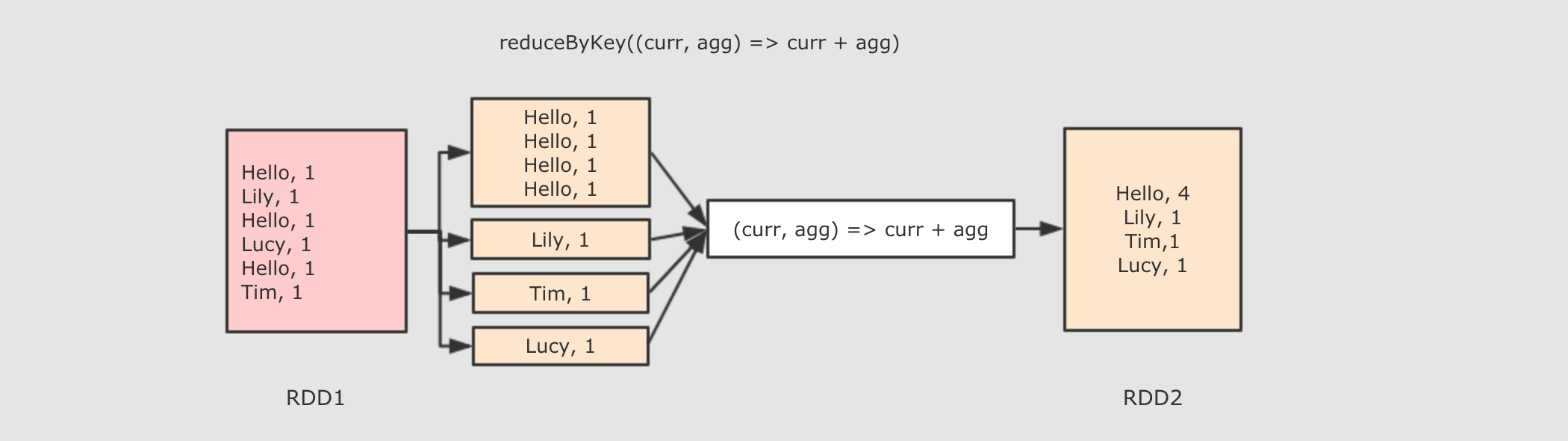
reduceByKey
foldByKey
combineByKey分组操作
cogroup
groupByKey连接操作
join
leftOuterJoin
rightOuterJoin排序操作
sortBy
sortByKeyAction
countByKey
take
collect

2.3.2RDD 对数字型数据的额外支持
对于数字型数据的额外支持基本上都是 Action 操作, 而不是转换操作
算子 含义
count个数
mean均值
sum求和
max最大值
min最小值
variance方差
sampleVariance从采样中计算方差
stdev标准差
sampleStdev采样的标准差

