
- 1ComfyUI中使用 SD3 模型(附模型下载详细说明)_comfyui sd3
- 2ChatGLM4重磅开源! 连忙实操测试一波,效果惊艳,真的好用!_chatglm4 开源发布时间
- 310款国内可用的AI工具分享,每一款都能让你工作效率翻倍_魔术todo任务分解
- 4普通人也能搞的,0成本,热门副业AI绘画,月入1w+_2024年0成本如何日入10000
- 5聚类模型的算法性能评价
- 6NLP综述:知识脉络图、四大类任务【序列标注(分词、词性标注、NER)、分类任务(文本分类、情感分析)、句子关系判断(顺序判断、相似度计算)、生成式任务(机器翻译、问答 、文本摘要)】_图书馆nlp标注 脉络洞察
- 7百度云不限速客户端让你获取SVIP速度_加速链接获取中啥意思
- 8C++11 智能指针详解_c++ 11所有的智能指针
- 9大模型入门指南:基本技术原理与应用_大模型原理
- 10Kafka和Spark Streaming的组合使用学习笔记(Spark 3.5.1)_2. kafka和structured streaming组合使用 (1)编写生产者程序每1秒生成一
ElasticSearch下载安装配置及其使用(windows)
赞
踩
一、ELK
一般情况下 ElasticSearch 并不单独使用。ElasticSearch、Logstash、Kibana这三个技术就是我们常说的ELK技术栈。Logstash负责搜集和过滤数据,ElasticSearch负责存储数据,Kibana拥有各种维度的查询和分析,并使用图形化的界面展示存放ElasticSearch中的数据。
二、ElasticSearch版本选择
在使用ElasticSearch的时候,要注意版本的选择,在后续ElasticSearch和SpringBoot整合的时候,版本之间是有影响的。Spring官网对版本对应关系也做了说明,下面链接是关系对应表
我选用的是ElasticSearch7.15.2版本。要注意如果ElasticSearch版本选择了7.15.2,则后续的ik分词器和Kibana版本也要对应为7.15.2
2.1、ES默认规则
ES全文检索默认分词器为standard analyzer。在standard analyzer中,character Filter什么也没有做,Token Filter只是把英文大写转化为小写。
2.2、IK分词器
ES常见的几种分词器
| 分词器 | 分词方式 |
| StandardAnalyzer | 单字分词 |
| CJKAnalyzer | 二分法 |
| IKAnalyzer | 词库分词 |
分词器作用是把一段中文或者别的划分成一个个的关键字或词,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词,比如“我爱中国"会被分为"我"“爱”“中”"国”,这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。
ik分词器提供了两种分词算法:ik_smart和ik_max_work,其中ik_smart是最少切分,ik_max_work是最细粒度划分。
2.3、ElasticSearch下载安装和配置

下载的时候同时下载Kibana,后续使用。
下载解压后目录如下:
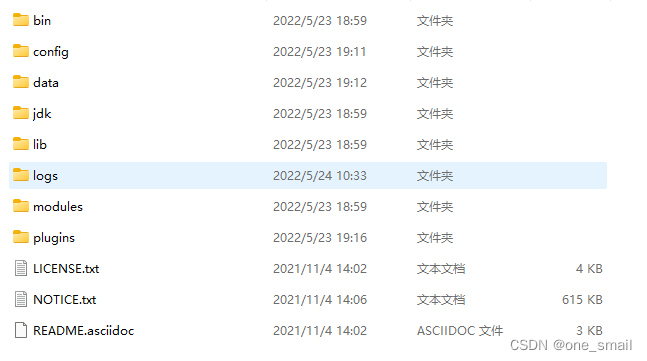
主要说明config和bin目录,bin目录中存放启动文件,config中存放配置文件。config下的文件:
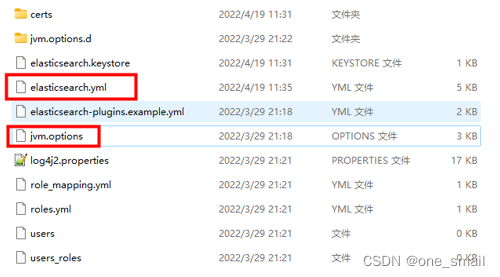
jvm.options中可以配置jvm运行参数,如果服务器过小,对应的需要下调参数。版本不同,默认的jvm参数有所不同。
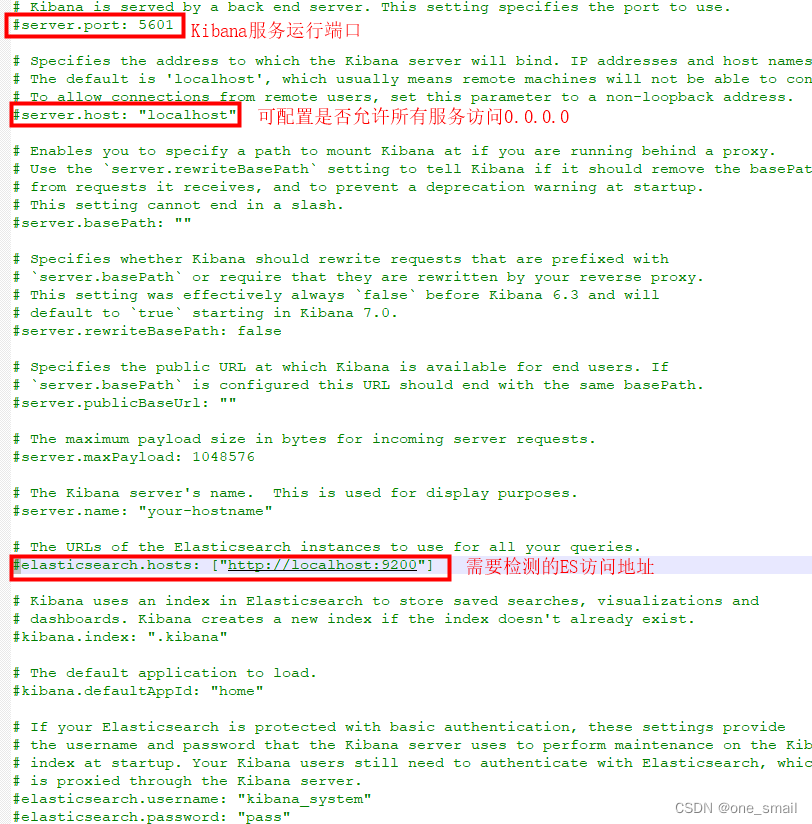
Elasticsearch.yml配置文件中可进行端口、是否允许外部访问、端口等的设置。其中:
path.data:指定数据存储位置
path.logs:指定日志存储位置
http.port:指定运行端口
需要注意的是,在elasticserach8版本开始,项目首次启动后,配置文件会自动出现关于ssl相关的配置,如果是本地开发使用,没有ssl相关配置的情况下,需要将配置xpack.security.enabled的值修改为false,否则服务启动后,无法访问。
配置完成后,双击bin目录下的elasticsearch.bat即可启动。
2.4、IK分词器安装
下载地址:
https://github.com/medcl/elasticsearch-analysis-ik![]() https://github.com/medcl/elasticsearch-analysis-ik
https://github.com/medcl/elasticsearch-analysis-ik
注意版本信息要与ElasticSeatch保持一致
下载后解压到ElasticSearch解压目录下的plugins文件夹下,需要注意的是,注意目录结构,ik分词器解压包解压后如果没有父级目录,则需要在plugins下先创建一个服务目录,用于存放ik分词器的解压文件

在plugins文件夹下创建一个新的文件夹,用于存放ik分词器解压文件

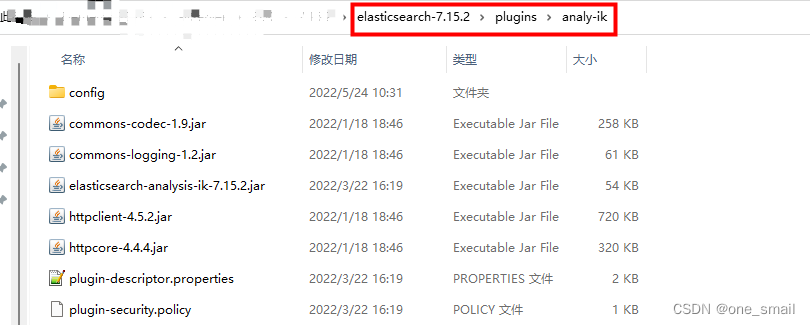
重新启动ElasticSearch,查看ik分词器是否安装成功
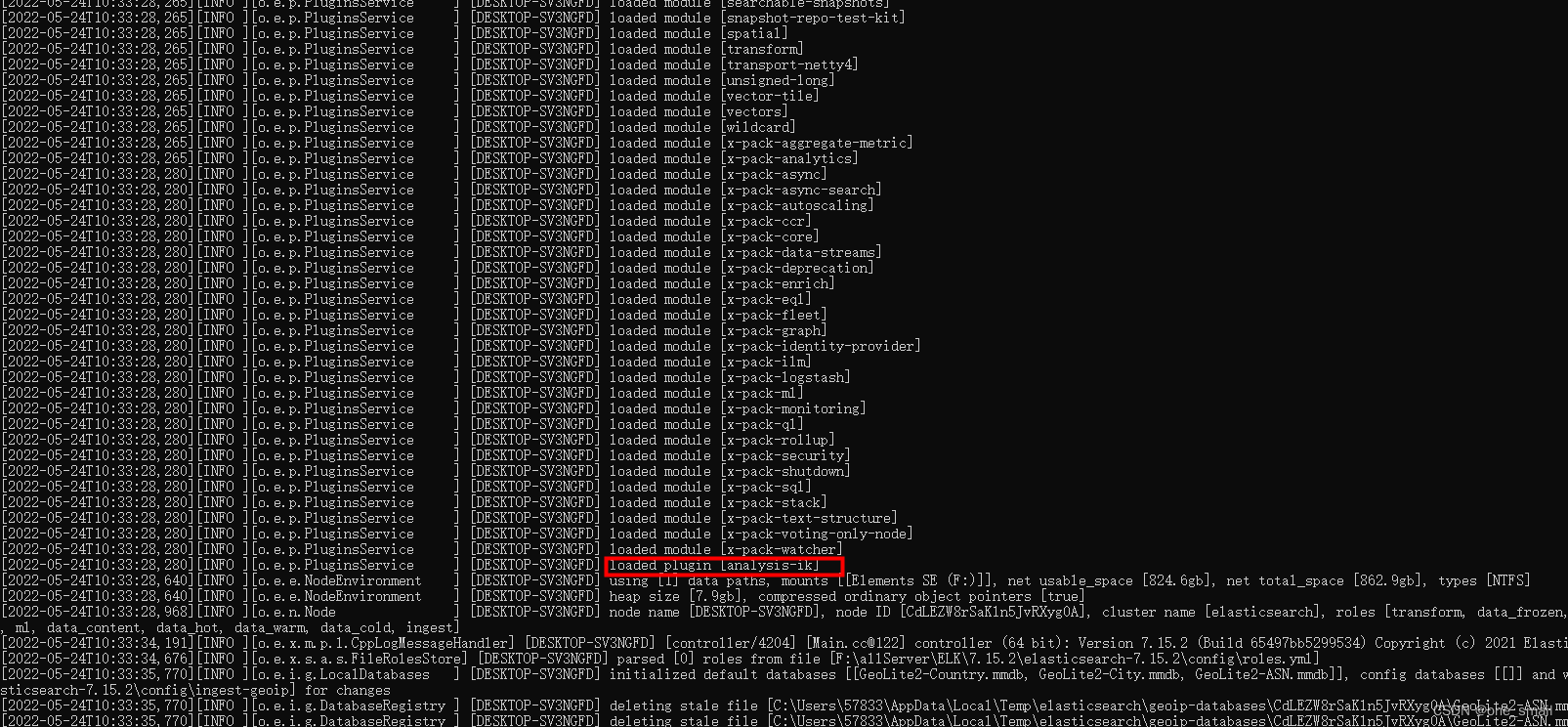
2.5、Kibana安装配置
解压下载好的Kibana安装包,注意版本号和ElasticSearch保持一致。解压后的config目录下的kibana.yml为配置文件
解压目录下bin文件夹下的kibana.bat为启动文件,双击即可启动。
启动后访问Kibana地址:
http://localhost:5601/![]() http://localhost:5601/
http://localhost:5601/
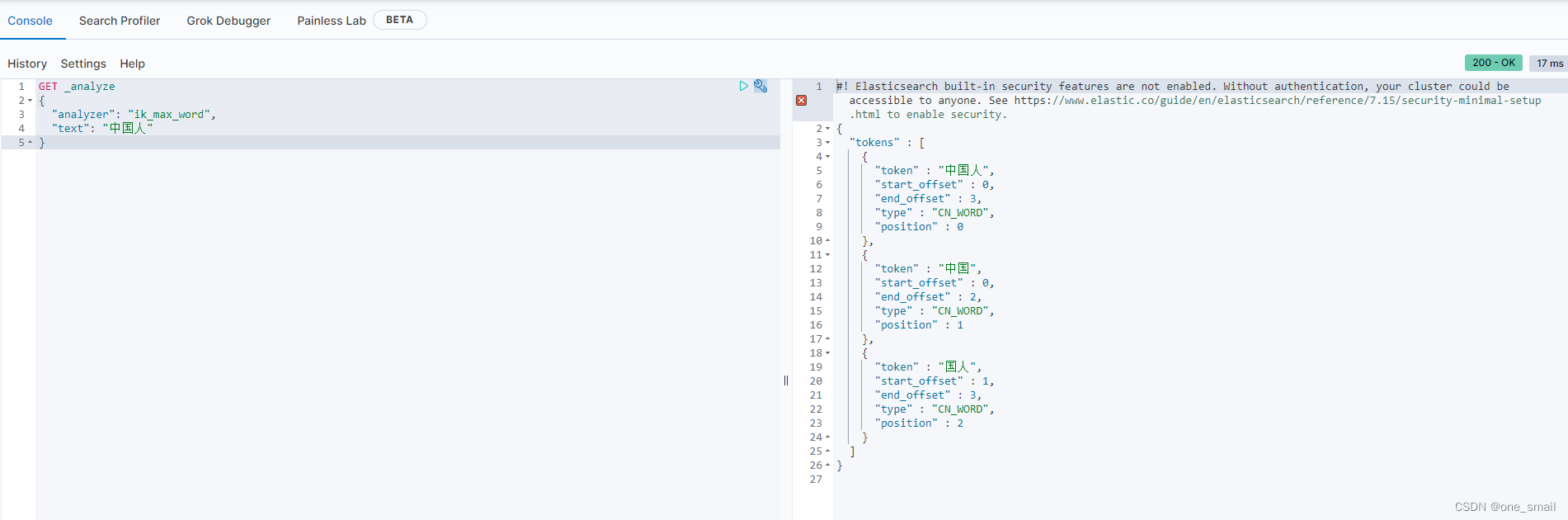
启动后选择Dev Tolls
在控制台编写分词请求,即可进行测试
三、词典扩展
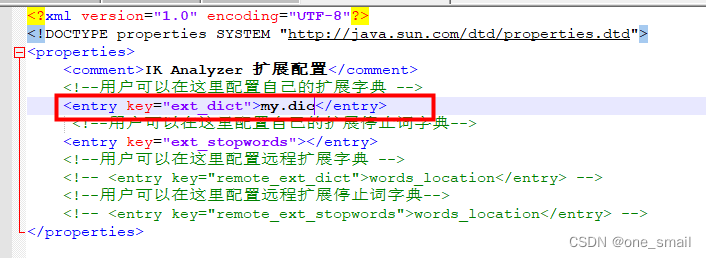
我们在使用ik分词器对内容分词后,如果没有得到自己想要的分词结果,则可以配置自己的扩展字典。就是在IK分词器中加入我们自定义的字典,在词典中加入想要的词
在ik分词器文件的config目录中新建自定义的字典文件,以.dic为后缀,并在文件中加入自定义的词



重新启动ES和Kibana,在用分词器对内容进行分词,此时自定义的词语就会出现

