
- 1每日一题:C语言经典例题之韩信点兵_c语言韩信点兵问题
- 2golang办公流程引擎初体验js-ojus/flow——系列四_flowprovider golang demoflow
- 3Zookeeper是什么
- 4K8S彻底卸载教程_卸载kubelet
- 5Window环境下mysql读写分离以及主从配置(不错可以的)_window mysql如何读写分离教程
- 6链表C++详解(知识点+相关LeetCode题目)_c++链表
- 7推荐一个在线stable-diffusion-webui,通过文字生成动画视频的网站-Ai白日梦_stablediffusion在线生成
- 8Qwen-14B Ai新手部署开源模型安装到本地_qwen本地部署
- 9静态IP代理哪个好用?_哪家的静态ip好
- 10大型语言模型 (LLM) 的系统消息框架和模板建议_llm下的智能客服的系统架构
MatrixOne:HTAP 数据库中的 OLAP 设计_htap olap
赞
踩
导读:矩阵起源是一家数据库创业公司,致力于打造开源超融合异构数据库 MatrixOne。MatrixOne 是一款面向未来的超融合异构云原生数据库管理系统。通过全新设计和研发的统一分布式数据库引擎,能够同时灵活支持 OLTP、 OLAP、Streaming 等不同工作负载的数据管理和应用,用户可以在公有云、自建数据中心和边缘节点上无缝部署和运行。
Github:https://github.com/matrixorigin/matrixone
本文将分享 MatrixOne 在 OLAP 方面的设计和实现。主要内容包括以下两大部分:
-
MatrixOne 整体架构
-
MatrixOne OLAP 引擎
第一部分:MatrixOne 整体架构
MatrixOne 早期的架构是一个典型的 share nothing 架构,数据存放在一个 Multi Raft 集群上面,数据的每一个切片存在一个 Raft 上面,不同的 Raft Group 之间的数据是完全没有重叠的。
早期架构存在着一些无法解决的问题,比如在扩展性上,每扩展一个节点,就需要同时扩展存算的资源,因为计算和存储没有完全分开。而且每扩展一个节点,需要大量的数据迁移工作。另外因为每一份数据都要保存至少 3 个副本,从扩展节点到完成的时间会非常久。在性能方面,Raft 协议所包含的 leader 角色,容易造成热点;在性能较差的存储下,数据库整体性能下降会超过预期;多种引擎各自用途不同,性能各异,无法有效应对 HTAP 场景。成本方面,数据保存 3 副本,随节点规模增长,成本不断攀升,云上版本更甚;只有高配存储才能发挥数据库的预期性能。
为了更好地满足客户的需求,我们升级了新的架构。
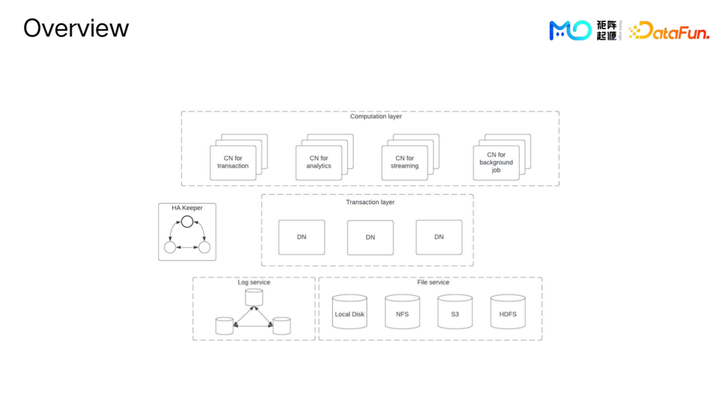
升级后的架构从整体上看,分为三个部分:
-
最上面是计算层,计算层里面的每一个单位是一个 Compute Node (CN) 计算节点。
-
在计算层下面是数据层,由 Data Node (DN) 组成。
-
再下面是 File service,支持各种不同的文件系统。
下面分别详细介绍一下每一部分。
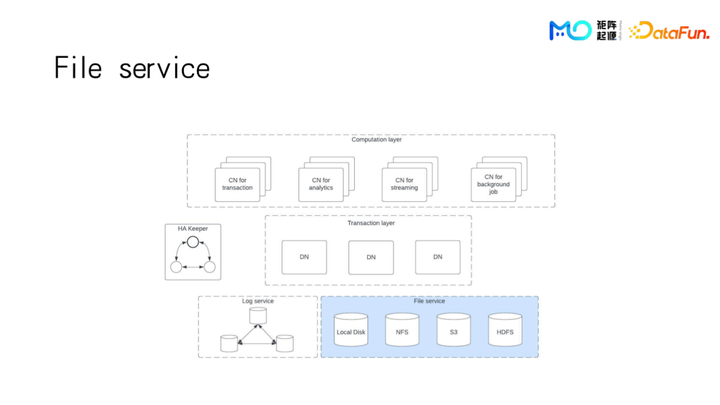
先从最底下的 File service 说起。File service 支持各种不同的文件系统,比如用户自己的本地的磁盘,NFS、HDFS、或者对象存储。File service 对上层提供一个统一的接口,对用户来说,他并不需要关心最底下的数据本身是存在什么样的介质上面。

这边还会有个 log service,因为我们知道在 file service 插入数据的时候,只能一整块一整块地写,尤其像 S3,一个 object 非常大,不可能一行一行地写,一般是积累到一定的量再往里面写一个整块,那么这些还没形成整块的部分,会放在一个单独的 log service 里面。log service 是一个 Multi Raft 的集群。已经形成整块的部分的数据完整性和一致性是用 S3 或者 HDFS 的功能来保证。还没有形成单个 block 的数据的一致性完整性则是通过 Multi Raft group 来保证。
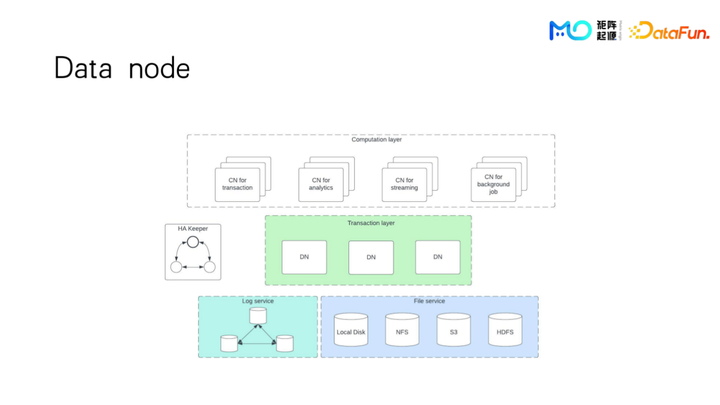
再上面是存储节点 DN,存储节点里只存放的是元数据信息,比如每个表会分成大的 segment,每个 segment 又会分成很多小的 block。比如用 S3 来存放数据,元数据里会存放每个 block,存放对应的具体 S3 object。还有其他元数据信息比如 row map,或者是次级索引 bloom filter 这些信息也会存在 DN 上。这里可以看到有多个 DN,它们是怎么分布的呢?比如一张表有一个主键,那么我们可以根据主键来做一个分区,目前是按 hash 来做分区,也可以按 range 来做都是没有问题的。对于数据规模较小的客户来说,存放元数据其实只需要一个 DN 就足够了。

再上面就是计算节点 CN,具体执行计算任务的节点。CN 可以分成各种不同类型,比如专门做 TP 查询用的,专门做 AP 查询用的,专门做 streaming 用的,还有一些对用户不可见的数据库自己后台的一些任务。
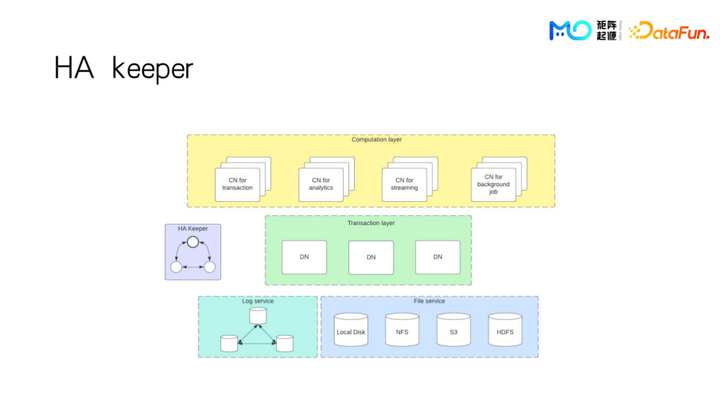
还有一个组件叫 HA Keeper,跟 ZooKeeper 功能类似,在节点之间互相通知上线下线这些信息,维护整个集群的可用信息。
新的 share storage 的架构优势在于:
1. DN 节点不保存任何数据,只保存元数据信息。这样就不会让单个 DN 成为瓶颈,如果需要做弹性扩缩容,比如 DN 要新增或者删除一个节点。做数据迁移只需要交换一些元数据的信息,不需要把所有数据都做搬迁的操作,这大大简化了数据迁移量,并提高了扩缩容的效率。
2.完整性和一致性主要是通过 S3 来保证,S3 本身就具备这一功能,并且从成本上来看也是非常低的,比用户自己去搭建 Multi Raft 集群的成本会低很多。
3.计算任务也可以很好地分离开,比如 TP 和 AP 的计算,可以放在不同的 CN 节点上去做。因为现在数据已经不跟 DN 绑定在一起,所以计算的节点也可以完全解耦。
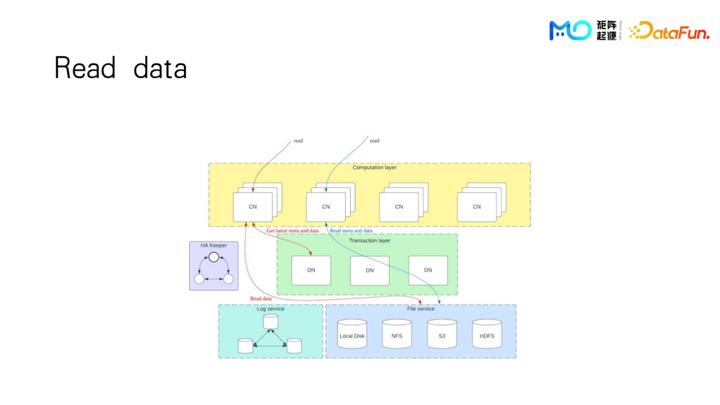
我们来看一个典型的查询里面读数据的操作是怎样的。数据查询从一个 CN 节点开始,首先去访问 DN 的信息,读取元信息,判断某张表在哪些 block,甚至会先通过过滤条件用 row map 来做过滤,剩下的是实际上需要去读的那些 block 信息,拿到之后直接去那个 file service 下面去读取数据。
在这里 DN 节点只提供了元数据信息,基本上不会成为性能瓶颈。因为更多的数据是 CN 节点去直接向 File service 读取的,CN 节点上面还会维护一个 metadata cache。假设这个数据新鲜度还没有过期,甚至可以不需要访问 DN,直接去 File service 下面拉取数据。
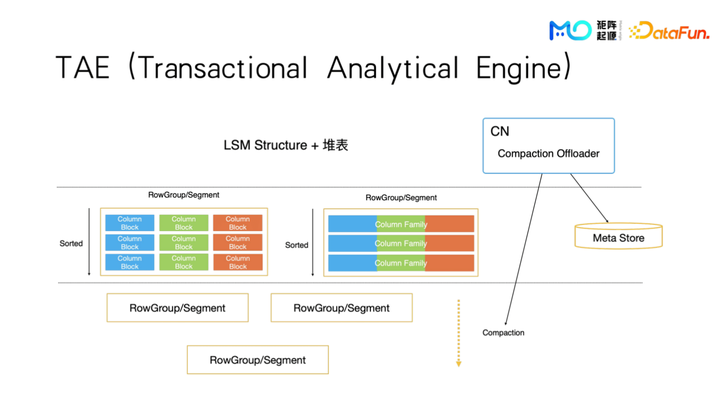
最后是存储引擎,TAE,T 和 A 分别是指 TP 和 AP,T 和 A 表示它既有事务的能力也可以很好的处理分析性查询,用同一套引擎同时支持 AP 和 TP。
在结构上,我们实际上还是可以把它看成是基于列存,不同的列之间,数据仍然是单独分开存放的,每一列会按照 8192 行分成一个小的 block。对于大多数的数字类型的 block,8192 行数据可以在 L1 cache 里面直接装下,在后面的批量计算的时候会对计算引擎比较友好。多个 block 会组成一个 segment,segment 的作用是假设这个表它有主键或者排序键的情况下,一个 segment 内部会通过排序键和主键去做排序,这样数据存储在每一个 segment 内部是保持有序的,但 segment 之间可能会有重叠。这跟 LSM 的存储有些相似的地方。但如果我们之后做了 partition 功能,可能会把一个 partition 内的所有 segment 也去做一次 compaction 操作。即把它们重新拿出来,做一个归变排序再放进去。
以上就是 MatrixOne 最新的架构。
第二部分:MatrixOne OLAP 引擎
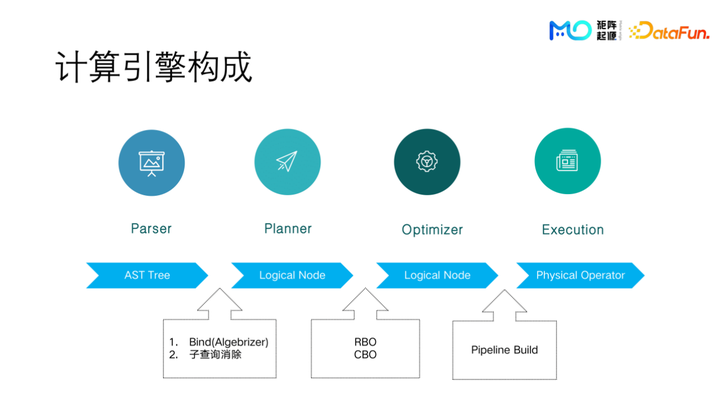
MatrixOne 的计算引擎分为四个部分:
-
第一个是 parser:把一个 SQL 语句解析成一个 AST 树。
-
第二个是 planner: 把 AST 树转化成一个逻辑计划。
-
第三个是 optimizer: 把逻辑计划通过各种优化器规则或者是通过一些基于代价估算的方式转化成更好的逻辑计划。
-
最后是 execution:把具体的逻辑计划转化成可执行的 pipeline,然后去具体的 CPU 上面执行。
语法解析器(Parser)
各大开源数据库大多都不会去手写一个 parser,至少是用 MySQL 或者 PG 的 parser。比如 DuckDB 就是直接使用 Postgres 的 parser 代码。即使我们不直照搬,也可以用一些 YACC 的工具去生成一个 parser。测试之后发现用 YACC 生成的 parser,并不会成为性能瓶颈,它的耗时非常少,所以我们没有必要去手写一个 parser。(除了 ClickHouse 的 parser 是手写的)。parser 生成 AST 树之后,会通过逻辑计划器,把 AST 树转换成一个可以执行的逻辑计划。
逻辑计划器(Planner)
逻辑计划器主要包含两个部分: Bind(Algebrizer) 和子查询消除。因为我们并不支持像 SQL Server 一样将子查询转换成 apply join,或者像 MySQL 一样完全从父查询里面拿出一行,再带入子查询里面,把子查询完整地执行一次。考虑到在 AP 查询的场景,这样的一个执行计划是不可接受的,就干脆完全不支持这种 apply join 的方式,所以我们在 planner 这一步,把子查询的消除给做掉。
优化器(Optimizer)
优化器部分,通常会有一个 RBO 基于规则的优化,基于规则对大部分查询已经是够用的。因为优化器通常分为两种,一种是减少数据 IO,它会减少实际从磁盘文件系统读取的数据量;还有一种是对于 CPU,在计算的过程中减少计算的代价。下面会具体举一些例子来说明 MatrixOne 是如何设计的。

第一部分是减少 IO,包括:
-
列裁剪,读一张表,有很多列,但我实际上只用到其中一列,那么其它列是不用读取的。
-
谓词下推,就是把一些过滤条件直接推到读取数据这一部分,这样可以尽量少的读取数据。
-
谓词推断,主要会影响 TPC-H 里面的 Q7 和 Q19,在后面会再举例详细介绍。
-
Runtime filter ,比如大表跟小表做 join 操作,在小表构建完 hash 表之后,可能 hash 表的计数非常小,这样我们可以直接通过 hash 表里面不同的词去大表里面通过 runtime 或者元数据信息进行过滤,这样在运行时就大大减少了需要读取的大表的 block 数量。

第二部分是减少计算。它并不能减少实际从磁盘里面读取的数据,但是会在计算过程中减少计算量,和减少中间结果的数据量:
1.join order 的 join 定序。通常使用 TPC-H 做 OLAP 的 benchmark,join order 会影响很多不同的查询,如果 join order 做的不好,这些查询都可能会以数量级的变慢。
2.聚合函数下推和上拉的操作。假设聚合函数是在一个 join 上面,如果是先做 join,之后再去做聚合,那么在 join 这里,数据可能会膨胀的非常多。但是如果可以把聚合函数推到 join 下面去做,即在 join 之前先聚合,数据已经减少很多,这也可以大大的减少计算。

简单介绍谓词推断。谓词下推是已经确定显式的可以下推的一个位置。但谓词推断可能是需要做一些逻辑上的变化之后,才能得到一些新的谓词,这些新的谓词才可以下推下去。比如 TPC-H Q19 的过滤条件是三个很长的谓词用 or 连接起来,通过观察实际上这三个 or 里面有很多共同的部分,可以把共同的部分提取出来,变成右图的样子。可以观察到,首先 part 这张表上面有一个可以下推的谓词,lineitem 这张表上面也有两个可以下推的谓词。这样可以先把这两个谓词下推到每个表的 table scan 上面去。然后还多出来一个在 part 和 lineitem 上面用主键做连接的谓词。如果原来不对这个执行计划做优化直接去执行,可能会先做一个笛卡尔积,再去做过滤操作,这样的效率会非常低。现在我们可以把它变成一个 join 操作。

简单介绍一下 MatrixOne 使用的 join order 算法。在各大开源数据库上,join order 的算法实现主要包括贪心法和动态规划。其中动态规划有很多不同方法,也有很多论文可以参考。但是动态规划存在一个问题,当表的数量稍微多一些,状态搜索空间就会以指数级膨胀。比如 StarRocks 的文档里面提到过,10 个表以上的计算就没办法使用动态规划来计算,只能使用贪心法来计算。
我们在 MatrixOne 里对这个问题做了思考,在大于 10 张表时,可以先用贪心的方法来做一个剪枝操作,让搜索空间大大减小,在贪心法之后再做动态规划。
贪心法分三步:
1.第一步是确定事实表和维度表,因为一般的 OLAP 查询的数据通常会把表分成事实表和维度表,之间用维度表的主键做 join。因此拿到一个查询之后,我们可以把事实表和维度表给找出来。
2.下一步事实表先与其维度表 join 成子树,因为事实表维度表之间始终是通过维度表的主键去做 join。做这样的 join 的结果的函数始终是不大于他本来输入的函数,所以做这么一个 join 并不会造成很多 OLAP 开销,不会造成数据膨胀。在做事实表维度表 join 的过程中,我们会考虑事实表先与过滤性好的维度表做 join。就优化器而言,越早减少数据量是越好的。
3.最后一步是在子树之间,像 TPC DS 的表,会有多个维度表,维度表互相之间都不是以主键来做 join。那么在子树之间,我们再使用经典的 join order 的算法,比如动态规划等等。
这样我们把 Join order 的算法从之前只能 10 表以下做动态规划,扩展到 10 个事实表之下都可以使用动态规划来做。

举个例子,TPC-H Q5 中有 customer、 orders、lineitem、supplier、nation、region 这么六张表,它是一个比较典型的星型结构。

我们将 orders 和 region 这两个表标红,因为它们上面有过滤条件,需要单独考虑。然后对于本身的 join 条件,标上一些带箭头的线。这里从事实表到维度表,用维度表的主键做 join 的条件。可以看出,一共有 5 个条件都是用主键来做 join,其中还有比较特殊的一个条件,用画的虚线标记,它的两边互相都不是用主键来做的 join。
这个 join 算法下一步还会有一个联合优化,最后可以跟谓词推断联合使用,形成一个新的优化。因为可以看到 supplier 和 customer 有一个 join 条件,supplier 跟 nation 也有一个 join 条件,用的都是同一个类型 T 来做决定。我们可以推导出来 nation 和 customer 表之间是以类型 key 做为 join 的条件,因此我们用黄色的选项表示。
最后实际生成的最优的 join 顺序是从 region 开始,先跟 nation 表 join,再跟 customer 表 join,再跟 orders 表 join,再和 lineitem 表 join,最后跟 supplier 表 join。这是我们新推断出来的条件。那么为什么是走这么一个路线,而不是先把上面这一条路 join 完成后再 join 下面这边的表,是因为我们考虑到 orders,region 这两张表都有过滤条件,放在一起过滤效果会更好。这样会让 lineitem 这张表的行数减少的速率更快。
执行器(Execution)
最后是执行器部分,从逻辑计划转化到实际可执行的 pipeline,执行器的好坏对 OLAP 系统的执行效率影响是非常大的,下面会做详细介绍。

众所周知,执行器有一个经典的火山模型。对于每一行它是一个典型的 pull 模型,从最上层的计算的 operator 开始,每次调用一个 NEXT 函数从下面的节点去拿一行新的数据出来,做完计算之后,再等待更上层的那个计算节点去调用 next 从它这里取走。
火山模型存在一些问题,首先它并没有做并行化,而是一行一行地处理;而且每一行在不同层级之间做一次调用,实际上会产生虚函数的开销。因为 next 在不同编程语言肯定是要做函数重载,就算是虚函数开销也很有可能是比实际计算的开销还大,在整体开销上会占相当的比例;同时对缓存也是非常不友好的,因为一行数据会跑多个不同的 operation,可能在取下一行的时候,原来的缓存已经被清洗掉了。
MatrixOne 的执行器是基于 push 模型,可以把几个连续的 operator 组成一个流水线,而且流水线里面流动的数据,并不是一行一行的数据,而是前面提到的 TAE 存储引擎里面的一个 block,包含 8192 行数据,对于一般的数字类型是可以直接放进 L1 Cache 里面的,对缓存非常友好。每一个 operator 每一次要处理完这 8192 行才会喂给下一个 operator,再加上调度是从最下面的,实际读取每一张表的 table scan 那个节点开始,往上面 push。
对于 push 模型,是以数据为中心而不是以 operator 为中心,它的生成过程是对上一步的 planner 和 optimizer 生成的逻辑计划,作一个后续遍历,后续遍历之后就可以得到一个基础的 pipeline 结构,这个基础的 pipeline 结构还没有带上比如每台机器有多少个 CPU 或者需要在多少个 CN 节点上去执行这样的信息。在后面实际执行的时候,再动态地根据这些基础信息去做扩展。
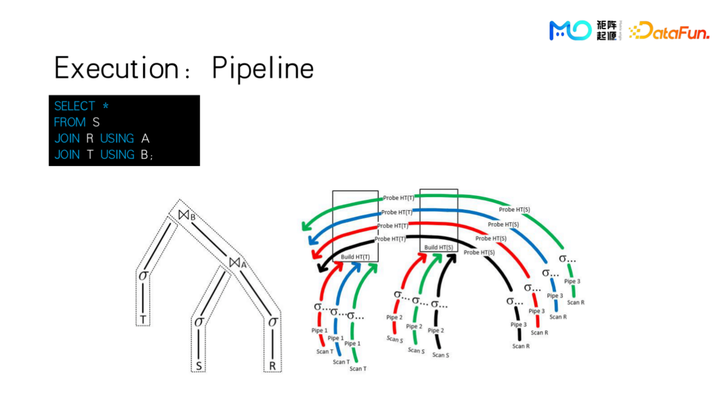
举个简单的例子,假设一个简单的查询,有 R、S、T 三张表做 join,其中 R 表是最大的一个表,S 表和 T 表相对比较小,并且每个表都有过滤条件。对于一个典型的 hash join,我们会把 S 和 T 这两张表去构建 hash 表,然后 R 表在这两个 hash 表上面依次去做探测(Probe)操作,得到 join 之后的数据。这么一个逻辑计划至少需要插上三个 pipeline,S 表的读取数据,做完过滤之后再建完 hash 表就在这里终止,T 表也是在建完 hash 表之后就在 join 算子上面终结掉。但是最大的 R 表它始终是要做 probe 的,这张表的 pipeline 就可以往上走很多步。比如先做完过滤,再跟 S 表 join 之后,仍然以批量数量。然后这个批会继续往下走,在下一个 join 中,仍然在同一个 pipeline 的下一个 operator 里面,再跟 T 表做一个 join。所以一个 3 表 join 通常会拆成 3 个 pipeline 出来。
右图还包括了数据并行的信息,比如 S 表可能会使用 go 语言里的三个协程并行的去读数据,再做合并操作,合并完之后构建 hash 表,T 表也是用三个协程去并行的读,读完之后,然后送到这里的构建 hash 表。R 表因为比较大,pipeline 会展开出更多的实际 pipeline 出来。我们可以看到就是 R 表这个 pipeline 是不会被阻断的,通过 hash operator 之后,会继续进到下一个 join 节点。

如上图,我们的 pipeline 提供了这些算子,比较典型的有聚合、分组和各种 join 操作。这里把 merge 和 connector、dispatch 的颜色标识成不一样,因为它们和其它 operator 的区别是其它算子都是只能在一个 pipeline 的中间,接受的数据是从上一个算子传过来,发送的数据就直接发送给下一个算子去做后续的计算。而标成灰色的这一部分是在一个 pipeline 的数据的 source 或者 sink,即入口或者出口的地方,比如 merge 它会去其他的 pipeline 去接收数据,把所有 pipeline 的数据合并成一个,返回给用户。同理 group by 或者 order by 算子,也会执行 merge 操作。
发送也分为两类:
1.connector 算子是一对一的发送;
2.dispatch 算子是一对多的发送。dispatch 会有很多不同的模式:
– 一种是广播的模式,假设 S 表是一个很小的表,构建完 hash 表之后,会把 hash 表广播到不同的 pipeline 出来去做计算;
– 一种是做 shuffle,假如 S 表和 R 表都比较大,因此要做 shuffle join,那么直接会通过一个 shuffle dispatch 算子把数据发送到不同的对应的一个 pipeline 上面去。

对于 OLAP 系统,从语义上来说通常跟 SQL 本身没什么关系。但是 OLAP 的分析性查询会是比较复杂的计算任务,有一些 SQL 能力是必须具备的,比如多表 join、子查询、窗口函数,还有 CTE 和 Recursive CTE,以及用户自定义函数等。MatrixOne 目前已经具备这些能力。

