- 1Sql Server 2008 R2出现"provider:命名管道提供程序,error:40"问题,无法登录数据库 做个记录_provider 命名管道提供程序error:40 用友 2008r2
- 2【解决】Win10/Win11家庭版不支持远程桌面?如何开启远程桌面?_win11家庭版远程桌面
- 3IntelliJ IDEA 控制台中文乱码,统一设置 UTF-8,解决方案都在这里了,完美解决乱码_控制台乱码
- 4陷入进退两难的境地,如何破局?_两难境地中如何破局
- 5windows10版本oracle12c,创建用户并登录时出现的ora-65096,ora-01017错误的一些处理方法_ora-65096: 公用用户名或角色名无效
- 6论文阅读:基于LSTM的船舶航迹预测模型_船舶轨迹跟踪论文复现
- 7执行'brew update'提示'Permission denied'解决方案_brew upgrade permission denied mac
- 8小程序自定义头部,返回按钮,指定返回某页面_小程序自定义头部之后怎么返回
- 9imtoken(钱包)中文版:im784.app——数字经济的双轮驱动!_imtoken钱包官网app下载
- 10jenkins安装不上awvs插件的ca证书_awvs 客户端证书
使用DSW训练一个线性回归模型_回归模型练习dsw
赞
踩
主要目的有两个:1、熟悉一些dsw的开发环境,以及是如何使用的
2、学习编写代码的能力,本人小白基础,只是为了记录一下学习过程
为什么选择DSW?DSW是阿里云机器学习pai的一个云上开发环境,是属于比较舒服的环境了,之前要为各种cpu、gpu环境的配置烦恼,最起码现在环境是现成的了。
线性回归是什么?
线性回归:线性回归是一种数据分析技术,它通过使用另一个相关的已知数据值来预测未知数据的值。它以数学方式将未知变量或因变量以及已知变量或自变量建模为线性方程。(看了这个定义呢,那我目前的理解是线性回归就是通过已知数据模拟出一条线性方程,这样我们就可以通过x去预测y或者通过y去预测x)
步骤一:安装依赖
如下示范了如何利用Jupyter(dsw里内置了jupyter)的快速安装此案例中需要的依赖。
pip install pandas pip install scikit-learn pip install matplotlib 步骤二:引入依赖 import matplotlib.pyplot as plt import numpy as np import pandas as pd from sklearn import datasets, linear_model from sklearn.metrics import mean_squared_error, r2_score 步骤三:加载数据,构建模型和训练 from sklearn.datasets import load_diabetes # diabetes 是一个关于糖尿病的数据集, 该数据集包括442个病人的生理数据及一年以后的病情发展情况。 # 数据集中的特征值总共10项, 如下: # 年龄 # 性别 #体质指数 #血压 #s1,s2,s3,s4,s4,s6 (六种血清的化验数据) #但请注意,以上的数据是经过特殊处理, 10个数据中的每个都做了均值中心化处理,然后又用标准差乘以个体数量调整了数值范围。验证就会发现任何一列的所有数值平方和为1. data=load_diabetes(as_frame=True) #as_frame是load_diabetes的一个参数,默认为Fales如图1-1,Ture如图1-2。如果为fales就会少了包裹的特征。
1-1
df=pd.concat([pd.DataFrame(data['data']),pd.DataFrame(data['target'])],axis=1)
df.head()#观察数据格式
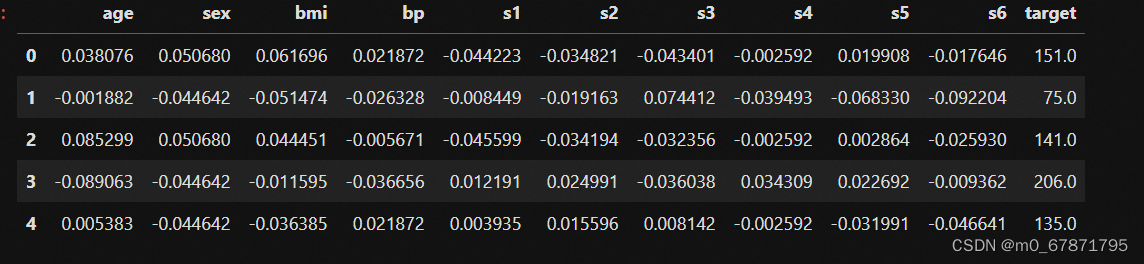
1-2
# 构造训练与测试集,如我们假设BMI指数和糖尿病指数相关,并通过线性回归模型来找出关系
diabetes_X=np.array([df['bmi']]).transpose()
diabetes_Y=np.array([df['target']]).transpose()
# 构造训练与测试数据
diabetes_X_train=diabetes_X[:-20]
diabetes_X_test=diabetes_X[-20:]
diabetes_Y_train=diabetes_Y[:-20]
diabetes_Y_test=diabetes_Y[-20:]
# 构造模型并训练
regr=linear_model.LinearRegression()
regr.fit(diabetes_X_train,diabetes_Y_train)
# 预测
diabetes_Y_predict=regr.predict(diabetes_X_test)
# 输出对应指标
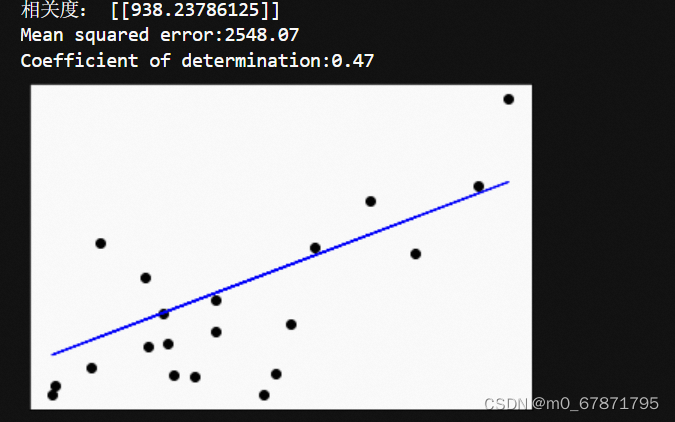
print("相关度:",regr.coef_)
print("Mean squared error:%.2f" %mean_squared_error(diabetes_Y_test, diabetes_Y_predict))
print("Coefficient of determination:%.2f" %r2_score(diabetes_Y_test, diabetes_Y_predict))
# 可视化训练结果
plt.scatter(diabetes_X_test,diabetes_Y_test,color='black')
plt.plot(diabetes_X_test,diabetes_Y_predict,color='blue',linewidth=1)
plt.xticks(())
plt.yticks(())
plt.show()