
- 1Ubuntu交叉编译libusb库_libusb ubuntu编译
- 2深度估计之旅 — AICrowd单目深度感知
- 3idea点击log in to jetbrains account弹出报错窗口。_idea log in to jetbrains account
- 4数据库|DR-AUTO-SYNC架构集群搭建及主备切换手册
- 5最新学习《Python数据分析与挖掘实战》之Python数据分析简介(2)
- 6基于Python的作业自动批改系统_批量检查python作业系统
- 722.哈希表
- 8大数据学习 -- 利用Java API 将文件写入HDFS_使用 java api 进行编程,上次本地文件至hdfs中。
- 9vue获取摄像头视频、拍照_vue获取摄像头视频流
- 10flutter windows环境配置win10_flutter环境配置win10
14-4 深入探究小型语言模型 (SLM)
赞
踩

大型语言模型 (LLM) 已经流行了一段时间。最近,小型语言模型 (SLM) 增强了我们处理和使用各种自然语言和编程语言的能力。但是,一些用户查询需要比在通用语言上训练的模型所能提供的更高的准确性和领域知识。此外,还需要定制小型语言模型,这些模型可以匹配 LLM 的性能,同时降低运行时费用并确保安全且完全可管理的环境。
在本文中,我们探讨了小型语言模型、它们的区别、使用它们的原因及其应用。我们还在小型语言模型 Llama-2–13b 上使用微调方法来解决上述问题。
此外,我们的目标是研究使该流程独立于平台的可能性。为此,我们选择了 Databricks 作为可以在 Azure、Amazon Web Services (AWS) 或 Google Cloud Platform 之间转移的平台。
在人工智能和自然语言处理的背景下,SLM可以代表“小型语言模型”。它是一种轻量级的生成式 AI 模型。在这种情况下,“小型”标签指的是 a) 模型神经网络的大小、b) 参数数量和 c) 模型训练的数据量。有几种实现可以在单个 GPU 上运行,并且参数超过 50 亿个,包括Google Gemini Nano、微软的Orca-2–7b和Orca -2–13b、Meta 的Llama-2–13b等。
SLM 和 LLM 之间存在一些差异。首先,与 SLM 相比,LLM 规模更大,并且经过了更广泛的训练。其次,LLM 具有显著的自然语言处理能力,可以捕捉复杂的模式并在自然语言任务(例如复杂推理)中胜出。最后,LLM 可以更彻底地理解语言,而 SLM 对语言模式的接触有限。这并不会让 SLM 处于劣势,在适当的用例中使用时,它们比 LLM 更有益。
使用这些模型的原因有很多。它们在各种应用中越来越受欢迎,并且越来越重要,尤其是在可持续性和训练所需的数据量方面。从硬件的角度来看,运行成本更低,即 SLM 需要更少的计算能力和内存,并且适合本地和设备部署,使其更安全。从使用的角度来看,这些是小型语言模型,针对特定领域或任务进行训练或微调,因此它们可以拥有从法律术语到保护知识产权的医疗诊断的专业术语和知识。根据场景的不同,SLM 会更便宜、更高效。
SLM 广泛应用于医疗保健、科技等各个领域。所有这些行业的常见用例包括摘要文本、生成新文本、情绪分析、聊天机器人、识别命名实体、纠正拼写、机器翻译、代码生成等。
语言模型微调是向预训练的语言模型提供额外训练的过程,使其更加针对特定领域或任务。此过程涉及使用额外的训练数据更新模型的参数,以提高其在特定领域或应用(如文本生成、问答、语言翻译、情绪分析等)中的表现。我们对“特定领域微调”感兴趣,因为当我们希望模型理解和生成与特定行业或用例相关的文本时,它特别有用。ParagogerAI训练营 2img.ai
硬件要求
硬件要求可能因模型的大小和复杂程度、项目规模和数据集而异。最好先从小规模开始,然后根据需要扩大规模。不过,以下是一些微调私有语言模型的一般准则。
- GPU(图形处理单元)进行处理。它可以基于云。
- 用于传输数据的快速可靠的互联网连接。
- 强大的多核 CPU 用于数据预处理和管理分发步骤。
- 内存充足,存储空间快速充足。

图 1. 用于微调过程的虚拟机。
数据准备
数据集的质量和可行性会显著影响微调模型的性能。为了实现此阶段的目标,我们需要从 PDF 中提取文本,清理和准备文本,然后从给定的文本块生成问题和答案对。最后,继续进行微调过程。
值得注意的是,我们使用了 GPT-3.5 之类的 LLM 来生成问答对(这可能会违背这里的目的),但是,我们也可以尝试使用 SLM 来根据用例生成这些对。
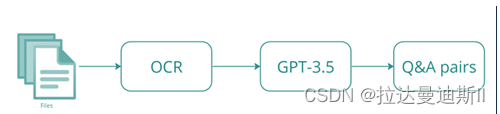
图 2. 准备微调数据集的关键步骤。
微调过程
我们使用了 HuggingFace 及其全套组件,并将它们集成在一起来完成这项任务。

图 3. 用于微调的集成组件。
我们选择了预训练语言模型Llama-2–13b-chat-hf。对于特定领域的数据集,我们将其转换为 HuggingFace 数据集类型,并使用可通过 HuggingFace API 访问的标记器。此外,量化用于降低模型中数值的精度,从而实现数据压缩、计算和存储效率以及降噪。还启用了性能配置,以有效适应预训练模型。最后,训练参数用于定义训练过程的细节,并向训练器传递参数、数据和约束。更多资讯,请访问 2img.ai
训练过程
我们对模型进行了 50 个 epoch 的微调。一个 epoch 指的是训练数据集的一个完整周期。它需要大约 16 个小时才能完成,并且我们的 CPU 和 RAM 资源在此过程中没有得到充分利用。具有有限 CPU 和 RAM 资源的机器可能适合这个过程。我们的 GPU 使用情况符合所述模型要求;也许增加批量大小可以加速训练过程。

图 4. CPU 和 RAM 使用情况。
总体而言,尽管最初在理解互连方面面临挑战,并且面临多次失败的尝试,但微调过程似乎进展顺利且一致。此微调过程的金钱成本约为 100 美元/83 英镑。但是,上述成本不包括最终微调过程的所有试验和错误的成本。
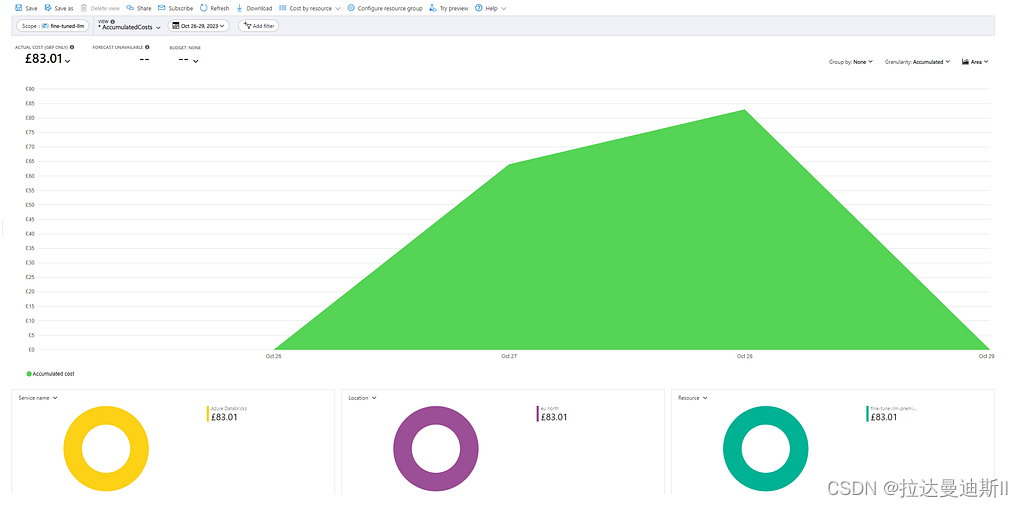
图 5. 以英镑计算的微调成本。
结果与观察
请注意,我们使用 GPT-3.5 从训练数据中生成问题和答案。我们微调的模型是 Llama-2–13b-chat-hf,它只有 130 亿个参数,而 GPT-3.5 有 1750 亿个参数。换句话说,我们期望小模型的表现与大模型一样好。因此,由于 GPT-3.5 和 Llama-2–13b-chat-hf 规模不同,直接比较答案并不合适,但是答案必须是可比的。
为 SLM 和 GPT-3.5 生成的答案创建了嵌入,并使用余弦距离来确定两个模型的答案的相似性。
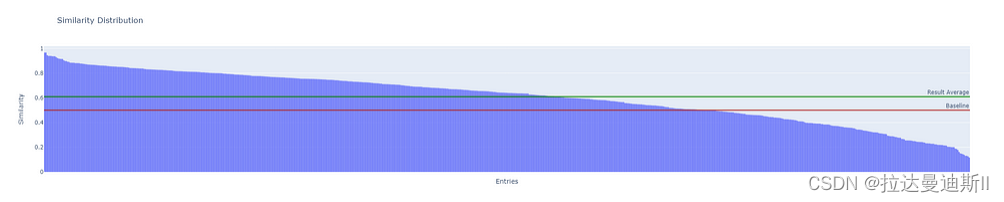
图 6. GPT-3.5 答案和 Llama-2–13b-chat-hf 答案的相似度分布。
根据图 6,0.5 被设定为质量的临界值,0.6 代表 Llama-2–13b-chat-hf 产生的结果的平均质量。高于 0.5 的任何值都被认为是可接受的,低于 0.5 的任何值都是不可接受的。这是因为,类似地,范围从 -1 表示相反,1 表示完全匹配,0 表示与 0.5 的值无关,这似乎是合理的论点。
对于微调过程,我们使用了大约 10,000 个从版本 1 的内部文档中生成的问答对。但为了进行评估,我们只选择了与版本 1 和过程相关的问题。对结果的进一步分析表明,超过 70% 的问题与 GPT-3.5 生成的答案非常相似,即相似度为 0.5 及以上(见图 6)。总共有 605 个被认为是可接受的答案,118 个有点可接受的答案(低于 0.4),以及 12 个不可接受的答案。
经过微调的模型似乎能够提取和维护知识,同时展示出生成特定领域答案的能力。平台无关的方法使我们能够在 AWS 上执行相同的微调过程,并在不更改代码的情况下获得几乎相同的结果。
结论
SLM 也有一些缺点.与 LLM 相比,其知识库更为有限,这意味着它无法回答诸如谁登上月球等问题和其他事实性问题。由于对语言和语境的理解狭隘,它只能给出更受限制和有限的答案。尽管如此,SLM 本身的前景还是相当光明的。语言模型的发展历程凸显了人工智能的一个基本信息,即只要不断进步和现代化,小规模也能令人印象深刻。此外,人们还认为,效率、多功能性、环保性和优化的培训方法抓住了 SLM 的潜力。
我们将拭目以待,看看与 LLM 相比,SLM 会变得多么受欢迎,尤其是最近推出的 SLM,例如 Gemini Nano、Mixtral、Phi-2等。
ParagogerAI训练营 2img.ai

