
- 1人工智能赋能安全应用案例大汇总【AI in Security】_数字赋能安全中的应用案例
- 2vue/js 相关网站导读_vue官网
- 3Spring Boot 初学者指南:快速启动你的项目_如何快速创建一个springboot启动程序
- 4Python 利用插值法实现数值重现——blog9_有重复的值怎么使用插值函数
- 5mac电脑安装iterm2以及配置环境高亮并加上完整的路径_iterm2 配置简化显示路径_iterm2设置展示文件绝对路径
- 6加速失败远程计算机不能反应,2008 R2 SP1远程桌面如何开启GPU加速?不讨论虚拟机...
- 7React Native使用高德地图获取地理位置定位_react-native使用高德sdk
- 8win11卸载mysql详细步骤_win11 卸载mysql
- 92021第四十界中国控制会议(CCC2021)论文投稿及参会经验_ccc会议
- 10【音视频 | RTSP】RTSP协议详解 及 抓包例子解析(详细而不赘述)_rtsp 音视频传输抓包
时序预测 | KAN+Transformer时间序列预测(Python)_kan transformer
赞
踩
预测效果
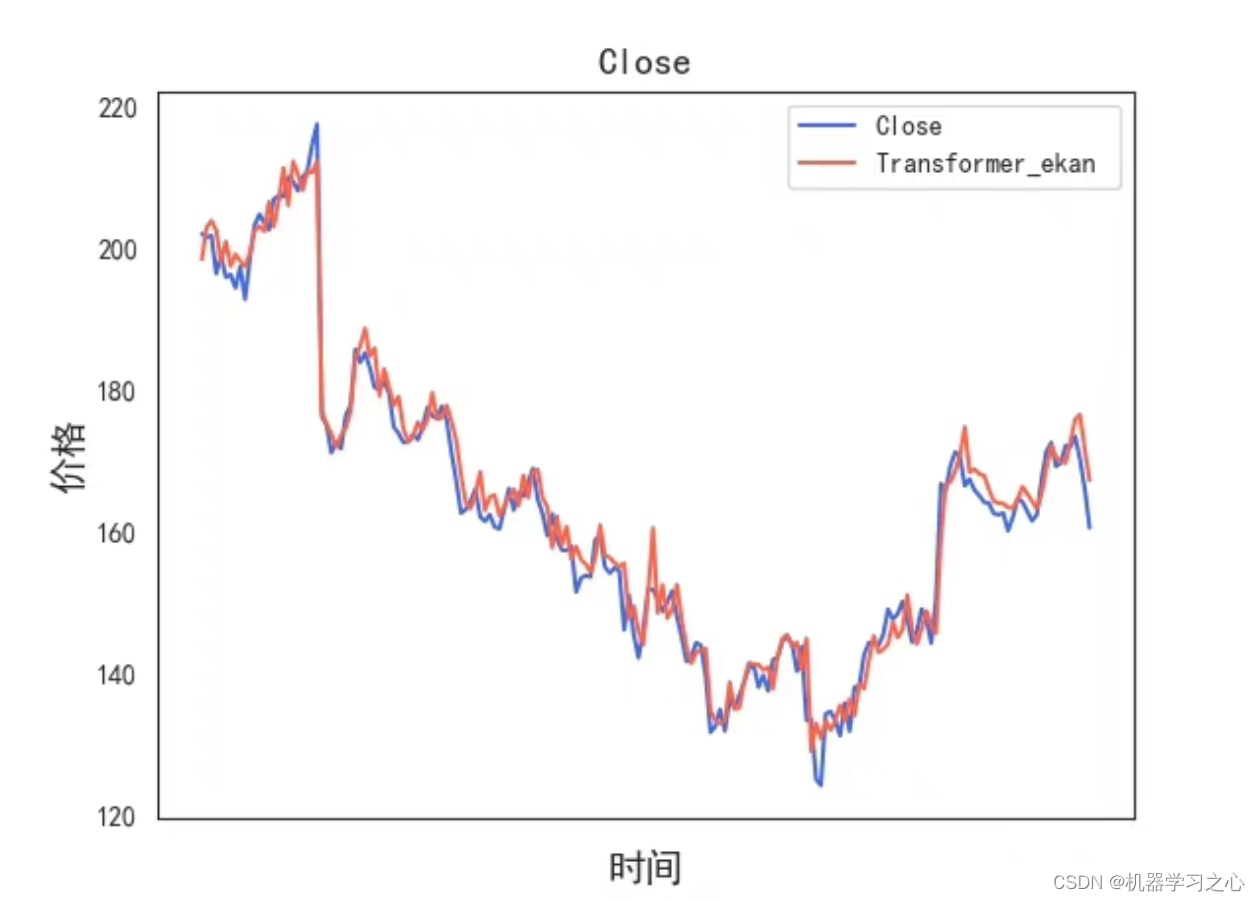
基本描述
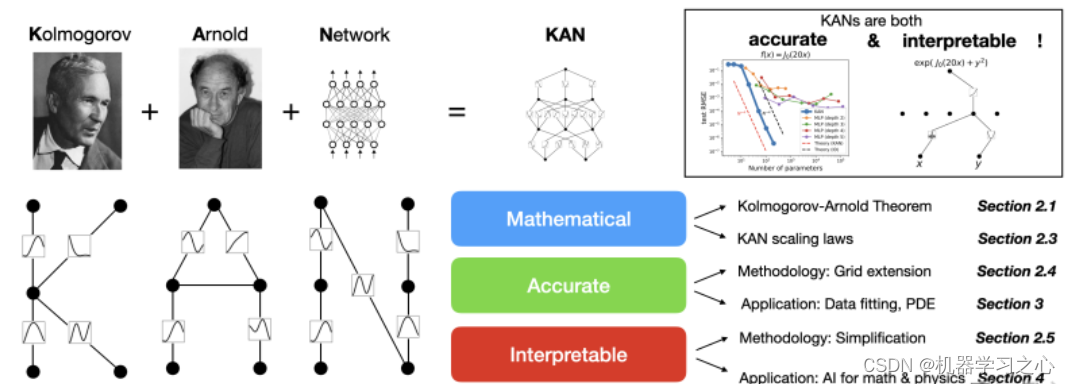
KAN+Transformer时间序列预测
KAN作为这两年最新提出的机制,目前很少人用,很适合作为时间序列预测的创新点,可以结合常规的网络加上个优化方法做创新。适合功率预测,负荷预测,流量预测,浓度预测,机械领域预测等等各种时间序列预测。
KAN(Kolmogorov–Arnold Networks)的模型,它对标的是MLPs(多层感知机),这个模型由数学定理Kolmogorov–Arnold启发得出的。该模型最重要的一点就是把激活函数放在了权重上,也就是在权重上应用可学习的激活函数,这些一维激活函数被参数化为样条曲线,从而使得网络能够以一种更灵活、更接近Kolmogorov-Arnold 表示定理的方式来处理和学习输入数据的复杂关系。
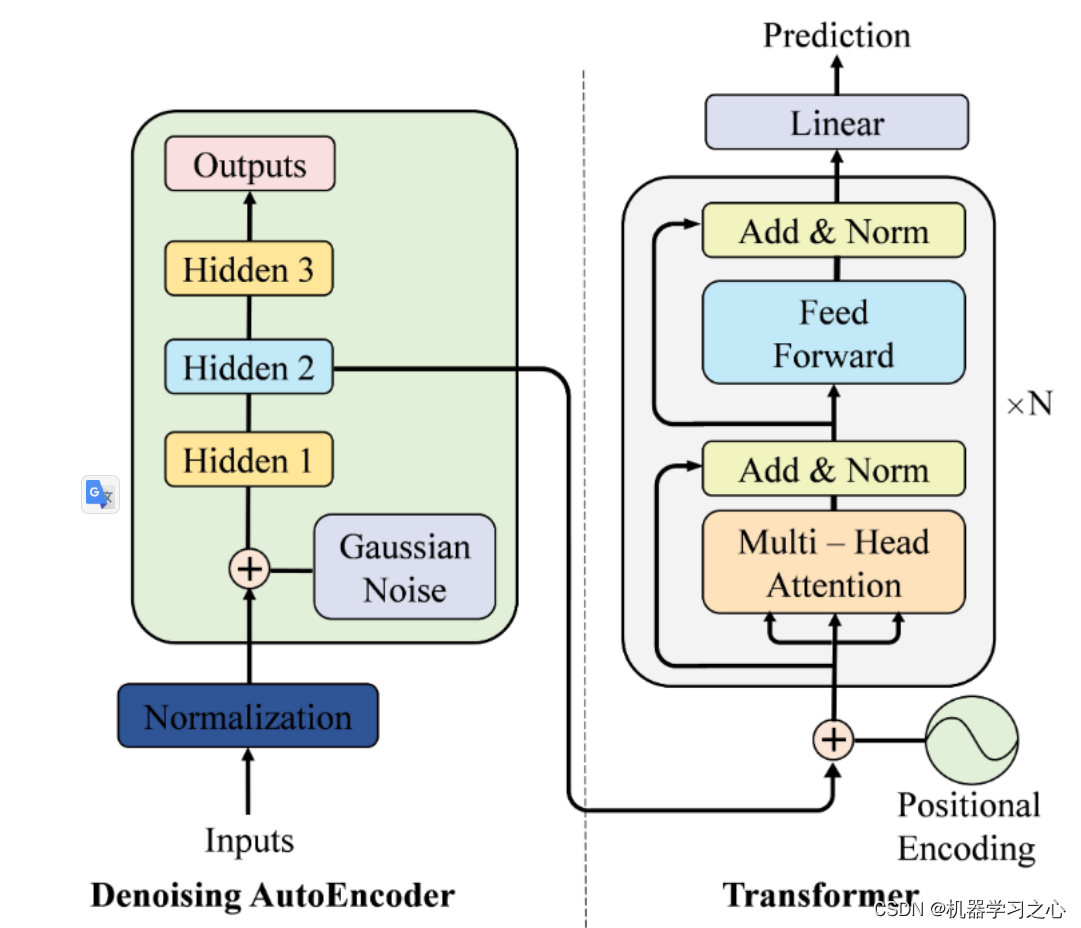
Transformer 模型本质上都是预训练语言模型,大都采用自监督学习 (Self-supervised learning) 的方式在大量生语料上进行训练,也就是说,训练这些 Transformer 模型完全不需要人工标注数据。Transformer 模型的标志就是采用了注意力层 (Attention Layers) 的结构,前面也说过,提出 Transformer 结构的论文名字就叫《Attention Is All You Need》。顾名思义,注意力层的作用就是让模型在处理数据时,将注意力只放在某些数据上。Transformer 模型本来是为了翻译任务而设计的。在训练过程中,Encoder 接受源语言的句子作为输入,而 Decoder 则接受目标语言的翻译作为输入。在 Encoder 中,由于翻译一个词语需要依赖于上下文,因此注意力层可以访问句子中的所有词语;而 Decoder 是顺序地进行解码,在生成每个词语时,注意力层只能访问前面已经生成的单词。
程序设计
- 完整源码私信博主回复KAN+Transformer时间序列预测(Python)
参考资料
[1] https://blog.csdn.net/kjm13182345320/article/details/139786303?spm=1001.2014.3001.5501
[2] https://blog.csdn.net/kjm13182345320/article/details/139786130?spm=1001.2014.3001.5501

