
- 1【EI会议征稿通知】第六届信息科学、电气与自动化工程国际学术会议(ISEAE 2024)
- 2创新引领、协同发展丨2024中国元宇宙论坛暨常孝元宇宙发布会即将召开
- 3开源知识介绍_sspl-1.0
- 42款一键word生成ppt的AI工具,让职场办公更为简单!
- 5一款GPT加持的编程神器,国内可免费使用_国内免费gpt
- 6Hadoop | 初学基础原理_hadoop 初始原理
- 7mysql signed unsigned zerofill详解_mysql中 无符号和填充0
- 8Elasticsearch分片原理_es 分片
- 9卷积神经网络学习心得_卷积神经网络实验心得
- 10利用LSTM(Long Short-Term Memory)进行回归预测的原理和python代码_lstm回归
认知篇-多模态与垂直领域大模型_垂直行业rag
赞
踩
一、 多模态RAG
1.1 LLM存在的问题
随着LLM的爆火,大模型在辅助我们高效工作中的地位越来越高,也在越来越多的领域中得到应用和推广。但是在具体应用场景中,仍旧发现通用大模型存在一些问题:
- 幻觉问题
这个问题在早期的LLM中尤为突出。比如我们向大模型询问“你听说过林黛玉倒拔垂杨柳的故事吗?”此时大模型经过一番思考,讲的头头是道,搞得我以为真有此事。结果发现却是信口雌黄,一本正经的胡说八道。当然像这个问题错误很明显,要是一些你也不清楚的内容,此时怕是要闹笑话了。究其原因,是因为数据收集和算法优化的问题。
- 知识的实时性
模型的规模越大,训练的成本就越高,而且训练的数据都是历史数据。 像ChatGPT 3.5的数据更新到2021年,如果此时你询问之后的内容,他就无法了解了。所以,比较注重时效性的问题,没有办法得到很好的解决。
- 数据安全性
数据泄密和隐私的问题一直也伴随着大模型的产生和发展,像OpenAI也是多次受到类似的投诉。如果企业想要通过大模型做内部的决策,将企业的经营数据上传到大模型,显然是不安全的。如果想要保证安全的同时,使用大模型实现决策,就需要使用完全本地化的部署。
1.2 RAG vs Fine-Tuning
为了解决大模型存在问题,可以有多种方式。
在已有的大模型基础上,如果想要处理特定领域的问题,此时我们可以引入特定数据即进行额外的训练来优化模型,以便更好的适应任务。这种方式也是常用的手段之一,被称为微调(Fine-Tuning)。这种方式可以一定程度上提高实时性,减少幻觉问题,缺陷在于需要重复的训练。
另一种方式是检索增强生成(Retrieval Augmented Generation),简称 RAG。RAG通过引入外部知识来源,结合检索和生成两个步骤,来增强大模型的能力。比如引入向量数据库,连接网络获取数据等方式,能够使大模型的数据实时性更好,也能减少幻觉的问题。当然缺陷也很明显,使用RAG需要处理检索和生成过程,比单纯微调更复杂。
1.3 RAG架构
在RAG的使用中,首先通过向量数据库对数据集进行收集和索引,借助于向量数据库强大的检索能力,召回目标知识。然后将召回的知识交给LLM大模型进行排序、归纳等操作,得到最终的输出。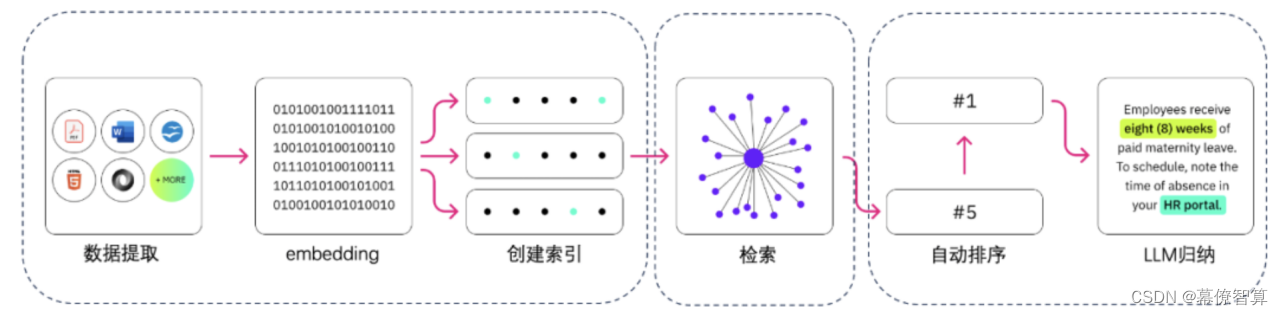
RAG在大模型的应用中有三种形式:基础RAG(Naive RAG)、高级RAG(Advanced RAG)和模块化RAG(Modular RAG)。
基础RAG主要包含信息检索和文本生成两个阶段;
高级RAG(Advanced RAG)在基础RAG的基础之上,引入了预检索(pre-retrieval)和后检索(post-retrieval)优化策略。在预检索阶段,会通过对查询的处理提高检索的相关性和准确性;在后检索阶段对检索信息进行排序、压缩等处理,以便更好的结合文本生成步骤。
模块化RAG(Modular RAG)允许不同的检索和生成模块,根据不同的业务需求,进行自由组合,这种方式更加的灵活,也更容易适应多变的场景。
1.4 RAG组件
RAG的流程包含数据提取、embedding(向量化)、创建索引、检索、自动排序(Rerank)、LLM归纳生成。
1.4.1 索引
索引部分主要是将私域的数据向量化后进行索引并存储到向量数据库。
- 数据提取
数据提取包含数据加载、数据处理、元数据提取。
数据加载是将一些来源不同的异构数据进行统一格式的提取;获取到数据之后,接着就是对数据进行必要的剔除、格式替换、压缩等步骤;
元数据提取用于将数据的文件名称、title、时间等信息提取。
- 文本分割
通常大模型在处理数据过程中,都会对token进行一定的长度限制。一方面在于处理成本的控制,另一方面过多过长的数据可能影响对整个语义的理解。因此通常都会进行分割
固定长度分割
长度取决于embedding模型,一般为256/512个tokens,这种分割方式缺陷很明显。比如“我只会剽窃他的想法”,有可能会被分割成“我只会剽”和“窃他的想法”。这种情况下可能会损失很多语义,对检索不友好,因而通常会通过增加冗余量来解决。
基于意图的分割
句分割:最简单的是通过句号和换行来做切分。当然也有通过专业的意图包来切分的。
递归分割:通过分而治之的思想,用递归切分到最小单元的一种方式。
- 向量化
向量化是一个将文本数据转化为向量矩阵的过程,embedding模型的好坏会直接影响到后面检索的质量。向量化完成以后就可以存入数据库等待检索。
1.4.2 检索
检索阶段,需要通过用户的访问,从向量数据库中检索召回知识,然后交给LLM生成,因而检索的结果好坏,关系到LLM生成的结果。
通常为了提升检索的效率,通过一些必要的处理。
- 元数据过滤
元数据中包含了向量的基本信息,包含名称、时间、title等。例如我们想要检索2023年去世的著名的物理学家,如果首先对元数据筛选过滤“物理学家+2023年”得到相应的文件,再从这些文件中检索会更加高效。
- 图检索
对于关系比较复杂的数据,可以利用图的先天优势,将每个节点看作为节点,他们之间的关系为Relation。此时如果涉及到多重跳点的关系,处理起来会更加方便。
- 相似性检索
计算查询向量与所有存储向量的相似性得分,返回得分高的记录。常见的有欧氏距离、曼哈顿距离等。
- 重排序
很多时候由于我们检索的维度和相关度不是太理想,检索出来的数据不是太好。这时候可以通过对检索的结果做重排序,或者把组合相关度、匹配度等因素做一些重新调整,得到更符合我们业务场景的排序。
1.4.3 生成
通过检索得到必要的知识之后,就可以通过LLM实现生成。通常可以通过Prompt(提示工程)实现对大模型的输入,包含任务、背景的描述等,由大模型进行处理并输出。
Prompt可以帮助模型更好地理解输入的意图,并作出相应的响应。但是不同质量的Prompt对结果的影响会比较大,因此后面再实践阶段,我们会专门讲解如何写出高质量的Prompt。
1.5 多模态RAG
随着RAG的发展,我们可能不仅仅局限于对文本内容的增强检索,于是便出现了多模态检索增强生成(Multimodal Retrieving-Augmented Generation)。包含对图片处理生成、音频识别、视频字幕处理、代码的检索和生成。
二、 垂直领域大模型
2.1 通用大模型的不足
大模型的火爆和无序之后,当人们冷静下来,可能会思考大模型如何改变现有的工作方式,毕竟不能总是闲聊吧。作为开发者可能想通过大模型编程,设计师希望是实现设计图的生成,作家可能想用它来写作…
但是真正使用起来会发现,它可能没有你想象的那么强大。貌似什么都懂,又好像什么都不怎么样。抱歉,我不是在说你。
相信我,更多的时候,我们可能不是需要懵懵懂懂的通用大模型。而是需要在某个领域能够独挡一面、可信赖的垂直大模型。
2.2 常见垂直领域大模型
垂直领域的大模型通常是基于通用大模型的继续预训练,同时补充相关领域的预料,减少幻觉的产生。
垂直领域大模型的构建,包括继续预训练,领域数据集构建,减缓幻觉,知识召回等方面。
对于特定领域的预训练,可以通过RAG实现实现相关领域问题的快速干预,同时增加时效性和减少幻觉。
除此之外,通过SFT激发大模型理解领域内各种问题并进行回答的能力,通过RLHF可以让大模型的回答对齐人们的偏好,比如行文的风格。
目前,已经有垂直领域的大模型产品落地。
模型名称:BERT-Financial
领域:金融
介绍:BERT-Financial是一个用于金融领域的预训练语言模型,基于Transformer架构,通过对大量金融文本数据进行训练,能够理解和生成金融领域的文本内容,如新闻、报告、分析等。
模型名称:AlphaFold
领域:生物信息学
介绍:AlphaFold是一个用于蛋白质结构预测的大规模深度学习模型。它通过对大量蛋白质序列数据进行训练,能够预测蛋白质的三维结构,为生物医学研究提供重要的帮助。
模型名称:GPT-News
领域:新闻媒体
介绍:GPT-News是一个用于新闻生成的大规模语言模型,基于Transformer架构。通过对大量新闻报道进行训练,能够生成高质量的新闻内容,为新闻媒体提供快速、准确的报道服务。
模型名称:Clinc150
领域:语音助手
介绍:Clinc150是一个用于语音识别和自然语言处理的大规模深度学习模型。它通过对大量语音数据进行训练,能够识别和理解人类语音,为智能语音助手提供强大的支持。
模型名称:Salesforce CTRL
领域:客户关系管理
介绍:Salesforce CTRL是一个用于客户关系管理的大规模深度学习模型,基于Transformer架构。通过对大量客户数据和业务数据进行训练,能够识别客户需求和趋势,为企业提供智能化的客户关系管理服务。
2.3 垂直大模型的一点思考
垂直大模型在各个领域都展现出了强大的能力,它们通过对大量数据进行训练,能够理解和生成各种专业领域的文本、图像、语音等内容,为各个行业的智能化和自动化提供重要的支持。
然而,垂直大模型也面临着一些挑战和问题。首先,由于模型的规模巨大,需要大量的计算资源和存储空间,这导致了训练和部署成本的增加。其次,由于模型的复杂性,需要大量的数据进行训练,而数据的获取和处理也是一项复杂的工作。此外,垂直大模型的泛化能力也需要进一步提高,以更好地适应各种实际应用场景。
为了解决这些问题,可以考虑采用一些技术手段。例如,采用模型压缩和剪枝技术,减小模型的规模,降低计算成本;采用增量学习和微调技术,提高模型的泛化能力;采用联邦学习和迁移学习等技术,减小数据的需求和模型的复杂性。
此外,垂直大模型的应用也需要考虑隐私和安全问题。在训练和使用垂直大模型时,需要保护用户的隐私和数据安全,避免数据泄露和滥用等问题。可以采用加密技术和差分隐私等技术来保护用户隐私和数据安全。
二、 结语
通过认知篇的内容,相信大家对大模型已经有了初步的认知。多模态RAG和垂直大模型的发展虽然面临一些挑战和问题,但随着技术的不断发展和应用的不断深入,将会在各个领域发挥更加重要的作用,也会为我们的生产和生活带来更多的便利和价值。
对大模型有了认知之后,后面我们将带大家进入大模型的实践。See you later!

