
- 1安卓开发错误记录:Manifest merger failed : Attribute application@allowBackup value=(true)
- 2JAVA 读取jar包中excel模板_java classpathresource 读取当前 jar中的文件模版
- 3Java中的链表_java链表
- 4python 日志 logging 模块详解_python logger日志模型详解
- 5Elasticsearch:Elasticsearch SQL介绍及实例(二)_ztod
- 6(无插件)简单快速硬破解头歌平台不允许复制粘贴问题。_头歌代码文件不允许复制粘贴
- 7【Rust指南】快速入门|开发环境|hello world_rust快速入门
- 8进程调度算法(拓跋阿秀笔记记录)_拓跋阿秀 进程通信
- 9面试了百度、美团、字节,唯独阿里云给我留下的印象最深!(Java开发岗)_阿里云和美团哪个好
- 10《GraphSNN: 超越WL同构图测试的图神经网络》论文解读
阿里通义千问,彻底爆了!(本地部署+实测)_通义千问qwen2
赞
踩
点击“终码一生”,关注,置顶公众号
每日技术干货,第一时间送达!
问大家一个问题:你是否想过在自己的电脑上部署一套大模型?并用自己的知识库训练他?
阿里通义千问今天发布了最新的开源大模型系列Qwen2,首批开放了多个不同参数的模型:0.5B、1.5B、7B、72B、MOE,其中Qwen2-72B一发布,就在十几个大模型权威测评榜单夺冠,2小时冲上了Hugging Face开源大模型榜首。
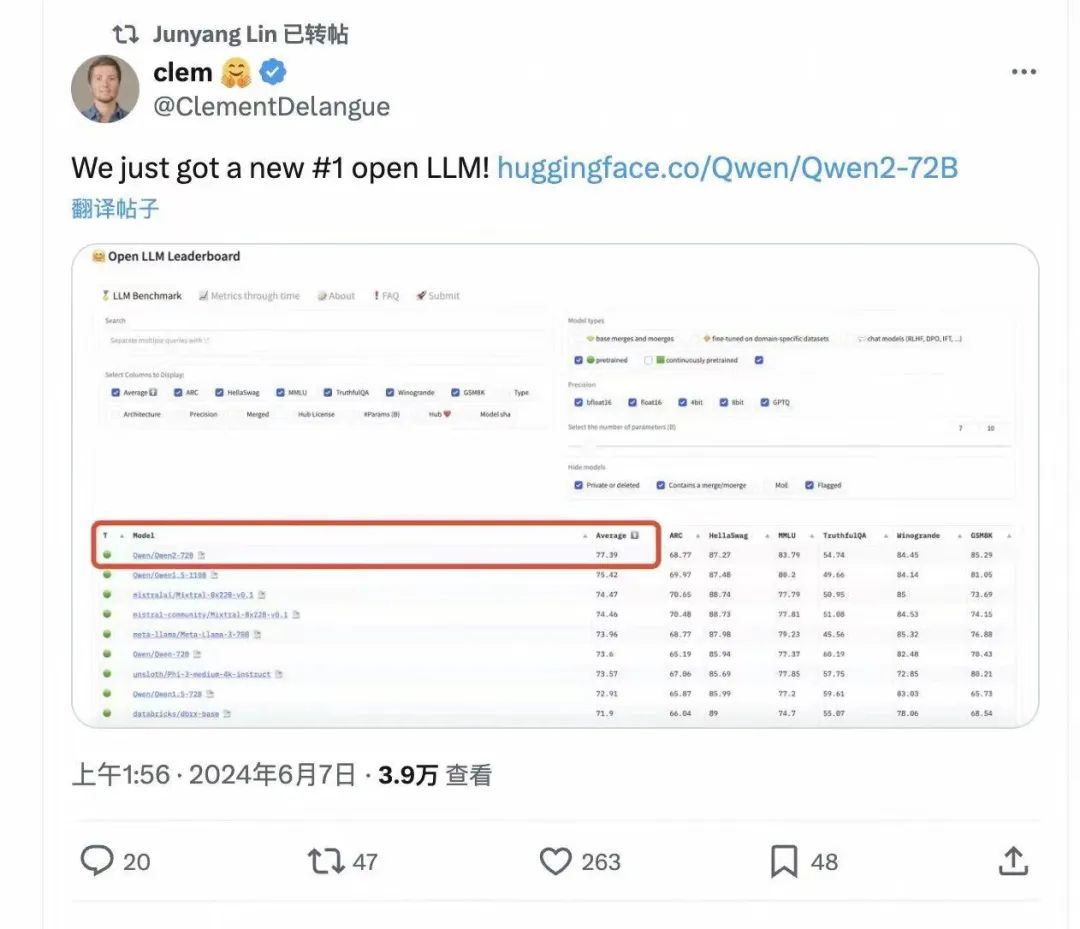
作为一个程序员,应该紧跟技术的发展,才不会被淘汰,我们在通过大模型帮助我们解决问题的同时,也应该更近距离的去接触大模型,安装测试一些开源大模型,这样才能更深刻的理解大模型。
借此阿里通义千问Qwen2大模型今天开源之际,我们本地部署测试一把,通义千问开源大模型主要有以下优势:
-
模型在同尺寸模型的测评中,都获得了超越所有开源模型的成绩;
-
开源频率和速度全球无二、模型性能也不断进化,在多个权威榜单多次创造中国大模型的“首次”
下面是我本次详细安装测试步骤,带领大家更近距离体验大模型的魅力。我们分布安装Qwen1.5和刚刚发布的Qwen2两个版本的不同参数大模型。在熟悉大模型部署的同时,也可以体验下新版开源更强的性能。
下面是主要步骤:
-
安装ollama工具
-
下载Qwen1.5大模型,测试
-
安装Docker,部署Open-WebUi可视化
-
下载Qwen2大模型,和上一代模型对比
1、下载Ollama工具
-
官网:https://ollama.com
-
Github:https://github.com/ollama/ollama
开始测试前,我们先介绍一款工具,Ollama,他是一个开源的大模型工具框架,它能在本地轻松部署和运行大型语言模型,如Llama 3, Phi 3, Mistral, Gemma,Qwen。它是专门设计用于在本地运行大型语言模型。Ollama和LLM(大型语言模型)的关系,有点类似于docker和镜像,我们可以在Ollama服务中管理和运行各种LLM,它将模型权重、配置和数据捆绑到一个包中,优化了设置和配置细节,包括GPU使用情况。
通过该工具,我们可以大大简化环境部署等问题,省去许多麻烦。
工具下载可以去官网根据自己的电脑系统,直接下载。
|
|
|
点击图片 查看大图
下载速度相对较慢,大家耐心等待下。
2、安装
1、安装Ollama
比较简单,我是Mac,下载的是一个zip压缩包,直接解压安装,其他电脑操作也是一样的,直接安装。
|
|
|
|
|
|

点击图片 查看大图
最后,点击Finish,安装完毕。
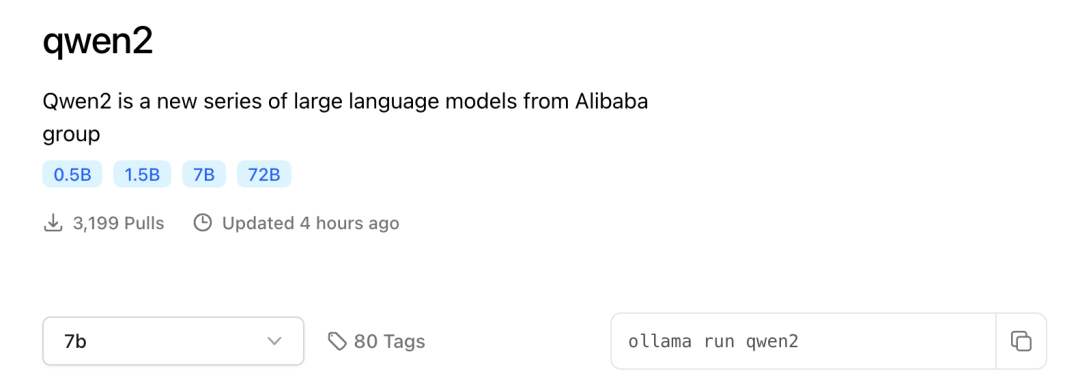
我们需要什么模型,可以直接在ollama.com网站搜索我们需要下载的模型,本次使用阿里开源的通义千问大模型Qwen,我们可以在网站搜下Qwen,如下:
|
|
|
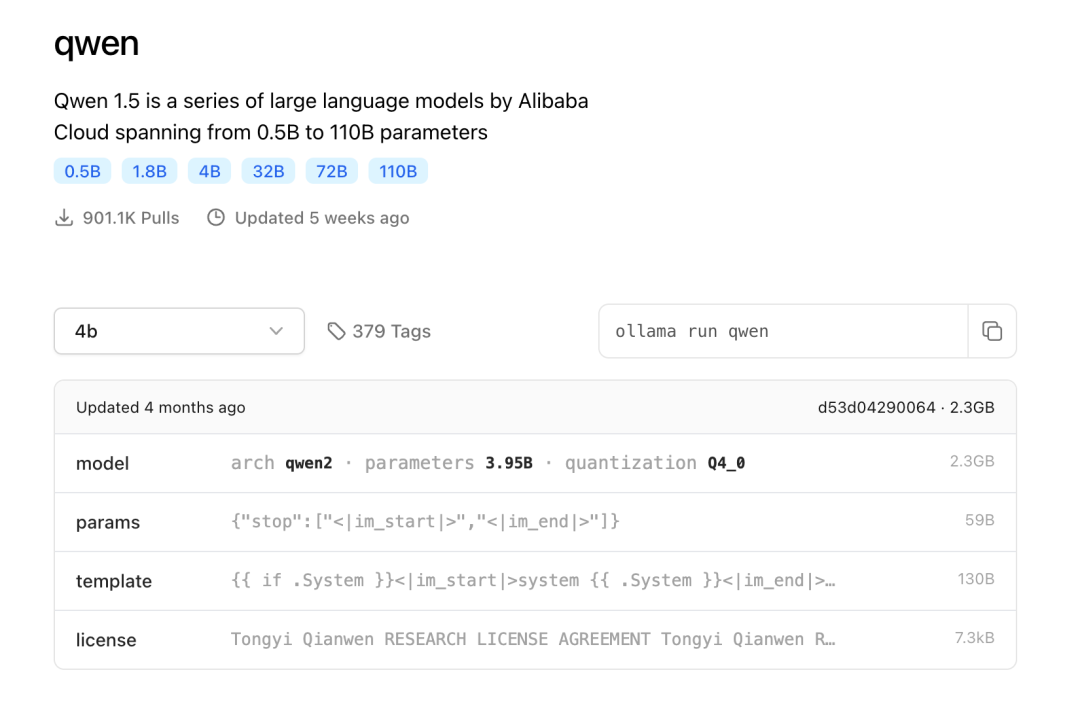

点击图片 查看大图
可以看到有Qwen1.5和Qwen2,我们先安装Qwen1.5版本,目前有0.5B1.8B4B32B72B110B,不同数值对应不同的参数大小,第一次使用,考虑到自己电脑配置,谨慎一些,先使用了模型1.8B(18亿参数)。整个模型不到2G的大小。
具体操作,打开终端直接运行命令,下载速度比较快。
ollama run qwen:1.8b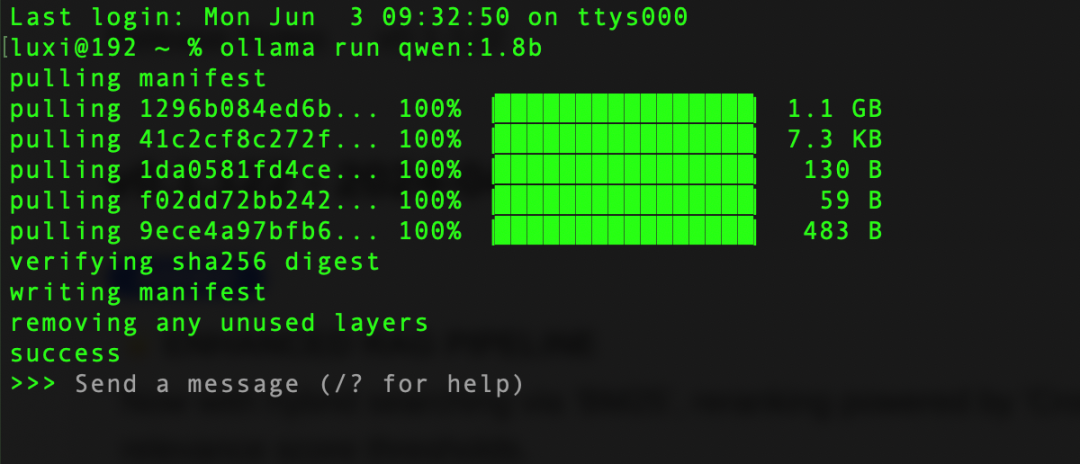
看到success表示已经安装完成,我们可以直接在终端下使用,进行提问。

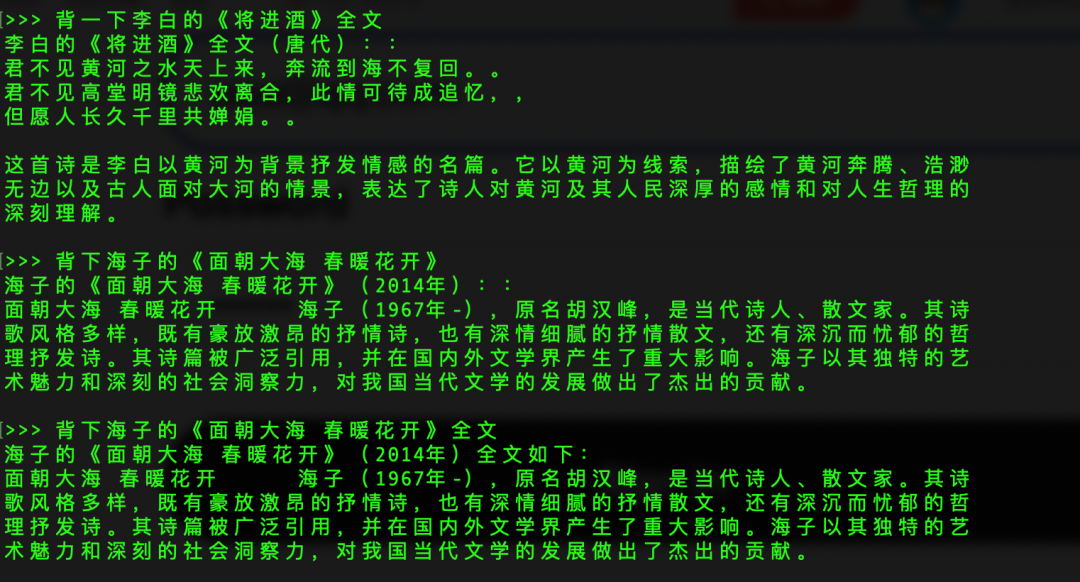
可以看到Qwen-1.8B的回答并不是很理想,这个不是重点,等下我们要下载其更先进更准确的模型。这样我们也可以更深刻的体会模型的训练和提升。
2、安装Docker(可选,更好的体验)
终端下操作,体验并不是很好,想要更好的体验,我们可以安装Docker,并启动open-webUI,这样我们可以在浏览器上使用自己下载的大模型,Docker的安装比较简单,这里不在过多介绍,基本是傻瓜式安装,官方下载即可。
地址:https://www.docker.com/products/docker-desktop/
安装时配置和注册信息我们都可以直接跳过。如果无法访问,请开魔法。
|
|
|

点击图片 查看大图
3、安装Open-WebUI
安装完毕docker,我们打开终端,执行open-webui安装口令,如下:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main|
|
|
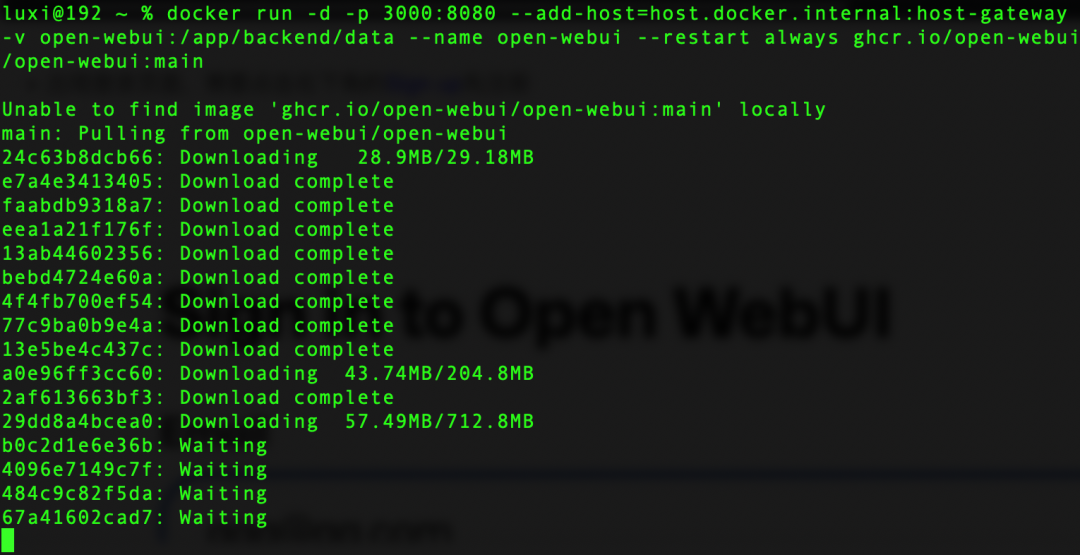
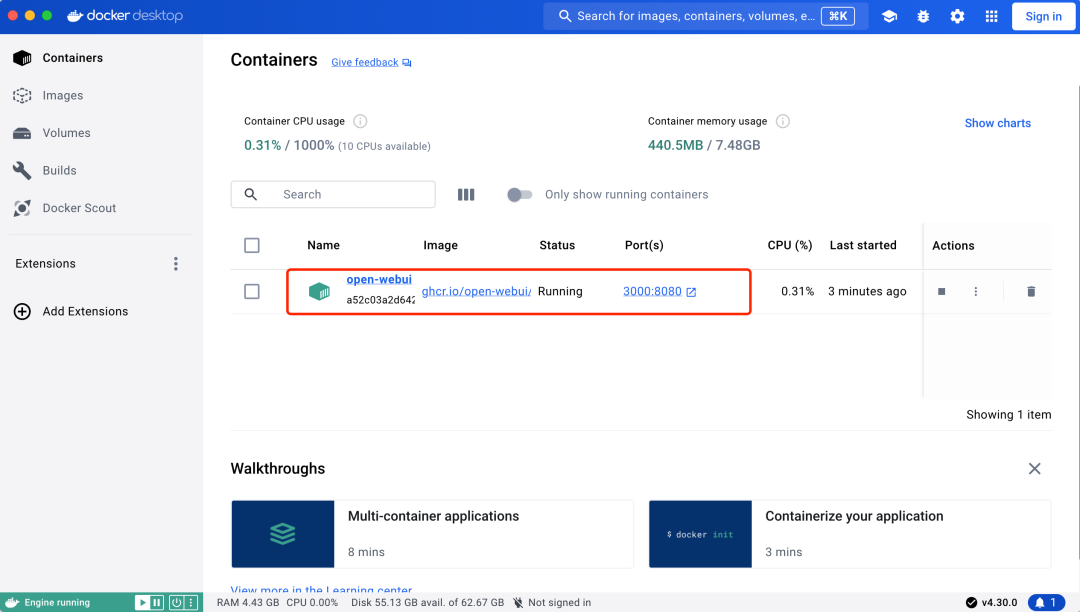
点击图片 查看大图
需要安装相应的组件,耐心等待下,下载完。我们可以通过Docker工具看到运行的open-webui,浏览器访问地址:http://localhost:3000/auth/
首次登陆,需要先点击Sign up注册,随便注册下,进入到管理后台。
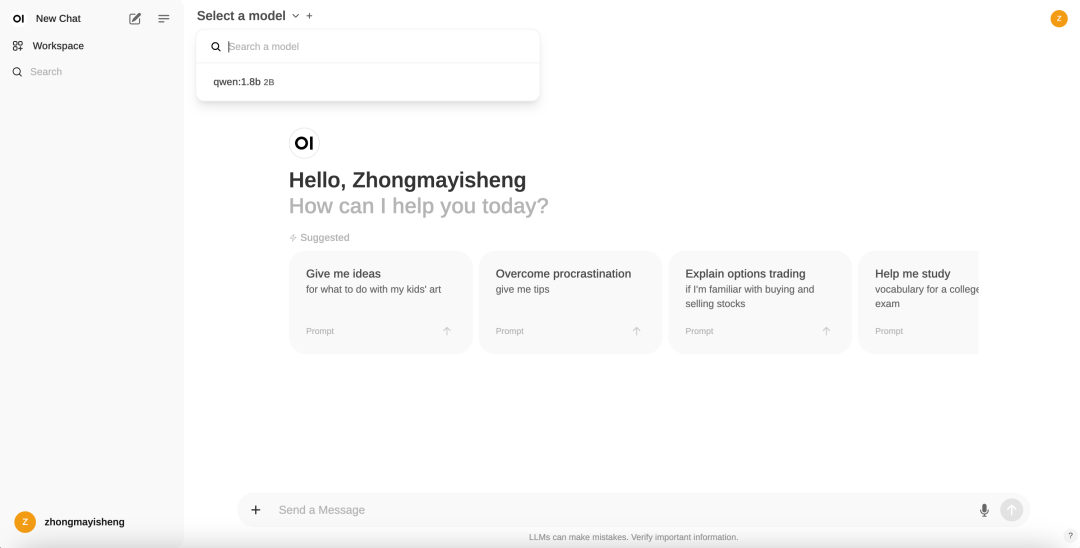
界面是不是有点似曾相识,没错,和GPT后台很相似。同样的,左上角可以选择我们安装的Qwen模型,如果我们安装多个模型的话,可以切换不同模型使用。

4、添加更先进的模型(Qwen2-7b)
因为刚才安装的1.8B,回答效果并不理想,我这添加其刚刚开源的最新大模型,通义千问Qwen2,我们下载7B,70亿参数,大小在4G左右(当然,还有更先进,大家根据自己的电脑配置选择),终端执行如下命令:
ollama run qwen2:7b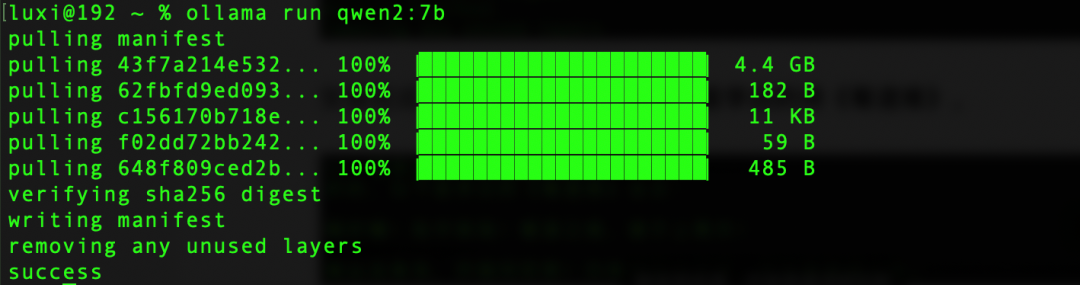
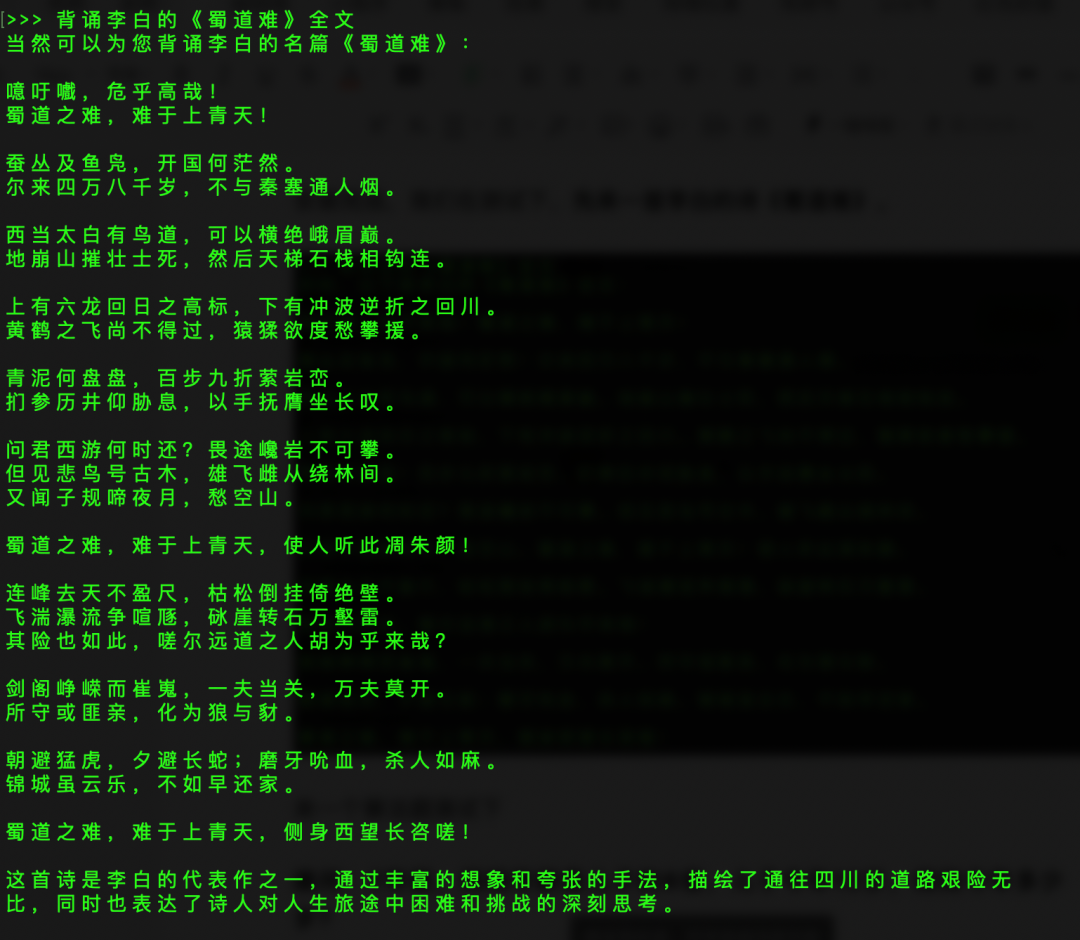
安装完成,我们在测试下,先来一首李白的诗《蜀道难》。
来一个算法题测试下
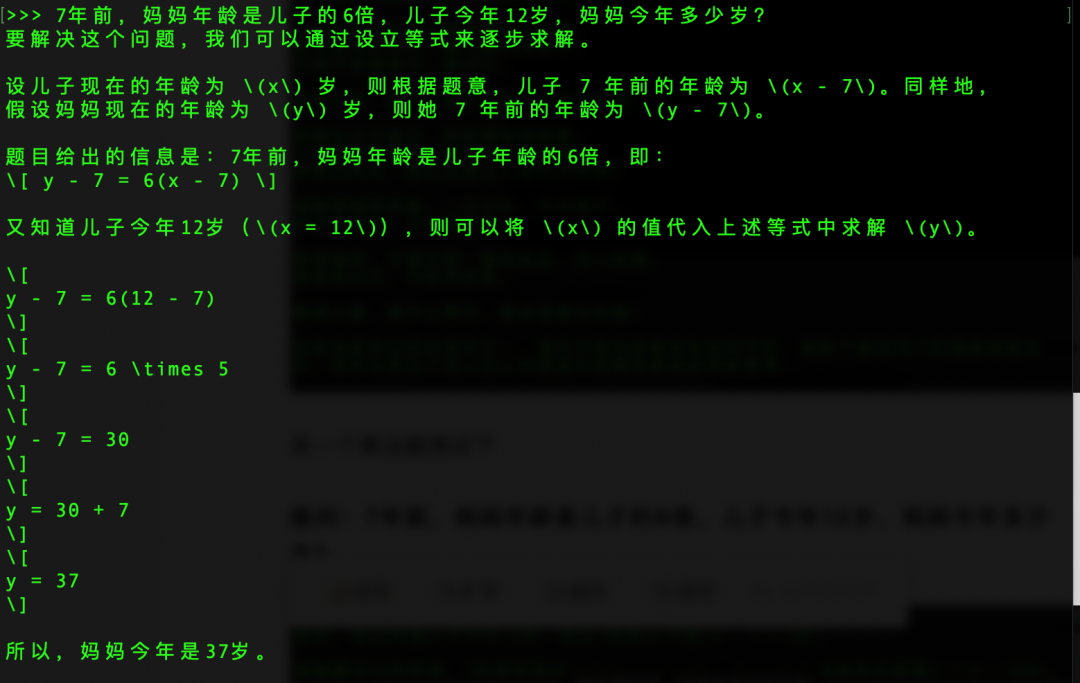
提问:7年前,妈妈年龄是儿子的6倍,儿子今年12岁,妈妈今年多少岁?
再来一个编程
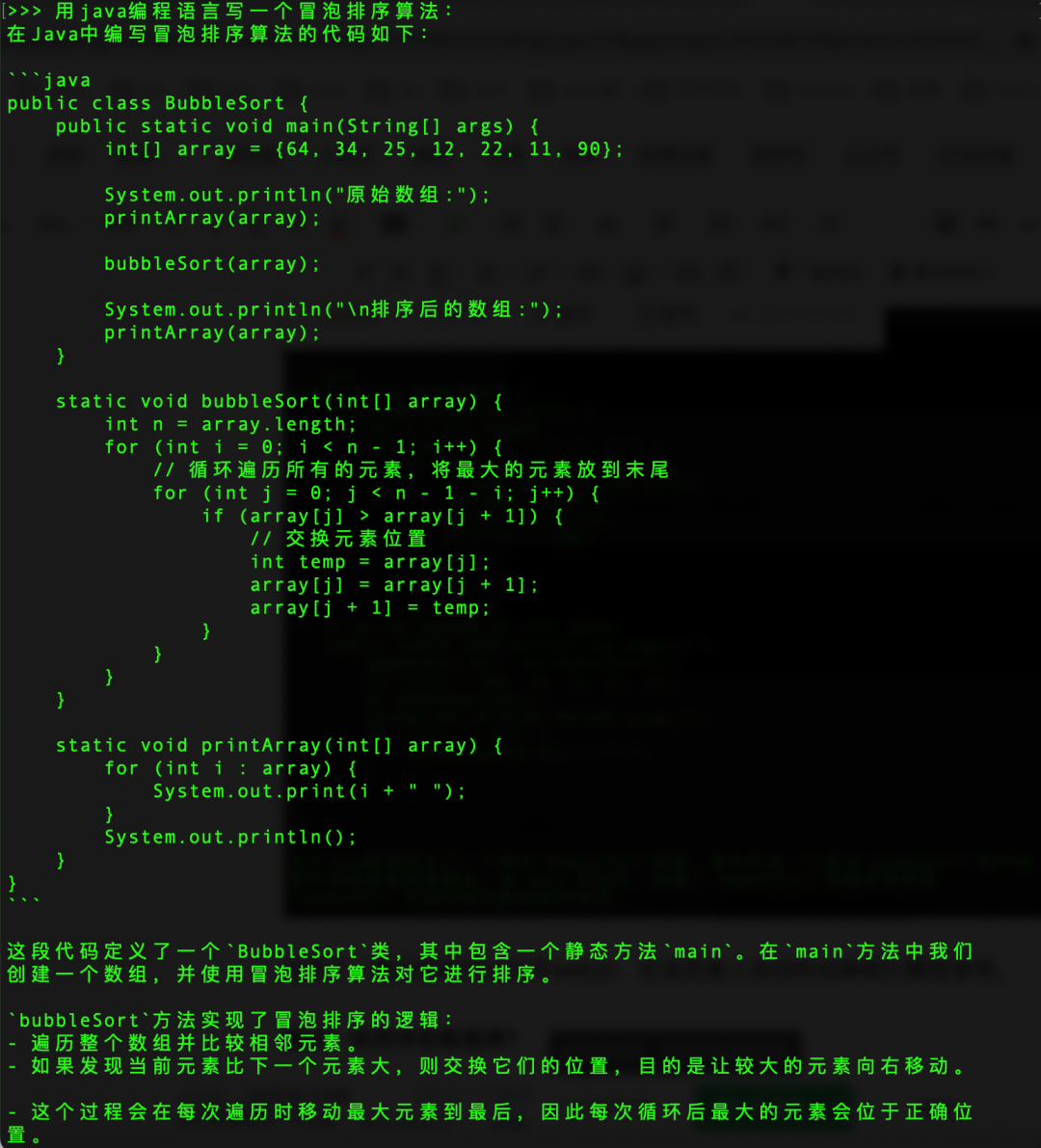
提问:用java编程语言写一个冒泡排序算法:
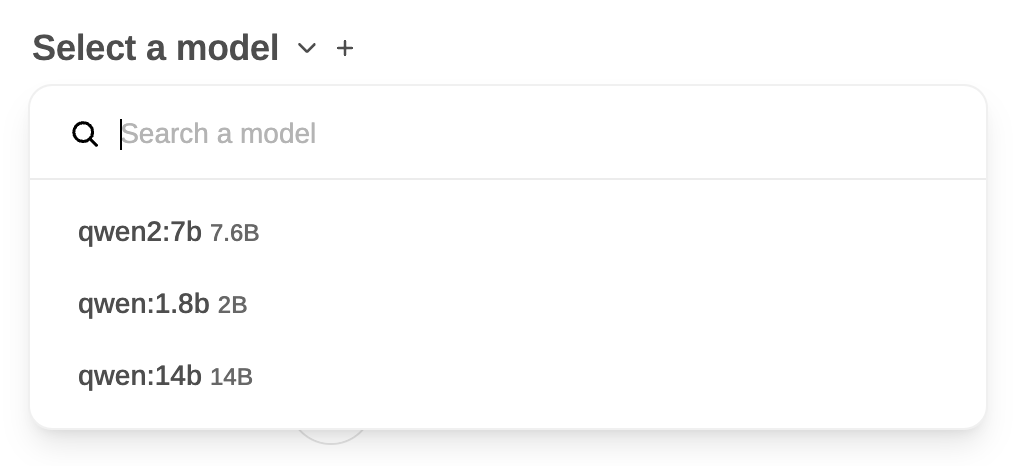
当然了,我们同样可以打开webUI,在浏览器上来回的切换我们模型。目前我安装了多个模型,我们在网页上试下Qwen2。
提问:如何评价陈独秀?

本人体验:相比之前Qwen1.5模型,Qwen2使用非常丝滑,处理性能大幅提升,基本上都是秒级相应速度。理解能力和准确性也提升了许多,回答内容也更加优质。当然还有更先进的模型,像Qwen2-72B,完全能够满足我们的需求,一些模型甚至在一些方面已经赶超GPT-4.0。
我们如果想要测试其他大模型,可以去https://ollama.com/网站搜索

3、最后
好了,今天的部署测试就到这里。Qwen2相比Qwen1.5实现了重大升级,具有以下特点:
-
5个尺寸的预训练和指令微调模型, 包括Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B以及Qwen2-72B;
-
在中文英语的基础上,训练数据中增加了27种语言相关的高质量数据;
-
多个评测基准上的领先表现;
-
代码和数学能力显著提升;
-
增大了上下文长度支持,最高达到128K tokens(Qwen2-72B-Instruct)。

是不是很香,很简单,再也不用到处注册账号,申请试用了。现在完全可以自己搭建一个通义千问大模型,在本地就可以使用自己的大模型。
马上自己部署体验一下吧!!

