
- 12023年全国大学生电子设计竞赛E题总结分享(全国一等奖)_2023电赛e题
- 2【JVM基础04】——组成-什么是虚拟机栈?
- 3percona mysql 5.7_使用Percona MySQL 5.7版本遇到的坑
- 4Java实现手机库存管理_java手机库存管理案例
- 5Mac环境Nginx的搭建以及使用,感悟分享_mac使用nginx
- 6鱼哥赠书活动第17期:看完这本《Python数据分析》菜鸟也能做Python数据分析?_菜鸟编程 python数据分析_谁说菜鸟不会数据分析python篇pdf
- 7Pytorch中设计随机数种子的必要性_pytorch为什么要几算随机数
- 8生成式对抗网络(GAN)的数学原理与实现_生成对抗网络的数学原理
- 9C# 开发Windows服务程序并在计算机上注册服务_c# 注册服务
- 10NLP文本相似度(word2vec)的原理及实现_word2vec计算文本相似度
视觉~合集xxs1_hierarchical latent structure for multi-modal vehi
赞
踩
## 论文分享目标检测、图像分割、监督学习等
主要是整理别人的发一下哦
ECCV 2022 论文分方向整理目前在极市社区持续更新中,已累计更新了54篇,项目地址:https://github.com/extreme-assistant/ECCV2022-Paper-Code-Interpretation
- - 检测
- - 分割
- - 图像处理
- - 视频处理
- - 图像、视频检索与理解
- - 估计
- - 目标跟踪
- - 文本检测与识别
- - GAN/生成式/对抗式
- - 神经网络结构设计
- - 数据处理
- - 模型训练/泛化
- - 模型压缩
- - 模型评估
- - 半监督学习/自监督学习
- - 多模态/跨模态学习
- - 小样本学习
- - 强化学习

检测
2D目标检测
[1] Point-to-Box Network for Accurate Object Detection via Single Point Supervision (通过单点监督实现精确目标检测的点对盒网络)
paper:https://arxiv.org/abs/2207.06827
code:https://github.com/ucas-vg/p2bnet
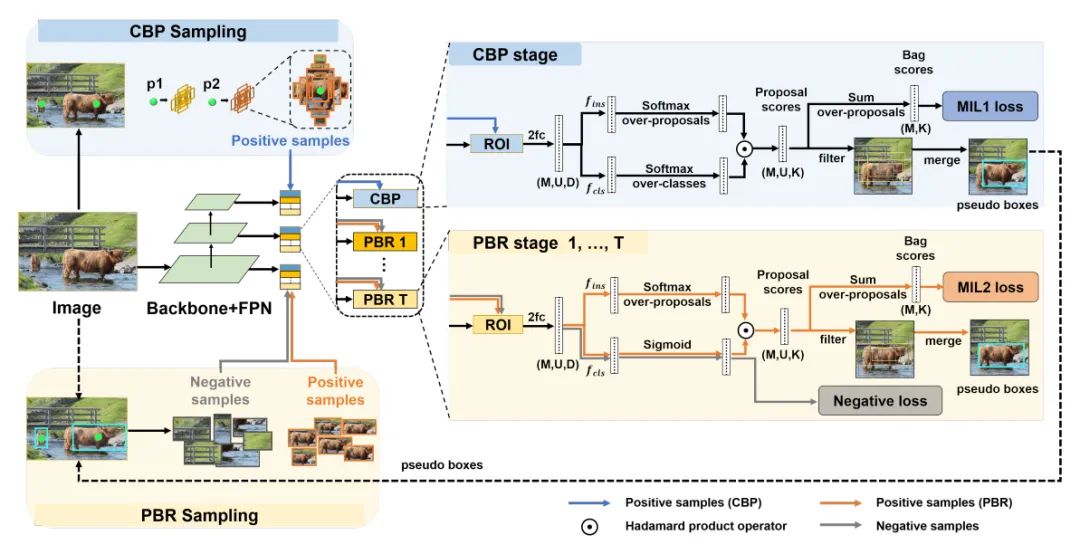
[2] You Should Look at All Objects (您应该查看所有物体)
paper:https://arxiv.org/abs/2207.07889
code:https://github.com/charlespikachu/yslao
[3] Adversarially-Aware Robust Object Detector (对抗性感知鲁棒目标检测器)
paper:https://arxiv.org/abs/2207.06202
code:https://github.com/7eu7d7/robustdet
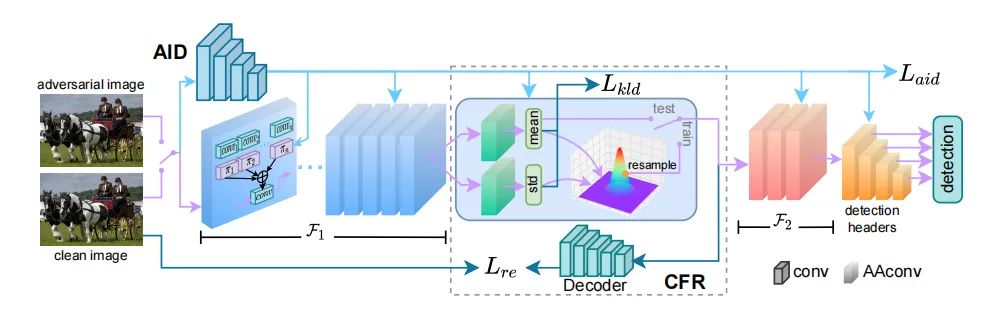
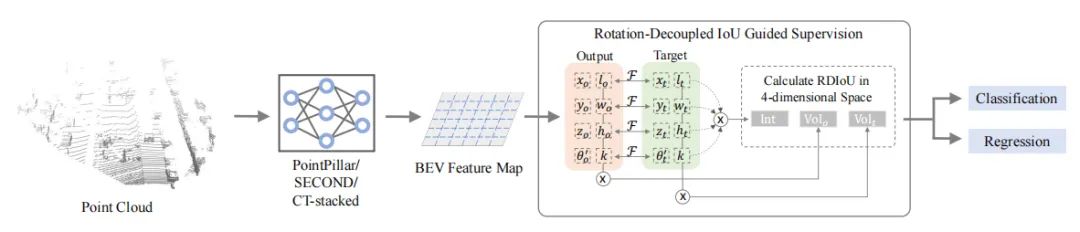
3D目标检测
[1] Rethinking IoU-based Optimization for Single-stage 3D Object Detection (重新思考基于 IoU 的单阶段 3D 对象检测优化)
paper:https://arxiv.org/abs/2207.09332
人物交互检测
[1] Towards Hard-Positive Query Mining for DETR-based Human-Object Interaction Detection (面向基于 DETR 的人机交互检测的硬性查询挖掘)
paper:https://arxiv.org/abs/2207.05293
code:https://github.com/muchhair/hqm

图像异常检测
[1] DICE: Leveraging Sparsification for Out-of-Distribution Detection (DICE:利用稀疏化进行分布外检测)
paper:https://arxiv.org/abs/2111.09805
code:https://github.com/deeplearning-wisc/dice
分割
实例分割
[1] Box-supervised Instance Segmentation with Level Set Evolution (具有水平集进化的框监督实例分割)
paper:https://arxiv.org/abs/2207.09055
[2] OSFormer: One-Stage Camouflaged Instance Segmentation with Transformers (OSFormer:使用 Transformers 进行单阶段伪装实例分割)
paper:https://arxiv.org/abs/2207.02255
code:https://github.com/pjlallen/osformer

语义分割
[1] 2DPASS: 2D Priors Assisted Semantic Segmentation on LiDAR Point Clouds (2DPASS:激光雷达点云上的二维先验辅助语义分割)
paper:https://arxiv.org/abs/2207.04397
code:https://github.com/yanx27/2dpass
视频目标分割
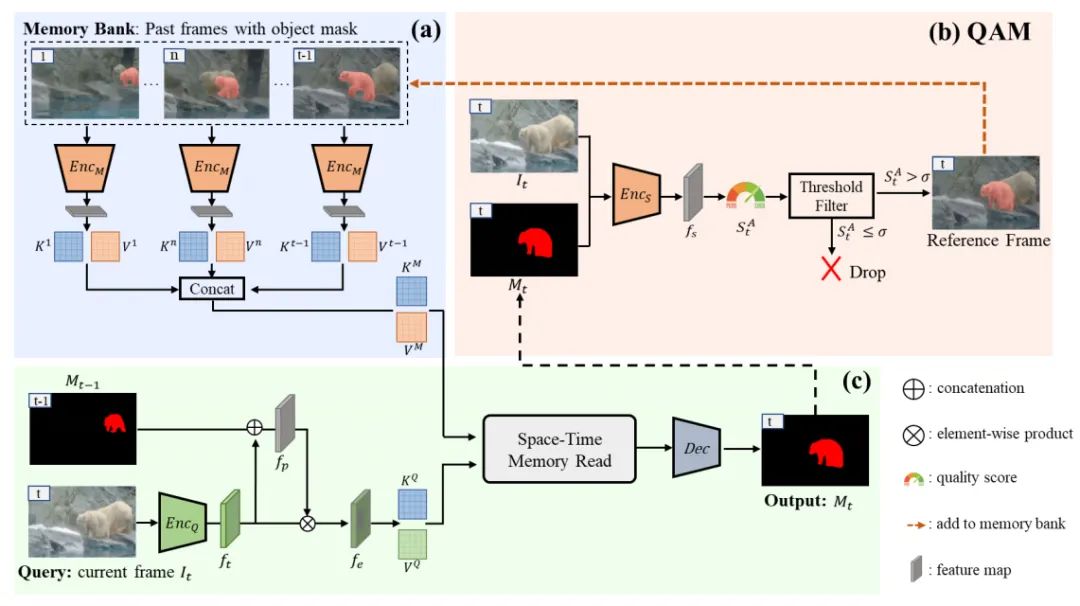
[1] Learning Quality-aware Dynamic Memory for Video Object Segmentation (视频对象分割的学习质量感知动态内存)
paper:https://arxiv.org/abs/2207.07922
code:https://github.com/workforai/qdmn
图像处理
超分辨率
[1] Dynamic Dual Trainable Bounds for Ultra-low Precision Super-Resolution Networks (超低精度超分辨率网络的动态双可训练边界)
paper:https://arxiv.org/abs/2203.03844
code:https://github.com/zysxmu/ddtb
图像去噪
[1] Deep Semantic Statistics Matching (D2SM) Denoising Network (深度语义统计匹配(D2SM)去噪网络)
paper:https://arxiv.org/abs/2207.09302
图像复原/图像增强/图像重建
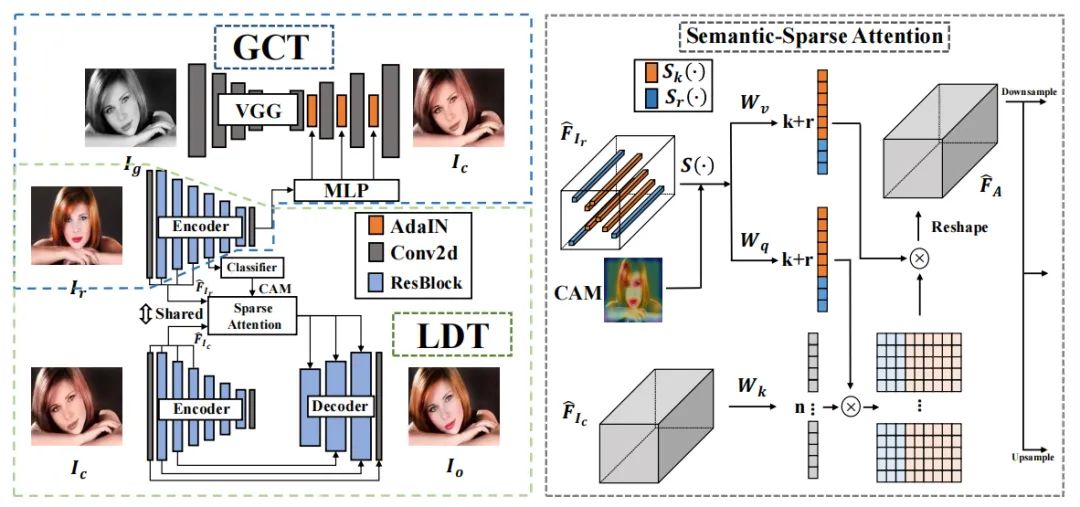
[1] Semantic-Sparse Colorization Network for Deep Exemplar-based Colorization (用于基于深度示例的着色的语义稀疏着色网络)
paper:https://arxiv.org/abs/2112.01335
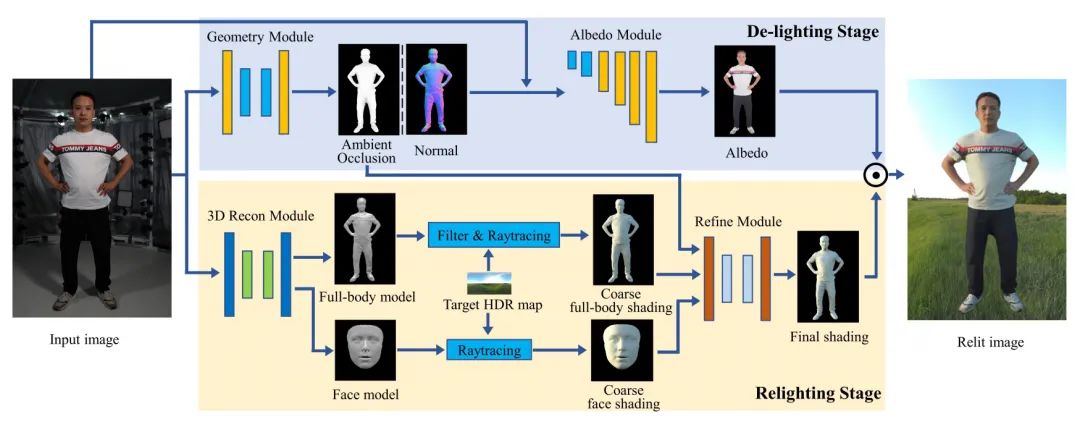
[2] Geometry-aware Single-image Full-body Human Relighting (几何感知单图像全身人体重新照明)
paper:https://arxiv.org/abs/2207.04750
[3] Multi-Modal Masked Pre-Training for Monocular Panoramic Depth Completion (单目全景深度补全的多模态蒙面预训练)
paper:https://arxiv.org/abs/2203.09855
[4] PanoFormer: Panorama Transformer for Indoor 360 Depth Estimation (PanoFormer:用于室内 360 深度估计的全景变压器)
paper:https://arxiv.org/abs/2203.09283
[5] SESS: Saliency Enhancing with Scaling and Sliding (SESS:通过缩放和滑动增强显着性)
paper:https://arxiv.org/abs/2207.01769
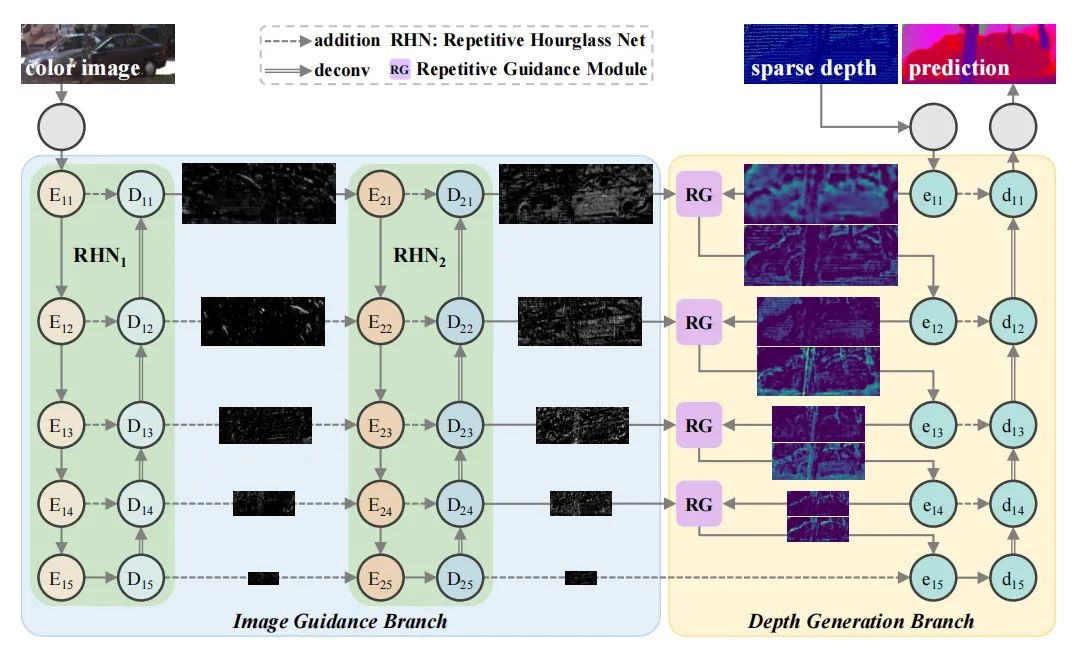
[6] RigNet: Repetitive Image Guided Network for Depth Completion (RigNet:用于深度补全的重复图像引导网络)
paper:https://arxiv.org/abs/2107.13802
图像外推(Image Outpainting)
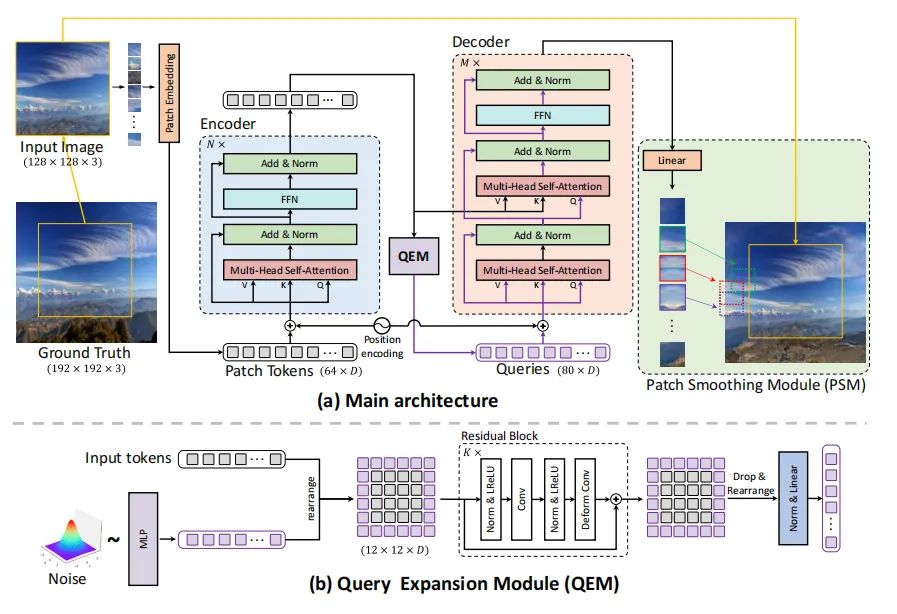
[1] Outpainting by Queries (通过查询进行外包)
paper:https://arxiv.org/abs/2207.05312
code:https://github.com/kaiseem/queryotr
风格迁移(Style Transfer)
[1] CCPL: Contrastive Coherence Preserving Loss for Versatile Style Transfer (CCPL:通用风格迁移的对比相干性保留损失)
paper:https://arxiv.org/abs/2207.04808
code:https://github.com/JarrentWu1031/CCPL
视频处理(Video Processing)
[1] Improving the Perceptual Quality of 2D Animation Interpolation (提高二维动画插值的感知质量)
paper:https://arxiv.org/abs/2111.12792
code:https://github.com/shuhongchen/eisai-anime-interpolator

[2] Real-Time Intermediate Flow Estimation for Video Frame Interpolation (视频帧插值的实时中间流估计)
paper:https://arxiv.org/abs/2011.06294
code:https://github.com/MegEngine/arXiv2020-RIFE
图像、视频检索与理解
动作识别
[1] ReAct: Temporal Action Detection with Relational Queries (ReAct:使用关系查询的时间动作检测)
paper:https://arxiv.org/abs/2207.07097
code:https://github.com/sssste/react
[2] Hunting Group Clues with Transformers for Social Group Activity Recognition (用Transformers寻找群体线索用于社会群体活动识别)
paper:https://arxiv.org/abs/2207.05254
视频理解
[1] GraphVid: It Only Takes a Few Nodes to Understand a Video (GraphVid:只需几个节点即可理解视频)
paper:https://arxiv.org/abs/2207.01375
[2] Deep Hash Distillation for Image Retrieval (用于图像检索的深度哈希蒸馏)
paper:https://arxiv.org/abs/2112.08816
code:https://github.com/youngkyunjang/deep-hash-distillation

视频检索(Video Retrieval)
[1] TS2-Net: Token Shift and Selection Transformer for Text-Video Retrieval (TS2-Net:用于文本视频检索的令牌移位和选择转换器)
paper:https://arxiv.org/abs/2207.07852
code:https://github.com/yuqi657/ts2_net
![]()
[2] Lightweight Attentional Feature Fusion: A New Baseline for Text-to-Video Retrieval (轻量级注意力特征融合:文本到视频检索的新基线)
paper:https://arxiv.org/abs/2112.01832
估计
位姿估计
[1] Category-Level 6D Object Pose and Size Estimation using Self-Supervised Deep Prior Deformation Networks (使用自监督深度先验变形网络的类别级 6D 对象姿势和大小估计)
paper:https://arxiv.org/abs/2207.05444
code:https://github.com/jiehonglin/self-dpdn

深度估计
[1] Physical Attack on Monocular Depth Estimation with Optimal Adversarial Patches (使用最优对抗补丁对单目深度估计进行物理攻击)
paper:https://arxiv.org/abs/2207.04718
目标跟踪
[1] Towards Grand Unification of Object Tracking (迈向目标跟踪的大统一)
paper:https://arxiv.org/abs/2207.07078
code:https://github.com/masterbin-iiau/unicorn

文本检测与识别
[1] Dynamic Low-Resolution Distillation for Cost-Efficient End-to-End Text Spotting (用于经济高效的端到端文本识别的动态低分辨率蒸馏)
paper:https://arxiv.org/abs/2207.06694
code:https://github.com/hikopensource/davar-lab-ocr
GAN/生成式/对抗式
[1] Eliminating Gradient Conflict in Reference-based Line-Art Colorization (消除基于参考的艺术线条着色中的梯度冲突)
paper:https://arxiv.org/abs/2207.06095
code:https://github.com/kunkun0w0/sga

[2] WaveGAN: Frequency-aware GAN for High-Fidelity Few-shot Image Generation (WaveGAN:用于高保真少镜头图像生成的频率感知 GAN)
paper:https://arxiv.org/abs/2207.07288
code:https://github.com/kobeshegu/eccv2022_wavegan
[3] FakeCLR: Exploring Contrastive Learning for Solving Latent Discontinuity in Data-Efficient GANs (FakeCLR:探索对比学习以解决数据高效 GAN 中的潜在不连续性)
paper:https://arxiv.org/abs/2207.08630
code:https://github.com/iceli1007/fakeclr
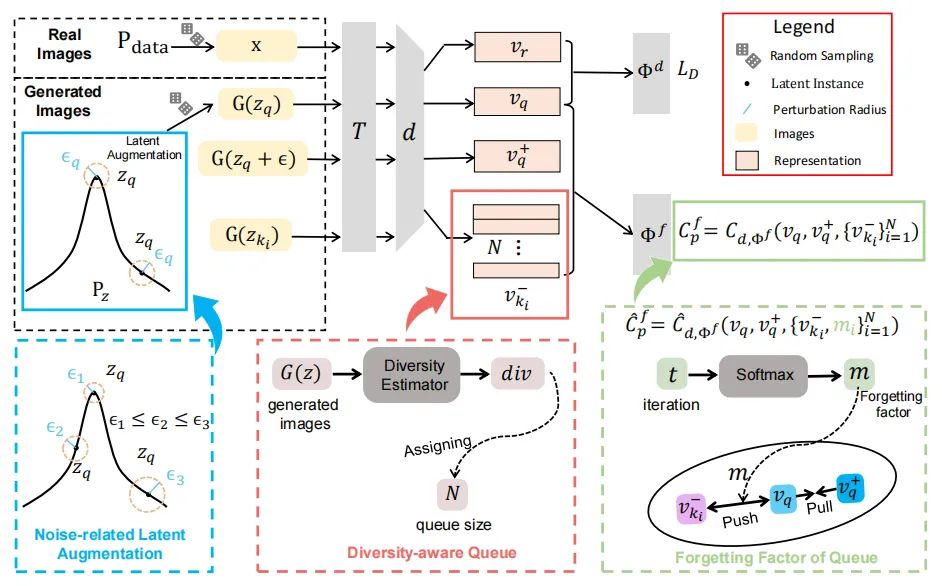
[4] UniCR: Universally Approximated Certified Robustness via Randomized Smoothing (UniCR:通过随机平滑获得普遍近似的认证鲁棒性)
paper:https://arxiv.org/abs/2207.02152
神经网络结构设计
神经网络架构搜索(NAS)
[1] ScaleNet: Searching for the Model to Scale (ScaleNet:搜索要扩展的模型)
paper:https://arxiv.org/abs/2207.07267
code:https://github.com/luminolx/scalenet
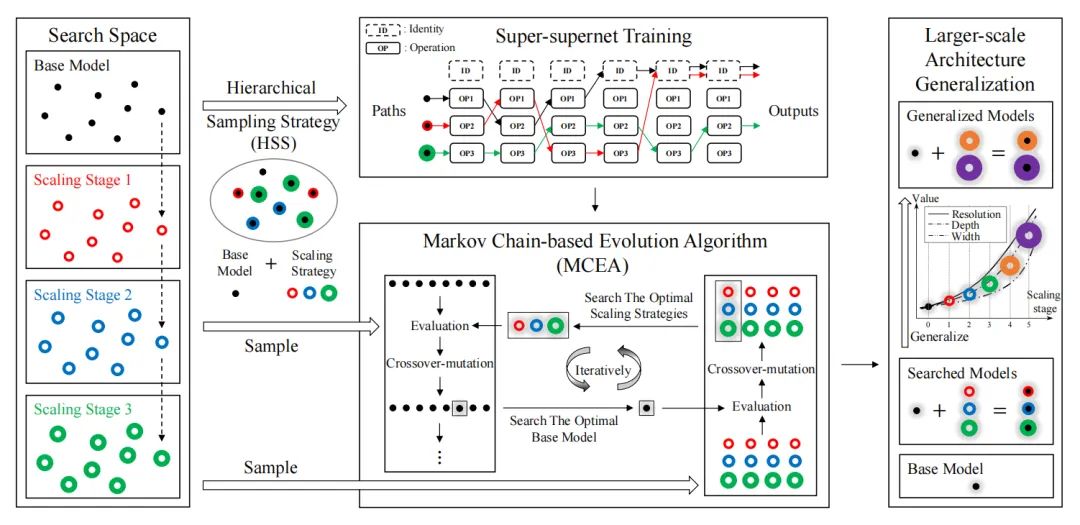
[2] Ensemble Knowledge Guided Sub-network Search and Fine-tuning for Filter Pruning (集成知识引导的子网络搜索和过滤器修剪微调)
paper:https://arxiv.org/abs/2203.02651
code:https://github.com/sseung0703/ekg
[3] EAGAN: Efficient Two-stage Evolutionary Architecture Search for GANs (EAGAN:GAN 的高效两阶段进化架构搜索)
paper:https://arxiv.org/abs/2111.15097
code:https://github.com/marsggbo/EAGAN
数据处理
归一化
whaosoft aiot http://143ai.com
[1] Fine-grained Data Distribution Alignment for Post-Training Quantization (训练后量化的细粒度数据分布对齐)
paper:https://arxiv.org/abs/2109.04186
code:https://github.com/zysxmu/fdda
模型训练/泛化
噪声标签
[1] Learning with Noisy Labels by Efficient Transition Matrix Estimation to Combat Label Miscorrection (通过有效的转移矩阵估计学习噪声标签以对抗标签错误校正)
paper:https://arxiv.org/abs/2111.14932

模型压缩
知识蒸馏
[1] Knowledge Condensation Distillation (知识浓缩蒸馏)
paper:https://arxiv.org/abs/2207.05409
code:https://github.com/dzy3/kcd)
模型评估
[1] Hierarchical Latent Structure for Multi-Modal Vehicle Trajectory Forecasting (多模式车辆轨迹预测的分层潜在结构)
paper:https://arxiv.org/abs/2207.04624
code:https://github.com/d1024choi/hlstrajforecast
半监督学习/无监督学习/自监督学习
[1] FedX: Unsupervised Federated Learning with Cross Knowledge Distillation (FedX:具有交叉知识蒸馏的无监督联合学习)
paper:https://arxiv.org/abs/2207.09158

[2] Synergistic Self-supervised and Quantization Learning (协同自监督和量化学习)
paper:https://arxiv.org/abs/2207.05432
code:https://github.com/megvii-research/ssql-eccv2022)
[3] Contrastive Deep Supervision (对比深度监督)
paper:https://arxiv.org/abs/2207.05306
code:https://github.com/archiplab-linfengzhang/contrastive-deep-supervision
[4] Dense Teacher: Dense Pseudo-Labels for Semi-supervised Object Detection (稠密教师:用于半监督目标检测的稠密伪标签)
paper:https://arxiv.org/abs/2207.02541
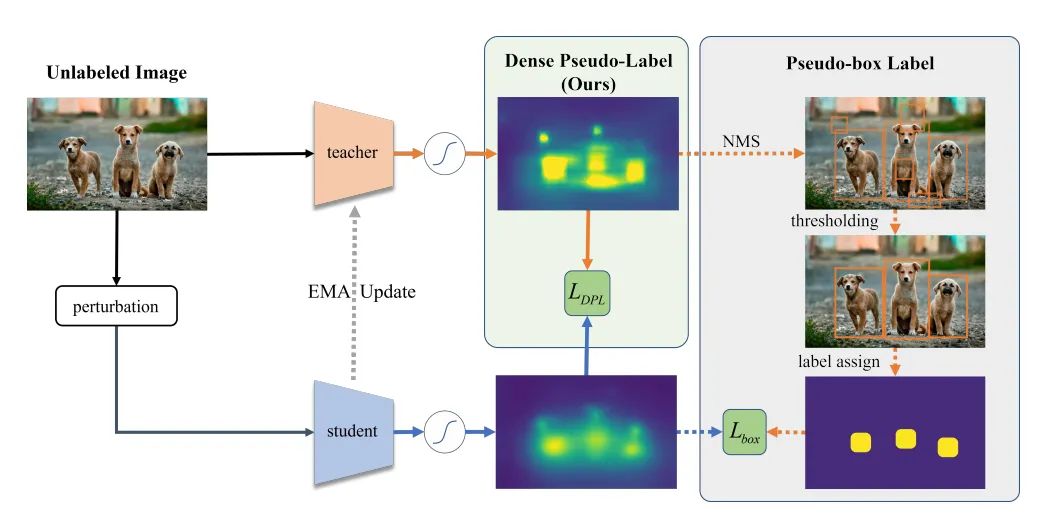
[5] Image Coding for Machines with Omnipotent Feature Learning (具有全能特征学习的机器的图像编码)
paper:https://arxiv.org/abs/2207.01932
多模态学习/跨模态
视觉-语言
[1] Contrastive Vision-Language Pre-training with Limited Resources (资源有限的对比视觉语言预训练)
paper:https://arxiv.org/abs/2112.09331
code:https://github.com/zerovl/zerovl
跨模态
[1] Cross-modal Prototype Driven Network for Radiology Report Generation (用于放射学报告生成的跨模式原型驱动网络)
paper:https://arxiv.org/abs/
code:https://github.com/markin-wang/xpronet

小样本学习
[1] Learning Instance and Task-Aware Dynamic Kernels for Few Shot Learning (用于少数镜头学习的学习实例和任务感知动态内核)
paper:https://arxiv.org/abs/2112.03494

迁移学习/自适应
[1] Factorizing Knowledge in Neural Networks (在神经网络中分解知识)
paper:https://arxiv.org/abs/2207.03337
code:https://github.com/adamdad/knowledgefactor
[2] CycDA: Unsupervised Cycle Domain Adaptation from Image to Video (CycDA:从图像到视频的无监督循环域自适应)
paper:https://arxiv.org/abs/2203.16244
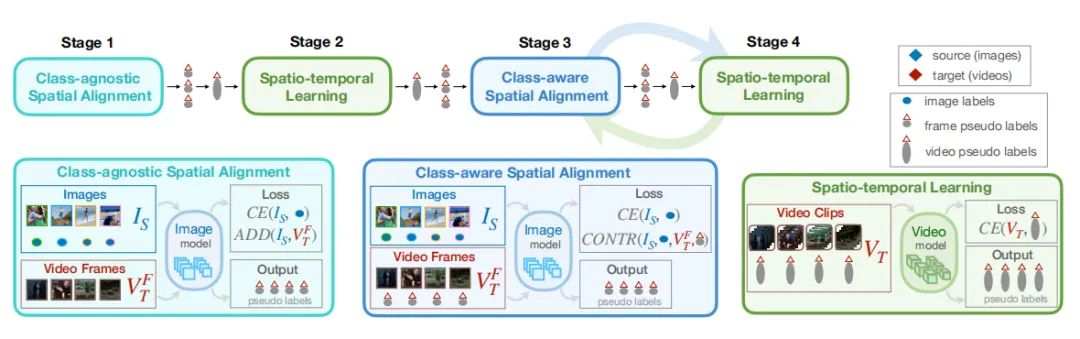
强化学习
延庆川北小区45孙老师 收卖废品破烂垃圾炒股 废品孙 再回收
[1] Target-absent Human Attention (目标缺失——人类注意力缺失)
paper:https://arxiv.org/abs/2207.01166
code:https://github.com/neouyghur/sess
## 序列置换的自回归Transformers
本文基于序列置换策略和自训练蒸馏两大创新构建一种高效的目标分割框架SPOT,SPOT可以改善基于slot注意力的自动编码器在复杂真实场景下的目标分割性能。
以目标为中心的深度学习方法(Object-Centric)需要将所见场景解析为可解释的目标实体,其中每个实体可以称为slot,表现形式通常为目标分割,作为计算机视觉领域中的一个重要任务,目标分割能够为目标跟踪、场景理解等高级视觉任务提供支持。为了摆脱需要大量标注数据的监督学习方法,近期的工作都聚焦于提升基于slot的无监督方法的性能。
本文介绍一篇发表在CVPR 2024上的论文,本文的研究团队来自雅典理工学院和valeo.ai等单位。本文深入分析了现有方法的所面临的关键挑战,即如何高效的指导编码器生成对应于独立目标的特定"slot"表示,尤其是对于复杂的现实世界图像。
为了应对这一挑战,本文在模型架构和训练等多个方面进行了探索创新,提出了一种称为SPOT的自回归Transformer,SPOT首先基于自训练的注意力蒸馏机制进行优化,可以直接从解码器生成的优质slot注意力掩码中抽取蒸馏知识,随后将其用于指导和优化编码器中的slot注意力模块,从而提升对象分割的精度。
随后SPOT设计了一种自回归解码器的序列置换策略,通过随机置换patch token的预测顺序,增强了解码器对slot向量的利用程度,从而产生更强的目标表示。大量的实验结果表明,上述多种策略能产生协同效应,使SPOT框架在无监督目标分割任务中达到SOTA性能。
论文链接:https://arxiv.org/abs/2312.00648
代码仓库:https://github.com/gkakogeorgiou/spot
一、引言
本文的研究目标是在无监督目标分割任务中提高基于slot方法的性能,以便能够更好的处理复杂的真实世界图像。先前的工作通常使用基于自编码器的无监督学习框架,尤其是基于slot注意力自动编码器(slot-based auto-encoders)的方法逐渐成为主流范式。这类方法首先对图像编码得到一组slot向量,再由解码器根据这些向量重构出原始图像,从而学习对应于不同目标的分割掩码。然而这种方法在处理复杂真实图像时仍然存在一些缺陷,比如分割精度较低、过度分割等问题。本文提出的SPOT框架旨在探索该类方法的运行机理,提升模型的综合性能。具体来说,作者希望解决以下两个关键问题:
-
如何提高编码器生成的slot对应的注意力掩码质量,使得每个Slot能够更好地聚焦于单个目标物体。
-
增强解码器在重构图像时利用slot信息的效率,避免过度依赖输入序列本身,从而提高模型的鲁棒性。

上图展示了SPOT框架在无监督情况下对复杂真实图像的分割效果,基于本文设计的自训练注意力蒸馏机制和自回归序列置换策略,SPOT改进了特定目标的slot向量生成效果,实现了高效的无监督目标解析效果。
二、本文方法
2.1 基于slot的自动编码器架构
本文提出的SPOT仍然遵循先前的Slot-based auto-encoder架构,这是目前无监督对象分割任务中的主流范式,该框架由编码器和解码器两个核心组件组成。
2.1.1 编码器

2.1.2 解码器

2.2 基于自训练的slot注意力蒸馏机制

因此,作者提出了一种基于自训练蒸馏的方法,方法过程如上图所示,该方法可以将解码器产生的注意力掩码信息递给编码器,以增强编码器生成的 slot 向量和对应注意力掩码的对象特异性。具体地,该自训练过程分两个阶段进行:

2.3 自回归解码器的序列置换策略
尽管自回归Transformer解码器在处理全局信息时表现出色,但作者通过实验发现它在训练过程中往往过度依赖于解码历史(已生成的patch token),而忽视了来自编码器的slot信息。这种现象会削弱slot向量对模型训练的作用,影响最终的对象分割质量。
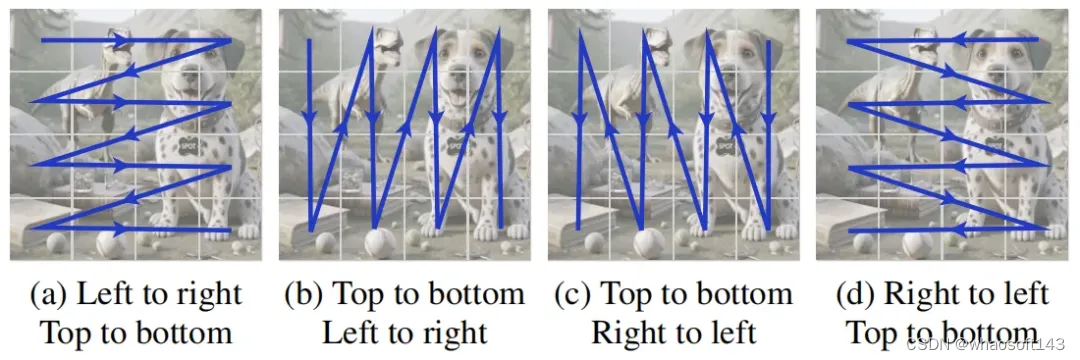

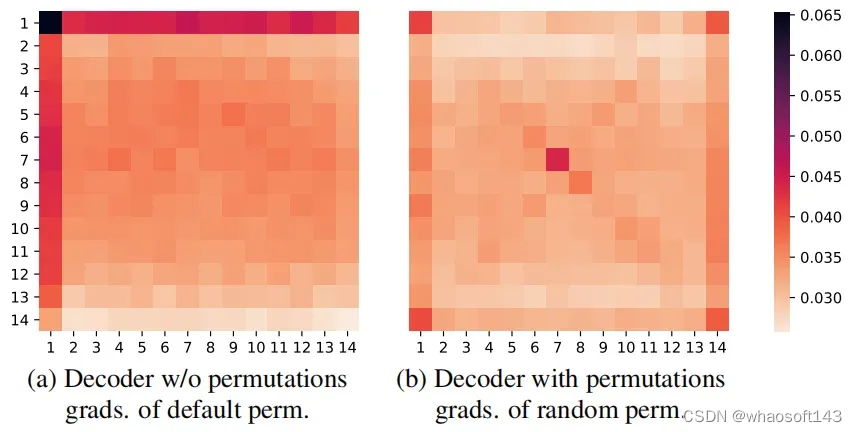
序列置换策略的关键在于打破了自回归解码器对解码历史的过度依赖。在某些置换模式下,原本处于后面位置的 patch token 现在需要首先被预测,这就迫使解码器必须充分利用slot向量信息进行全局推理。作者通过上图展示的可视化实验验证了这一点,在进行序列置换后,各 patch 重建损失相对于 slot 向量的梯度更加均匀,而不再过于集中在首个几行和几列的 patch 上。
三、实验效果
本文的实验在COCO 2017、PASCAL VOC 2012、MOVi-C和MOVi-E四个数据集上进行,其中后两者是合成数据集,包含了多个场景中的3D扫描目标。实验的评价指标使用MBO、MIoU和FG-ARI,其中MBO和MIoU可以更全面地评估目标分割的质量。在模型实验上,作者使用Vision Transformer(ViT)编码器和4层自回归Transformer的解码器。
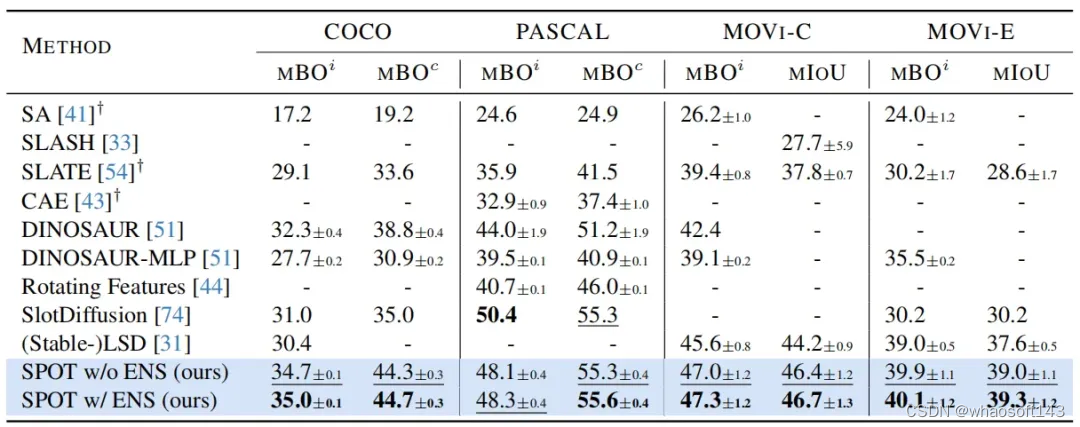
上表展示了本文SPOT框架在四个数据集上的实验结果,与其他方法相比,SPOT在所有数据集上均取得了SOTA或接近SOTA的表现,尤其在COCO上,SPOT在MBO和MIoU评估指标上分别比之前的SOTA结果高出2.7和5.9个百分点。这说明SPOT对复杂场景下的无监督对象分割有着显著的改进效果。

除此之外,作者还给出了一些SPOT的定性分割结果,如上图所示,SPOT可以灵活的应对各种复杂场景,能够较好地分割出个体目标,缓解之前框架过度分割的问题。

为了评估SPOT中各个模块的有效性,作者进行了详实的消融实验,实验结果如上表所示。其中SP代表序列置换策略,ST代表自训练,ENS代表整合多次置换后的效果,从表中我们可以看出,序列置换策略可以有效提升自回归解码器的性能,同时序列置换策略与自训练之间的协同也非常关键,如果不使用序列置换,自训练反而会降低解码器的性能。
四、总结
本文基于序列置换策略和自训练蒸馏两大创新构建一种高效的目标分割框架SPOT,SPOT可以改善基于slot注意力的自动编码器在复杂真实场景下的目标分割性能。其中自训练策略蒸馏了解码器注意力模块的更优分割表征,提高了编码器生成目标特异性slot的能力。而序列置换策略则增强了自回归解码器对slot向量的利用,产生了更强的目标表示。两种策略的协同应用使 SPOT 在各种真实和合成数据集上获得了新的SOTA性能。
参考资料
[1] Harold W Kuhn. The hungarian method for the assignment problem. Naval Research Logistics Quarterly, 2(1-2):83–97, 1955. 4
-------
Taobao 天皓智联 whaosoft aiot http://143ai.com


