
- 1机器学习实践(2.2)LightGBM回归任务
- 2搜索广告召回技术在美团的实践_美团 多模态生成式向量召回
- 3iOS 警告收集快速消除
- 4真实靠谱:百度的职级、T系列、薪资、及晋升潜规则
- 5Python之序列_python序列
- 6【OpenCV】图像/视频相似度测量PSNR( Peak signal-to-noise ratio) and SSIM,视频/图片转换
- 7最新php淘宝客优惠券网站源码
- 8面试题009-Java-MyBatis
- 9解决:安装MySQL 5.7 的时候报错:unknown variable ‘mysqlx_port=0.0‘_mysqlx-port
- 10大模型推理:vllm多机多卡分布式本地部署_vllm 多卡推理
Text-to-3D 任务论文笔记: Latent NeRF_text to 3d
赞
踩
概述
论文链接: https://arxiv.org/pdf/2211.07600.pdf
这篇文章做的task可以简单分为三个:
- 直接用文本生成3D;
- 用一个所谓的Sketch-Shape,让用户定义基础形状,然后加上文本,共同去引导生成3D;(Latent-NeRF主体)
- 用户给定mesh,可以给uv参数,也可以不给,然后引导latent-NeRF去给这个Mesh补充上纹理。(所谓的Latent-Paint)
其中,比较吸引我眼球的是第二点和第三点,实用性比较大,一个是使得输出的形状可控,再一个是能够使得在已有mesh的基础上用户自定义地去贴不同的皮。可玩性高,
相关工作
3D形状合成
3D形状合成一直是计算机图形学和计算机视觉领域的难题。近年来,随着神经网络的出现,3D建模的研究取得了巨大进展。
最常见的监督类型是直接对3D形状进行监督,通过不同的表示形式,如隐式函数、网格或点云。
然而,由于3D监督通常很难获得,其他研究使用图像来引导生成任务。事实上,即使有3D数据可用,有时也会选择2D渲染作为监督。
例如,在GET3D中,训练了两个生成器,一个生成3D SDF,另一个生成纹理场。然后,通过使用DMTet以可微分的方式获得输出带纹理的网格。值得关注的时,这些生成器就是通过2D图像数据集进行对抗训练的。
此外,在[47]中,扩散模型也已用于生成给定输入图像的多个视图。然而,它是在多视图数据集上以监督方式训练的,而我们的工作完全不需要数据集。
使用2D监督的text-to-3D 任务
最近,文本引导合成在许多领域中取得了成功,这激发了许多使用语言-图像模型来指导3D场景表示的工作。
CLIP-Forge由两个独立的组件组成,一个是基于形状代码的隐式自编码器,另一个是训练生成形状代码的归一化流模型。CLIP-Forge利用了CLIP具有联合文本-图像嵌入空间的特性,以在图像嵌入上进行训练并在文本嵌入上进行推断,实现了文本到形状的能力。
Text2Mesh 通过可微渲染和CLIP指导引入了网格着色和几何微调。
TANGO遵循类似的优化方案,同时通过考虑显式着色模型(explicit shading model)来改善结果。
CLIP-Mesh根据目标文本提示优化初始球形网格,使用修改后的CLIP损失考虑图像/文本CLIP嵌入之间的差距和歧义。与我们的方法类似,他们还使用UV纹理映射将颜色烘焙到网格中。
DreamFields也使用CLIP指导,但使用NeRFs代替显式三角形网格来表示3D对象,并且使用了专用的稀疏性损失。
CLIPNeRF在渲染的对象数据集上预训练了一个可分离的NeRF网络,然后在CLIP损失下约束NeRF场景优化。
DreamFusion首次引入了广泛成功的预训练2D扩散模型用于文本引导的3D对象生成。DreamFusion使用专有的2D扩散模型来监督由NeRF表示的3D对象的生成。为了使用预训练的扩散模型指导NeRF场景,作者推导出一个得分蒸馏损失(Score-Distiliiation loss),这个概念非常重要,数学表达是:
∇
x
L
S
D
S
=
w
(
t
)
(
ϵ
ϕ
(
x
t
,
t
,
T
)
−
ϵ
)
\nabla_{x} L_{S D S}=w(t)\left(\epsilon_{\phi}\left(x_{t}, t, T\right)-\epsilon\right)
∇xLSDS=w(t)(ϵϕ(xt,t,T)−ϵ)
具体细节见后文。
方法
整体方法流程图为:
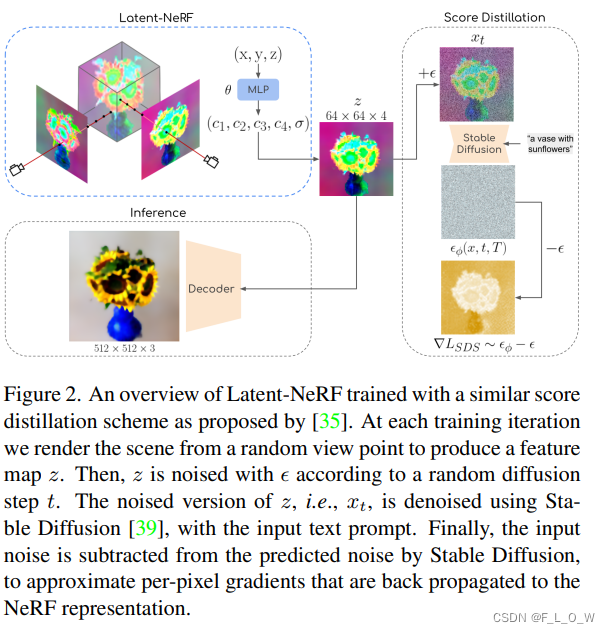
它使用类似于[35]提出的分数蒸馏方案进行训练。
在每个训练迭代中,均会从随机视点渲染场景以生成特征
z
z
z。然后,根据随机扩散步骤
t
t
t,
z
z
z会被噪声化。
使用输入文本提示和Stable Diffusion [39]对噪声版本的
z
z
z(即
x
t
x_t
xt)进行去噪。最后,stable diffusion预测的噪声减去输入的噪声,以近似每个像素的梯度,且这每个近似的梯度会被反向传播给NeRF表达。
前置知识
LDM
潜在扩散模型(LDM)[39]是扩散模型的一种特殊形式,
往往被训练用来对预训练自编码器(pretrained autoencoder)的潜在编码(latent codes)去噪,而不是直接对高分辨率图像去噪。
步骤一: 首先,训练一个由编码器 E \mathcal{E} E 和解码器 D D D 组成的自编码器,用来重建自然图像 x x x ~ X X X,其中 X X X为图像训练数据集,数学表达为 x ~ = D ( E ( x ) ) \tilde{x}=\mathcal{D}(\mathcal{E}(x)) x~=D(E(x))。
相当于从训练数据集中抽取一张图像,先对其进行编码,再对其进行解码。
该自编码器使用重建损失、感知损失[54]和基于补丁的对抗损失[22]进行训练。
步骤二: 然后,给定训练好的自编码器,训练一个去噪扩散概率模型(DDPM)[21],
【问】 自编码器与DDPM的关系是什么?请查阅文献[21]
根据 z = E ( x ) s.t. x ∼ X z = \mathcal{E}(x) \text { s.t. } x \sim X z=E(x) s.t. x∼X 的分布,
这里的 E \mathcal{E} E通常指代噪声预测器
从噪声中生成一个spatial latent z z z。
为了生成新图像,使用训练好的DDPM从学习到的分布中采样 latent z ~ \tilde{z} z~,并将其传递给解码器以获得最终图像 D ( z ~ ) \mathcal{D}(\tilde{z}) D(z~)。
在潜在空间中操作所需的计算量更少,训练和采样速度更快,这使得LDM得到了广泛的应用。
事实上,最近大火的stable diffusion 本质上也是一个LDM。
Score Distillation
Score Distillation是一种能够使用扩散模型作为测度的方法,即,直接使用它作为损失,而不需要通过扩散过程明确地反向传播。
它已经被引入到DreamFusion[35]中,用于指导使用Imagen模型[40]的3D生成。
Imagen应用于文本生成图片,其采用了级联超分,可生成1024分辨率高清大图,效果优于CLIP。基于此内容进一步开发了Imagen editing和Imagen video。
为了使用Score Distillation,首先将噪声添加到给定的图像中(例如,NeRF输出的一个视图);
然后,利用扩散模型对加噪图像中的附加噪声进行预测;
最后,利用预测噪声和添加噪声之间的差值计算逐像素梯度。
对于NeRF而言,梯度会被反向传播以更新3D NeRF模型。
在每一次Score Distillation优化的迭代过程中,一张渲染图 x x x在时间 t t t时的加噪 数学表达为:
x t = α t ‾ x + 1 − α t ‾ ϵ x_{t}=\sqrt{\overline{\alpha_{t}}} x+\sqrt{1-\overline{\alpha_{t}}} \epsilon xt=αt x+1−αt ϵ
其中,有:

此时,每一个像素的score distillation梯度就可以表示为:
∇ x L S D S = w ( t ) ( ϵ ϕ ( x t , t , T ) − ϵ ) \nabla_{x} L_{S D S}=w(t)\left(\epsilon_{\phi}\left(x_{t}, t, T\right)-\epsilon\right) ∇xLSDS=w(t)(ϵϕ(xt,t,T)−ϵ)
ϵ ϕ \epsilon_{\phi} ϵϕ是扩散模型的去噪器,用来估计需要被去除的噪声, ϕ \phi ϕ是去噪器的参数, T T T是可选的引导文本, w ( t ) w(t) w(t)是一个取决于 α t \alpha_t αt的常乘数因子。
Latent NeRF
NeRF模型在stable diffusion的latent space
Z
\mathcal{Z}
Z空间内进行2D特征图的渲染。
Latent-NeRF输出四个伪彩色通道
(
c
1
,
c
2
,
c
3
,
c
4
)
(c_1, c_2, c_3, c_4)
(c1,c2,c3,c4),分别对应stable diffusion所需要的四个潜在特征,同时,还输出一个体密度
σ
\sigma
σ:
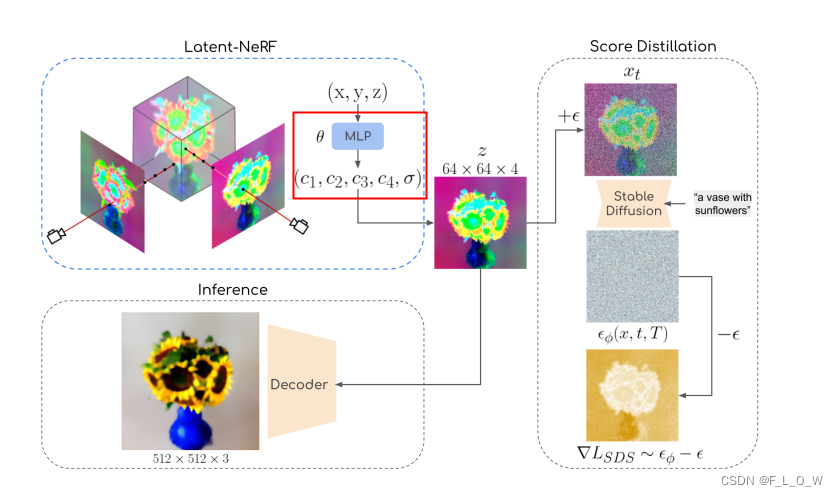
使用NeRF对场景进行表达的时候,其实已经隐式地在不同视角下施加了空间一致性。
然而,使用NeRF去表达 Z \mathcal{Z} Z并不是一件简单的事情。
先前的研究[1,45]表明, Z \mathcal{Z} Z 中的超像素主要依赖于输出图像中的单个patch。这可以归因于该潜在空间的高分辨率(64 × 64)和低通道深度(4),这鼓励了自编码器图像与潜在空间之间的局部依赖性。
如果说 Z \mathcal{Z} Z是对应RGB图像的近patch级别的表达的话,那么意味着latents基本上可以认为是场景的某种空间变化,这也就进一步地说明NeRF可以去合理表达这样的三维场景。
文本引导
Latent-NeRF的普通版本就是文本引导的,loss的形式是:
L = λ S D S L S D S + λ sparse L sparse L=\lambda_{S D S} L_{S D S}+\lambda_{\text {sparse }} L_{\text {sparse }} L=λSDSLSDS+λsparse Lsparse
注意,这个损失函数的具体数值无法被获取,但是其梯度能够通过去噪器的一个单向forward pass得到。
【问】 为什么?
且有:
L
sparse
=
B
E
(
w
blend
)
L_{\text {sparse }}=B E\left(w_{\text {blend }}\right)
Lsparse =BE(wblend )
L
s
p
a
r
s
e
L_{sparse}
Lsparse的好处是能够避免floating的”radiance clouds“,或者你可以这样理解,这个损失函数鼓励NeRF实现更理想的object NeRF与background NeRF之间的blending。
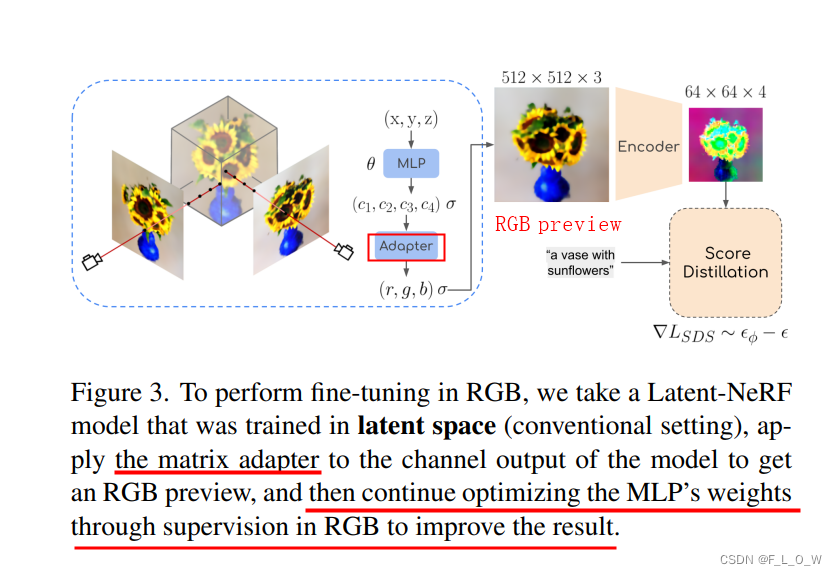
RGB refinement
需要将latent空间的NeRF转换成RGB空间中的NeRF。
这就需要将latent 空间的NeRF所输出的4个latent通道转换成3个RGB通道。
这样就可以使得初始渲染(应用至latent空间)得到的RGB图更能够接近decoder的输出,
有趣的是,[45]表示可以直接将4通道的输出通过以下数学转换公式,转换为三通道的RGB值:
(
r
^
g
^
b
^
)
=
(
0.298
0.187
−
0.158
−
0.184
0.207
0.286
0.189
−
0.271
0.208
0.173
0.264
−
0.473
)
(
c
1
c
2
c
3
c
4
)
,
\left(
具体实现的话,直接加一个线性层就好了。且这个用于转换的线性层直接和后边的模型一起进行finetune。
线性层的相关代码实现是:
self.linear_rgb_estimator = torch.tensor([
# R G B
[0.298, 0.207, 0.208], # L1
[0.187, 0.286, 0.173], # L2
[-0.158, 0.189, 0.264], # L3
[-0.184, -0.271, -0.473], # L4
]).to(self.device)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
整个finetuning的过程为:
Sketch-Shape Guidance
所谓的sketch-shape,指代一些简单的3D图元,比如说球体,箱体,圆柱体等。
期望:

损失函数的数学表达为:
L
S
k
e
t
c
h
−
S
h
a
p
e
=
C
E
(
α
N
e
R
F
(
p
)
,
α
G
T
(
p
)
)
⋅
(
1
−
e
−
d
2
2
σ
S
)
L_{S k e t c h-S h a p e}=C E\left(\alpha_{N e R F}(p), \alpha_{G T}(p)\right) \cdot\left(1-e^{-\frac{d^2}{2 \sigma_S}}\right)
LSketch−Shape=CE(αNeRF(p),αGT(p))⋅(1−e−2σSd2)
这个损失的后半部分其实是一个高斯核函数,绘制出图案后大概是:
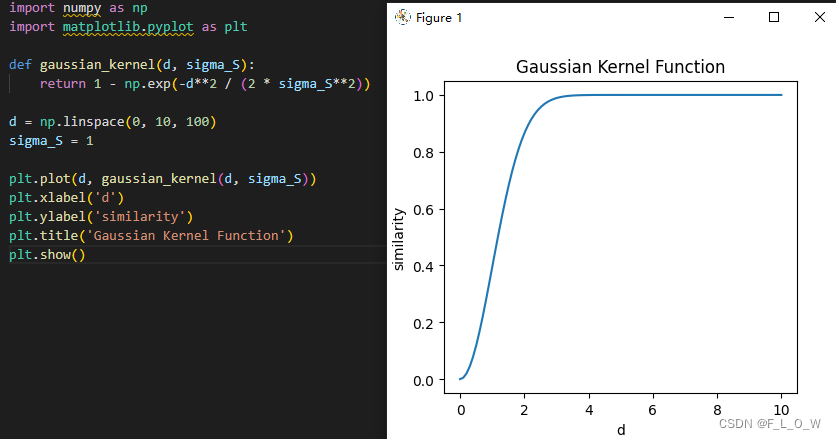
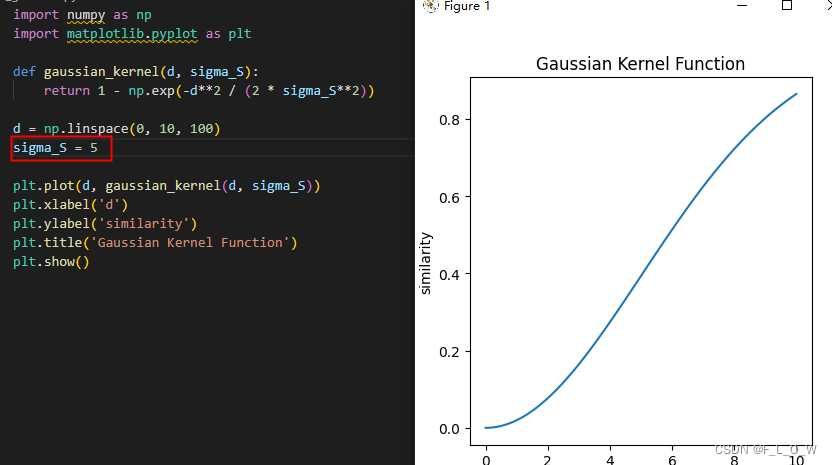
文章也做了关于
σ
S
\sigma_S
σS的消融实验:
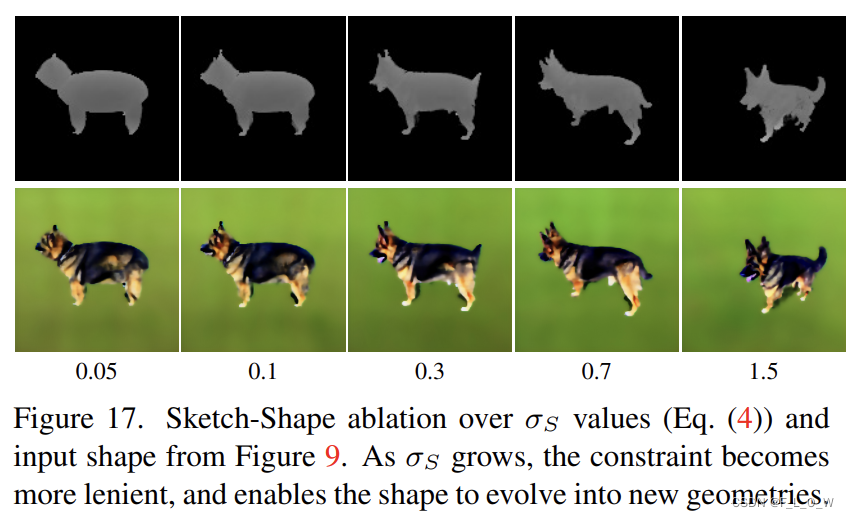
图 17中使用的条件shape是: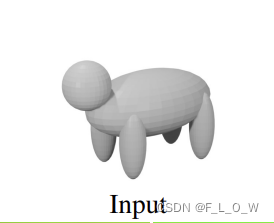
这个损失函数,希望距离表面越远的部分被损失限制的越好,而在越近的地方,则越受 score distillation的影响。
在这个公式中,有:
p
p
p是点云集合,这些点云集合都将被用于NeRF的体渲染中;
d
d
d代表
p
p
p中的点云距离物体表面的距离;
σ
S
\sigma_S
σS是一个超参数,在上面的两张图里也展现了这个参数对于高斯核的调节情况,总的来说,可以理解为,更小的
σ
S
\sigma_S
σS所实施的约束会更加严格。
当这个损失函数仅仅被应用在采样的点云集合 p p p里面的时候,能够使得效率变得更高,因为这些采样点已经作为Latent-NeRF渲染过程中的一部分进行过评估。
对于显式形状的Latent-Paint
考虑这样一种强限制的场景,已经给定了确定的mesh,我们现在只是希望给他更换一些贴图,或者说赋予一些贴图。
我们的方法主要通过UV纹理图来生成贴图,这个UV图既可以通过输入的mesh来提供,也可以通过XAtalas实时地提供。
为了对一个mesh进行着色,我们首先初始化了一个随机的latent纹理图像,并且这个纹理图像的前面两个维度的大小与我们最终希望的纹理图像大小是一致的,但是通道数是4,就是说这个latent纹理图像整体的维度是
H
∗
W
∗
4
H * W * 4
H∗W∗4。
在具体的实验里,
H
H
H和
W
W
W都被设为了128。
这张图是整个训练过程的示意:

在每一次迭代中,网格都会被一个可微的渲染器进行渲染。渲染的输出是一个随机视角下的特征图,特征图的大小是
64
∗
64
∗
4
64 * 64 * 4
64∗64∗4。
分数蒸馏就被用在这张渲染的特征图上面,并且这个梯度将会通过可微的渲染器被反向传播到latent纹理图像上。
然后我们一样去使用分数蒸馏的损失函数:
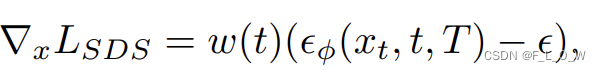
然而不同于之前把这个损失函数反向传播给NeRF的MLP参数,这里是在可微的渲染器之间进行反向传播,目标是去优化这一张texture image。
为了得到最终的RGB纹理图像,我们的做法是:将这一张latent 纹理图像喂给stable distribution的解码器
D
\mathcal{D}
D。
实验
实验细节
Stable diffusion的实现主要是基于HuggingFace diffuses,使用的checkpoint是v1-4。
score distillation使用的代码主要基于[43]。
NeRF模型采用的是[31]。
在单张V100上,15分钟内收敛。如果使用RGB-NeRF以及sd的话,则大约需要30分钟收敛。相比起dreamfusion而言,效率要高。
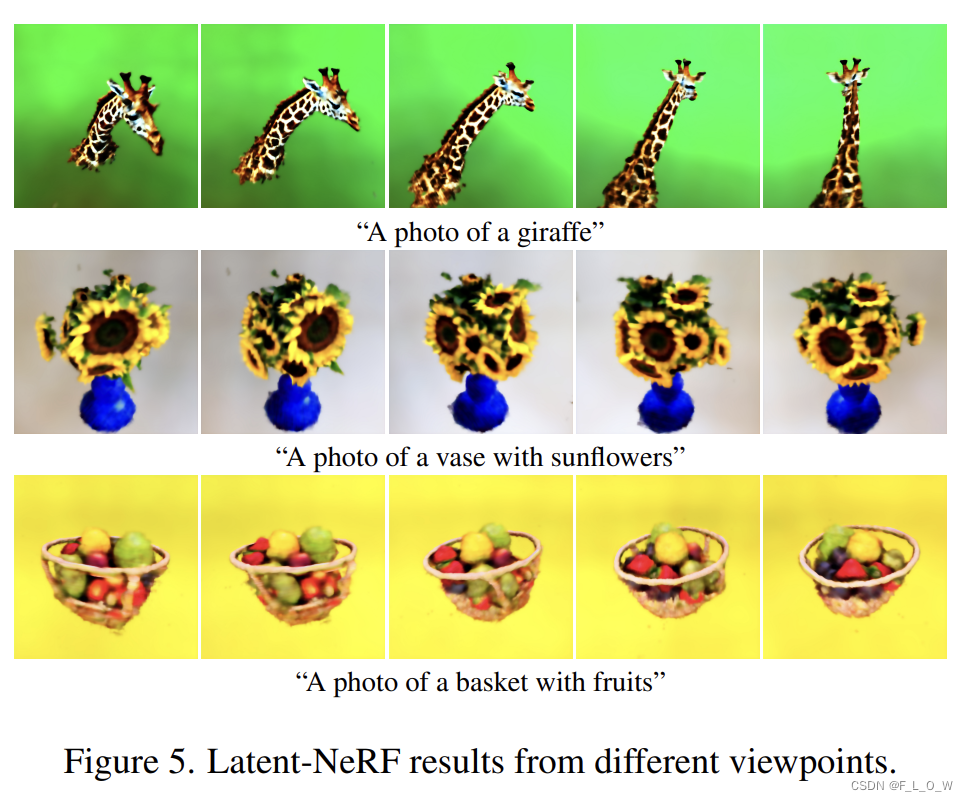
文本引导的生成
在图5中,体现了方法所生成的不同视角之间的一致性:
在图6中,显然可以看到本文效果比DreamFields以及CLIPMesh要好,但似乎没有Dreamfusion好(可能是因为其使用了Imagen):
其实看起来感觉依然不是很好

RGB Refinement
RGB Refinement对于复杂物体或者区域会更有用一些。
但是,在RGB空间,相对于在latent space里面,会慢一倍。
不过,得益于从latent到rgb的线性转换层,rgb refinement可以在3D形状已经基本收敛之后再进行。

Textual-Inversion
因为这个方法实际上是基于stable diffusion去做监督的,所以我们也可以使用Textual-Inversion[16] tokens来作为输入文本的一部分。
这将有助于控制物体的生成类别以及风格仅仅由输入图像来进行定义。
具体效果见:

Sketch-Shape Guidance
Sketch由blender进行快速定义。
实验效果图有:



Latent-Paint 生成
图12、13的实验都不带有预先计算的UV参数,文章使用XAtlas[52]来自动生成UV参数。


相反,图15中则已经输入已经带有UV参数化的mesh:

尽管说,可以直接通过优化每一个面的latent属性,进而直接计算任何一个UV Map。
但是,实验仍然发现,如果能够预先输入UV参数,效果会更好,主要原因是:
- UV图使得纹理贴图的粒度能够独立于几何分辨率,也就是说,即使是粗糙的几何,也并不会得到粗糙的着色效果;
- 纹理图会易于在下流应用中被使用,如MeshLab或者Blender。
Limitations
加些直白的文本引导可能效果会好些(比如说front,side之类的文本),但是效果仍然会受限于stable diffusion的效果:

此外,还会因为sd设置的seed不同,而得到截然不同的结果。
参考文献
- 感知损失 [54] : The unreasonable effectiveness of deep features as a perceptual metric. (2018)
- 基于补丁的对抗损失[22]:Image-to-image translation with conditional adversarial networks (2017)
- 去噪扩散概率模型(DDPM)[21]: Denoising diffusion probabilistic models (2020)
- DreamFusion[35] 包括分数蒸馏的具体推导: Dreamfusion: Text-to-3d using 2d diffusion
- Imagen模型[40]: Photorealistic text-to-image diffusion models with deep language understanding (2022)
-
L
s
p
a
r
s
e
L_{sparse}
Lsparse [43],也提供了score distillation的代码: A pytorch implementation of the text-to-3d
model dreamfusion, powered by the stable diffusion text-to-2d model. https://github.com/ashawkey/stable-dreamfusion, 2022 - 四通道latent与三通道RGB之间的转换 [45]: Decoding latents to rgb without upscaling. https://discuss.huggingface.co/t/decoding-latents-torgb-without-upscaling/23204
- winding-number [3, 23]: Fast winding numbers for soups and clouds. ACM Transactions on Graphics (TOG);Robust inside-outside segmentation using generalized winding numbers. ACM Transactions on Graphics (TOG)
- XAtlas[52]: Mesh parameterization / uv unwrapping library. https://github.com/jpcy/xatlas, 2022
- Textual-Inversion[16]: An image is worth one word: Personalizing text-to-image generation using textual inversion.
写在最后
我们最近创建了一个“三维重建技术动向与商业落地”的知识星球,这个星球汇聚了来自国内985和国际顶级学府的专家和学者,他们分享了最新的三维重建技术和商业应用的前沿知识和经验。
如果你对三维重建领域感兴趣,那么这个知识星球是你不可错过的。通过加入这个知识星球,你可以学习到最新的三维重建技术和商业应用,提高自己的技能和认知。
同时,如果你是一个三维重建领域的专家,你也可以在这个知识星球上分享自己的知识和经验,让更多的人受益。我们会追踪最新的AIGC与3D的技术,并试图从投资人、技术人、产品人以及用户的视角提出一些看法。加入知识星球,让我们一起探索三维重建领域的商业落地想法和前沿知识!如果你想加入这个知识星球,可以添加我的微信号(zhuanshanqwer),我会免费为你提供名额(我们目前期望打造一个免费的、高质量的信息资讯平台,最终的期望是充分实现三维重建技术转化,加速应用落地开花)。

