
- 1AI、ML 和数据工程 | InfoQ 趋势报告(2021 年)_deepspeed kubeflow
- 2neo4j操作_neo4j 怎么启动
- 3添加、删除、数据绑定、登录、修改的实现
- 4SQL Server 常用语句介绍_sql语句 server
- 5手撕LLM,弄懂这些,你大模型就算入门了
- 6项目:基于Python的人脸识别 算法:LBPH算法 环境:Windows或linux或mac、pycharm ?_人脸识别-局部二值模式直方图创建一个人脸识别器
- 7springboot026基于SpringBoot的在线文档管理系统的设计与实现_springboot 怎么管理 文档和代码
- 8win10 + cpu + pycharm + mindspore_pycharm mindspore
- 9浙江大学软件学院_浙大软院和北邮计算机
- 10【计算机网络基础篇】学习笔记系列之二《游览器输入URL后发生了什么?》_浏览器访问url后发生了什么 路由器 交换机
图解Vit 2:Vision Transformer——视觉问题中的注意力机制_vit注意力机制图解
赞
踩
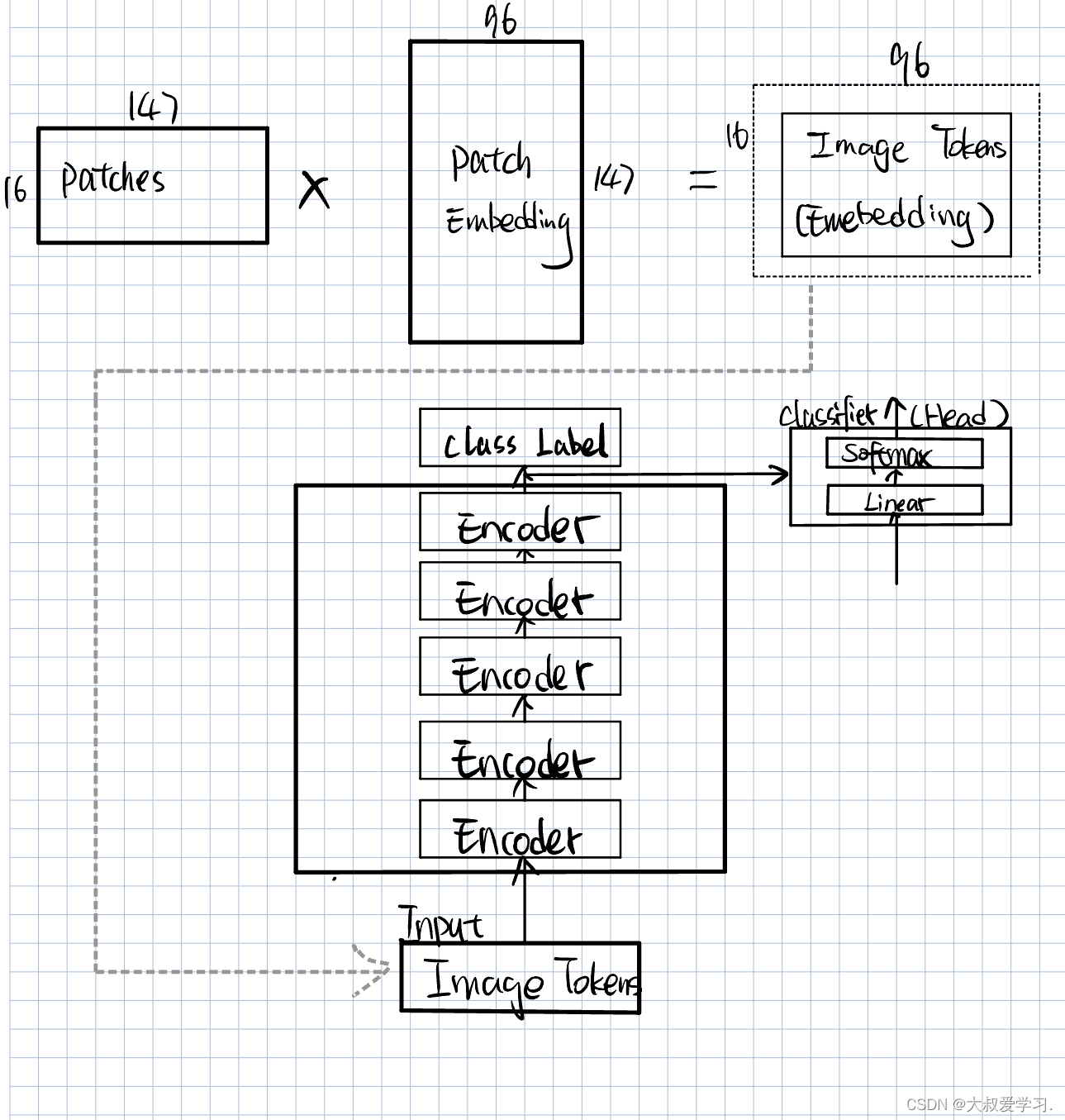
Patch Embedding 回顾
上节回顾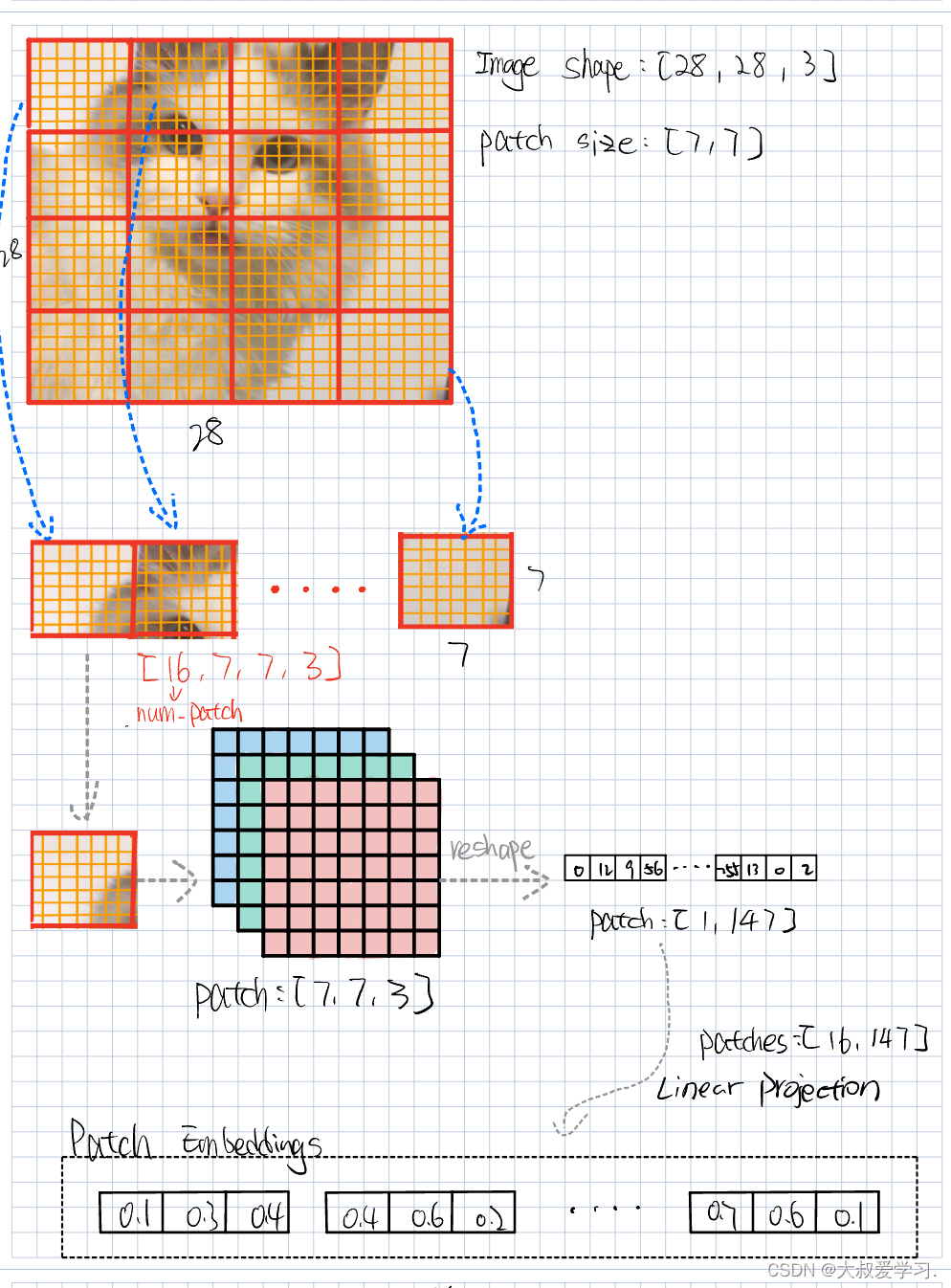
Seq2Seq中的attention
在Transformer之前的RNN,其实已经用到了注意力机制。Seq2Seq。
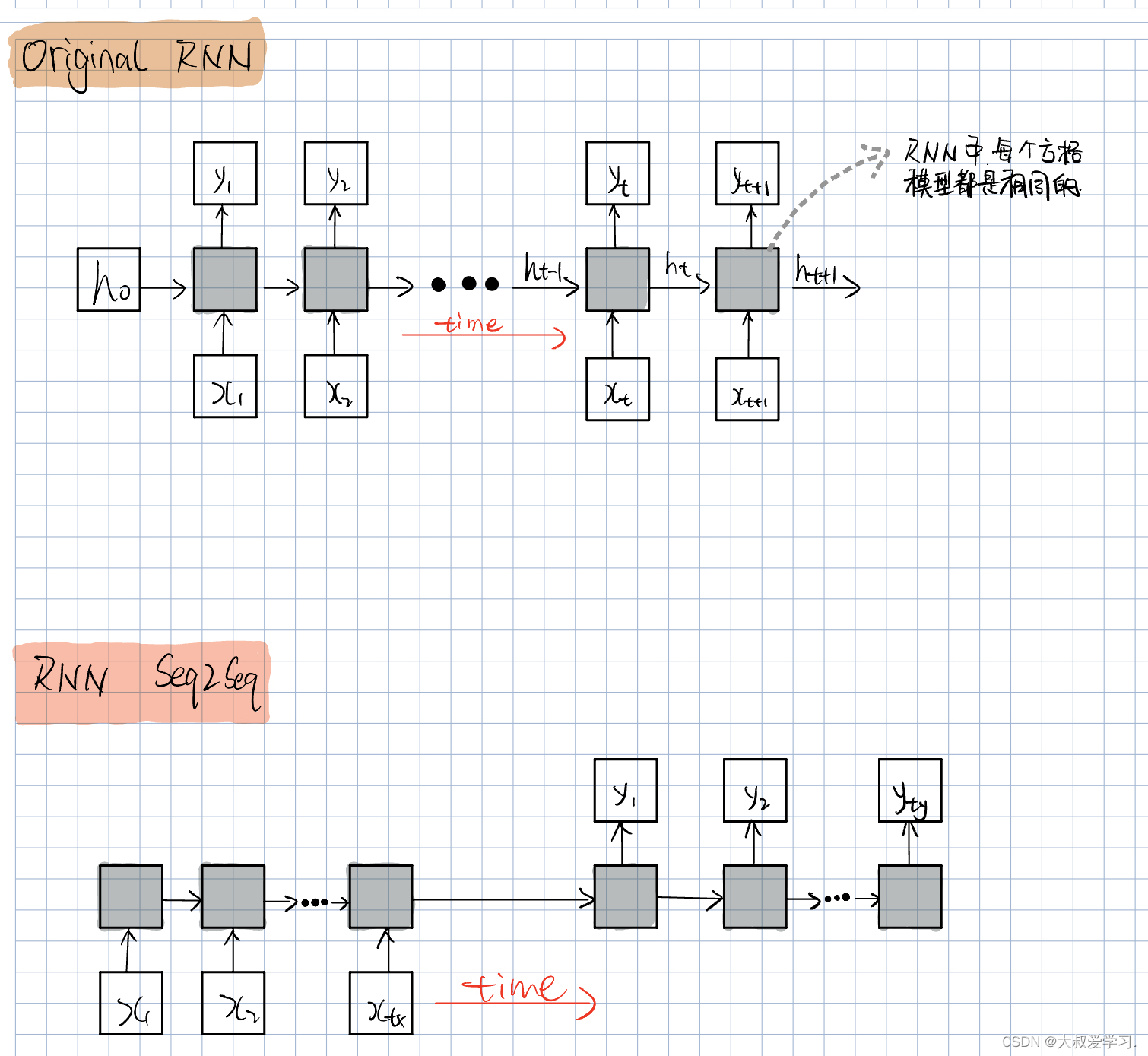
对于Original RNN,每个RNN的输入,都是对应一个输出。对于original RNN,他的输入和输出必须是一样的。
在处理不是一对一的问题时,提出了RNN Seq2Seq。也就是在前面先输入整体,然后再依次把对应的输出出来。
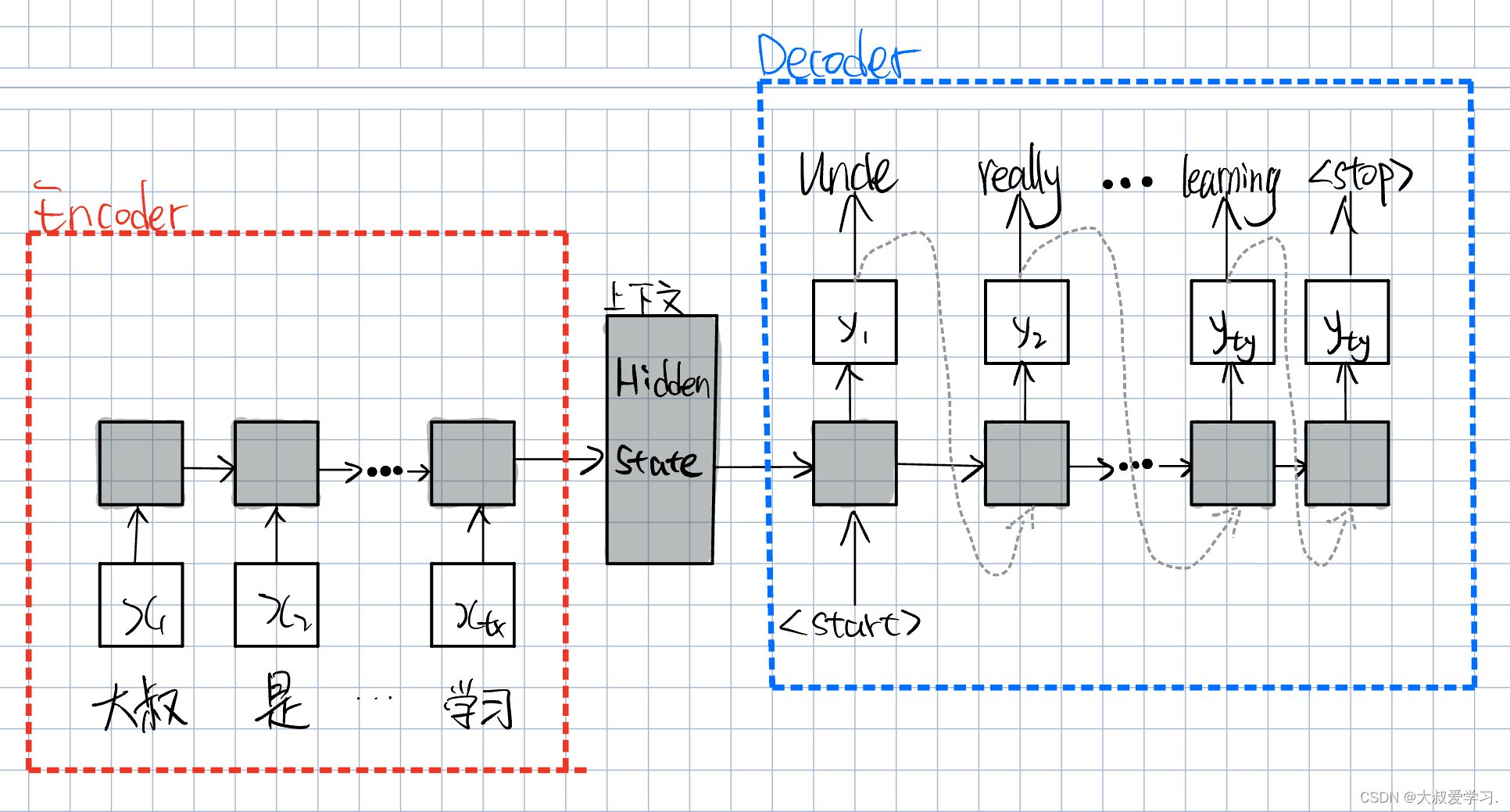
虽然Seq2Seq解决了输入和输出不定是相同长度的问题,但是我们所有信息都存在模型的一定地方,我们叫上下文,或者叫hidden state。又由于输入的都是同一个模型,每次都更新同一个位置,那么当我们的句子很长,或者是一个段落时,可能这个上下文就不会work,因为我们decoder的所有信息都是来自上下文的。效果不够好。把很多信息输入,就是encoder。后面把上下文信息解析出来,就是decoder。
很多学者想了办法去改进它。希望把前面时间段的信息,传递给解码decoder的时候。如下图所示。
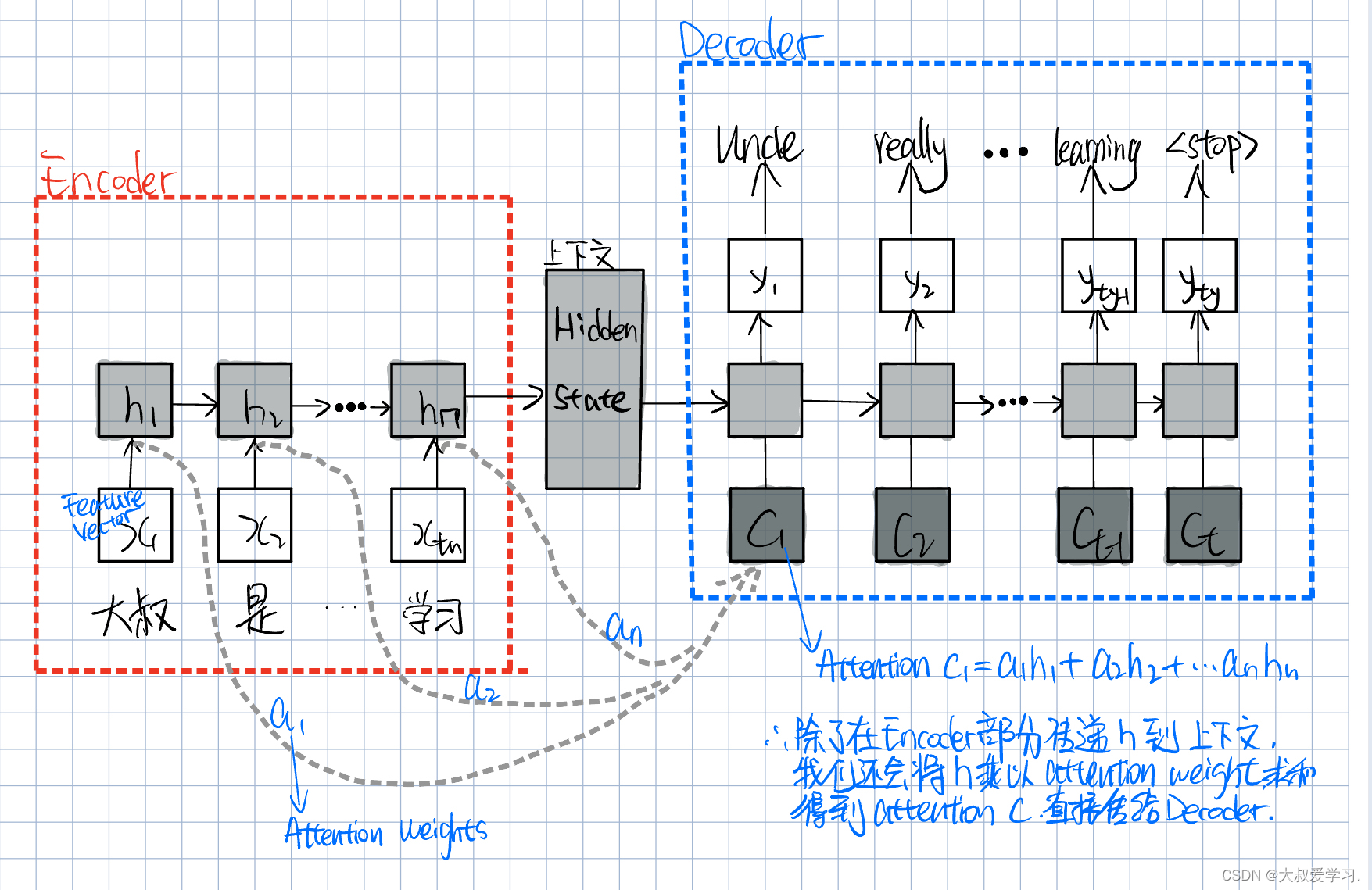
我们除了在encoder的部分传递h,还会多存一份p,直接传给decoder。
RNN每次都是传递一个h。h是隐变量,高层的语义信息。c就是attention。它等于前面所有时间点的语义信息分别乘以a,再sum。c看到了前面的所有时间点,如果是一个句子,就是看到了句子里的所有token。c看到了h1-hn。那它看到的谁更重要,是a1-an控制的。那么a应该怎么设置呢?最好的办法是,是让a可学习。即通过大量的句子数据训练一个网络,让c1明白,他应该更关注前面句子里的哪个token,哪个token的a就是最大的。
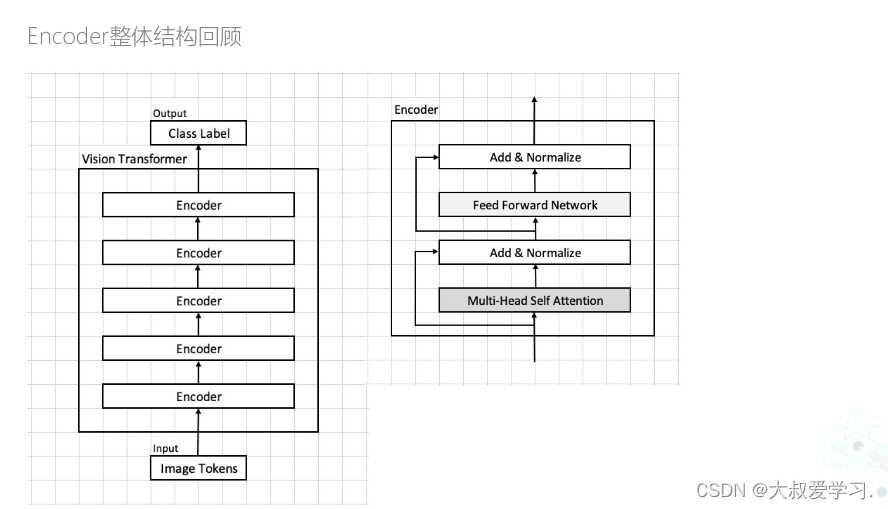
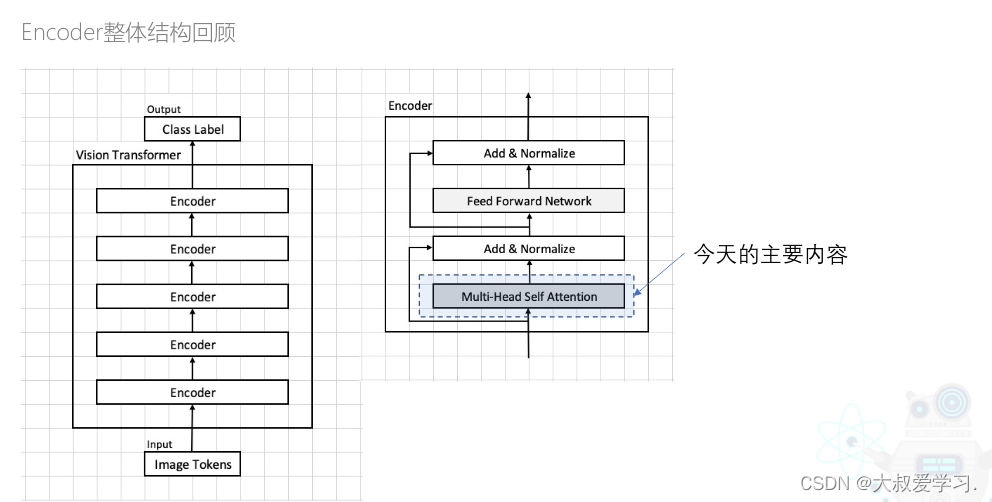
Transformer中的attention
上述是RNN中的attention机制,下面来论述attention在Transformer中是如何工作的。
x1-x3都是image token,也就是patch embedding后的token特征。他们首先会做一个projection。这里使用了神经网络,或升维,或降维。得到Vector v。v和权重a相乘再相加,得到了attention c。注意,这里的c1是给x1做的attention。

我们又在x的这里另开了一个网络,对x进行另一个网络的projection Projk。得到另一个feature vector k1。他和v1可能维度不同,也可以相同。
x,k,v都是feature vector。a是通过两个k的点积得到的。这里a是一个scalar数值。k1会分别和k1,k2,k3进行点击,得到a1,a2,a3,a称为attention weights。注意里面的Projk是同一个,并且是可学习的。Projk可学习,就相当于a是可学习的,也相当于c是可学习的。
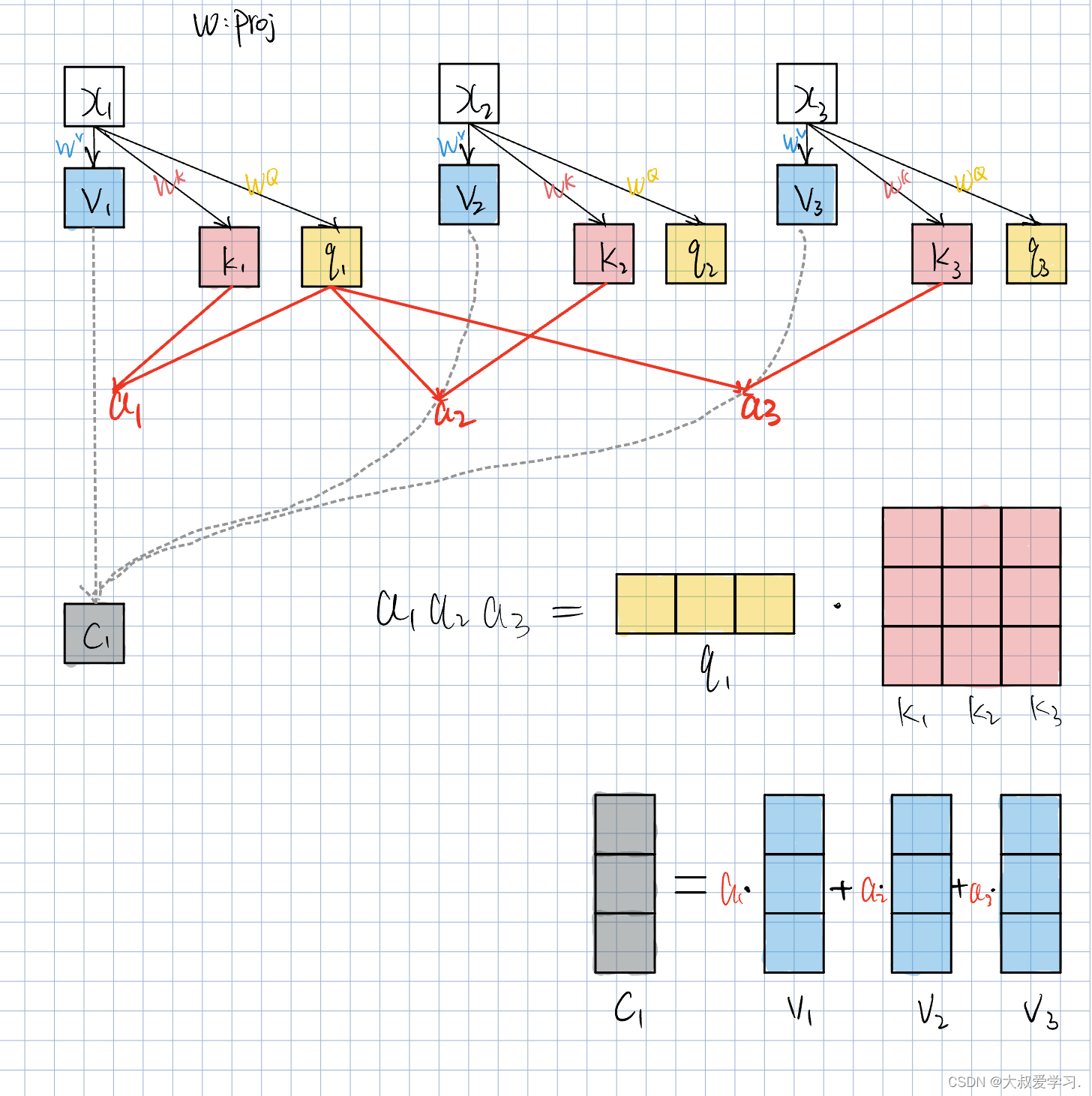
现在我们多出来一个Wq分支。q即query,也就是查询。q和k做点积,和上面讲的k与k做点积并没有不同,也就是我们不再通过k去做点积,而是通过q。query的作用就是去查询与key的相关性。比如q1,当它和其它k1,k2,k3点积加权得到attention c1时,c1就是表示x1与其它x的相关性。上述方法也就是让query和key进行了分离,key作索引功能,query作查询功能。给谁算attention,就用谁的query点积别人的key(包括自己的)。


这里x是vetor,就是一个patch feature,projection其实也是embedding,即提取特征。所以W的列其实就是embedd_dim(本质即卷积操作)。我们的attention是针对每一个token的。x1,x2,x3就是每一个单词token,或者图像的patch。Wq,Wk,Wv参数是不同的,他们都是可学习的。

p是attention weight。attention是表达,是token通过Transformer计算出来的,一个feature vector和其它vector的相关性,就是通过p表达的。

我们为什么要除以dk。variance方差表示数据的离散程度。如果variance值很大时,对于softmax,他会更偏向更大的那个值。如果variance更小,softmax波动就没有那么大。为了避免softmax在更大值上,我们需要把variance拉回来一点,让我们的attention更稳定一点,不能只盯着一个人看,让注意力更均衡一点,雨露均沾。这里是softmax写错了,要写最外面。
也就是我们输入多少个token,我们输出的attention z还是多少个。以上内容就是全部的self-attention了。
下面我们再讲讲multi-head self-attention。
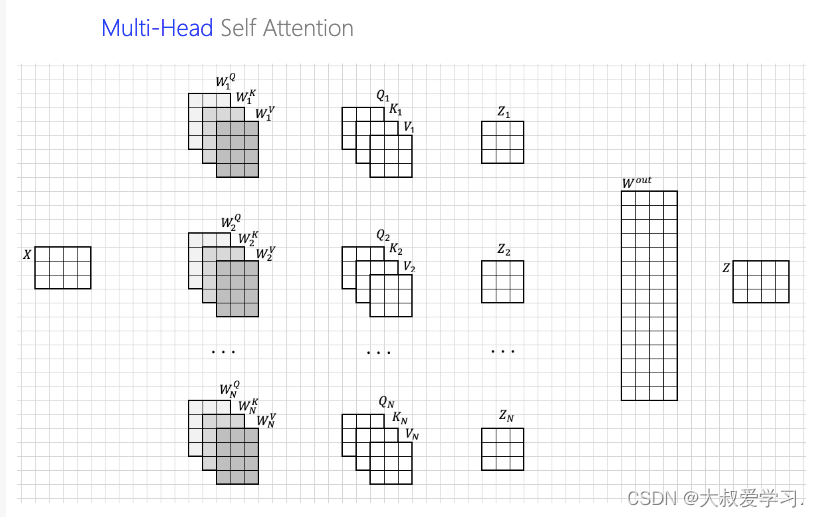
multi-head self-attention就是你看你的,我看我的。让不同的人去看相同的序列信息,qkv进行复制,但是他们的参数是不同的,然后最后集众家所长。大家最后统一一下意见。这个统一也是learnable的。z输出也是不变维度,还是n行(和token个数对应)。
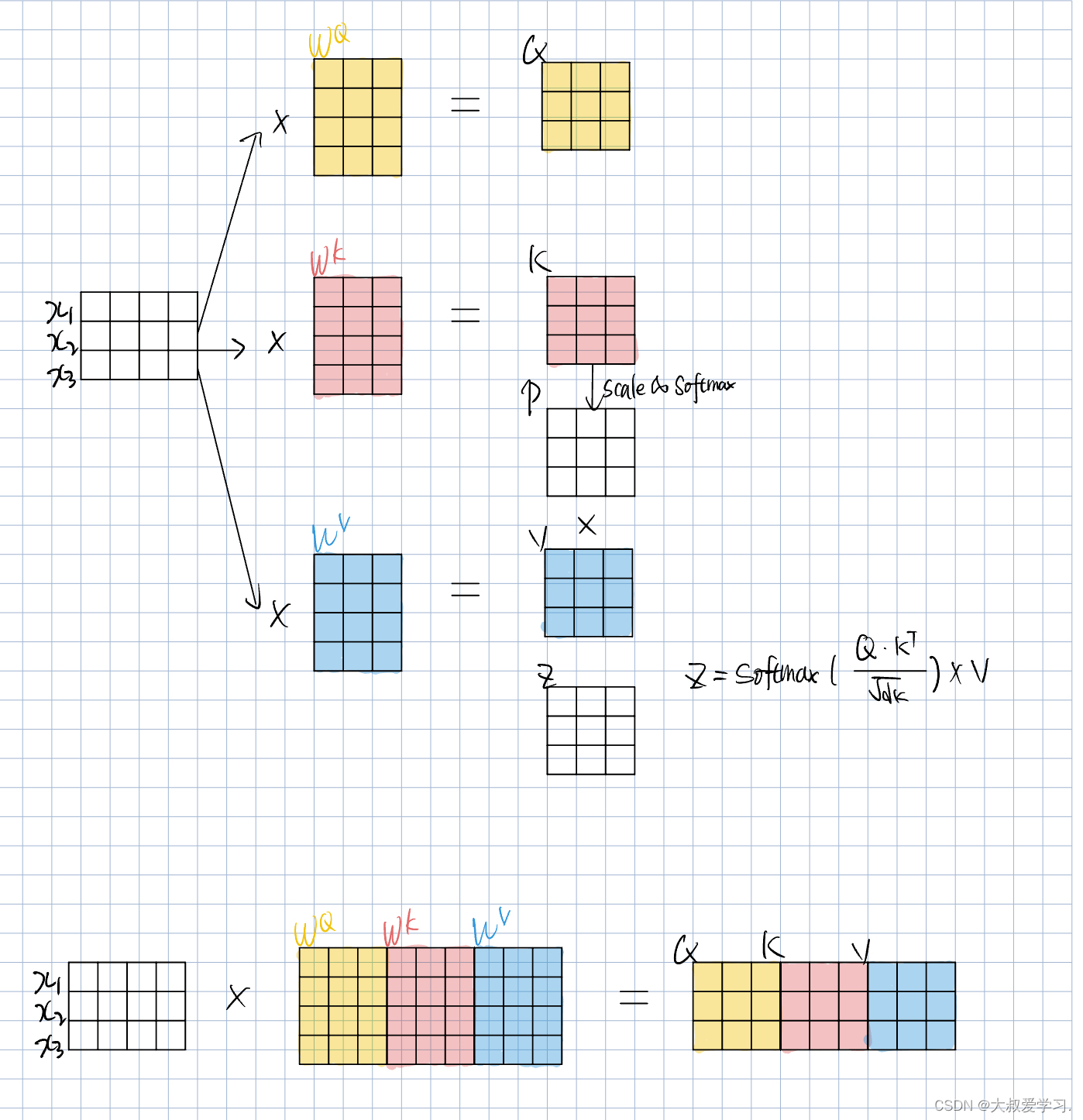
下面说下如何进行高效的attention计算,用矩阵计算。
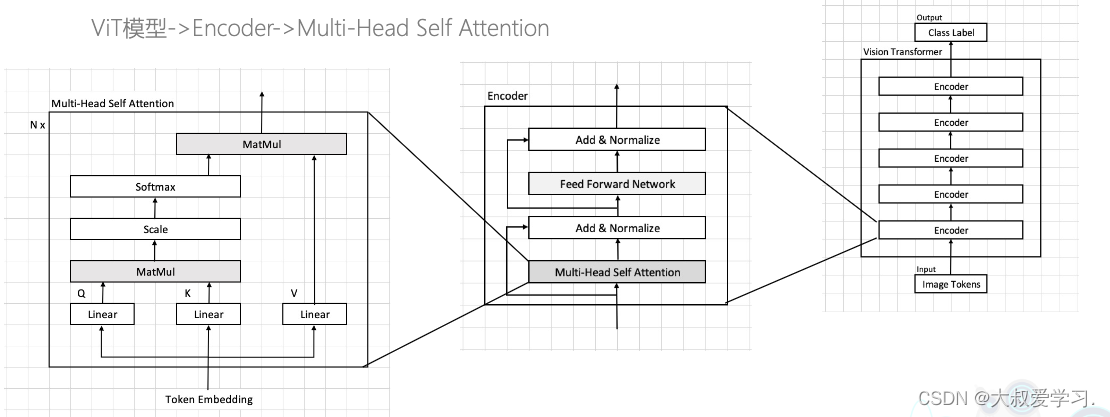
将Multi-Head Attention带回Vit整体结构中,如下图所示。
下面是Attention class的代码:
import paddle import paddle.nn as nn paddle.set_device('cpu') class Attention(nn.Layer): def __init__(self, embed_dim, num_heads, qkv_bias, qk_scale, dropout=0., attention_dropout=0.): super().__init__() self.embed_dim = embed_dim self.num_heads = num_heads self.head_dim = int(embed_dim / num_heads) self.all_head_dim = self.head_dim * num_heads # 避免不能整除 self.qkv = nn.Linear(embed_dim, self.all_head_dim * 3, bias_attr=False if qkv_bias is False else None) # bias=None,在paddle里是默认给0 self.scale = self.head_dim ** -0.5 if qk_scale is None else qk_scale self.softmax = nn.Softmax(-1) self.proj = nn.Linear(self.all_head_dim, embed_dim) def transpose_multi_head(self, x): new_shape = x.shape[:-1] + [self.num_heads, self.head_dim] x = x.reshape(new_shape) # [B, N, num_heads, head_dim] x = x.transpose([0, 2, 1, 3]) # [B, num_heads, N, head_dim] return x def forward(self, x): # [B, N, all_head_dim] * 3 B, N, _ = x.shape qkv = self.qkv(x).chunk(3, -1) # [B, N, all_head_dim] * 3 q, k, v = map(self.transpose_multi_head, qkv) # q,k,v: [B, num_heads, N, head_dim] attn = paddle.matmul(q, k, transpose_y=True) # q * k^t attn = self.scale * attn attn = self.softmax(attn) # [B, num_heads, N] attn_weight = attn # dropout # attn:[B, num_heads, N, N] out = paddle.matmul(attn, v) out = out.transpose([0, 2, 1, 3]) # attn:[B, N, num_heads, head_dim] out = out.reshape([B, N, -1]) out = self.proj(out) # dropout return out, attn_weight def main(): t = paddle.randn([4, 16, 96]) print('input shape = ', t.shape) model = Attention(embed_dim=96, num_heads=8, qkv_bias=False, qk_scale=None, dropout=0., attention_dropout=0.) print(model) out, attn_weights = model(t) print(out.shape) # [4, 16, 96] print(attn_weights.shape) # [4, 8, 16, 16] 8是num_heads,8个人去看; N(num_patch)=16, 16个img token互相看 if __name__ == "__main__": main()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64

