
热门标签
热门文章
- 1Linux:信号集_linux信号集
- 2pip安装模块警告InsecurePlatformWarning: A true SSLContext object is not available.
- 3《K12智能批改技术的实践与探索》的整理总结--NLP自然语言处理峰会_基于自然语言处理系统的学生作文批改方法
- 4论文解读 CodeX,Human Eval_humaneval论文
- 5绘唐3官网_绘唐官网
- 6Non-local的一些理解
- 7mybatis set标签用法
- 8NumPy与线性代数:掌握机器学习中的矩阵操作艺术
- 9浏览器打开PDF卡在加载(侧边翻译插件打不开PDF)
- 10flink写入paimon流程代码_flink 写入paimon外部表hive
当前位置: article > 正文
注意力机制与交叉注意力:理论、公式与实现_交叉注意力机制
作者:爱喝兽奶帝天荒 | 2024-07-20 05:06:40
赞
踩
交叉注意力机制
概述
在自然语言处理(NLP)和深度学习领域,注意力机制和交叉注意力是两种强大的技术,它们允许模型在处理序列数据时动态地聚焦于最重要的部分。本文将介绍这两种机制的数学原理,并通过代码示例展示如何在PyTorch中实现它们。
注意力机制(Attention Mechanism)
注意力机制模仿了人类在处理信息时的聚焦行为,它可以帮助模型在处理长序列时关注最相关的信息。
数学公式
给定一个序列 (X = [x_1, x_2, …, x_n]),其中 (x_i) 是序列中第 (i) 个元素的向量表示。注意力机制通过计算每个元素的注意力分数和输出来工作:
-
注意力分数:
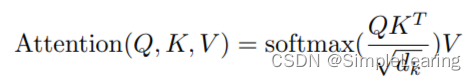
其中,(d_k) 是键向量的维度,用于缩放点积。
-
输出:
输出是所有元素的加权和,权重由注意力分数决定。
代码实现
import torch import torch.nn.functional as F def scaled_dot_product_attention(Q, K, V, mask): d_k = torch.tensor(Q.size(-1)) # 假设Q, K, V的最后一个维度是d_k scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(d_k) if mask is not None: scores = scores.masked_fill(mask == 0, float('-inf')) attention = F.softmax(scores, dim=-1) return torch.matmul(attention, V) # 示例输入 Q = torch.randn(1, 10, 64) # 查询序列 (1个序列, 10个元素, 64维向量) K = Q # 在自注意力中,键和值与查询来自同一序列 V = Q # 同上 # 假设我们没有mask mask = None # 计算自注意力 self_attention_output = scaled_dot_product_attention(Q, K, V, mask)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
交叉注意力(Cross-Attention)
交叉注意力是注意力机制的一种,它处理两个相关但不同的序列。这在多模态任务中特别有用,如图像和文本的联合处理。
数学公式
对于查询序列 (Q = [q_1, q_2, …, q_m]) 和键序列 (K = [k_1, k_2, …, k_n]),以及对应的值序列 (V = [v_1, v_2, …, v_n]),交叉注意力的计算如下:
-
注意力分数:
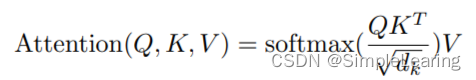
其中,(d_k) 是键向量的维度。 -
输出:
输出是查询序列中每个元素的加权值向量之和,权重由与键序列的注意力分数决定。
代码实现
def cross_attention(query, key, value, key_mask): d_k = torch.tensor(key.size(-1)) # 假设key和value的最后一个维度是d_k scores = torch.matmul(query, key.transpose(-2, -1)) / torch.sqrt(d_k) scores = scores.masked_fill(key_mask == 0, float('-inf')) # 应用mask attention = F.softmax(scores, dim=-1) return torch.matmul(attention, value) # 示例输入 query = torch.randn(1, 5, 64) # 查询序列 (1个序列, 5个元素, 64维向量) key = torch.randn(1, 10, 64) # 键序列 (1个序列, 10个元素, 64维向量) value = key # 在这个例子中,值序列与键序列相同 key_mask = torch.tensor([ [0, 0, 1, 1, 0, 0, 0, 0, 0] # 一个简单的mask,用于忽略特定的键 ], dtype=torch.float32) # 同上 # 计算交叉注意力 cross_attention_output = cross_attention(query, key, value, key_mask)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
结论
注意力机制和交叉注意力为深度学习模型提供了一种有效的方式来处理序列数据中的复杂关系。通过理解它们的数学原理和实现细节,我们可以更好地设计和优化模型,以处理各种序列处理任务。
参考文献
- Vaswani et al. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008).
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/爱喝兽奶帝天荒/article/detail/855285
推荐阅读
相关标签

