
- 1插入排序和希尔排序
- 2LIUNX /SYS/CLASS/GPIO捕获IO输入状态 C语言
- 3Android Automotive:在路上释放 Android 操作系统的力量
- 4java判断两个文件是否相同_java对比文件是否一致
- 5上位机图像处理和嵌入式模块部署(树莓派4b和pyqt5界面开发)_树莓派安装pyqt5
- 6C++ 结构型设计模式
- 7VMware安装Centos7虚拟机超详细图文教程_虚拟机 brokerssent: [localhost.localdomain]
- 8**为您的Vite项目提速:探索*vite-plugin-compression2*的魅力**
- 9AI工具(星形工具)(光晕工具)(移动复制)(柜子绘制)5.12
- 10大数据技术中的伦理问题
虚拟化之---virtio通信_虚拟化通信
赞
踩
一、理解virtio的背景
我们知道虚拟化hypervisor大的类型分为两种,全虚拟化和半虚拟化。
在全虚拟化的解决方案中,guest VM 要使用底层 host 资源,需要 Hypervisor 来截获所有的请求指令,然后模拟出这些指令的行为,这样会带来很多性能上的开销。半虚拟化通过底层硬件辅助的方式,将部分没必要虚拟化的指令通过硬件来完成,Hypervisor 只负责完成部分指令的虚拟化,要做到这点,需要 guest 来配合,guest 完成不同设备的前端驱动程序,Hypervisor 配合 guest 完成相应的后端驱动程序,这样两者之间通过某种交互机制就可以实现高效的虚拟化过程。
让我们以uart举例来说明和理解:
在完全虚拟化的情况下,当 guest VM 需要与物理串口进行通信时,它会发出读取或写入串口数据的指令。Hypervisor 需要截获这些指令,并模拟出串口的行为,将数据传递给物理串口或从物理串口接收数据。
在半虚拟化的情况下,底层硬件提供了辅助机制,使得部分指令可以直接由硬件完成,而无需 Hypervisor 的干预。对于 UART,底层硬件可能提供了一种机制,使 guest VM 的前端驱动程序能够直接访问物理串口,而无需 Hypervisor 的介入。这样,当 guest VM 发出读取或写入串口数据的指令时,前端驱动程序可以直接与物理串口进行交互,完成数据的传输。
然而,仍然有一些指令需要 Hypervisor 的虚拟化支持。例如,当 guest VM 需要打开或关闭串口时,这些操作可能涉及到对底层硬件的配置,需要 Hypervisor 的参与来确保正确的虚拟化行为。在这种情况下,Hypervisor 会截获相关指令,并模拟出打开或关闭串口的行为。
通过底层硬件的辅助,半虚拟化可以将一部分不必要的指令交给硬件来完成,减轻了 Hypervisor 的负担,提高了虚拟化的效率。在 UART 的例子中,底层硬件提供了直接访问物理串口的能力,使得部分串口操作可以直接由 guest VM 的前端驱动程序完成,而 Hypervisor 只需要处理一些需要虚拟化支持的操作。
如果是全虚拟化,比如以kvm为例,大致的数据流是如下:
整个数据通路如下:
a.Guest VM 发送数据: Guest VM 中的应用程序或驱动程序向虚拟的 UART 设备发送数据。
b.QEMU 截获操作: QEMU 截获了 guest VM 中对虚拟 UART 设备的操作。
c.QEMU 模拟并转发: QEMU 根据截获的操作,将数据发送给真实的 UART 设备。这可能涉及到与主机操作系统进行交互,以确保数据正确地传递给物理 UART 设备。QEMU相当于一个应用,就可以使用host硬件资源了,比如在windows下就是设备管理器的物理设备,linux下就是dev对应的设备。
d.Host 主机的 UART 设备接收数据: Host 主机上的真实 UART 设备接收到数据。
二、virtio架构
virtio 和 virtio-ring 可以看做是一层,virtio-ring 实现了 virtio 的具体通信机制和数据流程.
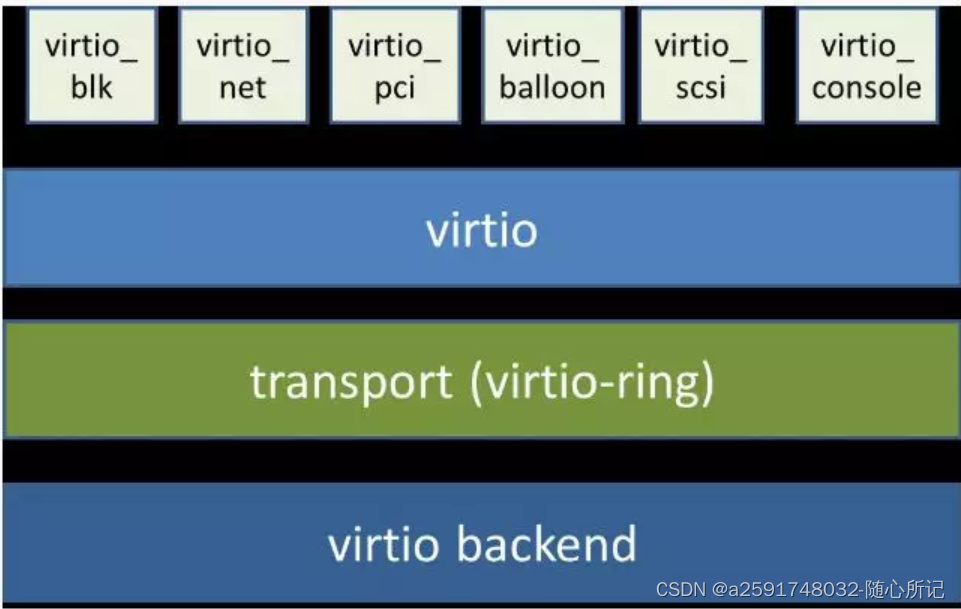
三、virtio通信机制

Front-End Virtio driver (a.k.a. frontend driver, or FE driver in this document)
Virtio adopts a frontend-backend architecture, which enables a simple but flexible framework for both frontend and backend Virtio driver. The FE driver provides APIs to configure the interface, pass messages, produce requests, and notify backend Virtio driver. As a result, the FE driver is easy to implement and the performance overhead of emulating device is eliminated.
Back-End Virtio driver (a.k.a. backend driver, or BE driver in this document)
Similar to FE driver, the BE driver, runs either in user-land or kernel-land of host OS. The BE driver consumes requests from FE driver and send them to the host’s native device driver. Once the requests are done by the host native device driver, the BE driver notifies the FE driver about the completeness of the requests.
Straightforward: Virtio devices as standard devices on existing Buses
Instead of creating new device buses from scratch, Virtio devices are built on existing buses. This gives a straightforward way for both FE and BE drivers to interact with each other. For example, FE driver could read/write registers of the device, and the virtual device could interrupt FE driver, on behalf of the BE driver, in case of something is happening. Currently Virtio supports PCI/PCIe bus and MMIO bus. In ACRN project, only PCI/PCIe bus is supported, and all the Virtio devices share the same vendor ID 0x1AF4.
Efficient: batching operation is encouraged
Batching operation and deferred notification are important to achieve high-performance I/O, since notification between FE and BE driver usually involves an expensive exit of the guest. Therefore batching operating and notification suppression are highly encouraged if possible. This will give an efficient implementation for the performance critical devices.
Standard: virtqueue
All the Virtio devices share a standard ring buffer and descriptor mechanism, called a virtqueue, shown in Figure 6. A virtqueue is a queue of scatter-gather buffers. There are three important methods on virtqueues:
add_bufis for adding a request/response buffer in a virtqueueget_bufis for getting a response/request in a virtqueue, andkickis for notifying the other side for a virtqueue to consume buffers.
The virtqueues are created in guest physical memory by the FE drivers. The BE drivers only need to parse the virtqueue structures to obtain the requests and get the requests done. How virtqueue is organized is specific to the User OS. In the implementation of Virtio in Linux, the virtqueue is implemented as a ring buffer structure called vring.
In ACRN, the virtqueue APIs can be leveraged directly so users don’t need to worry about the details of the virtqueue. Refer to the User VM for more details about the virtqueue implementations.
virtqueue的定义:
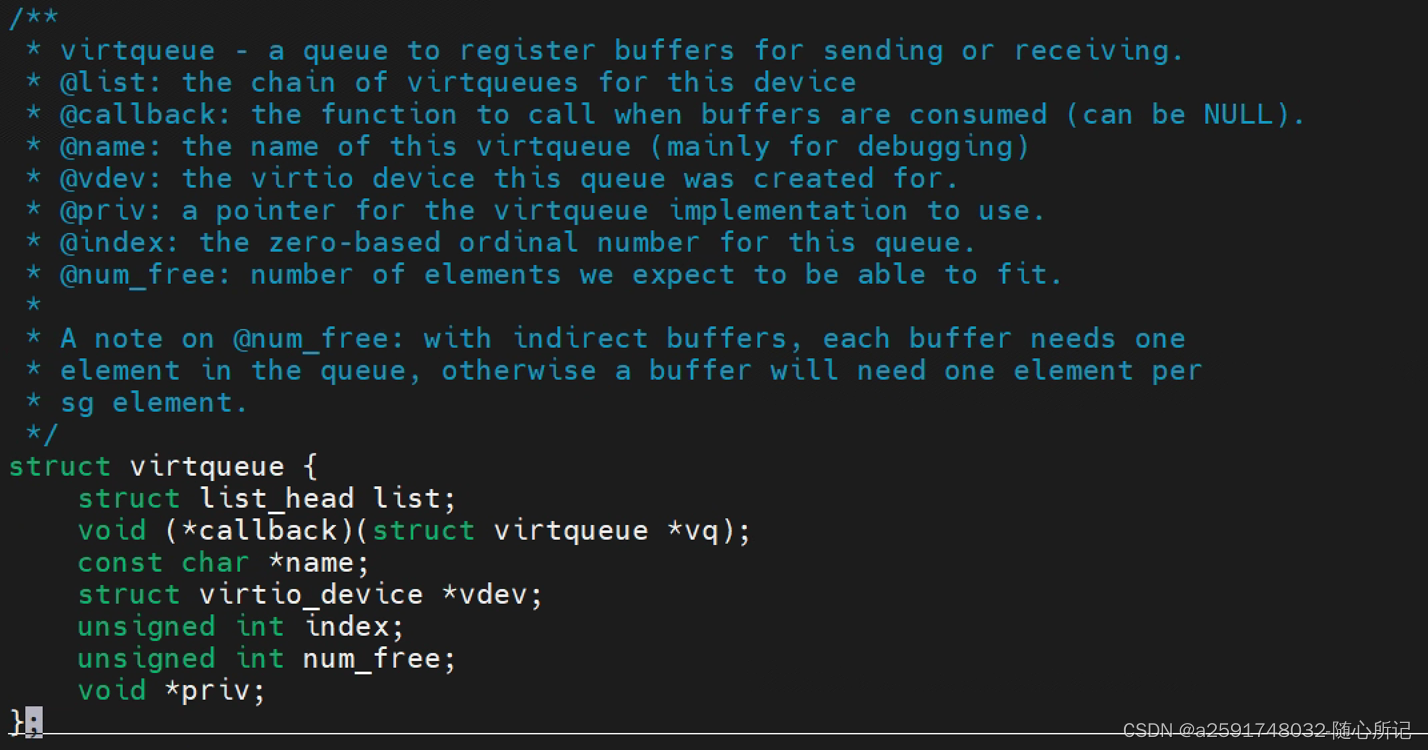
virtio核心代码:
- Kconfig virtio_balloon.c virtio_input.c virtio_pci_common.c virtio_pci_legacy.c virtio_ring.c
- Makefile virtio.c virtio_mmio.c virtio_pci_common.h virtio_pci_modern.c
比如guest 要向 host 发送数据,首先,guest 通过函数 virtqueue_add_buf 将存有数据的 buffer 添加到 virtqueue 中,然后调用 virtqueue_kick 函数,virtqueue_kick 调用 virtqueue_notify 函数,通过写入寄存器的方式来通知到 host。host 调用 virtqueue_get_buf 来获取 virtqueue 中收到的数据。
当 guest 向 virtqueue 中写数据时,实际上是向 desc 结构指向的 buffer 中填充数据,完了会更新 available ring,然后再通知 host。
当 host 收到接收数据的通知时,首先从 desc 指向的 buffer 中找到 available ring 中添加的 buffer,映射内存,同时更新 used ring,并通知 guest 接收数据完毕
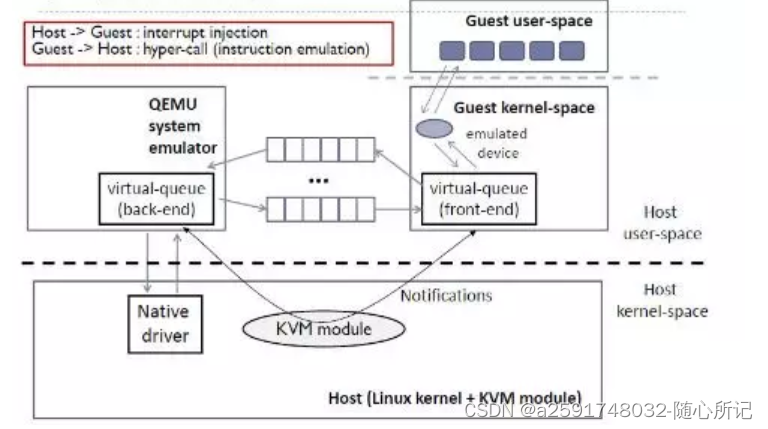
四、virtio总线案例
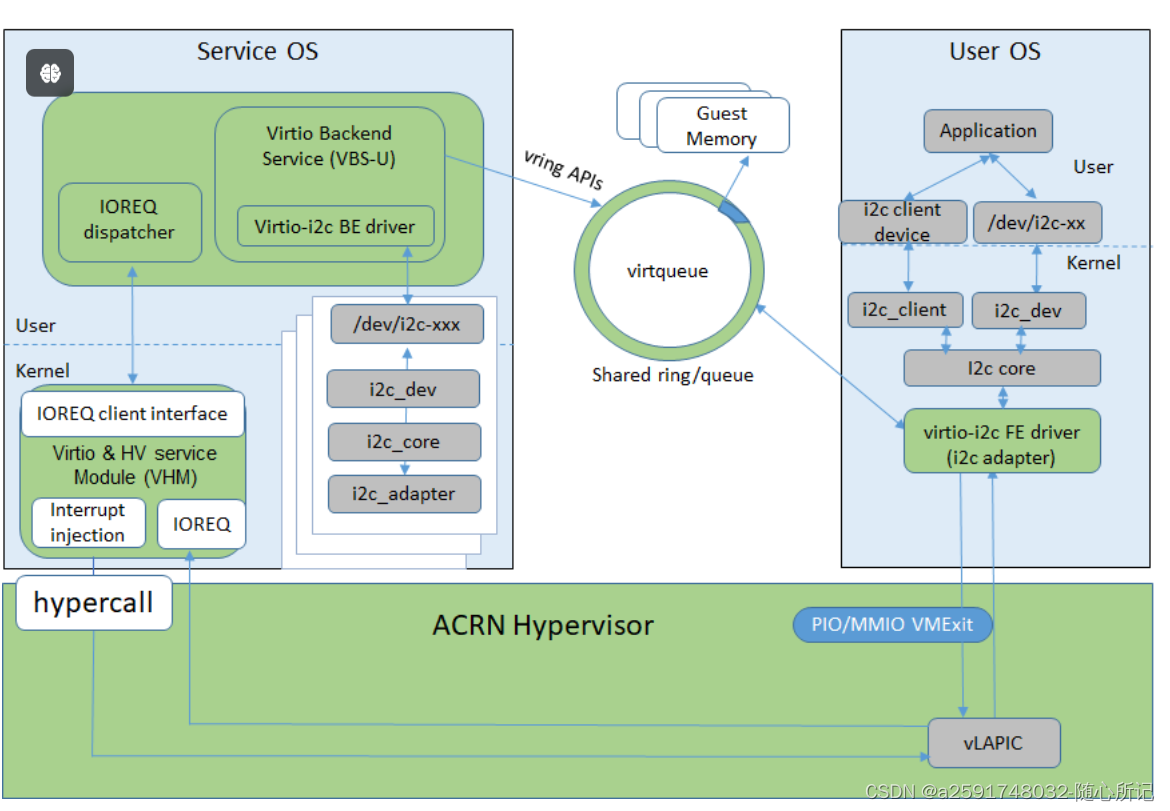
FE i2c driver <-> BE i2c driver <--> i2c client <-> i2c resource manager <-> i2c phsyical driver
说明:其中be driver可以在host的应用层来实现,而不是叫driver就要放到host的驱动中。在虚拟化厂家的be driver中收到guest os发过来的virtqueue 的notify消息后,然后进行相关处理。
SPI也是类似:
dtsi中配置virt spi:
spi1:spi1@11100001{
compatible = "platform,virtio-spi"
}
driver中添加spi-virtio.c相关驱动。
该driver中包含了spi 的属性配置,比如chip_select、spi mode、 spi speed_hz、spi_bus等信息,然后通过sg_init_one函数初始化tx_buf和rx_buf队列,以及head queue,返回队列等,然后调用virtqueue_kick来通知host(用的是notify share mem),并通过wait_event等待返回值。
guest 对virtio 中断的处理
guest kernel在vp_try_to_find_vqs中选择调用vp_request_intx或vp_request_msix_vectors, 在vp_request_intx中会使用request_irq注册中断,中断处理函数就是vp_interrupt.
从vp_interrupt->vp_vring_interrupt->vring_interrupt一层层调用,最终执行vq->vq.callback(&vq->vq).
而vq->vq.callback是在vring_new_virtqueue中初始化的:vq->vq.callback = callback.
从vring_new_virtqueue<-setup_vq<-vp_setup_vq<-vp_try_to_find_vqs<-vp_find_vqs<-vp_modern_find_vqs<-virtio_config_ops.find_vqs依次往上走
就会看到调用find_vqs的函数下callbacks对应的有virtblk_done, balloon_ack, control_intr, 或者virtscsi_req_done.
然后应用层可以看到/dev/spi节点,这样guest就可以正常操作虚拟出的spi设备了。
参考官网ACRN:
What is ACRN — Project ACRN™ v 1.6 documentation
参考QNX:
https://www.qnx.com/developers/docs/7.0.0/index.html#com.qnx.doc.hypervisor.nav/topic/bookset.html可以参考博文(写的非常好):
https://www.qnx.com/developers/docs/7.0.0/index.html#com.qnx.doc.hypervisor.nav/topic/bookset.html

