
热门标签
热门文章
- 1用 Sentence Transformers v3 训练和微调嵌入模型
- 2网络中常见攻击及其防御方式_smurf攻击
- 3华为od机试真题:火星符号运算(Python)
- 4git 克隆/拉取分支指定目录(稀疏检出)_git clone 分支个别文件夹
- 5git配置gitlab报错:Clone failed: Could not create work tree dir ‘ppt_indicators‘: Permission denied
- 6【计算机网络】一文带你弄懂DNS解析过程(最强详解!!)
- 7Ubuntu 20.04 LTS 安装zabbix监控部署_ubuntu20.04安装zabbix
- 8苹果开源iOS和macOS内核源代码 | 十一献礼_macos 和 ios 内核 xnu 可编译源代码
- 9Prometheus 监控 RabbitMQ
- 10用Python写个方面级情感分析系统
当前位置: article > 正文
十三、大模型项目部署与交付_大模型服务端部署
作者:爱喝兽奶帝天荒 | 2024-07-26 21:09:39
赞
踩
大模型服务端部署
1 硬件选型
- CUDA 核心和 Tensor 核心
- CUDA 核心:是NVIDIA开发的并行计算平台和编程模型,用于GPU上的能用计算,可做很多的工作。应用在游戏、图形渲染、天气预测和电影特效
- Tensor 核心:张量核心,专门设计用于深度学习的矩阵运算,加速深度学习算法中的关键计算过程
- 常用的GPU

| 显卡 | 目标市场 | 性能 | 应用场景 | 价格 |
|---|---|---|---|---|
| T4 | 企业/AI 推理 | 适中 | AI 推理, 轻量级训练, 图形渲染 | 7999(14G) |
| 4090 | 消费者 | 非常高 | 通用计算, 图形渲染, 高端游戏, 4K/8K 视频编辑 | 14599(24G) |
| A10 | 企业/图形 | 适中 | 图形渲染, 轻量级计算 | 18999(24G) |
| A6000 | 企业/图形 | 适中 | 图形渲染, 轻量级计算 | 32999(48G) |
| V100 | 数据中心/AI | 高 | 深度学习训练/推理, 高性能计算 | 42999(32G) |
| A100 | 数据中心/AI | 高 | 深度学习训练/推理, 高性能计算 | 69999(40G) |
| A800 | 数据中心/AI | 中等 | 深度学习推理, 高性能计算, 大数据分析 | 110000 |
| H100 | 数据中心/AI | 高 | 深度学习训练/推理, 高性能计算, 大数据分析 | 242000 |
- LPU

Jonathan Ross - 前谷歌工程师,参与设计 TPU 芯片核心。后创办 Groq 公司,创造了世界首个语言处理单元 LPU™。
LPU™ 推理引擎可提供卓越 AI 工作负载速度,比其他领先供应商快 18 倍。
- 云服务
国内主流云服务厂商
- 阿里云:https://www.aliyun.com/product/ecs/gpu
- 腾讯云:https://cloud.tencent.com/act/pro/gpu-study
- 火山引擎:https://www.volcengine.com/product/gpu
国外主流云服务厂商
- 算力平台
主要用于学习和训练,不适合提供服务。
- Colab:谷歌出品,升级服务仅需 9 美金。https://colab.google.com
- Kaggle:免费,每周 30 小时 T4,P100 可用。https://www.kaggle.com
- AutoDL:价格亲民,支持 Jupyter Notebook 及 ssh,国内首选。https://www.autodl.com
2 全球大模型选型
- 国产大模型
国产模型列表
| 公司 | 名称 | 网址 | 备注 |
|---|---|---|---|
| 百度 | 文心一言 | https://yiyan.baidu.com/ | |
| 阿里云 | 通义千问 | https://tongyi.aliyun.com/ | 开源模型Qwen-1.8B,7B,14B,72B、Qwen-VL和Qwen-Audio |
| 科大讯飞 | 星火 | https://xinghuo.xfyun.cn/ | |
| 百川智能 | 百川 | https://chat.baichuan-ai.com/ | 开源小模型baichuan-7B和Baichuan-13B |
| 零一万物 | Yi | https://github.com/01-ai/Yi | 6B 和 34B 开源模型 |
| 360 | 智脑/一见 | https://ai.360.cn/, https://github.com/360CVGroup/SEEChat | |
| 昆仑万维 | 天工 Skywork | https://github.com/SkyworkAI/Skywork | 开源且可商用,无需单独申请,Skywork 是由昆仑万维集团·天工团队开发的一系列大型模型,本次开源的模型有 Skywork-13B-Base 模型、Skywork-13B-Chat 模型、Skywork-13B-Math 模型和 Skywork-13B-MM 模型 |
| 腾讯 | 混元 | https://hunyuan.tencent.com/ | |
| 月之暗面 | Moonshot | https://www.moonshot.cn/ | “长文本”大模型 支持 20 万字输入 |
| 商汤科技 | 商量 | https://chat.sensetime.com/ |
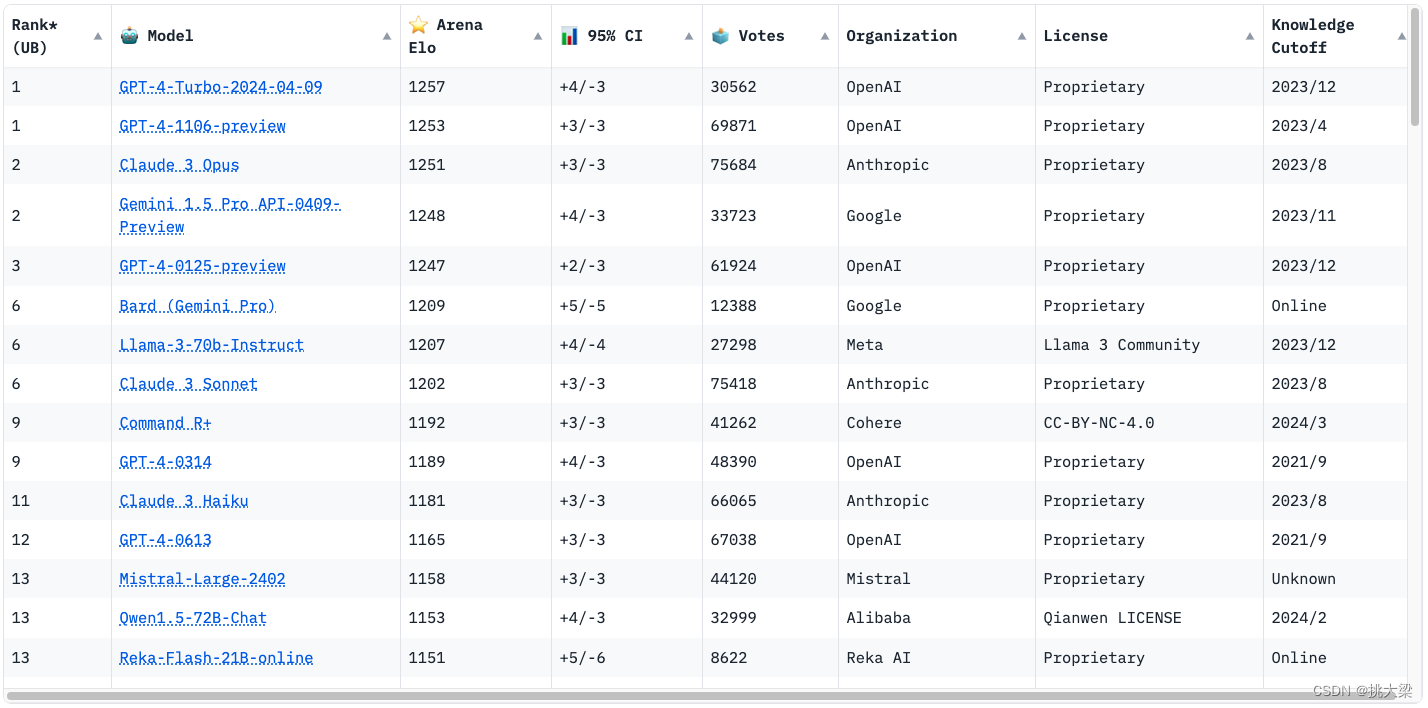

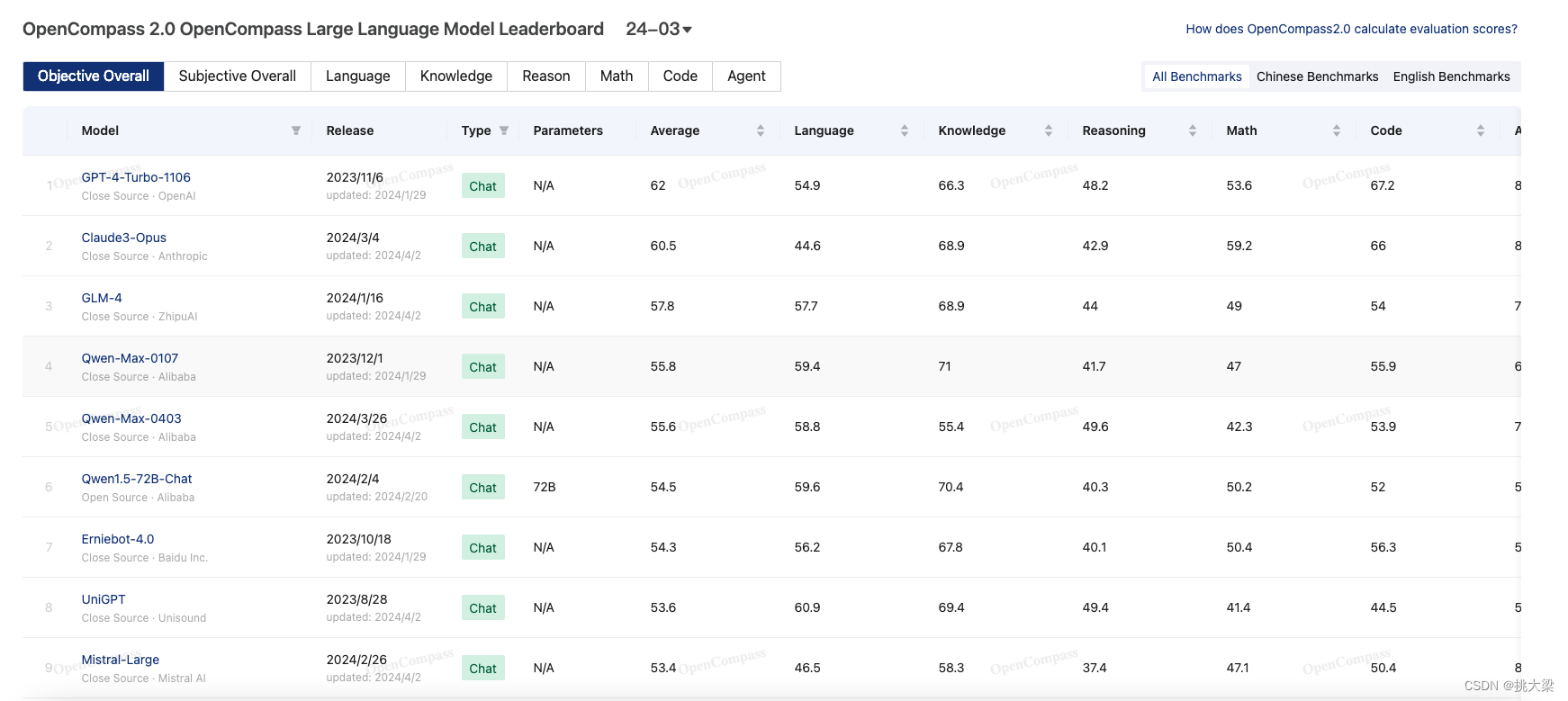
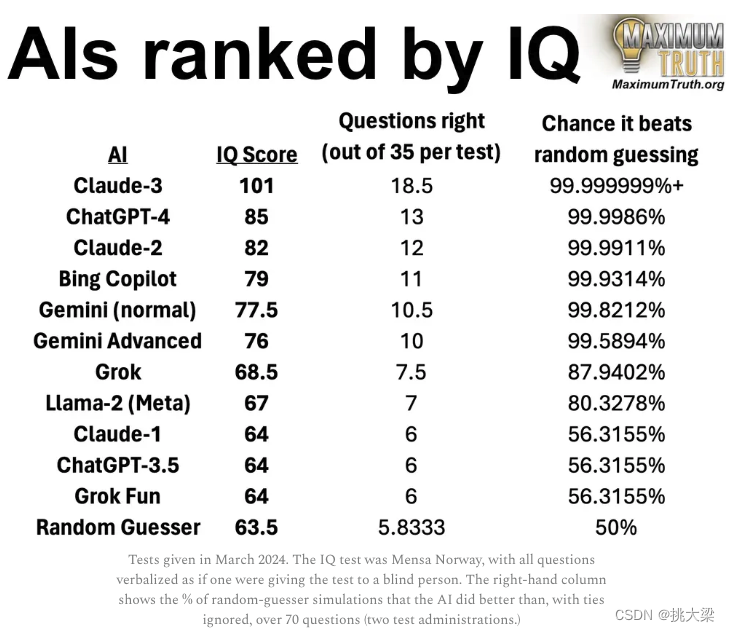
3 OLLAMA部署
- https://ollama.com/

- ollama run llama3

- run llama3
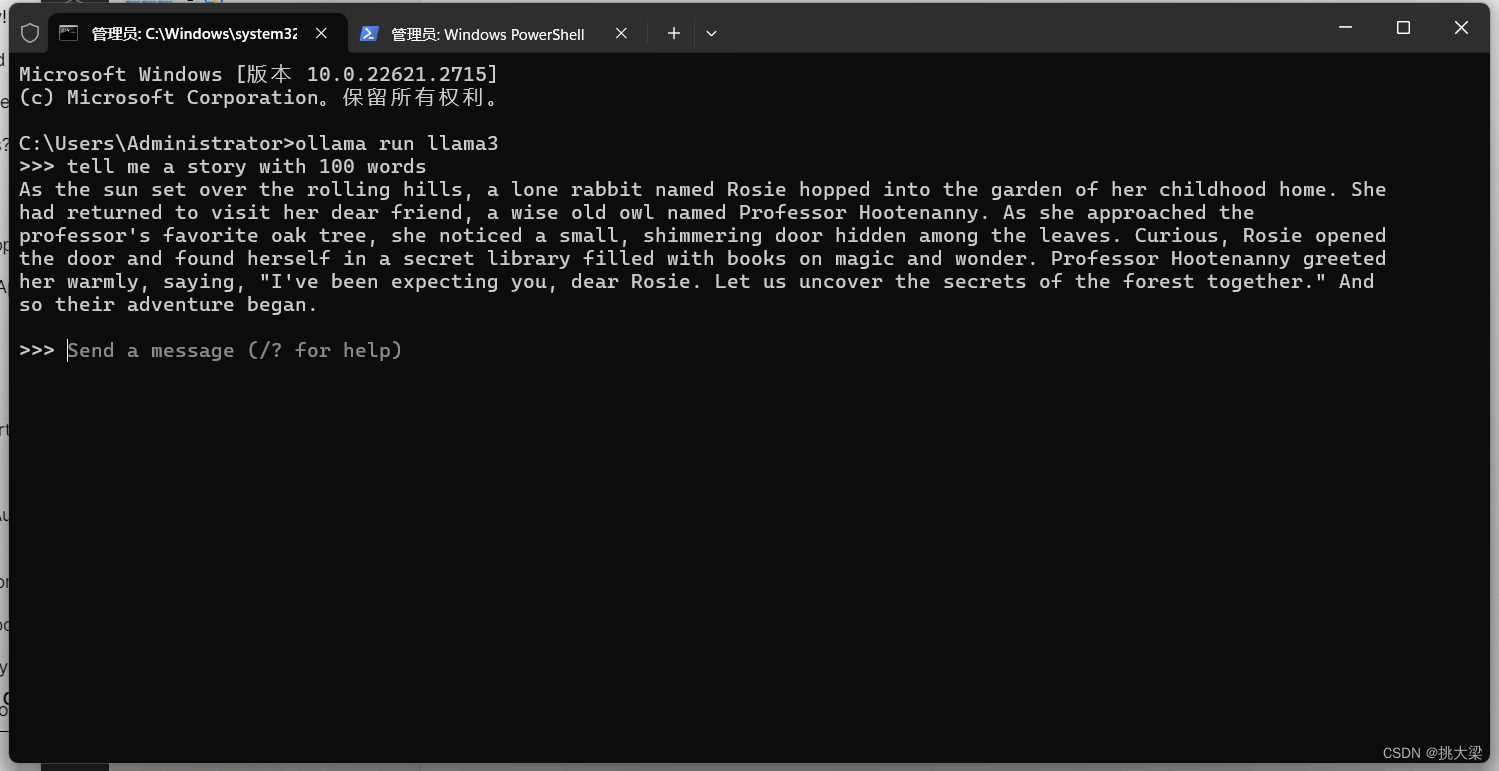
4. OpenWebUI 前端页面与大模型交互
4 VLLM部署

vLLM 是一个快速且易于使用的库,用于进行大型语言模型(LLM)的推理和服务。它具有以下特点:
-
速度快:
在每个请求需要 3 个并行输出完成时的服务吞吐量。vLLM 比 HuggingFace Transformers(HF)的吞吐量高出 8.5 倍-15 倍,比 HuggingFace 文本生成推理(TGI)的吞吐量高出 3.3 倍-3.5 倍 -
优化的 CUDA 内核
-
灵活且易于使用:
-
与流行的 Hugging Face 模型无缝集成。
-
高吞吐量服务,支持多种解码算法,包括并行抽样、束搜索等。
-
支持张量并行处理,实现分布式推理。
-
支持流式输出。
-
兼容 OpenAI API 服务器。
支持的模型
vLLM 无缝支持多个 Hugging Face 模型,包括 Aquila、Baichuan、BLOOM、Falcon、GPT-2、GPT BigCode、GPT-J、GPT-NeoX、InternLM、LLaMA、Mistral、MPT、OPT、Qwen 等不同架构的模型。
# (Recommended) Create a new conda environment.
conda create -n myenv python=3.9 -y
conda activate myenv
# Install vLLM with CUDA 12.1.
pip install vllm
- 1
- 2
- 3
- 4
- 5
- 6
- Prepared Model
以Yi-6B-Chat为例, 这个模型需要提前下载到服务器 - Run
python -m vllm.entrypoints.openai.api_server --model /root/autodl-tmp/Yi-6B-Chat --trust-remote-code --port 6006
- 1
使用autodl算力服务
curl https://u394727-bf57-ff9e7382.westb.seetacloud.com:8443/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/root/autodl-tmp/Yi-6B-Chat",
"max_tokens":60,
"messages": [
{
"role": "user",
"content": "你知道承德吗?"
}
]
}'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

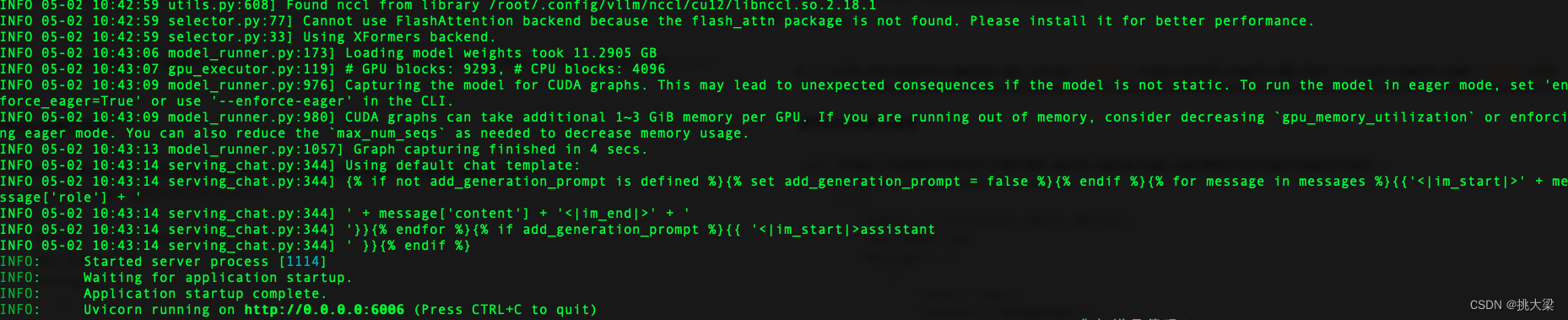

5. 分布式推理
要运行多 GPU 服务,请在启动服务器时传入 --tensor-parallel-size 参数。
例如,要在 2 个 GPU 上运行 API 服务器:
python -m vllm.entrypoints.openai.api_server --model /root/autodl-tmp/Yi-6B-Chat --dtype auto --api-key token-agiclass --trust-remote-code --port 6006 --tensor-parallel-size 2
- 1
5 Dify部署
- dify
- installation
cd docker
docker compose up -d
- 1
- 2
6 内容安全
敏感词库管理与用户输入过滤:
- 定期更新敏感词汇和短语库,应对文化变迁和当前事件。
- 使用第三方服务或自建工具进行实时输入过滤和提示。推荐使用:
7 备案步骤
什么情况下要备案?
- 对于 B2B 业务,不需要备案。
- 但在 B2C 领域,一切要视具体情况而定。
- 如果我们自主训练大型模型,这是必要的。
- 但如果是基于第三方模型提供的服务,建议选择那些已获得备案并且具有较大影响力的模型。
- 如果你使用了文心一言的模型,可以向他们的客服要相关算法备案号。
备案指南 && 申请引导
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/爱喝兽奶帝天荒/article/detail/887223
推荐阅读
相关标签

